
Создаем Streaming Lakehouse за час: руководство по RisingWave, Lakekeeper и Trino
Вы когда-нибудь мечтали о платформе, где данные, отправленные через простой API-вызов, через секунды становятся доступны для аналитических запросов в вашем озере данных? Мечты сбываются. Эта статья — подробное, основанное на реальном опыте руководство, которое покажет, как построить современный Streaming Lakehouse с нуля.
Доки, которые пригодились:
https://github.com/risingwavelabs/risingwave/blob/main/docker/docker-compose.yml
https://github.com/lakekeeper/lakekeeper/blob/main/examples/minimal/docker-compose.yaml
https://docs.risingwave.com/iceberg/deliver-to-iceberg#rest-catalog
Наши главные герои:
- RisingWave: Потоковая база данных, “сердце” нашего пайплайна. Она будет принимать, преобразовывать и материализовывать данные на лету.
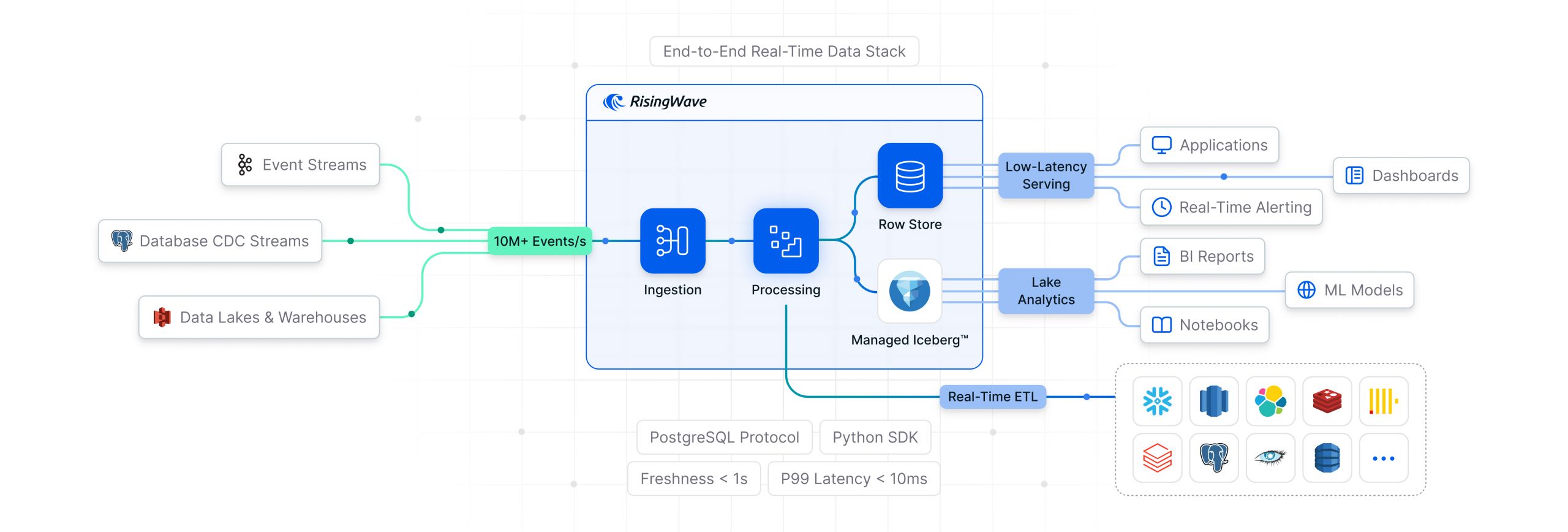
- Lakekeeper: Современный REST-каталог для Apache Iceberg. Наш “библиотекарь”, который знает все о структуре данных в озере.

- Trino: Мощный движок для федеративных запросов. Наше “окно” в озеро данных для выполнения ad-hoc аналитики.

Мы пройдем весь путь: от сравнения технологий и настройки окружения до отправки данных и любования результатами на дашбордах Grafana. И самое главное — мы поделимся всеми “граблями”, на которые наступили, чтобы вы могли их обойти.
Глава 1: Почему RisingWave? Взгляд на альтернативы
На рынке потоковой обработки есть много инструментов, но все они предлагают разные подходы. Почему для нашей задачи мы выбрали именно RisingWave?
RisingWave — это распределенная потоковая база данных, созданная для упрощения обработки данных в реальном времени. Ее ключевая особенность — использование материализованных представлений поверх потоков данных. Вы пишете знакомый SQL, а RisingWave берет на себя всю сложную работу по инкрементальному обновлению результатов с минимальной задержкой.
Давайте сравним его с популярными альтернативами.
