
Data Mesh & Data Fabric : лучше вместе!
Перевод: https://medium.com/@ashishverma_93245/data-mesh-data-fabric-better-together-15a8b70f4a9e
Оригинал: Data Mesh & Data Fabric : лучше вместе!
Эта статья изучает, как два популярных подхода к разработке платформ данных — Data Mesh и Data Fabric — могут эффективно использоваться вместе. Хотя некоторые уже понимают, как эти подходы дополняют друг друга, многое из существующего контента представляет их как конкурирующие решения. Этот блог нацелен опровергнуть такое восприятие, подчеркивая их синергию. Хотя некоторое содержание о их взаимодополняющей природе уже существует, отсутствуют реальные сценарии, иллюстрирующие, как они работают вместе и с какими потенциальными вызовами они сталкиваются. Поэтому в данной статье будет исследоваться, как интегрировать эти подходы, реальные сценарии их использования и ловушки, которых следует избегать.
Отказ от ответственности: высказанные в этой статье мнения являются моими и не представляют взгляды моих предыдущих, текущих или будущих работодателей. В статье несколько раз упоминается Microsoft Fabric, и поскольку на данный момент я работаю в Microsoft, это может рассматриваться как конфликт интересов. Я выделяю Microsoft Fabric, потому что это единственная реализация Data Fabric, с которой я ознакомлен, и считаю, что она эффективно решает поставленные задачи.
Структура обсуждения следующая:
- Обзор Data Mesh
- Обзор Data Fabric
- Взаимодополняющая природа двух подходов
- Реальные сценарии использования Data Mesh и Data Fabric
- Ловушки, которых стоит избегать
- Обзор Data Mesh
Общее определение Data Mesh звучит примерно так: «Data Mesh — это децентрализованный подход к архитектуре, который организует данные по конкретным бизнес-доменам, позволяя командам управлять данными как продуктом и обеспечивая самодостаточный доступ в рамках организации». Я считаю полезным рассматривать эти концепции через призму ключевых вызовов, для которых они были созданы. Давайте исследуем проблемы, которые привели к созданию Data Mesh.
До появления Data Mesh большинство организаций, использующих облачные платформы данных, полагались на одну центральную платформу для решения всех задач. Независимо от зрелости платформ — некоторые боролись с базовым управлением озерами данных, в то время как у других были отдельные платформы для каждого домена — общим элементом была центральная команда, управляющая всеми техническими обязанностями. Это часто приводило к множеству проблем, по мере масштабирования платформы с целью поддержки растущего количества задач:
Задержки в выпуске новых функций и задач. В модели центральной платформы все технические обязанности ложатся на команду платформы. Это работает хорошо, когда задач мало, а зрелость данных низка. Однако по мере увеличения количества задач и стремления бизнес-команд изучать больше источников данных, backlog команды платформы быстро растет. Они оказываются растянутыми между добавлением функций в основополагающую платформу, поддержкой новых и существующих задач и устранением проблем. Это чрезмерная нагрузка часто приводит к задержкам, негативно влияющим на бизнес, не позволяя реализовать ранее выявленные возможности.
Снижение производительности и морального духа центральной команды платформы. По мере увеличения рабочих нагрузок центральной команды с увеличением числа задач и требований на новые функции, приоритет отдается предоставлению бизнес-ценности, оставляя мало времени на улучшение технологического стека. Это создает порочный круг: концентрация на удовлетворении немедленных бизнес-потребностей препятствует техническим улучшениям, которые могут повысить эффективность. Со временем это приводит к увеличению времени отклика на запросы, а моральный дух команды страдает из-за постоянных жалоб, несмотря на их усердную работу и длинные часы.
Управление и технологический долг отходит на второй план. Как уже отмечено, команда платформы часто работает в режиме реагирования, сосредотачиваясь на запросах функций, фундаментальных обновлениях и устранении проблем. Это оставляет мало времени для устранения технического долга или внедрения надлежащего управления. Последствия включают в себя ухудшающуюся производительность, растущие неучтенные расходы и проблемы с безопасностью из-за неправильно отслеженного доступа к данным, среди прочих возможных последствий.
