Мой фреймворк управления данными (Статья)
Оригинал: https://medium.com/zs-associates/my-data-governance-framework-c1879486bc09
За последние 10+ лет у меня была возможность быть автором или внести вклад в более чем 100 стратегий и фреймворков управления данными в различных отраслях. Хотя у каждой организации есть свои уникальные вызовы, я обнаружил, что определенный общий фреймворк неизменно служил эффективной отправной точкой для внедрения управления данными.
Установление четкого фреймворка на раннем этапе имеет решающее значение. Оно проясняет, что такое управление данными и чем оно не является, помогая избежать путаницы, задать ожидания и стимулировать внедрение. Хорошо структурированный фреймворк предоставляет простое, повторяемое визуальное представление, которое вы можете использовать снова и снова, чтобы объяснить управление данными и то, как вы планируете внедрить его во всей организации.
В этой статье я разберу пять основных компонентов моего личного фреймворка, предоставив практический подход, который может работать для любой организации, в любом секторе.
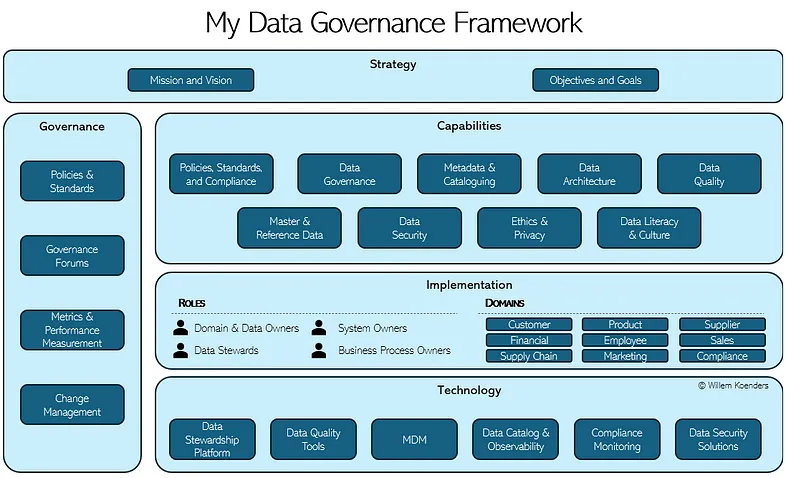

Стратегия
Четко определенная стратегия является основой любой успешной инициативы по управлению данными. Она устанавливает цель, направление и приоритеты усилий по управлению, обеспечивая соответствие бизнес-целям. Без четкой стратегии усилия по управлению данными станут фрагментированными и реактивными.
- Миссия, видение и общая стратегия.** Этот подкомпонент определяет, почему необходимо управление данными, чего оно стремится достичь и как оно будет реализовано. Миссия формулирует основную цель управления, такую как обеспечение целостности данных, соответствие требованиям и создание ценности. Видение обеспечивает долгосрочную перспективу, описывая желаемое состояние управления данными внутри организации. Общая стратегия определяет подход и руководящие принципы для внедрения управления в бизнес-операции.
- Задачи и цели.** Чтобы добиться значимых результатов, управление данными должно быть связано с измеримыми целями. Это включает в себя установление конкретных, количественно определяемых целей, таких как улучшение показателей качества данных на определенный процент, снижение рисков соответствия требованиям или увеличение внедрения метаданных. Четкие цели обеспечивают подотчетность и позволяют организациям отслеживать прогресс, демонстрировать ценность и постоянно совершенствовать свои усилия по управлению.

Области компетенции
Для эффективного внедрения управления данными организации должны разработать набор основных областей компетенции, которые касаются политик, процессов и структур, необходимых для управления данными. Эти области компетенции служат строительными блоками управления, обеспечивая охват всех критических аспектов – от качества данных до безопасности. Четко определенный набор компетенций гарантирует, что усилия по управлению являются взаимоисключающими и коллективно исчерпывающими (MECE), избегая пробелов или избыточности.
