
Iceberg в Trino: Путешествие по Вариантам Хранения, Сжатия и Конфигурации для Оптимальной Производительности
Iceberg, как табличный формат, совершил революцию в управлении данными в озерах данных (data lakes), предоставив транзакционные гарантии и схематическую эволюцию для данных, хранящихся в файлах. В контексте Trino, мощного распределенного SQL-движка, Iceberg раскрывает свой потенциал, позволяя пользователям взаимодействовать с данными в озерах как с традиционными базами данных. Эта статья углубится в различные варианты хранения, сжатия и конфигурации Iceberg в Trino, рассматривая преимущества и недостатки каждого, и поможет вам сделать осознанный выбор для достижения оптимальной производительности и минимизации затрат.

Автор: Gemini Flash. 2.5
1. Форматы Хранения (File Formats)
Iceberg не хранит данные сам по себе, а указывает на файлы данных, которые могут быть разных форматов. Выбор формата данных является одним из наиболее важных решений, напрямую влияющим на производительность запросов, эффективность сжатия и общую стоимость хранения.
a) Parquet
- Описание:** Колоночный формат хранения данных, оптимизированный для аналитических запросов. Он хранит данные в колоночной ориентации, что позволяет Trino считывать только необходимые колонки во время выполнения запросов. Parquet тесно интегрирован с концепциями Iceberg, такими как использование идентификаторов полей (Field IDs) для поддержки надежной схемы эволюции.
- Преимущества:**
- Высокая производительность в аналитике: За счет колоночного хранения и возможности Trino применять “push-down” предикатов, Parquet обеспечивает беспрецедентную скорость для большинства аналитических запросов, избирательно считывая только необходимые данные.
- Эффективное сжатие: Колоночная ориентация позволяет применять различные алгоритмы сжатия, оптимизированные для типов данных в каждой колонке, существенно снижая объем хранимых данных и, как следствие, затраты на хранение.
- Нативная поддержка схемы эволюции Iceberg: Iceberg использует Field IDs, которые записываются в метаданды Parquet. Это ключевой механизм, позволяющий Iceberg поддерживать эволюцию схемы (добавление, удаление, переименование колонок) без перезаписи данных и без нарушения целостности запросов.
- Широкая поддержка и зрелость: Parquet является фактическим стандартом для хранения аналитических данных в экосистеме больших данных и поддерживается всеми основными инструментами (Spark, Hive, Dremio, Athena, BigQuery, Snowflake и т.д.), обеспечивая отличную интероперабельность.
- Недостатки:**
- Неэффективен для точечных запросов (point lookups): Для выборки одной или нескольких записей требуется считывать данные из нескольких колонок, что может быть менее эффективно, чем строковые форматы данных.
- Сложность изменения данных: Изменение отдельных записей требует перезаписи целых файлов или их частей, что является общей чертой для колоночных форматов.
- Использование: **Parquet – это формат по умолчанию и наиболее рекомендуемый выбор для таблиц Iceberg в Trino. Он обеспечивает наилучший баланс производительности, эффективности хранения и простоты управления для большинства аналитических рабочих нагрузок.
b) ORC (Optimized Row Columnar)
- Описание:** Ещё один колоночный формат, разработанный специально для Apache Hive. Он имеет много сходств с Parquet, включая колоночное хранение и эффективное сжатие. Документация Iceberg подтверждает, что ORC также может хранить необходимые метаданные (например, `iceberg.id`, `iceberg.required`) в атрибутах типов ORC для поддержки схемы эволюции.
- Преимущества:**
- Высокая производительность и эффективное сжатие: Аналогично Parquet, ORC обеспечивает отличную производительность для аналитических запросов и эффективное сжатие.
- Расширенное индексирование: ORC часто содержит более гранулированные встроенные индексы (например, индексы позиций, Bloom-фильтры), которые могут быть полезны для некоторых специфических типов запросов.
