
Apache SeaTunnel – Движение к мультимодальной интеграции данных
Новое позиционирование Apache SeaTunnel. Движение к унифицированному инструменту для мультимодальной интеграции данных
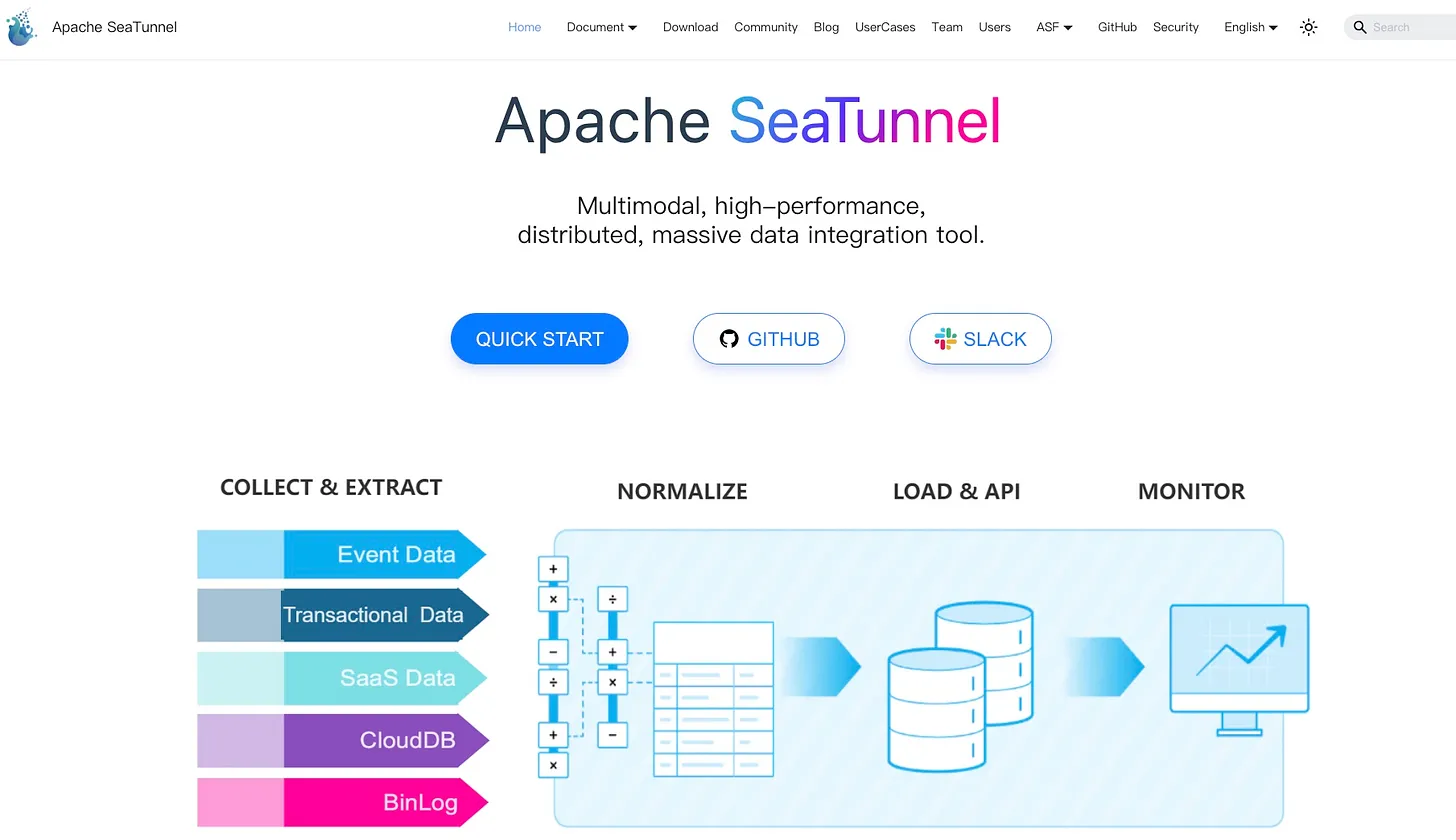
Введение
В постоянно меняющемся мире больших данных эффективная и надежная интеграция данных является ключевым фактором для успеха любого предприятия. Apache SeaTunnel (ранее известный как Waterdrop) зарекомендовал себя как мощный инструмент для синхронизации данных. Однако с развитием технологий и появлением новых вызовов, таких как интеграция разнородных типов данных (структурированных, полуструктурированных и неструктурированных), проект пересматривает свое позиционирование. Цель — превратиться из простого инструмента синхронизации в комплексную, унифицированную платформу для мультимодальной интеграции данных.
