
План запросов — Анализируем производительность в Trino
Оригинал: https://medium.com/@simon.thelin90/query-plans-analyse-sql-performance-in-trino-97ac1e8f8044
Или тут: https://a.gavrilov.info/data/posts/Query%20Plans%20—%20Analyse%20SQL%20Performance%20In%20Trino%20%7C%20by%20Simon%20Thelin%20%7C%20Medium.pdf Query Plans — Analyse SQL Performance In Trino
Ещё одно воскресенье и ещё одна #датаболь для обсуждения.
Сегодня я хочу углубиться в то, как мы можем понять план запроса в Trino.
Исследование плана запроса
Порядок выполнения SQL — Давайте вспомним
Прежде чем мы начнем рассматривать это, давайте вспомним порядок выполнения в SQL-запросе.
FROM, JOIN
WHERE
GROUP BY
HAVING
SELECT
DISTINCT
ORDER BY
LIMIT
Это поможет нам, когда будем читать план запроса.
Как определить, является ли ваш SQL производительным?⚡
Прежде чем запрос может быть запланирован, движок также должен:
Идентифицировать таблицы
Идентифицировать столбцы, использованные в запросе
SQL, простой подсчёт названий должностей, где мы группируем по департаменту.
EXPLAIN ANALYZE WITH
count_titles AS (
SELECT
department,
COUNT(job_title) AS count_job_titles
FROM lakehouse.bronze.jobs
GROUP BY 1
)
SELECT * FROM count_titles
SQL-запрос использует Общую Табличную Выражение (CTE) под именем count_titles для упрощения структуры и улучшения читаемости запроса.
Он начинается с выбора данных из таблицы lakehouse.bronze.jobs.
Внутри CTE данные группируются по столбцу department.
Для каждой группы департаментов подсчитывается количество вхождений job_title и обозначается как count_job_titles.
После определения CTE основной запрос выбирает все столбцы из count_titles CTE.
Основная цель запроса — получить количество названий должностей для каждого департамента из таблицы lakehouse.bronze.jobs.
План запроса 📣
В очереди: 1.84ms, Анализ: 85.69ms, Планирование: 58.35ms, Выполнение: 450.11ms
Фрагмент 1 [HASH]
CPU: 7.57ms, Запланировано: 11.12ms, Заблокировано: 1.80s (Вход: 933.53ms, Выход: 0.00ns), Вход: 8 строк (176B); на задачу: ср.: 4.00, отклонение: 2.00, Выход: 3 строки (67B)
Количество входных данных, обработанных рабочими для этого этапа, может быть перекошено
Выходная структура: [department, count]
Разделение выхода: SINGLE []
Агрегат[тип = FINAL, ключи = [department]]
│ Расклад: [department:varchar, count:bigint]
│ Оценки: {строк: 3 (68B), cpu: 226, память: 68B, сеть: 0B}
│ CPU: 3.00ms (15.00%), Запланировано: 3.00ms (6.52%), Заблокировано: 0.00ns (0.00%), Выход: 3 строки (67B)
│ Ср. вход: 1.00 строки, стандартное отклонение входа: 132.29%
│ count := count(count_0)
└─ LocalExchange[разделение = HASH, аргументы = [department::varchar]]
│ Расклад: [department:varchar, count_0:bigint]
│ Оценки: {строк: 10 (226B), cpu: 226, память: 0B, сеть: 0B}
│ CPU: 1.00ms (5.00%), Запланировано: 1.00ms (2.17%), Заблокировано: 716.00ms (31.49%), Выход: 8 строк (176B)
│ Ср. вход: 1.00 строки, стандартное отклонение входа: 86.60%
└─ RemoteSource[идентификаторы источников = [2]]
Расклад: [department:varchar, count_0:bigint]
