
Расцвет одноузловой обработки: Бросая вызов подходу – распределённое решение в первую очередь
Введение
В 2024 году наблюдается растущий интерес к одноузловым системам обработки данных. Инструменты вроде DuckDB, Apache DataFusion и Polars привлекли внимание сообщества и стали невероятно популярными. Этот тренд — не просто технологический прогресс, а переосмысление подходов к аналитике данных.
По мере отказа от парадигмы «распределённые системы прежде всего», доминировавшей в эпоху «больших данных», компании обнаруживают, что одноузловые решения часто эффективнее, экономичнее и проще в управлении, особенно при работе с данными умеренного объёма.
Недавний пост «Почему одноузловые системы набирают обороты в обработке данных» в LinkedIn вызвал неожиданно живой отклик сообщества, что подчеркнуло возросший интерес к теме. В этой статье мы рассмотрим её подробнее.
---
Переосмысление «больших данных»
Последнее десятилетие компании активно внедряли стратегии big data, инвестируя в распределённые системы вроде Hadoop и Spark. Однако исследования показывают, что большинству компаний «большие данные» не нужны.
Итоги анализа:
- Jordan Tigani (основатель Google BigQuery): медианный объём данных у активных пользователей BigQuery — менее 100 ГБ.
- Исследование 500 млн запросов Amazon Redshift:
- 99% обрабатывали менее 10 ТБ данных;
- 90% сессий работали с менее чем 1 ТБ;
- 98% таблиц содержат меньше миллиарда строк.
Вывод: Для 90% запросов достаточно одноузловых систем вместо распределённых (Spark, Trino, Athena).
---
Паттерны рабочих нагрузок и старение данных
1. Эффект старения данных
Доступ к данным резко сокращается со временем:
- Горячие данные (0–48 часов): обработка ETL-пайплайнами.
- Тёплые данные (2–30 дней): основа аналитических запросов.
- Холодные данные (30+ дней): редко запрашиваются (сохранены для истории или аудита).
Исследование Meta и eBay подтверждает: 95% обращений к данным происходят в первые 48 часов. В «золотой» аналитической зоне 95% запросов выполняются в течение 30 дней.
2. Правило 90/10
90% рабочих нагрузок приходится на 10% данных (за 30 дней). Даже при хранении данных год, аналитики в основном работают с последними 30 днями.
---
Эволюция оборудования: масштабирование вверх вместо распределения
Рост возможностей одноузловых систем:
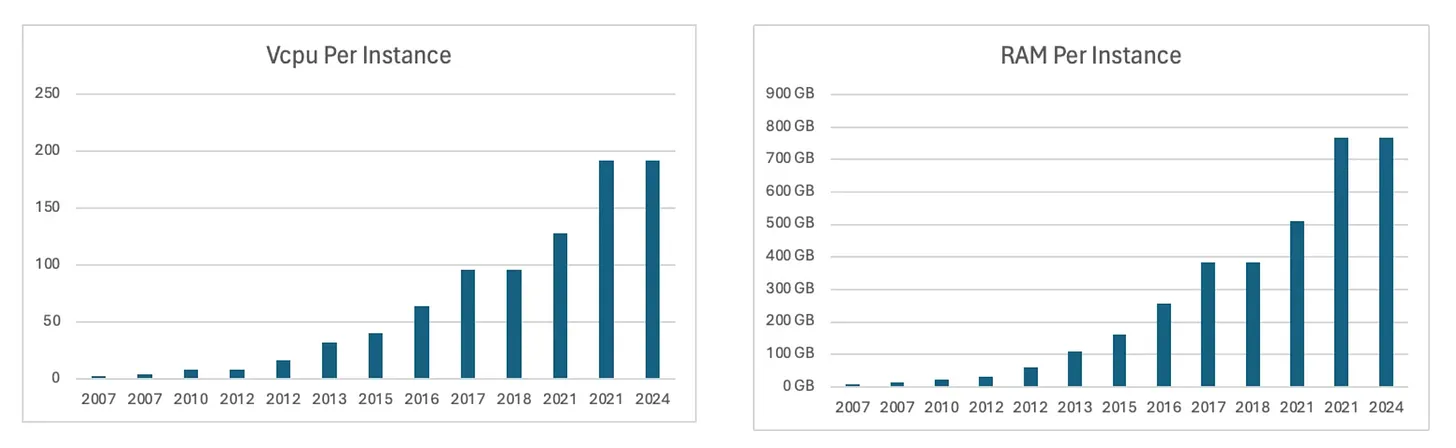
- В 2006 году (эпоха Hadoop) серверы имели 1 CPU и 2 ГБ RAM.