Сравнительная таблица
| Критерий | RisingWave | Связка Debezium + Flink | Apache SeaTunnel |
| Архитектура | Единая система: хранение состояния (state) и вычисления в одном продукте. | Компонентная: Debezium (CDC), Kafka (очередь), Flink (обработка), отдельное хранилище состояния. | Инструмент для перемещения данных (data mover) с коннекторами. |
| Основная задача | Создание и поддержка инкрементально обновляемых материализованных представлений. | Гибкая, низкоуровневая обработка потоков общего назначения. | Пакетная и потоковая синхронизация данных между разнородными источниками и приемниками. |
| Простота использования | Очень высокая. Знание SQL — это 90% успеха. Скрывает сложность управления состоянием. | Низкая. Требует экспертизы в каждом компоненте, написания кода на Java/Scala, управления состоянием. | Средняя. Конфигурация через файлы, но требует понимания особенностей каждого коннектора. |
| Обработка данных | SQL-ориентированная. `CREATE MATERIALIZED VIEW ... AS SELECT ...`. | Программная. DataStream API, Table API/SQL. Позволяет писать сложную бизнес-логику. | Декларативная. Определяет `source`, `transform`, `sink`. Менее гибкая для сложных трансформаций. |
| Поддержка SQL | Первоклассная. Совместимость с PostgreSQL на уровне синтаксиса и протокола. | Хорошая (Flink SQL), но не является основным интерфейсом. | Ограниченная. Используется для простых трансформаций, а не для определения логики потока. |
| Управление состоянием | Встроенное и автоматическое. Использует облачное хранилище (S3) как персистентный слой. | Ручное. Требуется настраивать и управлять чекпоинтами и состоянием (например, RocksDB). | Зависит от движка (Flink/Spark). Не является основной функцией самого SeaTunnel. |
Выводы:
- Связка Debezium + Flink — это невероятно мощный, но сложный “конструктор”. Он идеален для компаний с большими командами инженеров данных, которым нужна максимальная гибкость для создания кастомной логики.
- Apache SeaTunnel — это отличный “швейцарский нож” для перемещения данных. Его сила — в огромном количестве коннекторов. Он идеален для задач ETL/ELT, когда нужно перелить данные из точки А в точку Б с минимальными трансформациями.
- RisingWave занимает золотую середину для аналитических задач в реальном времени. Он предлагает простоту и элегантность SQL, скрывая под капотом всю сложность потоковой обработки. Если ваша цель — быстро получить свежие аналитические витрины из потоков данных, RisingWave — ваш выбор.
Глава 2: “Кексы” — фишки RisingWave, которые упрощают жизнь 🍰
Что делает RisingWave таким привлекательным на практике?
- PostgreSQL-совместимость: Вы можете подключиться к RisingWave любым клиентом, который “говорит” на протоколе Postgres (например, DBeaver, psql). Синтаксис SQL для создания представлений и запросов вам уже знаком.
- Все-в-одном для стриминга: RisingWave объединяет в себе прием данных (коннекторы), их обработку (инкрементальные вычисления) и хранение состояния. Вам не нужно разворачивать и связывать вместе Kafka, Zookeeper, Flink и RocksDB.
- Нативные Sink’и и Source’ы: В нашем примере мы использовали встроенный `webhook` коннектор — не нужно писать отдельный сервис для приема данных! RisingWave нативно умеет работать с Kafka/Redpanda, Kinesis, Pulsar, а также писать данные напрямую в Iceberg, Delta Lake и другие системы.
- Инкрементальные вычисления “под капотом”: Когда вы создаете материализованное представление, RisingWave строит план потоковой обработки. При поступлении новых данных он не пересчитывает все заново, а инкрементально обновляет результат. Это обеспечивает сверхнизкую задержку.
Глава 3: Практика: Строим наш Streaming Lakehouse шаг за шагом
Теперь перейдем к самому интересному — воссозданию нашего успешного проекта.
Этап 1: Архитектура и подготовка окружения (00:00 – 00:15)
Наша архитектура выглядит так:
`Webhook` → `RisingWave (Source → MView → Sink)` → `Lakekeeper (Catalog) + MinIO (Storage)` ← `Trino (Query)`
Мы используем два `docker-compose` файла:
- Для Lakekeeper и его экосистемы (Postgres, MinIO, Trino): lakekeeper/examples/minimal https://github.com/lakekeeper/lakekeeper/tree/main/examples/minimal .
- Для RisingWave и его окружения Postgres для метаданных, MinIO для состояния, Grafana): risingwave/docker/docker-compose.yml https://github.com/risingwavelabs/risingwave/blob/main/docker/docker-compose.yml .
Ключевое действие: Мы запускаем оба стека, но для RisingWave вносим изменения, чтобы он мог взаимодействовать с Lakekeeper и Trino. Мы объединяем их в одну сеть, добавив в `docker-compose.yml` от RisingWave следующие строки:
# risingwave/docker/docker-compose.yml
services:
risingwave-standalone:
# ...
# Открываем порт для вебхука, по умолчанию он не открыт наружу
.....
--webhook-listen-addr 0.0.0.0:4567 \
.....
ports:
- "4566:4566".
# ... другие порты
- "4567:4567" # <--- Это важно для рабочего webhook
networks:
- trino_network
# ... и для других сервисов, которые должны общаться с внешним стеком ...
networks:
trino_network:
name: minimal_iceberg_net # Имя сети из docker-compose Lakekeeper
external: trueВажный момент: По умолчанию RisingWave не выставляет порт `4567` для вебхуков наружу. Мы добавили его в секцию `ports`, чтобы иметь возможность отправлять `curl` запросы с хост-машины.
Этап 2: Настройка каталогов (00:15 – 00:25)
“Озеро” без каталога — это просто “болото”. Lakekeeper будет нашим каталогом, а Trino — первым, кто научится им пользоваться.
- Создаем динамический каталог в Trino:
CREATE CATALOG risingwave USING iceberg
WITH (
"iceberg.catalog.type" = 'rest',
"iceberg.rest-catalog.uri" = 'http://lakekeeper:8181/catalog',
"iceberg.rest-catalog.warehouse" = 'demo',
"s3.region"= 'dummy',
"s3.path-style-access" = 'true',
"s3.endpoint" = 'http://minio:9000',
"fs.native-s3.enabled" = 'true'
);- Создаем “пустую” таблицу в Trino: Этот шаг создает метаданные в Lakekeeper. RisingWave будет находить эту таблицу и наполнять ее данными.
