Теперь я тоже заmeshан
Heltec mesh pocket
Конект хороший, для иос приложение socialmesh не официальное, но работает.
Прошивку обновить проще простого, как файл на флешку записать.



+ Памятник зенитчикам

Welcome to my personal place for love, peace and happiness 🤖
Heltec mesh pocket
Конект хороший, для иос приложение socialmesh не официальное, но работает.
Прошивку обновить проще простого, как файл на флешку записать.
+ Памятник зенитчикам
Перевод статьи (доступный фрагмент)
Почему технические гиганты тихо отказываются от короля оркестрации, и налог на сложность в 10 миллионов долларов, который ваша компания платит прямо сейчас.
Если взглянуть на инфраструктуру самых горячих технологических компаний 2026 года, проявляется шокирующая закономерность. Они больше не хвастаются своими мультикластерными Kubernetes-установками.
Вместо этого они тихо удаляют YAML-файлы, демонтируют кластеры и движутся назад.
Почти десятилетие Kubernetes (K8s) был бесспорным королём развёртывания ПО. Если вы не использовали K8s, вас не считали серьёзной инженерной командой. Но сегодня похмелье наступило. Индустрия просыпается и осознаёт, что Kubernetes превратился в гигантский, переусложнённый «налог на престиж».
И самое забавное? Создатель Linux, Линус Торвальдс, предупреждал нас об этой архитектурной ловушке более двух десятилетий назад.
Предупреждение: ложная простота
Задолго до появления Kubernetes или Docker мир компьютерных наук был одержим микроядрами — идеей разбить операционную систему на крошечные, изолированные, независимые сервисы вместо того, чтобы строить один большой монолит.
Линус Торвальдс ненавидел это. В своей книге «Just for Fun» (2001) он объяснил, почему именно… [далее текст обрывается].
-—-
Дополнительные факты и контекст
——
##Итог
Статья намекает на системный сдвиг в 2026 году: индустрия устала от самопожертвования ради «модного» стека. Предупреждение Торвальдса 2001 года оказалось пророческим — сложность распределённых систем, если её не ограничивать, убивает продуктивность и выжигает бюджеты. Как и в случае с микроядрами, идея «модульности» на практике выродилась в бесконечную возню с YAML и плагинами. Ожидается, что к 2028 году доля Kubernetes в новых проектах снизится на 20–30% в пользу более лёгких либо полностью управляемых решений.
Ученые давно пытаются понять, как люди делают выбор. Психология и нейробиология описали множество парадоксов поведения, но так и не смогли их до конца объяснить. Неожиданное решение предложила квантовая физика. Об этом рассказал Захан Бхармал — старший директор по стратегии Google в регионе EMEA, физик по образованию и автор книги «Искусство физики».

Почему психология и нейробиология зашли в тупик
Классическая теория принятия решений исходит из того, что человек — рациональное существо, которое оценивает вероятности и выбирает оптимальный вариант. Однако реальность постоянно опровергает эту модель.
Люди регулярно демонстрируют парадоксальное поведение: нарушают принцип «несомненной вещи» (sure-thing principle), совершают ошибки конъюнкции (conjunction fallacy), меняют предпочтения в зависимости от порядка вопросов или демонстрируют эффект Эллсберга — избегают неопределенности даже вопреки рациональному расчету. Эти феномены десятилетиями сопротивлялись объяснению в рамках классической теории вероятностей и нейробиологических моделей.
Квантовое решение
Квантовая физика предложила неожиданный ответ на эти загадки. Как оказалось, математический аппарат, созданный для описания субатомных частиц, идеально подходит для моделирования человеческих решений.
Ключевое отличие квантовой теории вероятностей от классической — интерференция вероятностей. В квантовой механике вероятности не просто складываются, они могут интерферировать — усиливать или ослаблять друг друга, как волны. Именно этот механизм, как показали исследования, объясняет многие когнитивные парадоксы.
Другое важное понятие — контекстуальность. В квантовой физике результат измерения зависит от контекста, от того, что именно и в каком порядке измеряется. Точно так же человеческий выбор зависит от формулировки вопроса, порядка альтернатив и эмоционального состояния. Классические модели рассматривают выбор как изолированный акт, но квантовый подход учитывает, что решение — это процесс, в котором состояние человека эволюционирует, как квантовая система.
Что говорит Захан Бхармал
Бхармал, окончивший Оксфорд по специальности «физика» и получивший MBA в Стэнфорде, долгое время возглавлял направление стратегии в Google DeepMind. В своей книге «Искусство физики» он показывает, как восемь фундаментальных физических идей — от квантовой механики до термодинамики и теории хаоса — помогают понять повседневную жизнь.
«Физика может помочь нам ответить на очень человеческие вопросы, — говорит Бхармал. — Например, почему одни отношения нестабильны, а другие длятся всю жизнь? Почему сохраняется неравенство? И почему мы все принимаем так много иррациональных решений?»
По его словам, «парадоксы и неопределенность, лежащие в основе физики», позволяют «раскрыть более глубокое понимание себя и нашей вселенной». Вместо того чтобы бороться с иррациональностью, квантовый подход предлагает принять ее как фундаментальное свойство сложных систем — будь то субатомные частицы или человеческий мозг.
Что это меняет
Квантовая теория решений не утверждает, что мозг работает как квантовый компьютер. Речь о другом: математический язык, созданный для квантовой механики, оказался более адекватным для описания человеческого мышления, чем классическая теория вероятностей.
Это открывает новые возможности — от более точного прогнозирования поведения потребителей до создания ИИ, который лучше понимает человеческую нелогичность. Как подчеркивает Бхармал, те же принципы, которые лежат в основе физики, применимы к принятию решений, решению проблем и инновациям в бизнесе и жизни.
Парадокс в том, что физика, которую многие считают самой «точной» наукой, помогла объяснить самую неточную и запутанную часть реальности — нас самих.
В этой статье я расскажу, как поднять полноценную инфраструктуру для аналитических запросов, используя QueryFlux — высокопроизводительный SQL-прокси на Rust, который умеет принимать запросы по разным протоколам (Trino HTTP, PostgreSQL wire, MySQL wire) и маршрутизировать их на различные бэкенды (Trino, StarRocks, DuckDB, Athena). Мы соберем стек: Trino как основной движок, Lakekeeper как Iceberg REST-каталог, MinIO как S3-хранилище, StarRocks как альтернативный MPP-движок, и наконец сам QueryFlux, который предоставит единую точку входа для клиентов.

Все конфигурации взяты из реального рабочего проекта, запущенного на macOS с Podman (но совместимы и с Docker). Детально разберем файлы, шаги запуска, решим типичные проблемы, покажем интерфейс управления и сравним QueryFlux с Trino Gateway и другими решениями.
https://github.com/lakeops-org/queryflux/blob/main/examples/full-stack/docker-compose.yml
Современные data-платформы часто состоят из нескольких движков: Trino для федеративных запросов, StarRocks/ClickHouse для низкой задержки, DuckDB для ad-hoc аналитики, Athena для serverless-задач. Каждый движок имеет свой wire-протокол, свой диалект SQL и свои настройки аутентификации. Клиенты вынуждены либо подключаться напрямую к каждому движку, создавая $N \times M$ интеграций, либо использовать «костыли» в коде.
QueryFlux решает эту проблему, становясь единым шлюзом:
Документация: queryflux.dev
Мы развернем следующий стек через `podman-compose` (или `docker-compose`):
| Сервис | Назначение | Порт на хосте |
| trino | Движок запросов (федерация + Iceberg) | 8081 (прямой доступ) |
| starrocks | Альтернативный MPP-движок | 9030 (MySQL протокол) |
| lakekeeper | Iceberg REST-каталог | 8181 |
| minio | S3-совместимое хранилище (данные Iceberg) | 19000 (API), 19001 (консоль) |
| postgres | БД метаданных Lakekeeper | 5433 |
| queryflux | Прокси-сервер | 8080 (Trino), 5434 (PG wire), 3306 (MySQL), 9000 (Admin API), 3000 (Studio UI) |
Одним из важных аспектов настройки QueryFlux является управление конкурентностью (concurrency limit) через параметр `maxRunningQueries`.
Если мы обозначим лимит конкурентных запросов в группе маршрутизации как N, а среднее время выполнения одного запроса на бэкенде как T (в секундах), то теоретическая максимальная пропускная способность группы (Throughput, обозначается как R, в запросах в секунду) рассчитывается так:
R = N /T
Например, в нашем файле `config.yaml` мы задаем N = 100. Если средний аналитический запрос отрабатывает за T = 2.5 секунды, то пропускная способность нашей Trino-группы составит R = 40 запросов в секунду. Запросы сверх этого лимита попадают в очередь на стороне самого QueryFlux.
