Хроники Apache SeaTunnel
Давно откопал этого китайского друга уже успело выйти пару версий. Не могу сказать, что хорошо с ним знаком, но чем то он меня по прежнему манит, то ли своей солидностью гибкой архитектуры, то ли масштабом охвата и в то же время акценте на синхронизацию данных. Сложно сказать. Одно ясно, что достаточно легко его запускать как в локальном режиме, так и в кластером если нужно. А текстовые конфиги заданий вообще мечта, а еще есть даже sql формат для заданий.
В общем знакомимся: https://seatunnel.apache.org Next-generation high-performance, distributed, massive data integration tool.
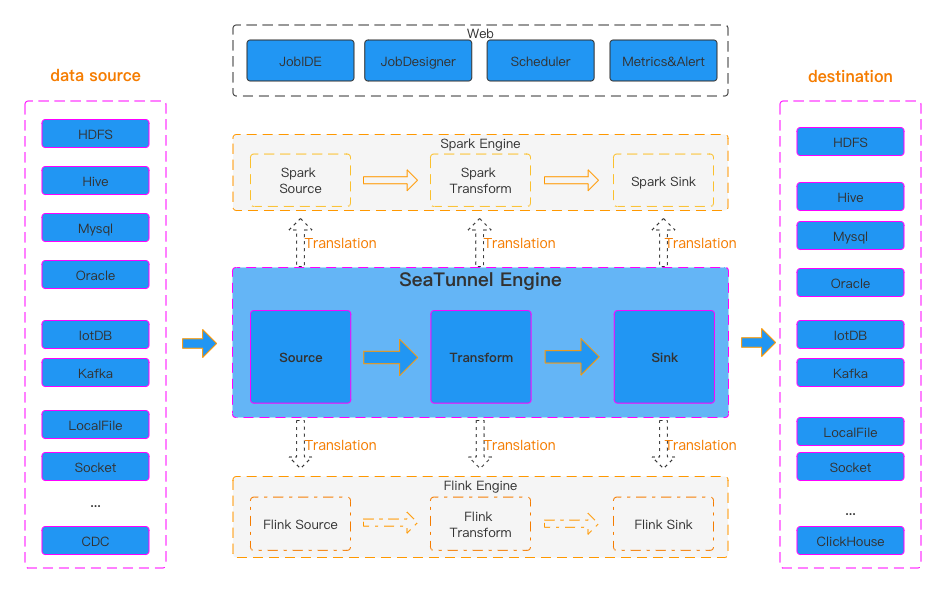
Вспомнил я его из за последнего релиза, где добавили LLM трансформер. А изначально была идея делать на нем синхронизацию данных из Кафки в s3 iceberg прямиком. Идея еще жива и потихоньку обрастает пылью. Но когда нибудь наступит час и все случится :) но не сегодня.
Пробуем записать файл 10gb в csv в s3:
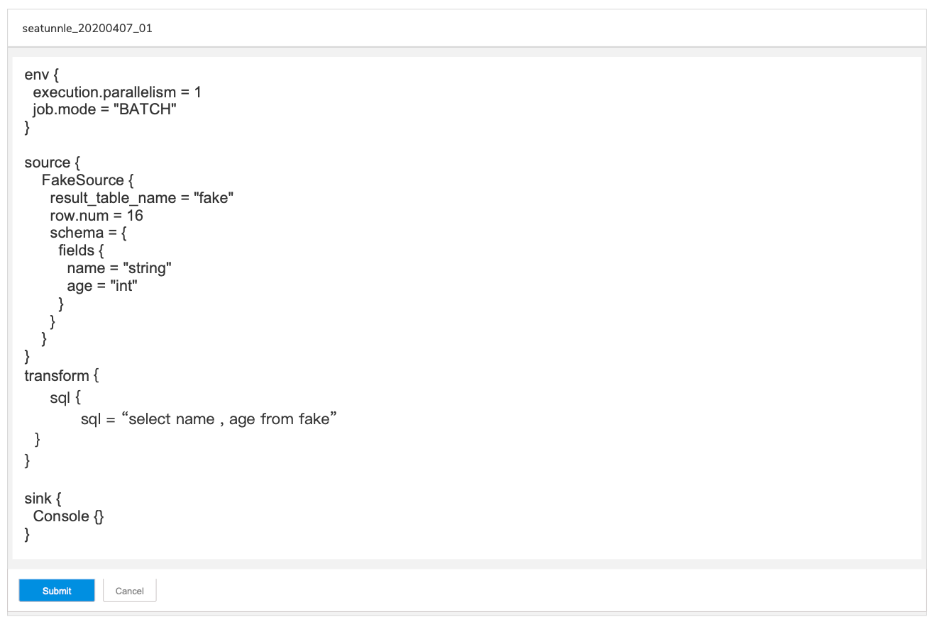
Set the basic configuration of the task to be performed
Пишем конфигурацию:
env {
parallelism = 1
job.mode = "batch"
# checkpoint.interval = 30000
# checkpoint.timeout = 5000
}
# read csv
source {
LocalFile {
schema {
fields {
vendorid = string
tpep_pickup_datetime = string
tpep_dropoff_datetime = string
passenger_count = string
trip_distance = string
ratecodeid = string
store_and_fwd_flag = string
pulocationid = string
dolocationid = string
payment_type = string
fare_amount = string
extra = string
mta_tax = string