CREATE TABLE risingwave.trino_namespace.product_view_events (
event_id varchar,
user_id varchar,
event_name varchar,
product_id varchar,
category varchar,
price double,
event_timestamp timestamp(6) with time zone,
raw_data varchar
);Этап 3: Магия RisingWave (00:25 – 00:45) 🚀
Подключаемся к RisingWave через DBeaver (используя порт `4566` и стандартный драйвер PostgreSQL) и начинаем творить магию.
- Создаем источник-вебхук:
CREATE TABLE wbhtable1 (
data JSONB
) WITH (
connector = 'webhook'
) VALIDATE AS secure_compare(
headers->>'authorization',
'TEST_WEBHOOK'
);Эта команда создает эндпоинт, который принимает JSON и кладет его в таблицу `wbhtable1`. `VALIDATE AS` обеспечивает простую, но эффективную аутентификацию.
- Создаем материализованное представление:
CREATE MATERIALIZED VIEW product_view_events AS
SELECT
(data->>'event_id')::VARCHAR AS event_id,
(data->>'user_id')::VARCHAR AS user_id,
(data->>'event_name')::VARCHAR AS event_name,
(data->'properties'->>'product_id')::VARCHAR AS product_id,
(data->'properties'->>'category')::VARCHAR AS category,
(data->'properties'->>'price')::DOUBLE PRECISION AS price,
(data->>'timestamp')::TIMESTAMP WITH TIME ZONE AS event_timestamp,
data::VARCHAR AS raw_data
FROM wbhtable1;Это ядро нашей логики. Мы на лету парсим входящий `JSONB`, приводим типы и создаем структурированное представление `product_view_events`, которое обновляется автоматически.
- Создаем синк (Sink) в Iceberg:
CREATE SINK rest_sink FROM product_view_events
WITH (
connector = 'iceberg',
type = 'upsert',
primary_key = 'event_id',
catalog.type = 'rest',
catalog.uri = 'http://lakekeeper:8181/catalog',
warehouse.path = 'demo',
database.name = 'trino_namespace',
table.name = 'product_view_events',
s3.endpoint = 'http://minio:9000',
s3.path.style.access = 'true',
s3.access.key = 'minio-root-user',
s3.secret.key = 'minio-root-password',
s3.region = 'dummy'
);“Грабли”, которые мы собрали: На пути к этому финальному запросу мы столкнулись с несколькими ошибками, которые стоили нам времени. Вот они, чтобы вы не повторяли наших ошибок:
- `catalog.uri`: Должен указывать на полный путь к REST API каталогу, в случае Lakekeeper это `http://lakekeeper:8181/catalog`.
- `warehouse.path`: Должен содержать логическое имя хранилища (`demo`), а не его физический путь в S3.
- `s3.region`: Критически важный параметр! S3-клиент внутри RisingWave требует его обязательного указания, даже для MinIO. Хотя само значение (`us-east-1` или любое другое) для MinIO не принципиально, его отсутствие приводит к ошибке `region is missing` и сбою записи данных.
Этап 4: Запуск и проверка (00:45 – 01:00)
Время накормить нашу систему данными! Запускаем в терминале скрипт для генерации и отправки 100 событий, а можно и тысячу. Этот скрипт полностью рабочий и готов к копированию:
seq 1 100 | xargs -I {} -P 10 bash -c '
EVENT_ID=$(uuidgen)
USER_ID="usr_$(uuidgen | head -c 8)"
PRODUCT_ID="prod_$(uuidgen | head -c 8)"
TIMESTAMP=$(date -u +"%Y-%m-%dT%H:%M:%SZ")
curl -s -o /dev/null -X POST \
http://localhost:4567/webhook/dev/public/wbhtable1 \
-H "Content-Type: application/json" \
-H "Authorization: TEST_WEBHOOK" \
-d "{
\"event_id\": \"$EVENT_ID\",
\"user_id\": \"$USER_ID\",
\"event_name\": \"product_viewed\",
\"properties\": {
\"product_id\": \"$PRODUCT_ID\",
\"category\": \"electronics\",
\"price\": 9199.99
},
\"timestamp\": \"$TIMESTAMP\"
}"
'И вот он, момент истины. Идем в DBeaver, открываем подключение к Trino и выполняем:
select * from risingwave.trino_namespace.product_view_events;Результат перед вами:
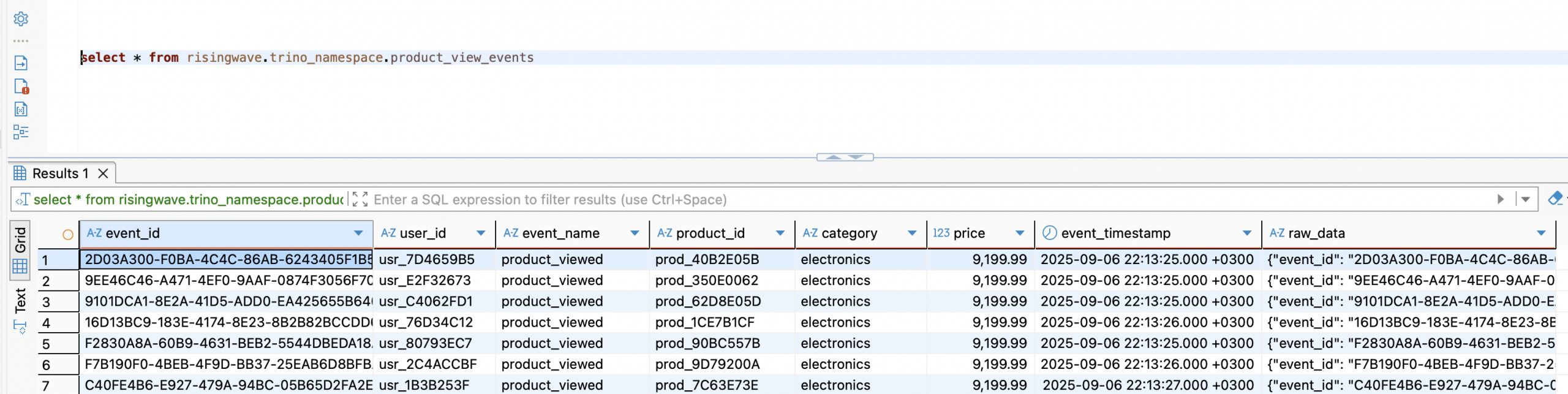
Данные, только что сгенерированные и отправленные по HTTP, уже лежат в озере данных в формате Parquet и доступны для анализа. Ура!
