
Cloudflare анонсирует платформу данных
*25 сентября 2025 г.*
*Мика Уайлд, Алекс Грэм, Жером Шнайдер*
https://blog.cloudflare.com/cloudflare-data-platform/
На неделе разработчиков в апреле 2025 года мы анонсировали публичную бета-версию R2 Data Catalog, полностью управляемого каталога Apache Iceberg поверх объектного хранилища Cloudflare R2. Сегодня мы развиваем эту область тремя новыми запусками:
- Cloudflare Pipelines получает события, отправленные через Workers или HTTP, преобразует их с помощью SQL и загружает в Iceberg или в виде файлов в R2.
- R2 Data Catalog управляет метаданными Iceberg и теперь выполняет постоянное обслуживание, включая уплотнение (compaction), для повышения производительности запросов.
- R2 SQL — наш собственный распределенный SQL-движок, разработанный для выполнения запросов петабайтного масштаба к вашим данным в R2.
Вместе эти продукты составляют Платформу данных Cloudflare (Cloudflare Data Platform) — комплексное решение для приема, хранения и запроса аналитических данных.
Как и все продукты Платформы для разработчиков Cloudflare , все они работают на нашей глобальной вычислительной инфраструктуре. Они построены на открытых стандартах и совместимы. Это означает, что вы можете использовать свой собственный движок запросов для Iceberg — будь то PyIceberg, DuckDB или Spark, — подключаться к другим платформам, таким как Databricks и Snowflake, и не платить за исходящий трафик (egress fees) при доступе к вашим данным.
Аналитические данные критически важны для современных компаний. Но традиционная инфраструктура данных дорога и сложна в эксплуатации. Мы создали Платформу данных Cloudflare, чтобы она была простой в использовании для любого пользователя и имела доступную цену, основанную на фактическом потреблении.
Если вы готовы начать прямо сейчас, следуйте нашему руководству по Платформе данных для пошагового создания конвейера, который обрабатывает события и доставляет их в таблицу R2 Data Catalog, к которой затем можно будет делать запросы с помощью R2 SQL.
Как мы пришли к созданию Платформы данных?
Мы запустили объектное хранилище `R2 Object Storage` в 2021 году с радикальной ценовой стратегией: никакой платы за исходящий трафик (egress fees) — это плата за пропускную способность, которую традиционные облачные провайдеры взимают за выгрузку данных, фактически держа ваши данные в заложниках.
Со временем мы увидели, что все больше компаний используют открытые форматы данных и таблиц для хранения своих аналитических хранилищ в R2.
Apache Iceberg. Iceberg — это формат таблиц, который предоставляет возможности, подобные базам данных (включая обновления, ACID-транзакции и эволюцию схемы), поверх файлов данных в объектном хранилище. Другими словами, это слой метаданных, который сообщает клиентам, какие файлы данных составляют определенную логическую таблицу, каковы их схемы и как эффективно их запрашивать.
Благодаря `R2` с нулевой платой за исходящий трафик, пользователи перестали быть привязанными к своим облакам. Они могут хранить свои данные в нейтральном месте и позволять командам использовать любой движок запросов, который подходит для их данных и шаблонов запросов.
Однако пользователям все еще приходилось управлять всей инфраструктурой метаданных самостоятельно. Мы поняли, что можем решить эту проблему, и так появился `R2 Data Catalog` — наш управляемый каталог Iceberg. Но оставалось несколько пробелов:
- Как загружать данные в таблицы Iceberg?
- Как оптимизировать их для повышения производительности запросов?
- Как извлекать ценность из данных, не размещая собственный движок запросов?
Далее мы рассмотрим, как три продукта, составляющие Платформу данных, решают эти задачи.
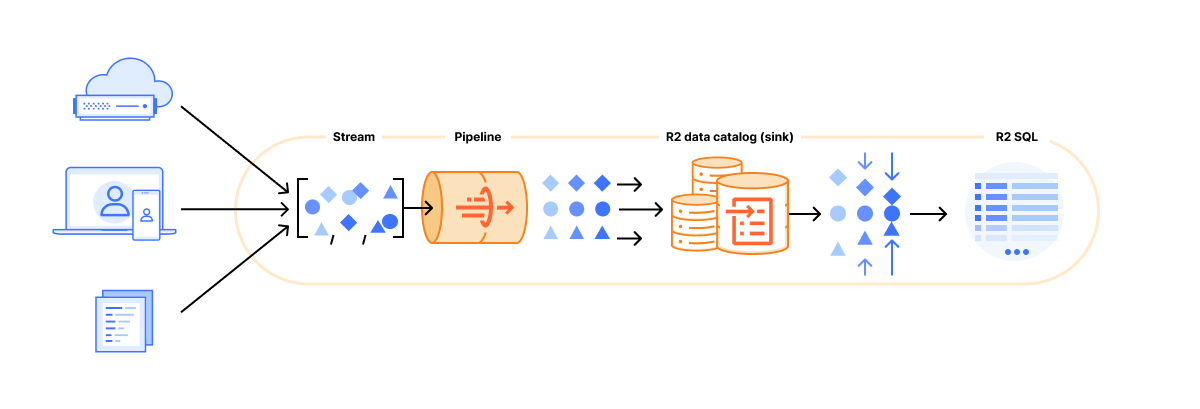
Cloudflare Pipelines
Аналитические таблицы состоят из событий, произошедших в определенный момент времени. Прежде чем вы сможете запрашивать их с помощью Iceberg, их нужно принять, структурировать по схеме и записать в объектное хранилище. Эту роль выполняют Cloudflare Pipelines.
