
Открытый ландшафт инженерии данных 2024
Оригинал: https://alirezasadeghi1.medium.com/open-source-data-engineering-landscape-2024-8a56d23b7fdb
Исходный пост был опубликован на Practical Data Engineering Substack.
Введение
Пока широко распространенный хайп вокруг Генеративного ИИ и ChatGPT взволновал мир технологий, 2023 год стал еще одним захватывающим и живым годом в ландшафте инженерии данных, который стабильно становился более разнообразным и сложным, с непрерывным инновационным и эволюционным процессом на всех уровнях аналитической иерархии.
С продолжающимся распространением инструментов с открытым исходным кодом, фреймворков и решений возросло количество вариантов, доступных для инженеров данных! В таком быстро меняющемся ландшафте важность быть в курсе последних технологий и тенденций не может быть переоценена. Умение выбирать правильный инструмент для нужной работы – это важный навык, обеспечивающий эффективность и актуальность в условиях постоянно меняющихся вызовов инженерии данных.
Будучи внимательным наблюдателем за тенденциями в инженерии данных в моей роли старшего инженера данных и консультанта, я хотел бы представить ландшафт открытых исходных данных в начале 2024 года. Это включает в себя выявление ключевых активных проектов и важных инструментов, давая читателям возможность принимать обоснованные решения при навигации в этом динамичном технологическом ландшафте.
Почему представлять еще один ландшафт?
Почему тратить усилия на представление еще одного ландшафта данных!? Есть аналогичные периодические отчеты, такие как известный MAD Landscape, State of Data Engineering и Reppoint Open Source Top 25, однако ландшафт, который я представляю, фокусируется исключительно на инструментах с открытым исходным кодом, в основном применимых к платформам данных и жизненному циклу инженерии данных.
MAD Landscape предоставляет очень полное представление о всех инструментах и услугах для машинного обучения, искусственного интеллекта и данных, включая как коммерческие, так и открытые исходники, тогда как представленный здесь ландшафт предоставляет более полное представление о активных проектах с открытым исходным кодом в части данных MAD. Другие отчеты, такие как Reppoint Open Source Top 25 и Data50, фокусируются больше на поставщиках SaaS и стартапах, тогда как этот отчет фокусируется на самих проектах с открытым исходным кодом, а не на услугах SaaS.
Ежегодные отчеты и опросы, такие как Github’s state of open source, ежегодный опрос Stackoverflow и отчеты OSS Insight, также являются отличными источниками для получения представления о том, что используется или популярно в сообществе, но они охватывают только ограниченные разделы (например, базы данных и языки) общего ландшафта данных.
Поэтому из-за моего интереса к открытым стекам данных я составил список инструментов с открытым исходным кодом и услуг в экосистеме инженерии данных.
Так что без дополнительного ожидания, вот Экосистема открытых исходных данных инженерии 2024 года:

Критерии выбора инструментов
Доступные проекты с открытым исходным кодом для каждой категории, очевидно, обширны, что делает невозможным включение каждого инструмента и сервиса в картину. Поэтому я придерживался следующих критериев при выборе инструментов для каждой категории:
- Исключаются любые устаревшие, архивные и заброшенные проекты. Некоторые заметные устаревшие проекты – это Apache Sqoop, Scribe и Apache Apex, которые все еще могут использоваться в некоторых производственных средах.
- Исключаются проекты, которые были полностью неактивны на Github в течение последнего года и едва упоминаются в сообществе. Например, Apache Pig и проекты Apache Oozie.
- Исключаются проекты, которые все еще довольно новы и не получили много внимания в виде звезд Github, форков, а также публикаций в блогах, демонстраций и упоминаний в онлайн-сообществах. Однако некоторые многообещающие проекты, такие как OneTable, которые достигли некоторых значимых результатов и реализованы на основе существующих технологий, упоминаются.