Глава 4: Наблюдаемость: Смотрим на систему под нагрузкой
RisingWave поставляется с готовыми дашбордами для Grafana. Взглянем на них после нашей нагрузки.
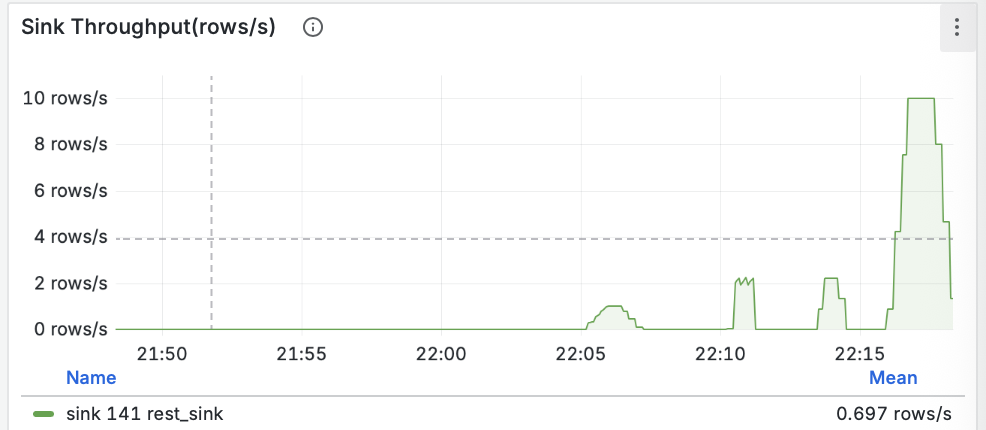
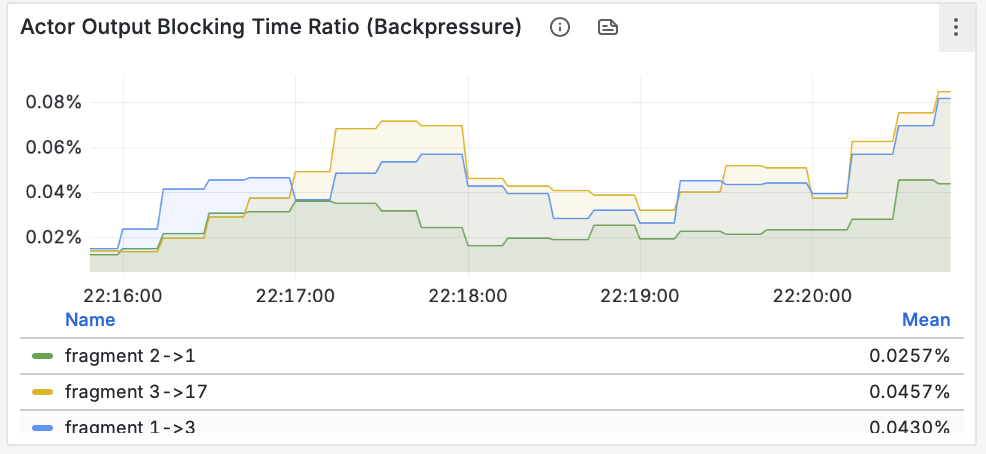
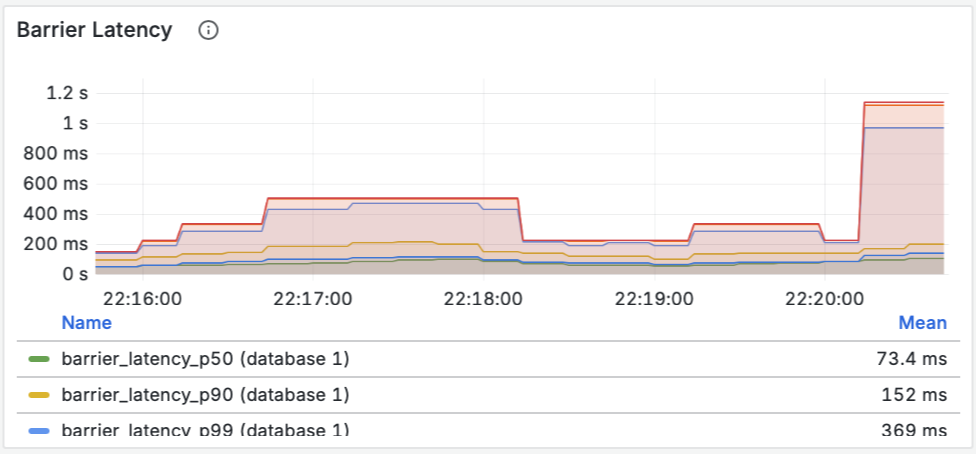
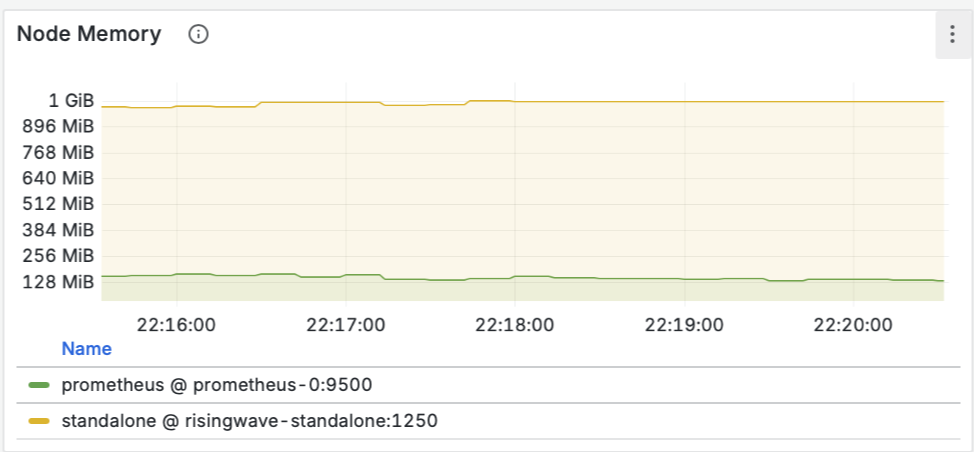
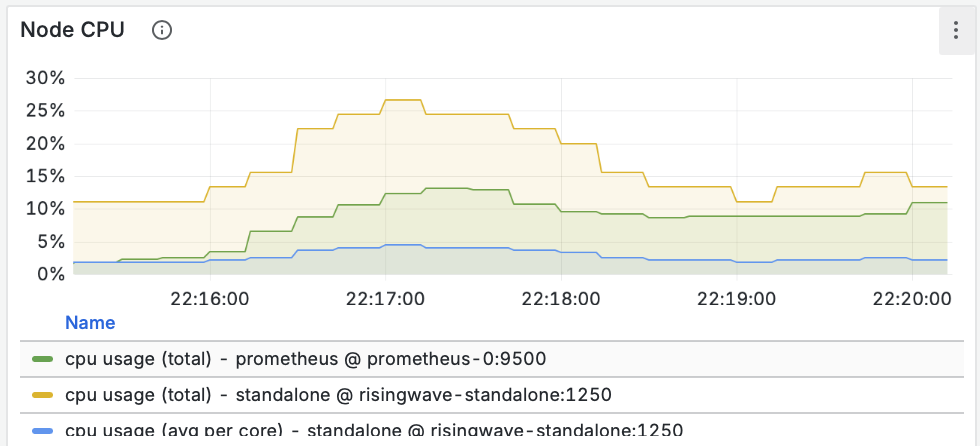
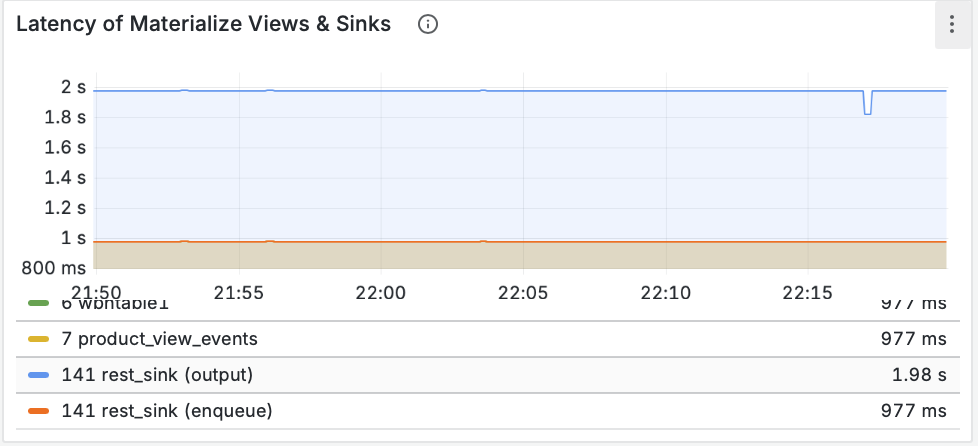
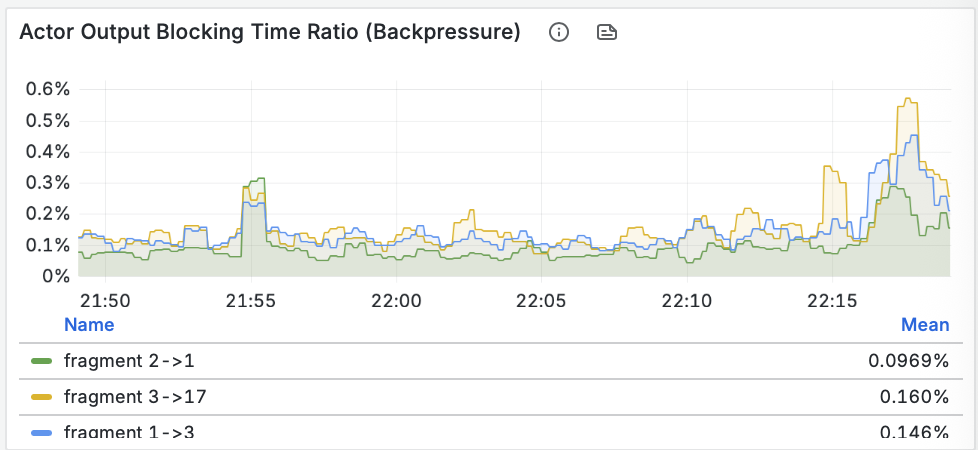
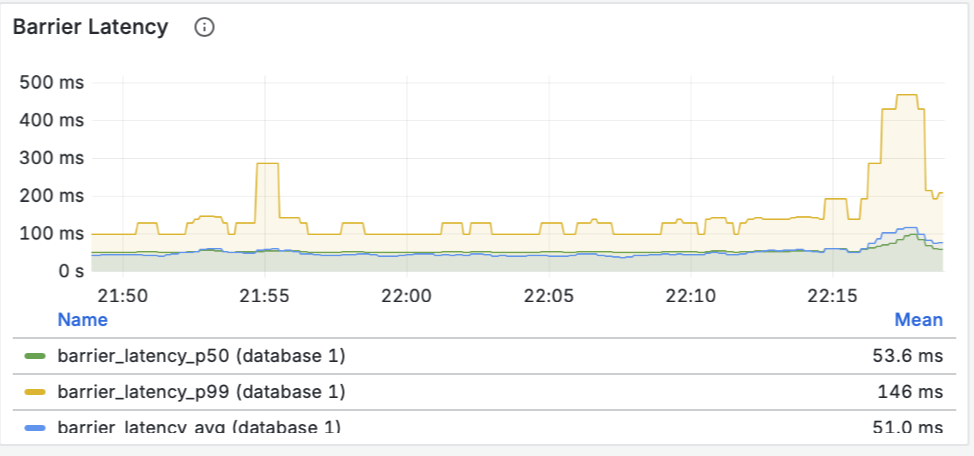
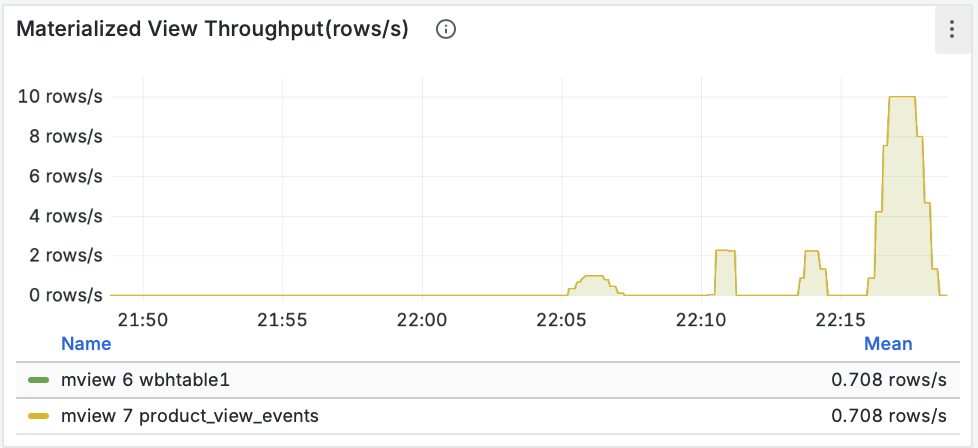
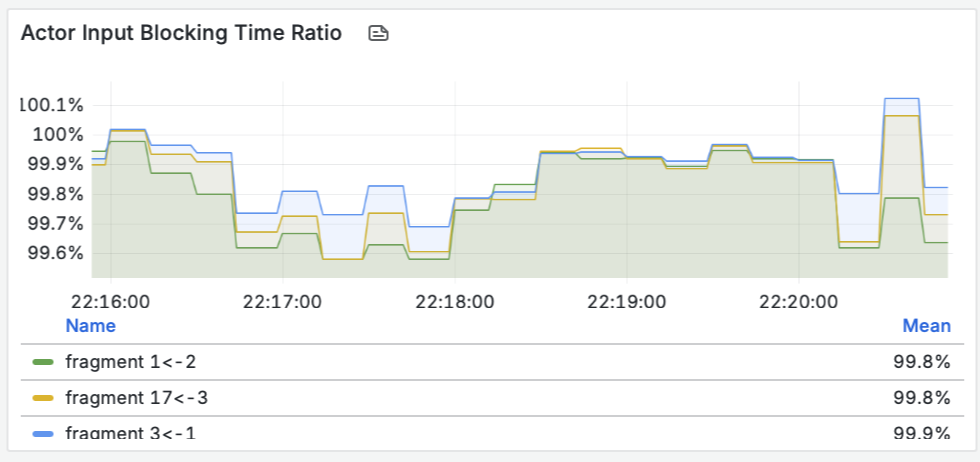
- Пропускная способность (Throughput): Мы видим, как данные проходят через материализованное представление и записываются синком. Пики на графике соответствуют нашей нагрузке.
- Задержка барьеров (Barrier Latency): Это ключевой показатель здоровья потоковой системы. Он показывает время, необходимое для создания контрольной точки (чекпоинта). Значения в десятки миллисекунд говорят о том, что система абсолютно здорова и справляется с нагрузкой без задержек.
- Ресурсы (CPU/Memory): Графики показывают стабильное и предсказуемое потребление ресурсов.
Эти метрики доказывают, что система не просто работает, а работает стабильно и эффективно.
Заключение
Мы сделали это! Меньше чем за час мы развернули и настроили полноценный Streaming Lakehouse. Мы доказали, что современные инструменты, такие как RisingWave, могут кардинально упростить создание сложных систем обработки данных в реальном времени.
Путь от ошибки `Table does not exist` до работающего пайплайна был непростым, но каждая решенная проблема углубляла мое понимание системы. Теперь есть не просто набор инструкций, а проверенный в бою рецепт, учитывающий все “подводные камни”.