tip_amount = string
tolls_amount = string
improvement_surcharge = string
total_amount = string
}
}
path = "./2018_Yellow_Taxi_Trip_Data.csv"
file_format_type = "csv"
field_delimiter = ","
# datetime_format = "dd/MM/yyyy hh:mm:ss"
skip_header_row_number = 1
}
}
transform {
}
# csv to iceberg
sink {
iceberg {
catalog_name = "iceberg"
iceberg.catalog.config={
"type"="hive"
"uri" = "thrift://metastore:9083"
"warehouse"="s3a://test/iceberg_p_listner5_podman/"
}
hadoop.config={
"fs.s3a.aws.credentials.provider" = "org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider"
"fs.s3a.endpoint" = "gateway.storjshare.io"
"fs.s3a.access.key" = "jvrKukurukutratatabq"
"fs.s3a.secret.key" = "jzwnieshotutblablabla44imhhs"
"fs.defaultFS" = "s3a://test/iceberg_p_listner5_podman/"
"fs.s3a.impl"="org.apache.hadoop.fs.s3a.S3AFileSystem"
}
namespace = "my_schema_i"
table = "taxi5"
iceberg.table.write-props={
write.format.default="parquet"
write.parquet.compression-codec="snappy"
write.target-file-size-bytes=136870912
}
# iceberg.table.primary-keys="id"
# iceberg.table.upsert-mode-enabled=true
# iceberg.table.schema-evolution-enabled=true
# case_sensitive=true
# result_table_name = "test_table"
}
}Запускаем конфигурацию:
./bin/seatunnel.sh --config ./config/V2.LLM.csv-ice1.config.template -m localпьем чай пару минут
***********************************************
Job Statistic Information
***********************************************
Start Time : 2024-09-12 20:38:36
End Time : 2024-09-12 20:55:45
