
CRISP-ML(Q)+MLOps and Platform: Стандартизированная методология разработки машинного обучения с гарантией качества
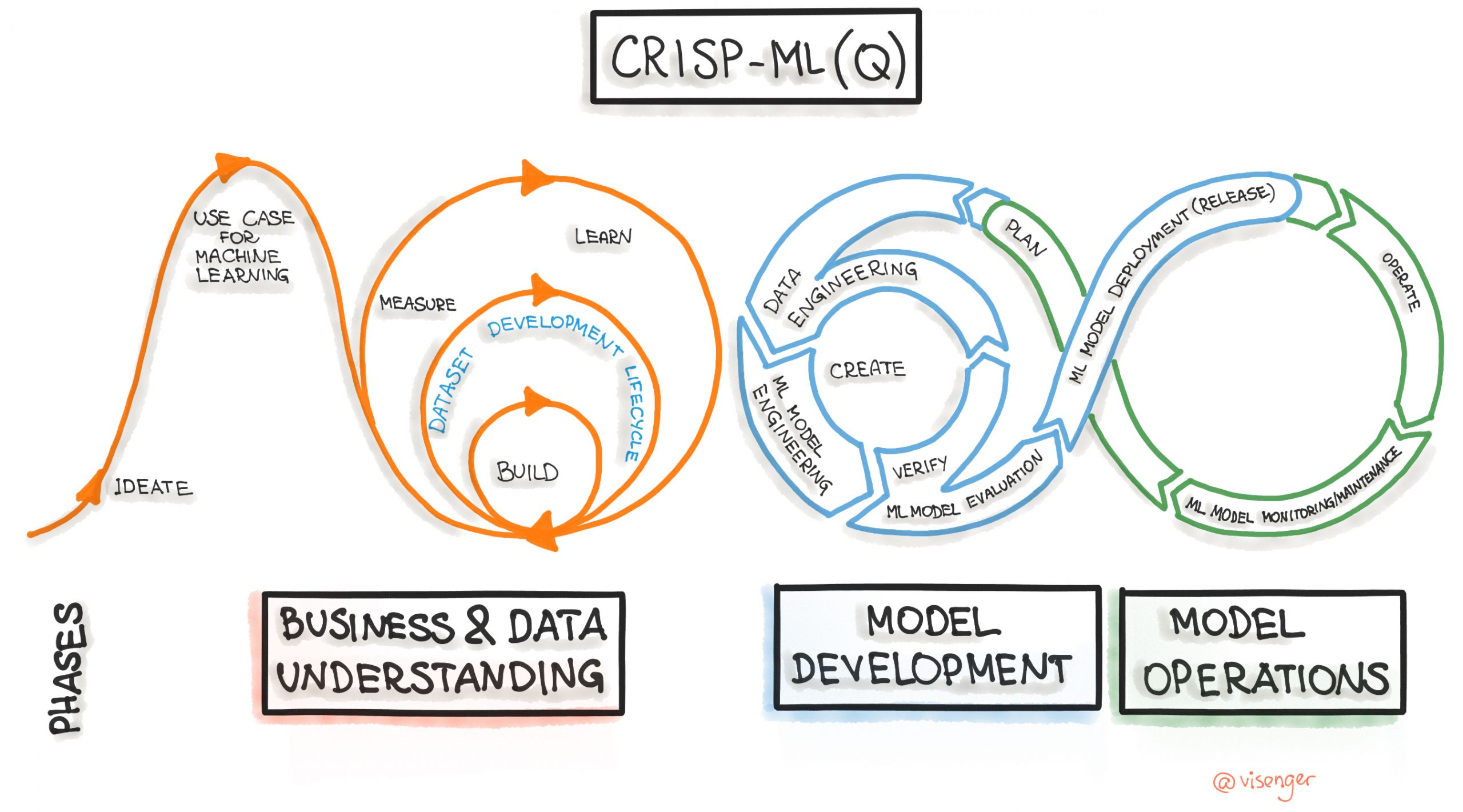
CRISP-ML(Q) (Cross-Industry Standard Process for Machine Learning with Quality Assurance) — это современная процессная модель для управления жизненным циклом ML-проектов. Она была разработана как эволюция классической методологии CRISP-DM (Cross-Industry Standard Process for Data Mining, 1999 г.), которая остается одной из самых популярных методологий для проектов по анализу данных datascience-pm.com. CRISP-ML(Q) адаптирует и расширяет CRISP-DM, добавляя этапы, критичные для промышленного машинного обучения: обеспечение качества, мониторинг и поддержку моделей в продакшене.