Data Mesh решает эти вызовы, предлагая следующие принципы:
Владение доменами. Команды доменов, такие как маркетинг и финансы, владеют своими данными и ресурсами, необходимыми для извлечения из них ценности. Эти ресурсы включают в себя персонал, такой как инженеры и ученые по данным, а также технологические инструменты, предоставляемые центральной командой. Эта структура позволяет доменным командам внедрять новые функции или использовать их без необходимости полагаться на центральную команду платформы, используя свой собственный талант.
Данные как продукт. Data Mesh продвигает идею обращения с данными как с продуктом, применяя к данным принципы управления продуктом. Data Product включает в себя наборы данных, метаданные, вспомогательную инфраструктуру и механизмы доставки, такие как API или потоки. Data Products подразделяются на два типа: ingestion (выравненные с источником) и consumption (выравненные с задачами). Этот подход обеспечивает эффективное управление, требующее от каждого набора данных выполнять свои функции или быть выведенным из эксплуатации. Продуктовые команды, находящиеся в домене, создают и поддерживают эти Data Products, используя инструменты, предоставляемые центральной командой платформы.
Самообслуживание. Самодостаточная инфраструктура позволяет доменным командам самостоятельно создавать и управлять своими Data Products, взаимодействуя с базовой облачной инфраструктурой платформы Data Mesh. Основная команда платформы оптимизирует облачные услуги и программное обеспечение с открытым исходным кодом, чтобы повысить производительность, соответствие и безопасность, обеспечивая легкую доступность этих инструментов для продуктовых команд через интерфейс самообслуживания.
Федеративное вычислительное управление. Управление децентрализовано, но стандартизировано на уровне всей организации, чтобы обеспечить интероперабельность и соответствие как организационным, так и промышленным стандартам. Оно не должно быть второстепенной мыслью; вместо этого, его следует интегрировать на этапе первоначального планирования и поддерживать на ранних этапах использования.
Вот такими представляют себе Data Mesh (немного больше, чем в кратком изложении).
- Обзор Data Fabric
Data Fabric должна рассматриваться как каркас или техническая спецификация дизайна, которая определяет интегрированный набор инструментов для создания полностью функциональной современной платформы данных, обеспечивающей централизованный доступ к распределенным данным. Этот всеобъемлющий набор инструментов направлен на удовлетворение потребностей всех заинтересованных сторон платформы, от инженеров данных, ученых и аналитиков до бизнес-пользователей. Обратите внимание, что задачи, которые решает Data Fabric, касаются в основном организации с большим объемом данных. Чтобы понять Data Fabric немного глубже, давайте поговорим о проблемах, которые она решает.
Разрастание стека данных. Управление объемом данных становится значительно сложной задачей, когда данные и инструменты для их управления распределены по различным облачным платформам и локальным системам. Ключевыми проблемами здесь являются:
а. Размножение инструментов. Использование множества инструментов для загрузки, хранения, обработки и анализа данных приводит к:
— путанице и дублированию
— сложностям в отслеживании происхождения данных
— трудностям в демонстрации бизнес-эффективности проектов
— потенциальным рискам безопасности и соответствия
b. Дублирование данных. Наборы данных часто копируются несколько раз в различных системах, усложняя стремление найти единый источник истины.
c. Отсутствие стандартизации. Без стандартизированных инструментов организации сталкиваются со сложностями в:
— контроле издержек и обеспечения безопасности
— поддержании единых стандартов качества на уровне всего объема данных
— росте затрат на лицензирование
d. Ограниченная видимость затрат. Обеспечение единого обзора затрат на уровень всего объема данных является редкостью из-за:
— отсутствия механизма отслеживания стоимости на уровне дизайна
— слабая интеграция различных инструментов и панель управления
Это ограничение видимости мешает директорами по технологиям (CTO) и директорами по данным (CDO) выявлять стратегические возможности для инвестиций и области для оптимизации затрат, усложняя эффективное управление объемом данных.
Обнаружение данных/инсайтов. Эта проблема в основном затрагивает бизнес-сторону организации. Без централизованного хаба для обнаружения данных бизнес-пользователи сталкиваются с значительными препятствиями:
— затруднения в исследовании и доступе к инсайтам
— неопределенность относительно точности, релевантности и своевременности данных
— ограниченная возможность делиться достижениями относительно данных
Это отсутствие координации и прозрачности значительно препятствует экспериментам и исследованиям, в конечном итоге ограничивая способность организации получать ценность из своих данных.
