
The DuckLake Manifesto: SQL как формат Lakehouse
The DuckLake Manifesto:
SQL как формат Lakehouse
Авторы: Марк Раасвельдт и Ханнес Мюляйзен
Оригинал: https://ducklake.select/manifesto/
DuckLake упрощает Lakehouse, используя стандартную базу данных SQL для всех метаданных вместо сложных файловых систем, при этом храня данные в открытых форматах, таких как Parquet. Это делает его более надежным, быстрым и простым в управлении.
Хотите послушать содержание этого манифеста? Мы также выпустили эпизод подкаста на ютубе, объясняющий, как мы пришли к формату DuckLake.
Или тут можно посмотреть:
Предыстория
Инновационные системы данных, такие как BigQuery и Snowflake, показали, что разделение хранилища и вычислений — отличная идея в то время, когда хранилище является виртуализированным товаром. Таким образом, и хранилище, и вычисления могут масштабироваться независимо, и нам не нужно покупать дорогие машины баз данных только для хранения таблиц, которые мы никогда не будем читать.
В то же время рыночные силы вынудили людей настаивать на том, чтобы системы данных использовали открытые форматы, такие как Parquet, чтобы избежать слишком распространенного “захвата” данных одним поставщиком. В этом новом мире множество систем данных с удовольствием резвились вокруг нетронутого «озера данных», построенного на Parquet и S3, и все было хорошо. Кому нужны эти старомодные базы данных!
Но быстро выяснилось, что – шокирующе – люди хотели вносить изменения в свои наборы данных. Простые добавления работали довольно хорошо, просто помещая больше файлов в папку, но что-либо, кроме этого, требовало сложных и подверженных ошибкам пользовательских сценариев без какого-либо понятия правильности или – упаси господь, Кодд – транзакционных гарантий.