Возникновение CRISP-ML(Q) продиктовано статистикой: значительная часть ML-проектов (по некоторым оценкам, 75-85%) не достигали поставленных целей из-за отсутствия стандартизации, проблем с данными и недооценки операционных рисков. В отличие от CRISP-DM, который сосредоточен в первую очередь на процессе анализа данных medium.com, CRISP-ML(Q) охватывает полный жизненный цикл — от бизнес-постановки до эксплуатации ML-систем, делая основной акцент на обеспечении качества на каждом шаге mdpi.com.
Кстати ранее писал про The Big Book of MLOps – 2nd Edition: https://gavrilov.info/all/sintez-the-big-book-of-mlops-2nd-edition/
А еще тут добавлю про ZenML pdf’ку и https://github.com/zenml-io/zenml
Ключевые фазы методологии (6 этапов)
CRISP-ML(Q) структурирует процесс разработки ML-решений в шесть основных взаимосвязанных и итеративных фаз:
- Понимание бизнеса и данных (Business Understanding & Data Understanding)
На этом начальном этапе определяются и понимаются бизнес-цели проекта (например, снижение времени обработки заявки на 20%), а также ключевые показатели эффективности (KPI). Эти бизнес-цели затем переводятся в конкретные задачи машинного обучения. Одновременно проводится глубокий анализ данных: исследуется их доступность, качество, потенциальные проблемы (пропуски, аномалии) и нормативные ограничения (например, GDPR), а также оцениваются необходимые ресурсы. На этом этапе могут использоваться инструменты типа ML Canvas для оценки осуществимости проекта.
- Инженерия данных (Data Engineering)
Эта фаза включает всестороннюю подготовку данных для моделирования. Это очистка данных (обработка пропущенных значений, удаление или корректировка выбросов), их трансформация (нормализация, стандартизация), балансировка классов (методы oversampling/undersampling), а также генерация новых, более информативных признаков (feature engineering). Важным нововведением здесь является внедрение Data Unit Tests для предотвращения ошибок и поддержания качества данных до их использования в моделях.
- Моделирование машинного обучения (Machine Learning Modeling)
На этом этапе команда выбирает подходящие алгоритмы машинного обучения, учитывая такие ограничения, как интерпретируемость модели, вычислительные ресурсы и требования к времени отклика. Происходит обучение моделей, настройка гиперпараметров и оценка их производительности на валидационных наборах данных. Для обеспечения воспроизводимости и отслеживаемости всех экспериментов фиксируются метаданные: используемые гиперпараметры, версии датасетов, окружение выполнения. Применяются такие инструменты, как MLflow и Kubeflow.
- Оценка качества ML-моделей (Quality Assurance)
Это одна из ключевых отличительных фаз CRISP-ML(Q), выделенная в отдельный этап. Здесь проводится всестороннее тестирование модели: оценка ее устойчивости к зашумленным данным, проверка ключевых метрик (accuracy, F1-score, ROC-AUC) и глубокий анализ справедливости (fairness) для выявления и устранения потенциальных смещений в предсказаниях. Решение о переходе к развертыванию принимается только после того, как модель достигнет заданных пороговых значений качества (например, precision > 0.9). Эта фаза может включать проверку надежности, стабильности и объяснимости модели mdpi.com.
- Развертывание (Deployment)
На этом этапе обученная и проверенная модель интегрируется в производственную среду. Развертывание может осуществляться различными способами: как REST-API, микросервис или встроенный плагин. Используются стратегии безопасного развертывания, такие как A/B-тестирование, канареечные релизы или сине-зеленое развертывание. Обязательной частью этой фазы является наличие четкого плана отката на предыдущую версию в случае возникновения сбоев или неожиданной деградации производительности.
