
Эволюция бизнес-аналитики: от монолитной к компонуемой архитектуре
Перевод: https://www.pracdata.io/p/the-evolution-of-business-intelligence-stack
По мере того, как мы вступаем в 2025 год, область инженерии данных продолжает свою стремительную эволюцию. В этой серии мы рассмотрим преобразующие тенденции, меняющие ландшафт инженерии данных, от новых архитектурных шаблонов до новых подходов к инструментарию.
Это первая часть нашей серии, посвященная эволюции архитектуры бизнес-аналитики (BI).
Введение
Ландшафт бизнес-аналитики (BI) претерпел значительные преобразования в последние годы, особенно в том, как данные представляются и обрабатываются.
Эта эволюция отражает более широкий переход от монолитных архитектур к более гибким, компонуемым решениям, которые лучше отвечают современным аналитическим потребностям.
В этой статье прослеживается эволюция BI-архитектуры через несколько ключевых этапов: от традиционных монолитных систем, через появление безголовой (headless) и бездонной (bottomless**) BI, до последних разработок в области BI-as-Code и встроенной аналитики.
** 😂 👯♀️

Традиционная BI-архитектура: Монолитный подход
Традиционные BI-инструменты были построены как комплексные, тесно связанные системы со значительным акцентом на дизайне пользовательского интерфейса.
Эти системы обеспечивали обширную гибкость благодаря функциональности “кликай и смотри” для нарезки, разделения и группировки данных с использованием различных визуализаций. В своей основе эти системы состояли из трех взаимосвязанных компонентов, которые работали в гармонии для предоставления бизнес-аналитики.
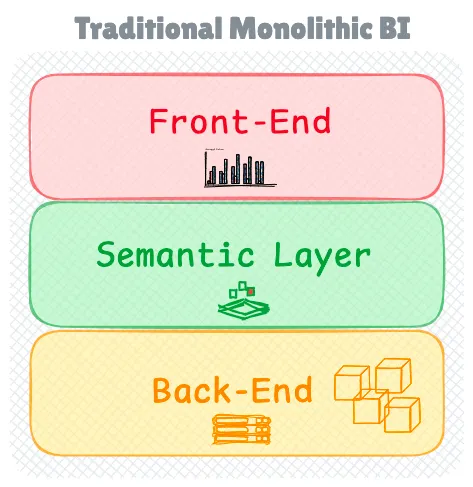
*Традиционный BI-стек*
Серверный уровень служил основой, обрабатывая прием данных из источников OLAP и создавая оптимизированные кубы данных на сервере. Эти кубы содержали предварительно вычисленные измерения, которые позволяли исследовать данные в режиме реального времени.
Работая совместно с серверной частью, клиентский уровень предоставлял интерфейс визуализации, подключаясь к серверной части для доступа к кубам данных и построения панелей мониторинга.
Семантический уровень завершал архитектуру, определяя ключевые показатели эффективности (KPI) и метрики, встроенные в BI-программное обеспечение.
Недостатки традиционных BI-инструментов
Хотя эти традиционные системы были мощными, они имели значительные накладные расходы.
Организациям требовалась существенная инфраструктура для локального развертывания до того, как управляемые облачные BI-сервисы стали более доступными, а стоимость лицензирования часто была непомерно высокой.
Сроки реализации были длительными, даже демонстрации концепции требовали недель настройки и конфигурации. Для предприятий, обслуживающих большую пользовательскую базу, требования к ресурсам были особенно высокими.
Эти фундаментальные ограничения в сочетании с растущей потребностью в гибкости и экономичности вызвали серию архитектурных инноваций в области BI.
