
Потоковая обработка: Stateful и Stateless

Современные системы обработки данных все чаще работают с непрерывными потоками событий — от отслеживания активности пользователей на сайтах до мониторинга IoT-устройств. Этот подход позволяет анализировать информацию в реальном времени. В основе таких систем лежит выбор между двумя фундаментальными парадигмами: потоковой обработкой с состоянием (stateful) и без него (stateless).
А все эти изыски пошли от этого поста:
I haven't dug deep into this project, so take this with a grain of salt. // пишет про ArkFlow
ArkFlow is a "stateless" stream processor, like vector or benthos (now Redpanda Connect). These are great for routing data around your infrastructure while doing simple, stateless transformations on them. They tend to be easy to run and scale, and are programmed by manually constructing the graph of operations.
Arroyo (like Flink or Rising Wave) is a "stateful" stream processor, which means it supports operations like windowed aggregations, joins, and incremental SQL view maintenance. Arroyo is programmed declaratively via SQL, which is automatically planned into a dataflow (graph) representation. The tradeoff is that state is hard to manage, and these systems are much harder to operate and scale (although we've done a lot of work with Arroyo to mitigate this!).
I wrote about the difference at length here: https://www.arroyo.dev/blog/stateful-stream-processingА про маленького Stateless зверька ArkFlow будет потом статейка. В прочем можете уже посмотреть и раньше.
Потоковая обработка с состоянием (stateful) означает, что система способна запоминать информацию о ранее обработанных событиях. Это позволяет выполнять сложные операции, такие как агрегации, объединения (joins) и вычисления в “окнах” времени.
В этой статье мы разберем, в чем разница между этими подходами, когда стоит выбирать тот или иной, и как современные движки, такие как Apache Flink или RisingWave, справляются со сложностями хранения состояния. Про “Восходящую волну” и делал тестик тут https://gavrilov.info/all/sozdaem-streaming-lakehouse-za-chas-rukovodstvo-po-risingwave-la
Потоковая обработка без состояния (Stateless)
Многие системы потоковой обработки являются stateless. Это означает, что они обрабатывают каждое событие изолированно, не имея возможности “помнить” информацию о данных, которые видели ранее.
На самом деле, наличие состояния — это источник больших сложностей. Хранение состояния делает систему в десятки раз сложнее в эксплуатации. Именно поэтому базы данных гораздо труднее обслуживать, чем типичные микросервисы, которые чаще всего проектируются как “stateless”.
В потоковой обработке отсутствие состояния также означает, что система выполняет только простые операции преобразования или фильтрации (в SQL-терминах это `SELECT` и `WHERE`). Сложные операции, требующие группировки или объединения данных (`GROUP BY`, `JOIN`, `ORDER BY`), в таких системах невозможны.
Преимущества stateless-систем:
- Простота эксплуатации: Их легко запускать в кластерных системах вроде Kubernetes или в бессерверных средах типа AWS Lambda.
- Легкость масштабирования: Достаточно просто добавить больше обработчиков (workers).
- Изолированные сбои: Выход из строя одного узла не влияет на другие.
- Быстрое восстановление: Не нужно восстанавливать какое-либо состояние.
Если ваши задачи укладываются в эти ограничения (нет агрегаций, нет необходимости группировать данные), вам следует использовать stateless-обработку. Часто для таких задач даже не нужен специализированный движок потоковой обработки — достаточно сервиса, который читает события из источника (например, Apache Kafka), выполняет простую логику и записывает результат.
Примеры использования:
- Сбор метрик с серверов, их преобразование и отправка в базу данных для мониторинга.
- Обработка логов: фильтрация, удаление конфиденциальных данных, изменение формата.
Пример простого SQL-запроса, который может быть выполнен в stateless-системе:
SELECT timestamp, redact(log_text) -- Выбираем время и скрываем часть текста лога
FROM logs
WHERE log_level = 'ERROR'; -- Только для событий с уровнем 'ERROR'Добавление состояния (Stateful)
Однако большинство бизнес-задач требуют запоминания информации о прошлых событиях, то есть требуют наличия состояния decodable.co. Вместе с состоянием часто возникает необходимость в перераспределении (shuffling) данных между узлами кластера.