- Мониторинг и поддержка (Monitoring & Maintenance)
После развертывания модели начинается фаза непрерывного мониторинга её производительности в реальных условиях. Это критически важно, так как модели машинного обучения могут терять свою эффективность со временем из-за дрейфа данных (concept drift или data drift). Мониторинг включает отслеживание метрик производительности модели, выявление аномалий и автоматическое переобучение при падении метрик или существенном изменении распределения входных данных. Также на этом этапе происходит сбор новых данных, которые могут быть использованы для последующего ретренинга моделей, замыкая цикл улучшения mdpi.com.
Таблица 1: Сравнение CRISP-DM и CRISP-ML(Q)
| Аспект | CRISP-DM | CRISP-ML(Q) |
| Фазы | 6 этапов | 6 этапов + углубление в QA |
| Фокус | Data Mining, анализ данных | End-to-end ML-приложения, производство |
| Мониторинг | Не включен как отдельный этап | Обязательная фаза №6 |
| Воспроизводимость | Частичная, не стандартизирована | Документирование метаданных, версионирование |
| Риск-менеджмент | Не явно выражен | Встроен в каждый этап, риск-ориентированный подход |
| Обеспечение качества | В основном, оценка модели | Системный QA на всех этапах жизненного цикла |
Таблица 2: Детализация Задач по Фазам CRISP-ML(Q)
| Фаза | Задачи |
| 1. Понимание Бизнеса и Данных | – Определение бизнес-целей проекта. |
| – Перевод бизнес-целей в цели машинного обучения (ML-цели). | |
| – Выявление и сбор доступных данных. | |
| – Верификация и первичный анализ данных. | |
| – Оценка осуществимости проекта (техническая, ресурсная, экономическая). | |
| – Создание концепции/доказательства концепции (POC – Proof of Concept), если необходимо. | |
| – Определение нормативных и этических ограничений. | |
| 2. Инженерия Данных | – Отбор признаков (feature selection). |
| – Отбор данных (data selection), создание выборок. | |
| – Балансировка классов (методы oversampling/undersampling). | |
| – Очистка данных (снижение шума, обработка пропущенных значений, удаление/коррекция выбросов). | |
| – Инженерия признаков (feature engineering), создание новых признаков. | |
| – Аугментация данных (data augmentation) для увеличения объема обучающих данных. | |
| – Стандартизация/нормализация данных. | |
| – Реализация Data Unit Tests для контроля качества входных данных. | |
| 3. Инженерия ML-модели | – Определение метрик качества модели (например, точность, F1-score, ROC AUC). |
| – Выбор алгоритма машинного обучения (включая выбор базового/эталонного решения – baseline). | |
| – Добавление специфических знаний предметной области для специализации модели. | |
| – Обучение модели. | |