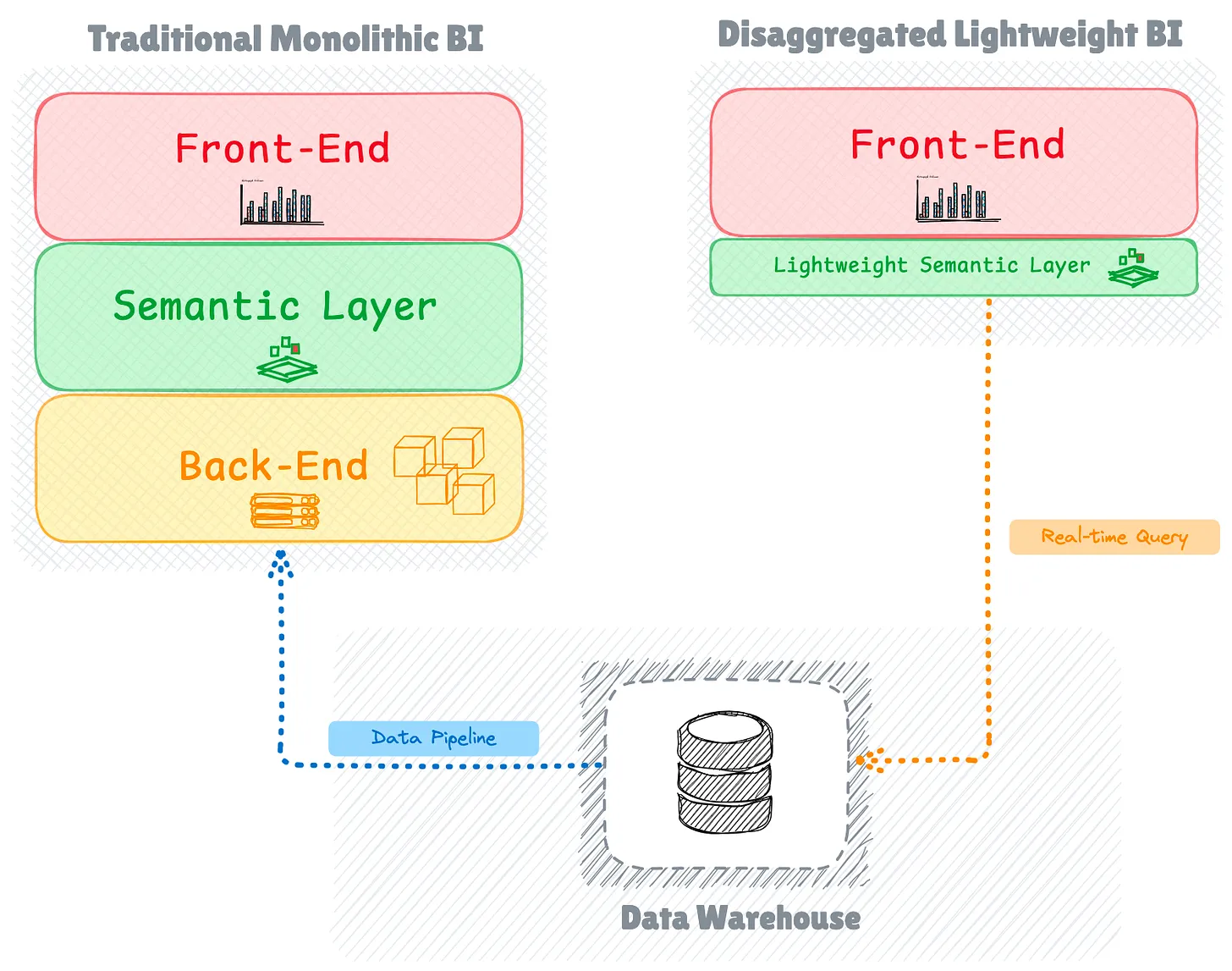
Появление бездонных (Bottomless) BI-инструментов
В ответ на эти вызовы появилось новое поколение легких, дезагрегированных BI-инструментов. Заметные решения с открытым исходным кодом, такие как Apache Superset, Metabase и Redash, начали появляться около десяти лет назад, причем Superset, первоначально разработанный в Airbnb, приобрел особую известность в экосистеме.