Настоящее озеро данных/Lakehouse

Iceberg и Delta
Для решения основной задачи изменения данных в озере появились различные новые открытые стандарты, наиболее заметные из которых — Apache Iceberg и Linux Foundation Delta Lake. Оба формата были разработаны для того, чтобы, по сути, вернуть некоторую разумность в изменении таблиц, не отказываясь от основной предпосылки: использовать открытые форматы в блочном хранилище. Например, Iceberg использует лабиринт файлов JSON и Avro для определения схем, снимков и того, какие файлы Parquet являются частью таблицы в определенный момент времени. Результат был назван «Lakehouse», по сути, дополнением функций базы данных к озерам данных, что позволило реализовать множество новых увлекательных вариантов использования для управления данными, например, обмен данными между движками.
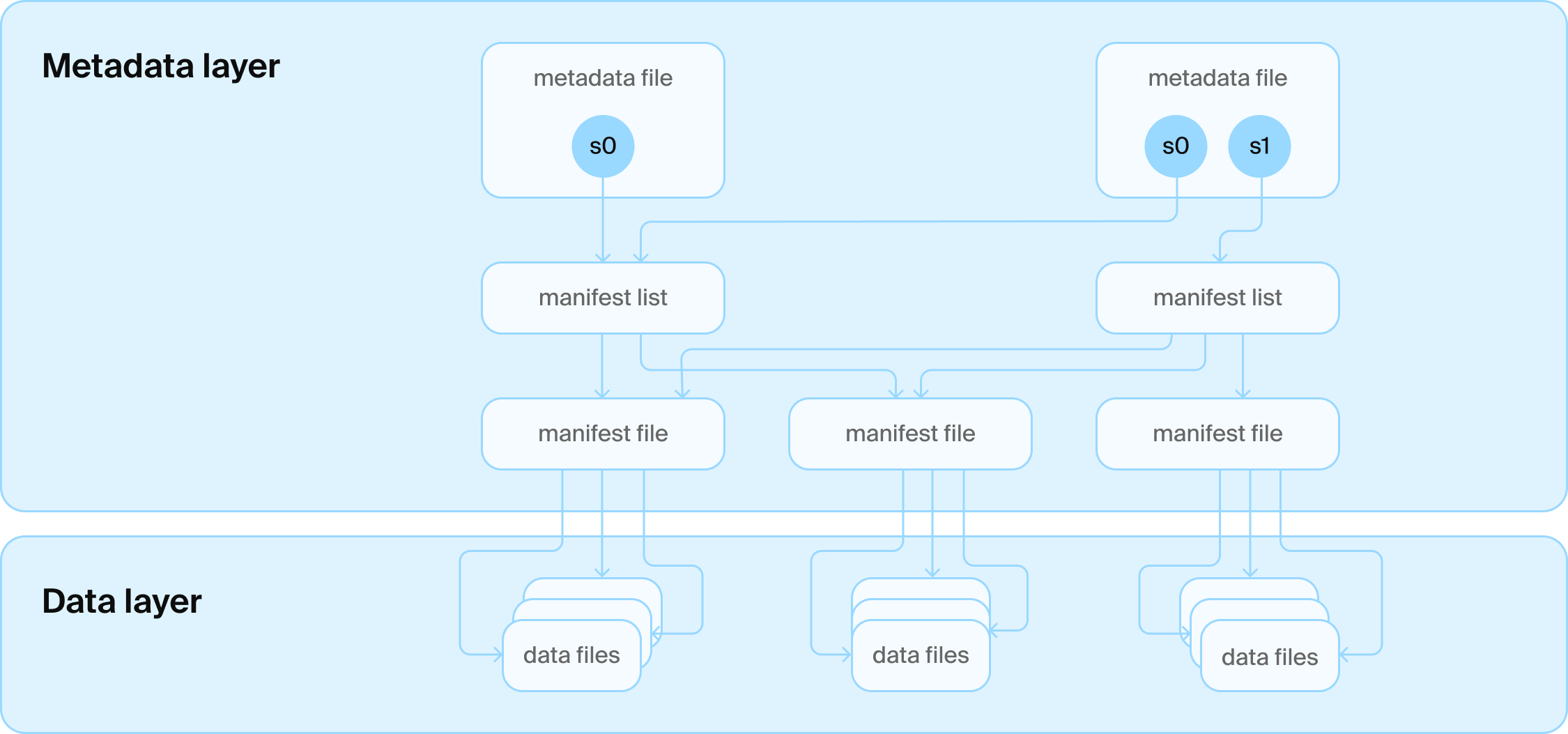
Но оба формата столкнулись с проблемой: поиск последней версии таблицы затруднен в блочных хранилищах с их изменчивыми гарантиями согласованности. Трудно атомарно (буква «А» в ACID) поменять указатель, чтобы убедиться, что все видят последнюю версию. Iceberg и Delta Lake также знают только об одной таблице, но люди – опять же, шокирующе – хотели управлять несколькими таблицами.
Каталоги
Решением стал еще один слой технологий: мы добавили службу каталогов поверх различных файлов. Эта служба каталогов, в свою очередь, взаимодействует с базой данных, которая управляет всеми именами папок таблиц. Она также управляет самой печальной таблицей всех времен, которая содержит только одну строку для каждой таблицы с текущим номером версии. Теперь мы можем использовать транзакционные гарантии базы данных для обновления этого номера, и все счастливы.