Создайте папку `queryflux-demo/examples/full-stack` и перейдите в нее. Ниже приведены все необходимые файлы.
📄 Показать содержимое файла
docker-compose.yml(Полный стек)
name: queryflux-example-full
services:
queryflux:
image: ghcr.io/lakeops-org/queryflux:latest
platform: linux/amd64
ports:
- "8080:8080" # Trino HTTP через QueryFlux
- "9000:9000" # Admin API
- "3000:3000" # QueryFlux Studio
- "3306:3306" # MySQL wire
- "5434:5434" # PostgreSQL wire
volumes:
- ./config.yaml:/etc/queryflux/config.yaml:ro
environment:
RUST_LOG: ${RUST_LOG:-queryflux=info,queryflux_frontend=info}
depends_on:
postgres:
condition: service_healthy
trino:
condition: service_healthy
starrocks:
condition: service_healthy
restart: unless-stopped
trino:
image: trinodb/trino:latest
platform: linux/amd64
environment:
CATALOG_MANAGEMENT: dynamic
ports:
- "8081:8080"
healthcheck:
test: ["CMD", "curl", "-sf", "http://localhost:8080/v1/info"]
interval: 10s
timeout: 5s
retries: 15
start_period: 30s
volumes:
- ./trino-config/access-control.properties:/etc/trino/access-control.properties:ro
starrocks:
image: starrocks/allin1-ubuntu:latest
platform: linux/amd64
ports:
- "9030:9030"
- "8030:8030"
healthcheck:
test: ["CMD", "curl", "-sf", "http://localhost:8030/api/health"]
interval: 15s
timeout: 10s
retries: 20
start_period: 60s
postgres:
image: postgres:16-alpine
platform: linux/amd64
ports:
- "5433:5432"
environment:
POSTGRES_DB: queryflux
POSTGRES_USER: queryflux
POSTGRES_PASSWORD: queryflux
volumes:
- queryflux-pg:/var/lib/postgresql/data
healthcheck:
test: ["CMD-SHELL", "pg_isready -U queryflux"]
interval: 5s
timeout: 3s
retries: 10
lakekeeper-db:
image: postgres:17
platform: linux/amd64
environment:
POSTGRES_PASSWORD: postgres
healthcheck:
test: ["CMD-SHELL", "pg_isready -U postgres -p 5432 -d postgres"]
interval: 2s
timeout: 10s
retries: 10
start_period: 10s
minio:
image: minio/minio:latest
platform: linux/amd64
environment:
MINIO_ROOT_USER: minio-root-user
MINIO_ROOT_PASSWORD: minio-root-password
command: ["server", "--console-address", ":9001", "/data"]
ports:
- "19000:9000"
- "19001:9001"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/ready"]
interval: 2s
timeout: 10s
retries: 20
start_period: 15s
createbuckets:
image: minio/mc:latest
platform: linux/amd64
depends_on:
minio:
condition: service_healthy
restart: on-failure
entrypoint: >
/bin/sh -c "
/usr/bin/mc alias set local http://minio:9000 minio-root-user minio-root-password;
/usr/bin/mc mb --ignore-existing local/warehouse;
exit 0;
"
migrate:
image: quay.io/lakekeeper/catalog:latest-main
platform: linux/amd64
pull_policy: always
environment:
LAKEKEEPER__PG_ENCRYPTION_KEY: dev-key-not-secure
LAKEKEEPER__PG_DATABASE_URL_READ: postgresql://postgres:postgres@lakekeeper-db:5432/postgres
LAKEKEEPER__PG_DATABASE_URL_WRITE: postgresql://postgres:postgres@lakekeeper-db:5432/postgres
restart: "no"
command: ["migrate"]
depends_on:
lakekeeper-db:
condition: service_healthy
lakekeeper:
image: quay.io/lakekeeper/catalog:latest-main
platform: linux/amd64
pull_policy: always
environment:
LAKEKEEPER__PG_ENCRYPTION_KEY: dev-key-not-secure
LAKEKEEPER__PG_DATABASE_URL_READ: postgresql://postgres:postgres@lakekeeper-db:5432/postgres
LAKEKEEPER__PG_DATABASE_URL_WRITE: postgresql://postgres:postgres@lakekeeper-db:5432/postgres
command: ["serve"]
ports:
- "8181:8181"
healthcheck:
test: ["CMD", "/home/nonroot/lakekeeper", "healthcheck"]
interval: 2s
timeout: 10s
retries: 30
start_period: 10s
depends_on:
migrate:
condition: service_completed_successfully
lakekeeper-db:
condition: service_healthy
minio:
condition: service_healthy
createbuckets:
condition: service_completed_successfully
bootstrap:
image: alpine/curl
platform: linux/amd64
tty: true
stdin_open: true
depends_on:
lakekeeper:
condition: service_healthy
restart: "no"
entrypoint: /bin/sh
command:
- -c
- |
curl -sv -X POST http://lakekeeper:8181/management/v1/bootstrap \
-H 'Content-Type: application/json' \
--data '{"accept-terms-of-use": true}'
exit 0
initialwarehouse:
image: alpine/curl
platform: linux/amd64
tty: true
stdin_open: true
depends_on:
lakekeeper:
condition: service_healthy
bootstrap:
condition: service_completed_successfully
restart: "no"
entrypoint: /bin/sh
command:
- -c
- |
curl -sv -X POST http://lakekeeper:8181/management/v1/warehouse \
-H 'Content-Type: application/json' \
--data @/config/create-warehouse.json
exit 0
volumes:
- ./create-warehouse.json:/config/create-warehouse.json:ro
sentinel:
image: alpine
platform: linux/amd64
command: ["tail", "-f", "/dev/null"]
depends_on:
lakekeeper:
condition: service_healthy
initialwarehouse:
condition: service_completed_successfully
healthcheck:
test: ["CMD", "true"]
interval: 1s
retries: 1
start_period: 0s
data-loader:
image: trinodb/trino:476
platform: linux/amd64
profiles: ["loader"]
environment:
TPCH_SCALE: ${TPCH_SCALE:-tiny}
entrypoint: ["/bin/bash", "-c"]
command:
- |
set -euo pipefail
sed "s/FROM tpch\\.tiny\\./FROM tpch.$${TPCH_SCALE}./g" /test-data/init.sql > /tmp/init.run.sql
exec trino --server http://trino:8080 --user loader --file /tmp/init.run.sql
volumes:
- ../../docker/fixtures/init.docker-network.sql:/test-data/init.sql:ro
depends_on:
trino:
condition: service_healthy
sentinel:
condition: service_healthy
starrocks-catalog-setup:
image: mysql:8.0
platform: linux/amd64
profiles: ["loader"]
entrypoint: ["/bin/bash", "-c"]
command: ["mysql -h starrocks -P 9030 -u root --connect-timeout=30 < /setup/starrocks-setup.sql"]
volumes:
- ../../docker/fixtures/starrocks-setup.sql:/setup/starrocks-setup.sql:ro
depends_on:
starrocks:
condition: service_healthy
volumes:
queryflux-pg:
📄 Вспомогательные конфигурационные файлы
Файл `config.yaml` (настройки QueryFlux):
queryflux:
externalAddress: http://localhost:8080
frontends:
trinoHttp:
enabled: true
port: 8080
postgresWire:
enabled: true
port: 5434
persistence:
type: inMemory
clusters:
trino-1:
engine: trino
endpoint: http://trino:8080
enabled: true
auth:
type: basic
username: trino
password: ""
clusterGroups:
trino-default:
enabled: true
maxRunningQueries: 100
members: [trino-1]
routers:
- type: protocolBased
trinoHttp: trino-default
postgresWire: trino-default
routingFallback: trino-defaultФайл `trino-config/access-control.properties`:
access-control.name=allow-allЭтот файл монтируется в `trino` и разрешает имперсонацию и чтение системных таблиц – иначе статистика в QueryFlux Studio не будет работать.