Эти новые инструменты приняли “безднную” архитектуру, устранив тяжелый серверный уровень, традиционно используемый для вычислений, построения и кеширования объектов куба.
Вместо того чтобы поддерживать свой собственный вычислительный уровень, они полагаются на подключенные исходные движки для запроса и предоставления данных на панели мониторинга во время выполнения. Этот архитектурный сдвиг вводит различные стратегии для обслуживания данных.
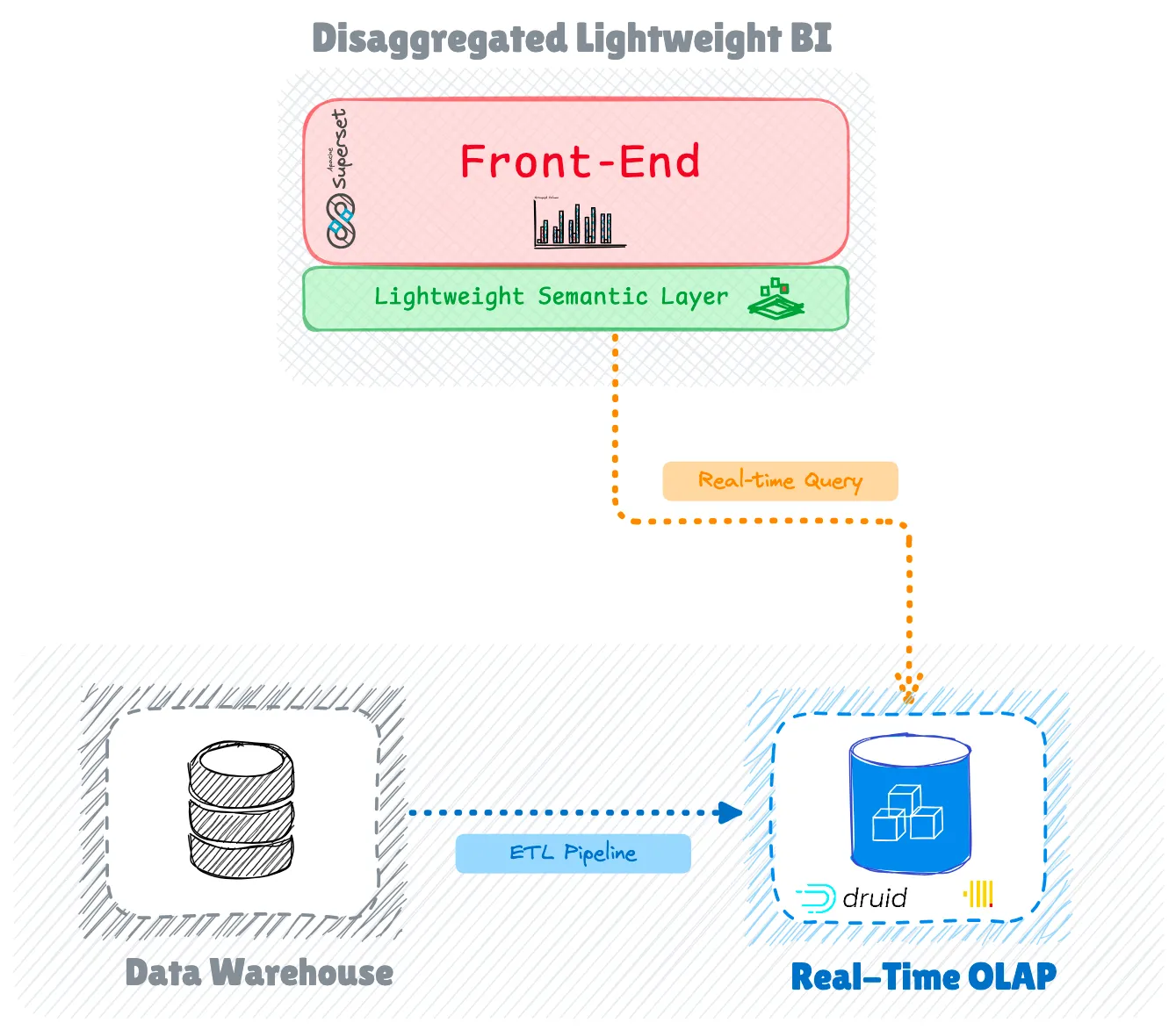
Работа с задержкой запросов
Отсутствие сервера отчетов представляет собой серьезную проблему для бездонных BI-инструментов: управление задержкой запросов при доступе к данным в режиме реального времени.
