
Распределённое хранилище данных с Bacalhau и DuckDB
Оригинал тут: https://blog.bacalhau.org/p/distributed-data-warehouse-with-bacalhau
Это часть 5-дневной серии о Bacalhau 1.7
День 1: Анонс Bacalhau 1.7.0: Расширение возможностей предприятий за счет улучшенной масштабируемости, управления заданиями и поддержки
День 2: Масштабирование вычислительных задач с помощью разделенных заданий Bacalhau
День 3: Упрощение безопасности: Облегчение модели аутентификации Bacalhau
День 4: Использование разделения AWS S3 с Bacalhau
Это пятая часть – Распределенное хранилище данных с Bacalhau и DuckDB
Во многих приложениях, полагающихся на хранилища данных, необходимо хранить источники данных в разных местах. Это может быть связано с соображениями конфиденциальности, нормативными требованиями или желанием обрабатывать данные ближе к источнику. Однако бывают случаи, когда необходимо проводить анализ этих источников данных из одного места, не перемещая данные.
В этой статье Bacalhau используется для организации распределенной обработки, а DuckDB предоставляет возможности SQL-хранения и запросов для некоторой фиктивной информации о продажах, расположенной в ЕС и США.
Предварительные требования
Для воспроизведения этого руководства вам понадобятся следующие компоненты:
- Bacalhau CLI
- Docker и Docker Compose
- Пример многорегиональной настройки:
git clone https://github.com/bacalhau-project/examples.gitАрхитектура
Пример файла Docker Compose и определения заданий Bacalhau в репозитории примеров имитируют следующую архитектуру:
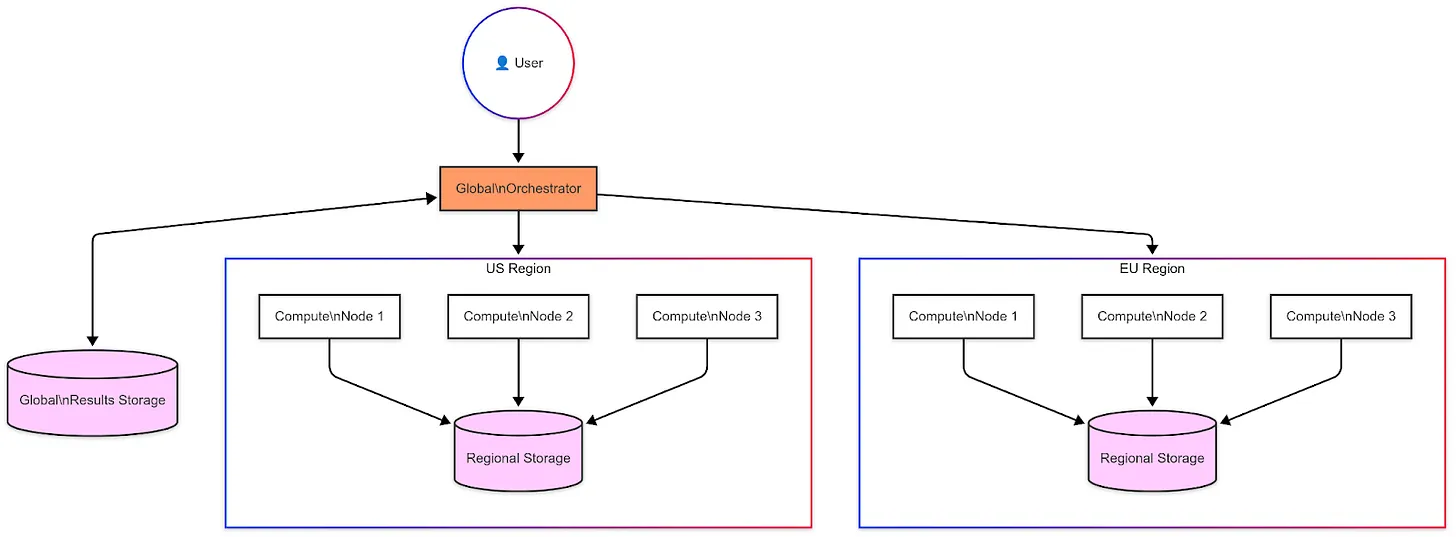
- Оркестратор Bacalhau:** Центральная панель управления для распределения заданий
- Вычислительные узлы:** Распределены по регионам, работают близко к данным
- Региональное хранилище:** Региональные хранилища данных, использующие MinIO в этой настройке
- DuckDB:** Механизм SQL-запросов, работающий на каждом вычислительном узле. Bacalhau использует пользовательский образ, который добавляет несколько определяемых пользователем функций для помощи в разделении больших наборов данных между узлами на основе следующих методов:
- `partition_by_hash`: Равномерное распределение файлов по разделам
- `partition_by_regex`: Разделение на основе шаблонов
- `partition_by_date`: Разделение на основе времени
Вы можете найти более подробную информацию о том, как работают эти функции, в документации по пользовательскому образу.