- Политики, стандарты и соответствие требованиям.** Управление начинается с четко определенных политик и стандартов, которые устанавливают правила, руководящие принципы и требования соответствия для управления данными во всей организации. Политики определяют, что необходимо сделать, устанавливая ожидания в отношении таких тем, как доступ к данным, качество и защита, а стандарты определяют, как эти ожидания реализуются с помощью конкретных процедур или пороговых значений. Важно отметить, что управление должно также включать возможность подтверждения соответствия этим политикам и стандартам посредством механизмов мониторинга, отчетности и аудита, обеспечивая подотчетность и соответствие нормативным требованиям.
- Управление данными.** Может показаться немного странным иметь «управление данными» в качестве компетенции в рамках управления данными, но оно служит уникальной и основополагающей цели. Эта компетенция определяет и реализует роли, обязанности и подотчетность во всей модели управления. Она обеспечивает организационную основу, которая поддерживает все другие компетенции, разъясняя, кто отвечает за принятие каких решений и деятельность, как назначается право собственности и как координируется деятельность по управлению между бизнесом и ИТ. Это включает в себя определение владельцев данных, распорядителей, руководителей доменов, путей эскалации и форумов по управлению.
- Метаданные и каталогизация.** Метаданные – данные о данных – необходимы для понимания, организации и управления информационными активами. Эта компетенция сочетает в себе управление метаданными с инструментами каталогизации и обнаружения данных для предоставления централизованного инвентаря активов данных, включая бизнес-определения, технические метаданные и происхождение данных. Управление метаданными также включает в себя определение минимальных стандартов метаданных, установление того, какие метаданные необходимо собирать и поддерживать, и где. Каталог данных строится на этой основе, делая метаданные доступными для поиска и доступными, позволяя пользователям находить, понимать и доверять данным, с которыми они работают. Это способствует прозрачности и демократизации данных, позволяя большему количеству пользователей в организации получать доступ к необходимым им данным.
- Архитектура данных.** Эта статья посвящена фреймворку управления данными, а не архитектуре предприятия или фреймворку архитектуры решений. Таким образом, роль архитектуры данных здесь конкретно ограничена теми аспектами, которые пересекаются с управлением данными. Сюда входит обеспечение того, чтобы посредством программ изменений, процессов проектирования решений и механизмов архитектурного управления правильные средства контроля и соображения по управлению данными были встроены на раннем этапе жизненного цикла новых систем, потоков данных и процессов. Это соответствие имеет решающее значение, поскольку отдача от инвестиций в управление данными значительно выше, когда оно внедряется на этапе проектирования, а не когда средства контроля управления ретроспективно устанавливаются после создания и развертывания систем. Таким образом, архитектура данных становится фактором, способствующим устойчивому управлению данными в масштабах предприятия в соответствии с политикой.
- Управление качеством данных.** Высококачественные данные являются основой надежной аналитики, искусственного интеллекта, нормативной отчетности и повседневных бизнес-операций. Эта компетенция охватывает ряд действий, которые обеспечивают соответствие данных цели, и ее обычно можно разбить на несколько различных областей. Во-первых, она начинается с понимания данных и формулирования четких бизнес-требований – какие данные необходимы, на каком уровне точности, своевременности или полноты и для какой цели. После установления этих требований организации могут обеспечить, чтобы правильные средства контроля качества данных были встроены в операционные процессы для предотвращения проблем в источнике (например, правила проверки в формах или автоматические проверки в каналах данных). Отдельная, но тесно связанная компетенция фокусируется на измерении самого качества данных, используя определенные метрики и методы профилирования для оценки данных по отношению к бизнес-требованиям. Кроме того, компетенция качества данных может включать в себя управление проблемами: структурированный процесс для выявления, документирования, отслеживания и устранения проблем с данными. Это позволяет организациям не только реагировать на проблемы с данными, но и анализировать основные причины и внедрять долгосрочные улучшения, обеспечивая надежность данных с течением времени.