Чтобы решить эту проблему, эти инструменты используют несколько стратегий оптимизации. Один из ключевых подходов включает использование предварительно вычисленных агрегатов, хранящихся в основном хранилище данных, что позволяет панелям мониторинга эффективно предоставлять результаты.
Кроме того, такие инструменты, как Superset, реализуют уровни кеширования с использованием Redis для хранения часто используемых наборов данных. Этот механизм кеширования оказывается особенно эффективным: после того, как первоначальный запрос загружает набор данных, последующие визуализации и перезагрузки панели мониторинга могут обращаться к кешированной версии до тех пор, пока не изменятся базовые данные, что значительно сокращает время отклика.
Для компаний, работающих с большими объемами данных, интеграция со специализированными OLAP-движками реального времени, такими как Druid и ClickHouse, обеспечивает аналитические возможности с низкой задержкой.
Появление универсального семантического слоя
По мере того, как отрасль стремилась к большей гибкости в своем BI-стеке, переносимый семантический слой, или то, что известно как безголовая (headless) BI, появился в качестве промежуточного шага между традиционными монолитными системами и полностью легкими решениями.
Платформы безголовой BI предоставляют выделенный семантический слой, а некоторые объединяют движок запросов, позволяя организациям использовать любой инструмент визуализации по своему выбору. Этот подход полностью отделяет уровень представления (фронтенд) от семантического слоя.
С помощью таких инструментов, как Cube и MetricFlow (теперь часть dbt Labs), например, организации могут определять свои метрики и модели данных в центральном месте, а затем подключать различные инструменты визуализации, пользовательские приложения или легкие BI-решения к этому семантическому слою.
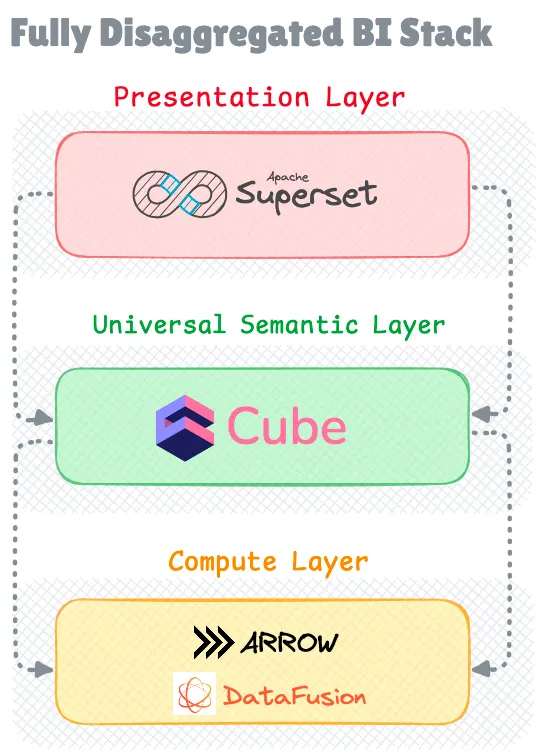
Этот архитектурный шаблон предлагает несколько преимуществ по сравнению с традиционными BI-системами. Он позволяет организациям поддерживать согласованные определения метрик в различных инструментах визуализации, поддерживает несколько интерфейсных приложений одновременно и обеспечивает лучшие возможности интеграции с современными стеками данных.