- Инструменты для науки о данных, машинного обучения и искусственного интеллекта исключены, за исключением инструментов платформы и инфраструктуры машинного обучения, так как я сосредотачиваюсь только на том, что связано с дисциплиной инженерии данных.
- Перечислены различные типы хранилищ данных, такие как реляционные OLTP и встроенные системы баз данных. Это потому, что дисциплина инженерии данных включает в себя работу с множеством различных внутренних и внешних систем хранения, используемых в приложениях и операционных системах (BSS), даже если они не являются частью стека аналитики.
- Названия категорий выбраны как можно более общими на основе того, куда инструмент вписывается в стек данных. Для систем хранения используются основная модель базы данных и рабочая нагрузка базы данных (OLTP, OLAP) для группировки и маркировки систем, но, например, “Распределенные SQL DBMS” также называются HTAP или масштабируемыми SQL-базами данных на рынке.
- Некоторые инструменты могут принадлежать к более чем одной категории. VoltDB является как базой данных в памяти, так и распределенной SQL DBMS. Но я старался разместить их в категории, по которой их больше всего признают на рынке.
- Для некоторых баз данных может быть нечеткая граница в отношении категории, к которой они на самом деле принадлежат. Например, ByConity утверждает, что является решением для хранилищ данных, но построен на основе ClickHouse, который признан как движок реального времени OLAP. Поэтому до сих пор неясно, является ли он системой OLAP в реальном времени (способной поддерживать запросы менее чем за секунду) или нет.
- Не все перечисленные проекты являются полностью Переносимыми инструментами с открытым исходным кодом. Некоторые из проектов скорее являются Open Core, чем открытым исходным кодом. В моделях Open Core не все компоненты полной системы, предлагаемой основным поставщиком SaaS, являются открытыми исходниками. Поэтому при принятии решения о принятии инструмента с открытым исходным кодом важно учитывать, насколько переносим и действительно открыт исходный код проекта.
Обзор категорий инструментов
В следующем разделе кратко обсуждается каждая категория.
- Системы хранения
Системы хранения являются самой крупной категорией в представленном ландшафте, в основном благодаря недавнему взлету специализированных баз данных. Две последние всплескающие категории – это векторные и потоковые базы данных. Примеры открытых потоковых баз данных – Materialize и RaisingWave. Векторные базы данных также испытывают быстрый рост в области систем хранения. Я разместил векторные системы хранения в разделе ML Platform, поскольку они в основном используются в стеках ML и AI. Распределенные файловые системы и объектные хранилища также размещены в своей собственной связанной категории – это Платформа для хранилищ данных.
Как упоминалось в разделе критериев выбора, системы хранения группируются и маркируются на основе основной модели базы данных и рабочей нагрузки. На самом высоком уровне системы хранения могут быть классифицированы на три основных класса: OLTP, OLAP и HTAP. Они могут быть дополнительно классифицированы на основе SQL против NoSQL для OLTP-движков и офлайн (не в реальном времени) против реального времени (результаты менее секунды) для OLAP-движков, как показано на следующей диаграмме.
