
Сравнение Query движков Trino и StarRocks
В этом посте мы хотим сравнить Trino, популярный распределенный движок для выполнения аналитических запросов на больших объемах данных с интерактивными задержками, с StarRocks.
Источники информации
Мы консультировались с участниками StarRocks (Хэнг Чжао, член TSC StarRocks; Дориан Чжэн, активный участник StarRocks). Что касается Trino, мы использовали веб-сайт Trino и поиск в Google для исследования различных тем. Мы сравнили последние версии обоих продуктов на октябрь 2023 года.
Возрождение Trino/Presto
Изначально Presto был задуман и разработан в Facebook (теперь известном как Meta) для того, чтобы позволить их аналитикам выполнять интерактивные запросы в их обширном хранилище данных Apache Hadoop. Проект, возглавляемый Мартином Траверсо, Дэйном Сандстромом, Дэвидом Филлипсом и Эриком Хуангом, начался в 2012 году как решение для преодоления ограничений Apache Hive, который ранее использовался для SQL-аналитики в обширном хранилище данных Facebook, но оказался слишком медленным для обширных потребностей компании. Presto был публично внедрен в Facebook в том же году и позже был представлен в виде open source в ноябре 2013 года.
В 2013 году, когда он появился, у него были некоторые значительные преимущества.
- Мог эффективно обрабатывать большие наборы данных и сложные запросы (по сравнению с другими технологиями, доступными на тот момент).
a. Конкретно, гораздо быстрее, чем технология MapReduce, такая как Apache Hive, которая тогда была актуальной.
b. Мог подключаться к множеству различных источников данных: в частности, подключаться к нескольким базам данных одного типа с возможностью объединения наборов данных между базами данных (например, горизонтальное масштабирование экземпляров баз данных). - Мог масштабироваться для удовлетворения потребностей крупных организаций: Facebook продемонстрировал, что Presto может работать, и другие технологические “единороги” быстро приняли его для своих потребностей в хранилище данных.
- Open Source: кто не хочет, чтобы кто-то другой проводил исследования и разработку программного обеспечения за “бесплатно”?
Проект Presto претерпел значительные изменения за десятилетие. В 2018–2019 годах, после ухода оригинальных основателей из Facebook, проект разделился на две ветки: PrestoDB и PrestoSQL. Это разделение было ответом на изменяющиеся потребности и направление сообщества Presto.
Trino возник из ветви PrestoSQL. В январе 2021 года PrestoSQL был переименован в Trino. Trino сохранил свои корни в обработке данных большого объема, принимая архитектуру Massively Parallel Processing (MPP) и разрабатываясь на Java. Это отличало его от традиционных фреймворков MapReduce, улучшая его способность эффективно обрабатывать и обрабатывать большие объемы данных.
Изменение требований пользователей
С момента появления Trino/Presto они удовлетворительно соответствовали большинству потребностей пользователей в анализе данных на тот момент. Тем не менее стоит отметить, что требования пользователей к анализу данных по-прежнему постоянно меняются и развиваются. Это особенно явно после того, как мир был завоеван мобильным интернетом и приложениями SaaS, с пользовательским анализом и аналитикой в реальном времени, становящимися важными трендами для предприятий.
Основные проявления этого тренда следующие:
- Предприятия надеются иметь более производительные системы запросов для удовлетворения потребности в запросах с низкой задержкой на огромных объемах данных. Ни один пользователь не хочет ждать больше трех секунд перед экраном.
- Предприятия нуждаются в возможности поддерживать сотни, а то и тысячи человек, одновременно проводящих запросы и анализ данных. Постоянно растущее количество пользователей стало толчком для этого спроса.
- Предприятия стремятся к своевременному анализу последних данных и использованию результатов анализа для направления последующей работы.
В нынешнюю постпандемическую эпоху, как сохранить издержки и улучшить эффективность работы в такой неблагоприятной экономической обстановке? Это еще один вопрос, на который каждое предприятие должно ответить.