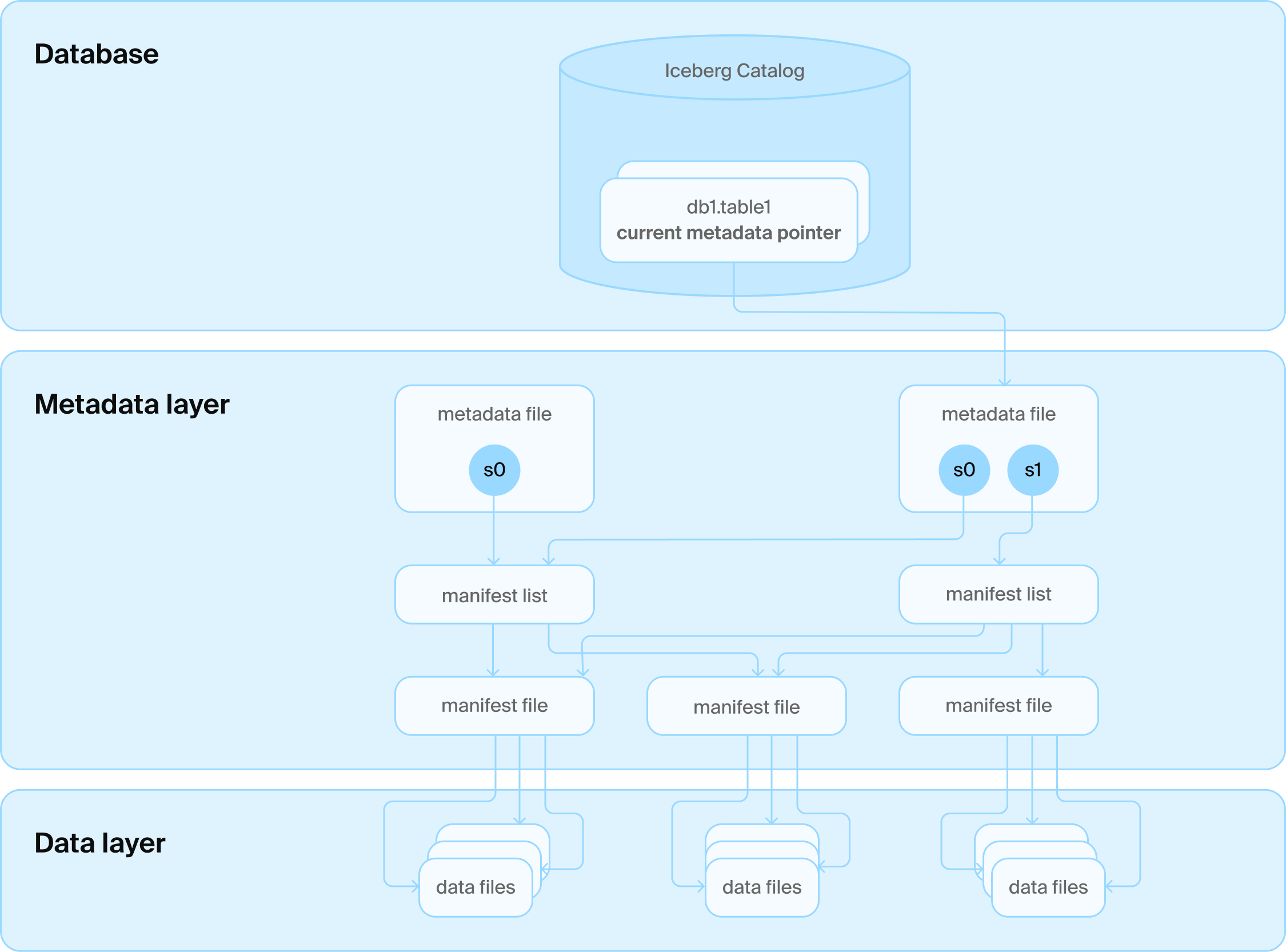
Вы говорите, база данных?
Но вот в чем проблема: Iceberg и Delta Lake были специально разработаны так, чтобы не требовать базу данных. Их дизайнеры приложили большие усилия, чтобы закодировать всю информацию, необходимую для эффективного чтения и обновления таблиц, в файлы в блочном хранилище. Они идут на многие компромиссы, чтобы достичь этого. Например, каждый корневой файл в Iceberg содержит все существующие снимки со схемой и т. д. Для каждого изменения записывается новый файл, который содержит полную историю. Многие другие метаданные должны были быть объединены, например, в двухуровневых файлах манифеста, чтобы избежать записи или чтения слишком большого количества мелких файлов, что не было бы эффективным в блочных хранилищах. Внесение небольших изменений в данные также является в значительной степени нерешенной проблемой, которая требует сложных процедур очистки, которые до сих пор не очень хорошо изучены и не поддерживаются реализациями с открытым исходным кодом. Существуют целые компании, и до сих пор создаются новые, чтобы решить эту проблему управления быстро меняющимися данными. Почти так, как если бы специализированная система управления данными была бы хорошей идеей.
Но, как указано выше, дизайны Iceberg и Delta Lake уже были вынуждены пойти на компромисс и добавить базу данных в качестве части каталога для обеспечения согласованности. Однако они никогда не пересматривали остальные свои проектные ограничения и стек технологий, чтобы приспособиться к этому фундаментальному изменению дизайна.