- Сегодня облачные инстансы (например, AWS EC2) предлагают 64+ ядер и 256+ ГБ RAM.
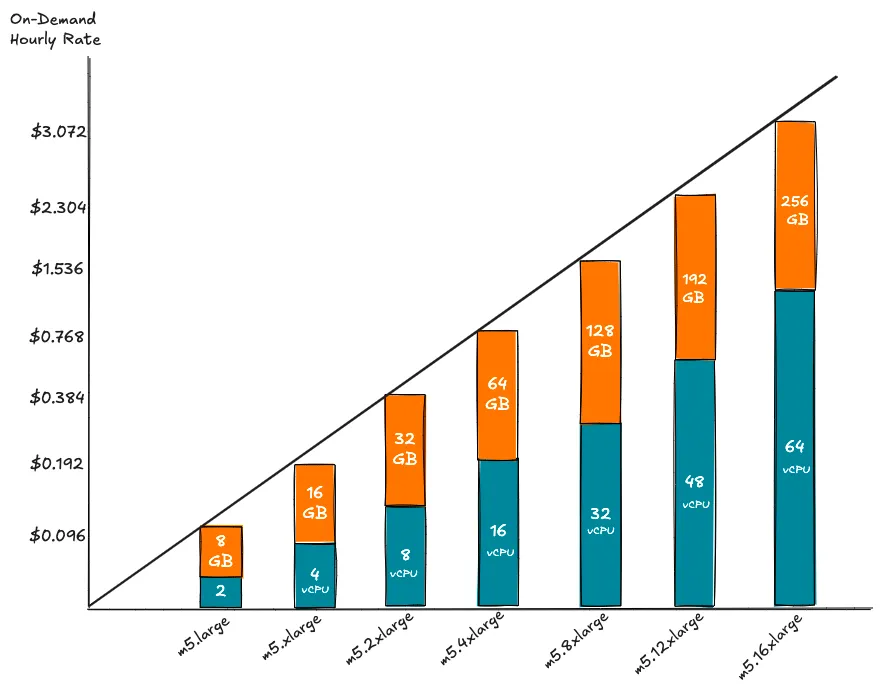
Экономика масштабирования:
- Стоимость крупных инстансов (например, m5.16xlarge) сопоставима с расходами на несколько мелких узлов (например, 8 × m5.2xlarge) при одинаковой мощности.
Итог: Современные одноузловые системы справляются с задачами, которые раньше требовали распределения, но с меньшей сложностью.
---
Производительность одноузловых систем
DuckDB, Apache DataFusion и другие движки используют:
- Векторизованное выполнение запросов;
- Параллелизм;
- Оптимизацию использования памяти.
Примеры роста скорости:
- Переход с Postgres на DuckDB дал ускорение в 4–200 раз (Vantage).
- DuckDB превзошёл коммерческие хранилища на TPC-DS до 300 ГБ (Fivetran).
---
Причины выбрать одноузловую обработку
- Простота: Меньше сложности, чем в распределённых системах.
- Эффективность: Реализация до 80% кода на C/C++ (против 10% в распределённых движках).
- Совместимость: Интеграция с облачными хранилищами, языками программирования, BI-инструментами.
---
Ограничения
- Не все движки эффективно используют многоядерные CPU.
- Пропускная способность RAM/CPU может стать узким местом.
- Очень большие наборы данных (>1 ТБ) всё ещё требуют распределения.
---
Заключение
Одноузловая обработка — прагматичный ответ на реальные потребности бизнеса. С развитием оборудования и оптимизацией движков необходимость в распределённых системах будет снижаться.
Главный вывод: Выбирайте инструмент под конкретную задачу, а не следуйте трендам. Будущее — за балансом между мощью одноузловых систем и гибкостью распределённых решений.