Именно из-за этих новых трендов несколько инженеров баз данных начали новый проект базы данных в 2020 году, названный StarRocks, и официально открыли его исходный код в сентябре 2021 года. StarRocks был передан в Linux Foundation в начале 2023 года. Хотя он существует недолго, влияние StarRocks, кажется, стремительно растет. В настоящее время сотни крупных предприятий по всему миру используют StarRocks в производственных средах.
Смотря на сценарии использования, у StarRocks и Trino/Presto есть значительная степень пересечения. Просто говоря, StarRocks более подходит для сценариев, ориентированных на конечного пользователя с низкой задержкой, в то время как Trino/Presto более подходит для аналитических сценариев, включающих извлечение данных из нескольких источников данных одновременно.
Сходства между Trino и StarRocks
У StarRocks и Trino много сходств в технических характеристиках.
Massively Parallel Processing (MPP)
Обе системы используют MPP в качестве своей распределенной среды выполнения. В этой среде запрос разбивается на множество логических и физических блоков выполнения и выполняется одновременно на нескольких узлах. В отличие от шаблона scatter-gather, используемого многими другими продуктами для аналитики данных в их распределенных вычислительных средах, MPP может использовать больше ресурсов для обработки запросов. Из-за этой среды обе системы могут использоваться для работы с петабайтами данных, и сотни крупных компаний уже используют эти системы в своих производственных средах.
Cost-based Optimizer (CBO)
У обеих систем есть Cost-based Optimizer. В запросах с многотабличным объединением, помимо исполнителя запроса, оптимизированные планы выполнения также могут сыграть ключевую роль в улучшении производительности запроса. Благодаря CBO обе системы могут поддерживать различные функции SQL, включая сложные запросы, объединения и агрегации. Как Trino, так и StarRocks успешно прошли тесты TPC-H и более сложного теста TPC-DS.
Pipeline Execution Framework
У обеих систем есть Framework выполнения конвейера. Основная цель Framework выполнения конвейера – улучшение эффективности использования многозадачных ресурсов в запросе на одном компьютере. Его основные функции охватывают три аспекта:
- Снижение стоимости планирования задач для различных вычислительных узлов в запросе.
- Увеличение использования процессора при обработке запросов.
- Автоматическая настройка параллелизма выполнения запросов для полного использования вычислительной мощности многозадачных систем, тем самым повышая производительность запроса.
ANSI SQL Support
Обе системы соответствуют ANSI SQL. Это означает, что аналитики могут использовать язык запросов, с которым они наиболее знакомы в своей повседневной работе, без необходимости дополнительных затрат на обучение. Инструменты бизнес-аналитики, которыми часто пользуются предприятия, также легко интегрируются с StarRocks или Trino.
Различия между Trino и StarRocks
Хотя есть некоторые сходства в технической реализации, мы также видим некоторые явно различные технические характеристики между этими двумя видами систем.
StarRocks – это нативный векторизированный движок, реализованный на C++, в то время как Trino реализован на Java и использует ограниченную технологию векторизации. Технология векторизации помогает StarRocks более эффективно использовать вычислительную мощность ЦП. Этот тип движка запросов обладает следующими характеристиками:
- Полностью использует эффективность управления данными в столбцах. Такой движок запросов читает данные из колоночного хранилища, и способ управления данными в памяти, а также способ обработки операторов данных, является колоночным. Такие движки могут более эффективно использовать кэш ЦП, повышая эффективность выполнения ЦП.
- Полностью использует SIMD-инструкции, поддерживаемые ЦП. Это позволяет ЦП завершать больше вычислений данных за меньшее количество тактовых циклов. Согласно данным, предоставленным StarRocks, использование векторизированных инструкций может улучшить общую производительность в 3-10 раз.
- Более эффективно сжимает данные, что значительно снижает использование памяти. Это делает такой тип движка запросов более способным обрабатывать запросы с большим объемом данных.