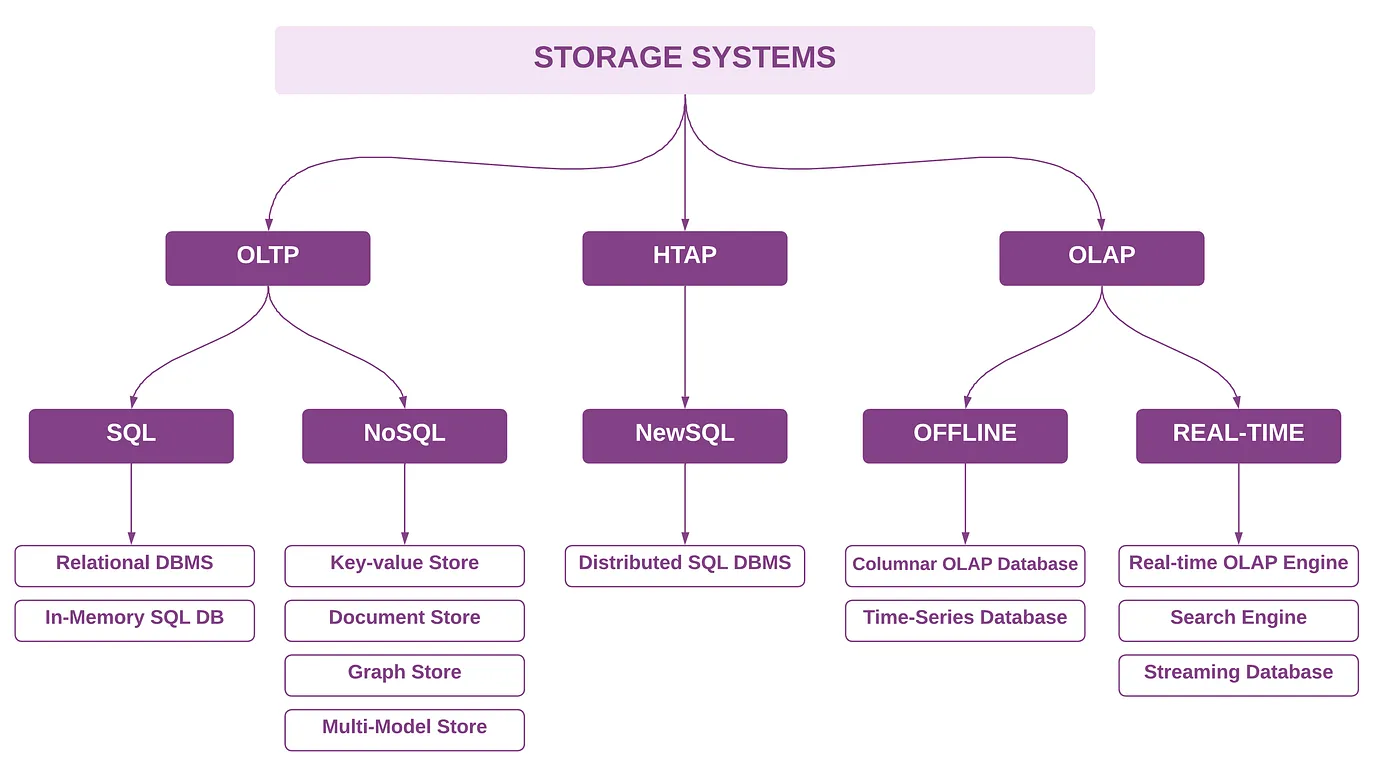
- Платформа для хранилищ данных
Платформа для хранилищ данных продолжает совершенствоваться в прошедшем году, и Gartner поместил Data Lake на склон просвещения в своем издании 2023 года Цикла гиперцикла управления данными.

Для слоя хранения распределенные файловые системы и объектные хранилища по-прежнему являются основными технологиями, служащими основой как для реализаций хранилищ данных на месте, так и для облачных. В то время как HDFS по-прежнему является основной технологией, используемой для кластеров Hadoop на месте, распределенное объектное хранилище Apache Ozone набирает обороты, чтобы предоставить альтернативную технологию хранения данных на месте. Cloudera, основной коммерческий поставщик Hadoop, теперь предлагает Ozone в рамках своего предложения CDP Private Cloud.
Выбор формата сериализации данных влияет на эффективность хранения и производительность обработки. Apache ORC остается предпочтительным выбором для колоночного хранения в экосистемах Hadoop, в то время как Apache Parquet стал де-факто стандартом для сериализации данных в современных хранилищах данных. Его популярность обусловлена компактным размером, эффективным сжатием и широкой совместимостью с различными движками обработки.