CPU: 0.00ns (0.00%), Запланировано: 1.00ms (2.17%), Заблокировано: 933.00ms (41.03%), Выход: 8 строк (176B)
Ср. вход: 1.00 строки, стандартное отклонение входа: 86.60%
Фрагмент 2 [HASH]
CPU: 11.24ms, Запланировано: 19.46ms, Заблокировано: 860.54ms (Вход: 444.24ms, Выход: 0.00ns), Вход: 10 строк (362B); на задачу: ср.: 5.00, отклонение: 2.00, Выход: 8 строк (176B)
Количество входных данных, обработанных рабочими для этого этапа, может быть перекошено
Выходная структура: [department, count_0]
Разделение выхода: HASH [department]
Агрегат[тип = PARTIAL, ключи = [department]]
│ Расклад: [department:varchar, count_0:bigint]
│ Оценки: {строк: 10 (226B), cpu: ?, память: ?, сеть: ?}
│ CPU: 4.00ms (20.00%), Запланировано: 7.00ms (15.22%), Заблокировано: 0.00ns (0.00%), Выход: 8 строк (176B)
│ Ср. вход: 1.25 строки, стандартное отклонение входа: 118.32%
│ count_0 := count(job_title)
└─ Агрегат[тип = FINAL, ключи = [department, job_title]]
│ Расклад: [department:varchar, job_title:varchar]
│ Оценки: {строк: 10 (362B), cpu: 362, память: 362B, сеть: 0B}
│ CPU: 1.00ms (5.00%), Запланировано: 2.00ms (4.35%), Заблокировано: 0.00ns (0.00%), Выход: 10 строк (362B)
│ Ср. вход: 1.25 строки, стандартное отклонение входа: 118.32%
└─ LocalExchange[разделение = HASH, аргументы = [department::varchar, job_title::varchar]]
│ Расклад: [department:varchar, job_title:varchar]
│ Оценки: {строк: 10 (362B), cpu: 362, память: 0B, сеть: 0B}
│ CPU: 0.00ns (0.00%), Запланировано: 0.00ns (0.00%), Заблокировано: 181.00ms (7.96%), Выход: 10 строк (362B)
│ Ср. вход: 1.25 строки, стандартное отклонение входа: 190.79%
└─ RemoteSource[идентификаторы источников = [3]]
Расклад: [department:varchar, job_title:varchar]
CPU: 0.00ns (0.00%), Запланировано: 0.00ns (0.00%), Заблокировано: 444.00ms (19.53%), Выход: 10 строк (362B)
Ср. вход: 1.25 строки, стандартное отклонение входа: 190.79%
Фрагмент 3 [SOURCE]
CPU: 11.49ms, Запланировано: 32.68ms, Заблокировано: 0.00ns (Вход: 0.00ns, Выход: 0.00ns), Вход: 10 строк (382B); на задачу: ср.: 10.00, std.dev.: 0.00, Выход: 10 строк (362B)
Выходная структура: [department, job_title]
Разделение выхода: HASH [department, job_title]
Агрегат[тип = PARTIAL, ключи = [department, job_title]]
│ Расклад: [department:varchar, job_title:varchar]
│ Оценки: {строк: 10 (362B), cpu: ?, память: ?, сеть: ?}
│ CPU: 1.00ms (5.00%), Запланировано: 3.00ms (6.52%), Заблокировано: 0.00ns (0.00%), Выход: 10 строк (362B)
│ Ср. вход: 10.00 строк, std.dev.: 0.00%
└─ Сканирование таблицы[таблица = lakehouse:bronze.jobs]
Расклад: [job_title:varchar, department:varchar]
Оценки: {строк: 10 (362B), cpu: 362, память: 0B, сеть: 0B}
CPU: 10.00ms (50.00%), Запланировано: 29.00ms (63.04%), Заблокировано: 0.00ns (0.00%), Выход: 10 строк (382B)
Ср. вход: 10.00 строк, std.dev.: 0.00%
job_title := job_title:varchar:ОБЫЧНО
department := department:varchar:ОБЫЧНО
Вход: 10 строк (382B), Физический вход: 1.32kB, Время физического входа: 7.50ms
Общая информация о выводе и плане запроса
Высокоуровневый вывод выполнения.
