
Транскрибация аудио python на faster-whisper

Все достаточно легко
Подготовка
python3 -m venv ./whisperАктивация и установка этого https://github.com/SYSTRAN/faster-whisper
source ./whisper/bin/activate
pip install faster-whisperСам код
import sys
import os
import time
from faster_whisper import WhisperModel
# --- Конфигурация модели Whisper ---
model_size = "large-v3"
# Выберите свою конфигурацию:
# model = WhisperModel(model_size, device="cuda", compute_type="float16") # Если есть GPU и CUDA
# model = WhisperModel(model_size, device="cuda", compute_type="int8_float16") # Если есть GPU и CUDA с INT8
model = WhisperModel(model_size, device="cpu", compute_type="int8") # Для CPU (как в вашем примере)
# -----------------------------------
def transcribe_mp3_to_text(mp3_filepath):
"""
Транскрибирует MP3 файл и сохраняет результат в текстовый файл.
"""
if not os.path.exists(mp3_filepath):
print(f"Ошибка: Файл MP3 не найден: {mp3_filepath}")
return False
if not mp3_filepath.lower().endswith(".mp3"):
print(f"Ошибка: Файл '{mp3_filepath}' не является MP3 файлом. Пропускаем.")
return False
# Извлечение имени файла без расширения
filename_without_ext = os.path.splitext(os.path.basename(mp3_filepath))[0]
output_txt_filepath = os.path.join(os.path.dirname(mp3_filepath), f"{filename_without_ext}.txt")
print(f"[{time.strftime('%Y-%m-%d %H:%M:%S')}] Начинаем транскрипцию '{mp3_filepath}'...")
print(f"Результат будет сохранен в '{output_txt_filepath}'")
try:
segments, info = model.transcribe(mp3_filepath, beam_size=5)
detected_language_msg = f"Detected language: '{info.language}' with probability {info.language_probability:.2f}"
print(detected_language_msg)
# Сохранение транскрипции в текстовый файл
with open(output_txt_filepath, 'w', encoding='utf-8') as f_out:
f_out.write(f"--- Транскрипция для: {os.path.basename(mp3_filepath)} ---\n")