DuckLake
Здесь, в DuckDB, мы на самом деле любим базы данных. Это удивительные инструменты для безопасного и эффективного управления довольно большими наборами данных. Раз уж база данных все равно вошла в стек Lakehouse, имеет безумный смысл использовать ее и для управления остальными метаданными таблицы! Мы все еще можем использовать «бесконечную» емкость и «безграничную» масштабируемость блочных хранилищ для хранения фактических данных таблицы в открытых форматах, таких как Parquet, но мы можем гораздо более эффективно и действенно управлять метаданными, необходимыми для поддержки изменений в базе данных! По совпадению, это также то, что выбрали Google BigQuery (со Spanner) и Snowflake (с FoundationDB), только без открытых форматов в нижней части.
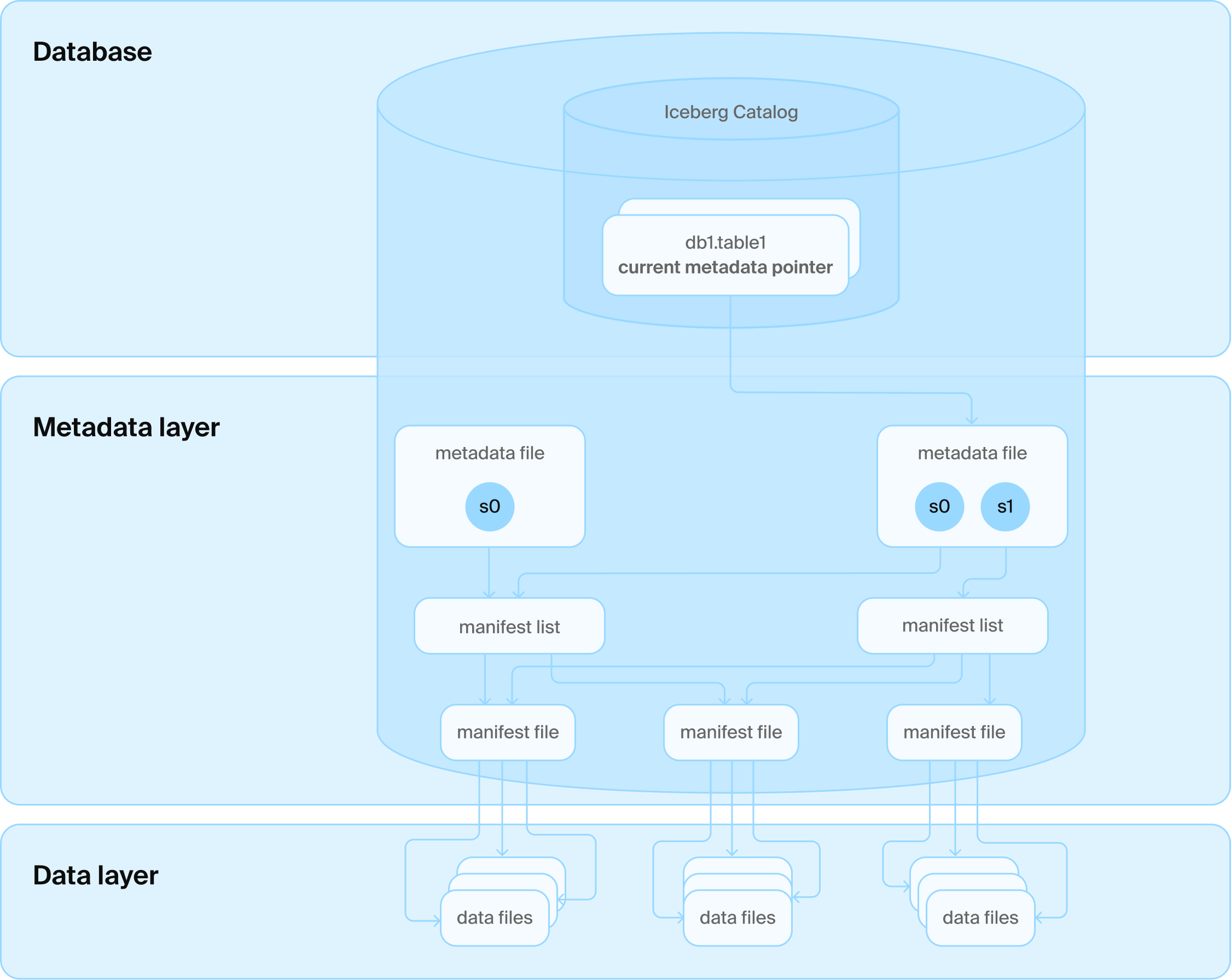
Для решения фундаментальных проблем существующей архитектуры Lakehouse мы создали новый открытый табличный формат под названием DuckLake. DuckLake переосмысливает то, как должен выглядеть формат «Lakehouse», признавая две простые истины:
Хранение файлов данных в открытых форматах в блочном хранилище — отличная идея для масштабируемости и предотвращения привязки к поставщику.