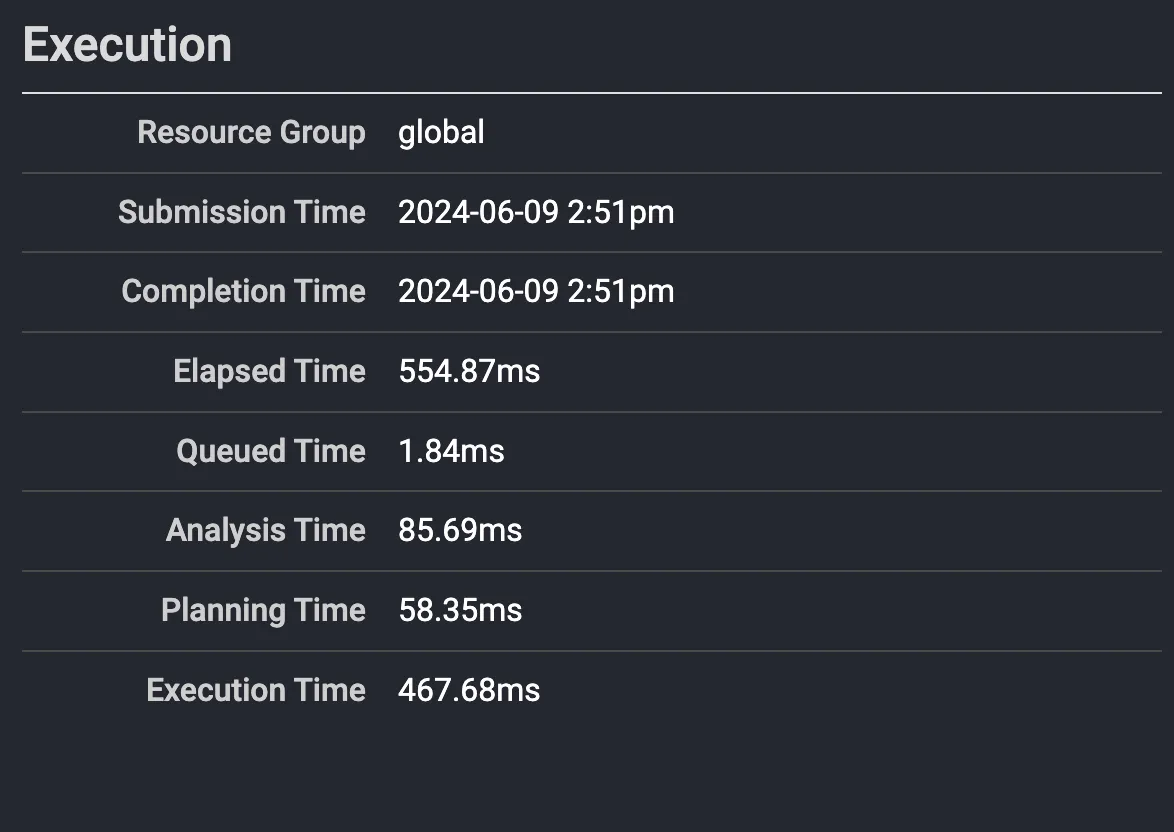
В очереди: 1.84ms
Анализ: 85.69ms
Планирование: 58.35ms
Выполнение: 467.68ms
Разделение на фрагменты
Выполнение запроса делится на три главные фрагмента. Каждый фрагмент представляет этап в процессе выполнения.
Фрагмент 1 [HASH]
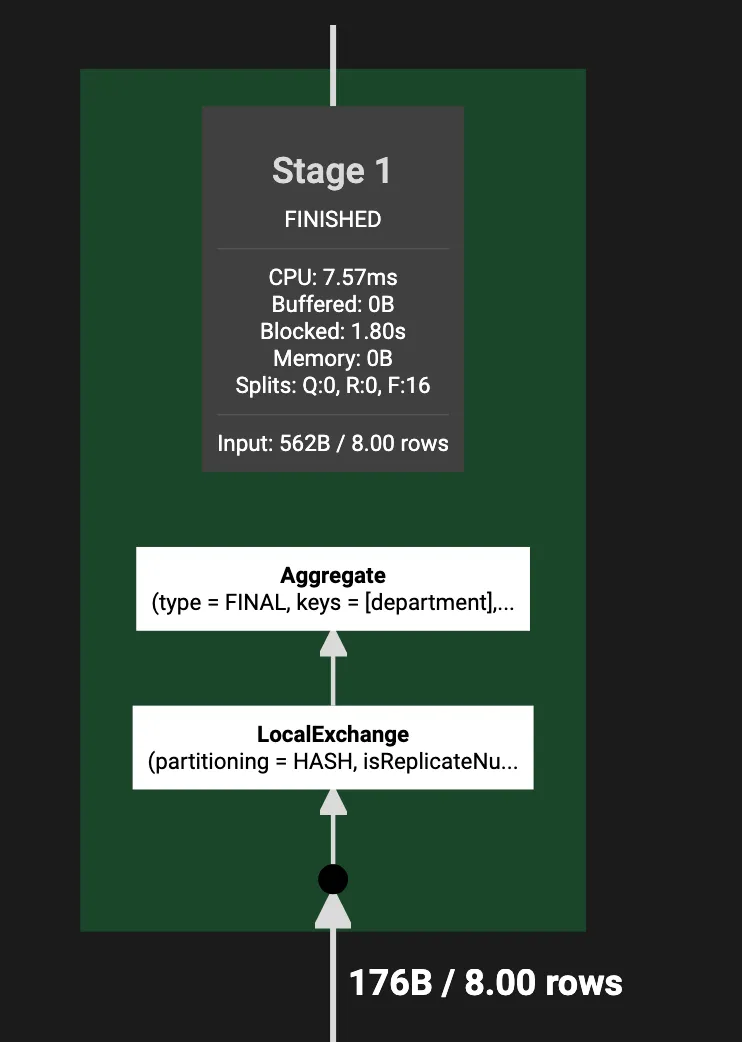
HASH
Роль: Этот фрагмент обрабатывает окончательную агрегацию результатов.
