
Nimtable: Единая панель управления для зоопарка Iceberg-каталогов
В современных компаниях, активно использующих данные, часто возникает проблема “зоопарка” технологий. Данные хранятся в озере данных (Data Lake), а метаданные об этих данных — в каталогах. Со временем таких каталогов становится много: один `Hive Metastore` для унаследованной аналитики, другой — `REST Catalog` для новой платформы на Trino, третий — `JDBC Catalog` для специфичного микросервиса, а где-то в среде разработки таблицы вообще создаются напрямую в S3. Каждая система решает свою задачу, но вместе они создают хаос.
https://github.com/nimtable/nimtable
Платформенным дата-командам становится сложно управлять этим разнообразием, отслеживать состояние таблиц, проводить оптимизацию и обеспечивать единые стандарты. Именно для решения этой проблемы и был создан open-source проект Nimtable. Это не просто очередной каталог для Iceberg, а полноценная платформа для наблюдения и управления (*observability platform*) существующими каталогами из одного окна.
Что такое Nimtable?
Nimtable — это легковесная веб-платформа с открытым исходным кодом, предназначенная для исследования и управления каталогами и таблицами Apache Iceberg. Его ключевая идея — предоставить единый интерфейс для подключения к различным существующим каталогам, агрегируя метаданные и предоставляя инструменты для их анализа и обслуживания.
Проект ориентирован на инженерные и платформенные команды, которые хотят получить контроль над своей Iceberg-инфраструктурой без привязки к конкретному вендору и без операционной сложности самостоятельного развертывания разрозненных инструментов.
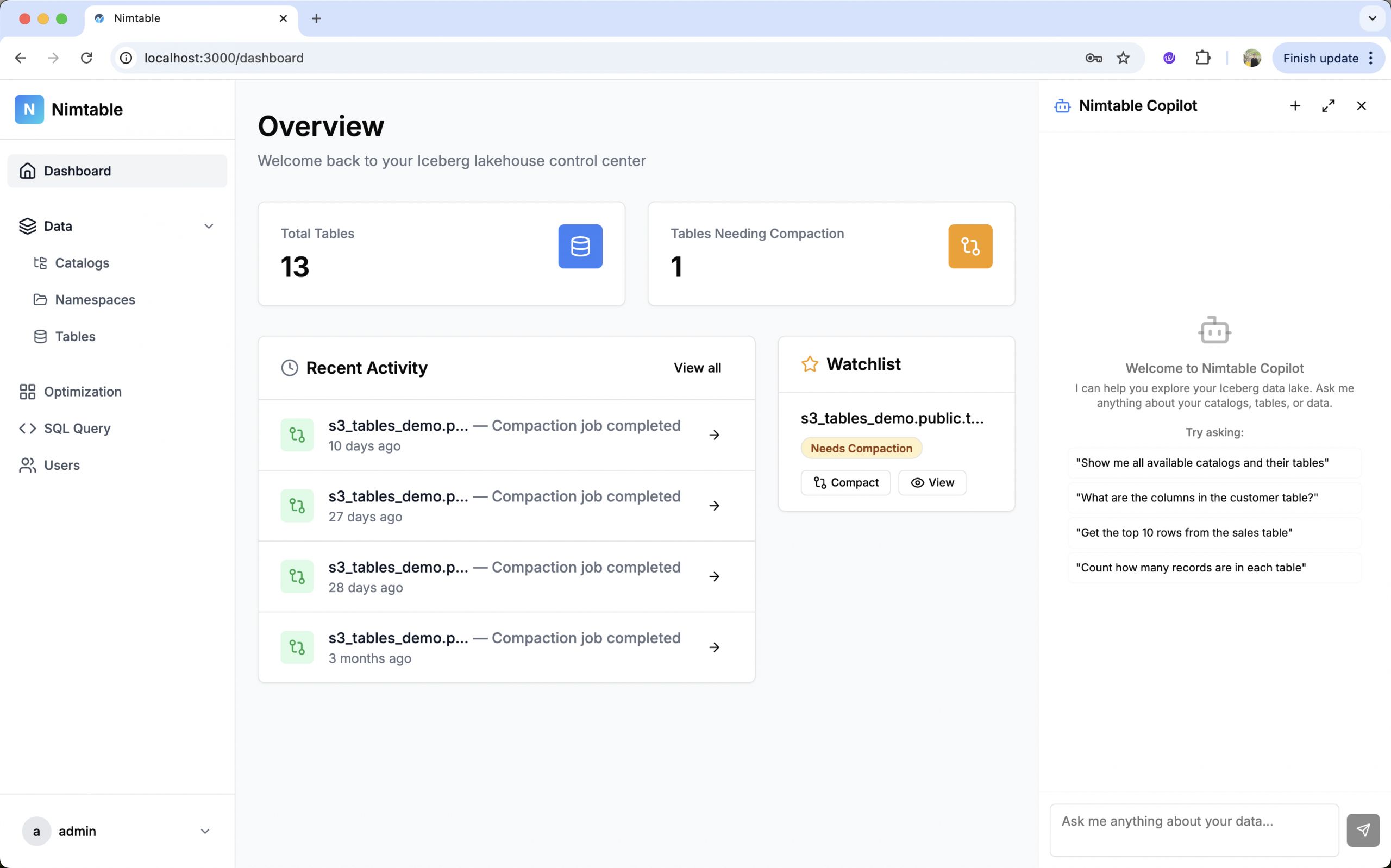
Ключевая функциональность
Nimtable предлагает набор функций, которые делают его мощным инструментом для управления озером данных.
пы: картинки можно листать, если что) там много, почти все меню.