Вы можете увидеть настройку каждого компонента в файле Docker Compose. Создайте архитектуру, выполнив следующую команду:
docker compose up -dФайл Docker Compose использует несколько файлов конфигурации Bacalhau, которые вы можете увидеть в папке configuration, где вычислительные узлы помечены как узлы US и EU соответственно.
Они также настраивают узлы оркестратора для записи данных в региональные бакеты MinIO.
Создание образцов данных
После того, как вы создали имитацию инфраструктуры, вы можете создать образцы данных, используя задание генератора данных, чтобы записать 3000 записей в каждый регион в формате JSON в соответствующий бакет MinIO.
Перейдите в каталог заданий
cd ../jobsСгенерируйте данные для США:
bacalhau job run -V Region=us -V Events=3000 \
-V StartDate=2024-01-01 -V EndDate=2024-12-31 \
-V RotateInterval=month data-generator.yamlСгенерируйте данные для ЕС:
bacalhau job run -V Region=eu -V Events=3000 \
-V StartDate=2024-01-01 -V EndDate=2024-12-31 \
-V RotateInterval=month data-generator.yamlДоступ к данным для анализа
Bacalhau поддерживает два способа доступа к региональным данным:
- Источники ввода Bacalhau**
InputSources:
- Type: s3
Source:
Bucket: local-bucket
Key: "data/*"Этот метод предоставляет больше контроля, параметров предварительной обработки и поддерживает другие типы источников, помимо S3.
- Прямой доступ DuckDB**
SET VARIABLE files = (
SELECT LIST(file)
FROM partition_by_hash('s3://local-bucket/**/*.jsonl')
);
SELECT * FROM read_json_auto(getvariable('files'));Этот метод проще и привычнее для заданий, использующих только SQL. Определения заданий также используют SQL-запросы для обработки данных из источника ввода.
Выполнение анализа
После размещения данных вы можете отправлять задачи анализа в виде заданий Bacalhau. В каждом случае, после запуска задания используйте `
bacalhau job describe <job_id>`, чтобы увидеть результаты задания, передав идентификатор задания из вывода команды `
bacalhau job run`. Во всех примерах показано использование данных из США. Вы также можете изменить `Region` на `eu`, чтобы увидеть результаты из региона ЕС.
- Анализ месячных трендов**
bacalhau job run -V Region=us monthly-trends.yamlОпределение задания.
Пример вывода:
month | total_txns | revenue | unique_customers | avg_txn_value
------------|------------|----------|------------------|---------------
2024-03-01 | 3,421 | 178,932 | 1,245 | 52.30
2024-02-01 | 3,156 | 165,789 | 1,189 | 52.53
2024-01-01 | 2,987 | 152,456 | 1,023 | 51.04- Оперативный мониторинг**
- Hourly Operations (Почасовые операции)
- Отслеживает метрики работоспособности
- Контролирует процент успешных транзакций
- Показывает почасовые закономерности
bacalhau job run -V Region=us hourly-operations.yaml- Anomaly Detection (Обнаружение аномалий)
- Идентифицирует необычные паттерны
- Использует статистический анализ
- Отмечает значительные отклонения
bacalhau job run -V Region=us anomaly-detection.yaml- Бизнес-аналитика**
- Product Performance (Эффективность продукта)
- Анализирует эффективность категорий
- Отслеживает долю рынка
- Показывает паттерны продаж
bacalhau job run -V Region=us product-performance.yaml- Monthly Trends (Месячные тренды)
- Долгосрочный анализ трендов
- Месячные агрегации
- Ключевые бизнес-показатели
bacalhau job run -V Region=us monthly-trends.yaml- Анализ клиентов**
- Customer Segmentation (Two-Phase) (Сегментация клиентов (Двухфазная))
- Фаза 1: Вычисление локальных метрик
- Фаза 2: Объединение и сегментация
- Запустите Фазу 1
bacalhau job run -V Region=us customer-segments-phase1.yaml- Запомните ID задания и запустите Фазу 2
bacalhau job run -V Region=us -V JobID=<phase1-job-id> customer-segments-phase2.yamlИтог
В этой статье объединены распределенные вычислительные мощности Bacalhau с гибкими возможностями SQL DuckDB для создания распределенного хранилища данных, разнесенного по регионам. Примеры заданий Bacalhau предоставляют ряд аналитических задач, от оперативного мониторинга до сегментации клиентов, при этом данные остаются в исходном месте и используются запросы SQL к данным, хранящимся в S3-совместимых бакетах.