Но Bloom-фильтры по умолчанию отключены в Trino вроде как, надо проверять этот конфиг:

- Совместимость со схемой эволюции Iceberg: Iceberg способен адаптировать ORC-схему (даже путем изменения имен колонок) для своей ID-основанной эволюции, что делает его совместимым.
- Недостатки:**
- Неэффективен для точечных запросов: Общий недостаток для всех колоночных форматов.
- Менее распространен как универсальный формат вне экосистемы Hive: Хотя ORC является основным форматом для Hive, Iceberg чаще ассоциируется с Parquet как универсальным форматом хранения для Data Lake. Это может потенциально означать меньшую поддержку или оптимизацию в некоторых не-Hive инструментах.
- Специфические моменты с отображением типов: Как видно из Iceberg documentation, существуют нюансы с отображением типов данных (например, `timestamp` и `timestamptz`) в ORC. Может потребоваться использование дополнительных атрибутов Iceberg (таких как `iceberg.timestamp-unit`) для корректной передачи семантики.
- Отсутствие “шрединга” для типа `variant`: Документация указывает, что для ORC не поддерживается “шрединг” (оптимизированное хранение) для полуструктурированного типа `variant`, что может быть ограничением для пользователей, активно работающих с такими данными.
- Использование: Хороший выбор для аналитических рабочих нагрузок, особенно если ваша существующая инфраструктура уже использует ORC, и вы хорошо знакомы с его нюансами. Однако, для новых развертываний Iceberg, **Parquet обычно является более простым и универсальным выбором по умолчанию.
c) Avro
- Описание: Строковый формат данных, ориентированный на быструю сериализацию и десериализацию. Avro широко используется в Apache Kafka и для передачи данных между системами. Важно отметить, что Iceberg использует Avro в качестве формата **своих внутренних файлов метаданных (например, манифестов и метаданных таблиц), где его строковая природа и возможности сериализации очень полезны. Iceberg также описывает, как Avro может быть использован для файлов данных, включая строгие правила для отображения типов данных Avro и использование Field IDs для поддержки эволюции схемы.
- Преимущества:**
- Отлично подходит для сериализации и передачи данных: Благодаря своей компактности и быстрой сериализации/десериализации, Avro идеален для потоковой передачи.
- Встроенная схема (Schema-on-Read): Схема хранится вместе с данными, что обеспечивает совместимость. Iceberg расширяет это, добавляя Field IDs в схему Avro для robustной эволюции.
- Поддержка эволюции схемы: Iceberg, благодаря внедрению Field IDs в схемы Avro и строгим правилам для `union` (например, использование `null` для опциональных полей), способен обеспечить эволюцию схемы даже для данных, хранящихся в Avro. Это технически возможно благодаря Iceberg.
- Недостатки:**
- Крайне низкая производительность для аналитики: Это ключевой и самый серьезный недостаток Avro для аналитических рабочих нагрузок. Для запросов требуется считывать всю строку данных, даже если нужны только некоторые колонки. Это приводит к значительному избытку I/O, увеличивает потребность в памяти и катастрофически замедляет аналитические запросы по сравнению с колоночными форматами.
- Неэффективное сжатие: Сжатие применяется ко всей строке, а не к отдельным колонкам. Это значительно снижает коэффициент сжатия по сравнению с Parquet или ORC, что приводит к увеличению объема хранимых данных и, соответственно, затрат.
- Отсутствие “шрединга” для типа `variant`: Как и в ORC, Avro не поддерживает “шрединг” для полуструктурированного типа `variant`, что может ограничивать работу со сложными схемами.
- Использование: **Категорически не рекомендуется использовать Avro в качестве формата хранения
данныхдля таблиц Iceberg, предназначенных для аналитических запросов в Trino. Несмотря на то, что Iceberg может технически поддерживать его для данных, это приведет к серьезному ухудшению производительности и увеличению затрат. Avro прекрасно подходит для файлов метаданных Iceberg и для потоковых данных, но не для аналитического хранения.