Созданные на базе `Arroyo` (движка потоковой обработки, который мы приобрели в этом году), `Pipelines` получают события, преобразуют их с помощью SQL-запросов и направляют (sinks) в R2 и R2 Data Catalog.
`Pipelines` организованы вокруг трех ключевых объектов:
- Streams (Потоки): Способ получения данных в Cloudflare. Это надежные буферизованные очереди, которые принимают события по HTTP или через привязку к Cloudflare Worker.
- Sinks (Приемники): Определяют место назначения ваших данных. Мы поддерживаем загрузку в R2 Data Catalog, а также запись необработанных файлов в R2 в формате JSON или Apache Parquet.
- Pipelines (Конвейеры): Соединяют потоки и приемники через SQL-преобразования, которые могут изменять события перед их записью.
Например, вот конвейер, который принимает события из источника данных о кликах (clickstream) и записывает их в Iceberg, отфильтровывая ботов и события, не являющиеся просмотрами страниц:
INSERT into events_table
SELECT
user_id,
lower(event) AS event_type,
to_timestamp_micros(ts_us) AS event_time,
regexp_match(url, '^https?://([^/]+)')[1] AS domain,
url,
referrer,
user_agent
FROM events_json
WHERE event 'page_view'
AND NOT regexp_like(user_agent, '(?i)bot|spider');SQL-преобразования позволяют вам:
- Приводить данные к нужной схеме и нормализовать их.
- Фильтровать события или разделять их на разные таблицы.
- Удалять конфиденциальную информацию перед сохранением.
- Разворачивать вложенные массивы и объекты в отдельные события.
`Cloudflare Pipelines` доступны сегодня в открытой бета-версии. Во время беты мы не взимаем плату за `Pipelines`, однако хранение и операции в `R2` оплачиваются по стандартным тарифам blog.cloudflare.com.
R2 Data Catalog
Мы запустили открытую бету `R2 Data Catalog` в апреле и были поражены откликом blog.cloudflare.com. Начать работу с Iceberg стало просто — не нужно настраивать кластер баз данных или управлять инфраструктурой.
Однако со временем, по мере поступления данных, количество базовых файлов данных, составляющих таблицу, будет расти, что приведет к замедлению запросов. Особенно это заметно при низколатентной загрузке, когда данные пишутся часто и маленькими файлами.
Решением является уплотнение (compaction) — периодическая операция обслуживания, выполняемая каталогом автоматически. Уплотнение перезаписывает мелкие файлы в более крупные, что снижает накладные расходы на метаданные и повышает производительность запросов.
Сегодня мы запускаем поддержку уплотнения в `R2 Data Catalog`. Включить его для вашего каталога очень просто:
$ npx wrangler r2 bucket catalog compaction enable mycatalogВо время открытой беты мы не взимаем плату за `R2 Data Catalog`. Ниже наши предполагаемые будущие цены:
| Услуга | Цена* |
| Хранилище R2 (стандартный класс) | $0.015 за ГБ в месяц (без изменений) |
| Операции R2 класса A | $4.50 за миллион операций (без изменений) |
| Операции R2 класса B | $0.36 за миллион операций (без изменений) |
| Операции Data Catalog | $9.00 за миллион операций каталога |
| – Обработка данных уплотнением | $0.005 за ГБ + $2.00 за миллион объектов |
| Исходящий трафик (Egress) | $0 (без изменений, всегда бесплатно) |
*\*цены могут быть изменены до официального выпуска.*
R2 SQL
Иметь данные в `R2 Data Catalog` — это только первый шаг. Реальная цель — извлечь из них ценность. Традиционно это означает настройку и управление Spark, Trino или другим движком запросов. А что, если бы вы могли выполнять запросы прямо на Cloudflare?
Теперь можете. Мы создали движок запросов, специально разработанный для `R2 Data Catalog` и пограничной инфраструктуры Cloudflare. Мы называем его R2 SQL, и он доступен сегодня в виде открытой беты.
Выполнить запрос к таблице `R2 Data Catalog` с помощью Wrangler так же просто, как:
$ npx wrangler r2 sql query "{WAREHOUSE}" "SELECT user_id, url FROM events WHERE domain = 'mywebsite.com'"Способность Cloudflare планировать вычисления в любой точке своей глобальной сети лежит в основе `R2 SQL`. Это позволяет нам обрабатывать данные прямо там, где они находятся. Результатом является полностью бессерверный опыт для пользователей.
Открытая бета-версия — это ранний предварительный просмотр возможностей `R2 SQL`, и изначально она ориентирована на запросы с фильтрацией. Со временем мы будем расширять его возможности для поддержки более сложных SQL-функций, таких как агрегации. Во время беты использование `R2 SQL` не оплачивается, но хранение и операции `R2`, вызванные запросами, оплачиваются по стандартным тарифам.
Подводя итоги
Сегодня вы можете использовать Платформу данных Cloudflare для приема событий в `R2 Data Catalog` и их запроса через `R2 SQL`. В первой половине 2026 года мы планируем расширить возможности всех этих продуктов, включая:
- Интеграцию с `Logpush`, чтобы вы могли преобразовывать, хранить и запрашивать свои логи прямо в Cloudflare.
- Пользовательские функции через `Workers` и поддержку обработки с состоянием для потоковых преобразований.
- Расширение функционала `R2 SQL` для поддержки агрегаций и объединений (joins).