f_out.write(f"{detected_language_msg}\n\n")
full_text = [] # Для сбора всего текста, если нужно вывести в конце
for segment in segments:
segment_line = f"[{segment.start:.2f}s -> {segment.end:.2f}s] {segment.text}"
print(segment_line) # Выводим в консоль для отладки
f_out.write(f"{segment.text}\n") # Записываем только текст в файл, по сегментам
full_text.append(segment.text)
# Если вы хотите сохранить всю транскрипцию одним блоком в конце файла или отдельный файл
# f_out.write("\n\n--- Полный текст ---\n")
# f_out.write(" ".join(full_text))
print(f"[{time.strftime('%Y-%m-%d %H:%M:%S')}] Транскрипция успешно завершена! Результат в '{output_txt_filepath}'")
return True
except Exception as e:
print(f"Ошибка при транскрипции файла '{mp3_filepath}': {e}")
# Вы можете добавить логирование ошибки в отдельный файл, если нужно
return False
if __name__ == "__main__":
if len(sys.argv) < 2:
print("Использование: python process_mp3.py <путь/к/вашему/файлу.mp3>")
sys.exit(1)
mp3_file_path_arg = sys.argv[1] # Это будет полный путь к MP3 файлу, переданный из Automator/Bash
transcribe_mp3_to_text(mp3_file_path_arg)Итоги запуска
(whisper) (base) yuriygavrilov@MacBookPro fastwhisper % python whisp.py
Detected language 'ru' with probability 0.998883
[0.00s -> 4.96s] Раз, два, три, привет, как дела?
[5.94s -> 8.54s] Все хорошо, а у тебя как?
[9.54s -> 10.78s] И у меня все хорошо
[10.78s -> 12.98s] Спасибо, пока
(whisper) (base) yuriygavrilov@MacBookPro fastwhisper %тестовый файл тут
ограничений по времени нет, кормите его любыми файлами любой длины. Если нужно можно упростить запуск как хотите. На мак можно даже поставить действие на папку и при появлении там файлов типа mp3 они будут автоматически транскрибироваться.
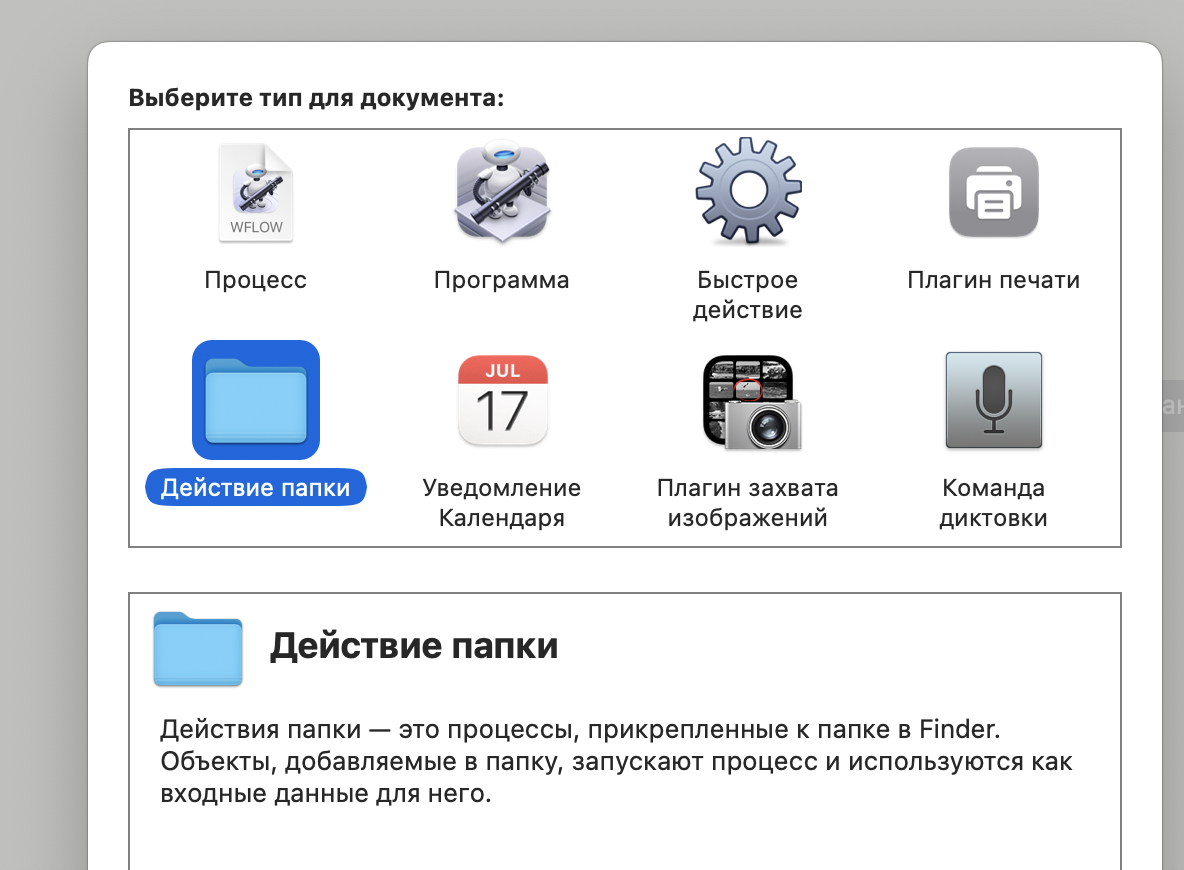
Буду делать через приложении на маке automator