Total Time(s) : 1028
Total Read Count : 112234626
Total Write Count : 112234626
Total Failed Count : 0
***********************************************Готово.
Файл был про такси Нью Йорка
VendorID,tpep_pickup_datetime,tpep_dropoff_datetime,passenger_count,trip_distance,RatecodeID,store_and_fwd_flag,PULocationID,DOLocationID,payment_type,fare_amount,extra,mta_tax,tip_amount,tolls_amount,improvement_surcharge,total_amount
1,02/06/2018 02:05:59 PM,02/06/2018 02:13:00 PM,1,1.1,1,N,161,100,2,6.5,0,0.5,0,0,0.3,7.3
1,02/06/2018 02:33:25 PM,02/06/2018 02:43:47 PM,1,1.1,1,N,170,161,1,8,0,0.5,1.75,0,0.3,10.55
1,02/06/2018 02:46:31 PM,02/06/2018 02:53:13 PM,1,0.9,1,N,161,170,2,6.5,0,0.5,0,0,0.3,7.3
1,02/06/2018 02:55:34 PM,02/06/2018 03:13:34 PM,1,6.1,1,N,170,231,1,20.5,0,0.5,2,0,0.3,23.3
1,02/06/2018 02:00:41 PM,02/06/2018 02:16:07 PM,1,1.4,1,N,163,170,1,10.5,0,0.5,2.25,0,0.3,13.55
1,02/06/2018 02:24:55 PM,02/06/2018 02:31:25 PM,1,0.7,1,N,170,161,1,6,0,0.5,1,0,0.3,7.8
1,02/06/2018 02:37:16 PM,02/06/2018 02:53:57 PM,1,2.2,1,N,162,262,2,12.5,0,0.5,0,0,0.3,13.3
1,02/06/2018 02:57:05 PM,02/06/2018 03:10:26 PM,1,1.8,1,N,262,162,1,11,0,0.5,2.35,0,0.3,14.15
1,02/06/2018 02:01:55 PM,02/06/2018 02:04:56 PM,1,0.4,1,N,239,143,2,4,0,0.5,0,0,0.3,4.8
и так далее до 112 234 626 строкиВ Трино все хорошо
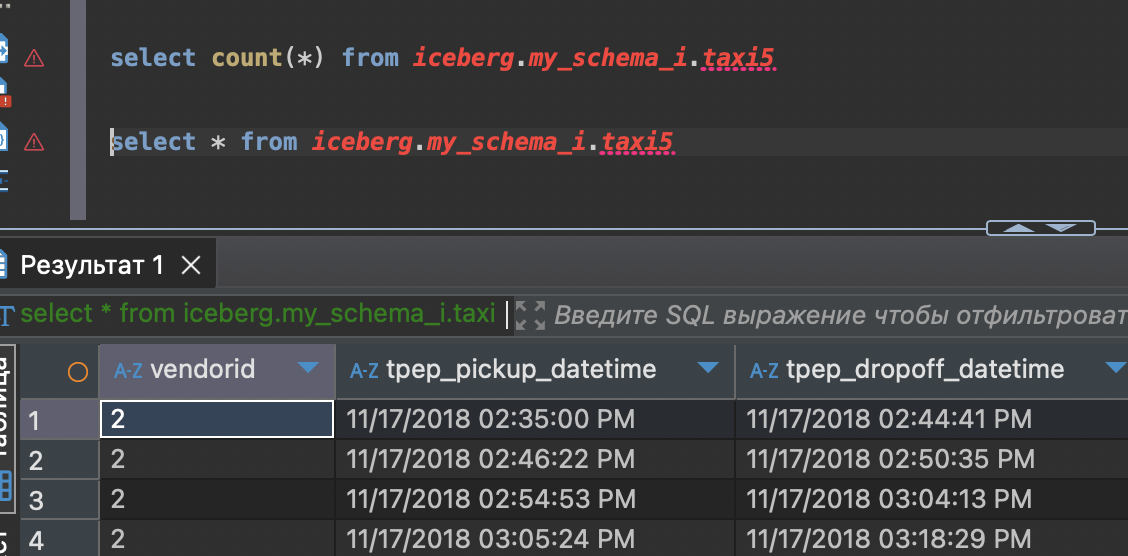
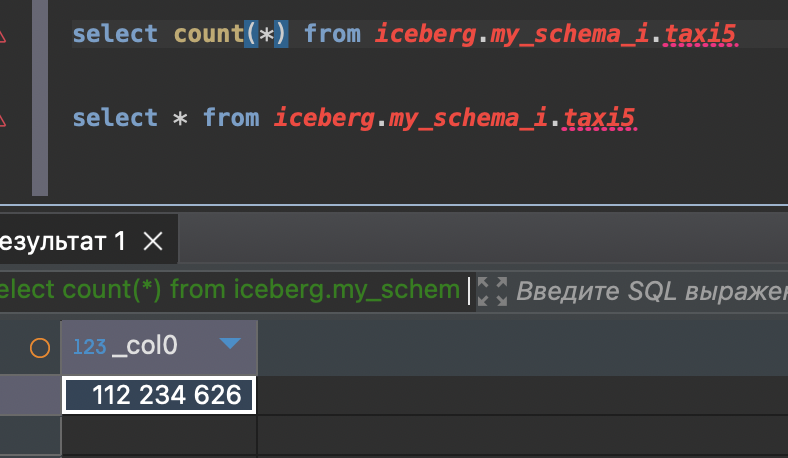
Но пришлось немного подрулить java в файле ./config/jvm_client_options
# JVM Heap
-Xms556m
-Xmx1512mЗадание после этого шло более стабильно.