Еще одним ключевым трендом в 2023 году стало разделение слоев хранения и вычислений. Многие системы хранения теперь предлагают интеграцию с облачными решениями для хранения объектов, такими как S3, используя их врожденную эффективность и эластичность. Такой подход позволяет масштабировать ресурсы обработки данных независимо от хранения, что приводит к экономии затрат и улучшенной масштабируемости. Поддержка Cockroachdb S3 в качестве хранилища и предложение Confluent по долгосрочному хранению данных тематической кафки на S3 дополнительно иллюстрируют этот тренд, подчеркивая растущее использование хранилищ данных как экономичных, долгосрочных решений для хранения.
Одним из самых горячих событий 2023 года стало появление открытых форматов таблиц. Эти фреймворки по существу действуют как абстракция таблицы и виртуальный уровень управления данными, находящийся над вашим хранилищем данных и слоем данных, как показано на следующей диаграмме.
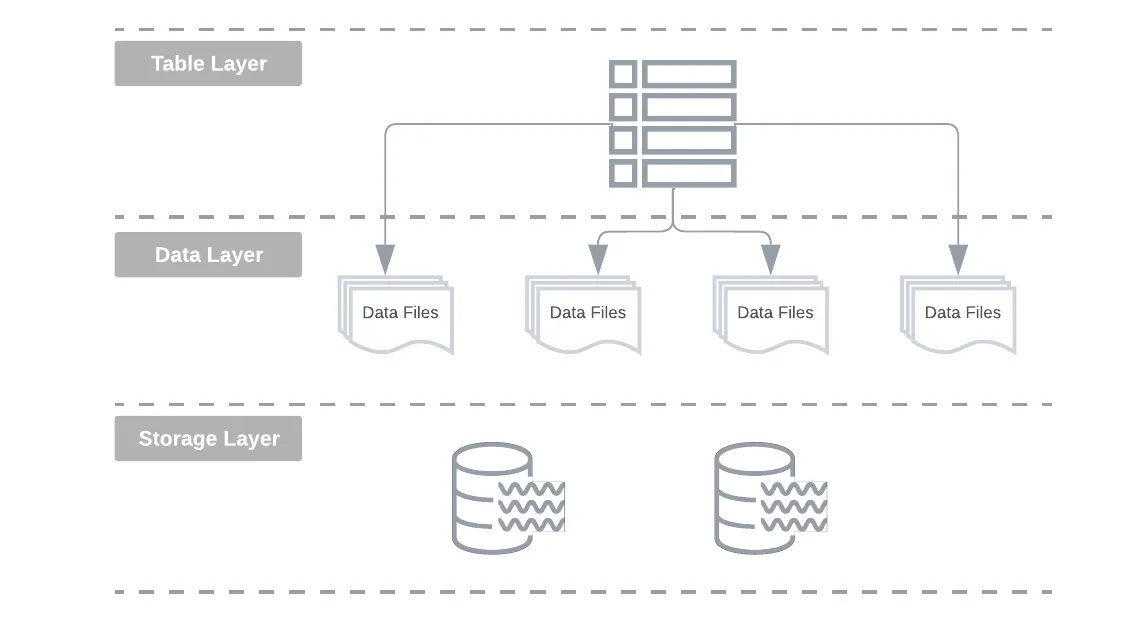
Пространство открытых форматов таблиц в настоящее время контролируется ожесточенной борьбой за главенство между следующими тремя основными претендентами:
Apache Hudi: Изначально разработанный и открытый Uber, с основной целью разработки для обновлений данных практически в реальном времени и транзакций ACID.
Apache Iceberg: Родившийся из команды инженеров Netflix.
Delta Lake: Созданный и открытый Databricks, с безупречной интеграцией с платформой Databricks.
Полученное финансирование ведущими поставщиками SaaS в этой области в 2023 году – Databricks, Tabular и OneHouse – подчеркивает интерес рынка и их потенциал для дальнейшего развития управления данными на хранилищах данных.