Фактически Trino также исследует технологию векторизации. У Trino есть некоторый SIMD-код, но он отстает по сравнению с StarRocks по глубине и охвату. Trino все еще работает над улучшением своих усилий по векторизации (см. https://github.com/trinodb/trino/issues/14237). Проект Velox в Meta направлен на использование технологии векторизации для ускорения запросов Trino. Однако до сих пор очень мало компаний официально использовали Velox в производственных средах.
У StarRocks есть несколько функций материализованных видов, которых у Trino нет. Материализованный вид – это продвинутый способ ускорения общих запросов. Как StarRocks, так и Trino поддерживают создание материализованных видов; однако у StarRocks есть возможность:
- Автоматически переписывать запросы для улучшения производительности запроса. Это означает, что StarRocks автоматически выбирает подходящие материализованные виды для ускорения запросов. Пользователям не нужно переписывать свои SQL-запросы, чтобы использовать материализованные виды.
- Выполнять обновление материализованного вида на уровне раздела, что позволяет пользователю добиться лучшей производительности и масштабируемости при снижении потребления ресурсов.
- Возможность записи материализованных видов на локальный диск вместо удаленного диска/хранилища. Это означает, что пользователи могут использовать высокую производительность локального диска. Локальное хранилище использует собственный колоночный формат хранения StarRocks, который лучше поддерживает выполнение векторизированного движка запросов.
У Trino в настоящее время нет этих функций:
- Отсутствие автоматической функции переписывания запросов. Пользователю нужно затратить много времени на переписывание запросов.
- Необходимость выполнять обновление материализованного вида для всей таблицы при изменении данных.
- Невозможность записи материализованных видов на локальный диск.
- Идет обсуждение о том, как улучшить “свежесть” материализованного вида.
Система кэширования в StarRocks сложнее, чем в Trino. StarRocks реализует кластер-осведомленный кэш данных на каждом узле. Этот кэш использует комбинацию памяти и диска, которую можно использовать для промежуточных и конечных результатов запроса. В результате этого компонента StarRocks имеет возможность кэшировать метаданные Apache Iceberg на локальных дисках для лучшей производительности запросов. StarRocks также поддерживает предварительное заполнение кэша, установку приоритетов кэша и установку черных списков кэша.
Кэш запросов StarRocks значительно улучшает производительность запросов в сценариях высокой конкурентоспособности. Он функционирует путем кэширования промежуточных результатов каждого вычислительного узла в памяти для последующего повторного использования. Кэш запросов отличается от обычного
кэша результатов. В то время как обычный кэш результатов эффективен только для идентичных запросов, кэш запросов также может ускорять запросы, которые не являются точными копиями. Согласно тестам инженеров разработки StarRocks, кэш запросов может улучшить эффективность запроса в 3-17 раз.
Система кэширования Trino работает только на уровне памяти. Это делает ее очень быстрой и предполагает использование более многочисленных и крупных виртуальных машин с памятью. Ведется работа по поддержке кэширования на локальном диске для “горячего кэша”.
Подробнее читайте по ссылкам https://github.com/trinodb/trino/pull/16375 и https://github.com/trinodb/trino/pull/18719.

Как Trino, так и StarRocks могут поддерживать сложные операции соединения. Однако StarRocks способен предоставить более высокую производительность. Это происходит потому, что, помимо векторизированного движка запросов, StarRocks также обладает некоторыми специальными техническими возможностями.
Переупорядочивание соединений – это техника, которая может быть использована для улучшения производительности запросов к базе данных, включающих множественные соединения. Она работает путем изменения порядка выполнения соединений.
Стоимость выполнения запроса соединения зависит от размера таблиц, участвующих в соединении, и порядка выполнения соединений. Переупорядочивая соединения, можно найти более эффективный план соединения. Переупорядочивание соединений может выполняться оптимизатором или может быть указано вручную пользователем. Оптимизатор обычно пытается переупорядочить соединения для минимизации стоимости запроса.
Существует несколько различных алгоритмов, которые могут использоваться для переупорядочивания соединений. Некоторые из наиболее распространенных алгоритмов, реализованных в StarRocks, включают:
- Жадный алгоритм: Жадный алгоритм работает путем повторного выбора пары таблиц с наименьшей стоимостью соединения и их объединения.