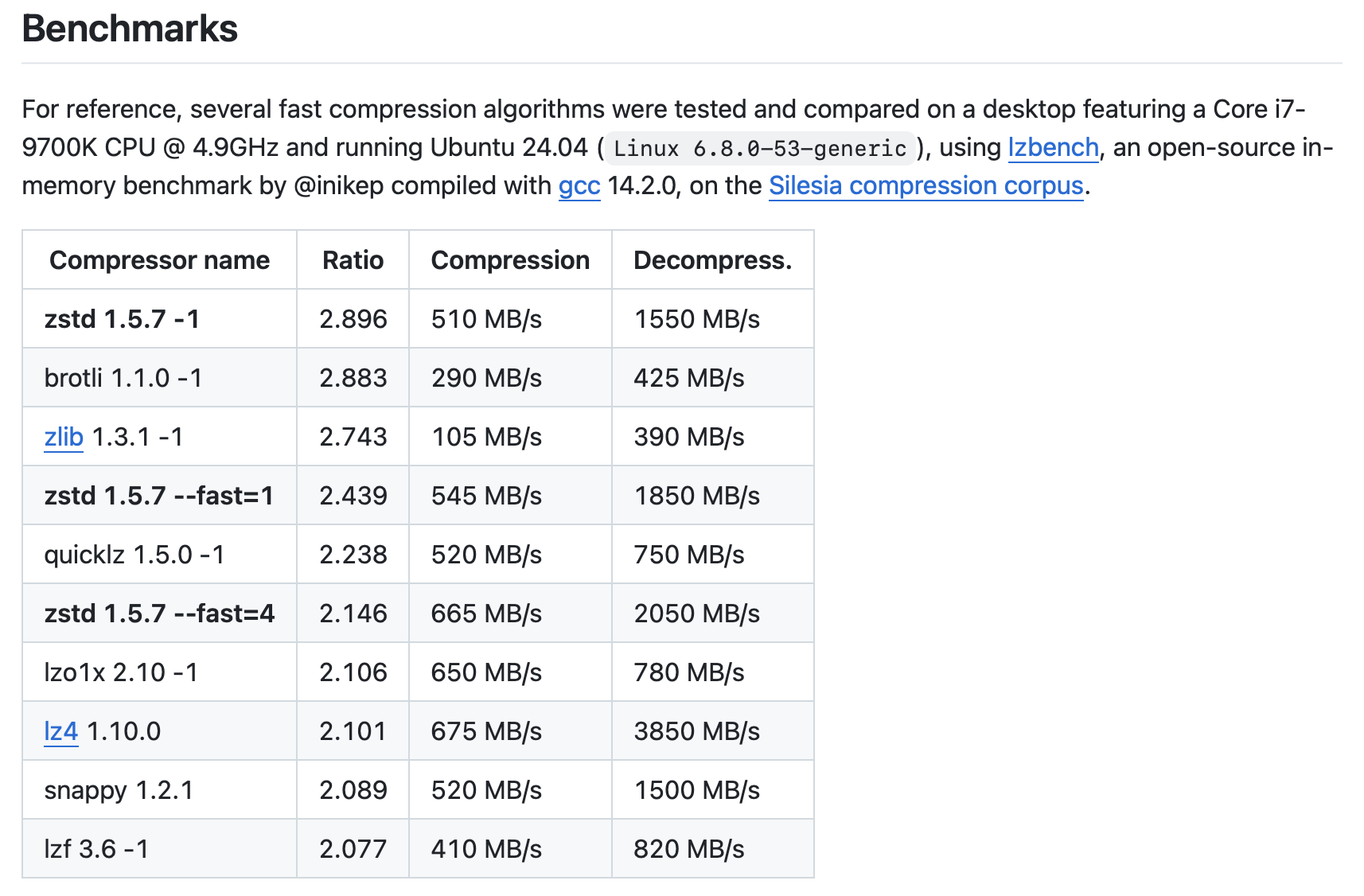
2. Алгоритмы Сжатия (Compression Algorithms)
Выбор алгоритма сжатия напрямую влияет на размер хранимых данных, скорость чтения/записи и потребление ресурсов CPU. Trino поддерживает различные алгоритмы сжатия для файлов Parquet и ORC.
