
Мир без Kafka: Почему Kafka не подходит для аналитики реального времени, что идет на смену)
Статья описывает переход от традиционных систем обмена сообщениями, таких как Apache Kafka, к специализированным решениям для потоковой аналитики, таким как Apache Fluss.
Основные тезисы:
- Проблема Kafka: Kafka — это система хранения на основе *записей* (record-based), не имеющая нативной поддержки схем и аналитических возможностей. Это приводит к избыточному чтению данных и перегрузке сети при аналитических запросах, когда нужны только конкретные колонки, а не всё сообщение целиком.
- Эволюция требований: Рынок перешел от простого перемещения данных (ingestion) к сложной аналитике реального времени и AI, что требует более эффективного хранения и доступа к данным.
- Решение (Apache Fluss):
- Табличная структура:** Данные хранятся как таблицы (Log Tables для логов и PK Tables для изменяемых данных), что обеспечивает строгую типизацию.
- Колоночное хранение:** Использование формата Apache Arrow позволяет читать только нужные колонки (projection pushdown) и эффективнее сжимать данные, что снижает нагрузку на диск и сеть.
- Интеграция с Lakehouse:** Fluss нативно поддерживает многоуровневое хранение (горячие данные в Fluss, теплые/холодные в S3/Iceberg/Paimon) без лишнего копирования, обеспечивая прозрачный доступ к историческим и оперативным данным.
- Вывод: Fluss в связке с Flink предлагает более дешевую, быструю и удобную архитектуру для современной аналитики реального времени, устраняя недостатки Kafka в этой области.
Ссылка на оригинал:
Why Kafka Falls Short for Real-Time Analytics (and What Comes Next
У Apache Kafka был замечательный период: она обеспечивала работу событийно-ориентированных архитектур более десяти лет. Но ландшафт изменился, обнажив явные ограничения Kafka для аналитики в реальном времени по мере того, как сценарии использования современной потоковой аналитики и принятия решений становятся всё более требовательными. Kafka все чаще пытаются заставить выполнять функции в архитектуре аналитики реального времени, для поддержки которых она никогда не проектировалась. Чтобы решить сегодняшние проблемы конвейеров потоковой передачи данных и аналитические требования, необходимы новые возможности. Пришло время для «новичка на районе».
Во время перехода от пакетной обработки к потоковой передаче данных в реальном времени значительное внимание и импульс получил проект с открытым исходным кодом, разработанный внутри LinkedIn: Apache Kafka. Цель состояла в том, чтобы упростить перемещение данных из точки А в точку Б масштабируемым и устойчивым способом, используя модель издатель/подписчик. Kafka позволила компаниям создавать ранние конвейеры потоковой передачи данных и открыть новый класс событийно-ориентированных сценариев использования. Постоянно растущая экосистема коннекторов и интеграций ускорила внедрение и утвердила Kafka в качестве предпочтительного слоя потокового хранения. Однако, по мере того как архитектуры аналитики реального времени эволюционировали за пределы простого приема данных (ingestion), ограничения Kafka для аналитических нагрузок становились всё более очевидными.