Пример: Агрегации с состоянием для обнаружения мошенничества
Представим, что e-commerce сайт должен обнаруживать и блокировать мошеннические операции с кредитными картами. Один из эффективных признаков мошенничества — “сколько неудачных транзакций было у этого пользователя за последние 24 часа”.
С помощью SQL это можно выразить так:
SELECT
user_id,
count(*) as failed_count
FROM transactions
WHERE
status = 'FAILED'
GROUP BY
user_id,
-- hop - это функция скользящего окна в некоторых диалектах SQL
hop(INTERVAL '5 seconds', INTERVAL '24 hours');SQL-запрос преобразуется в граф операторов (конвейер), где каждый шаг выполняет свою часть логики.

Этот запрос подсчитывает количество неудачных событий для каждого `user_id`. Чтобы получить итоговое число, нам нужно, чтобы все события для одного и того же пользователя (например, “bob”) попадали на один и тот же вычислительный узел. Этот процесс перенаправления данных называется перераспределением (shuffling) и в SQL вводится оператором `GROUP BY`.
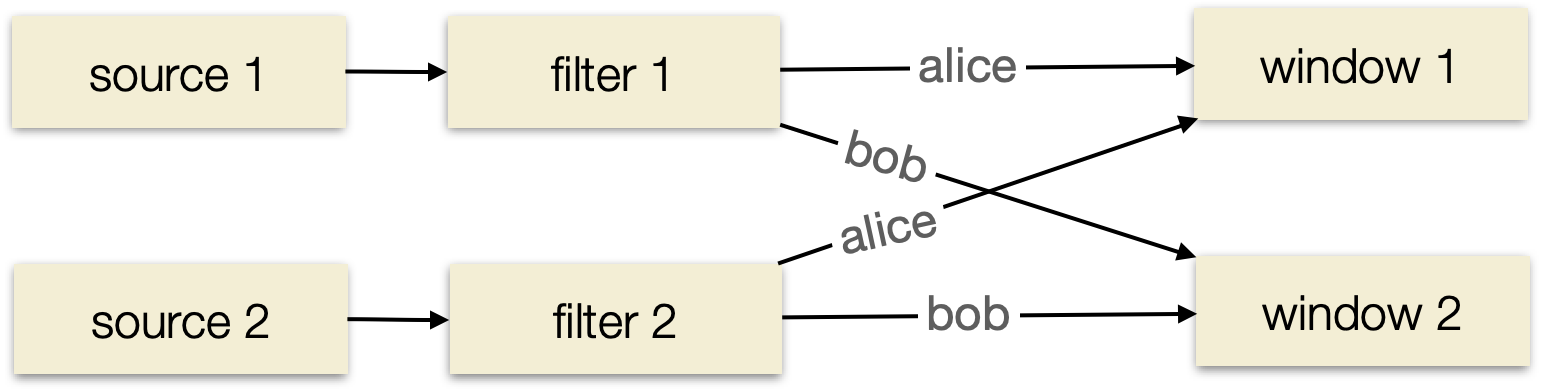
Но чтобы посчитать количество событий за 24 часа, система должна хранить эти события на протяжении всего окна. Это и есть состояние (state). Оно необходимо для любого запроса, который вычисляет агрегаты по времени.
Пример: Состояние в ETL-конвейерах
Состояние полезно даже в задачах, которые на первый взгляд кажутся простыми. Например, при загрузке событий в озерo данных ( вроде Amazon S3). Казалось бы, это stateless-операция: получил событие, преобразовал, записал.
Такой подход будет работать при небольшом объеме данных. Но с ростом трафика он приведет к проблемам с производительностью: запись множества мелких файлов в S3 неэффективна и сильно замедляет последующее чтение данных.