Путь к аналитике в реальном времени открыт. Хорошего стриминга и бурного потока с домом у озера, главное что бы избушку не смыло :)
UPD: Проверил еще пару штук
Создаем сурс из Кафки
CREATE SOURCE kafka_src (
action VARCHAR
) WITH (
connector = 'kafka',
topic = 'query_complete',
properties.bootstrap.server = 'broker1:29092'
);создаем синк в другую кафку
CREATE SINK kafka_sink from kafka_src WITH (
connector = 'kafka',
topic = 'query_complete',
properties.bootstrap.server = 'broker2:29092'
) FORMAT PLAIN ENCODE JSONЕще вебхук
CREATE TABLE wbhtable2 (
data JSONB
) WITH (
connector = 'webhook'
) VALIDATE AS secure_compare(
headers->>'authorization',
'TEST_WEBHOOK'
);Делаем материализацию
CREATE MATERIALIZED VIEW events AS
SELECT
(data->>'action')::VARCHAR AS action
FROM wbhtable2;делаем синк из материализации в кафку
CREATE SINK kafka_sink2 FROM events WITH (
connector = 'kafka',
topic = 'query_complete',
properties.bootstrap.server = 'broker2:29092'
) FORMAT PLAIN ENCODE JSON (force_append_only='true');Без материализации сообщения прилетают так: {“data”:“{\”action\“: \”55555\“}”}
А с материализацией: {“action”:“99999”}
Пример запроса
curl -s -o /dev/null -X POST \
http://localhost:4567/webhook/dev/public/wbhtable2 \
-H "Content-Type: application/json" \
-H "Authorization: TEST_WEBHOOK" \
-d "{\"action\": \"11111\"}"Еще про s3 подобные архитектуры: https://gavrilov.info/all/bitva-novyh-arhitektur-sravnivaem-arc-gigapi-i-ducklake/
Ошибки в версии 2.4 – какая то пакость была, но поставил 2.6.1 и все заработало
-- 0. устанавливаем последнюю версию risingwave ( 2.6.1 )
-- 1 Создаем вебхук
CREATE TABLE wbhtable5 (
data JSONB
) WITH (
connector = 'webhook'
) VALIDATE AS secure_compare(
headers->>'authorization',
'TEST_WEBHOOK'
);
-- 2 Создаем материализацию
CREATE MATERIALIZED VIEW product_view_events5 AS
SELECT
(data->>'event_id')::VARCHAR AS event_id,
(data->>'user_id')::VARCHAR AS user_id,
(data->>'event_name')::VARCHAR AS event_name,
(data->'properties'->>'product_id')::VARCHAR AS product_id,