- Алгоритм динамического программирования: Алгоритм динамического программирования работает построением таблицы, содержащей стоимость соединения каждой пары таблиц. Затем алгоритм использует эту таблицу для поиска оптимального плана соединения.
- Алгоритм исчерпания: Техника выполнения соединений данных, особенно подходящая для больших наборов данных. Он работает разбиением операции соединения на более мелкие, более управляемые задачи, что позволяет выполнять соединения с наборами данных, которые слишком велики для помещения в память.
- Переупорядочивание соединений слева-направо: Эвристический алгоритм, используемый для оптимизации порядка соединений в запросе. Алгоритм начинает с самой маленькой таблицы и затем рекурсивно соединяет ее с следующей по размеру таблицей, пока все таблицы не будут соединены.
- Алгоритм ассоциативности соединения: Техника оптимизации порядка соединений в запросе. Он работает путем использования свойства ассоциативности соединений, которое утверждает, что порядок соединений можно изменить без влияния на результат.
- Алгоритм коммутативности соединения: Техника оптимизации порядка соединений в запросе. Он использует свойство коммутативности соединений, которое утверждает, что порядок операндов соединения можно изменить без влияния на результат.
В целом StarRocks реализует (по последним данным) на 5 алгоритмов больше, чем Trino.
Еще одной важной особенностью StarRocks для производительности соединения является фильтрация во время выполнения. Фильтрация во время выполнения – это техника, которая может использоваться для улучшения производительности операций соединения данных. Она работает путем фильтрации строк из одной таблицы до их соединения с другой таблицей на основе условия соединения. Это может значительно снизить объем данных, который необходимо обработать, что может привести к значительному улучшению производительности.
Поддержка локальных и глобальных фильтров во время выполнения
Осведомленность о перемешивании
Отправка максимума/минимума, в фильтр в хранилище
Оценка стоимости на основе
Поддержка кэша фильтров во время выполнения
Передача фильтра во время выполнения в обе стороны
SIMD-фильтр Блума
Адаптивный выбор фильтров во время выполнения соединения
Поддержка фильтрации во времени выполнения с несколькими столбцами
Наконец, StarRocks может поддерживать соединение с соседним распределением. Соединение с соседним распределением – это тип соединения, при котором таблицы, участвующие в соединении, хранятся на тех же узлах распределенного кластера базы данных. Это может значительно улучшить производительность операции соединения, поскольку данные не нужно передавать между узлами для обработки.
Высокая доступность
У StarRocks есть два типа узлов, каждый из которых способен достигнуть высокой доступности через конкретные стратегии. Узлы Front End являются безсостоятельными, и высокую доступность можно достичь, развернув нечетное количество узлов Front End. Эти узлы используют протокол Raft для выбора лидера среди себя. Узлы Back End поддерживают механизм с множественными репликами, обеспечивая, что отказ любого узла не влияет на работу системы. Таким образом, StarRocks может выполнять горячие обновления системы. Во время обновления системы онлайн-сервисы системы не будут затронуты.
Trino не имеет встроенной поддержки высокой доступности (HA). Координатор Trino – единственная точка отказа в системе. Если этот узел выходит из строя, вся система становится недоступной. Это означает, что при каждом обновлении системы онлайн-сервисы Trino должны быть приостановлены на определенное время. До сих пор проект Trino не предложил решения этой проблемы. Подробнее читайте по ссылке https://github.com/trinodb/trino/issues/391.
Источники данных и открытые форматы таблиц
Как сторонники концепции Data Mesh, сообщество Trino всегда стремилось к интеграции большего количества источников данных. До сих пор Trino разработал более 60 различных коннекторов, обеспечивающих подключение к различным источникам данных, включая реляционные базы данных, озера данных и другие. Это позволяет Trino выступать в качестве унифицированного движка запросов для предприятий, облегчая совместный анализ данных из различных источников. Это особенно полезно для крупных предприятий с несколькими бизнесами и разнообразными источниками данных. В настоящее время StarRocks более ориентирован на запросы открытых озер данных и имеет меньше коннекторов для других источников данных.