Более того, сейчас разворачивается новый тренд с появлением объединенных уровней хранилищ данных. OneTable (недавно открыт OneHouse) и UniForm (в настоящее время не open source предложение от Databricks) – это первые два проекта, которые были объявлены в прошлом году. Эти инструменты выходят за рамки индивидуальных форматов таблиц, предлагая возможность работы со всеми тремя основными претендентами под одним зонтом. Это позволяет пользователям использовать универсальный формат, предоставляя данные обработчикам в их предпочитаемых форматах, что приводит к увеличению гибкости и мобильности.
- Интеграция данных
Ландшафт интеграции данных в 2023 году не только продолжает оставаться под влиянием установленных игроков, таких как Apache Nifi, Airbyte и Meltano, но также появляются многообещающие инструменты, такие как Apache Inlong и Apache SeaTunnel, предлагающие привлекательные альтернативы со своими уникальными преимуществами.
Тем временем Streaming CDC (Change Data Capture) дальше совершенствуется, подпитываемый активной разработкой в экосистеме Kafka. Плагины Kafka Connect и Debezium стали основным выбором для практически в реальном времени захвата данных из систем баз данных, а коннекторы Flink CDC получают популярность для развертывания с использованием Flink в качестве основного движка потоковой обработки.
За пределами традиционных баз данных инструменты, такие как CloudQuery и Streampipe, упрощают интеграцию данных из API, предоставляя удобные решения для внедрения данных из различных источников, что отражает растущую важность гибкой интеграции с облачными сервисами.
В области промежуточных событий и сообщений Apache Kafka сохраняет свою сильную позицию, хотя конкуренты, такие как Redpanda, сокращают разрыв. $100 млн. финансирование серии C Redpanda в 2023 году показывает растущий интерес к альтернативным брокерам сообщений, предлагающим низкую задержку и высокую пропускную способность.
- Обработка и вычисления данных
Мир потоковой обработки продолжал нагреваться в 2023 году! Apache Spark и Apache Flink остаются правящими чемпионами, однако Apache Flink сделал серьезные заголовки в 2023 году. Облачные гиганты, такие как AWS и Alibaba, присоединились к предложениям Flink в качестве сервиса, а приобретение Confluent Immerok для собственного полностью управляемого предложения Flink в качестве сервиса показывает моментум за этим мощным двигателем.
В экосистеме Python доступны библиотеки обработки данных, такие как Vaex, Dask, polars и Ray, для использования многоядерных процессоров. Эти библиотеки параллельного выполнения дополнительно открывают возможности для анализа массивных наборов данных в привычной среде Python. - Управление рабочим процессом и DataOps
Оркестрация рабочих процессов, вероятно, является самой насыщенной категорией в представленной экосистеме данных, наполненной установленными тяжеловесами и захватывающими новичками.
Инструменты-ветераны, такие как Apache Airflow и Dagster, по-прежнему демонстрируют свою мощь и остаются широко используемыми движками во время недавних ожесточенных дебатов в сообществе о распаковке, повторной упаковке и упаковке против распаковки движков оркестрации рабочих процессов. С другой стороны, за последние два года GitHub стал свидетелем появления нескольких убедительных претендентов, которые захватили значительное внимание. Kestra, Temporal, Mage и Windmill заслуживают внимания, каждый из них предлагает уникальные преимущества. Новички могут удовлетворять изменяющиеся потребности современных потоков данных, будь то сосредоточенность на серверной оркестрации, как Temporal, или на распределенном выполнении задач, как Mage. - Инфраструктура и мониторинг данных
Последний опрос Grafana Labs подтверждает, что Grafana, Prometheus и стек ELK продолжают доминировать в области наблюдаемости и мониторинга. Компания Grafana Labs сама была довольно активной, представив новые инструменты с открытым исходным кодом, такие как Loki (для агрегации журналов) и Mimir (для долгосрочного хранения Prometheus), чтобы дополнительно укрепить свою платформу.