| – Опционально: применение трансферного обучения (Transfer Learning) с использованием предобученных моделей. | |
| – Опционально: сжатие модели (Model Compression) для оптимизации ресурсов. | |
| – Опционально: использование ансамблевого обучения (Ensemble Learning). | |
| – Тщательное документирование ML-модели и проведенных экспериментов (метаданные, гиперпараметры, версии). | |
| 4. Оценка Качества ML-модели | – Валидация производительности модели на тестовых данных. |
| – Определение робастности (устойчивости) модели к изменениям во входных данных. | |
| – Повышение объяснимости (Explainability) модели (например, с использованием SHAP, LIME). | |
| – Оценка справедливости (Fairness) модели для предотвращения смещений. | |
| – Принятие решения о развертывании модели (Deploy/No Deploy) на основе установленных порогов качества. | |
| – Документирование фазы оценки и принятых решений. | |
| – Проведение аудита модели. | |
| 5. Развертывание Модели | – Оценка модели в производственных условиях (производительность, стабильность, потребление ресурсов). |
| – Обеспечение приемлемости для пользователя и удобства использования системы. | |
| – Управление моделью (Model Governance): контроль версий, политики доступа. | |
| – Развертывание согласно выбранной стратегии (A/B-тестирование, многорукие бандиты, канареечные релизы, сине-зеленое развертывание). | |
| – Разработка плана отката (rollback plan) на случай проблем. | |
| 6. Мониторинг и Поддержка Модели | – Мониторинг эффективности и результативности предсказаний модели в продакшене. |
| – Сравнение данных производительности модели с ранее заданными критериями успеха и порогами (например, деградация метрик). | |
| – Выявление дрейфа данных (data drift) и концептуального дрейфа (concept drift). | |
| – Принятие решения о необходимости переобучения модели. | |
| – Сбор новых данных из продакшена. | |
| – Выполнение разметки новых точек данных для обновления обучающей выборки. | |
| – Повторение задач из фаз “Инженерия модели” и “Оценка модели” при переобучении. | |
| – Непрерывная интеграция (CI), непрерывное обучение (CT) и непрерывное развертывание (CD) модели в рамках MLOps пайплайна. |
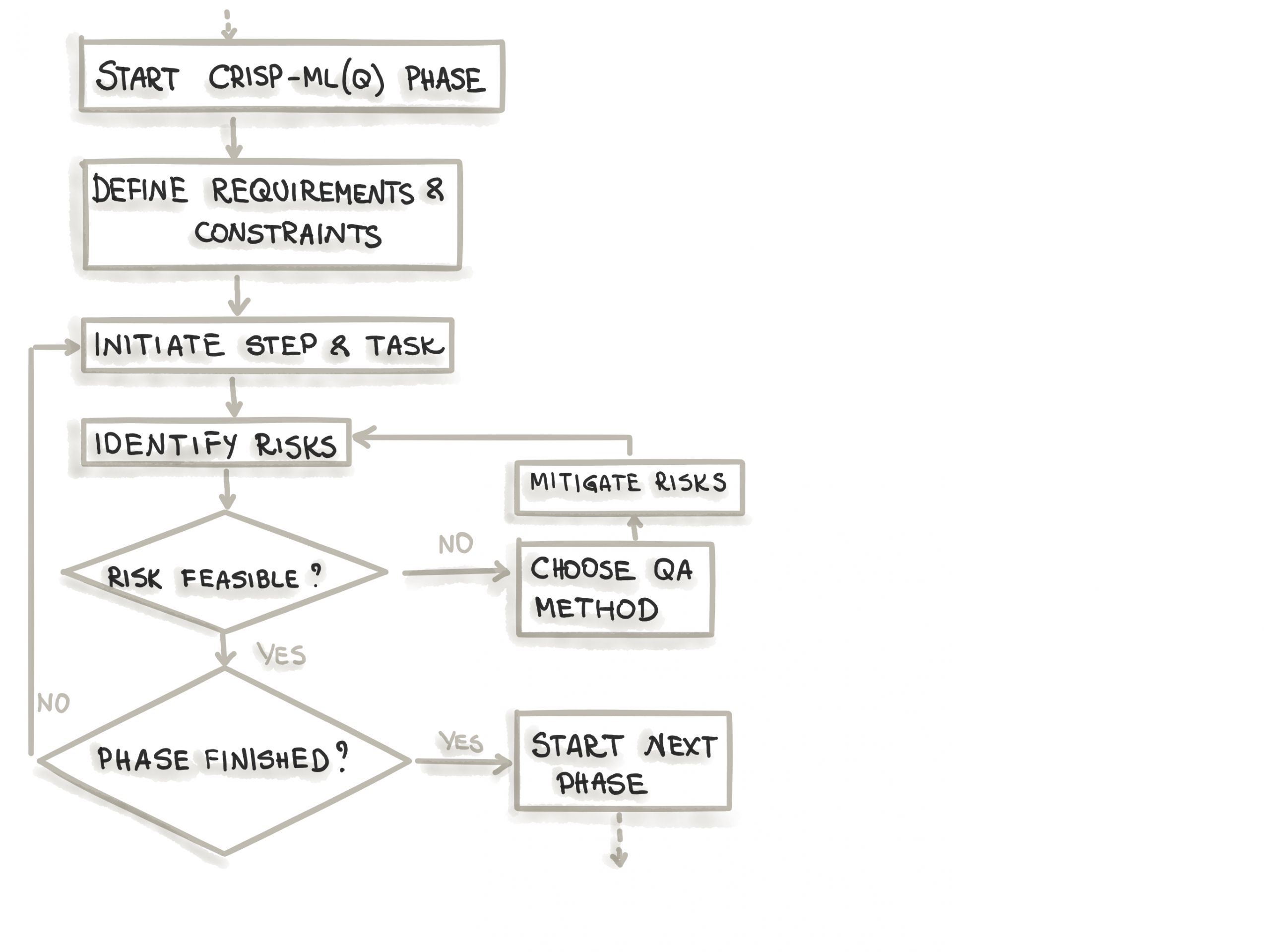
Принципы обеспечения качества (QA)
CRISP-ML(Q) интегрирует принципы обеспечения качества на каждом этапе цикла разработки ML:
- Риск-ориентированный подход: Для каждой фазы идентифицируются потенциальные риски (например, смещение данных, переобучение, дрейф модели), и разрабатываются методы их минимизации. Примеры включают использование кросс-валидации, объяснимых моделей (таких как SHAP для интерпретации предсказаний) и тщательное логирование экспериментов.