- Мастер-данные и справочные данные.** Управление мастер-данными и справочными данными управляет основными бизнес-сущностями данных (например, клиентами, продуктами, поставщиками), чтобы устранить дублирование, повысить согласованность и обеспечить единый источник истины. Во многих организациях эта компетенция поддерживается платформой управления мастер-данными (MDM). Платформа MDM обеспечивает централизованные рабочие процессы, создание золотой записи, сопоставление данных и синхронизацию между системами. Она играет решающую роль в обеспечении согласованности, целостности и точности данных, особенно для общекорпоративной отчетности и обработки транзакций.
- Безопасность данных.** Безопасность данных обеспечивает защиту конфиденциальных, критически важных и регулируемых данных от несанкционированного доступа, неправильного использования или раскрытия в соответствии с политиками управления и схемами классификации данных. Это включает в себя внедрение и мониторинг контроля доступа на основе ролей, шифрование, токенизацию, маскирование, протоколы безопасной передачи данных и разделение обязанностей. Эффективное управление безопасностью данных также гарантирует, что меры безопасности соответствуют утвержденным политикам использования данных и регулярно тестируются и подтверждаются посредством проверок соответствия требованиям и оценок рисков.
- Этика и конфиденциальность.** Технически, эту область можно интерпретировать как подпадающую под действие “Политики, стандарты и соответствие требованиям”, поскольку многие этические требования и требования конфиденциальности в конечном итоге регулируются посредством формальной политики. Однако часто стоит выделять их отдельно из-за их растущей актуальности и заметности – особенно с ростом искусственного интеллекта, алгоритмического принятия решений и усилением нормативного контроля. Эта компетенция фокусируется на обеспечении ответственного, справедливого и прозрачного использования данных путем определения этических принципов, практик конфиденциальности, процессов управления согласием и стратегий защиты персональных данных. Учитывая, насколько централизованными стали доверие и подотчетность в организациях, движимых данными, рассмотрение этики и конфиденциальности как отдельных компетенций помогает обеспечить, чтобы она получала необходимую видимость, право собственности и ресурсы.
- Грамотность в области данных и культура.** Управление – это не только контроль, или не должно быть. Речь также идет о том, чтобы предоставить людям возможность эффективно и ответственно использовать данные. Эта компетенция способствует повышению грамотности в области данных, снабжая бизнес-пользователей и технических пользователей обучением, знаниями и инструментами, необходимыми им для интерпретации, доверия и действий на основе данных. Она включает в себя информационные кампании, образовательные ресурсы, передовые методы и поддержку самообслуживания для развития культуры, основанной на данных, во всей организации.
Адаптация фреймворка
Области компетенции, описанные выше, оказались хорошей отправной точкой в каждом проекте, в котором я участвовал. Но у каждой организации есть свой собственный контекст, операционная модель, приоритеты и история, и в результате я часто трачу значительное время с клиентскими организациями на доработку этого списка, чтобы он наилучшим образом соответствовал их уникальной ситуации. Ниже приведены некоторые из наиболее распространенных аспектов, по которым адаптируется модель компетенции:
- Безопасность данных и архитектура данных** иногда явно не выделяются как часть фреймворка компетенции управления данными. Во многих организациях они рассматриваются как ответственность ИТ-функции или функции технологий, и предполагается, что соображения управления встроены в более широкие процессы архитектурного управления и управления безопасностью.
- Грамотность в области данных** иногда переименовывается или перефразируется, называя ее управлением изменениями, расширением возможностей данных, пропагандой данных или продвижением данных. Во всех случаях основная цель, которая заключается в расширении возможностей пользователей и развитии культуры, основанной на данных, остается очень похожей.
- Этика и конфиденциальность** иногда полностью встроены в более широкую компетенцию “Политики, стандарты и соответствие требованиям”, особенно когда этические принципы и принципы конфиденциальности уже формально кодифицированы посредством политических инструментов. В этих случаях основное внимание уделяется пониманию соответствующих нормативных требований (например, GDPR, HIPAA или законов, связанных с искусственным интеллектом), преобразованию их в действенные политики и стандарты, а затем обеспечению соответствия посредством структур управления, обучения и механизмов надзора.