---
Полный дословный перевод:
Введение
В 2024 году наблюдался растущий интерес к фреймворкам одноузловой обработки, при этом такие инструменты, как DuckDB, Apache DataFusion и Polars, привлекли повышенное внимание и завоевали беспрецедентную популярность в сообществе специалистов по данным.
Эта тенденция представляет собой не просто технологический прогресс — она знаменует собой фундаментальную переоценку подхода к анализу данных.
По мере того, как мы отходим от подхода “распределённое решение в первую очередь” эпохи “больших данных”, многие предприятия обнаруживают, что решения одноузловой обработки зачастую обеспечивают более эффективный, экономичный и управляемый подход к своим аналитическим потребностям, когда размер их данных не так велик.
Когда я недавно опубликовал небольшую заметку в LinkedIn под названием “Почему одноузловые движки набирают обороты в обработке данных”, я не ожидал, что она привлечет такое значительное внимание со стороны сообщества специалистов по данным в LinkedIn. Этот отклик подчеркнул растущий интерес отрасли к этой теме.
В этой статье я углублюсь в эту тему, изучив её более детально и предоставив дополнительные сведения.
Переосмысление больших данных
Последнее десятилетие многие предприятия изо всех сил пытались внедрить стратегии больших данных, при этом многие компании вкладывали значительные средства в фреймворки распределенной обработки, такие как Hadoop и Spark.
Однако недавние анализы выявили удивительную правду: у большинства компаний на самом деле нет “больших данных”.
Значительному большинству компаний не требуются крупные платформы данных для удовлетворения своих потребностей в анализе данных. Часто эти компании поддаются маркетинговой шумихе и делают значительные инвестиции в эти платформы, которые могут неэффективно решать их фактические проблемы с данными.
Джордан Тигани, один из инженеров-основателей Google BigQuery, проанализировал шаблоны использования и обнаружил, что медианный размер хранилища данных среди активных пользователей BigQuery составляет менее 100 ГБ.
Ещё более показательным является анализ полумиллиарда запросов, выполненных в Amazon Redshift и опубликованных в статье:
- Более 99% запросов обработали менее 10 ТБ данных.
- Более 90% сеансов обработали менее 1 ТБ.
В статье также говорится, что:
