
И еще немного про безопасность в масштабе
Ranger vs. OPA: Битва архитектур... и почему OPAL меняет правила игры
● Ranger has a fixed development model
● To add new systems you need to write new modules,
compile and roll out Ranger
● OPA is all REST
● Basically everything is configuration
● We can build the 80% abstraction layer easily
● Anybody else -> they can build whatever extra they need -> in config!В мире современных распределённых систем управление доступом (авторизация) — одна из самых сложных и критически важных задач. Компании постоянно ищут баланс между безопасностью, гибкостью и скоростью разработки. Начальные тезисы были абсолютно точны:
У Ranger фиксированная модель разработки. Чтобы добавить поддержку новых систем, нужно писать новые модули. [...] OPA полностью построен на REST. По сути, всё является конфигурацией. [...] Мы можем создать 80% абстракции, а остальные сами допишут всё, что нужно, через конфиг!
Это сравнение описывает переход от традиционной, монолитной архитектуры к современной, микросервисной. Однако история неполная без третьего ключевого элемента — OPAL, который решает фундаментальную проблему OPA при масштабировании.
Давайте рассмотрим все три компонента по порядку.
1. “Классический” подход: Apache Ranger
Apache Ranger — это зрелая и мощная система для централизованного управления политиками безопасности в экосистеме больших данных (Hadoop, Hive, Kafka и т.д.).
- Как это работает: Ranger работает по принципу “сервер + плагины”. Центральный сервер хранит все политики доступа. В каждую защищаемую систему (например, в Hive) устанавливается специальный плагин, который периодически опрашивает сервер Ranger, скачивает актуальные политики и кэширует их для быстрой проверки доступа.
- Сильные стороны:
- Централизация: Единый центр для аудита и управления доступом.
- Мощность: Глубокая интеграция с поддерживаемыми системами (например, безопасность на уровне колонок в Hive).
- Слабые стороны (те самые “фиксированные модели разработки”):
- Негибкость: Поддержка новой системы, не входящей в стандартный набор, требует написания плагина на Java, компиляции и развертывания новой версии Ranger. Это медленно и требует узкой экспертизы.
- “Бутылочное горлышко”: Все изменения проходят через центральную команду, что замедляет продуктовые команды.
- Не для микросервисов: Этот подход плохо подходит для динамичного мира микросервисов, где новые сервисы появляются каждый день.
Аналогия: Ranger — это как служба безопасности крупного завода, которая работает только со стандартными станками этого завода. Если вы покупаете новый станок из-за границы, вам нужно написать для службы безопасности целую новую инструкцию и переобучить персонал.
2. “Гибкий” подход: Open Policy Agent (OPA)
OPA — это универсальный движок политик с открытым исходным кодом. Его философия прямо противоположна Ranger. OPA ничего не знает о тех, кого он защищает.
- Как это работает:
- Ваш сервис, получив запрос, формирует JSON-документ с контекстом (`{“user”: “alice”, “action”: “read”, “resource”: “document”}`).
- Он отправляет этот JSON в OPA через простой REST API-вызов.
- OPA применяет к этому JSON’у правила, написанные на языке Rego, и мгновенно возвращает решение: `allow` или `deny`.
- Сильные стороны:
- Универсальность: OPA может управлять доступом к чему угодно — микросервисам, Kubernetes, конвейерам CI/CD, базам данных.
- Policy-as-Code: Политики на Rego — это код. Их можно хранить в Git, версионировать, тестировать и автоматически развертывать.
- Децентрализация: OPA обычно развертывается как “сайдкар”-контейнер рядом с каждым экземпляром сервиса, что обеспечивает низкую задержку и высокую отказоустойчивость.
- Проблема, которую OPA создает:
Представьте, у вас 500 микросервисов, и рядом с каждым работает свой экземпляр OPA. Возникают вопросы: - Как доставить обновление политики во все 500 экземпляров OPA одновременно?
- Откуда OPA возьмет данные для принятия решений (например, список ролей пользователя или владельцев документа)? Если каждый из 500 экземпляров OPA будет сам ходить в базу данных, это создаст колоссальную нагрузку.
Здесь на сцену выходит OPAL.
3. “Связующее звено”: OPAL (Open Policy Administration Layer)
OPAL — это не еще один движок политик. Это административный слой реального времени для OPA. Его единственная задача — поддерживать политики и данные в ваших OPA-агентах в актуальном состоянии.