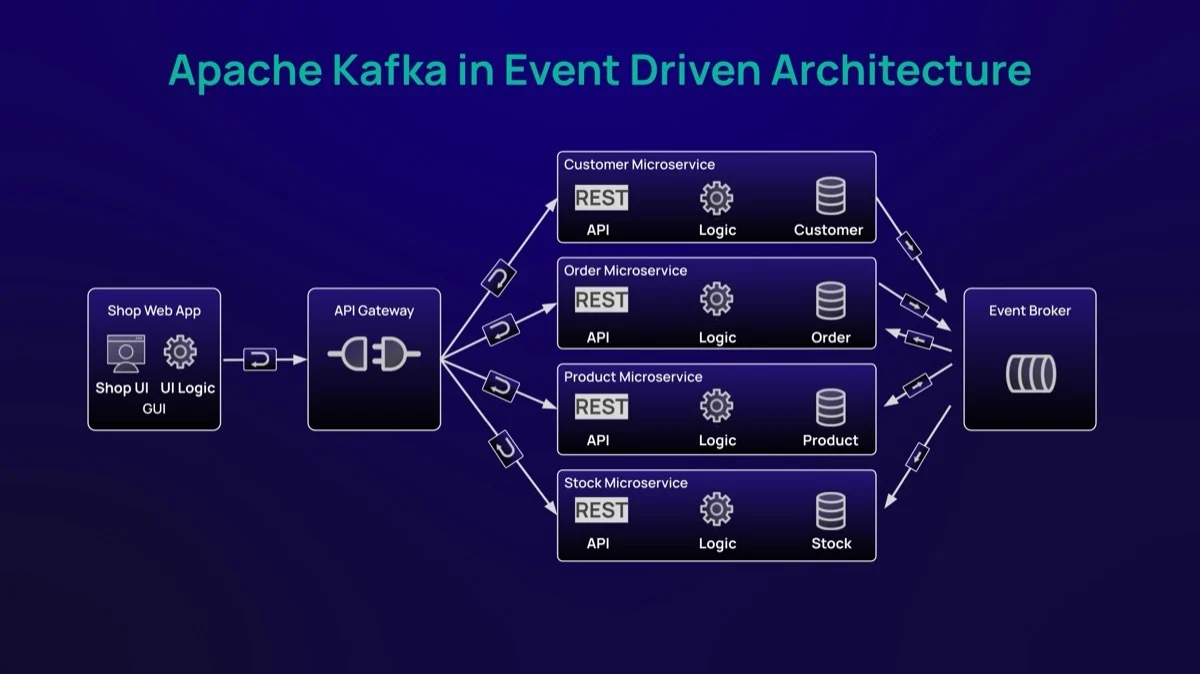
С архитектурной точки зрения Kafka — это не аналитический движок. Это устойчивая и масштабируемая система хранения на основе записей (record-based storage system) для свежих данных в реальном времени — часто называемая «горячим слоем». Следовательно, аналитические нагрузки должны выполняться за пределами кластера Kafka, постоянно перемещая данные между системами хранения и обработки, что увеличивает сетевой трафик и накладные операционные расходы. Кроме того, Kafka нативно не обеспечивает соблюдение схем для данных, публикуемых в топиках.
Хотя эта гибкость была приемлема для ранних сценариев использования потоковой передачи, современные платформы аналитики реального времени требуют схем для обеспечения согласованности, управления и качества данных. В качестве компенсации появились реестры схем (Schema Registries) для обеспечения контрактов между издателями и подписчиками, добавляя сложности аналитическим архитектурам на основе Kafka.
И последнее, но не менее важное (и, возможно, самый важный аспект): Kafka — это система хранения на основе записей. Это хорошо подходит для использования в качестве очереди сообщений, например, для приема данных в реальном времени или событийно-ориентированных архитектур, но имеет значительные ограничения при решении текущих и будущих задач проектов реального времени. Движки обработки, такие как Spark и Flink, должны потреблять все данные топика, даже если требуется только часть данных события (столбцы). Результатом является ненужный сетевой трафик, снижение производительности обработки и чрезмерные требования к хранилищу.
Компоненты потокового хранения на основе записей по-прежнему будут занимать свое место в архитектуре данных. Такие решения, как Kafka и Pulsar, хорошо подходят для случаев, требующих чтения полных записей. Архитектурные паттерны, основанные на микросервисах, могут использовать вышеуказанные решения для обмена данными, отделяя функции от транспортировки сообщений для повышения производительности, надежности и масштабируемости. Чтение полных записей также полезно для конвейеров приема данных (ingestion pipelines), в которых данные будут храниться в системах долгосрочного хранения, таких как объектное хранилище (Object Storage), для исторических и архивных целей. Узкие места и ограничения возникают, когда они используются для аналитических нагрузок, требующих возможностей, выходящих за рамки простого слоя транспорта данных.
Эволюция потоковых данных
Сегодняшний разговор движим единственным аспектом: Эволюция. Другими словами, новые потребности требуют новых подходов к управлению данными. Kafka удовлетворила первоначальные потребности в потоковой передаче данных. В этой первой волне в основном доминировали конвейеры приема данных в реальном времени и дискретная (SEP, Simple Event Processing) аналитика. По сути, способность перемещать данные из точки А в точку Б и, в некоторых случаях, выполнять простую подготовку и обработку данных между ними. Kafka, в сочетании со Spark Streaming или специальными коннекторами, справлялась с этими ранними сценариями использования.