Проблемы предыдущей архитектуры
Изначально Apache SeaTunnel был разработан как плагин, работающий поверх вычислительных движков, таких как Apache Spark и Apache Flink. Такой подход имел свои преимущества, позволяя использовать мощность этих движков, но также порождал ряд проблем:
- Зависимость от сторонних движков: Для выполнения даже самых простых задач по пересылке данных требовалось развертывание и поддержка тяжеловесных кластеров Spark или Flink. Это увеличивало накладные расходы, усложняло настройку и повышало порог входа для новых пользователей.
- Сложность конфигурации: Пользователям приходилось разбираться не только в конфигурации самого SeaTunnel, но и в настройках Spark/Flink, что часто приводило к так называемому “конфигурационному аду”.
- Ограничения коннекторов: Разработка коннекторов была тесно связана с API Spark и Flink, что затрудняло создание универсальных коннекторов, работающих в обеих средах без изменений.
- Низкая производительность для простых задач: Использование мощных, но громоздких движков для элементарных задач ETL (Extract, Transform, Load) было избыточным и неэффективным с точки зрения ресурсов и времени запуска.
Новое видение: унифицированная платформа с собственным движком
Чтобы решить эти проблемы и соответствовать современным требованиям, сообщество Apache SeaTunnel представило новую архитектуру, в основе которой лежит собственный вычислительный движок — SeaTunnel Engine.
Этот стратегический шаг позволил отделить SeaTunnel от обязательной зависимости от Spark и Flink. Теперь SeaTunnel может работать в самостоятельном режиме, что обеспечивает следующие ключевые преимущества:
- Легковесность и быстрота: `SeaTunnel Engine` специально оптимизирован для задач интеграции данных. Он запускается быстрее и потребляет значительно меньше ресурсов, чем полноценные кластеры Spark или Flink, что делает его идеальным для широкого круга задач.
- Унификация пакетной и потоковой обработки: Новая архитектура изначально спроектирована для бесшовной работы как с пакетными (batch), так и с потоковыми (streaming) данными. Пользователям больше не нужно поддерживать два разных стека для разных типов задач — SeaTunnel предоставляет единый интерфейс и модель выполнения.
- Упрощенная разработка коннекторов: С введением унифицированного API коннекторов (`Connector API`), разработчикам стало проще создавать новые интеграции. Коннектор, написанный для `SeaTunnel Engine`, будет работать одинаково для всех сценариев, что ускоряет расширение экосистемы.
Мультимодальная интеграция данных
Ключевой аспект нового позиционирования — это поддержка мультимодальных данных. Это означает способность работать с данными различных форматов и из различных источников в рамках единого конвейера.
- Структурированные данные: Традиционная область для SeaTunnel. Поддерживается множество реляционных баз данных (MySQL, PostgreSQL), аналитических СУБД (ClickHouse, Doris) и хранилищ данных.
- Полуструктурированные данные: Эффективная работа с NoSQL базами данных (MongoDB, Elasticsearch) и потоками событий (Kafka, Pulsar).
- Неструктурированные данные: Расширение поддержки для озер данных (Data Lakes) и файловых систем (HDFS, S3, OSS). Это включает интеграцию с форматами вроде Apache Hudi, Iceberg и Delta Lake.
Особое внимание уделяется критически важным функциям, таким как Захват изменяемых данных (CDC) и синхронизация всей базы данных целиком. SeaTunnel теперь может считывать журналы транзакций (например, binlog в MySQL) для захвата изменений в реальном времени и применять их к целевой системе. Функция полной синхронизации позволяет в одной задаче перенести схему и все данные из одной базы в другую, что значительно упрощает миграцию.
Будущее развитие
Дорожная карта проекта включает в себя:
- Расширение экосистемы коннекторов: Добавление поддержки еще большего числа источников и приемников, включая современные SaaS-платформы и векторные базы данных для задач ИИ.
- Улучшенная поддержка озер данных: Углубление интеграции с форматами Hudi и Iceberg, поддержка эволюции схем и транзакционных операций.
- Пользовательский интерфейс: Разработка визуального интерфейса для создания и мониторинга заданий, что сделает инструмент более доступным для широкого круга пользователей.
- Повышение производительности и стабильности: Непрерывная оптимизация `SeaTunnel Engine` для еще более быстрой и надежной обработки данных.
