
Возникновение (Монолитных) Систем Обработки Данных
https://medium.com/@jordan_volz/is-it-time-for-composable-data-systems-aaa72e0aa9bd
В 1970 году Эдгар Ф. Кодд опубликовал работу “Реляционная модель данных для крупных общих банков данных” во время работы исследователем в IBM. Эта влиятельная статья стала началом бурного развития систем обработки данных в течение десятилетий, что продолжается и по сей день. Среди тех, кто был вдохновлен этой статьей, были Майкл Стоунбрейкер и Ларри Эллисон, которые немедленно начали реализовывать реляционную модель в системах обработки данных, которые позже стали известными как Oracle и Ingres (позже Postgres — т.е. после Ingres). Фактически любая современная система обработки данных обязана значительной благодарностью работе Кодда.
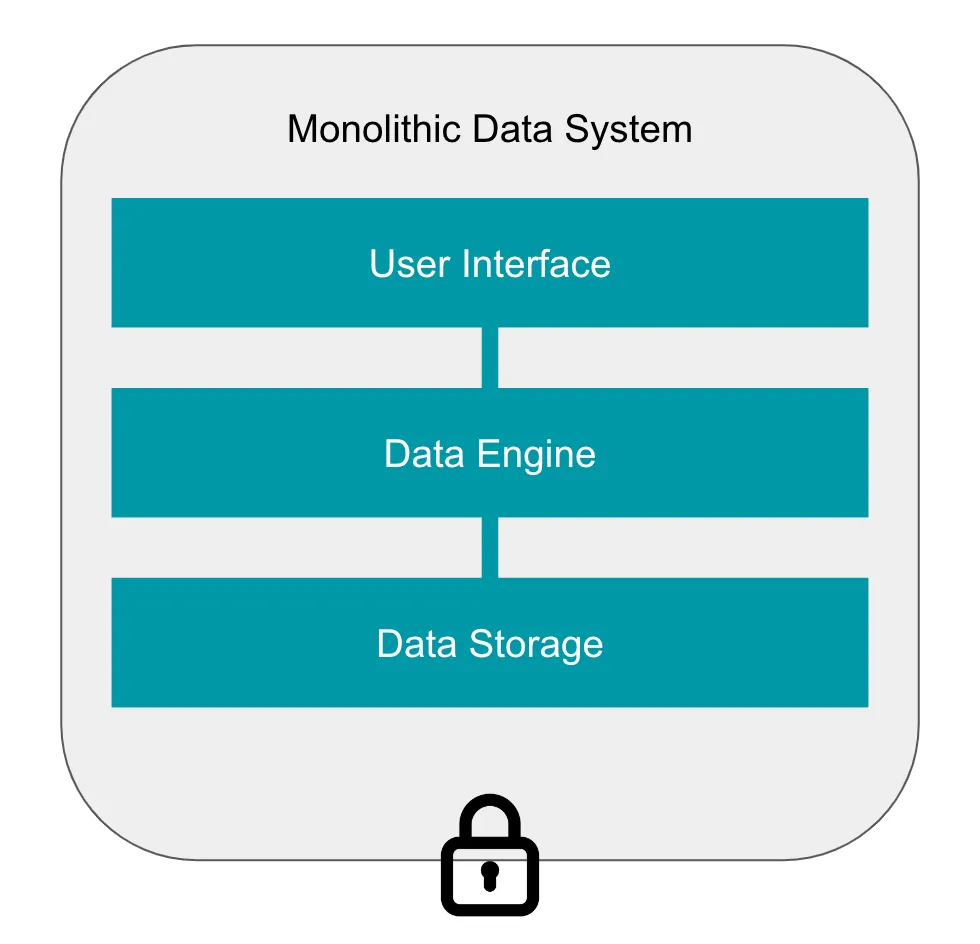
Одной из характерных черт этих ранних систем было то, что они были монолитами: эти системы были очень тесно интегрированы от верха до низа, обрабатывая все — от пользовательского интерфейса (например, SQL), где пользователи указывают операции для выполнения, до вычисления этих операций и хранения данных. Когда мы рассматриваем контекст, в котором эти системы были созданы, логично, что они были разработаны как монолиты; те, кто создавал системы обработки данных в 1970-х годах, фактически строили их с нуля, поскольку не существовало общего набора инструментов для их создания. Естественно, эти разработчики создавали все сами, что означало, что каждая система хорошо работала внутри себя, но практически не существовало совместимости между системами (даже появление SQL в качестве основного интерфейса для реляционных баз данных заняло некоторое время — что сегодня мы принимаем как должное).