- Документирование: Поддерживается строгая документация требований, версий данных, используемых метрик оценки и любых изменений в пайплайне. Инструменты типа Model Cards Toolkit могут использоваться для создания прозрачных отчетов о моделях.
- Автоматизация пайплайнов: Для обеспечения воспроизводимости и эффективности процессов активно используются автоматизированные конвейеры (data pipelines, ML pipelines).
MLOps: Концепция, Инструменты и Сравнение с Apache Airflow
MLOps — это, по сути, инженерная дисциплина, сосредоточенная на автоматизации и масштабировании жизненного цикла ML-систем, включая CI/CD (непрерывная интеграция/непрерывная поставка) для моделей, автоматизированное тестирование и мониторинг в продакшене mdpi.com.
CRISP-ML(Q), напротив, является процессной моделью, которая задает последовательность шагов и необходимых активностей для успешного выполнения ML-проекта.
Таким образом, они дополняют друг друга:
- CRISP-ML(Q) определяет “что делать” и “когда делать” на каждом этапе жизненного цикла ML-проекта, фокусируясь на методологии и целях.
- MLOps предоставляет инструменты и практики для реализации этих “что делать”, отвечая на вопрос “как делать”.
Apache SeaTunnel и Apache DolphinScheduler в контексте MLOps
На этапе инженерии данных и мониторинга в рамках MLOps-пайплайна часто требуются мощные инструменты для интеграции, обработки и оркестрации данных. Здесь на помощь приходят такие открытые фреймворки и платформы, как Apache SeaTunnel и Apache DolphinScheduler.
- Apache SeaTunnel: Этот фреймворк является высокопроизводительным, распределенным решением для интеграции и синхронизации больших объемов данных news.apache.org. Он позволяет быстро и эффективно перемещать данные между различными источниками (например, базы данных, облачные хранилища, Kafka) и потребителями данных.
> В контексте MLOps, SeaTunnel играет ключевую роль в:
> – Подготовке данных: Автоматизация сбора, очистки и трансформации данных для обучения и переобучения моделей. Это включает потоковую ETL/ELT обработку, что обеспечивает актуальность и качество обучающих данных.
> – Получении данных для мониторинга: Сбор метрик производительности модели и данных о её входящих запросах из различных систем для последующего анализа дрейфа данных или деградации производительности.
> – Интеграции с ML-платформами: SeaTunnel может выступать в качестве универсального коннектора для передачи данных в хранилища признаков (feature stores) или напрямую в тренировочные пайплайны.
> Фактически, SeaTunnel унифицирует процесс синхронизации и интеграции данных, поддерживая разнообразные источники и цели, необходимые для обработки больших объёмов данных в ML-системах. blog.devgenius.io. Например, его можно использовать для эффективного сбора данных для поиска сходства между книгами с помощью больших языковых моделей apacheseatunnel.medium.com.
- Apache DolphinScheduler: Это распределенная платформа для оркестрации рабочих процессов (workflow orchestration) с возможностью визуализации и мониторинга dolphinscheduler and seatunnel vs airflow and nifi. Если Apache SeaTunnel занимается *движением данных*, то DolphinScheduler отвечает за *управление последовательностью задач*.
> В MLOps DolphinScheduler может использоваться для:
> – Оркестрации ML-пайплайнов: Автоматизация запуска задач по подготовке данных (с помощью SeaTunnel), обучению моделей, их оценке, развертыванию и мониторингу. Он позволяет определять зависимости между задачами, управлять их выполнением по расписанию или по событию, а также обрабатывать ошибки.
> – Управление ресурсами: Эффективное распределение вычислительных ресурсов для различных этапов ML-рабочих процессов.