Промежуточный контрольный лог выглядит норм:
2024-09-12 20:53:16,054 INFO [c.h.i.d.HealthMonitor ] [hz.main.HealthMonitor] - [localhost]:5801 [seatunnel-872250] [5.1] processors=6, physical.memory.total=14.5G, physical.memory.free=419.0M, swap.space.total=0, swap.space.free=0, heap.memory.used=1.0G, heap.memory.free=437.8M, heap.memory.total=1.4G, heap.memory.max=1.4G, heap.memory.used/total=70.25%, heap.memory.used/max=70.25%, minor.gc.count=5327, minor.gc.time=32576ms, major.gc.count=7, major.gc.time=677ms, load.process=40.78%, load.system=41.68%, load.systemAverage=2.35, thread.count=151, thread.peakCount=163, cluster.timeDiff=0, event.q.size=0, executor.q.async.size=0, executor.q.client.size=0, executor.q.client.query.size=0, executor.q.client.blocking.size=0, executor.q.query.size=0, executor.q.scheduled.size=0, executor.q.io.size=0, executor.q.system.size=0, executor.q.operations.size=0, executor.q.priorityOperation.size=0, operations.completed.count=764, executor.q.mapLoad.size=0, executor.q.mapLoadAllKeys.size=0, executor.q.cluster.size=0, executor.q.response.size=0, operations.running.count=0, operations.pending.invocations.percentage=0.00%, operations.pending.invocations.count=0, proxy.count=10, clientEndpoint.count=1, connection.active.count=0, client.connection.count=0, connection.count=0Важно добавить:
Задание падало не ясно почему. Хазлкаст куда-то девался и писал проблемы с тайм-аутами.
тут все изложил, но пока все описывал нашел ошибки. https://github.com/apache/seatunnel/issues/7650
Писал слишком маленькие файлы и накосячил с полями, они оказывается чувствительные к регистру.
А еще заметил, что когда задание падает, то Селесты в трико не проходят. Точнее показывают пустую таблицу, но вот в s3 файлы есть. Команда optimize ничего не дает, все равно остаются.
в итоге пока не нашел как почистить ошибочные файлы.
а вот еще пример с моделью llm gpt4o. Для доступа к api я использовать сервис http://proxyapi.ru – вроде не очень дорого и удобно платить с России и расходовать по мере использования. Еще пользуюсь этим http://openrouter.ai там большое моделей, но платить чуть сложнее, можно криптой оплатить.
И так, вот пример конфига:
# Set the basic configuration of the task to be performed111
env {
parallelism = 1
job.mode = "batch"
# checkpoint.interval = 30000
# checkpoint.timeout = 5000
}
# Create a source to connect to Clickhouse
source {
Clickhouse {
host = "some-clickhouse-server:8123"
database = "default"
sql = "select * from test_table"
username = ""
password = ""
server_time_zone = "UTC"
# result_table_name = "test_table"
clickhouse.config = {
"socket_timeout": "300000"
}
}
}
transform {
LLM {
model_provider = OPENAI
model = gpt-4o
api_key = sk-GIkitutblablabalkakayatoest5D33l5a
prompt = "Determine whether someone is Chinese, American or Russian, give a feedback in json string with quatation"
openai.api_path = "https://api.proxyapi.ru/openai/v1/chat/completions"
output_data_type = "STRING"
}
}
# Console printing of the read Clickhouse data
sink {
iceberg {
catalog_name = "iceberg"
iceberg.catalog.config={
"type"="hive"
"uri" = "thrift://metastore:9083"
"warehouse"="s3a://test/iceberg_p_listner5_podman/"
}
hadoop.config={
"fs.s3a.aws.credentials.provider" = "org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider"
"fs.s3a.endpoint" = "gateway.storjshare.io"
"fs.s3a.access.key" = "jvr2blablablayjrbq"
"fs.s3a.secret.key" = "jzwnleotuteshokayayatohrenbilaqskh3323imhhs"
"fs.defaultFS" = "s3a://test/iceberg_p_listner5_podman/"
"fs.s3a.impl"="org.apache.hadoop.fs.s3a.S3AFileSystem"
}
namespace = "my_schema_i"
table = "test_table6"
iceberg.table.write-props={
write.format.default="parquet"
write.parquet.compression-codec="snappy"
write.target-file-size-bytes=536870
}
iceberg.table.primary-keys="id"
iceberg.table.upsert-mode-enabled=true
iceberg.table.schema-evolution-enabled=true
case_sensitive=true
# result_table_name = "test_table"
}
}Таблица в клике была такая:

схемка эта:
CREATE TABLE default.test_table
(
`id` Int32,
`name` String
)
ENGINE = MergeTree
ORDER BY id
SETTINGS index_granularity = 8192
......