Переместимся на три десятилетия после статьи Кодда, и произошли существенные изменения в технологии и обществе. Мы онлайн, web 2.0 в полном разгаре, и данные повсюду. Системы стали крупнее, быстрее и мощнее. Системы управления реляционными базами данных (RDBMS) прошлого уступили место базам данных MPP, затем “большим данным” и распределенным системам. SQL как лингва франка данных уступил место Python и R. Монолитные системы обработки данных также уступили место... еще более монолитным системам обработки данных. Некоторое время мы пытались убедить себя, что “озера данных” — это нечто другое, но роза под другим именем...
Прошло уже пять десятилетий со времени статьи Кодда, но дизайн систем обработки данных сегодня существенно не изменился. Большинство систем обработки данных по-прежнему действуют как монолиты, где разработчики систем по сути многократно воссоздают общие внутренние компоненты. Кроме того, многие системы обработки данных работают по довольно узнаваемым шаблонам — возможно, из-за обратной разработки конкурентов, набора разработчиков из установленных продуктов или создания новой компании/продукта для создания более современной системы с меньшим техническим долгом. Однако то, что не сильно улучшилось, — это взаимодействие между системами, но это не должно вызывать удивление, поскольку почти никогда не в интересах поставщика оперировать таким образом.
За последние два десятилетия выделились два основных тренда в технологии, которые существенно повлияли на мир данных:
Многие рабочие нагрузки перешли из локальной среды в облачную.
Инструменты с открытым исходным кодом обширно распространены в мире данных и широко используются.
Интересным является то, что до сих пор не произошло переосмысления базовой структуры систем обработки данных. Это, возможно, более удивительно, если учесть, что рост облаков и открытого исходного кода фактически привел к взрыву количества новых систем обработки данных. Многие из них являются очень специализированными системами, предназначенными для конкретного случая использования, но что большинство из них имеют общее — они, в своей основе, тоже монолитные системы. Результатом является увеличение фрагментации области данных, что увеличивает операционную сложность для компаний, пытающихся использовать свои данные.
Возникает вопрос: есть ли лучший способ построения системы обработки данных? Если бы мы могли создать идеальную систему, учитывая десятилетия технического долга, с которым большинство предприятий живет сегодня, как бы она выглядела? Я убежден, что правильная архитектура для многих компаний сегодня — это композиционная система обработки данных, и об этом мы расскажем в этой статье, но давайте сначала рассмотрим, почему монолитные системы не являются идеальными.
Проблемы с монолитными системами обработки данных
Монолитные системы не являются по своей сути плохими. Позвольте мне честно сказать это. И, конечно же, они лучше, чем отсутствие системы вообще. Создание системы обработки данных не просто и не прямолинейно, поэтому тот, кто сумел это сделать, заслуживает много похвал. Мое основное возражение к монолитным системам — и их более спорному кузену, “силосу данных” — заключается в том, что фундаментальное предположение, на котором все они строятся, просто не верно для современного предприятия: “Все ваши данные находятся в этой системе”.
Пятьдесят лет назад это действительно было верным утверждением. Почти каждая компания только начинала работу с данными, поэтому каждая система данных была более или менее первой системой данных для этой компании, что означало, что это также была система, в которой “все данные”. Сегодня это не соответствует положению дел большинства компаний в их стратегии данных. Обычно у компаний есть несколько уровней устаревших систем, которые устарели, но не выведены из строя. Это могут быть старые продукты, старые приобретения, новые приобретения, операции теневого IT, целый набор заброшенных проектов по искусственному интеллекту и так далее. Данные распределены по множеству различных систем, нет недостатка в языках, написанных для работы с данными (SQL, Python, R, Scala, Java, Julia и т. д.), и все меньше и меньше людей, понимающих, как работают эти старые системы. То, что я все чаще встречаю на практике в современных командах по обработке данных, даже когда ваша система данных работает невероятно хорошо, результаты, которые вы получаете, часто неудовлетворительны, потому что в ней отсутствуют все данные, которые вам нужны на повседневной основе.
Ожидания также были более умеренными в прошлом, чем они сейчас. Пятьдесят лет назад сделать что-либо с данными было победой. Сегодня все намного сложнее, поскольку компании пытаются использовать большие языковые модели (LLM), чтобы создавать приложения с генеративным искусственным интеллектом ко-пилота во всех своих продуктах. Увеличившаяся сложность просто мутит воду и продолжает углублять разрыв между данными и пониманием бизнеса.