> – Мониторинг рабочих процессов: Предоставление наглядных дашбордов для отслеживания статуса пайплайнов, выявления узких мест и оперативного реагирования на сбои. blog.devgenius.io.
SeaTunnel и DolphinScheduler против Apache Airflow
Обычно для оркестрации рабочих процессов в MLOps применяется Apache Airflow. Однако, в определенных сценариях, комбинация Apache DolphinScheduler и Apache SeaTunnel может предложить преимущества:
- Apache Airflow: Широко используется для создания, планирования и мониторинга программно определенных рабочих процессов (DAGs – Directed Acyclic Graphs) risingwave.com. Он обладает высокой гибкостью и огромным комьюнити.
- Преимущества DolphinScheduler + SeaTunnel в MLOps:
- Специализация: SeaTunnel специализируется на высокопроизводительной передаче данных, что делает его более эффективным для задач, связанных с перемещением и синхронизацией больших объемов данных, часто возникающих в ML. Airflow, с другой стороны, является более общим оркестратором.
- Визуализация и удобство: DolphinScheduler часто отмечается за его более интуитивный графический интерфейс и drag-and-drop функциональность, что может упростить создание и управление ML-пайплайнами для пользователей с меньшим опытом программирования, чем в Airflow, который требует написания кода на Python для DAGs. dev.to. DolphinScheduler поддерживает модель “Workflow as Code”, но дополняется более удобной визуализацией.
- Распределенная архитектура: DolphinScheduler изначально разрабатывался как распределенная система, что может быть преимуществом для очень больших и сложных рабочих процессов, эффективно распределяя нагрузку.
- Комплексное решение для данных: Сочетание DolphinScheduler с SeaTunnel предоставляет более цельное решение для управления как потоками данных, так и рабочими процессами, тогда как Airflow требует интеграции с отдельными инструментами для обработки данных.
В итоге, выбор между Airflow и связкой DolphinScheduler + SeaTunnel зависит от конкретных потребностей проекта, в частности от объема и сложности задач по интеграции данных, а также от предпочтений команды в отношении визуализации и кодирования пайплайнов.
Примеры MLOps-платформ: Databricks и ZenML
На рынке существуют как открытые, так и коммерческие MLOps-платформы, которые объединяют различные инструменты для реализации полного цикла ML-разработки:
- Databricks: Эта компания является одним из лидеров в области озер данных (Data Lakehouse) и MLOps. Их платформа предоставляет интегрированную среду для полной цепочки MLOps: от подготовки данных с использованием Apache Spark (ядра платформы Databricks risingwave.com), обучения моделей, управления экспериментами (MLflow, разработанный Databricks) до развертывания и мониторинга. “The big book of MLOps от Databricks” — это всеобъемлющее руководство, которое детализирует их подход к построению MLOps-систем, подчеркивая важность воспроизводимости, автоматизации и совместной работы.
- ZenML: Это Extensible MLOps фреймворк, ориентированный на Developer Experience. ZenML позволяет создавать портативные, воспроизводимые и масштабируемые MLOps-пайплайны, абстрагируя пользователей от сложности базовой инфраструктуры. Он поддерживает множество интеграций с другими популярными ML-библиотеками и платформами (например, TensorFlow Extended, PyTorch, Kubeflow, MLflow), позволяя командам выбирать лучшие инструменты для своих задач, сохраняя при этом единую MLOps-структуру. ZenML фокусируется на “workflow-as-code” и модульности, что делает его гибким решением для различных MLOps-сценариев.
Из россияйских есть Neoflex Dognauts она обеспечивает полный цикл разработки и эксплуатации
ML-моделей для решения задач бизнеса. Это единая платформа корпоративного MLOps позволяет управлять всем жизненным циклом DS/ML от постановки бизнес-задач до управления внедренными моделями Neoflex Dognauts
Коммерческая реализация WhaleOps
На рынке существуют и коммерческие реализации платформ, основанные на технологиях Apache и тесно интегрированные с принципами CRISP-ML(Q) и MLOps. Одним из ярких примеров является компания WhaleOps Technology. linkedin.com Основанная в августе 2021 года ключевыми участниками проектов Apache DolphinScheduler и Apache SeaTunnel, WhaleOps специализируется на создании решений для DataOps и MLOps. github.com Платформа WhaleOps предлагает комплексный набор инструментов, который помогает компаниям внедрять и управлять ML-моделями в продакшене, используя открытые стандарты и обеспечивая высокий уровень автоматизации и контроля качества на всех этапах жизненного цикла модели. cn.linkedin.com Такая интеграция open-source фреймворков и коммерческих платформ позволяет организациям строить масштабируемые и надежные ML-системы, полностью соответствующие лучшим практикам, описанным в CRISP-ML(Q).