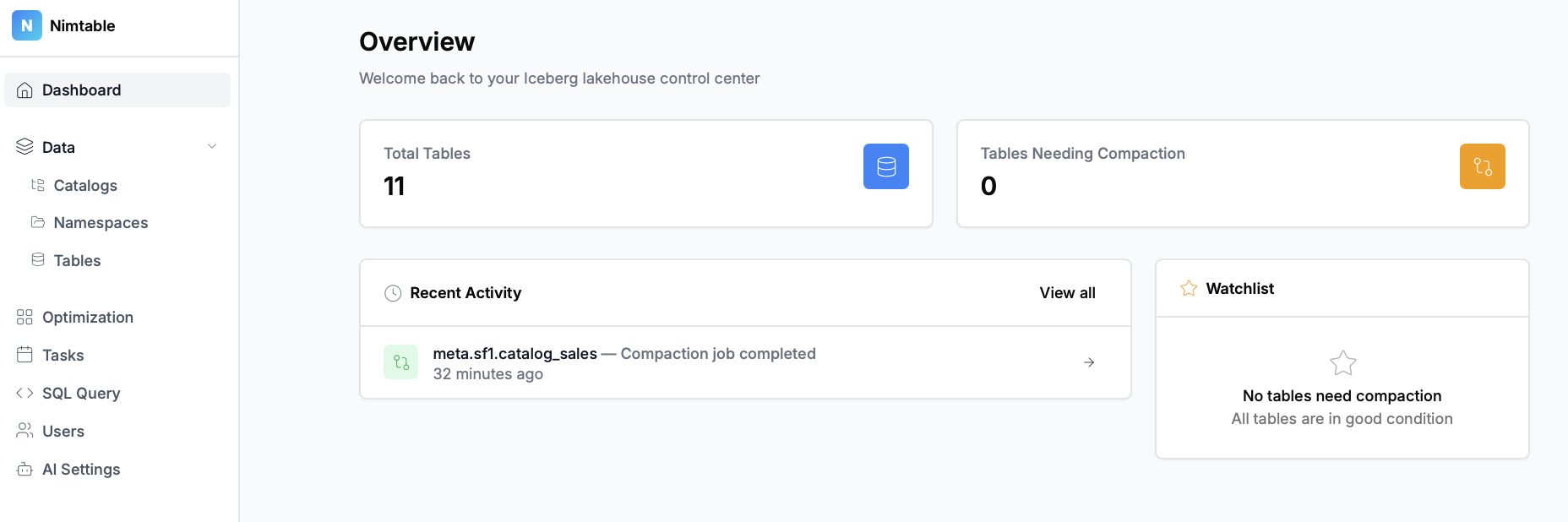
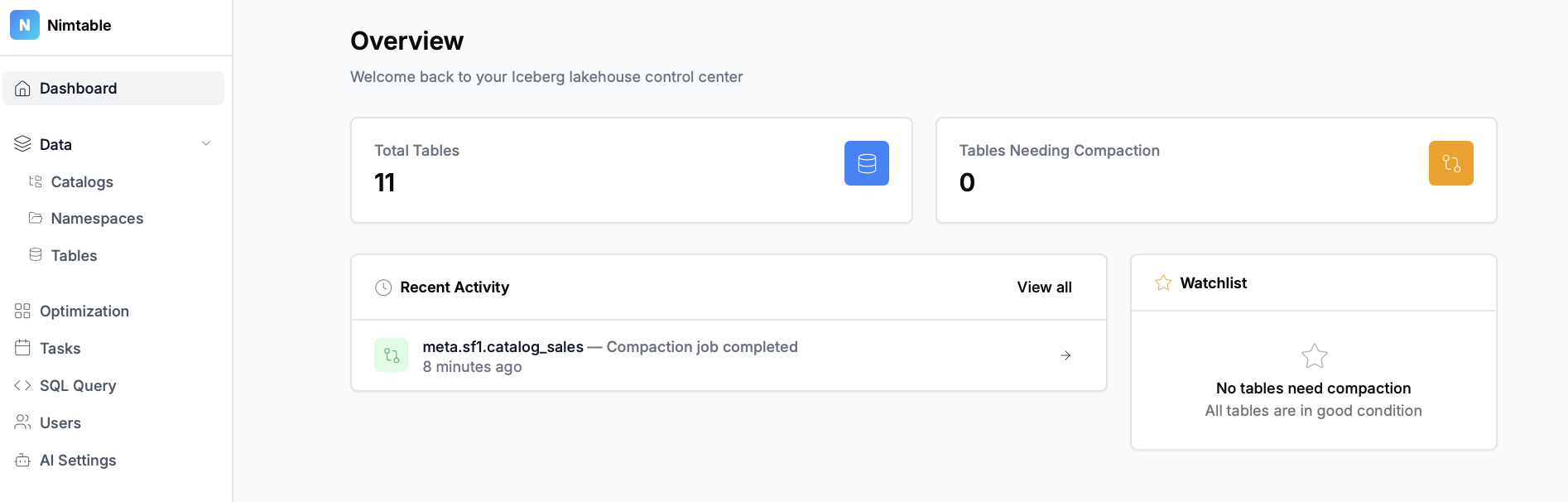

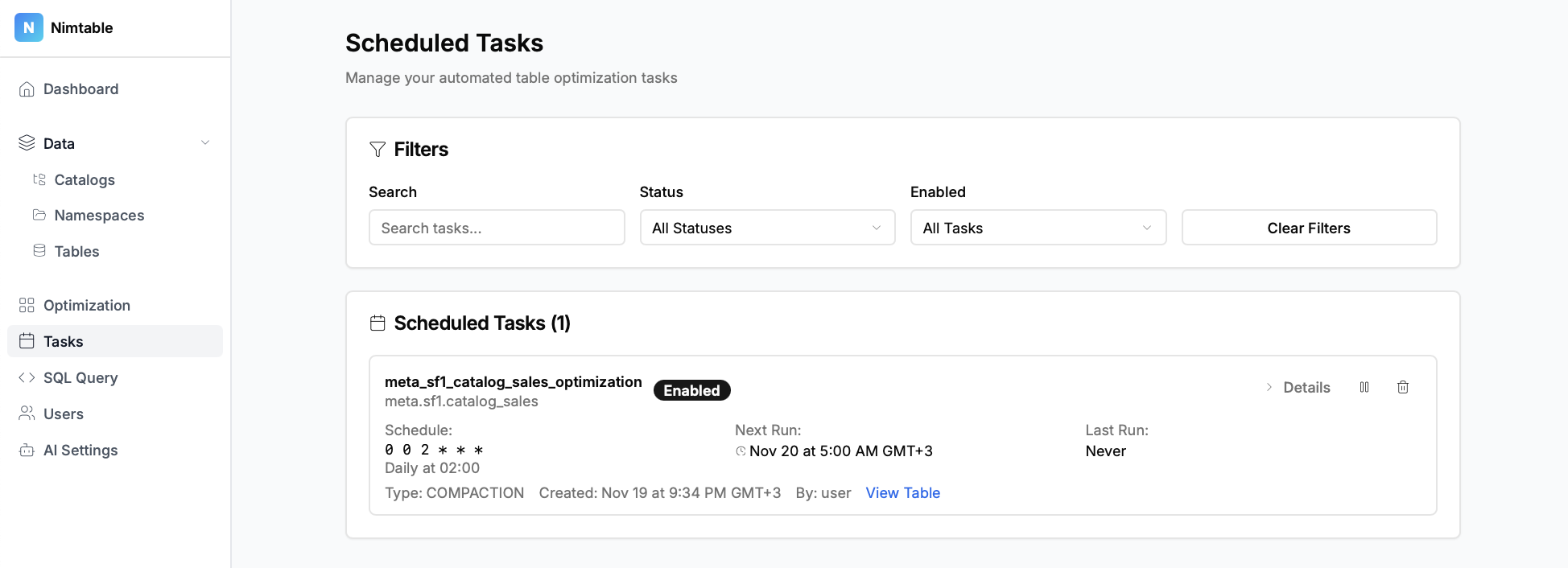
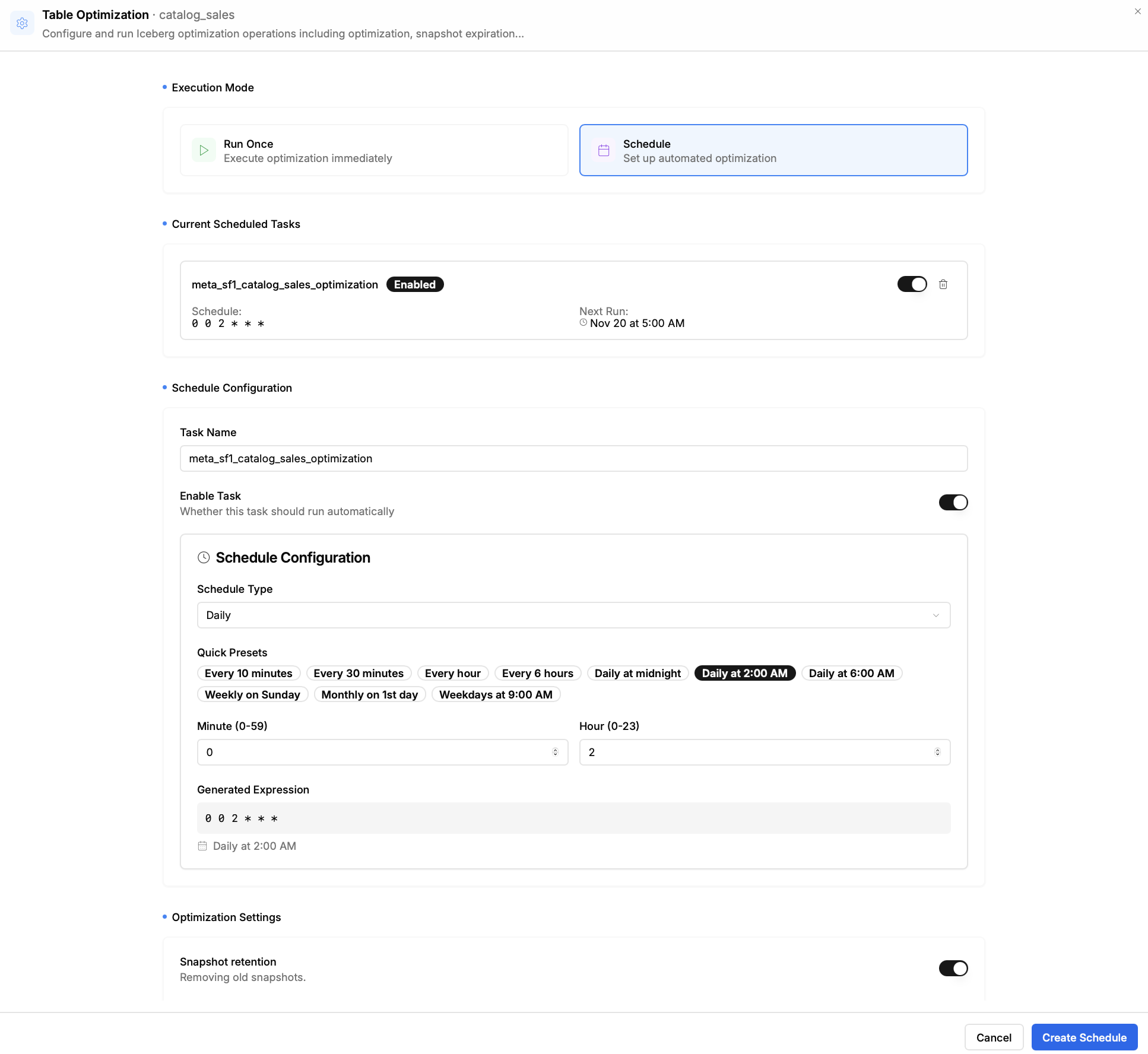
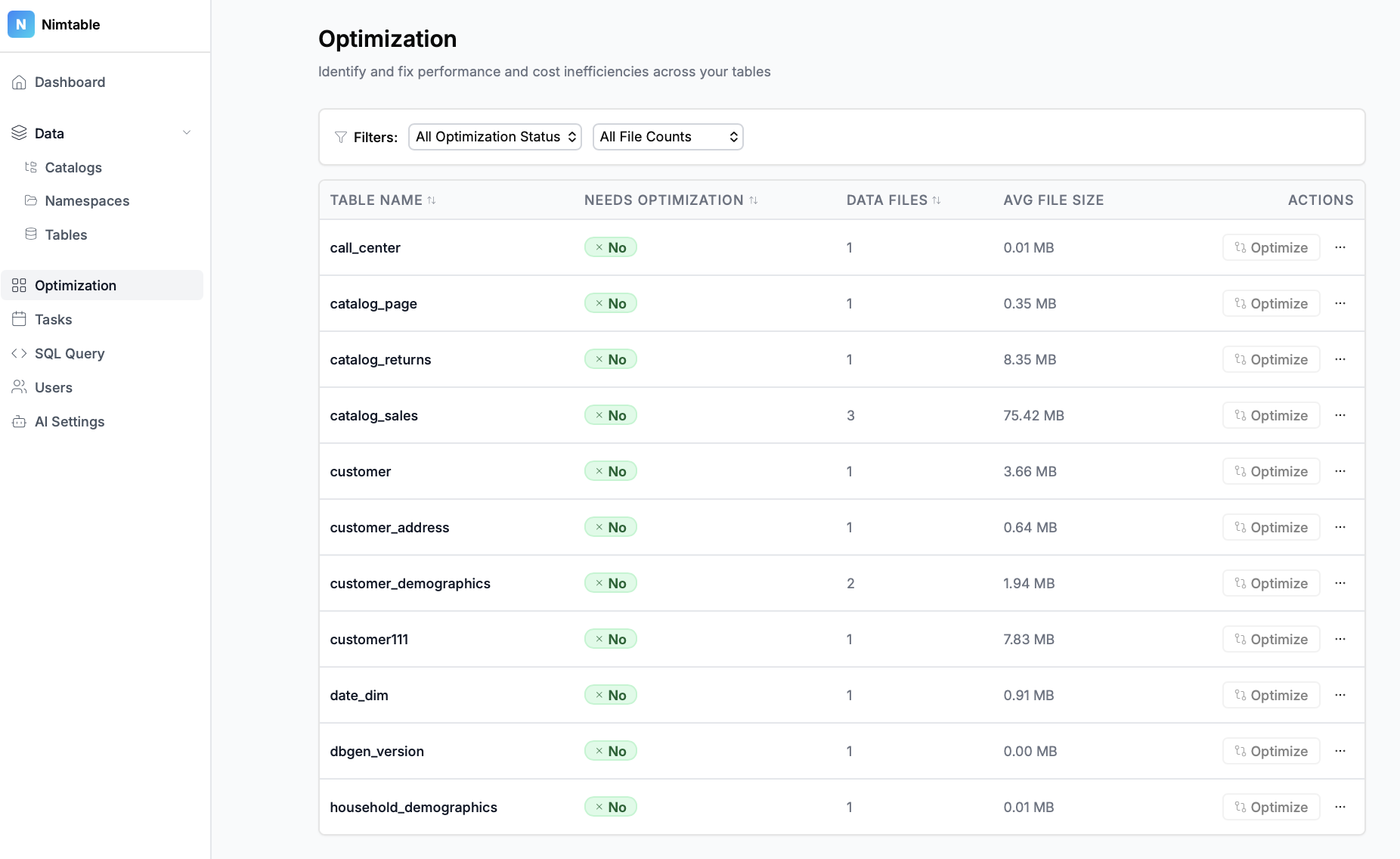
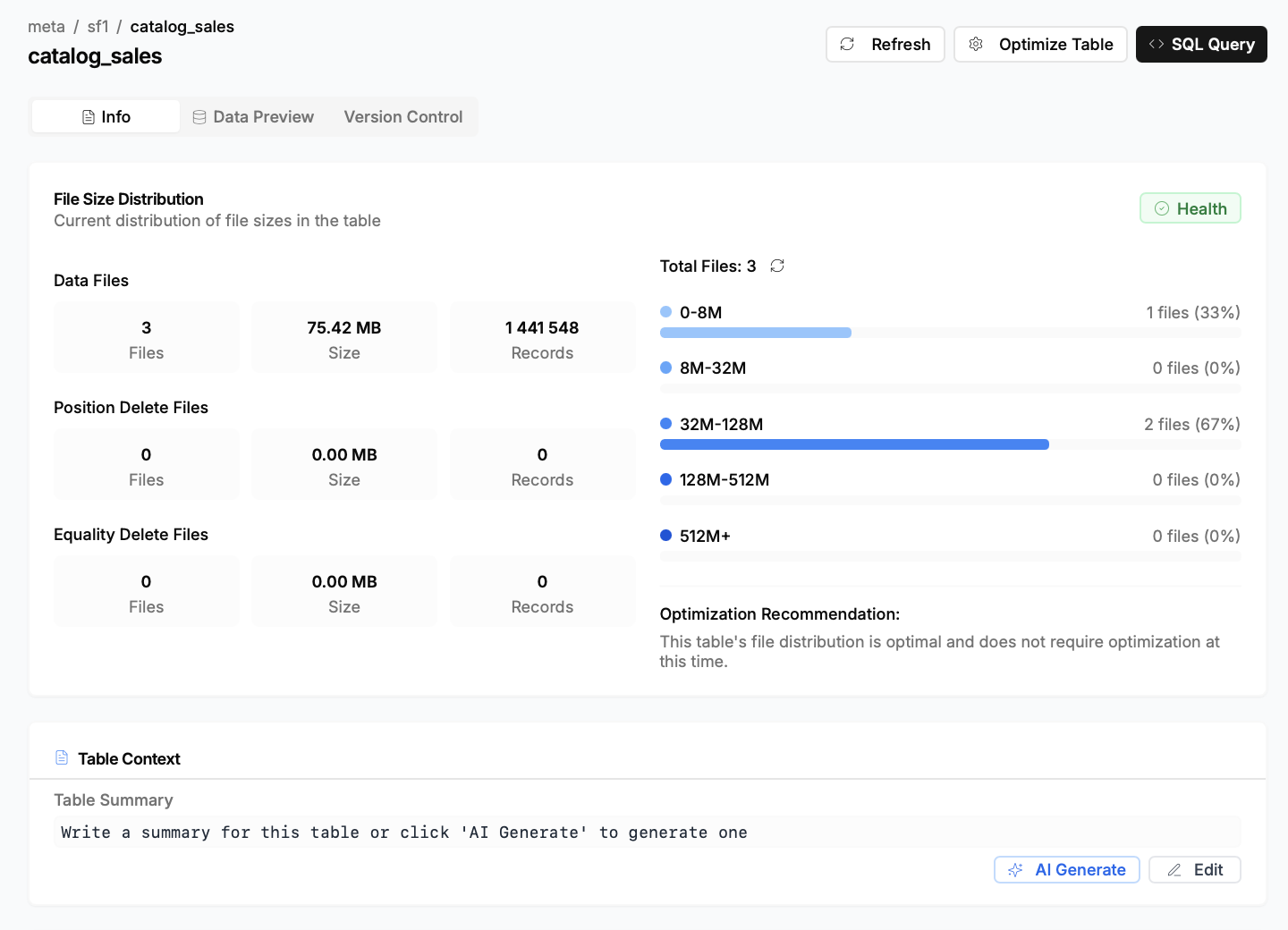
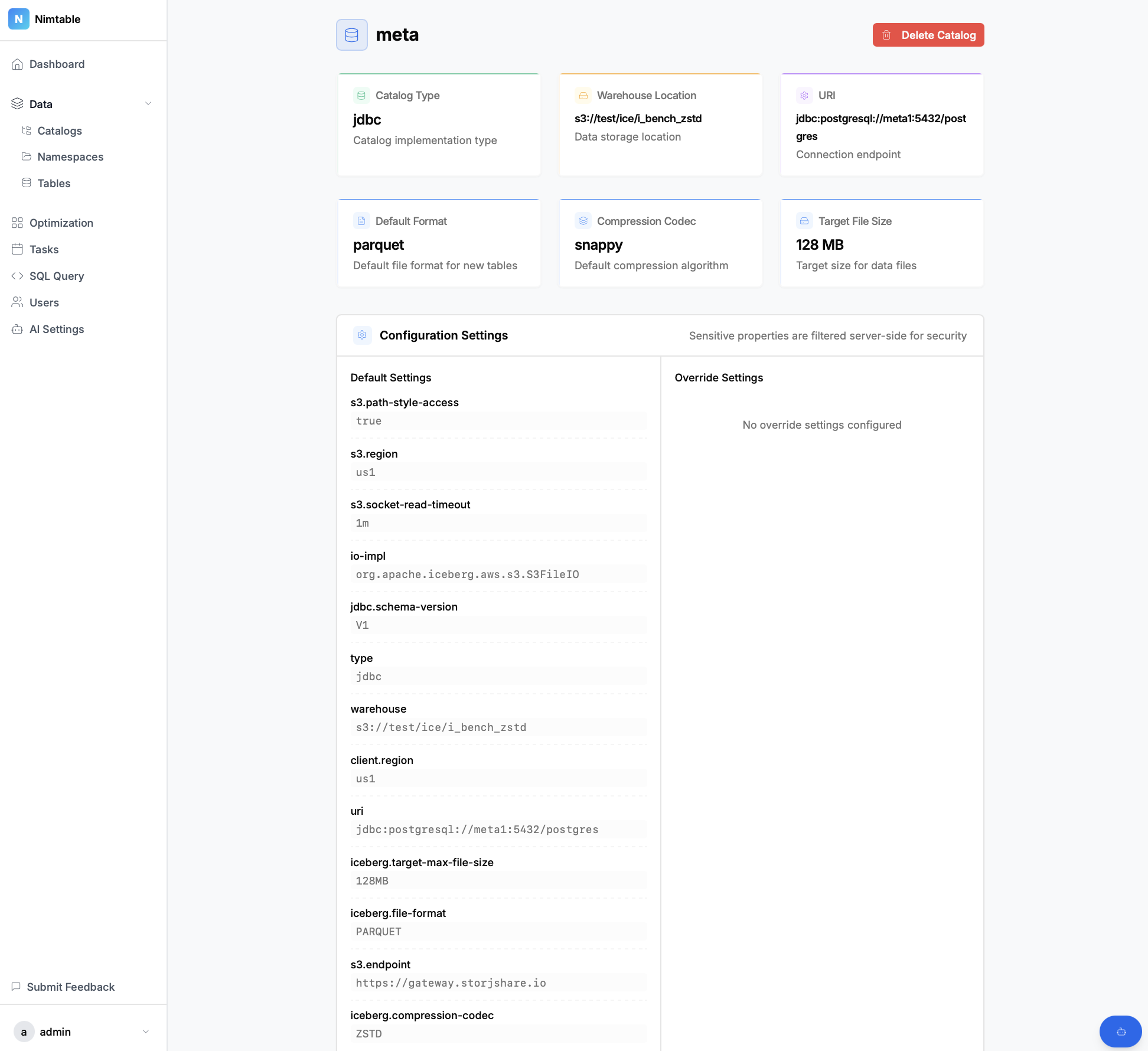
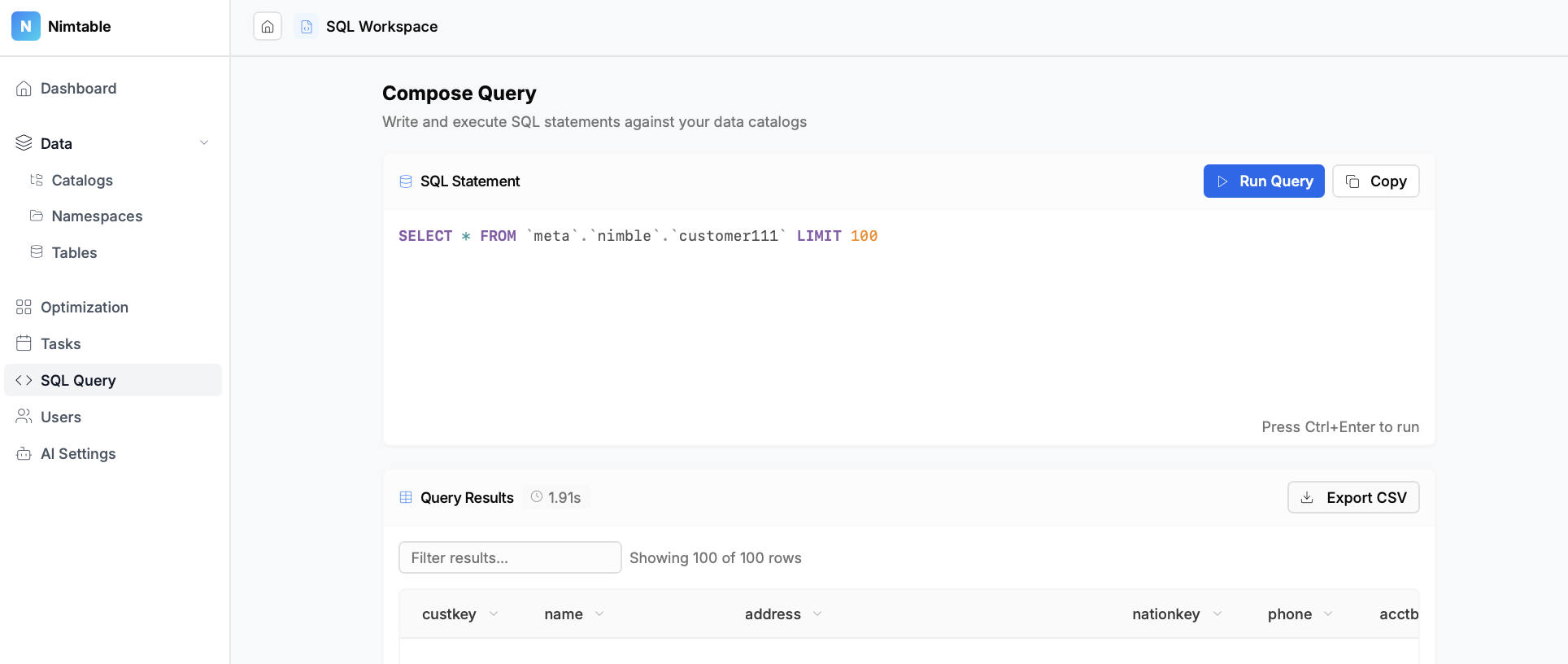
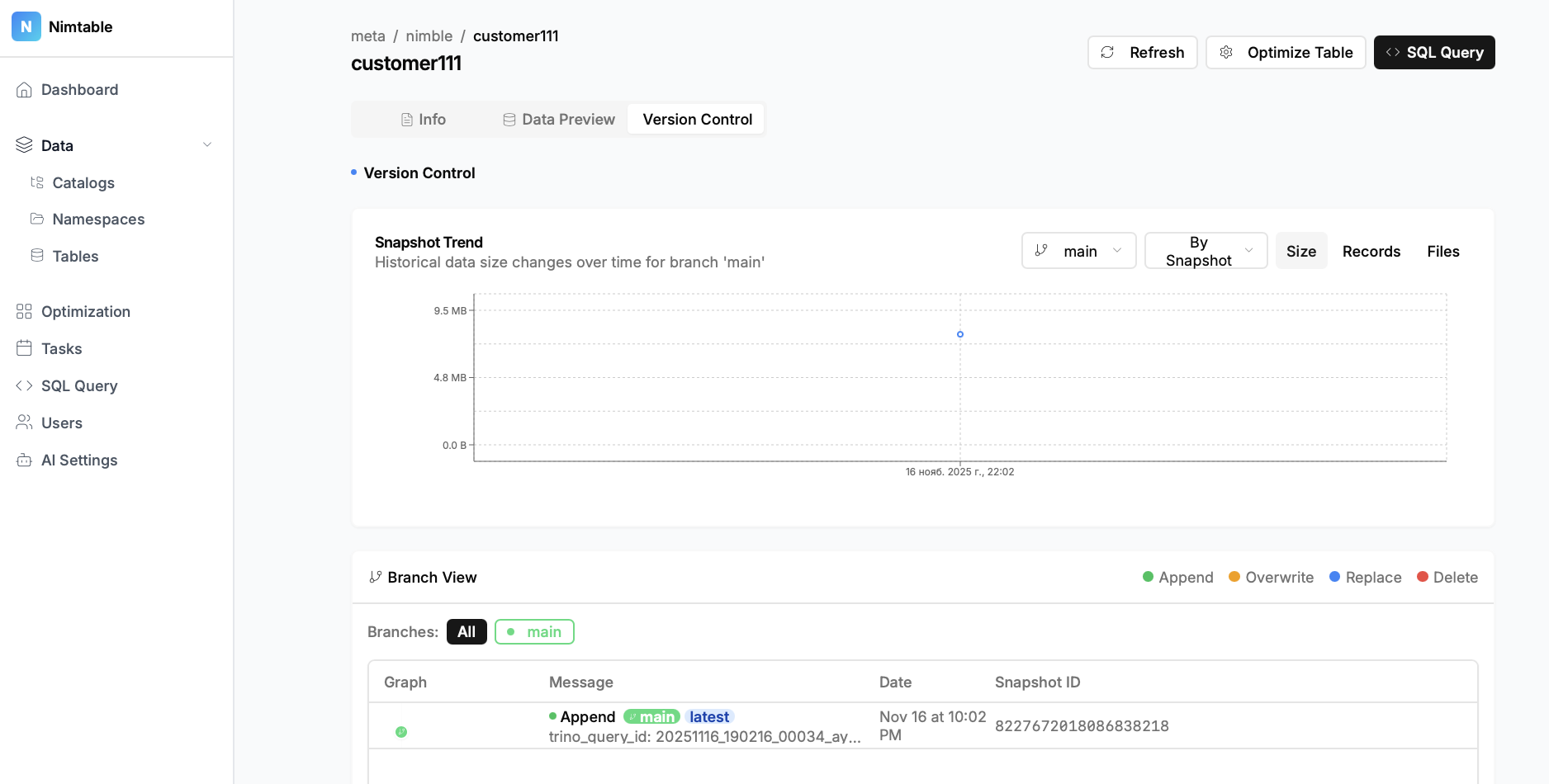
- Агрегация каталогов: Это главная особенность проекта. Nimtable позволяет в одном интерфейсе подключить и работать с несколькими типами каталогов Apache Iceberg, включая:
- `REST Catalog`
- `AWS Glue`
- `PostgreSQL` (через JDBC)