Появляется поставщик, предлагающий крутую, современную систему обработки данных. Эта система, безусловно, будет быстрее любых ваших существующих систем, проще в использовании и дешевле! Звучит как удачный случай, не так ли? Ну, на самом деле, нет. Правда в том, что эта система, возможно, будет работать так, как заявлено, только если вы сможете:
а) Мигрировать свои данные в эту систему.
б) Переобучить свою команду обработки данных на использование новой системы.
в) Переписать ваши существующие рабочие нагрузки в новом интерфейсе.
Переоснащение всегда сопряжено с огромными издержками на переключение и представляет собой значительные вложения, как в терминах времени, так и денег. Даже если вы решите взять на себя трудности и выполнить миграцию данных в полностью новую систему обработки данных, вам придется снова столкнуться с таким же выбором не ранее, чем через 5–10 лет.
Грубо говоря, для бизнеса крайне сложно изменить свою стратегию данных. Даже стартапы, которые существуют всего несколько лет, накапливают огромное количество технического долга за короткое время. Успех стартапа лишь означает, что он быстро накапливает большие объемы данных, находясь в условиях нехватки персонала — настоящий рецепт катастрофы. Компании с большим стажем более удачливы, но они просто замедленно двигаются под тяжестью десятилетий технического долга. Бросать еще больше монолитных систем в огонь в 2023 году не может быть решением.

Переход в облако также ничего не исправил; теперь мы просто используем монолиты в облаке. В первые дни облако обещало оптимизированные и упрощенные рабочие процессы за счет разделения вычислений и хранения. Это хороший базовый принцип, но в конечном итоге это не прерывает цикл монолитных систем, потому что данные все еще заключены в технологию поставщика для большинства случаев использования. Например, я часто не могу разумно запросить свои данные в платформе X с заданием, выполняемым в платформе Y. Даже если это возможно, мне все равно придется заплатить много штрафов (не говоря уже о более высоких счетах) за попытки разрушить стены и придется смириться с неоптимальной производительностью. Системы не созданы с учетом этого пути в качестве основного, и пользователи платят цену, когда их решения начинают выходить за границы возможного.
И эти стены между системами обработки данных — именно проблема, не наименьшая из-за того, что они преднамеренные. Действующие облачные платформы не стимулируются к созданию лучших систем, поскольку доход в настоящее время в основном зависит от использования. Хотя на первый взгляд это звучит замечательно для тех, кто платит счета — вы платите только за то, что используете — непреднамеренным следствием является то, что улучшения базовой технологии будут снижать доход и, следовательно, не вероятны (если такие улучшения все-таки произойдут, они будут стоить дорого, независимо от затрат поставщика). Поставщики медленно внедряют новые технологии, потому что технический долг намеренно очень велик, и многие новые функции созданы для продолжения построения стен и усложнения для клиентов покидать их платформу. Чистый эффект для вас, потребителя, заключается в том, что вы упускаете возможность использовать последние и лучшие улучшения, которые могли бы повысить эффективность ваших рабочих процессов и, таким образом, ваш бизнес.
Для современной организации данных монолитные системы уже не подходят. Так в чем же альтернатива? Композиционные системы обработки данных, построенные на открытых стандартах обработки данных.