StarRocks поддерживает чтение как для Apache Iceberg, Apache Hudi, Apache Hive, так и для Delta Lake. Кроме того, StarRocks также поддерживает ограниченные возможности записи в Apache Iceberg. Результаты бенчмарк-тестирования показывают, что StarRocks работает быстрее в качестве движка запросов для озер данных. Trino поддерживает чтение и запись как для Apache Iceberg, Apache Hudi, Apache Hive, так и для Delta Lake. Согласно дорожной карте StarRocks, возможности записи в открытые озера данных будут улучшены в ближайшее время.
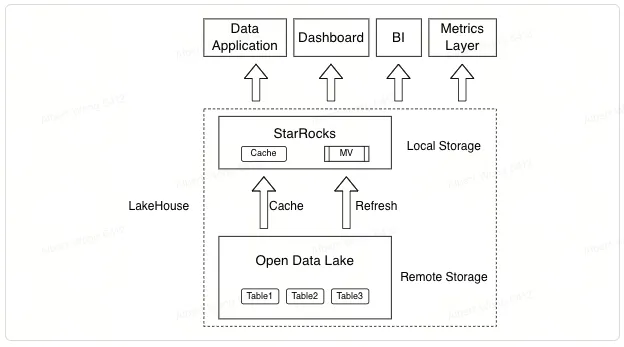
Возможности Data Lakehouse StarRocks
Именно благодаря этим уникальным техническим особенностям StarRocks может предоставить пользователям более полный опыт работы с Lakehouse. Использование StarRocks для прямого запроса данных из озер данных позволяет достигнуть производительности, сравнимой с хранилищами данных. Это позволяет строить множество бизнес-приложений напрямую на озерах данных, устраняя необходимость импорта данных в хранилища данных для анализа. Система кэширования StarRocks может использовать локальное хранилище вычислительных узлов для кэширования данных, транспарентно ускоряя производительность запросов. Пользователям не нужно создавать дополнительные конвейеры для управления передачей данных.
В некоторых сценариях анализа данных, где требуется более низкая задержка запроса и более высокая конкурентоспособность запроса, материализованные представления StarRocks играют значительную роль. Материализованные представления не только ускоряют связанные запросы с использованием локального хранилища вычислительных узлов, но и их обновления данных автоматически, не требуя ручного вмешательства. Кроме того, функция автоматического переписывания материализованных представлений позволяет пользователям наслаждаться ускоренными эффектами представлений без переписывания SQL.
Совмещая различные уникальные технологии, StarRocks действительно достигает пользовательского и высокопроизводительного опыта с открытым исходным кодом в сфере озер данных.
Команда StarRocks провела бенчмарк-тестирование на наборе данных TPC-DS объемом 1 ТБ. Они использовали StarRocks и Trino для запроса одной и той же копии данных, хранящихся в формате таблицы Apache Iceberg с файлами Parquet. Результат заключается в том, что общее время ответа на запрос в Trino медленнее в 5,54 раза по сравнению с StarRocks. Подробнее см. по ссылке https://www.starrocks.io/blog/benchmark-test
Вывод
Trino/Presto — это очень известный движок запросов с открытым исходным кодом. Когда у предприятий есть несколько источников данных и необходимо анализировать данные из этих источников единым образом, Trino является подходящим выбором. По сравнению с Trino, StarRocks — это новый движок запросов с открытым исходным кодом, обладающий множеством инновационных и уникальных решений. Используя StarRocks в качестве движка запросов для озер данных, клиенты могут легко достичь высокопроизводительного опыта запросов. Более того, клиенты могут использовать различные методы для дополнительного ускорения запросов, достигая более низкой задержки и более высокой конкурентоспособности. StarRocks также отличный выбор для запросов к озерам данных.
Перевод сделал ChatGPT