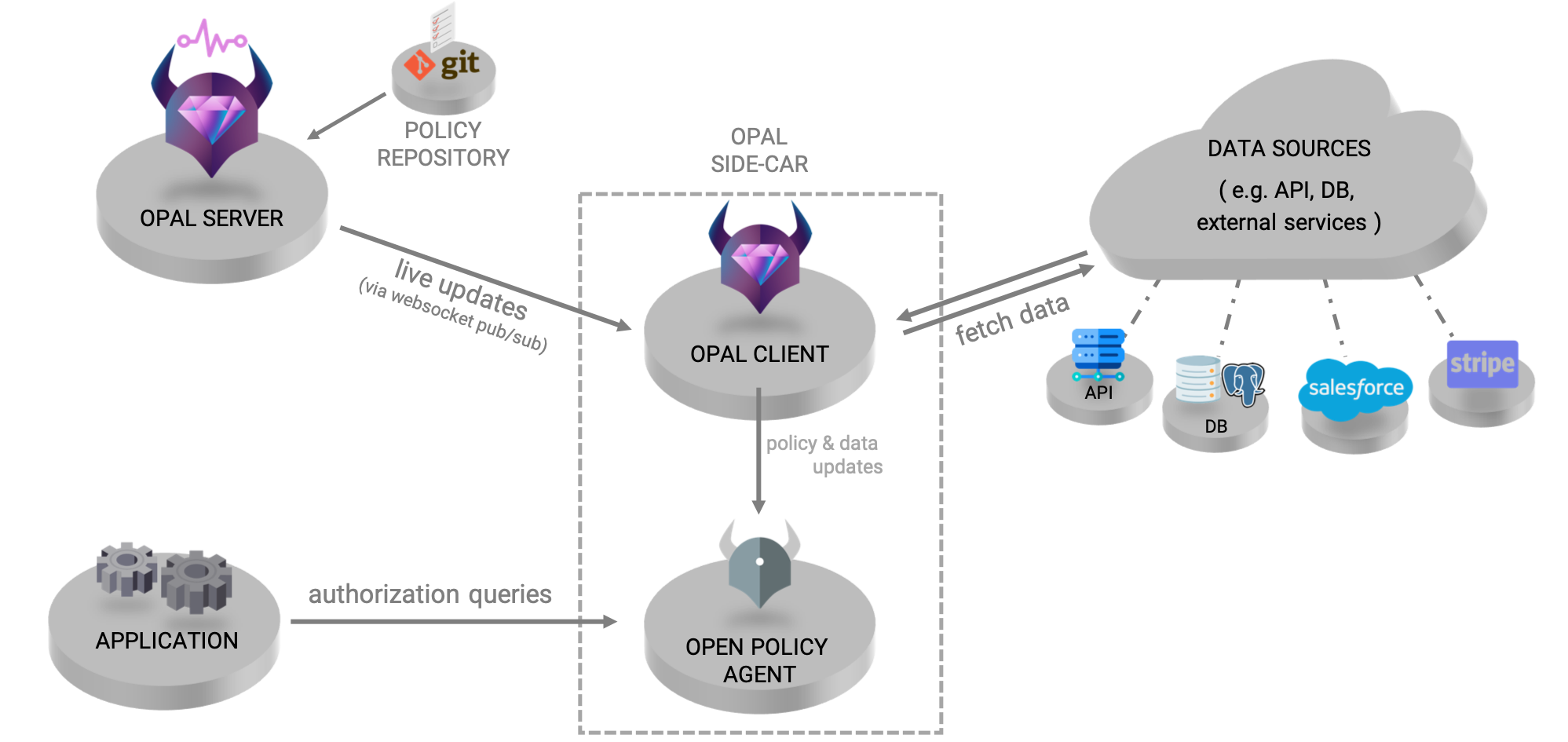
- Как это работает (OPA + OPAL):**
- Политики (Rego-файлы) хранятся в Git-репозитории. Данные (роли, атрибуты) — в базах данных или API.
- OPAL Server подписывается на изменения в этих источниках (например, через веб-хуки из Git или топики Kafka).
- Когда происходит изменение (например, разработчик пушит новую политику в Git), OPAL Server получает уведомление.
- Сервер немедленно публикует сообщение об обновлении в легковесный канал (pub/sub, обычно через WebSockets).
- OPAL Clients, работающие рядом с каждым OPA, получают это сообщение.
- Клиенты сами скачивают нужные обновления (новую политику из Git, свежие данные из БД) и загружают их в свой локальный OPA.
- Что это дает:
- Обновления в реальном времени: Изменение политики в Git моментально распространяется по всей системе.
- Событийная архитектура: Нет необходимости постоянно опрашивать источники. Это очень эффективно.
- Полное разделение: OPA отвечает только за принятие решений. OPAL — за доставку “знаний” для этих решений.
- Масштабируемость: Эта архитектура легко управляет тысячами OPA-агентов, решая проблему синхронизации.
- Завершение истории GitOps: Вы управляете доступом ко всей вашей инфраструктуре через `git push`, что полностью соответствует исходному тезису: “всё является конфигурацией”. medium.com
Итоговое сравнение
| Критерий | Apache Ranger | OPA (самостоятельно) | OPA + OPAL (Современный стек) |
| Архитектура | Монолитный сервер + плагины | Децентрализованный движок политик | Децентрализованный движок + слой управления реального времени |
| Процесс обновления | Код -> Компиляция -> Развертывание | Ручная загрузка политик через API | `git push` -> Автоматическое распространение |
| Гибкость | Низкая (только для поддерживаемых систем) | Очень высокая (универсальный) | Очень высокая + управляемость в масштабе |
| Управление данными | Встроено | Требует самостоятельного решения | Встроено в архитектуру (OPAL следит за данными) |
| Масштабируемость | Масштабируется, но обновления медленные | Плохо масштабируется с точки зрения управления | Отлично масштабируется |
| Подход | Классический, централизованный | `Policy-as-Code`, но неполный | `Policy-as-Code` + `GitOps`, событийно-ориентированный |
Вывод
Возвращаясь к исходным тезисам, становится ясно, что их автор описывал потенциал OPA. Однако чтобы этот потенциал раскрылся в крупной организации, необходима система, которая возьмет на себя рутинную, но критически важную работу по синхронизации.
- Ranger — это мощный, но неповоротливый инструмент из прошлого, идеальный для статичных, гомогенных сред.
- OPA — это гениально простой и гибкий движок, сердце современной авторизации.
- OPAL — это нервная система, которая соединяет это сердце с “мозгом” (Git, базы данных) и позволяет всему организму (вашим микросервисам) реагировать на изменения мгновенно.
Современный, масштабируемый и по-настоящему гибкий “слой абстракции”, о котором говорилось в начале, строится именно на связке OPA + OPAL. Это позволяет создавать платформу, ценность которой, как и было сказано, “заключается в способности объединять внешние инструменты, команды, данные и процессы”.
Еще было это: https://gavrilov.info/all/evolyuciya-upravleniya-dostupom-opa-opal-vs-fga-rbac-rebac/