- Каталоги на основе S3 (`S3 Tables`)
- Исследование и визуализация: Платформа предоставляет удобный UI для навигации по метаданным:
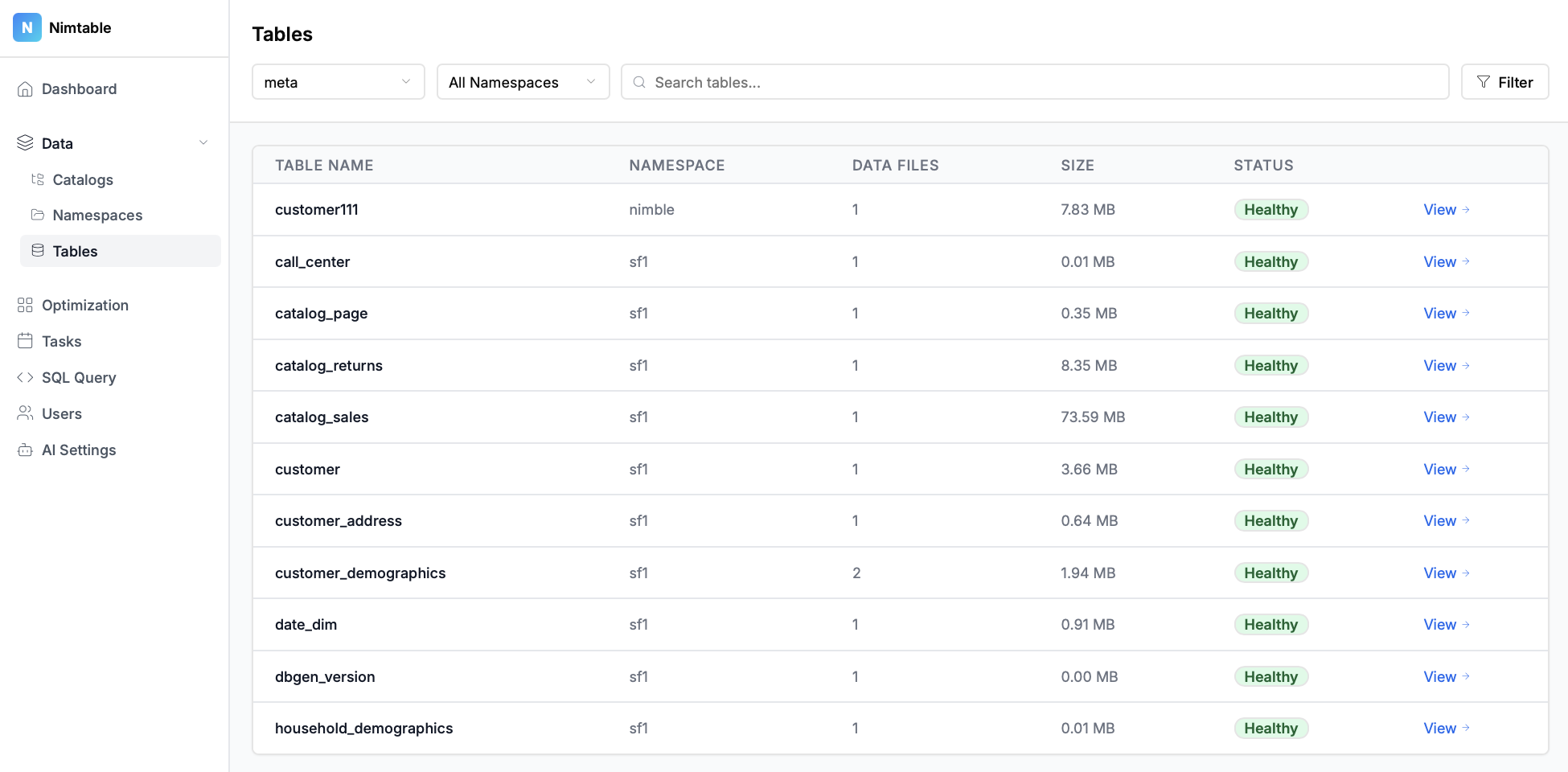
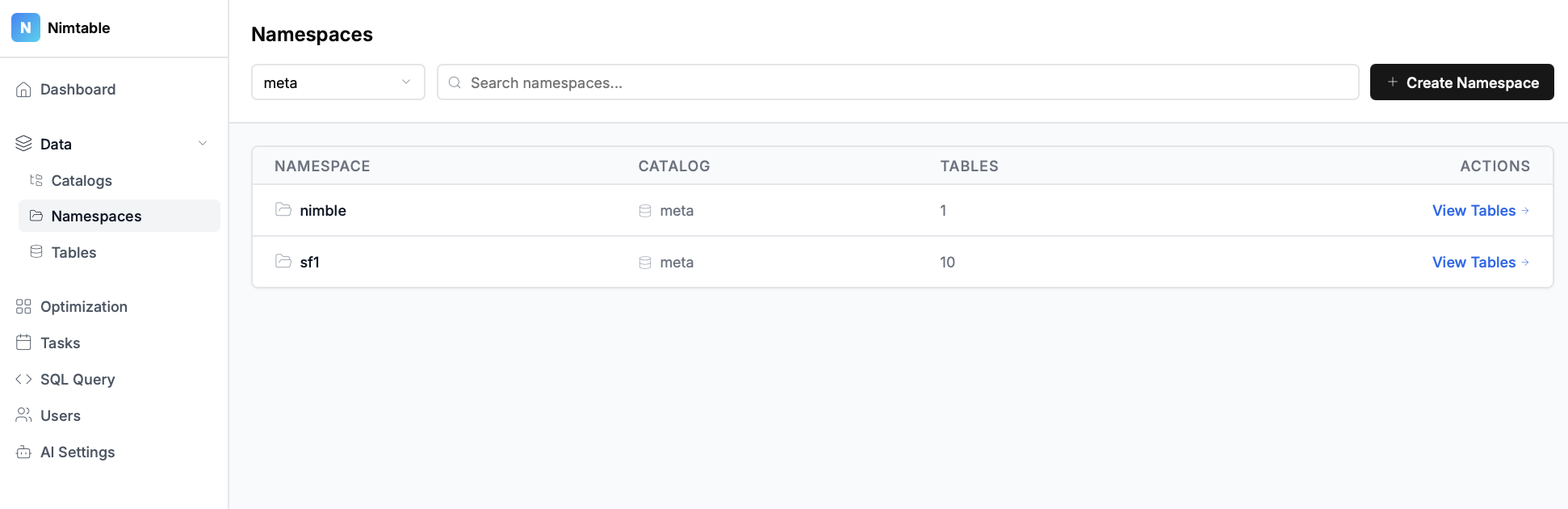
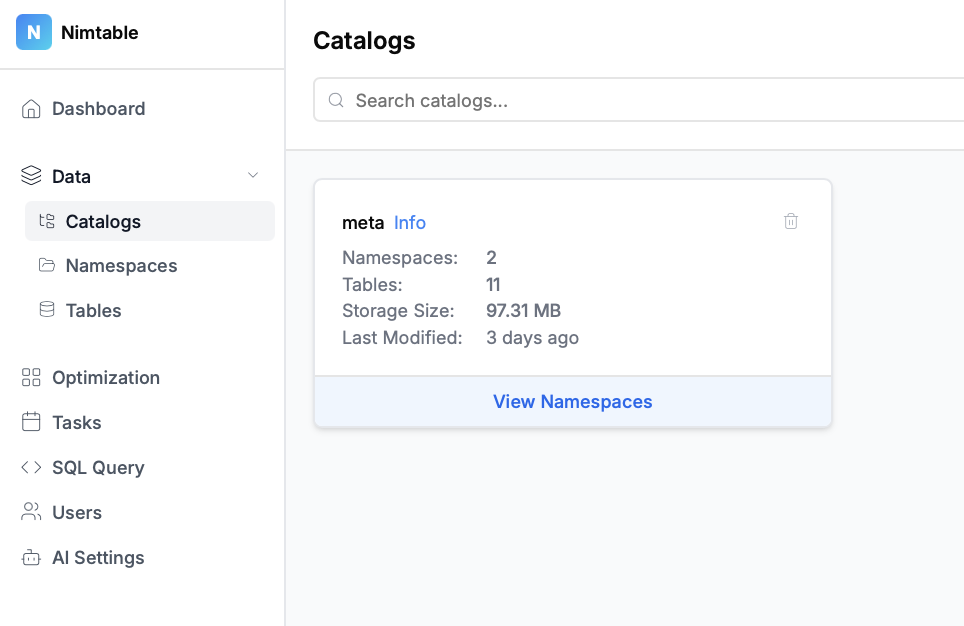
- Просмотр каталогов, пространств имен (схем) и таблиц.
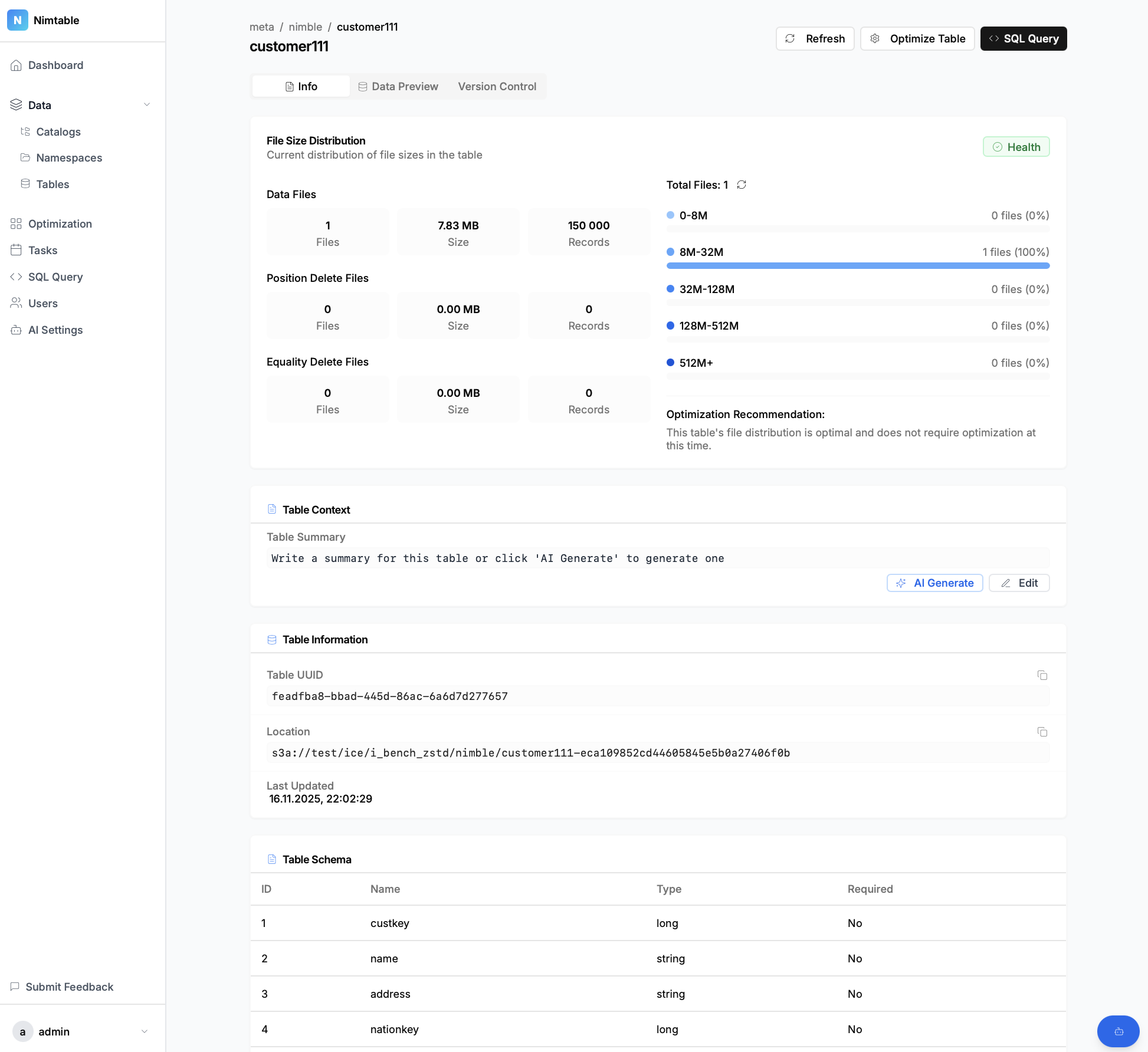
- Анализ схемы таблиц, их партиций, снэпшотов и манифестов.
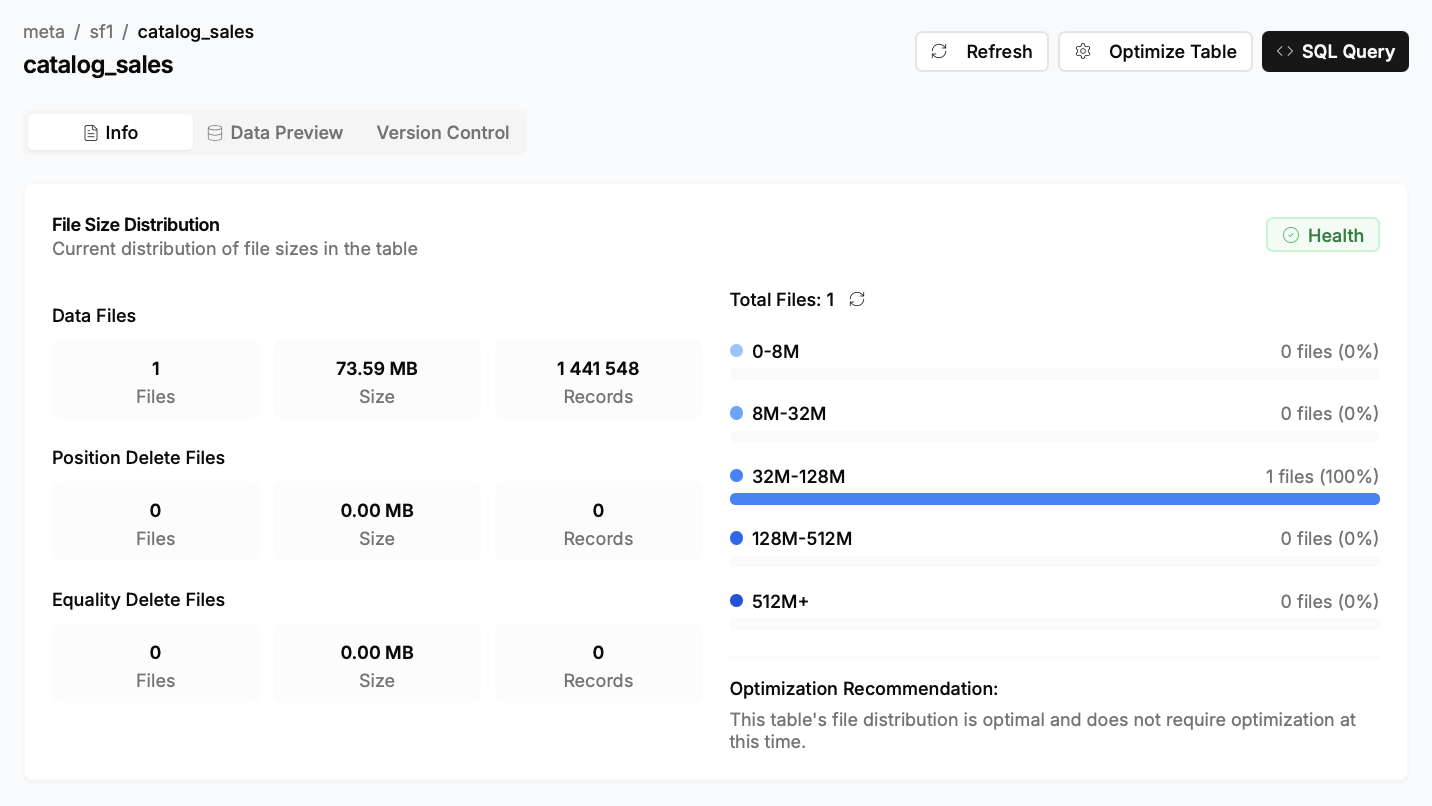
- Визуализация распределения файлов и снэпшотов, что помогает быстро находить таблицы, требующие оптимизации (например, с большим количеством мелких файлов).