- Взаимодополняющая природа двух подходов — Mesh & Fabric
Из нашего обсуждения ясно, что Data Mesh и Data Fabric служат различным целям в рамках общего решения. Давайте исследуем это в контексте различных уровней, составляющих конечное. Хотя это и не является стандартной структурой, я нахожу это полезным для понимания, как эти два подхода работают вместе.
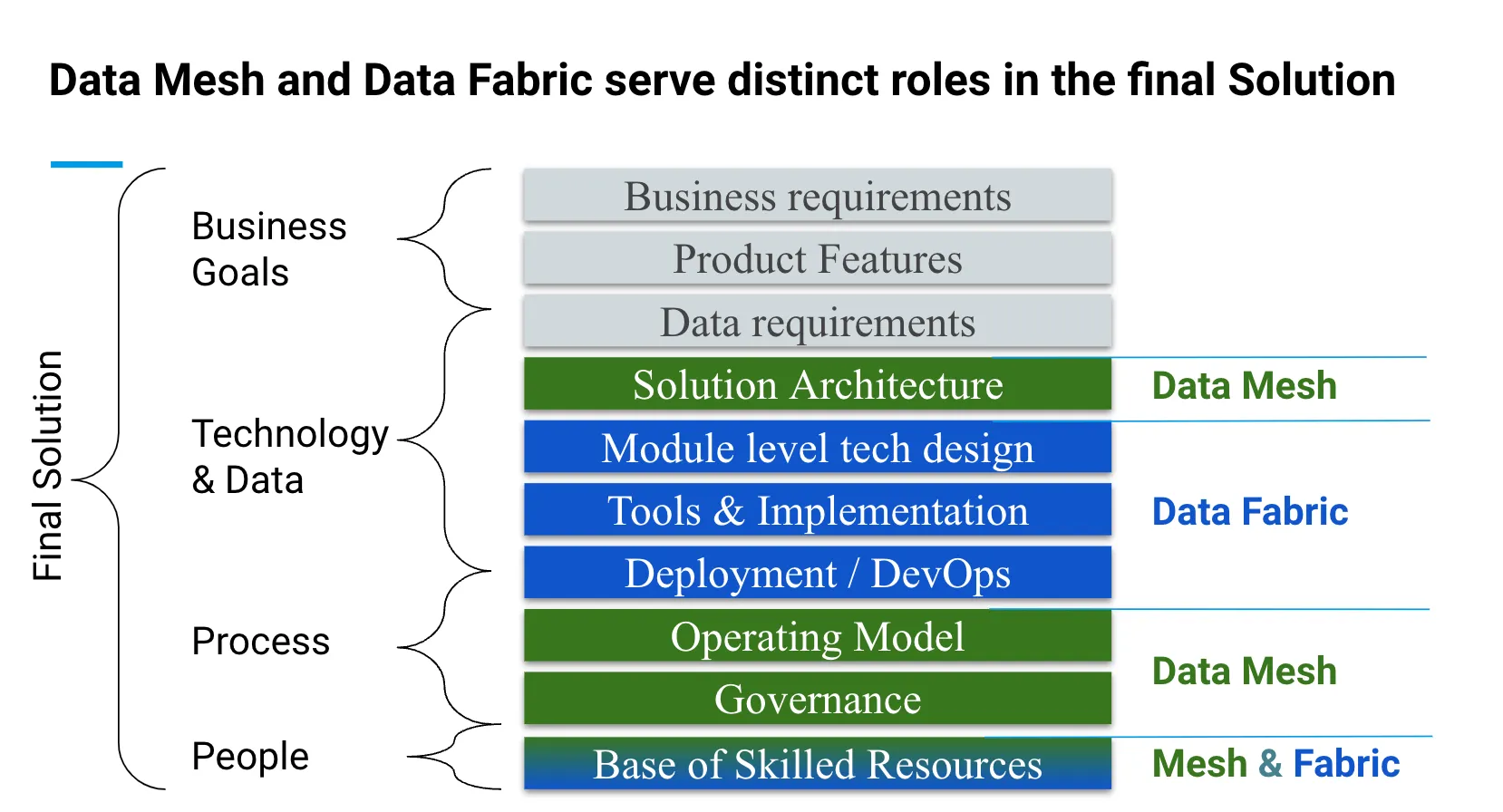
Любое программное обеспечение, созданное для решения бизнес-задачи, является всего лишь частью общего решения. Полное решение требует гораздо большего, начиная с спонсорства проекта, четких бизнес-требований и так далее.