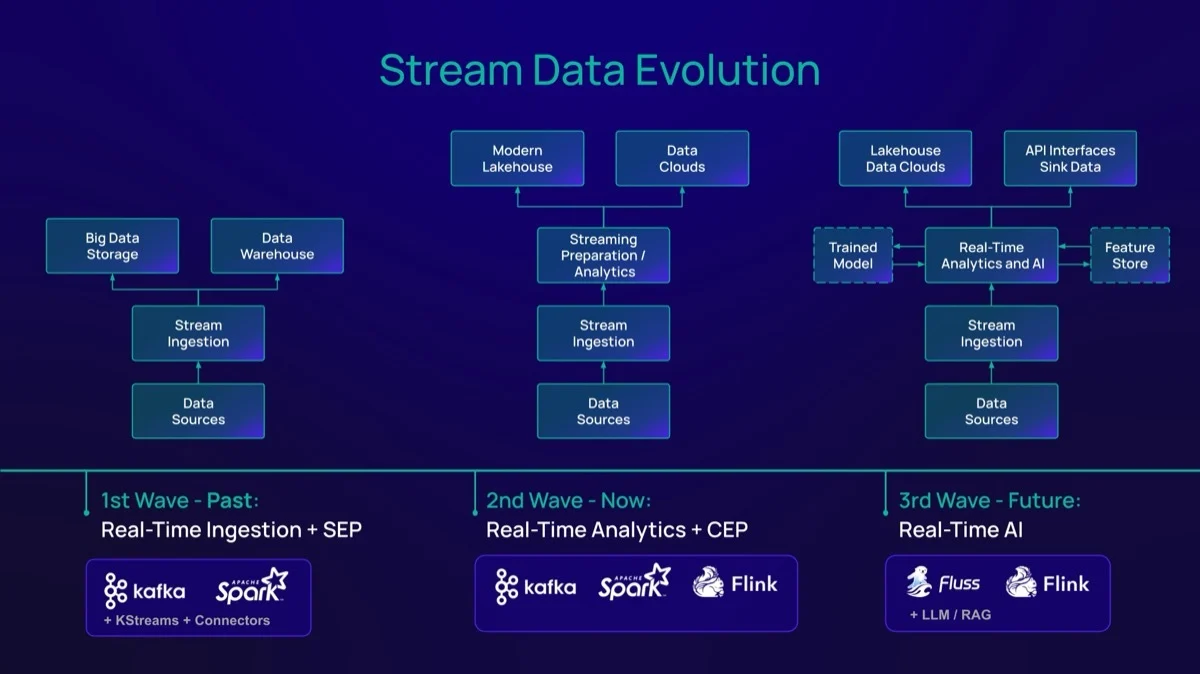
Перенесемся вперед: вторая волна привнесла сложность в потоковый конвейер. Помимо дискретной подготовки данных, сценарии использования на этом этапе требовали расширенных аналитических функций, таких как агрегация, обогащение и сложная обработка событий (CEP). Микро-батчинг (micro-batching) оказался недостаточным. Требуется новый архитектурный подход, основанный на колоночном хранении с эффективным проталкиванием проекций (projection pushdown) и прозрачным многоуровневым хранением данных (data tiering), в сочетании с движками обработки с задержкой менее секунды. `Apache Fluss` и `Apache Flink` могут выполнить это обещание и вместе составляют будущее и третью волну по шкале зрелости.
Каждая техническая статья сегодня упоминает AI/ML. Эта эволюция «третьей волны» позволяет компаниям создавать AI-конвейеры реального времени, которые внедряют передовые аналитические методы (такие как Generative AI) в потоковые данные. Это увеличивает потребность в современных системах хранения данных в реальном времени с расширенными функциями, которые распределяют данные как по быстрым потоковым, так и по историческим слоям, обеспечивая интегрированный, унифицированный доступ к бизнес-данным.
Новичок на районе
`Apache Fluss` — это современная система хранения потоковых данных в реальном времени для аналитики. Она консолидирует многолетний опыт и уроки, извлеченные из предшественников, отвечая текущим и будущим потребностям организаций. Fluss родился в эпоху, когда для питания моделей машинного обучения требуется больше данных, Лейкхаусы (Lakehouses) являются частью корпоративной экосистемы, а облачная инфраструктура является предпочтительной стратегией для компаний.

