
Искусство скорости: Руководство по оптимизации для аналитики в Data Lakehouse с DuckDB

DuckDB завоевал огромную популярность как “SQLite для аналитики”. Это невероятно быстрый, встраиваемый, колоночный движок, который не требует отдельного сервера. Однако его мощь по-настоящему раскрывается, когда он получает доступ к данным эффективно. Просто натравить DuckDB на петабайтный дата-лейк без подготовки — это рецепт для медленных запросов и высоких затрат.
Как же построить мост между огромным хранилищем данных и молниеносной интерактивной аналитикой, которую обещает DuckDB?
В этой статье рассмотрим три фундаментальных архитектурных подхода к организации доступа к данным для DuckDB. Но прежде чем мы погрузимся в то, как *читать* данные, давайте поговорим о том, как их *готовить*.
Большая картина: Подготовка данных с помощью Trino
Данные в вашем Lakehouse не появляются из ниоткуда. Они поступают из операционных баз данных, потоков событий (Kafka), логов и десятков других источников. Прежде чем DuckDB сможет их эффективно запросить, эти данные нужно собрать, очистить, трансформировать и, что самое важное, организовать в надежный и производительный формат.
Здесь на сцену выходит Trino (ранее известный как PrestoSQL).
Что такое Trino? Это мощный распределенный SQL-движок, созданный для выполнения запросов к гетерогенным источникам данных. Его суперсила — способность “на лету” объединять данные из PostgreSQL, Kafka, Hive, MySQL и многих других систем.
Роль Trino в Lakehouse: В современной архитектуре Trino часто выступает в роли “фабрики данных”. Он выполняет тяжелую работу по ETL/ELT (Extract, Transform, Load), подготавливая данные для аналитических инструментов вроде DuckDB.
Типичный сценарий использования:
- Источники: У вас есть события о прослушивании треков в Kafka, а информация о пользователях — в базе данных PostgreSQL.
- Задача: Создать единую, денормализованную таблицу Iceberg для аналитики.
- Решение с Trino: Вы настраиваете в Trino коннекторы к Kafka и PostgreSQL. Затем вы запускаете периодический SQL-запрос, который читает данные из обоих источников, объединяет их и записывает результат в новую или существующую таблицу Iceberg.
-- Этот запрос выполняется в Trino, а не в DuckDB!
INSERT INTO iceberg_catalog.analytics.daily_user_activity
SELECT
u.user_id,
u.country,
e.event_timestamp,
e.track_id,
e.duration_ms
FROM
postgres_catalog.public.users u
JOIN
kafka_catalog.raw_data.listen_events e ON u.user_id = e.user_id
WHERE
e.event_date = CURRENT_DATE;Как отмечается в одном из руководств, именно такой `INSERT INTO ... SELECT ...` является типичным способом перемещения данных в Iceberg с помощью Trino.
Итог: Trino работает “глубоко в машинном отделении” вашего Lakehouse. Он берет на себя тяжелые, распределенные задачи по преобразованию данных, а DuckDB получает на вход уже чистые, структурированные и оптимизированные для чтения таблицы Iceberg.
Теперь, когда данные готовы, давайте рассмотрим, как их лучше всего потреблять.
Подход 1: Табличные форматы (Iceberg) — Читайте только то, что нужно
Это самый продвинутый и рекомендуемый подход для серьезной аналитики, особенно в serverless-архитектуре.
- Как это работает: Вместо того чтобы работать с “россыпью” файлов Parquet, вы работаете с логической таблицей, управляемой Apache Iceberg. Расширение `iceberg` в DuckDB использует метаданные Iceberg для интеллектуального отсечения ненужных файлов (partition pruning) и блоков данных (predicate pushdown), читая с диска минимально необходимый объем информации.
- Архитектура: `Данные на S3 -> Trino (ETL) -> Таблица Iceberg -> DuckDB (Аналитика)`
Назначение и сценарии использования:
- Serverless-аналитика: Основной кейс. AWS Lambda или Google Cloud Function, оснащенная DuckDB, выполняет SQL-запрос к озеру данных. Благодаря Iceberg, функция читает всего несколько мегабайт вместо гигабайт, что делает ее выполнение быстрым (<1 сек) и дешевым.