Файл `./create-warehouse.json` (инициализация warehouse Lakekeeper):
{
"warehouse-name": "test_warehouse",
"project-id": "00000000-0000-0000-0000-000000000000",
"storage-profile": {
"type": "s3",
"bucket": "warehouse",
"endpoint": "http://minio:9000",
"region": "us-east-1",
"path-style-access": true,
"flavor": "minio",
"sts-enabled": false
},
"storage-credential": {
"type": "s3",
"credential-type": "access-key",
"aws-access-key-id": "minio-root-user",
"aws-secret-access-key": "minio-root-password"
}
}Запускаем весь стек в фоновом режиме:
cd examples/full-stack
podman-compose up -d --waitcurl -X POST http://localhost:8081/v1/statement \
-H 'X-Trino-User: test' \
-d 'SELECT 1'Подключимся через стандартный клиент `psql` к порту `5434`, который прослушивает QueryFlux:
psql -h localhost -p 5434 -U trino -d trinoСначала выполним простой запрос для проверки работоспособности протокола:
SELECT 42;А теперь проверим аналитический потенциал стека. Выполним тяжелый запрос к таблице `call_center` в БД Iceberg, сгенерированной по стандарту TPC-DS:
SELECT cc_call_center_sk, cc_call_center_id, cc_rec_start_date, cc_rec_end_date,
cc_closed_date_sk, cc_open_date_sk, cc_name, cc_class, cc_employees,
cc_sq_ft, cc_hours, cc_manager, cc_mkt_id, cc_mkt_class, cc_mkt_desc,
cc_market_manager, cc_division, cc_division_name, cc_company,
cc_company_name, cc_street_number, cc_street_name, cc_street_type,
cc_suite_number, cc_city, cc_county, cc_state, cc_zip, cc_country,
cc_gmt_offset, cc_tax_percentage
FROM tpcds.sf10.call_center;*Скриншот успешного выполнения запроса через psql*
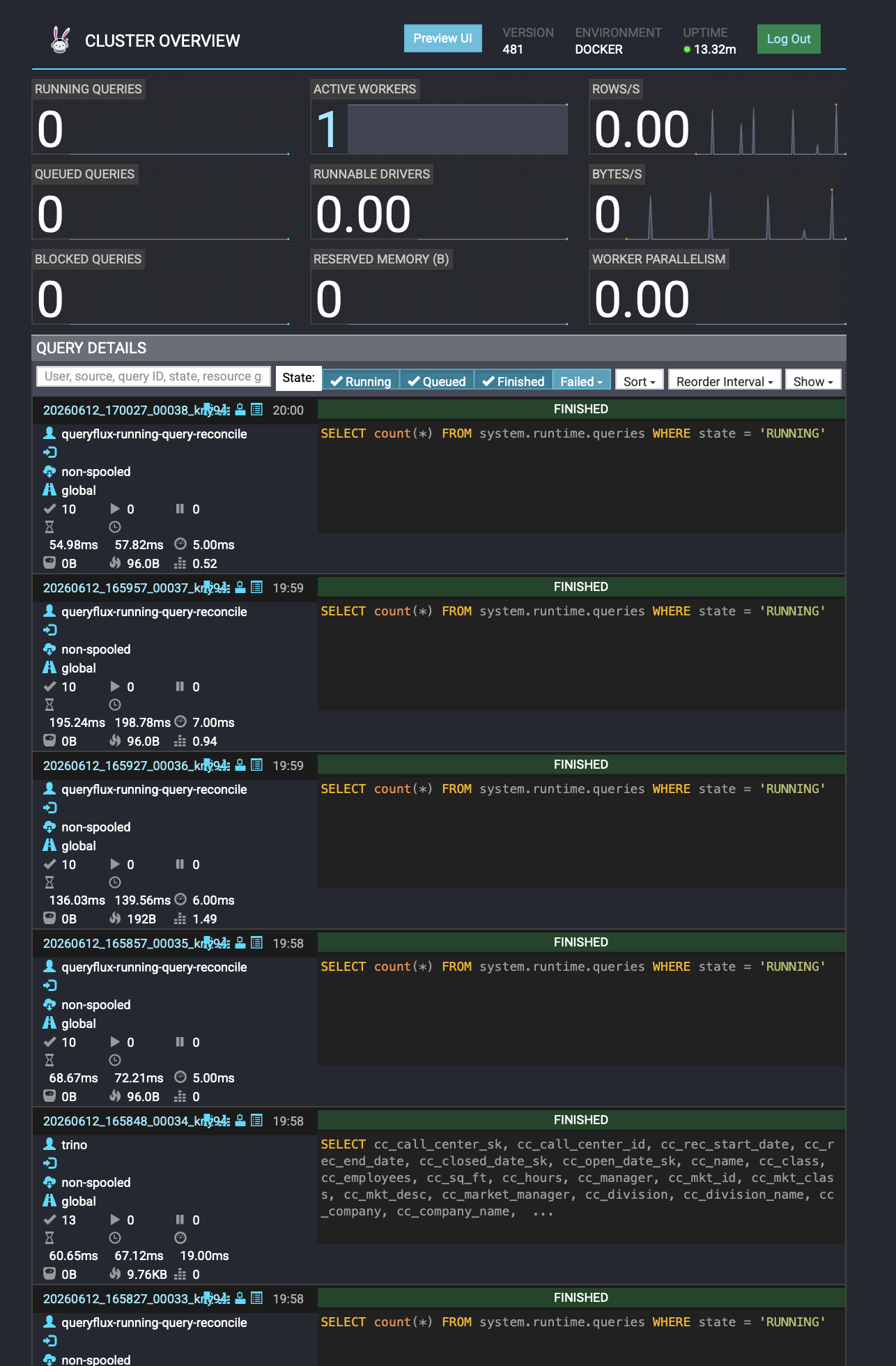
Откройте браузер и перейдите на `http://localhost:3000`. Логин по умолчанию: `admin` / `admin`.
*Главная панель (Dashboard)*
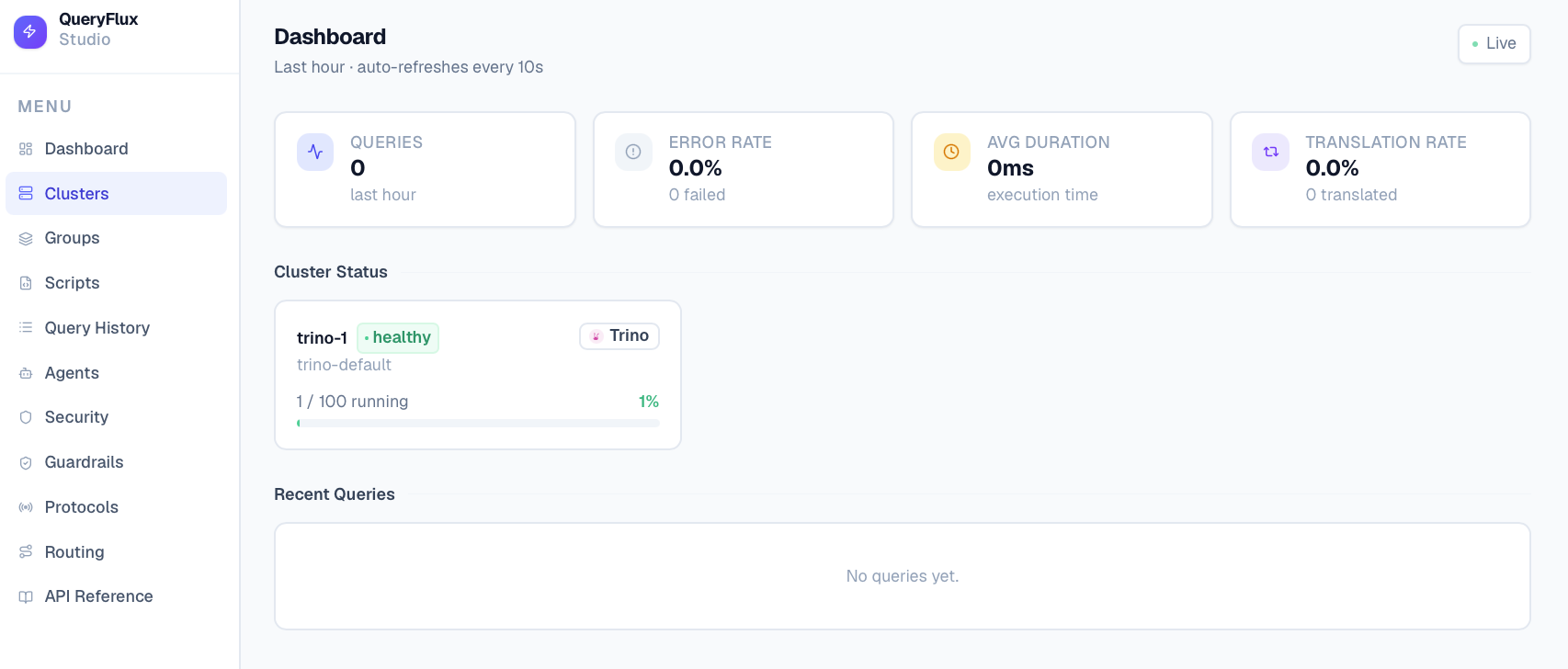
*Список кластеров*
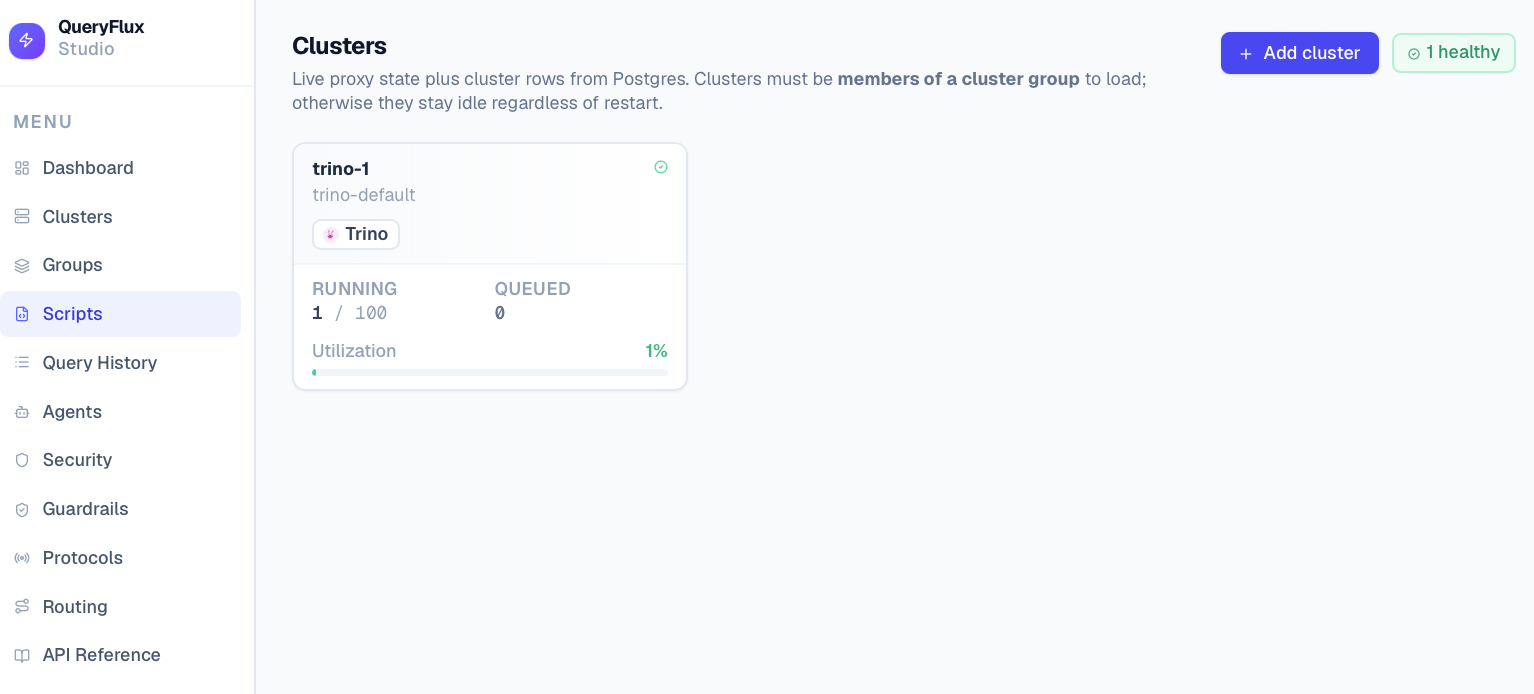
*Группы кластеров*
*Скрипты (translation fixups)*
*Guardrails (ограничения)*
*Протоколы (frontends)*
*Маршрутизация*
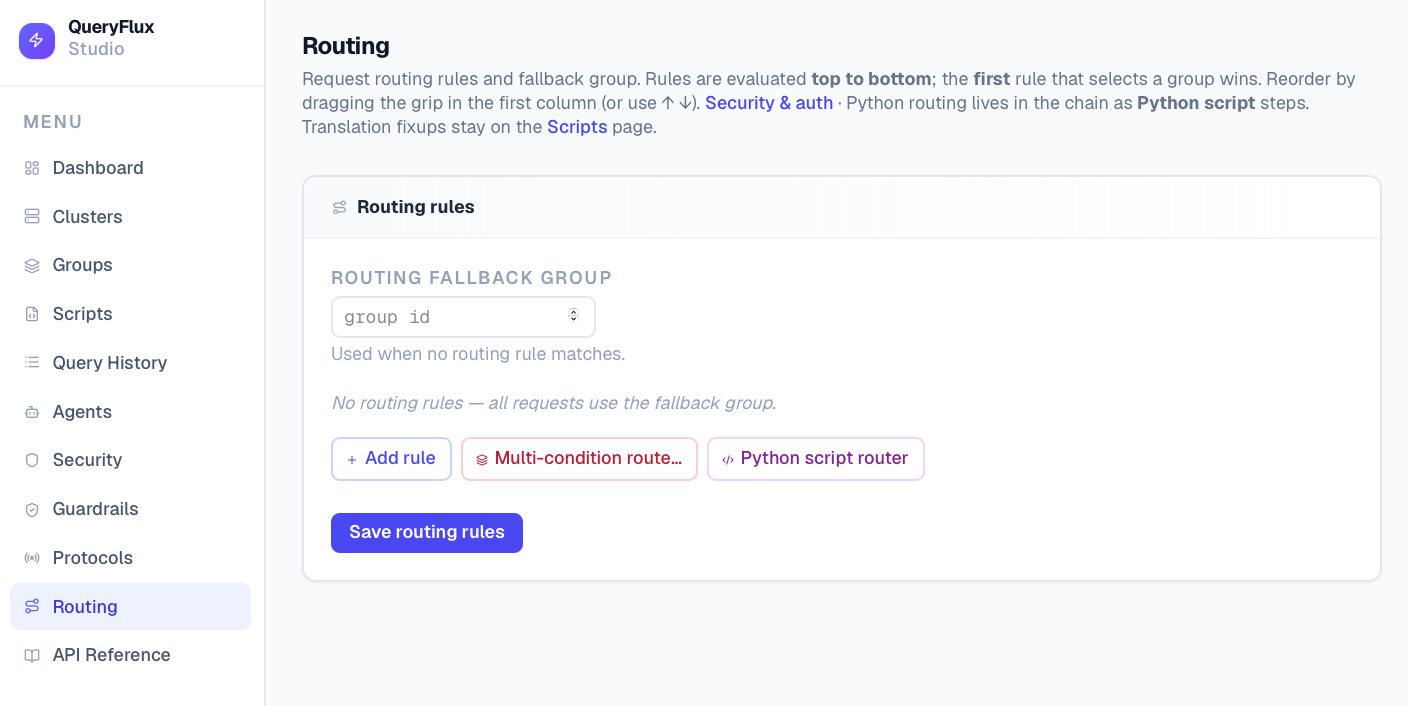
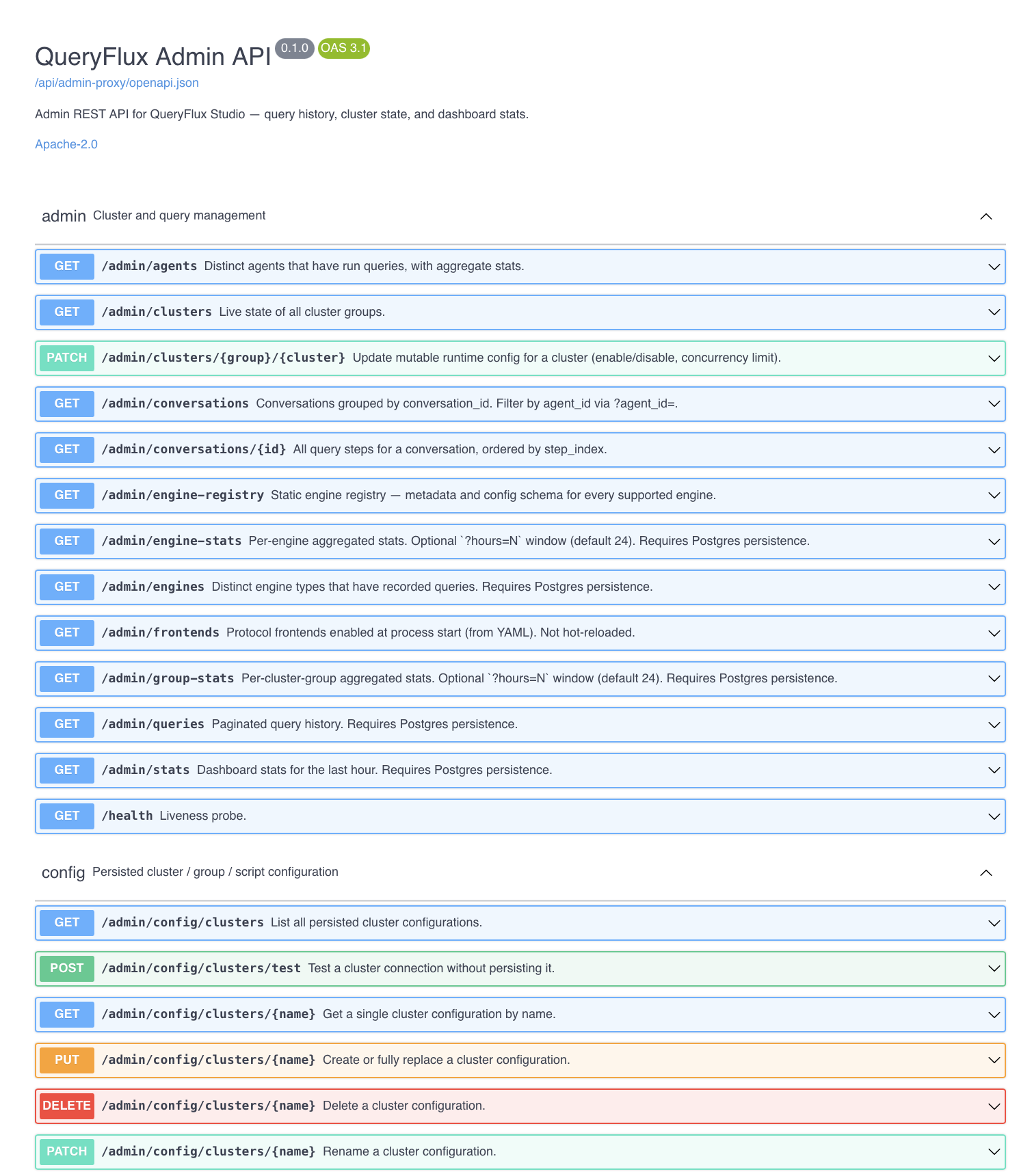
*Admin API (Swagger)*
🐞 1. Ошибка
internal libpod errorдля одноразовых контейнеров на macOS