Производительность:
CPU: 7.57ms
Запланировано: 11.12ms
Заблокировано: 1.80s (главным образом ожидание данных от других фрагментов)
Вход/Выход:
Вход: 8 строк (176B)
Выход: 3 строки (67B)
Выходная структура: [department, count]
Операции:
Агрегация: Окончательная агрегация по департаменту для вычисления общего количества названий должностей.
Локальный обмен: Перераспределение данных по департаменту для подготовки к окончательной агрегации.
Фрагмент 2 [HASH]
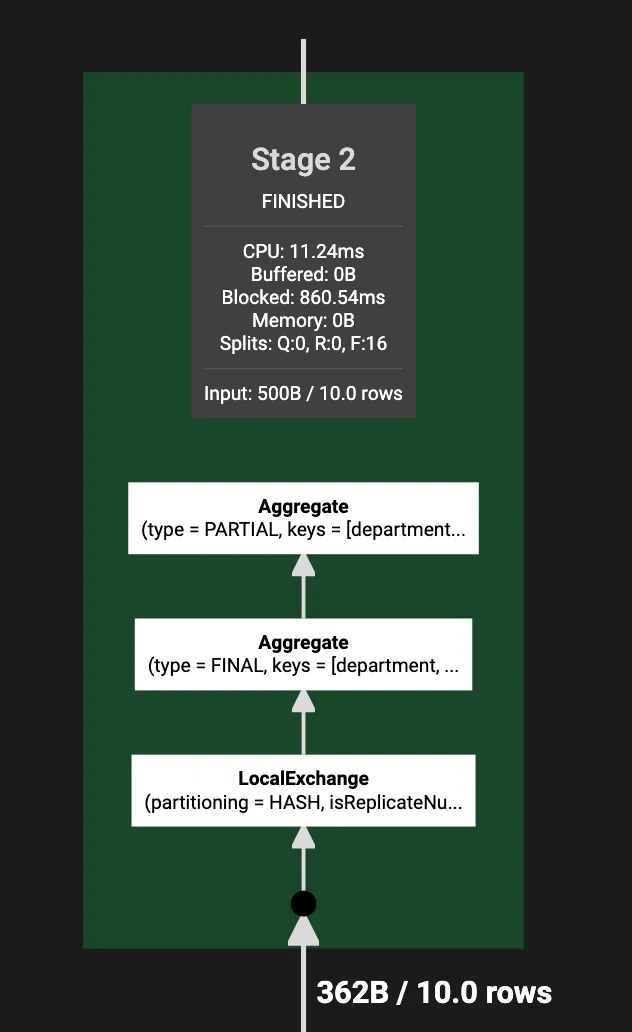
Роль: Этот фрагмент выполняет частичную агрегацию названий должностей по департаменту.
Производительность:
CPU: 11.24ms
Запланировано: 19.46ms
Заблокировано: 860.54ms
Вход/Выход:
Вход: 10 строк (362B)
Выход: 8 строк (176B)
Выходная структура: [department, count_0]
Операции:
Частичная агрегация: Подсчитывает названия должностей по департаменту.
Локальный обмен: Перераспределение данных по департаменту, job_title для дальнейшей агрегации.