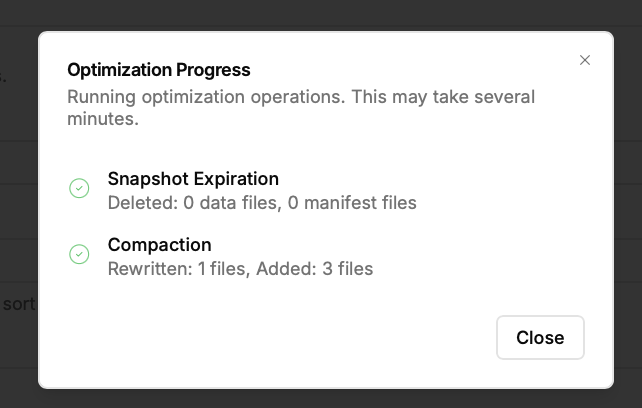
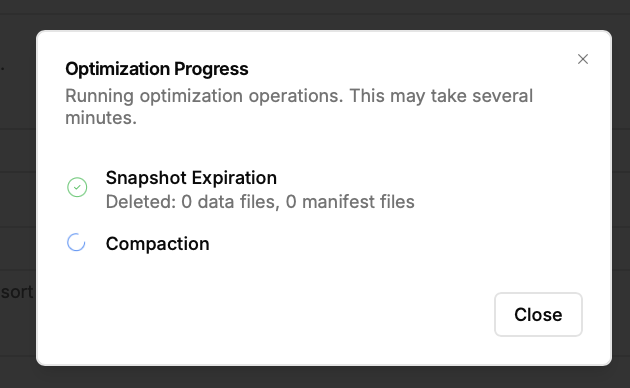
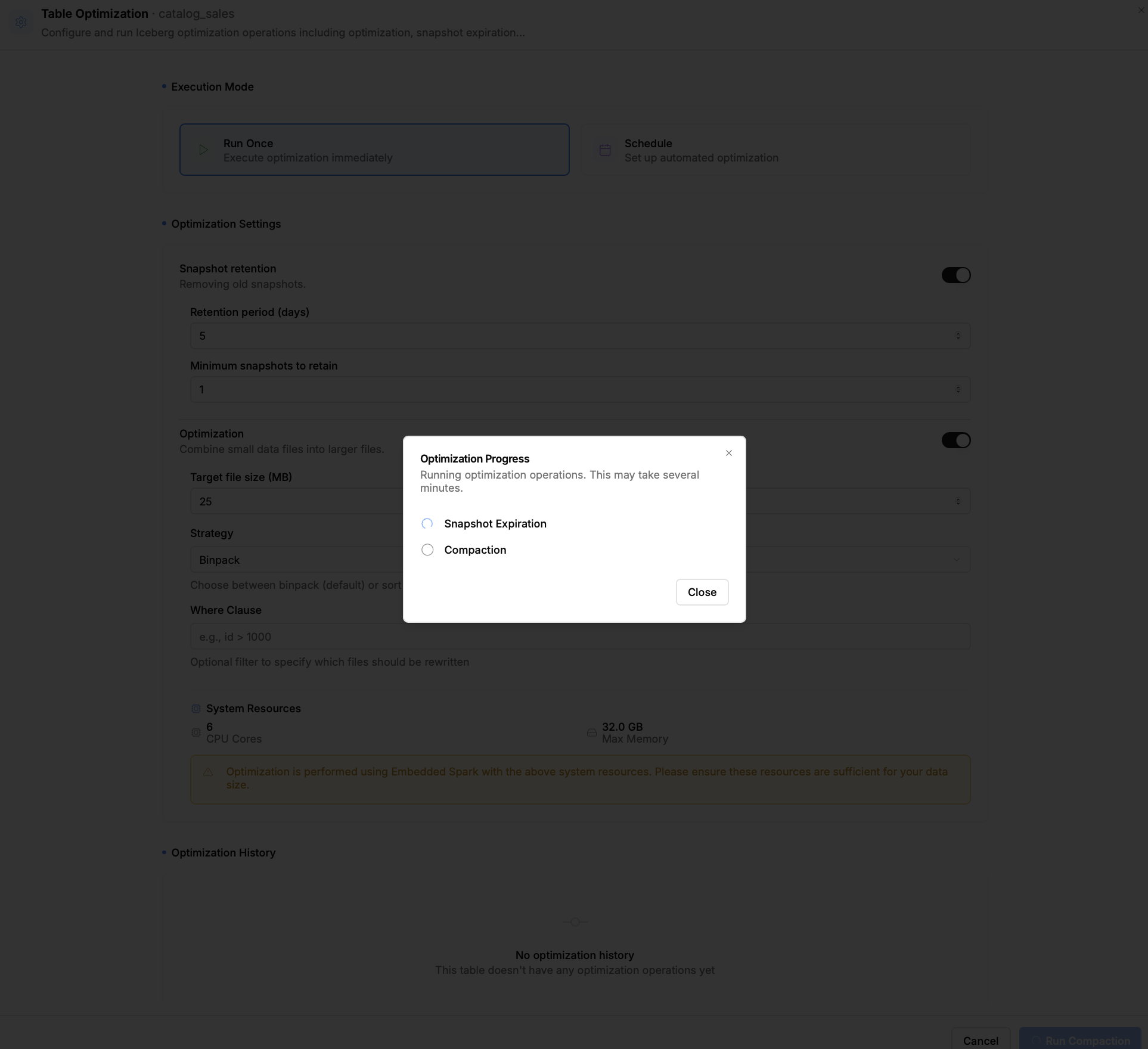
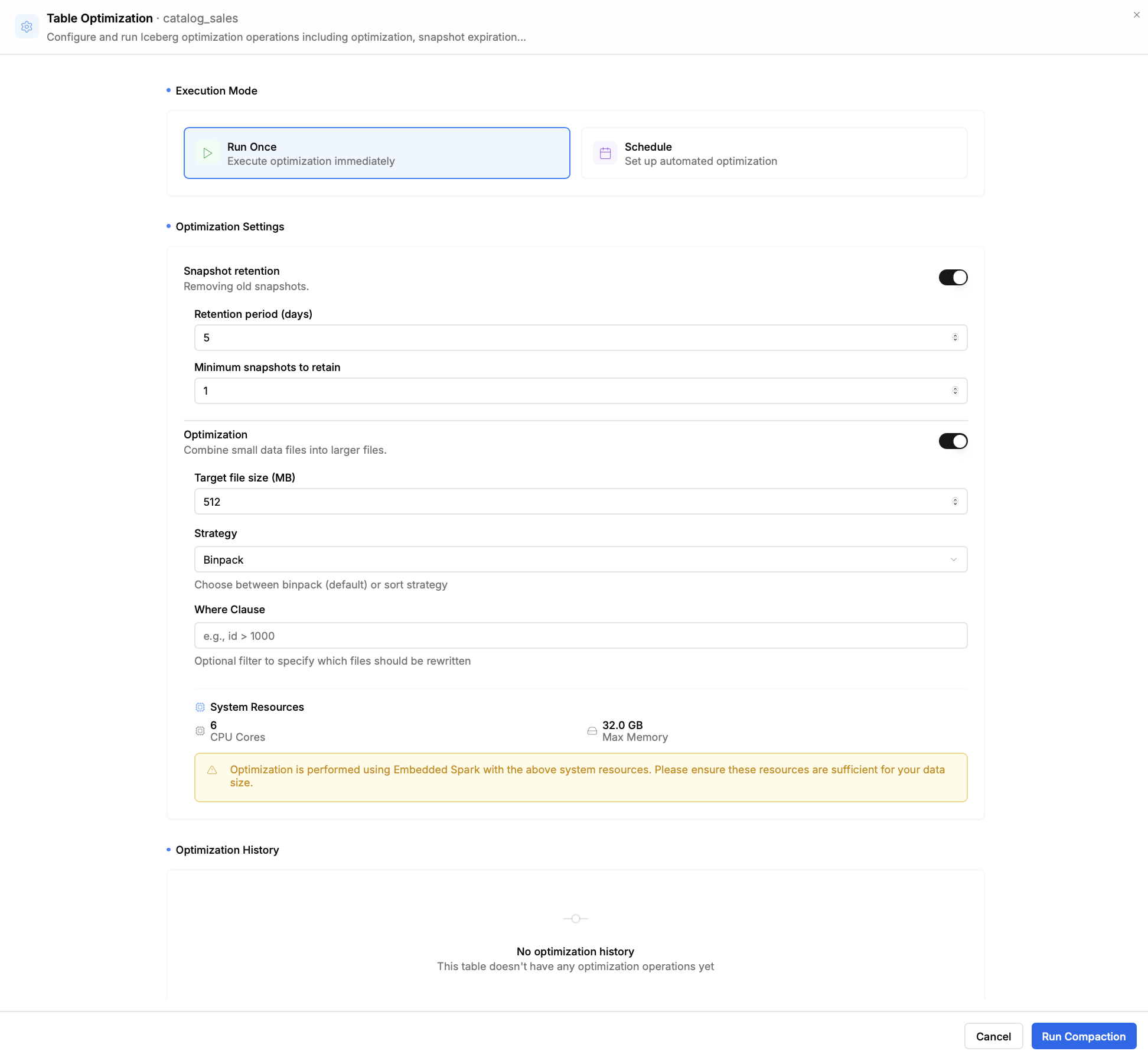
- Управление оптимизацией: Nimtable не просто показывает проблемы, но и помогает их решать. Он интегрируется с внешними вычислительными движками, такими как Apache Spark или RisingWave, позволяя запускать и отслеживать задачи по обслуживанию таблиц (например, `compaction` или `expire_snapshots`) прямо из веб-интерфейса.