a) Snappy
- Описание:** Высокоскоростной алгоритм сжатия, разработанный Google. Он оптимизирован для скорости сжатия и декомпрессии, а не для максимальной степени сжатия.
- Преимущества:**
- Очень быстрая декомпрессия: Минимальное влияние на производительность запросов, что критично для активных аналитических систем.
- Сбалансированное соотношение сжатия: Обеспечивает хорошее сокращение размера файла без значительных затрат CPU.
- Широкая поддержка: Один из наиболее часто используемых алгоритмов сжатия в экосистеме big data.
- Недостатки:**
- Менее эффективное сжатие: По сравнению с алгоритмами, ориентированными на максимальное сжатие (например, ZSTD), Snappy может занимать больше места на диске.
- Использование: **Отличный выбор по умолчанию для большинства рабочих нагрузок, где скорость чтения является приоритетом, а степень сжатия “достаточно хороша”.
b) ZSTD
- Описание:** Алгоритм сжатия, разработанный Facebook, предлагающий значительно лучшую степень сжатия, чем Snappy, при сохранении приемлемой скорости сжатия/декомпрессии.
- Преимущества:**
- Высокая степень сжатия: Заметно сокращает объем данных на диске, что приводит к значительной экономии затрат на хранение и уменьшению объема передаваемых данных (IO).
- Хорошая скорость декомпрессии: Хотя и медленнее, чем Snappy, ZSTD всё ещё очень быстр, особенно по сравнению с GZIP, что делает его пригодным для аналитических нагрузок.
- Недостатки:**
- Более высокое использование CPU: Процесс сжатия и декомпрессии требует больше ресурсов CPU, чем Snappy, что может немного увеличить нагрузку на вычислительные кластеры.
- Использование: Рекомендуется, когда **снижение затрат на хранение является приоритетом, и вы готовы пожертвовать небольшой частью производительности CPU. Отличный выбор для архивных данных или данных с высоким коэффициентом повторения.
Trino использует кстати уровень 3 и его поменять пока нельзя :(
public static final int DEFAULT_COMPRESSION_LEVEL = 3;c) GZIP
- Описание:** Широко распространенный и очень эффективный алгоритм сжатия.
- Преимущества:**
- Очень высокая степень сжатия: Обеспечивает максимальное уменьшение размера файла, что идеально для архивирования.
- Недостатки:**
- Очень медленная декомпрессия: Существенно замедляет операции чтения запросов, что делает его непригодным для интерактивной аналитики.
- Высокое использование CPU: значительно увеличивает нагрузку на CPU при сжатии и декомпрессии.
- Использование: **Категорически не рекомендуется для активных аналитических данных в Iceberg. Его использование оправдано только для долгосрочного архивирования, где данные редко запрашиваются, а максимальное сжатие является единственным приоритетом. Для активных данных он значительно ухудшит производительность Trino.
d) LZ4
- Описание:** Еще один очень быстрый алгоритм сжатия, схожий по производительности со Snappy, но иногда предлагающий чуть лучшее сжатие.
- Преимущества:**
- Очень высокая скорость: Схож со Snappy.
- Хорошее соотношение сжатия.
- Недостатки:**
- Схож со Snappy.
- Использование:** Альтернатива Snappy, если требуется очень высокая скорость и хорошее сжатие.