- Большинство таблиц содержит менее миллиона строк, и подавляющее большинство (98%) — менее миллиарда строк. Большая часть этих данных достаточно мала, чтобы её можно было кэшировать или реплицировать.
Этот анализ показывает, что при пороговом значении для больших данных в 1 ТБ более 90% запросов находятся ниже этого порога.
В результате, одноузловые движки обработки потенциально способны обрабатывать рабочие нагрузки, которые ранее требовали распределенных систем, таких как Spark, Trino или Amazon Athena, для обработки на нескольких машинах.
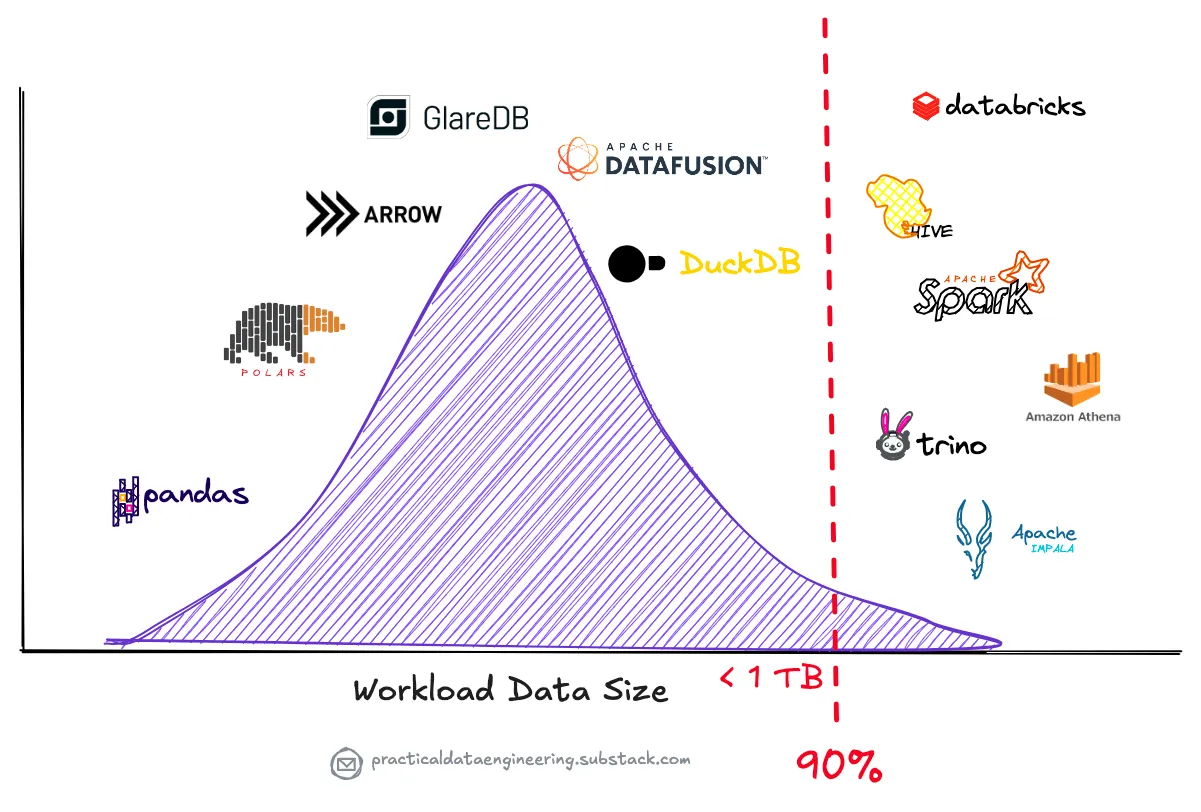
Эта реальность ставит под сомнение распространенное представление о том, что инфраструктура больших данных является необходимостью для всех современных предприятий.
Шаблоны рабочей нагрузки и быстрое устаревание данных
Аргументы в пользу одноузловой обработки становятся ещё более убедительными, когда мы изучаем, как организации в действительности используют свои данные.
Выявляются два ключевых шаблона: эффект устаревания данных и правило 90/10 для аналитических рабочих нагрузок.
Эффект устаревания данных
По мере устаревания данных частота доступа к ним резко снижается. Для большинства компаний шаблоны доступа к данным следуют предсказуемому жизненному циклу:
- Активные данные (0-48 часов): в основном из конвейеров ETL.
- Теплые данные (2-30 дней): составляют большую часть аналитических запросов.
- Холодные данные (30+ дней): редко используются, но часто хранятся для соответствия требованиям или исторического анализа.
Исследование шаблонов доступа к данным Meta и eBay выявило резкое снижение доступа после первых нескольких дней, причем данные обычно становились холодными через месяц.
В нашем анализе озера данных петабайтного масштаба мы обнаружили, что необработанные данные остаются активными только в течение 48 часов, причем 95% доступа приходится на это время, в основном со стороны нисходящих конвейеров ETL. В зоне Analytics (Gold) активный период длится около 7 дней, и 95% запросов выполняются только в течение 30 дней.
Правило 90/10 для аналитических рабочих нагрузок
Этот эффект устаревания приводит к правилу 90/10 в аналитических рабочих нагрузках:
- Если общий активный и теплый период составляет 30 дней и приходится на 90% рабочих нагрузок, то, при годовом сроке хранения, более 90% рабочих нагрузок получают доступ менее чем к 10% данных.