- Встроенный SQL-редактор: Для быстрой проверки данных или метаданных в Nimtable встроен простой SQL-редактор, позволяющий выполнять запросы к таблицам напрямую из браузера.
- Собственный REST API: Помимо агрегации других каталогов, Nimtable сам может выступать в роли стандартного Iceberg REST-каталога. Это позволяет использовать его как единую точку входа для различных движков запросов (Trino, Spark, Flink).
Варианты использования в большой компании
Представим себе компанию, где исторически сложился разнородный ландшафт данных:
- Прод-кластер Hadoop использует `Hive Metastore` для аналитических витрин.
- Аналитическая платформа на Trino работает с CedrusData Catalog, который реализует `Iceberg REST API` habr.com.
- Команда разработки для своих экспериментов использует таблицы, зарегистрированные напрямую в S3, чтобы не “загрязнять” общие каталоги.
- Какой-то сервис использует собственную `PostgreSQL` базу как JDBC-каталог.
В такой среде Nimtable становится незаменимым инструментом:
- Единая точка входа: Платформенная команда подключает все четыре каталога к Nimtable. Теперь для мониторинга состояния всех Iceberg-таблиц в компании достаточно зайти на один дашборд, не переключаясь между разными консолями и инструментами.
- Централизованная оптимизация: Инженер замечает, что в одной из таблиц на прод-кластере накопилось тысячи мелких файлов. Прямо из интерфейса Nimtable он может запустить `compaction-job` на общем Spark-кластере, выбрав нужную таблицу, независимо от того, в каком каталоге она зарегистрирована.
- Упрощение доступа: Вместо того чтобы объяснять новому аналитику, как настроить 4 разных подключения, ему можно дать доступ к Nimtable, где он сможет исследовать все доступные данные в едином, понятном интерфейсе.
- Контролируемая миграция: Если команда решит перенести таблицы из `Hive Metastore` в новый `REST Catalog`, Nimtable позволит одновременно наблюдать за источником и приемником, контролируя процесс и сверяя метаданные.
Архитектура и развертывание
Архитектурно Nimtable располагается между конечными пользователями (или движками запросов) и нижележащими каталогами метаданных.
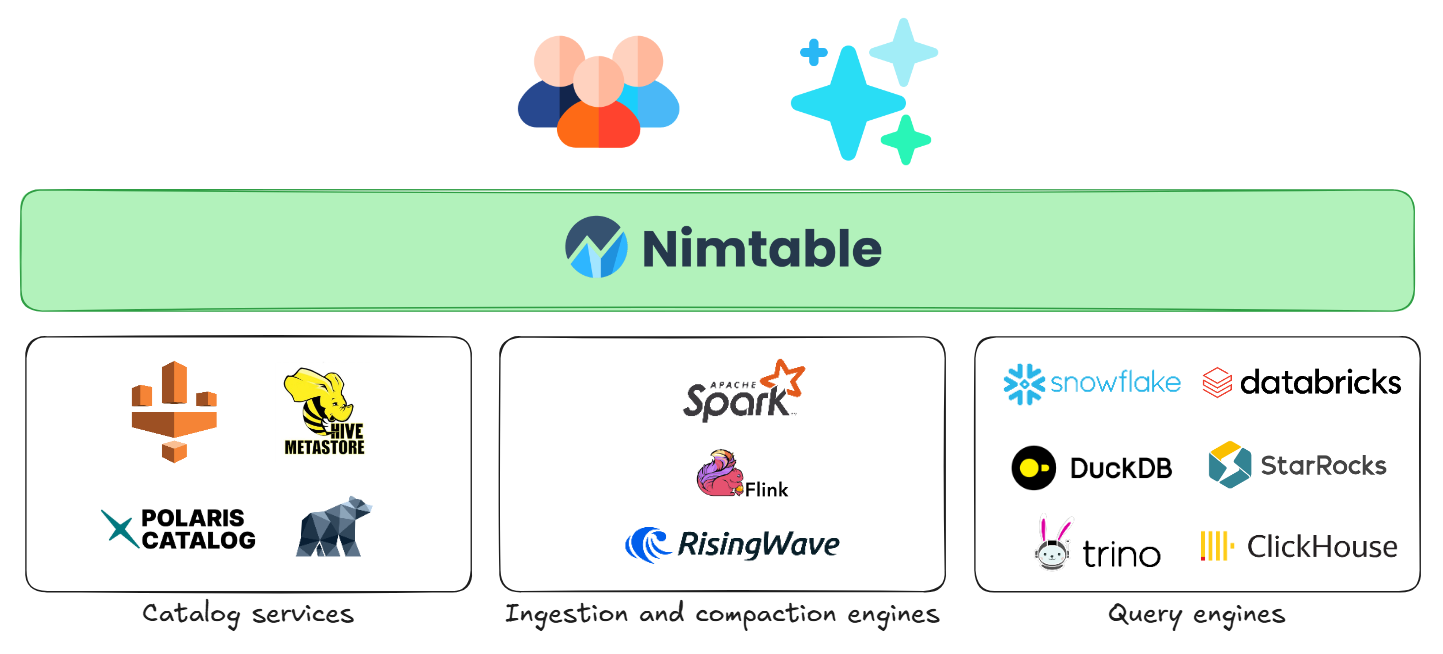
Проект очень прост в развертывании. Самый быстрый способ начать работу — использовать Docker:
# Переходим в директорию с docker-файлами в репозитории проекта
cd docker
# Запускаем сервисы в фоновом режиме
docker compose up -dПосле этого веб-интерфейс будет доступен по адресу `http://localhost:3000`.
Сравнение с другими решениями
Чтобы понять нишу, которую занимает Nimtable, сравним его с другими популярными решениями для управления метаданными.
| Параметр | Nimtable | Project Nessie | Hive Metastore | CedrusData Catalog |
| Основное назначение | Платформа для наблюдения и управления несколькими каталогами. | Каталог с Git-подобным версионированием данных. | Хранилище метаданных для экосистемы Hadoop. | Высокопроизводительный Iceberg REST каталог. |
| Поддержка нескольких каталогов (агрегация) | Да (ключевая функция) | Нет (является самостоятельным каталогом) | Нет (является самостоятельным каталогом) | Нет (является самостоятельным каталогом) |
| Встроенный UI для управления | Да, с фокусом на агрегацию и оптимизацию. | Да, с фокусом на ветки, теги и коммиты. | Нет (обычно управляется через CLI или сторонние UI). | Управляется через API; UI не является основной частью docs.cedrusdata.ru. |
| Управление оптимизацией (Compaction) | Да, через интеграцию с внешними движками. | Нет, это задача движков запросов. | Нет, это задача движков запросов (Spark/Hive). | Нет, это задача движков запросов. |
| Git-подобные операции | Нет | Да (ключевая функция) | Нет | Нет |
Как видно из таблицы, Nimtable не конкурирует напрямую с каталогами вроде Nessie или Hive и другими, а дополняет их, выступая в роли “менеджера менеджеров”.
Заключение
Nimtable — это многообещающий проект, который пока не собрал много звёзд, но уже готов решать реальную боль платформенных дата-команд в крупных организациях. Вместо того чтобы создавать еще один стандарт каталога, он предлагает удобный слой абстракции для управления уже существующим “зоопарком”. Возможность в одном месте видеть, анализировать и оптимизировать таблицы из разных систем (`Hive`, `JDBC`, `REST`) делает его уникальным и крайне полезным инструментом для построения зрелой и управляемой платформы данных на базе Apache Iceberg.
Кстати, у меня после запуска он сначала жутко тупил, а потом прочихался, на третий день работы в докере))) я уже даже не надеялся, а он смог. ниче не делал) оно само) Но, видимо, если таблиц очень много, то первый запуск надо как то отдельно планировать. В общем зверь интересный и полезный, а запускать не сложно. Ну почти не сложно и баги есть. вот эту нашел например? https://github.com/nimtable/nimtable/issues/200 но это не критично.
Видосик ниже, компакшен в онлайне не получился, но 5 минут ранее он прошел хорошо. вероятно, что моих локальных ресурсов не хватает для записи видео и этой операции.
Да точно, дело в ресурсах, теперь 16 файлов.