Но хранение данных — это лишь часть архитектурной головоломки. `Apache Flink` предоставляет возможности и устойчивость для обработки огромных объемов данных в реальном времени с задержкой менее секунды, обеспечивая скорость, необходимую для будущих потоковых приложений. Не ограничиваясь Flink, дополнительные движки обработки и библиотеки разрабатывают интеграции с Fluss, тем самым укрепляя экосистему.
Ниже приведены основные функции современной аналитики реального времени.
Поток как таблица (Stream as Table)
Fluss хранит данные как схематизированные таблицы. Этот подход подходит для большинства сценариев использования в реальном времени, включая те, которые опираются как на структурированные, так и на полуструктурированные данные. Структурируя потоковые данные, компании могут улучшить управление, повысить качество данных и гарантировать, что издатели и потребители используют общий язык. Fluss определяет два типа таблиц:
- Log Tables (Лог-таблицы)** работают только на добавление (append-only), аналогично топикам Kafka. Такие сценарии использования, как мониторинг логов, кликстримы (clickstreams), показания датчиков, журналы транзакций и другие, являются хорошими примерами данных только для добавления. События неизменяемы и не должны изменяться или обновляться.
- Primary Key (PK) Tables (Таблицы с первичным ключом)** — это изменяемые таблицы, определенные ключом. Записи сначала вставляются, а затем обновляются или удаляются с течением времени в соответствии с журналом изменений (changelog), который они представляют. Таблица PK хранит последние изменения всей таблицы, обеспечивая паттерн доступа «поиск записи» (record lookup). Сценарии использования журнала изменений, такие как балансы счетов, корзина покупок и управление запасами, могут извлечь выгоду из этого подхода. Kafka не может выполнять такое поведение, требуя внешних баз данных типа «ключ-значение» или NoSQL для отслеживания текущего статуса записи, что приводит к сложным и трудным в обслуживании решениям.

Вкратце, PK Tables обеспечивают уникальность записей на основе первичного ключа, операций `INSERT`, `UPDATE` и `DELETE`, а также предоставляют широкие возможности изменения записей. С другой стороны, Log Tables работают только на добавление; обновления записей не требуются.
Колоночное хранение (Columnar Storage)
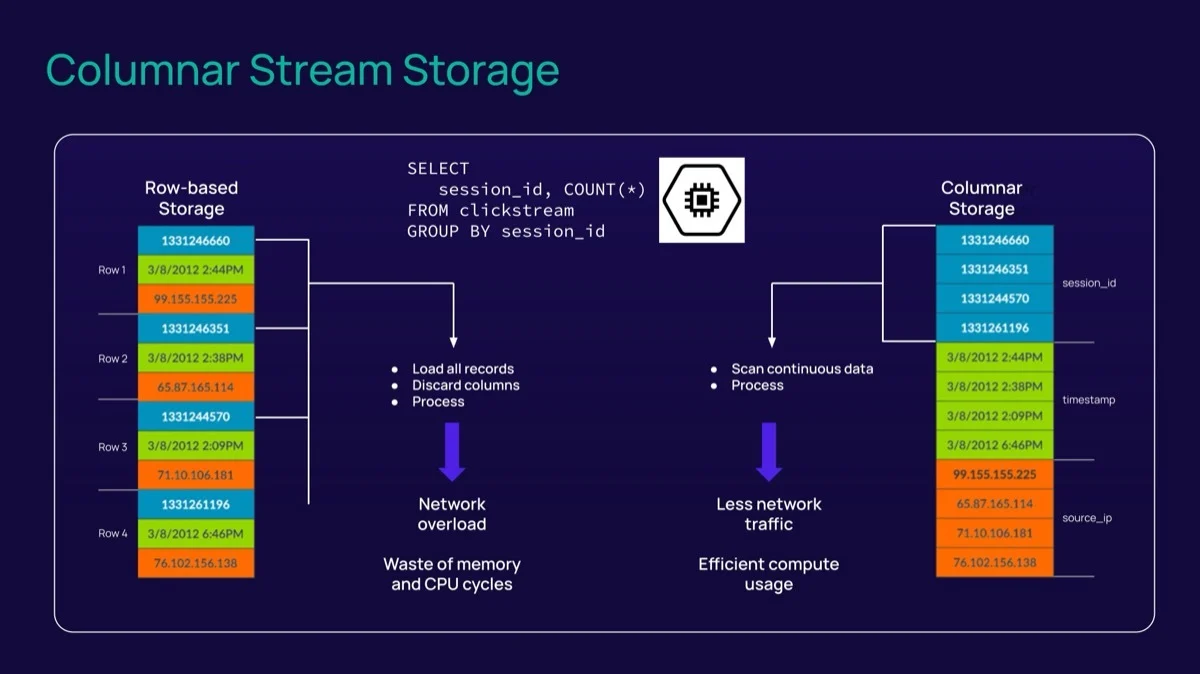
То, как Fluss хранит данные на диске, возможно, является наиболее фундаментальным архитектурным сдвигом по сравнению с другими решениями. В отличие от Kafka, Fluss использует формат `Apache Arrow` для хранения данных в колоночном формате, что дает следующие преимущества:
- Улучшенное использование хранилища**, так как хранение данных в колоночном формате требует меньше дискового пространства. Степень сжатия зависит от множества характеристик данных, но первоначальные тесты показывают многообещающее улучшение в 5 раз при использовании Apache Arrow в качестве базового формата хранения. Меньше хранилища = меньше затрат. Kafka предоставляет лишь несколько вариантов сжатия данных, которые не сравнимы с теми, что доступны в Apache Arrow «из коробки».
- Эффективные запросы с использованием обрезки столбцов (column pruning).** В общем случае запрашивается или доступно менее половины атрибутов данного бизнес-события, т.е. только те имена столбцов, которые вы добавляете в ваше выражение `SELECT FROM`. Проталкивание проекции (projection pushdown) — это метод, который удаляет ненужные атрибуты (также известный как column pruning) при извлечении данных из системы хранения. Kafka работает по принципу «все или ничего» из-за своего формата хранения на основе записей.
- И колоночное сжатие, и проталкивание проекции улучшат сетевой трафик — перемещение меньшего количества данных приведет к тому, что сетевые администраторы станут счастливее. С Kafka компании постоянно сталкиваются с перегрузкой сети и потенциально высокими расходами на исходящий трафик (egress costs).
Унификация с Lakehouse
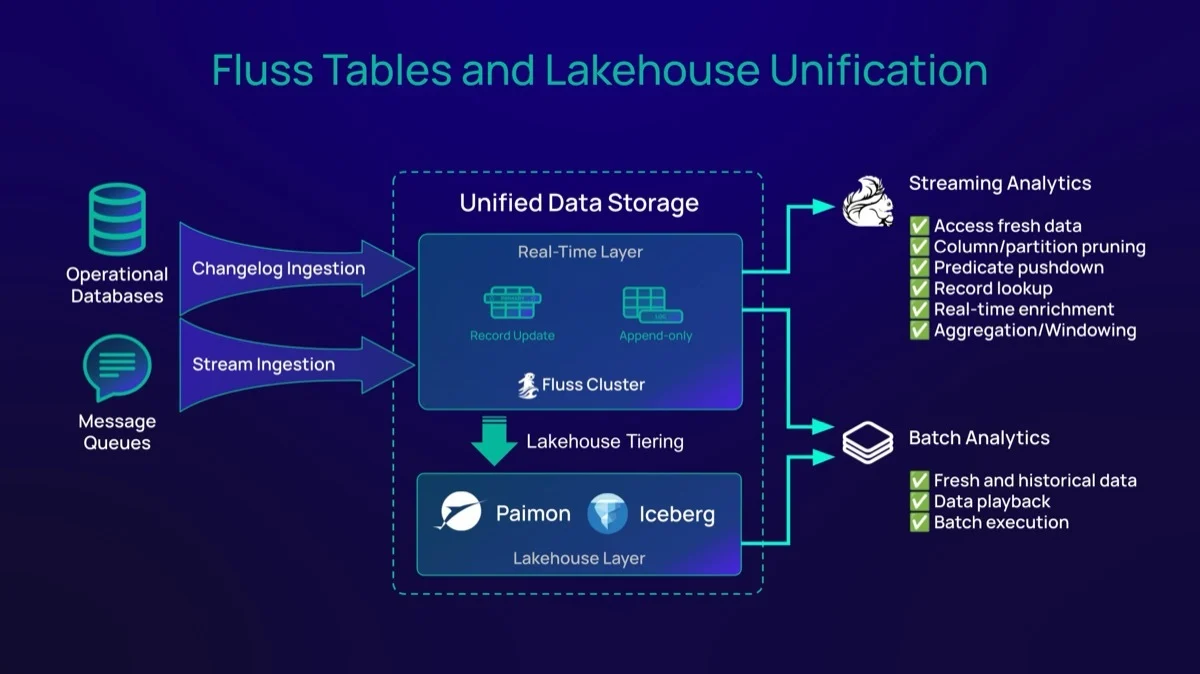
Kafka была создана в эпоху Data Lake (Озер данных). С самого начала проектирования Fluss создавался для Lakehouse. Это создает большую разницу. Компании поняли, что Озера данных (или во многих случаях «Болота данных» — Data Swamps) трудно поддерживать в рабочем состоянии и окупать инвестиции в лицензии, оборудование и персонал для создания решений больших данных. К счастью, Лейкхаусы преодолевают эти проблемы. Лейкхаусы утверждают, что данные должны быть широко и легко доступны независимо от их возраста. Пакетные события и события реального времени перекрываются, и движки обработки должны иметь возможность прозрачно обращаться к обоим слоям.
Вот возможности тиринга данных (распределения по уровням) и унифицированного просмотра, которые может предоставить Fluss, в дополнение к слою горячих/свежих данных:
- Теплый слой (Warm layer):** для данных возрастом от минут до часов, в основном хранящихся в решениях объектного хранения (Object Storage).
- Холодный слой (Cold layer):** для данных возрастом от дней до лет. Решения Lakehouse, такие как `Apache Paimon` и `Iceberg`, являются предпочтительными платформами для этих исторических данных, питающих модели ML, ретроспективную аналитику и комплаенс.