Фрагмент 3 [SOURCE]
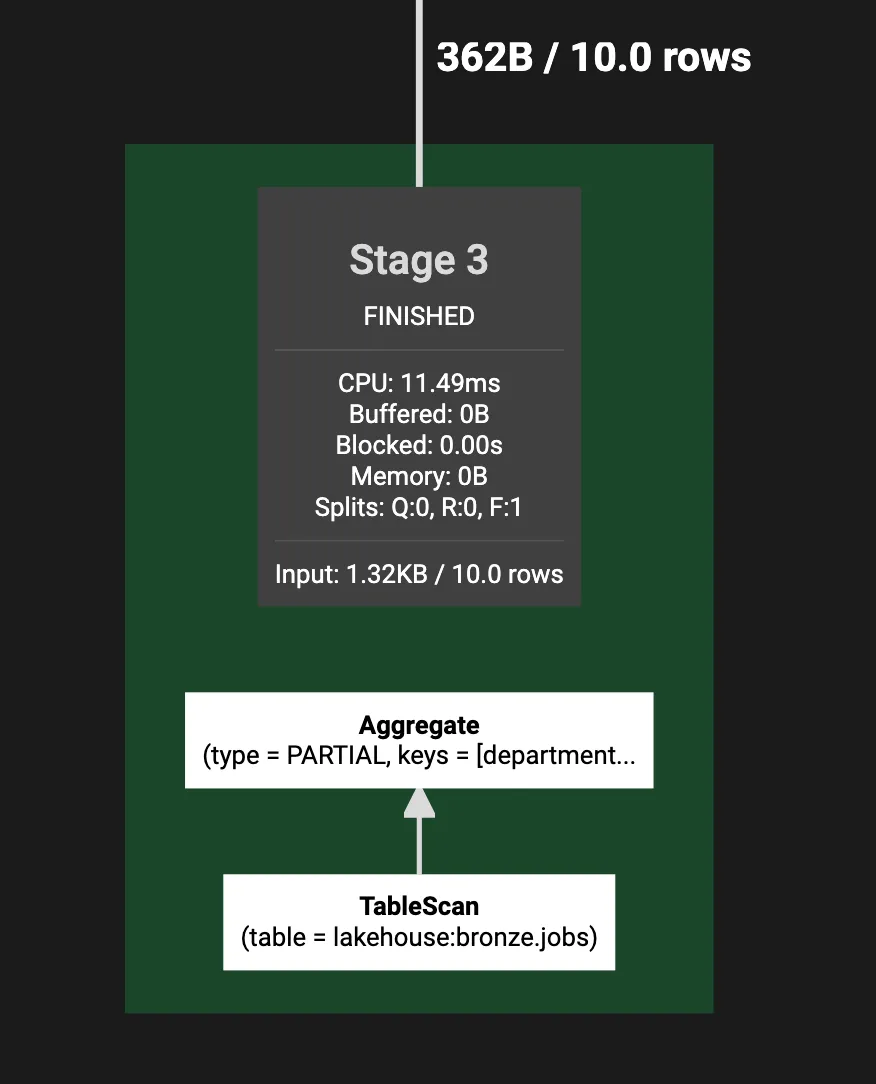
SOURCE — Сканирование таблицы
Роль: Этот фрагмент читает данные из исходной таблицы.
Производительность:
CPU: 11.49ms
Запланировано: 32.68ms
Вход/Выход:
Вход: 10 строк (382B)
Выход: 10 строк (362B)
Выходная структура: [department, job_title]
Операции:
Сканирование таблицы: Чтение столбцов department и job_title из таблицы lakehouse.bronze.jobs.
Частичная агрегация: Группировка данных по департаменту и job_title и подготовка их к дальнейшей обработке.
Ключевые выводы
Чтение плана запроса: Этапы представлены в порядке от наименьшего значения этапа к последнему шагу, и от наибольшего значения этапа к первому шагу. Это также связывается с порядком выполнения, который мы упомянули выше.
Время блокировки: Значительное время блокировки указывает на ожидание передачи данных между фрагментами, особенно в Фрагменте 1 и Фрагменте 2. Это часто является признаком задержек передачи данных или неравенства во времени обработки между фрагментами.
Перекос данных: Обратите внимание на перекос в количестве данных, обрабатываемых рабочими на различных этапах, что приводит к тому, что некоторые рабочие обрабатывают больше данных, чем другие. Это может вызывать неэффективность.
Шаги агрегации: Запрос включает несколько этапов частичных и окончательных агрегаций, которые можно оптимизировать, если возможно, уменьшив переброс данных между фрагментами.
CPU и планирование: Время работы CPU и планирования относительно низкое по сравнению с заблокированным временем, что предполагает, что ресурсы CPU не являются узким местом.
Настройка SQL: Измените ваш SQL и изучите план запроса, чтобы найти правильный баланс между этими факторами.
Предложения по оптимизации
Модель данных: Убедитесь, что у вас есть правильная модель данных, например, звездная схема, и выполните расчет OBT на основе звездной схемы.
Материализованное представление: Предварительно посчитайте частые агрегации. Однако я бы предпочел предыдущий шаг этому, это может быть полезно, если у вас нет много времени или вы работаете над первым шагом параллельно, но будьте осторожны, чтобы избежать большого технического долга.
Упростите агрегации: Минимизируйте сложные шаги агрегации, чтобы уменьшить переброс данных.