Причина: podman-compose на macOS иногда имеет баг с `tty` и `stdin_open`.
Решение: Параметры уже добавлены в наш `docker-compose.yml`, но если баг не ушел, выполните инициализацию Lakekeeper вручную:
podman run --rm --network queryflux-example-full_default alpine/curl \
-X POST http://lakekeeper:8181/management/v1/bootstrap \
-H 'Content-Type: application/json' \
-d '{"accept-terms-of-use": true}'
🐞 2. PostgreSQL Extended Query Protocol
QueryFlux поддерживает только Simple Query Protocol (сообщение `Q`). Extended Query (Parse/Bind/Execute) не поддерживается.
jdbc:postgresql://localhost:5434/trino?prepareThreshold=0
🐞 3. Ошибка
Access Denied: User trino cannot impersonate user queryflux-running-query-reconcile
Причина: Trino не разрешает имперсонацию для системных запросов QueryFlux.
Решение: Мы добавили файл `access-control.properties` со свойством `access-control.name=allow-all`. После этого статистика в Studio заработала (см. Рис. 1 и Рис. 2).
QueryFlux предоставляет три основных интерфейса для наблюдения:
Рекомендуемая практика: для production используйте `persistence: postgres`, чтобы конфигурация групп и маршрутов сохранялась при перезапусках, а история запросов накапливалась.
| Характеристика | QueryFlux | Trino Gateway |
| Поддерживаемые протоколы клиента | Trino HTTP, PostgreSQL wire, MySQL wire, Arrow Flight SQL | Только Trino HTTP |
| Бэкенды | Trino, DuckDB, StarRocks, Athena, ClickHouse (planned) | Только Trino |
| Маршрутизация | По протоколу, заголовкам, тегам, regex, Python скриптам | По весам, группам, header `X-Trino-Routing-Group` |
| SQL трансляция | Да (sqlglot) – из PostgreSQL в Trino и наоборот | Нет |
| Конкурентность и очереди | `maxRunningQueries` на группу, очередь на прокси, spillover | `maxConcurrentQueries` на кластер, очереди нет |
| Auth/AuthZ | OIDC, LDAP, Static, OpenFGA | Базовая поддержка `X-Trino-User` |
| Метрики | Prometheus, Grafana, Admin API, Studio | Prometheus (JMX), менее развит |
| GUI управления | Полноценный веб-интерфейс (Studio) | Отсутствует (только конфигурация API) |
Плюсы QueryFlux: гетерогенность (один шлюз на разные виды движков), гибкая маршрутизация, встроенный перевод диалектов, PostgreSQL wire, наличие красивого веб-интерфейса.
