
Как Binance строил 100PB сервис для обработки логов на Quickwit
Оригинал: https://quickwit.io/blog/quickwit-binance-story
Три года назад мы открыли исходный код Quickwit, распределенного поискового движка для работы с большими объемами данных. Наша цель была амбициозной: создать новый тип полнотекстового поискового движка, который был бы в десять раз более экономичным, чем Elasticsearch, значительно проще в настройке и управлении, и способным масштабироваться до петабайт данных.
Хотя мы знали потенциал Quickwit, наши тесты обычно не превышали 100 ТБ данных и 1 ГБ/с скорости индексации. У нас не было реальных наборов данных и вычислительных ресурсов для тестирования Quickwit в масштабе нескольких петабайт.
Это изменилось шесть месяцев назад, когда два инженера из Binance, ведущей криптовалютной биржи, обнаружили Quickwit и начали экспериментировать с ним. В течение нескольких месяцев они достигли того, о чем мы только мечтали: они успешно перенесли несколько кластеров Elasticsearch объемом в петабайты на Quickwit, достигнув при этом следующих результатов:
- Масштабирование индексации до 1,6 ПБ в день.
- Операция поискового кластера, обрабатывающего 100 ПБ логов.
- Экономия миллионов долларов ежегодно за счет сокращения затрат на вычисления на 80% и затрат на хранение в 20 раз (при том же периоде хранения).
- Значительное увеличение возможностей хранения данных.
- Упрощение управления и эксплуатации кластера благодаря хорошо спроектированной многокластерной установке.
В этом блоге я расскажу вам, как Binance построила сервис логов объемом в петабайты и преодолела вызовы масштабирования Quickwit до нескольких петабайт.
Вызов Binance
Как ведущая криптовалютная биржа, Binance обрабатывает огромное количество транзакций, каждая из которых генерирует логи, важные для безопасности, соответствия и оперативных аналитических данных. Это приводит к обработке примерно 21 миллиона строк логов в секунду, что эквивалентно 18,5 ГБ/с или 1,6 ПБ в день.
Для управления таким объемом Binance ранее полагалась на 20 кластеров Elasticsearch. Около 600 модулей Vector извлекали логи из различных тем Kafka и обрабатывали их перед отправкой в Elasticsearch.
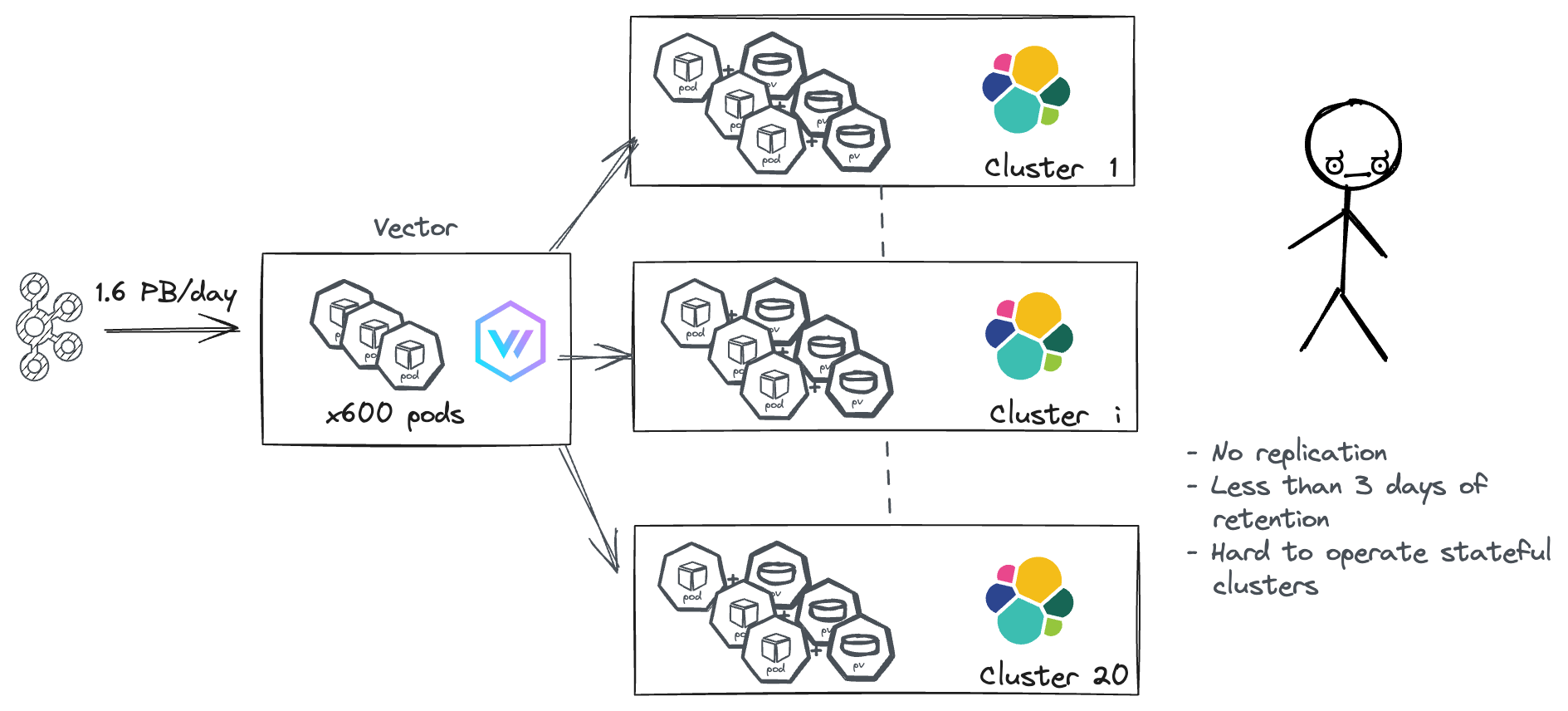