- Локальная разработка и BI: Аналитик данных или инженер открывает Jupyter Notebook на своем ноутбуке. С помощью DuckDB он подключается напрямую к производственному Lakehouse и выполняет исследовательский анализ, не создавая копий данных и не перегружая кластеры.
- Встраиваемая аналитика: Backend-сервис на Python или Node.js, которому нужно быстро отвечать на аналитические вопросы (например, “показать статистику пользователя за последний месяц”). Он использует DuckDB для прямого запроса к Lakehouse без обращения к промежуточной базе данных.
Подход 2: RPC-стриминг (Apache Arrow Flight) — Прямой канал к данным
Иногда вам не нужна вся мощь Iceberg, а нужно просто эффективно выполнить запрос на удаленном экземпляре DuckDB и получить результат.
- Как это работает: Вы запускаете сервер, который инкапсулирует DuckDB. Клиент и сервер общаются по протоколу Arrow Flight — высокопроизводительному фреймворку для стриминга колоночных данных в формате Apache Arrow без затрат на сериализацию.
- Архитектура: `Клиент -> Arrow Flight RPC -> Сервер с DuckDB -> Данные (любой источник)`
Назначение и сценарии использования:
- Интерактивные дашборды: Веб-интерфейс (React, Vue) должен строить графики в реальном времени. Он отправляет SQL-запросы на Flight-сервер и получает данные для отрисовки практически мгновенно, без “тяжести” HTTP/JSON.
- API-шлюз для данных: Централизация доступа к данным для множества внутренних микросервисов. Вместо того чтобы каждый сервис имел свои креды и логику подключения к БД, они обращаются к единому, стабильному Flight API.
- Кросс-языковое взаимодействие: Сервис на Java должен получить результаты вычислений из BI-системы, построенной на Python и DuckDB. Arrow Flight обеспечивает эффективный и стандартизированный мост между ними.
Подход 3: “API поверх данных” (ROAPI & DataFusion) — Декларативная альтернатива