Семантический слой действует как универсальный переводчик между источниками данных и уровнями визуализации, обеспечивая согласованную бизнес-логику во всех аналитических приложениях.
Движение BI-as-Code
В последние годы наблюдается появление BI-as-Code, представляющего собой еще более легкий подход к разработке панелей мониторинга и интерактивных приложений для работы с данными.
Этот сдвиг парадигмы привносит рабочие процессы разработки программного обеспечения в разработку BI, позволяя использовать контроль версий, тестирование и методы непрерывной интеграции. Поскольку код служит основной абстракцией, а не пользовательским интерфейсом, разработчики могут реализовывать правильные рабочие процессы разработки перед развертыванием в производственной среде.
Известные инструменты в этой области, такие как Streamlit, легко интегрируются с экосистемой Python, позволяя разработчикам оставаться в рамках своих проектов Python без необходимости установки внешнего программного обеспечения для создания панелей мониторинга и приложений для работы с данными.
Этот подход делает упор на простоту и скорость, используя SQL и декларативные инструменты, такие как YAML, для создания панелей мониторинга. Полученные веб-приложения можно легко разместить самостоятельно, обеспечивая гибкость развертывания.
Хотя Streamlit лидирует по популярности, в последние годы появились новые решения с открытым исходным кодом, такие как Evidence, Rill, Vizro и Quary, каждое из которых привносит свой собственный подход к концепции BI-as-Code.
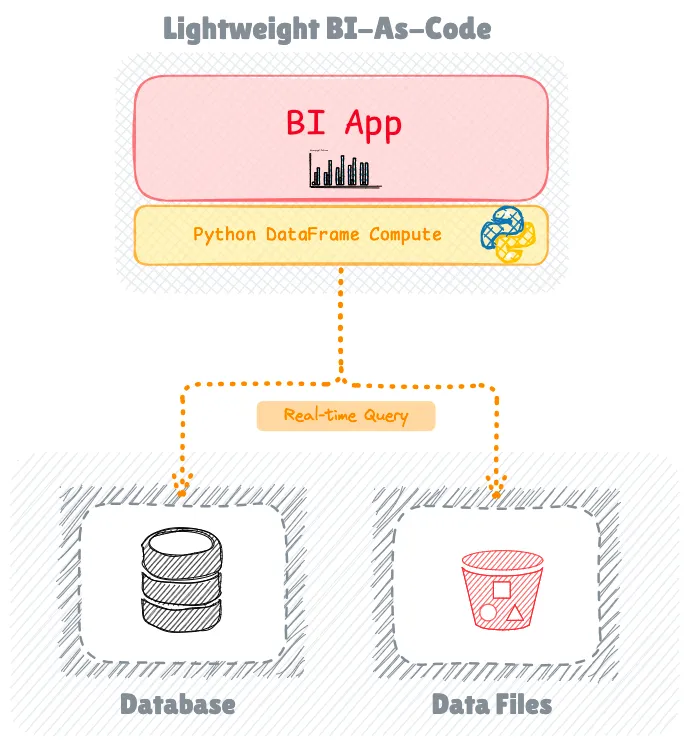
Ограничения BI-as-Code
Инструменты BI-as-Code в настоящее время имеют ограничения с точки зрения интерактивных функций исследования данных и предоставления BI-возможностей корпоративного уровня.
Они не обеспечивают тот же пользовательский опыт для нарезки и разделения данных, что и традиционные BI-инструменты, и им не хватает поддержки управления данными и семантического слоя, которые есть как в традиционных, так и в легких BI-решениях.
Тем не менее, BI-as-Code все чаще используется различными способами, например, командами специалистов по обработке данных, создающими интерактивные автономные приложения, командами разработчиков продуктов, создающими встроенные функции аналитики, и аналитиками, разрабатывающими внутренние приложения для работы с данными.