Минусы: молодой проект (версия 0.1.2), не поддерживается Extended Query Protocol для PostgreSQL, требует настройки доступа к системным таблицам Trino.
и еще много с акцентов на gateway: Hoop.dev кстати интересный и GatewayD
Вывод: QueryFlux идеален, если у вас уже есть несколько движков и вы хотите дать единую точку входа для бизнес-пользователей и аналитиков (особенно тех, кто привык к `psql`). Для production, где критична поддержка prepare-statements, стоит использовать Trino JDBC напрямую или использовать дополнительный прокси (например, `trino-pg-gateway`).
Мы успешно запустили полноценный аналитический стек с Lakekeeper (Iceberg), Trino и StarRocks, а QueryFlux обеспечил единый вход через HTTP и PostgreSQL wire. Ключевые достижения:
Рекомендации для production:
Заключение: QueryFlux — очень перспективный и многообещающий инструмент для построения унифицированного доступа к аналитическим движкам. Несмотря на молодость, он уже пригоден для некоторых сценариев, особенно если вы готовы ограничиться simple query protocol при использовании PostgreSQL wire. В связке с Iceberg-каталогами и объектным хранилищем он образует мощную open-source альтернативу дорогим коммерческим решениям.
Вчера зевнул на улице, съел муху. Блин, надо больше спать 😅

И добавить нечего
ПредположенИИе 🤖
Ray — это унифицированный фреймворк с открытым исходным кодом для масштабирования AI- и Python-приложений. Он предоставляет простой API для создания распределённых приложений, которые могут масштабироваться от одного ноутбука до целого кластера без изменения кода. Ray эффективно обрабатывает разнообразные рабочие нагрузки: от пакетной обработки данных и распределённого обучения моделей до гиперпараметрической оптимизации и serving-а инференса моделей в продакшене. Ray не ограничивается только задачами ML: он также предоставляет Ray Data и потоковые примитивы для эффективных входных пайплайнов, пакетной обработки и онлайн-инференса.
Для визуализации данных и создания интерактивных дашбордов на Python сегодня доступны два мощных инструмента: проверенный временем Streamlit и современный Marimo.