- Zero-copy data tiering (Тиринг данных без копирования):** старение данных из горячего слоя (таблицы Fluss) в теплые/холодные слои (Object Storage и Lakehouse). Это означает, что доступна единственная копия единицы данных, либо в слое реального времени, либо в историческом слое. Fluss управляет переключением между слоями, облегчая запросы и доступ. Подход Kafka опирается на дублирование данных с помощью задания потребителя/издателя, что приводит к увеличению затрат на хранение и необходимости конвертировать топики Kafka в табличный формат Lakehouse.
Светлое будущее впереди
Аналитика данных в реальном времени становится краеугольным камнем современных компаний. Цифровые бизнес-модели должны обеспечивать лучший пользовательский опыт и своевременные ответы на взаимодействия с клиентами, что заставляет компании создавать системы для использования и управления данными в реальном времени, создавая увлекательный и впечатляющий («wow») опыт. Действовать сейчас — это не просто вопрос технической осуществимости; для большинства предприятий это становится уникальным преимуществом для выживания в высококонкурентной глобальной рыночной среде.
Fluss помогает компаниям преодолеть разрыв между мирами реального времени и аналитики, предлагая унифицированный доступ как к свежим данным в реальном времени, так и к историческим, холодным данным. Вкратце, Fluss обеспечивает беспрепятственный доступ к данным независимо от возраста набора данных и упрощает сложные архитектуры аналитики данных, которые тянулись годами, в основном из-за отсутствия наиболее подходящих компонентов и фреймворков.
В то время как Fluss служит слоем хранения в реальном времени для аналитики, Лейкхаусу предоставляется управление, простота и масштабируемость, которые защищают современные архитектуры в будущем.
С операционной стороны он предлагает значительные преимущества за счет снижения сложности управления, хранения и обслуживания как данных реального времени, так и пакетных данных. Эта эффективность трансформируется в прямую экономию средств, достигаемую в первую очередь за счет оптимизированного формата таблиц Fluss, двухуровневой системы хранения, основанной на температуре данных, и, наконец, минимизации общего использования ЦП конвейера с помощью проталкивания предикатов (predicate pushdown) и обрезки столбцов. В совокупности эти архитектурные элементы снижают накладные операционные расходы, связанные с обслуживанием платформы, ускоряют внедрение новых сценариев использования и облегчают бесшовную интеграцию с существующей ИТ-инфраструктурой предприятия.