- Некоторые организации проявляют интерес к выделению возможности искусственного интеллекта или аналитики в качестве отдельной компетенции или управлению ими (“Управление искусственным интеллектом”). Лично я считаю, что большая часть того, что требуется для обеспечения надежной аналитики и искусственного интеллекта, может и должна обрабатываться с помощью существующих компетенций. Тем не менее, небольшое число организаций, с которыми я работал, предпочли рассматривать это как отдельную компетенцию, особенно когда управление моделями искусственного интеллекта/машинного обучения является текущим приоритетом.

Реализация (внедрение и исполнение)
В то время как стратегия и области компетенции управления данными в основном универсальны, реализация управления может значительно варьироваться между организациями, отраслями и нормативной средой. Этот компонент фокусируется на том, как управление структурировано, встроено и введено в действие в организации. Речь идет о том, как вы “делаете” управление – как вы стимулируете исполнение на местах.
Эта часть фреймворка в некоторой степени уникальна для моего личного взгляда на управление данными. В то время как большинство организаций определяют управление через список компетенций или столпов, они не доходят до интеграции того, как управление фактически реализуется. Я намеренно включаю его как часть основного фреймворка, потому что я считаю, что без четкого пути к исполнению и внедрению управление рискует остаться теоретическим. Встраивание реализации непосредственно во фреймворк усиливает то, что управление должно быть действенным, прожитым и встроенным в повседневные операции, а не просто набором добрых намерений.
То, как вы думаете о реализации, может варьироваться, но я обычно выделяю два основных компонента: роли и домены. Определение ролей (таких как владельцы данных или распорядители) помогает прояснить, кто за что несет ответственность, и обеспечивает согласованность во всей организации. Определение доменов (таких как данные о клиентах, продуктах или финансах) помогает структурировать управление вокруг логических бизнес-группировок. Вместе эти компоненты обеспечивают подход к управлению данными, ориентированный на домен, а это означает встраивание обязанностей по управлению в бизнес-области, которые лучше всего знают данные, и выполнение управления в контексте, а не изолированно.
- Основные роли и обязанности**
Право собственности и подотчетность могут быть разъяснены с помощью определенного набора ролей. Хотя в управлении данными участвует много ролей, приведенные ниже представляют собой некоторые из наиболее важных ролей, которые обычно повторяются в разных доменах данных:
- Владельцы доменов.** Несут ответственность за надзор за управлением в пределах определенного бизнес-домена, такого как данные о клиентах, финансы или продукты. Они помогают расставлять приоритеты в усилиях, обеспечивают соответствие бизнес-целям и несут ответственность за успех управления в своем домене.
- Владельцы данных.** Несут ответственность за качество, безопасность и жизненный цикл конкретных данных (или наборов данных). Они принимают решения об использовании данных, доступе к ним и критических требованиях к управлению.
- Распорядители данных.** Обычно работают от имени владельцев данных или доменов, выполняя большую часть повседневной работы, связанной с управлением данными. Это включает в себя обеспечение соблюдения стандартов, ведение метаданных, поддержку инициатив по качеству данных и координацию решения проблем.
- Владельцы систем.** Несут ответственность за технические системы и платформы, где данные хранятся, обрабатываются или передаются. Они обеспечивают, чтобы требования к управлению были встроены в архитектуру, средства контроля и уровни доступа этих систем.
- Владельцы бизнес-процессов.** Обеспечивают интеграцию политик управления и стандартов данных в бизнес-процессы, которые собирают, создают или изменяют данные. Они помогают встроить управление в операционные рабочие процессы и проектирование процессов.
- Домены данных**
Управление может применяться в значимых бизнес-контекстах, известных как домены данных. Эти домены определяют логические группировки данных на основе того, как они используются в организации. Хотя конкретные домены будут различаться в зависимости от отрасли (следовательно, эта часть фреймворка обязательно является пользовательской), следующие примеры иллюстрируют, как розничная компания может структурировать свои домены данных:
- Клиент** – Информация о физических или юридических лицах, которые покупают или используют ваши продукты или услуги.