Решение с использованием состояния:
Stateful-движок может перераспределять события по их типу (`event_type`), направляя каждый тип на свой узел. Затем, используя состояние, он накапливает события в буфере в памяти, пока не соберется достаточно большой пакет (например, 8-16 МБ), и только потом записывает его в S3 одним большим файлом. Это значительно повышает производительность как записи, так и чтения.
Как и где хранится состояние?
Разные движки потоковой обработки решают эту задачу по-разному skyzh.dev:
| Движок/Система | Подход к хранению состояния | Пояснение |
| Apache Flink | Локально на узле (в памяти или RocksDB) | RocksDB — это встраиваемая key-value база данных, основанная на LSM-деревьях. Она позволяет хранить огромные объемы состояния, но сложна в настройке и может вызывать проблемы с I/O диска из-за операций сжатия (compaction). |
| ksqlDB / Kafka Streams | Гибридное (в Kafka и локально) | Часть состояния хранится в топиках Apache Kafka, а состояние для оконных функций — локально на узлах в памяти или RocksDB. |
| RisingWave / Arroyo | Удаленно (в S3 или FoundationDB) с локальным кэшем | Современный подход, при котором основное хранилище состояния отделено от вычислений. На вычислительных узлах находится только “горячий” кэш активных данных. Это значительно ускоряет масштабирование и восстановление после сбоев, так как не нужно перемещать терабайты данных между узлами. |

Согласованное сохранение состояния (Checkpointing)
Теперь, когда наши узлы хранят состояние, что произойдет, если они выйдут из строя? Если не принять мер, состояние будет потеряно.
Для обеспечения отказоустойчивости stateful-системы используют механизм контрольных точек (checkpointing) — периодическое создание согласованных “снимков” состояния всего конвейера и сохранение их в надежное хранилище (например, S3).
Ключевая задача здесь — гарантировать семантику “exactly-once” (ровно один раз). Это означает, что даже в случае сбоев и восстановлений каждое входящее событие будет обработано и повлияет на итоговое состояние ровно один раз, без потерь и дубликатов export.arxiv.org.
Для этого используется элегантный алгоритм Чанди-Лэмпорта. Его суть в том, что через поток данных пропускаются специальные маркеры — барьеры контрольных точек. Когда оператор получает барьеры от всех своих входов, он делает снимок своего текущего состояния и пересылает барьер дальше.

Современные системы делают этот процесс максимально эффективным:
- Асинхронность: Создание контрольной точки не блокирует обработку новых данных.
- Инкрементальность: В хранилище отправляются только измененные данные, а не всё состояние целиком.
Это позволяет создавать контрольные точки очень часто (например, каждые 10 секунд). В случае сбоя системе потребуется перечитать и обработать заново лишь данные за последние 10 секунд, что делает восстановление почти мгновенным.
Итог
Потоковая обработка без состояния (stateless) проста и эффективна для ограниченного круга задач, таких как фильтрация или простое преобразование данных.
Однако большинство нетривиальных бизнес-задач — распознавание паттернов, аналитика в реальном времени, корреляция событий — требуют обработки с состоянием (stateful) e6data.com. Исторически это было связано с большими операционными сложностями, особенно при использовании систем раннего поколения, которые хранили всё состояние локально на вычислительных узлах.
Современные движки, такие как RisingWave и Arroyo, решают эту проблему, отделяя хранение состояния от вычислений. Они используют удаленное хранилище с локальным кэшированием, что делает масштабирование, восстановление после сбоев и развертывание новых версий кода значительно проще и быстрее.
Таким образом, хотя stateful-системы по своей природе сложнее, современные архитектурные решения делают их мощь доступной для широкого круга задач, открывая дорогу для по-настоящему продвинутой аналитики в реальном времени.
А это тут пока положу, а то забуду :)
https://habr.com/ru/articles/774870 – Землю — крестьянам, gRPC — питонистам. Она про grpc питонячий.