Новая развивающаяся тенденция: BI + Встроенная аналитика
Последняя эволюция в BI-архитектуре включает интеграцию высокопроизводительных встраиваемых OLAP-движков запросов, таких как Apache DataFusion и DuckDB.
Этот подход устраняет несколько пробелов в текущем ландшафте, сохраняя при этом преимущества легких, дезагрегированных архитектур.
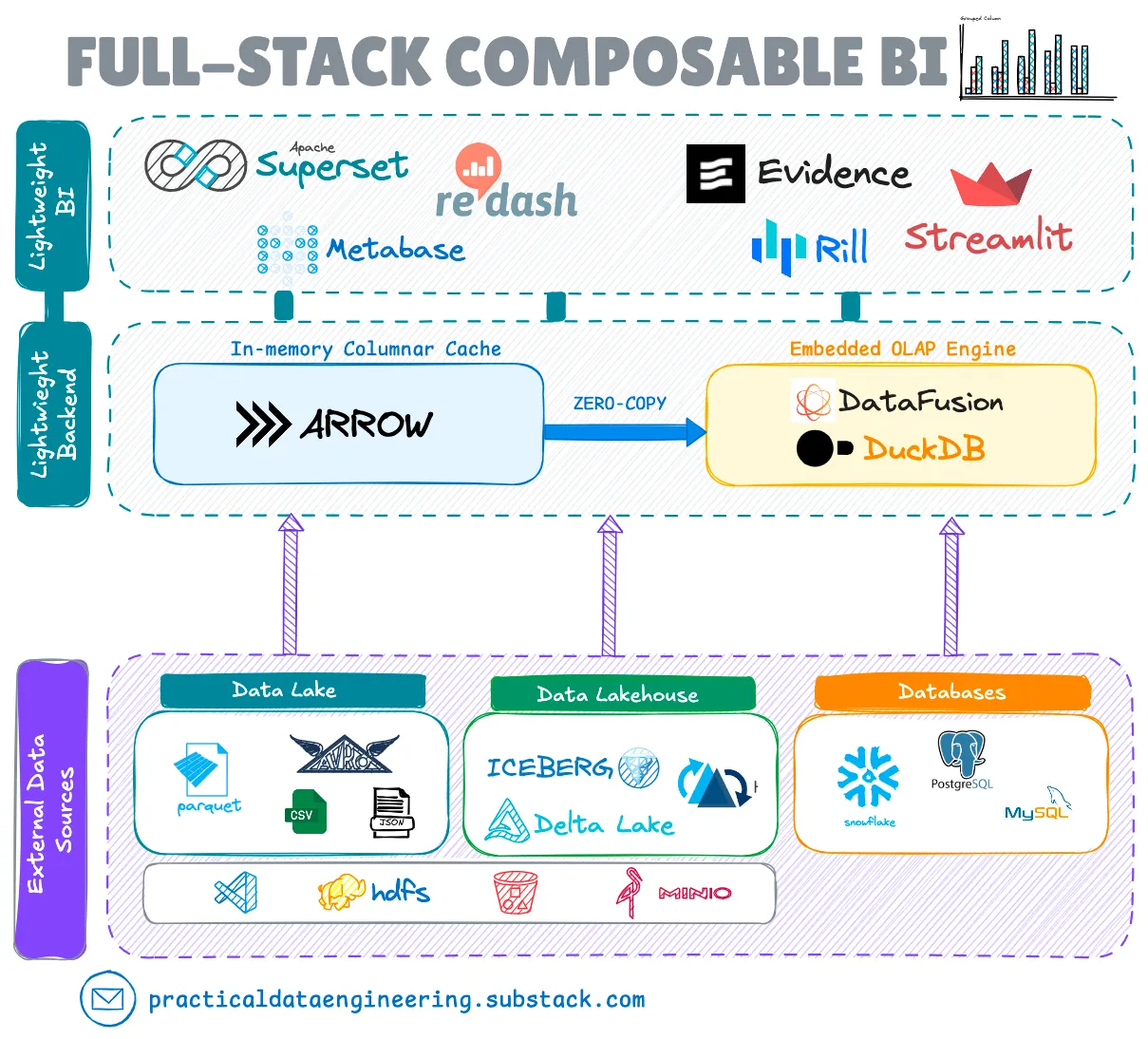
Новая полнофункциональная компонуемая BI-архитектура дает несколько ключевых преимуществ:
Во-первых, она предлагает настоящую компонуемость и совместимость с возможностью замены встроенных вычислительных движков по мере необходимости, сохраняя при этом автономный семантический слой для определения метрик.