Настройка Elasticsearch в Binance
Однако эта установка не удовлетворяла требованиям Binance в нескольких критических областях:
- Операционная сложность: Управление многочисленными кластерами Elasticsearch становилось все более сложным и трудоемким.
- Ограниченное хранение: Binance хранила большинство логов только несколько дней. Их целью было продлить этот срок до месяцев, что требовало хранения и управления 100 ПБ логов, что было чрезвычайно дорого и сложно с их настройкой Elasticsearch.
- Ограниченная надежность: Кластеры Elasticsearch с высокой пропускной способностью были настроены без репликации для ограничения затрат на инфраструктуру, что компрометировало долговечность и доступность.
Команда знала, что им нужно радикальное изменение, чтобы удовлетворить растущие потребности в управлении, хранении и анализе логов.
Почему Quickwit был (почти) идеальным решением
Когда инженеры Binance обнаружили Quickwit, они быстро поняли, что он предлагает несколько ключевых преимуществ по сравнению с их текущей установкой:
- Нативная интеграция с Kafka: Позволяет инжектировать логи непосредственно из Kafka с семантикой “ровно один раз”, что дает огромные операционные преимущества.
- Встроенные преобразования VRL (Vector Remap Language): Поскольку Quickwit поддерживает VRL, нет необходимости в сотнях модулей Vector для обработки преобразований логов.
- Объектное хранилище в качестве основного хранилища: Все проиндексированные данные остаются в объектном хранилище, устраняя необходимость в предоставлении и управлении хранилищем на стороне кластера.
- Лучшее сжатие данных: Quickwit обычно достигает в 2 раза лучшего сжатия, чем Elasticsearch, что еще больше сокращает занимаемое место индексами.
Однако ни один пользователь не масштабировал Quickwit до нескольких петабайт, и любой инженер знает, что масштабирование системы в 10 или 100 раз может выявить неожиданные проблемы. Это не остановило их, и они были готовы принять вызов!

Поиск в 100 ПБ, вызов принят
Масштабирование индексации на 1,6 ПБ в день
Binance быстро масштабировала свою индексацию благодаря источнику данных Kafka. Через месяц после начала пилотного проекта Quickwit они индексировали на нескольких ГБ/с.