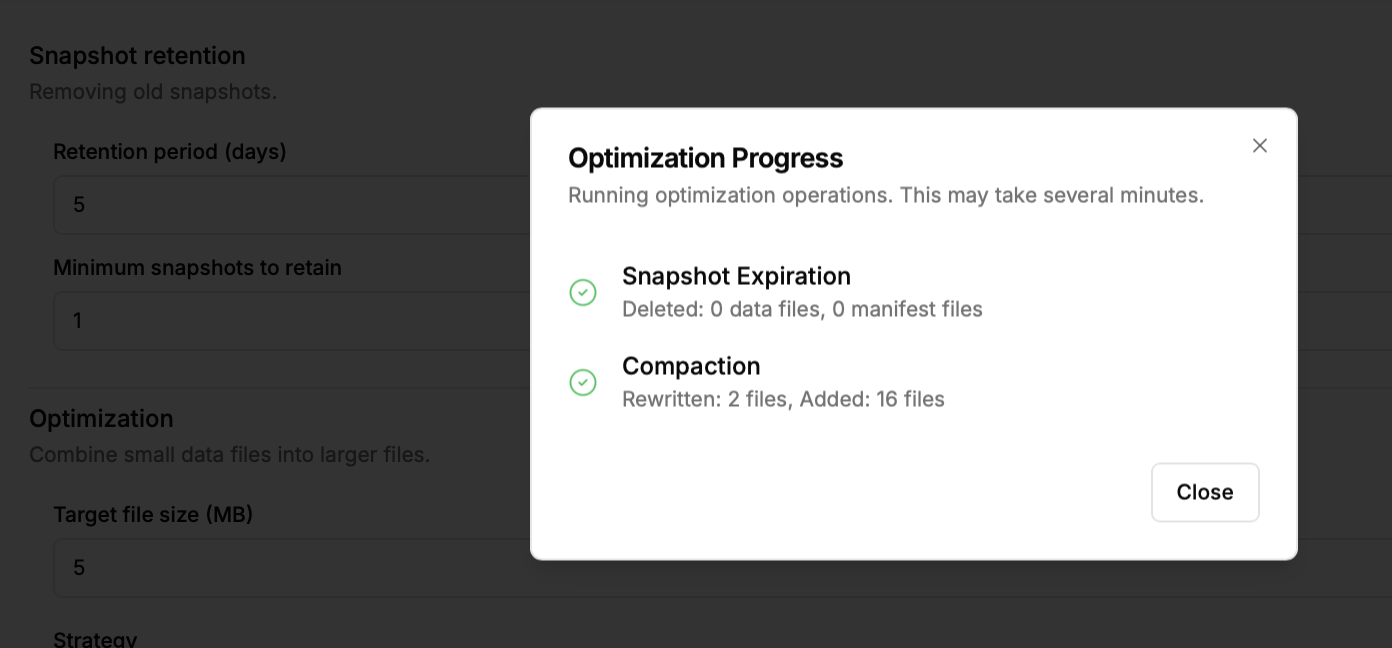
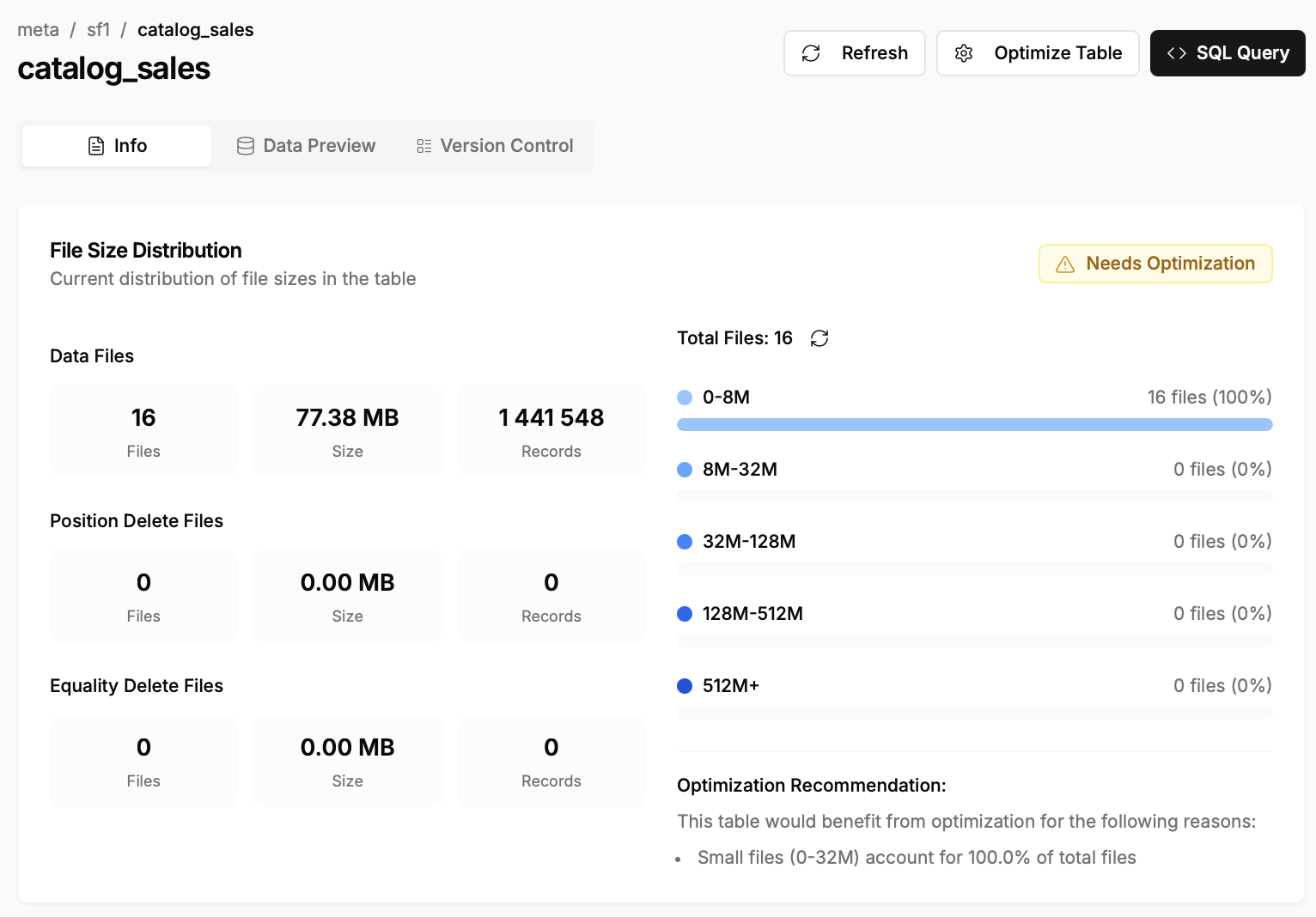
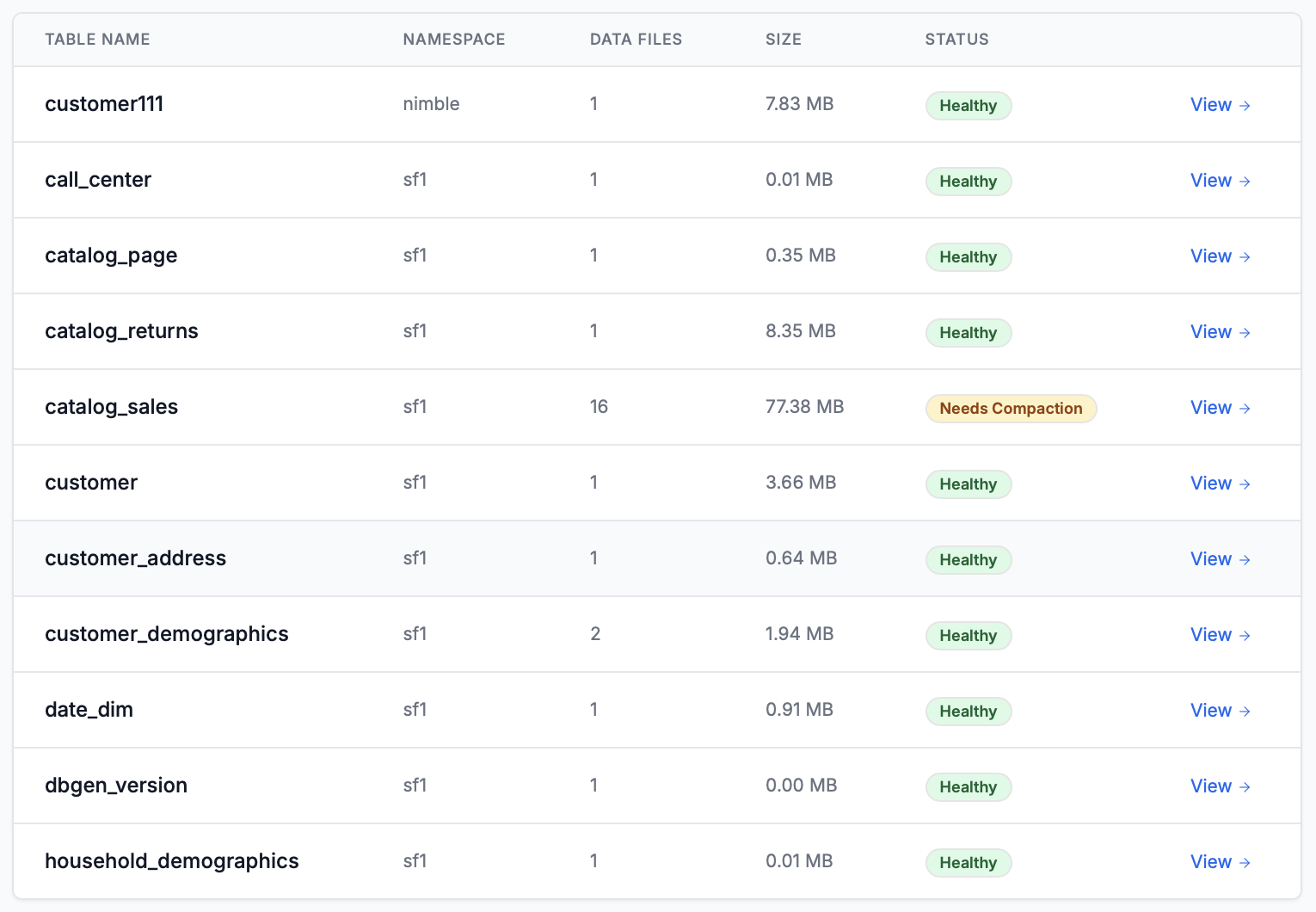
Теперь кстати хочет оптимизации)), хороший тула, можно и сломать табличку им))
Ранее писал о разных каталогах тут: https://gavrilov.info/all/rukovodstvo-po-rest-katalogam-dlya-trino-i-iceberg/