Управление метаданными — это сложная и взаимосвязанная задача управления данными, которую лучше оставить системе управления базами данных.
Основная идея DuckLake заключается в перемещении всех структур метаданных в базу данных SQL, как для каталога, так и для табличных данных. Формат определяется как набор реляционных таблиц и «чистые» транзакции SQL над ними, описывающие операции с данными, такие как создание, изменение схемы, а также добавление, удаление и обновление данных. Формат DuckLake может управлять произвольным количеством таблиц с межтабличными транзакциями. Он также поддерживает «расширенные» концепции баз данных, такие как представления, вложенные типы, транзакционные изменения схемы и т. д.; см. ниже список. Одним из основных преимуществ такого дизайна является использование ссылочной целостности (буква «C» в ACID), схема гарантирует, например, отсутствие дублирующихся идентификаторов снимков.
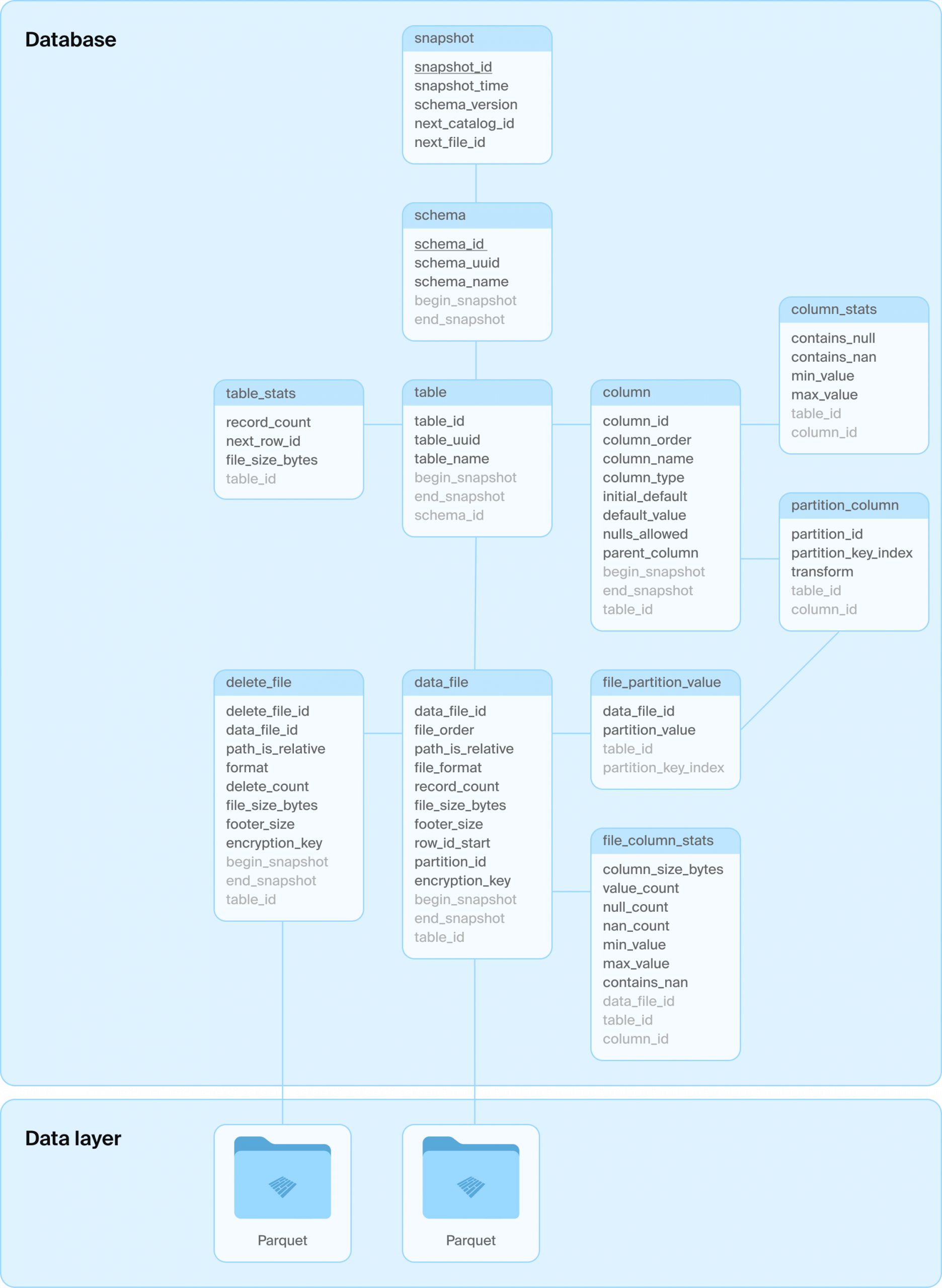
Какую именно базу данных SQL использовать, решает пользователь, единственные требования — система должна поддерживать операции ACID и первичные ключи, а также стандартный SQL. Внутренняя схема таблицы DuckLake намеренно сделана простой, чтобы максимизировать совместимость с различными базами данных SQL. Вот основная схема на примере.
Давайте рассмотрим последовательность запросов, которые происходят в DuckLake при выполнении следующего запроса на новой, пустой таблице:
INSERT INTO demo VALUES (42), (43);
BEGIN TRANSACTION;
-- некоторые чтения метаданных здесь пропущены
INSERT INTO ducklake_data_file VALUES (0, 1, 2, NULL, NULL, 'data_files/ducklake-8196...13a.parquet', 'parquet', 2, 279, 164, 0, NULL, NULL);
INSERT INTO ducklake_table_stats VALUES (1, 2, 2, 279);
INSERT INTO ducklake_table_column_stats VALUES (1, 1, false, NULL, '42', '43');