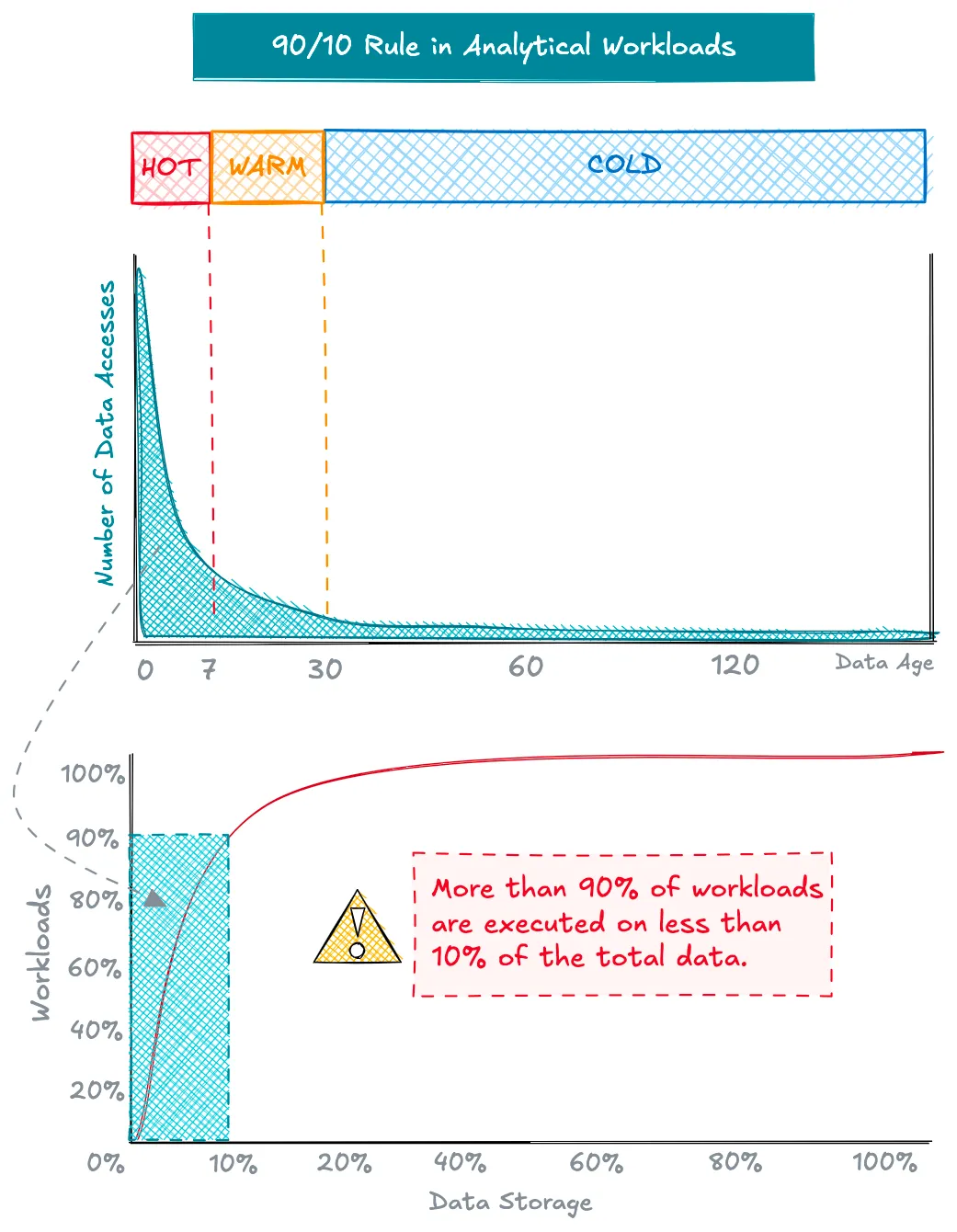
Этот шаблон остается удивительно постоянным в разных отраслях и вариантах использования. Даже в организациях с большими наборами данных большинство аналитических рабочих нагрузок работает с последними, агрегированными данными, которые легко помещаются в возможности одноузловой обработки.
Эволюция оборудования и переосмысление масштабирования вверх
Возможности одноузловых систем экспоненциально выросли со времен зарождения больших данных.
Обоснование и мотивация стратегии масштабирования по горизонтали (scale-out), которая стала популярной с появлением Hadoop в середине 2000-х годов в области обработки данных, заключаются в необходимости объединения нескольких машин для решения проблем масштабирования, что позволяет эффективно обрабатывать большие наборы данных в разумные сроки и с приемлемым уровнем производительности.
Интегрируя несколько машин в распределенные системы, мы фактически создаем единый большой блок, объединяя ресурсы, такие как ОЗУ, ЦП, дисковое пространство и пропускную способность, в одну большую виртуальную машину.
Однако нам необходимо переоценить наши предположения о распределенной обработке и проблемах масштабирования, с которыми мы столкнулись в 2000-х годах, чтобы увидеть, остаются ли они актуальными сегодня.