(data->'properties'->>'category')::VARCHAR AS category,
(data->'properties'->>'price')::DOUBLE PRECISION AS price,
(data->>'timestamp')::TIMESTAMP WITH TIME ZONE AS event_timestamp,
data::VARCHAR AS raw_data
FROM wbhtable5;
-- 3 создаем подключение к iceberg
CREATE CONNECTION my_iceberg_conn5 WITH (
type = 'iceberg',
warehouse.path = 'risi', -- s3://my-bucket/warehouse/
-- database.name = 'risi_space', оказалось не нужна
s3.region = 'dummy',
s3.access.key = 'ЧЧЧ', -- Ваши ключи
s3.secret.key = 'ЧЧЧ', -- Ваши ключи
catalog.type = 'rest',
s3.endpoint = 'https://gateway.storjshare.io',
s3.path.style.access = 'true',
-- ИСПОЛЬЗУЕМ ИМЯ СЕРВИСА И ЕГО ВНУТРЕННИЙ ПОРТ!
catalog.uri = 'http://lakekeeper:8181/catalog'
)
-- 4 Устанавливаем его по умолчанию
SET iceberg_engine_connection = 'public.my_iceberg_conn5';
-- Создаем таблицу ( обязательно с ключами )
CREATE TABLE public.my_iceberg_table5 (
event_id VARCHAR PRIMARY KEY,
user_id varchar,
event_name varchar,
product_id varchar,
category varchar,
price double,
event_timestamp Timestamptz,
raw_data varchar
) ENGINE = iceberg;
-- 5 создаем синк
CREATE SINK to_sales_events5 INTO my_iceberg_table5 AS
SELECT * FROM product_view_events5;
--- Тут можно curl запустить
seq 1 10 | xargs -I {} -P 10 bash -c '
EVENT_ID=$(uuidgen)
USER_ID="usr_$(uuidgen | head -c 8)"
PRODUCT_ID="prod_$(uuidgen | head -c 8)"
TIMESTAMP=$(date -u +"%Y-%m-%dT%H:%M:%SZ")
curl -s -o /dev/null -X POST \
http://localhost:4567/webhook/dev/public/wbhtable5 \
-H "Content-Type: application/json" \
-H "Authorization: TEST_WEBHOOK" \
-d "{
\"event_id\": \"$EVENT_ID\",
\"user_id\": \"$USER_ID\",
\"event_name\": \"product_viewed\",
\"properties\": {
\"product_id\": \"$PRODUCT_ID\",
\"category\": \"electronics\",
\"price\": 9199.99
},
\"timestamp\": \"$TIMESTAMP\"
}"
'
-- 6 проверяем
SELECT * FROM product_view_events5;
-- 7 проверяем ( появляются не сразу )
select * from my_iceberg_table5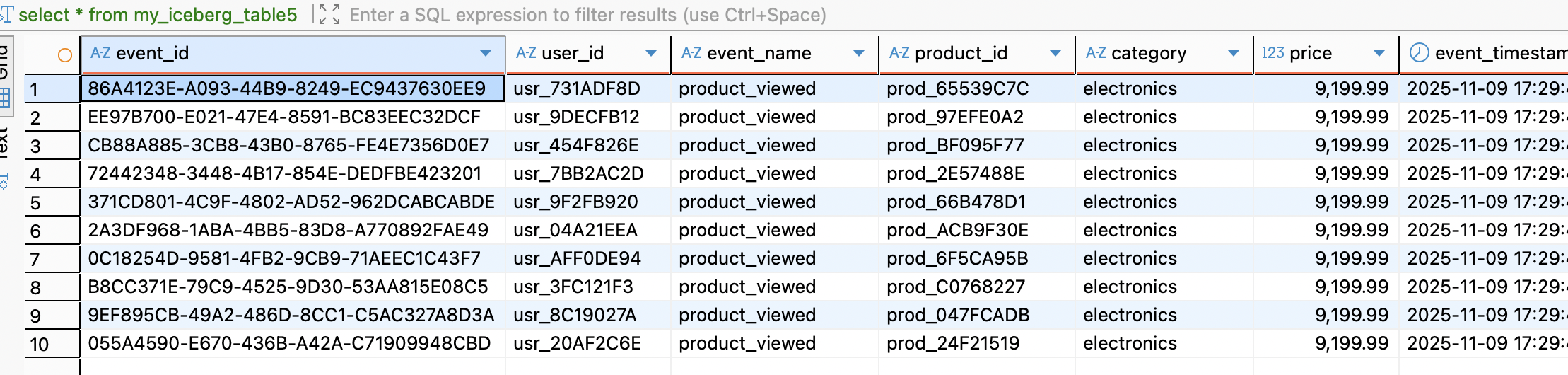
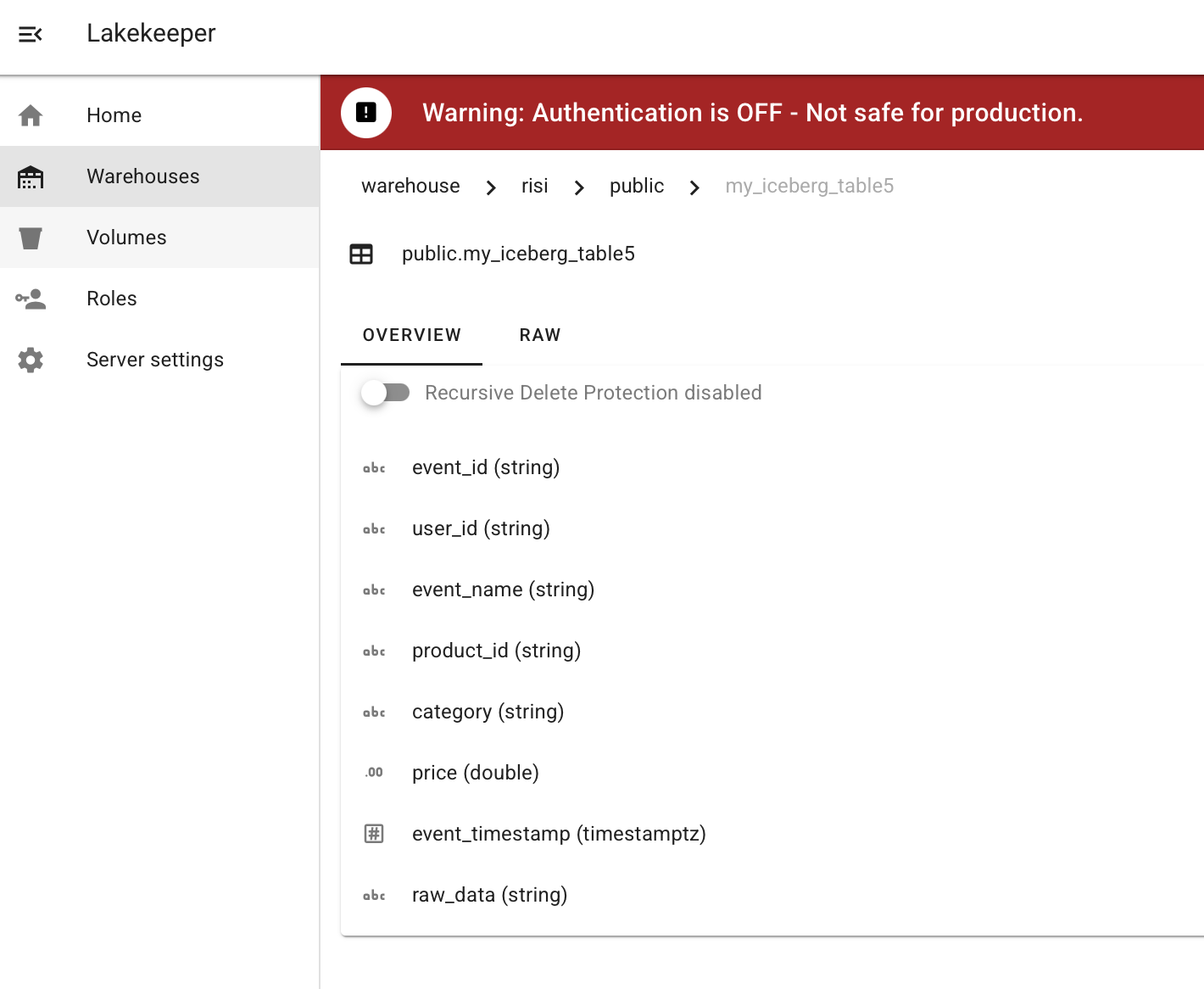
И в keeper она есть

И на S3