Возможности встроенной аналитики особенно мощны благодаря интеграции без копирования через стандартные фреймворки, в основном Apache Arrow, обеспечивающей доступ к данным на уровне микросекунд через оптимизированные столбчатые форматы в памяти.
Интеграция без копирования относится к методу оптимизации производительности, при котором доступ к данным и их обработка могут осуществляться без необходимости сериализации и преобразования данных между различными представлениями в памяти. В контексте DataFusion и Apache Arrow это означает, что когда данные загружаются в память в столбчатом формате Arrow, DataFusion может напрямую выполнять вычисления с этими данными без необходимости их преобразования или копирования во внутренний формат.
Прямая поддержка озер данных и lakehouse представляет собой еще один значительный шаг вперед, позволяя командам создавать панели мониторинга непосредственно поверх открытых табличных форматов, таких как Apache Iceberg и Apache Hudi, без промежуточного перемещения данных.
Эта возможность в сочетании с комплексной поддержкой федеративных запросов решает давнюю проблему в существующих легких BI-инструментах, которые с трудом эффективно объединяли данные из нескольких источников без необходимости использования внешнего движка федеративных запросов.
Внедрение в отрасли
Внедрение встраиваемых движков запросов в отрасли набирает обороты в экосистеме BI. Коммерческие поставщики возглавляют эту трансформацию: Omni интегрировала DuckDB в качестве своего основного аналитического движка, в то время как Cube.dev реализовала сложное сочетание Apache Arrow и DataFusion в своей безголовой BI-архитектуре.
Аналогичным образом, GoodData приняла эту тенденцию, реализовав Apache Arrow в качестве основы уровня кеширования своей системы FlexQuery, а Preset (Managed Superset) интегрировалась с MotherDuck (Managed DuckDB).
В области открытого исходного кода и Superset (с использованием библиотеки duckdb-engine), и Metabase теперь поддерживают встроенное подключение DuckDB с потенциальной будущей интеграцией в их основные движки.
Движение BI-as-Code также приняло встраиваемые движки. Rilldata объявила об интеграции DuckDB в 2023 году для автоматического профилирования и интерактивного моделирования при разработке панелей мониторинга, в то время как Evidence представила Universal SQL в 2024 году, основанный на реализации WebAssembly от DuckDB.
Заключение
Ландшафт бизнес-аналитики продолжает развиваться в сторону более гибких и эффективных решений.
Каждое архитектурное изменение принесло явные преимущества: безголовая BI обеспечила согласованность метрик между инструментами, бездонная BI снизила сложность инфраструктуры, BI-as-Code привнесла рабочие процессы разработчиков в аналитику, а встроенные движки теперь объединяют эти преимущества с высокопроизводительными возможностями запросов.
Интеграция встраиваемых движков запросов с легкими BI-инструментами представляет собой перспективное направление для реализации легкой BI, объединяющее лучшие аспекты традиционных BI-возможностей с современными архитектурными шаблонами. По мере развития этих технологий и роста экосистемы компании могут рассчитывать на все более сложные, но компонуемые решения для своих аналитических потребностей.