В 2006 году, когда появился Hadoop MapReduce, первые инстансы AWS EC2 (m1.small) имели всего 1 ЦП и менее 2 ГБ ОЗУ. Сегодня облачные провайдеры предлагают инстансы с 64+ ядрами и 256 ГБ+ ОЗУ, что кардинально меняет ситуацию с возможностями одноузловой обработки.
Изучение эволюции сбалансированных инстансов EC2 с точки зрения памяти и ЦП (с соотношением 1:4) на протяжении многих лет выявляет экспоненциальный рост, поскольку эти инстансы со временем становятся все более мощными.
Экономика масштабирования вверх (Scale-Up) против масштабирования по горизонтали (Scale-Out)
Можно предположить, что масштабирование по горизонтали на нескольких небольших инстансах более рентабельно, чем использование более крупных инстансов. Однако модели облачного ценообразования говорят об обратном.
Стоимость за вычислительную единицу в облаке является постоянной, независимо от того, используете ли вы меньший или больший инстанс, поскольку стоимость увеличивается линейно.
То есть стоимость более крупных вычислительных инстансов в облаке увеличивается линейно, и общая цена остается той же, независимо от того, используете ли вы один более крупный инстанс или несколько небольших инстансов, при условии, что общее количество ядер и памяти одинаково.
Используя семейство инстансов m5 от AWS в качестве примера, независимо от того, масштабируетесь ли вы вверх с помощью одного инстанса m5.16xlarge или масштабируетесь по горизонтали с помощью восьми инстансов m5.2xlarge, цена за час останется той же.
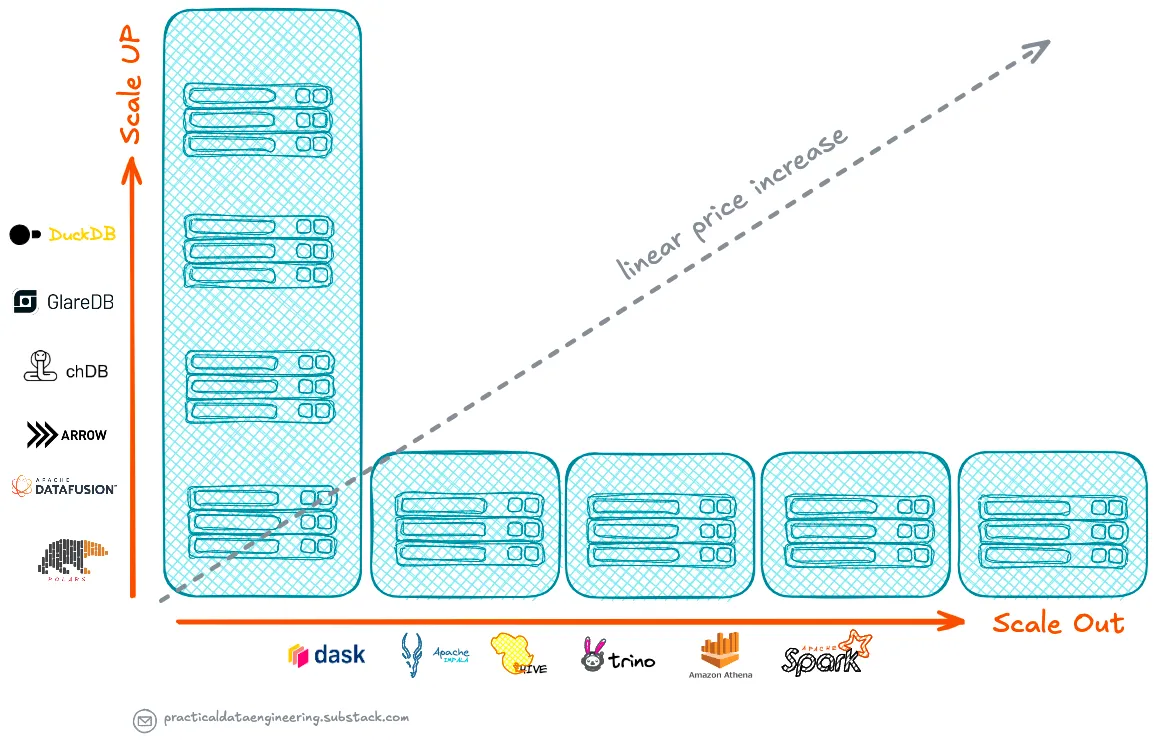
Эта эволюция оборудования имеет важные последствия для решений по архитектуре системы, поскольку:
- Современные инстансы могут обрабатывать рабочие нагрузки, которые ранее требовали десятков небольших узлов, и делают это с меньшей сложностью и накладными расходами.