Заключение
Apache SeaTunnel совершает важный переход от зависимого инструмента к самостоятельной, легковесной и унифицированной платформе для интеграции данных. Отказ от обязательной привязки к Spark/Flink и внедрение собственного `SeaTunnel Engine` открывают новые возможности для пользователей, которым нужно простое, но мощное решение для пакетной и потоковой обработки разнородных данных. Новое позиционирование делает SeaTunnel сильным конкурентом в мире современных ETL/ELT инструментов.
---
Выводы
Проанализировав направление развитие Apache SeaTunnel, можно сделать несколько ключевых выводов:
- Стратегическая зрелость: Переход на собственный движок (`SeaTunnel Engine`) — это признак зрелости проекта. Команда осознала, что зависимость от универсальных, но тяжеловесных движков (Spark/Flink) является узким местом для основного сценария использования — интеграции данных. Создание специализированного движка позволяет оптимизировать производительность и снизить накладные расходы именно для этих задач.
- Соответствие трендам: Этот шаг полностью соответствует общему тренду в индустрии данных — движению от монолитных, “умеющих все” платформ к более легковесным и специализированным инструментам. Для многих задач по перемещению и простой трансформации данных запуск Spark-кластера является избыточным. SeaTunnel теперь предлагает “золотую середину”.
- Конкурентное позиционирование:
- Против коммерческих SaaS ETL (Fivetran, Airbyte): SeaTunnel является мощной open-source альтернативой. Он привлекателен для компаний, которые хотят полного контроля над своей инфраструктурой, стремятся избежать зависимости от поставщика (vendor lock-in) и имеют техническую экспертизу для самостоятельного развертывания и поддержки.
- Против специализированных CDC-инструментов (Debezium): SeaTunnel не просто захватывает изменения (CDC), а встраивает эту функциональность в полноценный конвейер интеграции. Это решение “все в одном”, которое позволяет не только извлечь данные, но и доставить их в целевую систему (например, озеро данных или хранилище) в рамках одного инструмента.
- Фокус на “мультимодальности” — это задел на будущее. Поддержка не только реляционных баз и Kafka, но и озер данных (Hudi, Iceberg) и, в перспективе, векторных баз, говорит о том, что проект нацелен на обслуживание современных стеков данных, включая аналитику в реальном времени и конвейеры для машинного обучения (MLOps).
Рекомендации
Исходя из этого, можно дать следующие рекомендации:
- Кому стоит обратить внимание на Apache SeaTunnel:
- Командам, для которых Spark/Flink избыточны. Если ваша основная задача — это синхронизация данных между различными источниками (например, из MySQL в ClickHouse или из Kafka в HDFS) без сложных вычислений, `SeaTunnel Engine` может оказаться значительно более эффективным и простым в эксплуатации решением.
- Компаниям, ищущим open-source замену коммерческим ETL-инструментам. Если у вас есть экспертиза для управления Java-приложениями и вы хотите построить гибкую, масштабируемую и экономичную платформу интеграции данных, SeaTunnel — отличный кандидат.
- Пользователям экосистемы Apache. Проект тесно интегрируется с другими популярными проектами Apache (Doris, Hudi, Flink, Spark), что делает его естественным выбором для тех, кто уже использует эти технологии.
- Инженерам, которым нужна унификация. Если вы устали поддерживать отдельные скрипты или инструменты для пакетной и потоковой обработки, SeaTunnel предлагает единый подход к обоим сценариям.
- Что нужно проверить перед внедрением:
- Экосистему коннекторов: Самое важное — убедиться, что в SeaTunnel есть готовые, стабильные коннекторы для всех ваших источников и приемников данных. Хотя сообщество активно их добавляет, покрытие может быть не таким широким, как у коммерческих лидеров рынка.
- Функциональность CDC: Если вам нужен захват изменений в реальном времени, детально изучите поддержку вашей СУБД. Проверьте, насколько стабильно работает коннектор и какие гарантии доставки (exactly-once, at-least-once) он предоставляет.
- Операционная сложность: Несмотря на то, что SeaTunnel стал проще, это все еще open-source инструмент, требующий мониторинга, настройки и периодических обновлений. Убедитесь, что у вашей команды есть ресурсы для его поддержки.
Apache SeaTunnel трансформируется в мощный и современный инструмент, который заслуживает внимания со стороны инженеров данных. Его новое позиционирование как легковесной, унифицированной платформы делает его сильным игроком на поле интеграции данных.