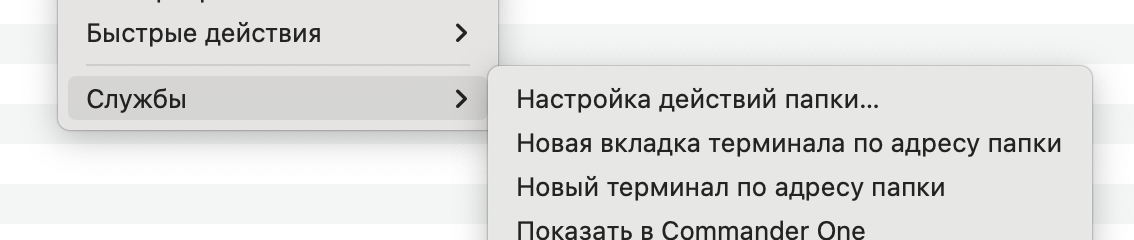
Как то примерно так :)
осталось прикрутить это а действие к папке
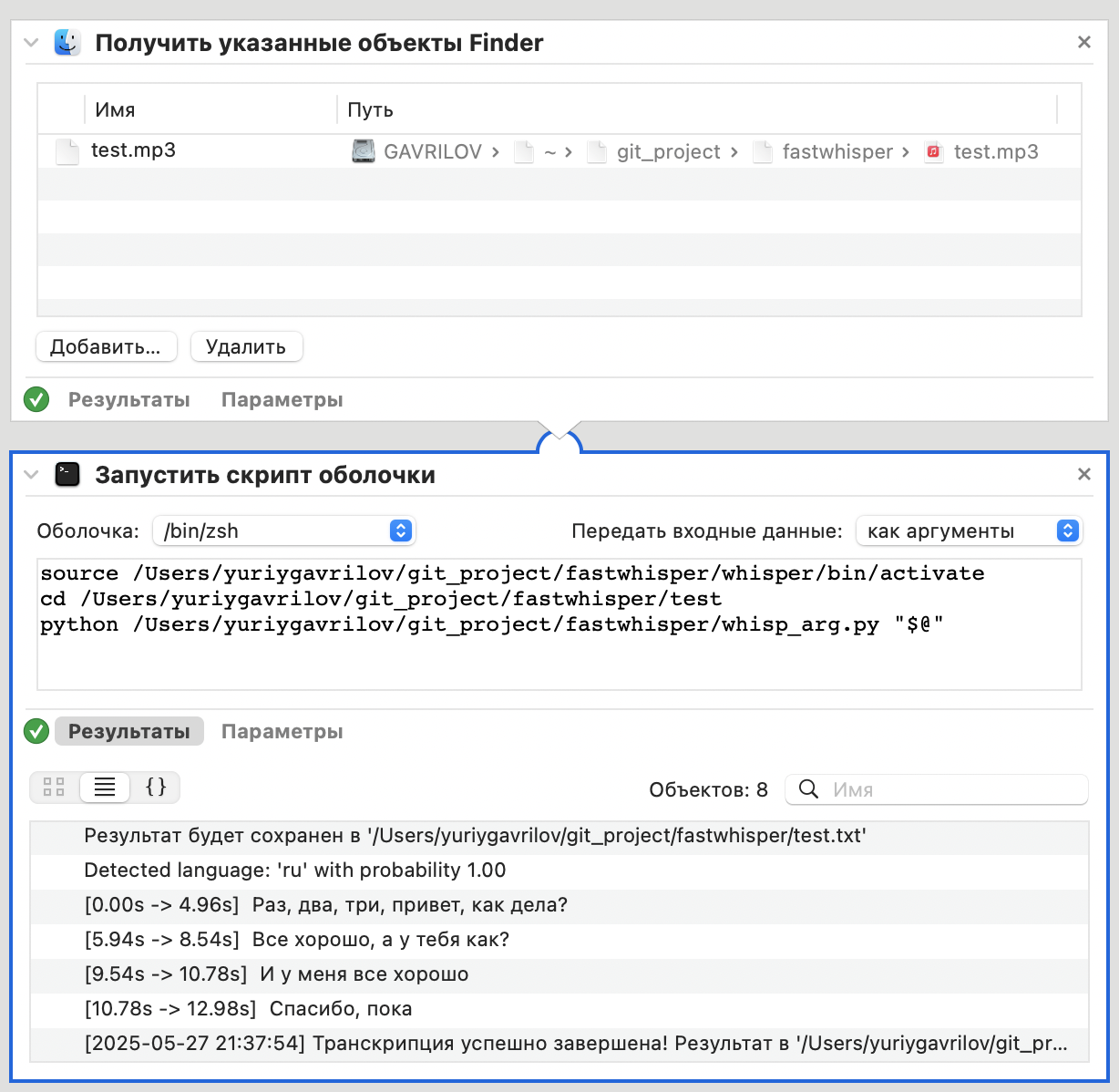
кажись заработало :)

Создалась транскрипция сама

получилось в итоге вот так: Открываем Automator, настраиваем действие и все.

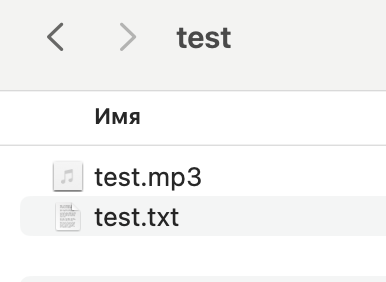
работает так: кидаем файл в папку тест, скрипт запускается, транскрипция появляется рядом. Все.
Проверим качество модели на этом:

почти идеал 🤘
Второй раз чуть иначе, но почти точно.