INSERT INTO ducklake_file_column_statistics VALUES (0, 1, 1, NULL, 2, 0, 56, '42', '43', NULL);
INSERT INTO ducklake_snapshot VALUES (2, now(), 1, 2, 1);
INSERT INTO ducklake_snapshot_changes VALUES (2, 'inserted_into_table:1');
COMMIT;Мы видим единую целостную транзакцию SQL, которая:
Вставляет новый путь к файлу Parquet
Обновляет глобальную статистику таблицы (теперь имеет больше строк)
Обновляет глобальную статистику столбцов (теперь имеет другое минимальное и максимальное значение)
Обновляет статистику столбцов файла (также записывает помимо прочего минимум/максимум)
Создает новый снимок схемы (#2)
Регистрирует изменения, произошедшие в снимке
Обратите внимание, что фактическая запись в Parquet не является частью этой последовательности, она происходит заранее. Но независимо от того, сколько значений добавлено, эта последовательность имеет ту же (низкую) стоимость.
Давайте обсудим три принципа DuckLake: простоту, масштабируемость и скорость.
Простота
DuckLake следует принципам проектирования DuckDB, заключающимся в сохранении простоты и постепенности. Для запуска DuckLake на ноутбуке достаточно просто установить DuckDB с расширением ducklake. Это отлично подходит для целей тестирования, разработки и прототипирования. В этом случае хранилищем каталога является просто локальный файл DuckDB.
Следующим шагом является использование внешних систем хранения. Файлы данных DuckLake неизменяемы, он никогда не требует модификации файлов на месте или повторного использования имен файлов. Это позволяет использовать его практически с любой системой хранения. DuckLake поддерживает интеграцию с любой системой хранения, такой как локальный диск, локальный NAS, S3, Azure Blob Store, GCS и т. д. Префикс хранения для файлов данных (например, s3://mybucket/mylake/) указывается при создании таблиц метаданных.