Что, если вам не нужна вся гибкость SQL, а нужен стандартный REST или GraphQL API поверх ваших данных без строчки кода? Здесь на сцену выходит ROAPI.
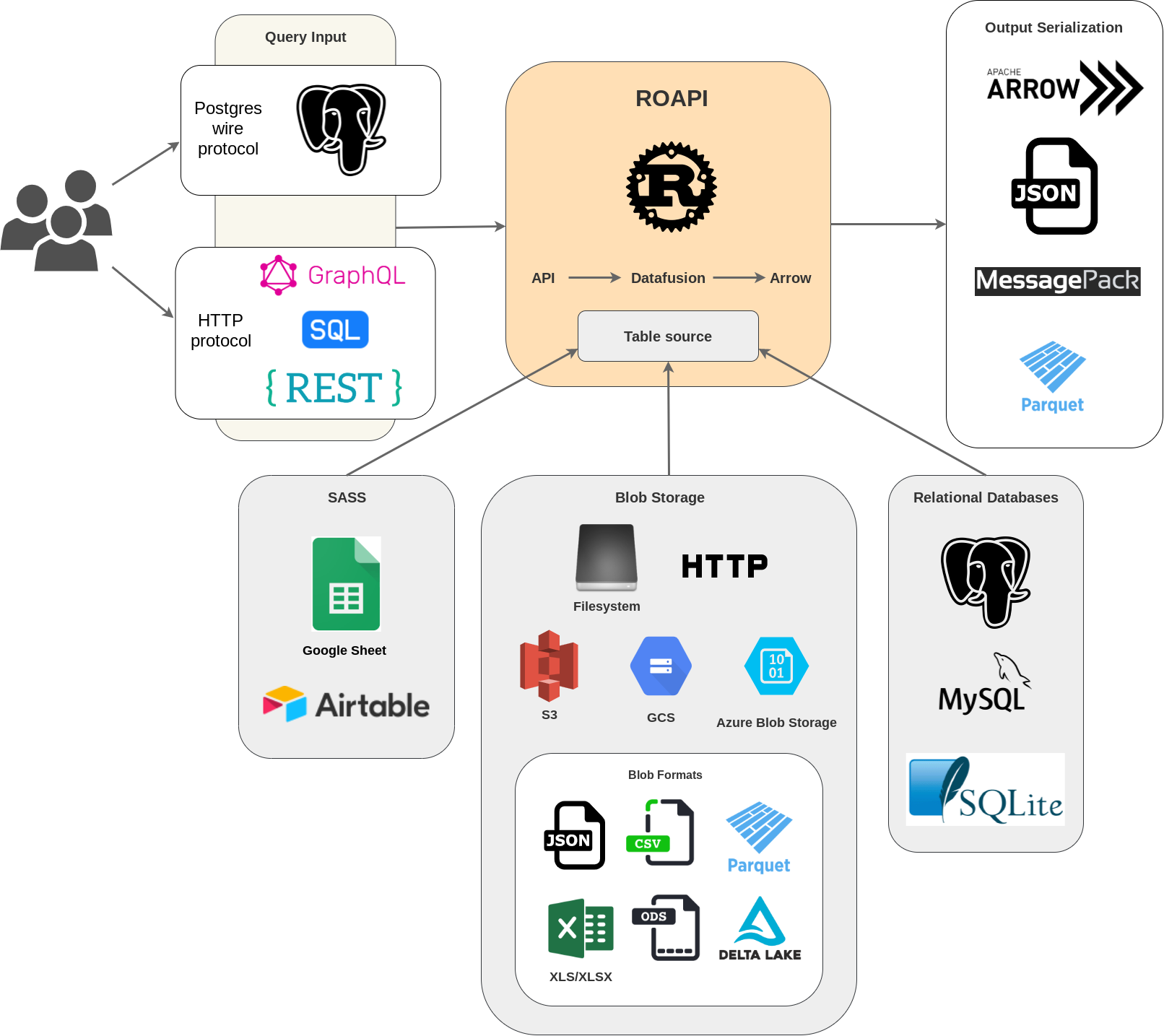
- Как это работает: ROAPI — это инструмент, который автоматически создает API, читая конфигурационный YAML-файл, где вы описываете ваши данные (Parquet, CSV и т.д.). Под капотом он использует Apache Arrow DataFusion, движок запросов, написанный на Rust, являющийся идейным братом DuckDB.
- Архитектура: `Клиент (HTTP/GraphQL) -> ROAPI Server -> Данные (файлы)`
Назначение и сценарии использования:
- Быстрое прототипирование: Вам нужно за 5 минут предоставить команде фронтенда API для нового набора данных. Вы пишете 10 строк в YAML, запускаете ROAPI — и API готов.
- Простые микросервисы данных: Сервис, единственная задача которого — раздавать данные из файла с поддержкой фильтрации и пагинации. ROAPI делает это из коробки, избавляя вас от написания рутинного кода на FastAPI или Express.js.
- Дата-фиды для внешних систем: Предоставление стандартизированного API для партнерской системы, которая умеет работать с REST, но не умеет читать Parquet.
и еще немного про DuckDB
1. Читайте меньше данных (Золотое правило)
- Используйте Iceberg: Это лучший способ.
- Проекция колонок (`SELECT col1, col2...`): Никогда не используйте `SELECT *`.
- Проталкивание предикатов (`WHERE`): Пишите максимально конкретные фильтры. DuckDB автоматически проталкивает их в сканеры Parquet и Iceberg. Используйте `EXPLAIN` для проверки того, что фильтры применяются на этапе сканирования.
2. Оптимизация SQL-запросов
- Материализация промежуточных результатов: Если вы делаете несколько агрегаций над одним и тем же отфильтрованным срезом, сохраните его во временную таблицу с помощью `CREATE TEMP TABLE ... AS`.
- Используйте `COPY` для массовой загрузки: При загрузке данных в DuckDB `COPY` на порядки быстрее, чем `INSERT`.