3. Конфигурация Iceberg в Trino
Правильная настройка Iceberg в Trino включает в себя конфигурацию каталога и параметров создания самих таблиц.
a) Конфигурация Каталога (Catalog Configuration)
В файле `etc/catalog/
connector.name=iceberg
iceberg.catalog.type=hive_metastore # или rest, hadoop
hive.metastore.uri=thrift://namenode:9083 # Если hive_metastore
# Для объектного хранилища (например, S3, MinIO)
iceberg.s3.endpoint-url=http://s3.local:9000
iceberg.s3.region=us-east-1
iceberg.s3.access-key=YOUR_ACCESS_KEY
iceberg.s3.secret-key=YOUR_SECRET_KEY
iceberg.s3.path-style-access=true # Для некоторых S3-совместимых хранилищ- `connector.name=iceberg`: Определяет, что используется коннектор Iceberg.
- `iceberg.catalog.type`: Определяет, какой бэкенд каталога Iceberg будет использоваться для хранения метаданных (схемы таблиц, версий и расположения файлов данных).
- `hive_metastore`: Использует существующий Hive Metastore. Это самый распространенный вариант, если у вас уже есть Hive Metastore.
- `rest`: Подключается к Iceberg REST Catalog (требует развертывания отдельного сервиса). Предоставляет более чистый API и может обеспечивать лучшую производительность для операций с каталогом.
- `hadoop`: Использует HDFS для хранения метаданных Iceberg. Менее распространен для продакшн-развертываний.
- Параметры хранилища данных (Data Storage):** Независимо от типа каталога, фактические файлы данных Iceberg могут храниться в S3, HDFS, Google Cloud Storage, Azure Blob Storage и т.д. Вам нужно настроить соответствующие параметры в конфигурации каталога Trino для доступа к этому хранилищу (например, `iceberg.s3.endpoint-url`, `iceberg.s3.access-key` для S3).
b) Конфигурация Таблиц (Table Configuration)
При создании таблиц Iceberg в Trino вы можете указывать различные параметры через секцию `WITH`. Это позволяет точно настроить, как Iceberg будет хранить данные.
CREATE TABLE my_iceberg_table (
id INT,
name VARCHAR,
event_timestamp TIMESTAMP(6) WITH TIME ZONE,
data_json VARCHAR -- Пример для хранения полуструктурированных данных
)
WITH (
format = 'PARQUET', -- Формат файлов данных
partitioning = ARRAY['WEEK(event_timestamp)', 'bucket(16, id)'], -- Стратегия партиционирования
format_version = 2, -- Версия формата Iceberg (рекомендуется 2)
parquet_compression = 'ZSTD', -- Алгоритм сжатия Parquet
parquet_row_group_size = '256MB', -- Целевой размер группы строк в Parquet
write_target_data_file_size_bytes = '536870912', -- ~512MB, Целевой размер файлов данных, записываемых Iceberg
vacuum_max_snapshots_to_keep = 10, -- Количество последних снимков для хранения
expire_snapshots_min_retention_ms = 86400000 -- Минимальное время удержания снимков (24 часа)
);- `format`: Определяет формат файла данных (`’PARQUET’` или `’ORC’`). По умолчанию Iceberg использует Parquet.
- `partitioning`: Определяет стратегию партиционирования данных. Это критически важно для производительности запросов, так как Trino может пропускать целые партиции, не соответствующие условиям фильтрации. Примеры: `ARRAY[‘year(column_name)’, ‘month(column_name)’]` для временных данных, `ARRAY[‘bucket(N, column_name)’]` для равномерного распределения данных на основе хеша.
- `format_version`: Версия формата Iceberg (текущие версии 1 или 2). Рекомендуется использовать `2` для новых таблиц, так как она предлагает больше возможностей (например, поддержка удаления строк, более гибкие индексы, поддержку Positional Deletes).
- `parquet_compression`: Указывает алгоритм сжатия для Parquet файлов (`’SNAPPY’`, `’ZSTD’`, `’GZIP’`, `’LZ4’`).