insert into `default`.test_table values (7, 'Petya')
insert into `default`.test_table values (8, 'Dasha')
insert into `default`.test_table values (9, 'Dima')
insert into `default`.test_table values (10, 'Tony')
insert into `default`.test_table values (11, 'Fekla')
insert into `default`.test_table values (12, 'Jekie Chan')
insert into `default`.test_table values (13, 'ben')
insert into `default`.test_table values (14, 'Howard')
insert into `default`.test_table values (16, 'Semen')
insert into `default`.test_table values (17, 'Katya')
insert into `default`.test_table values (18, 'Kostya')
insert into `default`.test_table values (19, 'Natasha')
insert into `default`.test_table values (20, 'Tonya')
insert into `default`.test_table values (21, 'Tanya')
.....Что выходит в итоге:
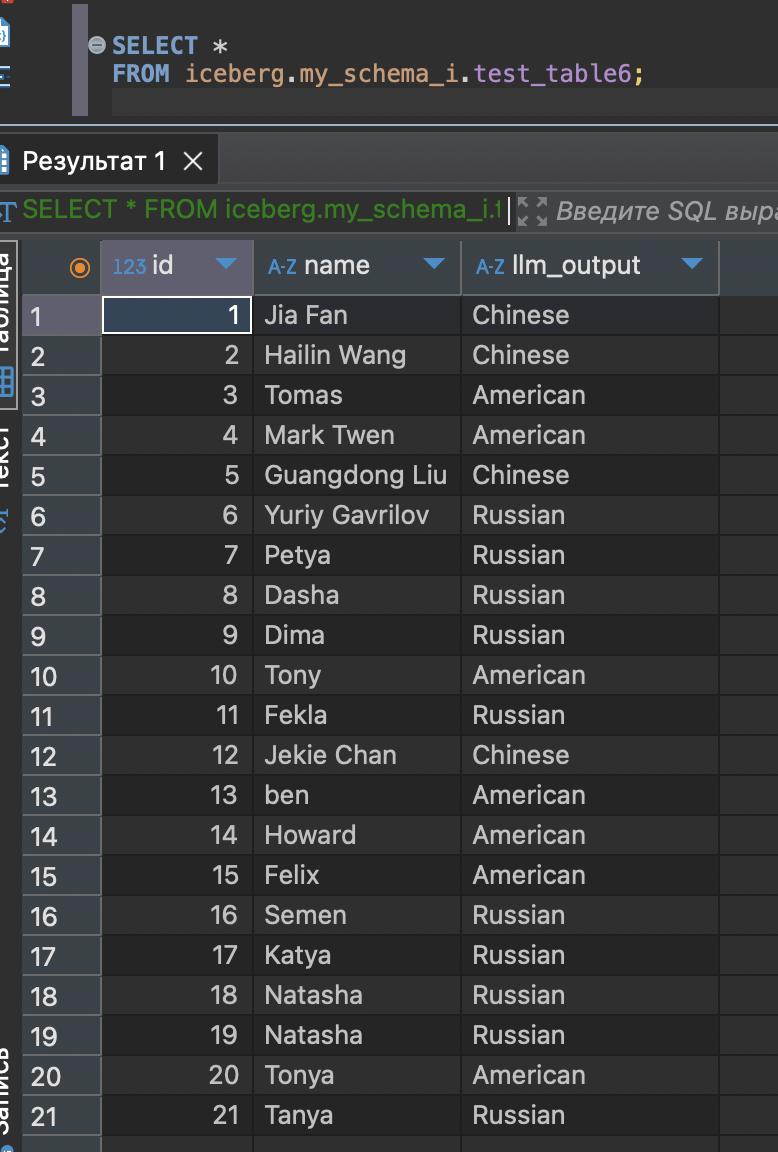
Данные были прочитаны из clickhouse и отправлены в модель построчно.
Модель ответила и заполнила колонку llm_outputю.
2024-09-12 21:47:12,075 INFO [s.c.s.s.c.ClientExecuteCommand] [main] -
***********************************************
Job Statistic Information
***********************************************
Start Time : 2024-09-12 21:46:33
End Time : 2024-09-12 21:47:12
Total Time(s) : 38
Total Read Count : 21
Total Write Count : 21
Total Failed Count : 0
***********************************************В общем если хотите пробуйте SeaTunnel. Норм работает и качество улучшается.
Iceberg например не получалось у меня загрузить в прошлой версии 2.3.7, пришлось собрать свежую по рекомендации. в Ней еще надо было добавить пару либ. Они не все нужны, но обязательны для hive внизу плагины hive-exec-3.1.3.jar и libfb303-0.9.3.jar, ну и рабочая либа seatunnel-hadoop3-3.1.4-uber.jar из за которой как раз и пришлось все собирать вручную.