- Предварительная агрегация: Для сверхбольших данных создавайте “витрины” с помощью Trino (см. выше) или DuckDB, а запросы стройте уже по ним.
3. Настройка окружения DuckDB
- Управление памятью: `SET memory_limit = ‘1GB’;` — обязательная настройка в Lambda и контейнерах.
- Параллелизм: `SET threads = 4;` — адаптируйте количество потоков под vCPU вашего окружения.
- Настройка `httpfs` для S3: Настройте регион (`s3_region`), креды и включите кэширование метаданных, чтобы не перечитывать их при каждом запуске. ( Это комьюнити дополнение -cache_httpfs, см. ниже “Проблема Шторм” )
Еще вот тут можно почитать: https://duckdb.org/docs/stable/guides/performance/how_to_tune_workloads
Заключение: Какой подход выбрать?
Выбор архитектуры зависит от вашей задачи. Каждая из них занимает свою нишу в стеке современной инженерии данных.
| Подход | Ключевая технология | Когда использовать |
| Табличный формат | Trino (Подготовка) + DuckDB/Iceberg (Потребление) | Стандарт для Lakehouse. Нужна строгая структура, надежность и максимальная производительность для аналитических SQL-запросов от различных инструментов. |
| RPC-стриминг | DuckDB + Arrow Flight | Нужен быстрый интерактивный SQL-доступ к удаленному экземпляру DuckDB, например, для дашборда или кастомного клиента. |
| API поверх данных | ROAPI + DataFusion | Нужно быстро и без кода поднять стандартный `REST`/`GraphQL` API поверх наборов данных для прототипирования или простых микросервисов. |
Проблема Шторм из GET-запросов к S3
Давайте представим, что вы выполняете запрос к таблице Iceberg или просто к набору из 1000 файлов Parquet на S3:
SELECT count(*)
FROM read_parquet('s3://my-bucket/data/*.parquet')
WHERE event_type = 'click';Чтобы выполнить этот запрос с максимальной эффективностью (с “проталкиванием предиката”), DuckDB должен сделать следующее, *прежде чем* читать основные данные:
- Получить список всех 1000 файлов.
- Для каждого из 1000 файлов прочитать его метаданные (футер). Футер Parquet-файла — это небольшой блок в конце файла, содержащий схему и, что самое важное, статистику по колонкам (min/max значения).
- Проанализировав футер, DuckDB понимает, может ли в этом файле вообще содержаться `event_type = ‘click’`. Если статистика говорит, что в файле есть только типы `’view’` и `’purchase’`, утка его пропустит.
Проблема в том, что для чтения футера каждого файла DuckDB должен отправить отдельный HTTP `GET` запрос с указанием диапазона байт (range request) к S3. То есть, один SQL-запрос порождает 1000+ мелких HTTP-запросов. Это может быть медленно и может быть дорого, так как в S3 вы платите за каждый `GET` запрос.
Кэширование метаданных решает именно эту проблему: оно сохраняет результаты этих мелких запросов на локальный диск, чтобы при повторном обращении к тем же файлам DuckDB брал их из локального кэша, а не летел снова в S3.
Решение: Комьюнити-расширение `cache_httpfs`
Для реализации постоянного, дискового кэширования в DuckDB используется специальное комьюнити-расширение `cache_httpfs`. Оно работает как “обертка” над стандартным `httpfs`.
Основная идея: Вы говорите DuckDB использовать `cache_httpfs` в качестве клиента для HTTP-запросов. Этот клиент сначала проверяет, нет ли уже нужного блока данных (например, футера Parquet-файла) в локальном кэше. Если есть — отдает его мгновенно. Если нет — идет в S3, скачивает блок, сохраняет его в кэш и отдает DuckDB.
Вот как это настроить:
Шаг 1: Установка и загрузка расширений
Вам понадобятся три расширения: `httpfs` (для работы с S3), `cache_httpfs` (для кэширования) и, если вы работаете с Iceberg, то и `iceberg`.