Этот быстрый прогресс был в значительной степени обусловлен тем, как Quickwit работает с Kafka: Quickwit использует группы потребителей Kafka для распределения нагрузки между несколькими модулями. Каждый модуль индексирует подмножество партиций Kafka и обновляет метахранилище с последними смещениями, обеспечивая семантику “ровно один раз”. Эта установка делает индексаторы Quickwit безсостоятельными: вы можете полностью разобрать свой кластер и перезапустить его, и индексаторы возобновят работу с того места, где они остановились, как будто ничего не произошло.
Однако масштаб Binance выявил две основные проблемы:
- Проблемы со стабильностью кластера: Несколько месяцев назад протокол переговоров Quickwit (называемый Chitchat) с трудом справлялся с сотнями модулей: некоторые индексаторы покидали кластер и возвращались, делая пропускную способность индексации нестабильной.
- Неоднородное распределение нагрузки: Binance использует несколько индексов Quickwit для своих логов, с различной пропускной способностью индексации. Некоторые имеют высокую пропускную способность в несколько ГБ/с, другие – всего несколько МБ/с. Алгоритм размещения Quickwit не распределяет нагрузку равномерно. Это известная проблема, и мы будем работать над этим позже в этом году.
Чтобы обойти эти ограничения, Binance развернула отдельные кластеры индексации для каждой темы с высокой пропускной способностью, сохраняя один кластер для меньших тем. Изоляция каждого кластера с высокой пропускной способностью не накладывала операционного бремени благодаря безсостоятельным индексаторам. Кроме того, все модули Vector были удалены, так как Binance использовала преобразование Vector непосредственно в Quickwit.
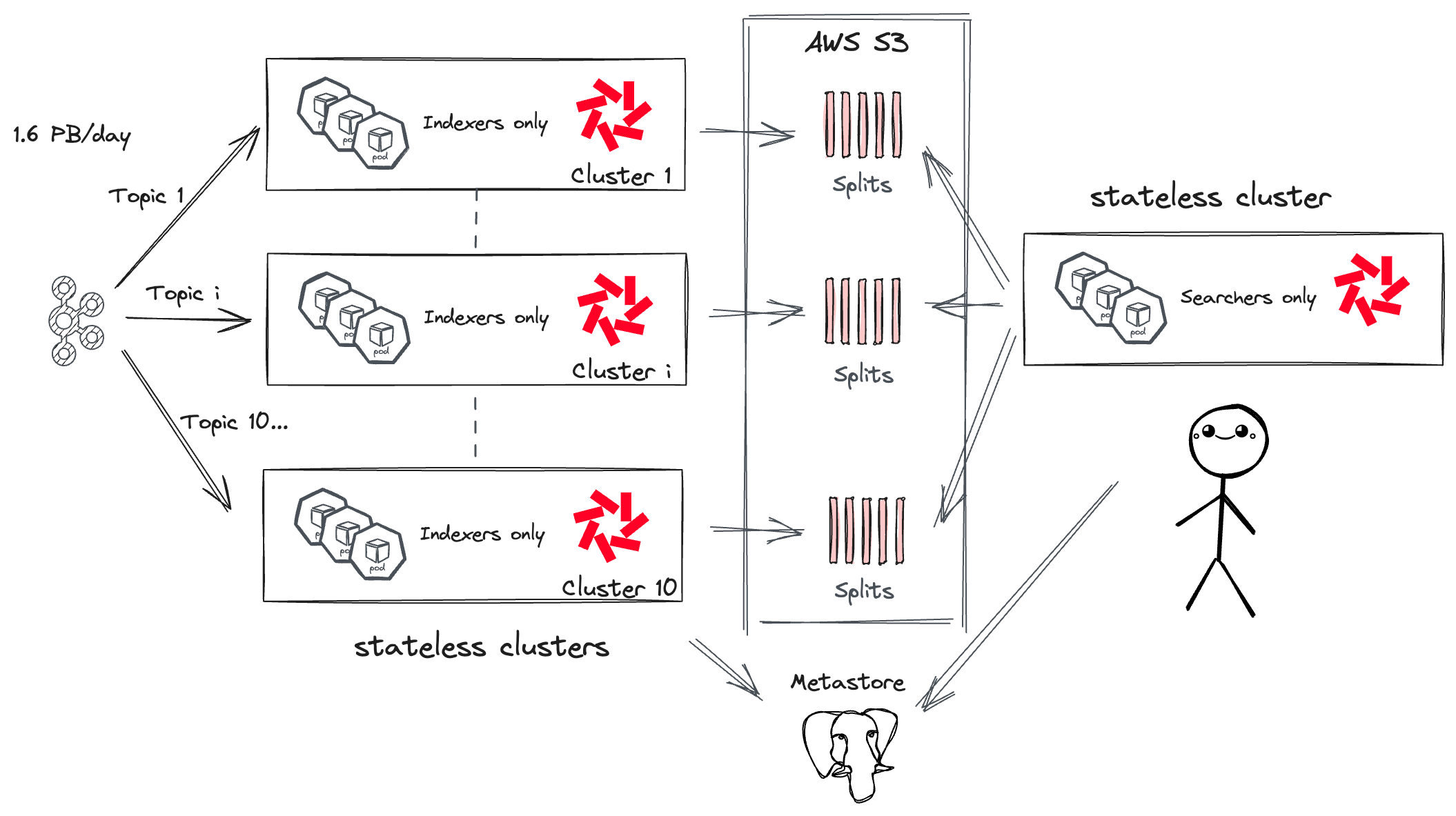
Настройка Quickwit в Binance
После нескольких месяцев миграции и оптимизации Binance наконец достигла пропускной способности индексации в 1,6 ПБ с 10 кластерами индексации Quickwit, 700 модулями, запрашивающими около 4000 vCPU и 6 ТБ памяти, что в среднем составляет 6,6 МБ/с на vCPU. На заданной теме Kafka с высокой пропускной способностью этот показатель увеличивается до 11 МБ/с на vCPU.
Следующий вызов: масштабирование поиска!
Один поисковый кластер для 100 ПБ логов
С Quickwit, способным эффективно индексировать 1,6 ПБ ежедневно, вызов сместился к поиску по петабайтам логов. С 10 кластерами Binance обычно потребовалось бы развернуть модули поиска для каждого кластера, что подрывало одно из преимуществ Quickwit: объединение ресурсов поиска для доступа к общему объектному хранилищу всех индексов.
Чтобы избежать этой ловушки, инженеры Binance придумали умный обходной путь: они создали унифицированное метахранилище, реплицируя все метаданные из метахранилища каждого кластера индексации в одну базу данных PostgreSQL. Это унифицированное метахранилище позволяет развернуть один единственный централизованный поисковый кластер, способный искать по всем индексам!
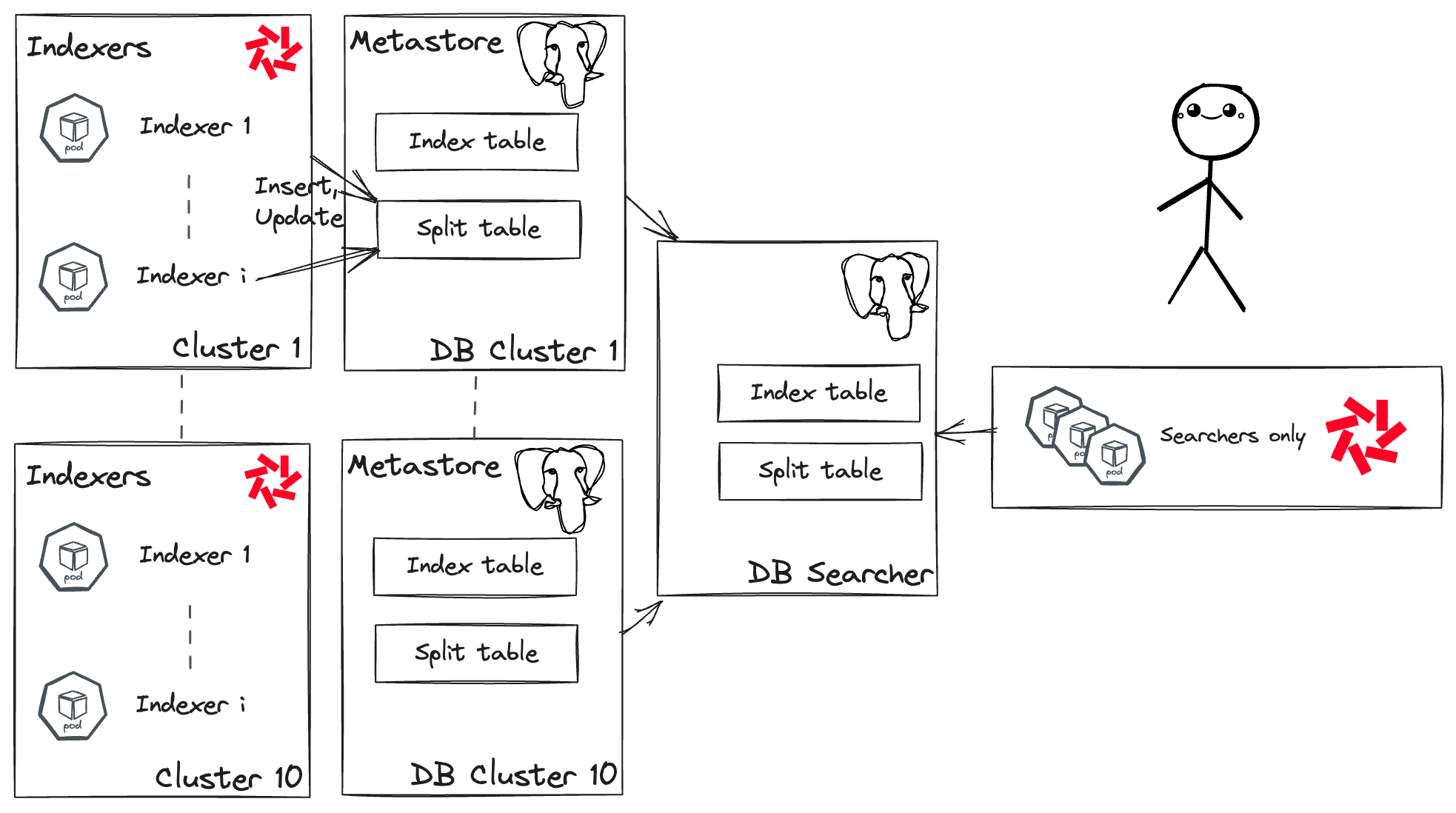