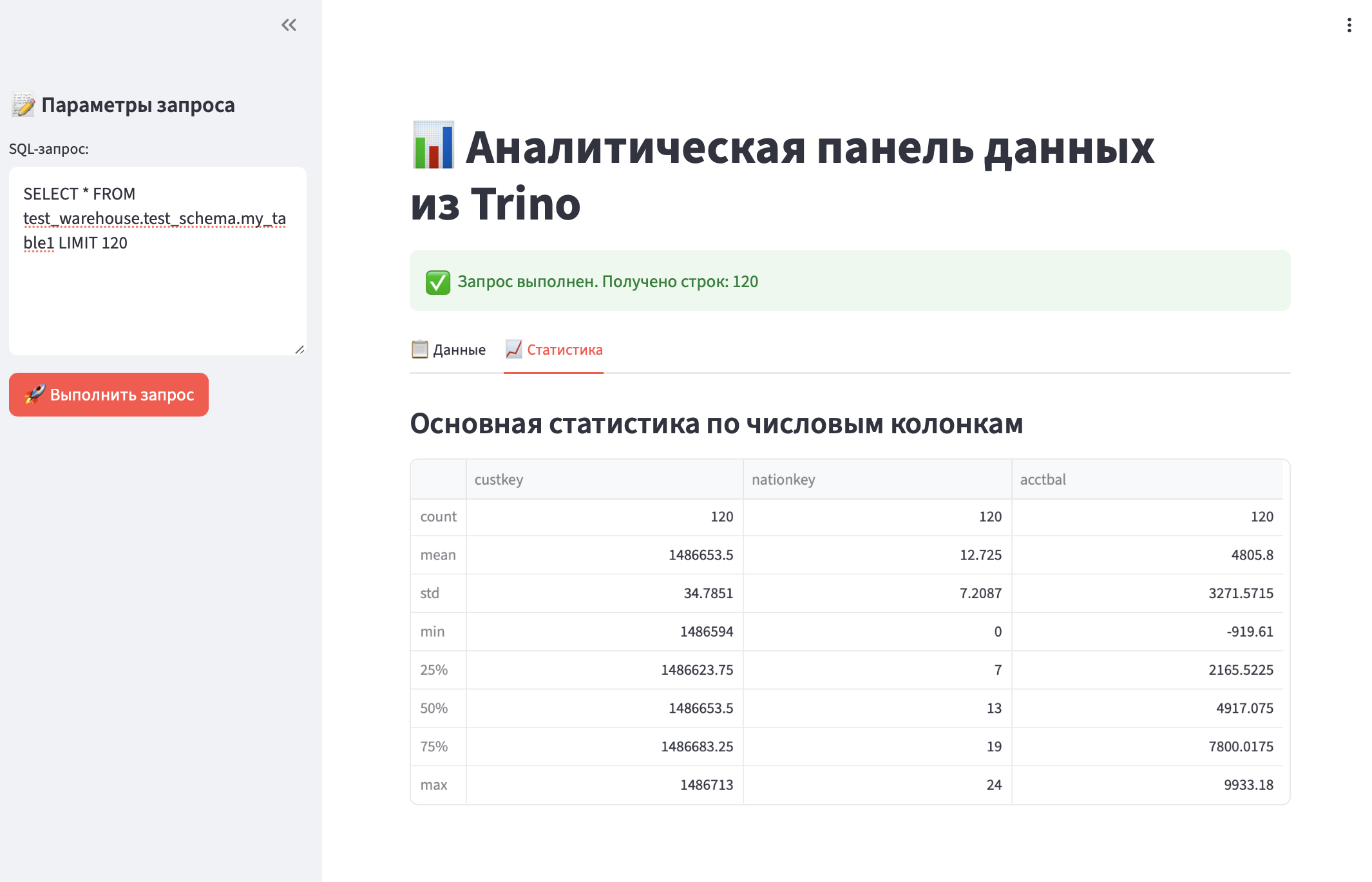
Streamlit — это open-source Python-библиотека, которая позволяет превратить скрипты анализа данных в полноценные веб-приложения за считанные минуты, без необходимости писать HTML, CSS или JavaScript. Streamlt поддерживает:
Marimo — это реактивный Python-ноутбук нового поколения, который также можно использовать для создания веб-приложений. Главное отличие от Streamlit — реактивная модель выполнения: при изменении одной ячейки или взаимодействии с UI-элементом автоматически пересчитываются только зависимые ячейки, а не весь скрипт. Marimo подходит для сложного исследовательского анализа и интерактивных дашбордов, где важна производительность и детальный контроль выполнения.
Рассмотрим практический пример построения масштабируемой системы отчётности, где Ray выступает в роли мощного бэкенда для обработки и serving-а данных, а Streamlit (или Marimo) — в роли фронтенда для визуализации. Код визуализаций хранится в Git, что упрощает версионирование, совместную работу и развёртывание.
import ray
from ray import serve
from fastapi import FastAPI, HTTPException
import trino
import pandas as pd
app = FastAPI()
@serve.deployment(
ray_actor_options={"num_cpus": 0.5},
autoscaling_config={"min_replicas": 1, "max_replicas": 2},
)
@serve.ingress(app)
class TrinoQuery:
def __init__(self):
self.conn = trino.dbapi.connect(
host="192.168.0.125",
port=9999,
user="jupyter",
catalog="test_warehouse",
schema="test_schema",
http_scheme="http",
)
print("Соединение с Trino установлено.")
@app.get("/query")
async def execute_query(self, query: str):
if not query:
raise HTTPException(status_code=400, detail="Query parameter is required.")
try:
cursor = self.conn.cursor()
cursor.execute(query)
rows = cursor.fetchall()
col_names = [desc[0] for desc in cursor.description]
df = pd.DataFrame(rows, columns=col_names)
return df.to_dict(orient="records")
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
ray.init(ignore_reinit_error=True)
serve.start(http_options={"host": "0.0.0.0", "port": 8000})
serve.run(TrinoQuery.bind(), blocking=True)import streamlit as st
import pandas as pd
import requests
BACKEND_URL = "http://127.0.0.1:8000/query"
st.set_page_config(page_title="Аналитическая панель", layout="wide")
st.title("Дашборд данных из Trino через Ray")
with st.sidebar:
st.header("Параметры запроса")
query = st.text_area(
"SQL-запрос:",
value="SELECT nationkey, COUNT(*) as cnt FROM test_warehouse.test_schema.my_table1 GROUP BY nationkey",
height=200,
)
execute_button = st.button("Выполнить запрос", type="primary")
if execute_button:
if not query:
st.warning("Введите SQL-запрос.")
else:
with st.spinner("Выполняется запрос через Ray Serve..."):
try:
response = requests.get(BACKEND_URL, params={"query": query}, timeout=30)
response.raise_for_status()
data = response.json()
if data:
df = pd.DataFrame(data)
st.success(f"Запрос выполнен. Получено строк: {len(df)}")
st.dataframe(df, use_container_width=True)
if df.select_dtypes(include='number').shape[1] > 0:
st.subheader("Статистика по числовым колонкам")
st.dataframe(df.describe(), use_container_width=True)
else:
st.info("Запрос вернул пустой результат.")
except Exception as e:
st.error(f"Ошибка: {e}")Код фронтенда (Streamlit-скрипты или Marimo-ноутбуки) должен храниться в Git-репозитории. Это обеспечивает:
Репозиторий может иметь следующую структуру:
.
├── app.py # Основной файл Streamlit-приложения
├── pages/ # Дополнительные страницы (если используются)
├── marimo_notebooks/ # Marimo-ноутбуки (если используются)
├── requirements.txt # Зависимости
├── .gitignore
└── README.mdВ распределённой системе, где множество пользователей одновременно обращаются к дашборду, а сам бэкенд масштабируется на множество реплик, управление состоянием (state management) становится критически важным. Ошибка может привести к тому, что пользователь увидит чужие данные или потеряет свой прогресс в сессии.
Ray поддерживает оба подхода:
Для большинства BI-дашбордов идеальна следующая схема:
Иногда возникает необходимость, чтобы бэкенд хранил какое-то состояние для повышения производительности. Например, каждая реплика может загружать большую модель машинного обучения в свою память. В таком случае используется подход Soft Session Affinity: все запросы от одного пользователя направляются на одну и ту же реплику, используя уникальный ключ (`X-SERVE-SHARD-KEY`).
Рассмотрим сценарий, где бизнес-пользователь хочет “заказать” отчёт, который генерируется 10 минут, и вернуться за ним через час. Stateless архитектура здесь не подойдёт, так как бэкенд “забудет” о задаче.
Ray, Streamlit и Marimo образуют мощный тандем для построения современных систем отчётности и аналитики. Ray обеспечивает масштабируемый и производительный бэкенд, способный обрабатывать большие объёмы данных. Streamlit и Marimo предоставляют удобные средства для создания интерактивных и красивых дашбордов, а Git гарантирует контроль версий и простоту развёртывания. Ключом к успешной архитектуре является правильный выбор стратегии управления состоянием: в большинстве случаев подходит stateless бэкенд с хранением состояния во фронтенде, что обеспечивает простоту и отказоустойчивость. Для более сложных сценариев (долгие задачи, кэширование моделей) можно использовать stateful подход с Ray акторами и внешним хранилищем.
Если вы хотите увидеть полный рабочий пример с кодом, архитектурной схемой и инструкцией по развёртыванию, дайте знать — я подготовлю подробный гайд.
Сегодня еще кстати крылатое выражение на уме или цитата, как хотите. «Когда выручка не растет, кровати 🛌 передвинуты, ш..х сменили и все против вас, то на помощь приходят ИИгрушки) 😁☺️😉 (с)
В первой части Утиных историй мы детально разбирали, как DuckDB переворачивает принципы локальной и встраиваемой аналитики. Сегодня на календаре 19 апреля 2026 года, и экосистема «утки» развивается с невероятной скоростью. На днях вышел юбилейный, 40-й выпуск информационного бюллетеня от команды MotherDuck.