Наконец, база данных SQL, размещающая сервер каталога, может быть любой более-менее компетентной базой данных SQL, которая поддерживает ACID и ограничения первичного ключа. Большинство организаций уже имеют большой опыт эксплуатации такой системы. Это значительно упрощает развертывание, поскольку помимо базы данных SQL не требуется никакого дополнительного программного обеспечения. Кроме того, базы данных SQL в последние годы стали широко доступны, существует бесчисленное множество размещенных служб PostgreSQL или даже размещенных DuckDB, которые могут использоваться в качестве хранилища каталога! Опять же, привязка к поставщику здесь очень ограничена, потому что переход не требует перемещения данных таблицы, а схема проста и стандартизирована.
Нет файлов Avro или JSON. Нет дополнительного сервера каталогов или дополнительного API для интеграции. Все это просто SQL. Мы все знаем SQL.
Масштабируемость
DuckLake фактически увеличивает разделение проблем в архитектуре данных на три части: хранение, вычисления и управление метаданными. Хранение остается на специализированном файловом хранилище (например, блочное хранилище), DuckLake может масштабироваться бесконечно в хранении.
Произвольное количество вычислительных узлов запрашивают и обновляют базу данных каталога, а затем независимо читают и записывают из хранилища. DuckLake может масштабироваться бесконечно в отношении вычислений.
Наконец, база данных каталога должна быть способна выполнять только те транзакции метаданных, которые запрашиваются вычислительными узлами. Их объем на несколько порядков меньше, чем фактические изменения данных. Но DuckLake не привязан к одной базе данных каталога, что позволяет мигрировать, например, из PostgreSQL на что-то другое по мере роста спроса. В конечном итоге, DuckLake использует простые таблицы и базовый, переносимый SQL. Но не беспокойтесь, DuckLake, поддерживаемый PostgreSQL, уже сможет масштабироваться до сотен терабайт и тысяч вычислительных узлов.
Опять же, это именно тот дизайн, который используют BigQuery и Snowflake, которые уже успешно управляют огромными наборами данных. И, ничего не мешает вам использовать Spanner в качестве базы данных каталога DuckLake, если это необходимо.
Скорость
Как и сам DuckDB, DuckLake очень ориентирован на скорость. Одной из самых больших проблем Iceberg и Delta Lake является сложная последовательность операций ввода-вывода файлов, необходимая для выполнения самого маленького запроса. Следование по пути каталога и метаданных файлов требует многих отдельных последовательных HTTP-запросов. В результате существует нижний предел того, насколько быстро могут выполняться чтения или транзакции. Много времени тратится на критический путь фиксации транзакций, что приводит к частым конфликтам и дорогостоящему разрешению конфликтов. Хотя кэширование может использоваться для решения некоторых из этих проблем, это добавляет дополнительную сложность и эффективно только для «горячих» данных.
Единые метаданные в базе данных SQL также позволяют планировать запросы с низкой задержкой. Чтобы прочитать данные из таблицы DuckLake, один запрос отправляется в базу данных каталога, которая выполняет сокращение на основе схемы, разделов и статистики, чтобы, по сути, получить список файлов для чтения из блочного хранилища. Нет множественных обращений к хранилищу для извлечения и восстановления состояния метаданных. Также меньше вероятность возникновения ошибок, нет регулирования S3, нет неудачных запросов, нет повторных попыток, нет еще не согласованных представлений хранилища, которые приводят к невидимости файлов и т. д.
DuckLake также способен улучшить две самые большие проблемы производительности озер данных: небольшие изменения и множество одновременных изменений.
Для небольших изменений DuckLake значительно сократит количество мелких файлов, записываемых в хранилище. Нет нового файла снимка с крошечным изменением по сравнению с предыдущим, нет нового файла манифеста или списка манифестов. DuckLake даже опционально позволяет прозрачно встраивать небольшие изменения в таблицы непосредственно в метаданные! Оказывается, систему баз данных можно использовать и для управления данными. Это позволяет выполнять запись за доли миллисекунды и улучшать общую производительность запросов за счет уменьшения количества файлов, которые необходимо считывать. Записывая гораздо меньше файлов, DuckLake также значительно упрощает операции очистки и сжатия.