Одной из областей, где инструменты с открытым исходным кодом кажутся менее распространенными, является управление и мониторинг кластеров. Это, вероятно, связано с тенденцией к облачной миграции, уменьшающей необходимость в управлении крупными локальными платформами данных. Хотя проект Apache Ambari, однажды популярный для управления кластерами Hadoop, фактически был заброшен после слияния Hortonworks и Cloudera в 2019 году, недавнее возрождение вызывает некоторую надежду на его будущее. Однако его долгосрочная судьба остается неопределенной.
Что касается планирования ресурсов и развертывания рабочих нагрузок, Kubernetes кажется предпочтительным планировщиком ресурсов, особенно на облачных платформах.
- Платформа ML
Платформа машинного обучения стала одной из самых активных категорий с беспрецедентным ростом и интересом к векторным базам данных, специализированным системам, оптимизированным для хранения и извлечения высокомерных данных. Как подчеркнуто в отчете DB-Engines за 2023 год, векторные базы данных стали самой популярной категорией баз данных в прошлом году.
Инструменты MLOps также играют все более важную роль в эффективном масштабировании проектов машинного обучения, обеспечивая плавную работу и управление жизненным циклом приложений ML. Поскольку сложность и масштаб развертывания ML продолжают расти, инструменты MLOps стали неотъемлемыми для оптимизации разработки, развертывания и мониторинга моделей ML. - Управление метаданными
В последние годы управление метаданными заняло центральное место, подталкиваемое растущей потребностью в управлении и улучшении доступа к данным. Однако отсутствие комплексных платформ управления метаданными побудило гигантов технологической отрасли, таких как Netflix, Lyft, Airbnb, Twitter, LinkedIn и Paypal, создать свои собственные решения.
Эти усилия принесли значительные вклады в сообщество с открытым исходным кодом. Инструменты, такие как Amundsen (от Lyft), DataHub (от Netflix) и Marquez (от WeWork), являются решениями внутрикорпоративного разработки, которые были открыты и находятся в активной разработке и вкладе.
Что касается управления схемами, здесь пейзаж остается относительно стабильным. Hive Metastore продолжает быть основным решением для многих, поскольку на данный момент нет альтернативных решений с открытым исходным кодом для его замены. - Аналитика и визуализация
В области бизнес-аналитики (BI) и визуализации Apache Superset выделяется как самая активная и популярная альтернатива лицензионным SaaS решениям BI.
Что касается распределенных и массово-параллельных обработчиков (MPP), некоторые эксперты утверждают, что большие данные мертвы и большинству компаний не требуется распределенная обработка крупномасштабных данных, предпочитая использовать одиночные мощные серверы для обработки своих объемов данных.
Несмотря на это утверждение, распределенные массово-параллельные обработчики (MPP), такие как Apache Hive, Impala, Presto и Trino, остаются распространенными в крупных платформах данных, особенно для данных в петабайтном масштабе.
Помимо традиционных обработчиков MPP, еще одним трендом, набирающим обороты, являются единые исполнительные движки. Движки, такие как Apache Linkis, Alluxio и Cube, предоставляют промежуточный запрос и вычисление между верхними приложениями и базовыми двигателями.

Заключение
Это исследование открытой ландшафта инжиниринга данных представляет лишь мгновенный взгляд на динамичный и живой мир данных. Хотя важные инструменты и технологии были рассмотрены в различных категориях, экосистема продолжает быстро развиваться, появляясь новые решения.
Помните, что это не исчерпывающий список, и “лучшие” инструменты в конечном итоге определяются вашими конкретными потребностями и применением. Не стесняйтесь поделиться любыми замечательными инструментами, которые я упустил и которые, по вашему мнению, должны были быть включены.
Оригинальный пост был опубликован на Practical Data Engineering Substack.