В этой статье мы разберем самые горячие новинки обновления: релиз DuckLake 1.0, нативную поддержку протокола PostgreSQL, векторный поиск и то, как DuckDB покоряет новые горизонты программирования (от Elixir к Rust).
Главная новость апреля — релиз DuckLake 1.0. Это lakehouse-формат, в котором все метаданные хранятся непосредственно в каталоге базы данных (в PostgreSQL, SQLite или самой DuckDB), а не в разрозненных файлах, как это сделано в Delta Lake или Apache Iceberg.
Отказ от чтения разрозненных файлов метаданных дает феноменальный прирост производительности базовых операций агрегации. Если сравнивать время выполнения запросов до оптимизации (T old) и с использованием чтения исключительного из каталога метаданных DuckLake (T new), то выигрыш в скорости можно выразить формулой:
Speedup =T new / T old
Для запросов вида `COUNT(*)` этот Speedup составляет от 8 до 258 раз! А вызов системной функции `duckdb_views()` ускорился примерно в 70 раз.
Неудивительно, что DuckLake уже входит в топ-10 расширений по количеству скачиваний и поддерживается клиентами Apache DataFusion, Spark, Trino и Pandas. Издательство O’Reilly даже готовит книгу *“DuckLake: The Definitive Guide”*. (Фича доступна в DuckDB v1.5.2).
Чтобы внедрить мощь DuckDB в свою инфраструктуру разработчикам часто приходилось искать специальные драйверы и коннекторы. Это в прошлом!
MotherDuck запустили PostgreSQL wire-protocol endpoint. Теперь вы можете выполнять аналитические SQL-запросы к DuckDB, используя совершенно любой клиент, пулер (pooler) или BI-инструмент, совместимый с Postgres. Устанавливать библиотеки DuckDB на клиент больше не нужно!
Достаточно направить ваш текущий клиент по адресу:
pg.us-east-1-aws.motherduck.com:5432Авторизация происходит с помощью токена MotherDuck. При этом диалект SQL остается утиным (хотя он в значительной степени и совместим с PostgreSQL). Миграция данных возможна через обычные ETL-утилиты или расширение `pg_duckdb`.
Мощным толчком для развития комьюнити-плагинов стал релиз `quack-rs`. До сих пор написание расширений для DuckDB на Rust требовало создания слоев совместимости (C++ glue) и возни с CMake.
`quack-rs` — это SDK на чистом Rust, который оборачивает *C Extension API* (v1.1+). Инструмент предоставляет безопасные абстракции и устраняет 16 задокументированных проблем с FFI (Foreign Function Interface), предотвращая “тихую” порчу данных через NULL и ошибки “double-free” в callback-функциях агрегации.
Для старта нового расширения достаточно вызвать функцию:
generate_scaffold();Она сгенерирует все 11 файлов, необходимых для подачи плагина в репозиторий сообщества. Теперь безопасность памяти Rust и скорость DuckDB идут рука об руку.
Открытый колоночный формат Lance, оптимизированный под ML и векторный поиск, теперь доступен и в DuckDB! Hao Ding реализовал поддержку чтения и записи таблиц Lance.
Писать данные можно так:
COPY (...) TO 'path/dataset.lance' (FORMAT lance, MODE 'overwrite');Для поиска доступны функции: `lance_vector_search()`, `lance_fts()` и `lance_hybrid_search()`.
Появилась библиотека `dux` — lazy-by-default (ленивые по умолчанию) датафреймы для Elixir поверх DuckDB. Конвейеры данных аккумулируются в AST структуре `%Dux{}` и компилируются в SQL CTE. Заявлено, что на тестах ($10$ млн строк, Apple M4 Max) Dux обгоняет Polars (Explorer) до 2.5 раз на операциях фильтрации.
Инструмент для трассировки ядра Linux `systing` (написанный Josef Bacik) перешел с сохранения логов Perfetto на прямую запись в DuckDB. А интеграция с Claude Code MCP (Model Context Protocol) позволяет ИИ динамически анализировать эти базы данных DuckDB в реальном времени.
Создано полноценное Go-ядро DuckDB для Jupyter, которое напрямую отправляет поток данных (Arrow IPC) во встроенный WASM-просмотрщик `hugr-perspective-viewer`. На панели также агрегируются метрики без написания SQL: `approx_unique`, `avg`, `min`, `max`, `count`.
Способен ли базовый ноутбук переваривать серьезную аналитику? Gábor проверил работу DuckDB на новом MacBook Neo с процессором Apple A18 Pro.
| Бенчмарк | Параметры | Результат (медиана) |
| ClickBench | 100M строк, лимит RAM: 5GB | < 1 секунды (cold run) |
| TPC-DS | SF100 | 1.63 секунды на запрос |
| TPC-DS | SF300 | 79 минут (высокий disk spill) |
Даже при 5 гигабайтах оперативной памяти DuckDB демонстрирует субсекундные ответы, эффективно утилизируя NVMe-память, когда RAM исчерпан (disk spill).
Стоит отдельно отметить профессора Dr. Torsten Grust из Тюбингенского университета (Германия). Его исследовательская группа, стоящая на стыке баз данных и технологий языков программирования, недавно запустила открытый курс DiDi (*Design and Implementation of DuckDB Internals*).
Курс использует DuckDB для обучения студентов архитектуре СУБД: от управления памятью и векторизованного исполнения до оптимизации запросов (включает около 50 рабочих примеров кода).
Экосистема DuckDB перестала быть просто *“SQLite для аналитики”*. С релизом DuckLake, нативной интеграцией протокола Postgres и появлением SDK для Rust, “утка” окончательно закрепилась как основополагающий инструмент в стеке современных данных.
Сегодня Gemini 3.1 Pro Preview расскажет свое мненИИе))
Связывание транзакционных баз (PostgreSQL) и аналитических хранилищ (ClickHouse) через прямые агрегации и `JOIN` часто приводит к жесточайшим блокировкам и деградации продакшена. Когда бизнес требует быстрый результат, а внедрение полноценного CDC (Debezium + Kafka) откладывается из-за сроков и сложности, лучшим решением становится пакетная и микро-пакетная выгрузка данных в озеро (в форматы Parquet и Apache Iceberg).
С точки зрения архитектуры, наша главная цель — минимизировать время загрузки данных T load и усилия инженеров на развертывание E setup. Наша целевая функция: min(T load × E setup)
В этой статье собраны исключительно рабочие, протестированные подходы для быстрой интеграции с озером данных (Data Lake) и аналитическим движком Trino.
Мы полностью исключаем создание и восстановление тяжелых дампов (`pg_dump`). Вся транзитная нагрузка ложится исключительно на асинхронные реплики.
Для задачи “результат нужен вчера и без сложного стека” идеально подходит OLake. Это высокопроизводительный движок репликации баз данных напрямую в Apache Iceberg (или Parquet), минуя промежуточные шины сообщений.
Шаг 1. Запуск сервиса (конфигурация `docker-compose.yml`):
version: '3.8'
services:
olake:
image: olakeio/olake:latest
ports:
- "8080:8080"
environment:
# Настройки доступов к вашему S3/MinIO
- AWS_ACCESS_KEY_ID=your_access_key
- AWS_SECRET_ACCESS_KEY=your_secret_key
- AWS_REGION=us-east-1Шаг 2. Запуск репликации:
Вы отправляете JSON-манифест в OLake (через UI или REST API). Движок самостоятельно делает первоначальный слепок PostgreSQL (Full Load со скоростью до 580K RPS), а затем переключается на чтение инкрементов (CDC):
{
"pipeline_name": "pg_to_iceberg_fast",
"source": {
"type": "postgres",
"connection_url": "postgresql://readonly_user:password@replica_host:5432/prod_db",
"tables": ["public.customer", "public.orders"]
},
"destination": {
"type": "iceberg",
"catalog_type": "rest",
"catalog_uri": "http://iceberg-rest:8181",
"warehouse_path": "s3://my-datalake/warehouse/"
},
"replication_mode": "full_and_cdc"
}Если вы хотите управлять выгрузкой через свои `cron`-задачи или Airflow, идеальным инструментом выступает аналитическая in-memory СУБД DuckDB. Ниже приведен протестированный Python-скрипт, который напрямую подключается к реплике и потоково перегоняет данные в Parquet на S3.