- Продукт** – Информация о предлагаемых товарах или услугах, в том числе структура, цены и описания.
- Поставщик** – Информация о поставщиках, их контрактах и результатах их деятельности.
- Финансовый** – Записи о доходах, расходах, бюджетах и других финансовых транзакциях.
- Сотрудник** – Информация о персонале, в том числе роли, вознаграждение и история отдела кадров.
- Продажи** – Данные о покупках, транзакциях и деятельности, приносящей доход.
- Запасы и цепочка поставок** – Отслеживает уровни запасов, перемещение товаров и процессы доставки.
- Маркетинг и кампании** – Захватывает кампании, расходы на рекламу и стратегии таргетинга.
- Соответствие требованиям и нормативным требованиям** – Данные, используемые для выполнения юридических, аудиторских и нормативных обязательств.
- Цифровая и веб-аналитика** – Измеряет, как пользователи взаимодействуют с цифровыми платформами и веб-сайтами.

Технологическое обеспечение
Технологии играют решающую роль в том, чтобы сделать управление данными практичным и масштабируемым. Хотя эти технологии соответствуют ключевым областям компетенции управления данными, они не сопоставляются 1:1, поскольку многие компетенции поддерживаются более широкими технологическими стеками или интегрированными решениями. Кроме того, то, как организации структурируют и развертывают эти технологии, может значительно варьироваться в зависимости от их размера, отрасли и зрелости данных.
Тем не менее, в большинстве случаев технологии, связанные с управлением данными, можно сгруппировать по следующим ключевым категориям.
- Платформа управления данными.** Эти платформы позволяют организациям определять и управлять правом собственности на данные, обязанностями по управлению, рабочими процессами и утверждениями, а также облегчают операции управления, такие как ведение журналов проблем, запросы на изменение данных и подтверждение. Все чаще они также поддерживают управление проблемами на основе рабочих процессов, позволяя организациям назначать, отслеживать и решать проблемы управления данными между командами. Эти инструменты служат основой для того, чтобы сделать управление действенным и видимым в разных доменах.
- Примеры: Collibra, Informatica Axon, Alation Stewardship Workbench
- Качество данных.** Обеспечение высокого качества данных требует специализированных инструментов мониторинга, профилирования, очистки и исправления. Эти решения выявляют несоответствия, отсутствующие значения и ошибки, позволяя командам исправлять проблемы с данными в режиме реального времени и обеспечивать соблюдение стандартов качества данных в разных системах.
- Примеры: Informatica Data Quality, Talend, Ataccama ONE
- Каталог данных и наблюдаемость.** Каталоги данных предоставляют центральный инвентарь активов данных, объединяя метаданные, происхождение и бизнес-определения для повышения обнаружения и прозрачности данных. Все чаще каталоги объединяются с инструментами наблюдаемости данных для мониторинга работоспособности, свежести и поведения данных в режиме реального времени. Некоторые инструменты также предлагают автоматическое сканирование и классификацию данных по всему ландшафту данных.
- Примеры: Alation, Collibra, BigID
- Управление мастер-данными.** Платформы MDM необходимы для управления основными бизнес-сущностями, такими как клиенты, продукты и поставщики. Эти инструменты поддерживают сопоставление данных, создание золотой записи, рабочие процессы проверки и синхронизацию мастер-данных в разных системах. Они являются ключом к обеспечению согласованности в масштабах предприятия, удалению дубликатов и единому источнику истины для ключевых доменов данных.
- Примеры: Informatica MDM, Reltio
- Решения для обеспечения безопасности данных.** Эта категория включает в себя инструменты, которые управляют контролем доступа, шифрованием, маскированием, токенизацией и безопасной передачей данных. Она также поддерживает рабочие процессы запросов на доступ к данным, гарантируя, что только авторизованные пользователи могут получить доступ к конфиденциальным или классифицированным данным на основе политик управления и классификации данных.