- `parquet_row_group_size`: Целевой размер группы строк (row group) в Parquet файле. Рекомендуемый диапазон обычно составляет от 128MB до 512MB. Большие группы строк могут улучшить сжатие и эффективность IO, но могут замедлить запись.
- `parquet_page_size`: Размер страницы в пределах группы строк Parquet. Обычно не требует частых изменений, но может влиять на сжатие и гранулярность доступа к данным.
- `write_target_data_file_size_bytes`: Очень важный параметр. Определяет целевой размер файлов данных, которые Iceberg будет записывать. Хороший диапазон — от 128 МБ до 1 ГБ (~134217728 до 1073741824 байт). Чрезмерно маленькие файлы приводят к “проблеме маленьких файлов” (Small File Problem), что увеличивает нагрузку на метаданные и замедляет запросы. Чрезмерно большие файлы могут снизить параллелизм чтения.
- `vacuum_max_snapshots_to_keep`: Количество последних снимков таблицы, которые Iceberg должен сохранять. Важно для операций `VACUUM` и возможности откатывать таблицу к предыдущим состояниям.
- `expire_snapshots_min_retention_ms`: Минимальное время удержания снимков (в миллисекундах) до их удаления.
Подведение Итога
Выбор правильных форматов, сжатия и конфигурации для Iceberg в Trino является решающим для оптимизации производительности, стоимости и управляемости вашего озера данных.
- Формат Хранения:**
- Parquet: Явно превосходит для большинства аналитических рабочих нагрузок. Колоночная природа, эффективное сжатие, нативная интеграция Field IDs Iceberg для схемы эволюции и широкая поддержка делают его выбором по умолчанию и наиболее рекомендуемым.
- ORC: Достойная альтернатива Parquet, особенно если ваша инфраструктура уже использует ORC. Однако, учитывая нюансы отображения типов и общий тренд, Parquet часто является предрочтительнее для новых проектов.
- Avro: Категорически не подходит для хранения
данныханалитических таблиц. Несмотря на то, что Iceberg использует Avro для своих метаданных, применение его для самих данных приведет к крайне низкой производительности и высоким затратам.
- Алгоритмы Сжатия:**
- Snappy: Отличный компромисс между скоростью и степенью сжатия. Хорош для большинства активных данных, где скорость доступа критична.
- ZSTD: Предпочтителен, если снижение затрат на хранение является приоритетом, и вы готовы к небольшому увеличению использования CPU. Начинает обгонять Snappy по популярности для многих сценариев.
- GZIP: Избегайте для активных данных из-за низкой скорости декомпрессии. Используйте только для долгосрочного архивирования.
- Конфигурация:**
- Партиционирование: Критично для ускорения запросов. Выбирайте его с умом, основываясь на шаблонах запросов и объеме данных.
- Версия формата Iceberg (v2): Используйте для новых таблиц, чтобы получить доступ к последним возможностям.
- Целевой размер файлов (`write_target_data_file_size_bytes`): Настройте в диапазоне 128MB-1GB, чтобы избежать проблемы маленьких файлов и обеспечить хороший параллелизм Trino.
- Параметры сжатия и размера блоков Parquet: Настройте такие параметры, как `parquet_row_group_size` и `parquet_compression` для дальнейшей оптимизации.
Используя Iceberg с Trino, вы получаете мощную комбинацию для создания высокопроизводительных, надежных и управляемых озер данных. Тщательный выбор форматов хранения, алгоритмов сжатия и тонкая настройка конфигурации будут ключами к максимальному использованию потенциала этих технологий, обеспечивая оптимальную производительность запросов при контролируемых затратах. Начните с Parquet и Snappy/ZSTD, а затем адаптируйте конфигурацию в зависимости от ваших конкретных рабочих нагрузок и требований к стоимости.
Ставим +1 https://github.com/trinodb/trino/issues/25142 если хотим поддержки zstd level 1