В DuckLake изменения таблицы состоят из двух шагов: подготовки файлов данных (если таковые имеются) к хранению, а затем выполнения одной транзакции SQL в базе данных каталога. Это значительно сокращает время, затрачиваемое на критический путь фиксации транзакций, поскольку нужно выполнить только одну транзакцию. Базы данных SQL довольно хорошо справляются с разрешением конфликтов транзакций. Это означает, что вычислительные узлы тратят гораздо меньше времени на критический путь, где могут возникать конфликты. Это позволяет значительно быстрее разрешать конфликты и выполнять гораздо больше параллельных транзакций. По сути, DuckLake поддерживает столько изменений таблицы, сколько может зафиксировать база данных каталога. Даже почтенный Postgres может выполнять тысячи транзакций в секунду. Можно было бы запустить тысячу вычислительных узлов, выполняющих добавление в таблицу с интервалом в одну секунду, и это работало бы нормально.
Кроме того, снимки DuckLake — это всего лишь несколько строк, добавленных в хранилище метаданных, что позволяет существовать множеству снимков одновременно. Нет необходимости заблаговременно удалять снимки. Снимки также могут ссылаться на части файла Parquet, что позволяет существовать гораздо большему количеству снимков, чем файлов на диске. В совокупности это позволяет DuckLake управлять миллионами снимков!
Возможности
DuckLake обладает всеми вашими любимыми функциями Lakehouse:
Произвольный SQL: DuckLake поддерживает все те же обширные возможности SQL, что и, например, DuckDB.
Изменения данных: DuckLake поддерживает эффективное добавление, обновление и удаление данных.
Множественная схема, множественные таблицы: DuckLake может управлять произвольным количеством схем, каждая из которых содержит произвольное количество таблиц в одной и той же структуре метаданных.
Межтабличные транзакции: DuckLake поддерживает транзакции, полностью соответствующие ACID, для всех управляемых схем, таблиц и их содержимого.
Сложные типы: DuckLake поддерживает все ваши любимые сложные типы, такие как списки, произвольно вложенные.
Полная эволюция схемы: Схемы таблиц могут изменяться произвольно, например, столбцы могут быть добавлены, удалены или их типы данных изменены.
Отмотка времени и откат на уровне схемы: DuckLake поддерживает полную изоляцию снимков и отмотку времени, позволяя запрашивать таблицы на определенный момент времени.
Инкрементальное сканирование: DuckLake поддерживает получение только тех изменений, которые произошли между указанными снимками.
Представления SQL: DuckLake поддерживает определение лениво оцениваемых представлений SQL.
Скрытое разбиение на разделы и отсечение: DuckLake учитывает разбиение данных на разделы, а также статистику на уровне таблиц и файлов, что позволяет заранее отсекать сканирование для максимальной эффективности.
Транзакционные DDL: Создание, эволюция и удаление схем, таблиц и представлений полностью транзакционны.
Избегание уплотнения данных: DuckLake требует гораздо меньше операций уплотнения, чем сопоставимые форматы. DuckLake поддерживает эффективное уплотнение снимков.
Встраивание: При внесении небольших изменений в данные DuckLake может опционально использовать базу данных каталога для прямого хранения этих небольших изменений, чтобы избежать записи множества мелких файлов.
Шифрование: DuckLake может опционально шифровать все файлы данных, записываемые в хранилище, что позволяет размещать данные с нулевым доверием. Ключи управляются базой данных каталога.
Совместимость: Файлы данных и (позиционные) файлы удаления, которые DuckLake записывает в хранилище, полностью совместимы с Apache Iceberg, что позволяет выполнять миграцию только метаданных.
Заключение
Мы выпустили DuckLake v0.1 с расширением DuckDB ducklake в качестве первой реализации. Мы надеемся, что вы найдете DuckLake полезным в своей архитектуре данных – с нетерпением ждем ваших творческих вариантов использования!
Немного про эффективность от себя