Многокластерная установка Quickwit
На данный момент Binance управляет разумно размером кластером из 30 модулей поиска, каждый из которых запрашивает 40 vCPU и 100 ГБ памяти. Чтобы дать вам представление, вам нужно всего 5 поисковиков (8 vCPU, 6 ГБ запросов памяти) для нахождения иголки в стоге сена в 400 ТБ логов. Binance выполняет такие запросы на петабайтах, а также запросы агрегации, отсюда и более высокие запросы ресурсов.
Заключение
В целом, миграция Binance на Quickwit была огромным успехом и принесла несколько существенных преимуществ:
- Сокращение вычислительных ресурсов на 80% по сравнению с Elasticsearch.
- Затраты на хранение сократились в 20 раз при том же периоде хранения.
- Экономически жизнеспособное решение для управления большими объемами логов, как с точки зрения затрат на инфраструктуру, так и эксплуатации.
- Минимальная настройка конфигурации, эффективно работающая после определения правильного количества модулей и ресурсов.
- Увеличение хранения логов до одного или нескольких месяцев в зависимости от типа лога, улучшение возможностей внутренней диагностики.
В заключение, миграция Binance с Elasticsearch на Quickwit была захватывающим шестимесячным опытом между инженерами Binance и Quickwit, и мы очень гордимся этим сотрудничеством. Мы уже запланировали улучшения в сжатии данных, поддержке многокластерных систем и лучшем распределении нагрузки с источниками данных Kafka.
Большое спасибо инженерам Binance за их работу и идеи в ходе этой миграции <3