Рабочий скрипт на Python (`export_to_lake.py`):
import duckdb
# Открываем in-memory соединение DuckDB
con = duckdb.connect()
# 1. Устанавливаем и загружаем необходимые расширения
con.execute("INSTALL postgres;")
con.execute("INSTALL httpfs;")
con.execute("LOAD postgres;")
con.execute("LOAD httpfs;")
# 2. Настраиваем подключение к объектному хранилищу
con.execute("""
SET s3_region='us-east-1';
SET s3_access_key_id='YOUR_KEY';
SET s3_secret_access_key='YOUR_SECRET';
SET s3_endpoint='s3.your-domain.com';
""")
# 3. Подключаемся к реплике PostgreSQL
# Команда ATTACH монтирует Postgres прямо в DuckDB под именем 'pg'
con.execute("""
ATTACH 'host=replica_host port=5432 dbname=postgres user=postgres password=password'
AS pg (TYPE postgres);
""")
# 4. Копируем таблицу public.customer в S3 в сжатом формате Parquet
con.execute("""
COPY pg.public.customer
TO 's3://my-datalake/raw/customer.parquet'
(FORMAT PARQUET, COMPRESSION ZSTD);
""")
print("Выгрузка в Data Lake успешно завершена!")Данные из ClickHouse также необходимо перегружать в Озеро (для Trino), чтобы избежать дублирования логики таблиц и нагрузки на саму СУБД тяжелыми сторонними `JOIN`-ами.
Самый простой и не требующий дополнительной инфраструктуры способ — использовать встроенную функцию `s3()`. Она позволяет в один SQL-запрос отправить результат выборки прямо в объектное хранилище в нужном формате.
Пример выгрузки из ClickHouse в Parquet (выполняется в `clickhouse-client`):
-- Прямая вставка данных из локальной MergeTree таблицы в файл Parquet на S3
INSERT INTO FUNCTION s3(
'https://s3.us-east-1.amazonaws.com/my-datalake/raw/clickhouse_export/events_{_partition_id}.parquet',
'YOUR_KEY',
'YOUR_SECRET',
'Parquet'
)
SELECT id, event_type, payload, event_date
FROM local_events_mergetree
WHERE event_date = today();*Совет: Используйте макрос `{_partition_id}` в пути файла для автоматического разбиения больших выгрузок.*
Для построения архитектуры на десятилетие вперед разработчики из Altinity создали сборку Project Antalya. Она позволяет использовать таблицы Iceberg в S3 как *полноценное разделяемое хранилище*, работающее со скоростью локального диска, но обходящееся в 10 раз дешевле.
Пример прозрачного монтирования:
-- 1. Подключаем готовую Iceberg-таблицу прямо как движок ClickHouse
CREATE TABLE iceberg_customer
ENGINE = Iceberg('s3://my-datalake/warehouse/customer', 'aws_key', 'aws_secret');
-- 2. Запрашиваем данные. Теперь Trino и ClickHouse читают одни и те же Parquet-файлы!
SELECT count(*) FROM iceberg_customer WHERE status = 'active';
1. Управление оперативной памятью (OOM) в DuckDB
При скриптовой выгрузке гигантских таблиц in-memory движок может исчерпать RAM сервера.
Решение: Обязательно ограничивайте ресурсы сразу после
duckdb.connect():
con.execute("PRAGMA memory_limit='16GB'")
con.execute("PRAGMA threads=4")
2. Консолидация сложных типов данных PostgreSQL
Если в вашей таблице есть
JSONB,
UUIDили пользовательские массивы, Parquet может упасть с ошибкой соответствия типов.
Решение: Вместо
COPY pg.tableнапишите явный SQL-запрос с приведением к строке (
::VARCHAR):
con.execute("""
COPY (
SELECT id, metadata::VARCHAR AS metadata
FROM pg.public.customer
)
TO 's3://my-datalake/raw/customer.parquet' (FORMAT PARQUET);
""")Внутри Trino эти строки легко парсятся функциями вроде
json_extract().
3. Защита асинхронных реплик PostgreSQL от разрывов
Длительный процесс
SELECT *(или
COPY) мешает мастеру применять WAL-логи на реплике (из-за очистки строк VACUUM-ом).
Решение: На аналитической реплике (в файле
postgresql.conf) обязательно пропишите:
max_standby_streaming_delay = -1
max_standby_archive_delay = -1
hot_standby_feedback = onЭто позволит реплике “ставить на паузу” конфликтующие обновления и не обрывать ваш транзит данных.
В современных data-архитектурах часто возникает задача переноса реляционных данных в озера данных (Data Lakes). Если ваш стек включает PostgreSQL, Trino и Iceberg (например, с REST-каталогом Lakekeeper), возникает архитектурный вопрос: как переносить данные и обращаться к ним максимально эффективно?
В этой статье мы разберем два мощных подхода: использование “нативного” для Trino проталкивания через `system.query()` и применение расширения `pg_lake` на стороне базы данных.
Обычно в Trino мы пишем простой федеративный запрос:
SELECT * FROM postgres_catalog.public.customer WHERE acctbal > 1000;В идеальном сценарии оптимизатор Trino считывает предикат (`acctbal > 1000`) и транслирует его в SQL-диалект PostgreSQL. Это называется Pushdown (проталкивание).
Но на практике аналитические запросы гораздо сложнее. Если запрос содержит специфичную бизнес-логику, нестандартные оконные функции, сложные JOIN-ы или функции обработки строк, которых нет в базовом словаре коннектора Trino, оптимизатор не сможет транслировать этот кусок SQL. В результате Trino принимает решение скачать всю таблицу в память своих воркеров и применить фильтрацию уже там.
Особую роль при JOIN-ах играет механизм динамической фильтрации (Dynamic Filtering). Когда вы джоините большую таблицу из Postgres с маленькой таблицей (например, справочником из Hive/Iceberg), Trino сначала читает справочник (Build side), извлекает ключи, формирует SQL-фильтр (например, `IN (1, 2, 3)`) и на лету отправляет его в Postgres (Probe side).
Два критичных параметра в конфигурации коннектора управляют этим процессом:
В чем кроется опасность?
Если вычисление справочника на стороне Trino занимает больше времени, чем задано в `dynamic-filtering.wait-timeout` (например, 25 секунд против 20), координатор Trino прерывает ожидание. Чтобы не блокировать выполнение, он отправляет в Postgres “голый” запрос: `SELECT * FROM table`.
Вместо пары тысяч строк по сети внезапно начинают передаваться миллионы. Если загрузка сети — B, а объем таблицы PostgreSQL — V total, то время выполнения стремится к: T pull = B V total
что может привести к Out-of-Memory на воркерах Trino и падению кластера.
Чтобы гарантировать, что вычисления и фильтры 100% выполнятся на мощностях PostgreSQL, мы можем использовать специальную табличную функцию `system.query()`.
Этот подход разделяет обязанности: PostgreSQL занимается фильтрацией и тяжелой математикой локально, а Trino просто оркестрирует запись результата в Parquet/Iceberg.
-- Создаем таблицу в Iceberg (Lakekeeper) и наполняем её результатами из Postgres
CREATE TABLE iceberg_catalog.raw_data.customer_metrics WITH (
format = 'PARQUET',
partitioning = ARRAY['mktsegment']
) AS
SELECT
*
FROM
TABLE(
postgres_catalog.system.query(
query => '
-- Этот SQL выполняется СТРОГО внутри PostgreSQL
SELECT
custkey,
name,
mktsegment,
acctbal,
array_agg(acctbal) OVER (
PARTITION BY mktsegment
ORDER BY custkey
ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING
EXCLUDE GROUP
) AS rolling_bals
FROM public.customer
WHERE acctbal > 1000
AND created_at >= current_date - interval ''1 month''
'
)
);Преимущество: Если селективность нашего фильтра S равна 0.05 (остается 5% строк), то объем передаваемых по сети данных составит строго V total \ times S. Никакие таймауты Trino не заставят Postgres отдать лишние данные.
Если первый метод идеально подходит для использования Trino как движка трансформации, то зачем вообще существует проект `pg_lake`?
`pg_lake` внедряет под капот PostgreSQL движок DuckDB через `pgduck_server`. Это позволяет базе данных самостоятельно подключаться к S3 и читать/писать формат Iceberg, минуя Trino.
pg_lakeпрямо в PostgreSQL?
-- Объединение горячих данных из кучи (heap) PG и холодных данных из Iceberg
SELECT * FROM public.orders_current
UNION ALL
SELECT * FROM iceberg.orders_archive WHERE order_date < '2023-01-01';