Схема выше иллюстрирует соответствующие уровни окончательного решения, которые относятся к четырем областям: бизнес, технологии и данные, процесс и люди. Она также подчеркивает уровни, на которых действуют Data Mesh и Data Fabric.
Ключевые моменты о взаимодополняющей природе Data Mesh и Data Fabric:
- Data Mesh и Data Fabric не конкурируют друг с другом, а служат разным целям при создании окончательного решения.
- Перекрытие на уровне «Люди» между Mesh и Fabric подчеркивает необходимость в квалифицированных ресурсах для обоих подходов.
- Data Mesh определяет архитектуру решений, модель работы и управление.
- Решения Data Fabric (например, Microsoft Fabric) реализуют определенную архитектуру, политику управления и возможности самодостаточного использования.
- Конкретные проектирования модулей (например, потоки данных) диктуются доступными инструментами Fabric.
- Используя оба подхода, вы можете создать комплексное решение, которое использует сильные стороны как методологии Data Mesh, так и Data Fabric.
- Реальные сценарии использования Data Mesh и Data Fabric
Теперь, когда мы понимаем, как Data Mesh и Data Fabric дополняют друг друга, давайте рассмотрим реальные сценарии
а. Свежая реализация Data Mesh с использованием Data Fabric: этот сценарий соответствует нашему предыдущему обсуждению, где каждый слой решения адресуется соответствующим подходом. Начните с нескольких ключевых задач для приоритизации доменных команд и их продуктов данных. Основная команда платформы:
- Реализует Data Fabric, например, Microsoft Fabric
- Устанавливает ключевые компоненты, такие как безопасность, соответствие и интеграции, при поддержании архитектуры Data Mesh и управлении на основе федеративных принципов
- Предоставляет интерфейс самообслуживания для команд, занимающихся продуктами данных
Команды Data Product:
- Используют инструменты самооблуживания для создания продуктов, предназначенных для получения данных и удовлетворения конкретных задач.
- Управляют функциями своих Data Products, чтобы обеспечить их эффективное предоставление значимых результатов для целевых бизнес-кейсов.
- Обновляют свои инструменты продукта с помощью обновлений, таких как патчи безопасности и улучшения производительности, предоставляемые основными командами.
Этот подход упрощает процессы и позволяет инженерам сосредоточиться на эффективном предоставлении своих задач.
б. Дополнение существующей платформы Data Mesh с помощью Data Fabric : рассмотрим организацию с уже построенной платформой Data Mesh, поддерживающей многочисленные продукты данных, и дополнительными базами данных, как облачными, так и локальными. Учитывая этот обширный объем данных, должны быть веские причины для инвестирования в новую технологию. Некоторые из таких задач или причин могут быть:
- Недоступность активов данных, сдерживающая инновации : Ключевым преимуществом для зрелой организации данных является то, что их бизнес-персонал обладает высокой мотивацией к исследованию активов данных для извлечения инсайтов для создания новых функций и продуктов. В постиночно выросших больших данных, эта задача самоисследования становится экспоненциально сложнее из-за таких проблем как:
— надежное обнаружение нужных данных,
— наличие инструментов для исследования обнаруженных данных в контексте друг друга
— техническая экспертиза, необходимая для настройки и использования доступных инструментов
Решение Data Fabric справляется с этими проблемами с помощью двух ключевых функций:
а. Унифицированный просмотр данных:
— Предоставляет единое окно для всех организационных данных
— Позволяет выполнять запросы к любому набору данных без его копирования, используя виртуализацию данных (например, в Microsoft Fabric)
b. Возможности самообслуживания:
— Упрощает исследование данных для нетехнических пользователей
— Включает AI-ассистентов (например, Copilot от Microsoft Fabric) для запросов на естественном языке и отчетности
Решение этих проблем с открытием данных может существенно повлиять на организацию, позволив выявить новые продуктовые линии и источники дохода.