Это поднимает критический вопрос:
- С точки зрения соотношения цены и производительности, если одноузловой движок запросов может эффективно обрабатывать большинство рабочих нагрузок, есть ли еще выгода от распределения обработки по нескольким узлам?
Аргумент производительности для одноузловой обработки
Современные одноузловые движки обработки используют передовые методы для достижения впечатляющей производительности.
Движки, такие как DuckDB и Apache DataFusion, достигают превосходной производительности благодаря сложным методам оптимизации, включая векторизованное выполнение, параллельную обработку и эффективное управление памятью.
Многочисленные тесты показывают эти улучшения производительности:
- Vantage сообщила, что при переходе с Postgres на DuckDB для анализа затрат на облако они увидели улучшение производительности в диапазоне от 4X до 200X.
- Тесты генерального директора Fivetran с использованием наборов данных TPC-DS показали, что DuckDB превосходит коммерческие хранилища данных для наборов данных размером менее 300 ГБ.
- Эксперимент с 1 миллиардом строк поддельных данных о заказах, сравнивающий DuckDB с Amazon Athena.
Почему стоит выбрать одноузловую обработку?
Аргументы в пользу одноузловой обработки выходят за рамки простой производительности. Для большинства предприятий современные одноузловые движки предлагают несколько веских преимуществ:
- Они значительно упрощают архитектуру системы, устраняя сложность распределенных систем. Это упрощение снижает эксплуатационные расходы, облегчает отладку и снижает порог входа для команд, работающих с данными.
- Они часто обеспечивают лучшее использование ресурсов. Без накладных расходов на сетевую связь и распределенную координацию больше вычислительной мощности можно выделить для фактической обработки данных. Эта эффективность напрямую приводит к экономии затрат и повышению производительности.
- Они предлагают отличную интеграцию с современными рабочими процессами обработки данных. Такие движки, как chDB и DuckDB, могут напрямую запрашивать данные из облачного хранилища, бесперебойно работать с популярными языками программирования и органично вписываться в существующие конвейеры обработки данных.
- Встраиваемая природа некоторых из этих движков обеспечивает бесшовную интеграцию с существующими системами — от расширений PostgreSQL, таких как pg_analytics и pg_duckdb, до различных современных инструментов Business Intelligence — расширяя аналитические возможности без нарушения установленных рабочих процессов.
Проблемы и ограничения
Хотя одноузловая обработка предлагает много преимуществ, важно признать её ограничения.
- Некоторые движки по-прежнему сталкиваются с проблемами полного использования всех доступных ядер ЦП на больших машинах, особенно по мере увеличения количества ядер. Пропускная способность иерархии памяти между ОЗУ и ЦП может стать узким местом для определенных рабочих нагрузок.
- При чтении из облачного хранилища, такого как S3, скорость передачи данных через одно соединение может быть ограничена, хотя это часто можно смягчить с помощью параллельных соединений и интеллектуальных стратегий кэширования. И, естественно, остаются рабочие нагрузки, включающие очень большие наборы данных, которые превышают доступную память и хранилище, требующие распределенной обработки.
Заключение
Расцвет одноузловых движков обработки представляет собой прагматичный сдвиг в анализе данных. Поскольку возможности оборудования продолжают развиваться, а одноузловые движки становятся все более сложными, потребность в распределенной обработке, вероятно, продолжит снижаться для большинства организаций.
Для подавляющего большинства компаний фреймворки одноузловой обработки предлагают более эффективное, экономичное и управляемое решение для их потребностей в анализе данных. По мере продвижения вперед главное — не автоматически тянуться к распределенным решениям, а тщательно оценивать фактические требования к рабочей нагрузке и выбирать правильный инструмент для работы.
Будущее обработки данных вполне может быть менее связано с управлением кластерами и больше с использованием впечатляющих возможностей современных одноузловых систем.
Спасибо автору ALIREZA SADEGHI и оригиналу: https://www.pracdata.io/p/the-rise-of-single-node-processing