Практические кейсы применения
CRISP-ML(Q) применяется в различных отраслях для создания надежных и управляемых ML-решений:
- Предиктивное обслуживание в Mercedes-Benz: Использование CRISP-ML(Q) для прогнозирования поломок автомобилей. На фазе мониторинга был выявлен дрейф данных, вызванный изменением условий эксплуатации, что потребовало своевременного переобучения моделей для поддержания их точности.
- Кредитный скоринг в банках: На фазе оценки качества (QA) методики CRISP-ML(Q) помогли обнаружить смещение модели против клиентов старше 60 лет. Это позволило скорректировать модель перед её развертыванием, обеспечив справедливость и соответствие этическим нормам.
Критика и ограничения
Несмотря на свои преимущества, CRISP-ML(Q) имеет и некоторые ограничения:
- Сложность внедрения: Для небольших проектов или стартапов, возможно, будет избыточным следование всем детальным процедурам CRISP-ML(Q) из-за требований к документации и ресурсам.
- Нехватка инструментов: Хотя MLOps предоставляет множество инструментов, некоторые аспекты QA, такие как автоматизированная проверка этики или полностью автоматизированное управление дрейфом данных, все еще требуют активного участия человека и не всегда полностью автоматизированы.
Заключение
CRISP-ML(Q) — это наиболее полная и зрелая методология для управления промышленными ML-проектами. Она успешно закрывает пробелы CRISP-DM за счет:
- Системного обеспечения качества (QA) на всех этапах жизненного цикла.
- Эффективного эксплуатационного мониторинга развернутых моделей.
- Пристального внимания к воспроизводимости всех экспериментов и моделей.
Для достижения максимального успеха в ML-проектах рекомендуется комбинировать методологические рамки CRISP-ML(Q) с инженерными практиками MLOps. Интеграция мощных open-source фреймворков, таких как Apache SeaTunnel и Apache DolphinScheduler, а также использование комплексных MLOps-платформ, как Databricks или ZenML, и коммерческих решений вроде WhaleOps, позволяет автоматизировать и масштабировать эти процессы. Дальнейшее развитие методологии, вероятно, будет направлено на стандартизацию этических аудитов и дальнейшую автоматизацию процессов обработки дрейфа данных, делая ML-системы ещё более надёжными и управляемыми.
Источники
- Оригинальная статья CRISP-DM: https://medium.com/voice-tech-podcast/cross-industry-standard-process-for-data-mining-crisp-dm-9edc0c5e3a1
- CRISP-DM и его популярность: https://www.datascience-pm.com/crisp-dm-still-most-popular/
- CRISP-ML(Q) и MLOps: https://www.mdpi.com/2076-3417/11/19/8861
- Руководство по выбору алгоритма: https://www.kdnuggets.com/2020/05/guide-choose-right-machine-learning-algorithm.html
image-194.png.jpg - Подробное описание CRISP-ML(Q) на Medium: https://medium.com/@desmondonam/understanding-the-crisp-ml-q-1e8c5bbfb8cb
- Apache SeaTunnel (официальный проект): news.apache.org
- SeaTunnel – эволюция архитектуры: blog.devgenius.io
- SeaTunnel для поиска (пример): apacheseatunnel.medium.com
- DolphinScheduler и SeaTunnel vs Airflow и NiFi: dev.to
- DolphinScheduler – Workflow as Code + SageMaker: blog.devgenius.io
- Apache Airflow vs Spark: risingwave.com
- WhaleOps Technology (LinkedIn): linkedin.com
- WhaleOps Technology (GitHub): github.com
- WhaleOps Technology (LinkedIn CN): cn.linkedin.com
- Databricks: (“The big book of MLOps от Databricks” – ссылка на книгу, если доступна, или на соответствующий раздел сайта Databricks. Например: databricks.com)
- ZenML: zenml.io/