- Централизованное аналитическое рабочее пространство: Предположим, что платформа Data Mesh в основном обслуживает продукты данных, выровненные с бизнесом и выровненные с источником. Организации может быть полезно вложиться в аналитическое рабочее пространство, которое позволит изучать и обрабатывать все наборы данных — будь то локальные, в облачных хранилищах или как продукты данных — позволяя анализировать данные относительно друг друга без необходимости создания копий. В современную эпоху ИИ данные являются вашим самым ценным активом, и их доступность для анализа может дать значительные преимущества вашей организации. Решения Data Fabric, такие как Microsoft Fabric, идеально подходят для реализации такого рабочего пространства, потому что они:
— Предоставляют унифицированное рабочее пространство без необходимости настройки отдельных решений для работы друг с другом
— Обеспечивают бесшовное сотрудничество
— Предлагают интеграцию AI, которая помогает на всех этапах
— Гарантируют встроенную безопасность на протяжении всего процесса
Теперь, когда мы обосновали необходимость включения Fabric в дополнение к DataMesh, реализация — это еще одна история. Если вы захотите получить детали по конкретной реализации, пожалуйста, оставляйте комментарии ниже. Давайте быстро ознакомимся с ловушками.
- Ловушки, которых стоит избегать при использовании обоих подходов
Представленная выше структура “Solution Layers” предлагает прочную основу для понимания правильного использования Data Mesh и Data Fabric вместе. При сравнении этих двух подходов важно учитывать, на каком уровне вы решаете проблему. Ниже приведены некоторые общие первопричины, которые следует помнить: - Запутывание децентрализации в Data Mesh с централизацией в Data Fabric: Децентрализация в Data Mesh относится к распределенному владению продуктами данных (данными, инструментами и т. д.). Однако это не исключает использование централизованно управляемой технологии для поддержки этих различных продуктов данных. Например, в Azure несколько продуктов данных, принадлежащих различным командам (децентрализованно), могут использовать Azure Data Factory (ADF) для загрузки данных. В таком сценарии Центр выдающихся достижений в области инженерии данных (Data Engineering Center of Excellence) может контролировать общие политики по используемым инструментам для управлением загрузки данных для всех продуктов данных, эффективно централизуя управление технологиями.
Аналогично, решения Data Fabric, такие как Microsoft Fabric, предоставляют интегрированный набор инструментов для операций, таких как загрузка данных, обработка, хранение и визуализация из одного централизованного, универсального решения. Microsoft Fabric расширяет эту концепцию “центрального управления”, предоставляя доступ к обработке данных, хранящихся на других системах, без необходимости их копирования непосредственно в Fabric.
- Управление: Data Mesh продвигает федеративное вычислительное управление, которое является децентрализованным, в то время как Data Fabric может предложить реализацию более централизованной модели управления. Такой подход может хорошо работать, если у вас есть только одна платформа Data Mesh, реализованная с помощью одного решения Data Fabric. Однако для разнообразного объема данных с Data Mesh, реализованного наряду с существующими хранилищами данных и платформами, может быть более целесообразно рассмотреть возможность использования “каталога каталогов” для обеспечения управления на уровне всего объема данных. Дополнительно, совместимость существующих инструментов управления с выбранным решением Fabric также является важной частью этого уравнения. Конечная цель должна заключаться в том, чтобы определить наилучшую версию модели управления, которая работает для вашей организации, а затем найти наиболее эффективные способы и инструменты для ее реализации.
- Сосредоточенность на решении бизнес-проблемы, а не инструменте: Я уверен, что вы уже знаете это, но стоит отметить, основная цель не должна заключаться в использовании Fabric и Mesh вместе, а в решении вашей проблемы с наименьшими затратами.
Заключение
В заключение, я верю, что оба этих подхода могут работать вместе для достижения значительной бизнес-ценности. Если у вас есть опыт с такими реализациями, пожалуйста, свяжитесь со мной... мне бы хотелось узнать больше. И, пожалуйста, не стесняйтесь делиться любыми отзывами. Спасибо за внимание!