- Примеры: Immuta, Privacera, Microsoft Purview Data Security
- Мониторинг этики, конфиденциальности и соответствия требованиям.** Эти инструменты поддерживают обеспечение соблюдения и мониторинг этичного использования данных, правил конфиденциальности (например, GDPR, HIPAA) и внутренних политик. Они предоставляют возможности для управления правами субъектов данных, отслеживания согласия, контрольных журналов и мониторинга использования, которые имеют решающее значение для укрепления доверия и выполнения нормативных обязательств.
- Примеры: BigID, OneTrust, Collibra Protect
При создании этой части фреймворка вы можете заменить общие категории фактическими инструментами и платформами, которые вы используете, например, перечислив Collibra вместо “платформы управления данными” или Informatica Data Quality вместо “инструментов качества данных”. Это обеспечивает более ощутимое, специфичное для организации представление о том, как конкретные технологии обеспечивают ключевые возможности.

Управление управлением данными
Чтобы управление данными работало, ему необходима четкая координация, постоянный надзор и устойчивый прогресс. Именно этим и занимается управление управлением данными – обеспечение того, чтобы остальная часть фреймворка действительно была реализована. Это придает структуру тому, как все части работают вместе, и привлекает людей к ответственности.
- Политики и стандарты**
Политики и стандарты являются основой управления данными. Они определяют правила, ожидания и обязанности, как правила дорожного движения на дороге. Все остальное во фреймворке указывает на них. Политики задают направление, а стандарты воплощают его в жизнь:
- Политика** говорит, что необходимо сделать. Это четкое правило, например, “данные о клиентах должны быть защищены”.
- Стандарт** говорит, как это сделать. Он дает подробности, например, “зашифруйте данные о клиентах и храните их в течение 3 лет”.
- Форумы управления**
Форумы управления обеспечивают необходимый надзор, координацию и структуры принятия решений для управления данными. Хотя конкретные форумы зависят от структуры организации и потребностей в управлении, к распространенным типам относятся:
- Совет по управлению корпоративными данными.** Центральный орган, который устанавливает стратегическое направление, решает межфункциональные вопросы и обеспечивает соответствие управления бизнес-целям.
- Форумы управления данными, ориентированные на домен.** Группы, которые осуществляют надзор за управлением в пределах конкретных доменов данных (например, клиенты, финансы, продукты), обеспечивая реализацию политик на уровне домена и эскалируя критические вопросы на корпоративный уровень.
- Региональные форумы управления или форумы управления бизнес-подразделением.** В глобальных или децентрализованных организациях управление данными может быть структурировано по региональному, бизнес-подразделению или дивизионному признаку для учета местных требований, нормативных различий и операционных потребностей.
- Рабочие группы, ориентированные на конкретные компетенции.** Некоторые организации учреждают группы управления, ориентированные на конкретные компетенции, такие как качество данных, управление метаданными, безопасность данных или этика данных, для продвижения передовых методов и технической реализации.
- Метрики и измерение производительности**
Чтобы продемонстрировать эффективность и влияние управления данными, организации должны отслеживать ключевые показатели эффективности (KPI), такие как показатели качества данных, показатели соблюдения политик, время решения проблем управления и внедрение метаданных. Эти метрики помогают обосновать инвестиции, выявить пробелы и стимулировать постоянное совершенствование.
- Управление изменениями**
Чтобы управление было по-настоящему встроено, вы можете повышать осведомленность, внедрять и изменять поведение, например, с помощью программ обучения, коммуникационных стратегий и инициатив по вовлечению.
Заключение

Надежный фреймворк управления данными обеспечивает ясность, структуру и повторяемый, масштабируемый подход к управлению данными. Хотя путь управления каждой компании уникален, фреймворк, представленный в этой статье, служит проверенной отправной точкой – той, которая может быть адаптирована в соответствии с любой отраслью, любой организацией и любым уровнем зрелости данных.