INSTALL httpfs;
INSTALL cache_httpfs;
LOAD httpfs;
LOAD cache_httpfs;Шаг 2: Активация кэширующего клиента
Это ключевой шаг. Вы должны указать DuckDB использовать `cache_httpfs` для всех HTTP-операций.
SET httpfs_client = 'cached_httpfs';Шаг 3: Настройка пути к кэшу (критически важно для Serverless)
По умолчанию `cache_httpfs` сохраняет кэш в директорию `~/.cache/duckdb/`. Это хорошо работает на локальной машине, но в serverless-окружениях (AWS Lambda, Cloud Functions) эта папка либо недоступна для записи, либо является эфемерной.
В serverless-среде единственное гарантированно доступное для записи место — это директория `/tmp`.
SET cache_httpfs_cache_path = '/tmp/duckdb_cache';Этот кэш в `/tmp` будет “жить” между “теплыми” вызовами вашей Lambda-функции. Если одна и та же функция вызывается несколько раз подряд, второй и последующие вызовы будут использовать уже заполненный кэш, что кардинально ускорит выполнение запросов к одним и тем же данным.
Полный пример конфигурации (Python)
import duckdb
# Подключаемся к базе данных
con = duckdb.connect()
# Устанавливаем и загружаем расширения
con.execute("INSTALL httpfs;")
con.execute("INSTALL cache_httpfs;")
con.execute("LOAD httpfs;")
con.execute("LOAD cache_httpfs;")
# --- Настройка S3 и кэша ---
# 1. Настройте креды для S3 (если не используются IAM-роли)
# con.execute("SET s3_access_key_id='YOUR_KEY';")
# con.execute("SET s3_secret_access_key='YOUR_SECRET';")
con.execute("SET s3_region='us-east-1';")
# 2. Активируем кэширующий http-клиент
con.execute("SET httpfs_client = 'cached_httpfs';")
# 3. Указываем путь к директории кэша (обязательно для serverless)
con.execute("SET cache_httpfs_cache_path = '/tmp/duckdb_http_cache';")
# --- Выполняем запрос ---
# Первый запуск этого запроса будет медленнее,
# так как он заполнит кэш метаданными файлов.
result1 = con.execute("SELECT count(*) FROM 's3://my-bucket/data/*.parquet'").fetchone()
print(f"Первый запуск: {result1[0]}")
# Второй запуск будет на порядки быстрее,
# так как все метаданные будут прочитаны из локального кэша в /tmp.
result2 = con.execute("SELECT count(*) FROM 's3://my-bucket/data/*.parquet'").fetchone()
print(f"Второй запуск (с кэшем): {result2[0]}")Сравнение: Встроенный кэш vs `cache_httpfs`
Стоит отметить, что стандартный `httpfs` тоже имеет небольшой *внутренний, оперативный кэш*, но его возможности ограничены.
| Параметр | Встроенный кэш `httpfs` | Расширение `cache_httpfs` |
| Тип | Внутренний, в памяти | Явный, на диске |
| Жизненный цикл | Живет в рамках одного соединения (connection). При переподключении кэш пуст. | Живет между сессиями и процессами. Сохраняется на диске до очистки. |
| Назначение | Ускорение повторных запросов в одной и той же длительной сессии. | Радикальное ускорение для любых повторных запросов, особенно в serverless (warm starts) и при локальной разработке. |
| Активация | Включен по умолчанию | Требует `SET httpfs_client = ‘cached_httpfs’;` |
| Настройка | Не настраивается | Настраивается путь (`cache_httpfs_cache_path`) и максимальный размер. |
Для серьезной работы с данными на S3, особенно в serverless-архитектуре, использование расширения `cache_httpfs` является приятным дополнением и зачастую обязательным. Это та самая “серебряная пуля”, которая убирает узкое место в виде задержек сети и большого количества API-вызовов к облачному хранилищу.
Начиная с тяжелых ETL-процессов на Trino и заканчивая быстрыми запросами в DuckDB, современный стек данных предлагает невероятную гибкость и производительность. Выбрав правильный инструмент или их комбинацию для каждой задачи, можно построить по-настоящему эффективную и масштабируемую аналитическую платформу.