Обзор композиционных систем обработки данных
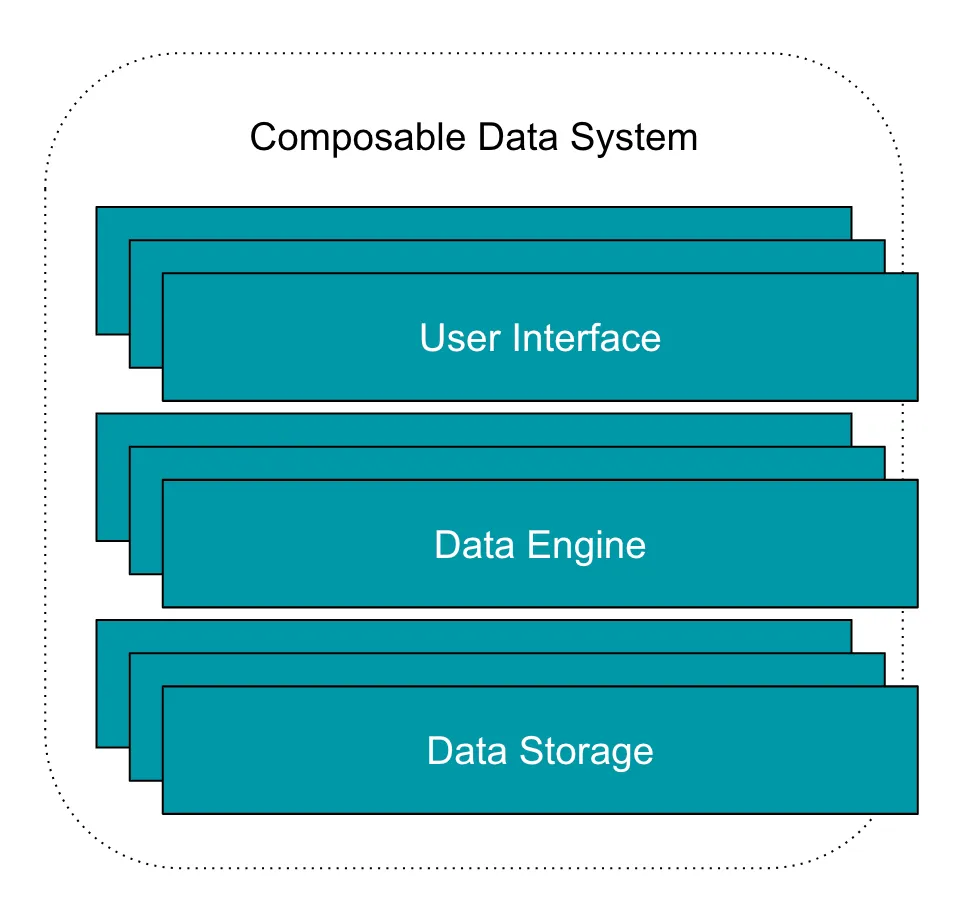
Систему обработки данных можно разбить на 3 основные части:
Хранилище данных: часть, которая хранит данные, доступные пользователям.
Движок данных: часть, которая выполняет операции с данными, как указано пользователями.
Пользовательский интерфейс: часть, с которой взаимодействуют пользователи для инициирования операций. Обычно предоставляется в виде языкового интерфейса или API.
В монолитных системах эти компоненты практически не разделены. Система была построена для использования определенным образом, и потребители системы должны смириться с выбором разработчиков. Используя систему, вы неявно фиксируете свой выбор для хранилища данных, движка данных и пользовательского интерфейса.
В отличие от этого, композиционная система обработки данных обеспечивает полное разделение между каждой частью этого стека, и потребители свободны выбирать технологии для каждого компонента. Это представляет собой совершенно новый способ проектирования и создания систем обработки данных и предоставляет потребителям безграничную гибкость. Существующие стены между системами обработки данных теперь могут быть разрушены.
Представьте себе инженера данных, который пишет рабочий процесс Apache Spark на Java, который считывает данные из внутренней базы данных Oracle и выгружает данные в хранилище S3. Затем ученый по данным создает систему рекомендаций с использованием этих данных на Python и сохраняет результаты в транзакционной базе данных для использования в приложении, предназначенном для конечного пользователя. Для многих компаний сегодня такой рабочий процесс легко мог бы включать три или более систем обработки данных, и интеграция была бы довольно сложной, но в композиционной системе обработки данных это было бы совершенно нормально.
Для правильного построения композиционной системы обработки данных каждый компонент системы должен быть разработан с учетом четырех основных принципов:
- Модульность: Каждый компонент в системе данных легко может быть заменен другим компонентом того же типа (например, слой хранения).
- Автономность: Компоненты должны быть разработаны так, чтобы не требовать использования других компонентов.
- Стандартизированные API: Компоненты должны использовать стандартный набор API для облегчения передвижения данных по системе.
- Расширяемость: Компоненты должны позволять пользователям легко расширять функциональность, не требуя переписывания всего компонента.
Для тех, кто знаком с разработкой программного обеспечения, все это, надеюсь, выглядит довольно нормально.
Если бы вы начали создавать композиционную систему обработки данных, вы, возможно, обнаружили бы проблему: на самом деле довольно сложно создать ее с нуля. Быстро возникают несколько проблем:
- При создании движка, как мы вообще можем обрабатывать любой тип пользовательского интерфейса, который пользователи могли бы хотеть использовать? Кажется, что любой новый интерфейс/язык потребует значительной работы по разработке.
- Точно так же, как мы можем обрабатывать любое произвольное хранилище данных?
- После того как мы разрушаем систему обработки данных, как мы затем снова соединяем эти разрывы, чтобы предоставить пользователям приятный опыт? Это сложные вопросы, и я считаю, что именно этот пропасть удерживала нас в области монолитных систем обработки данных в последние пятьдесят лет.
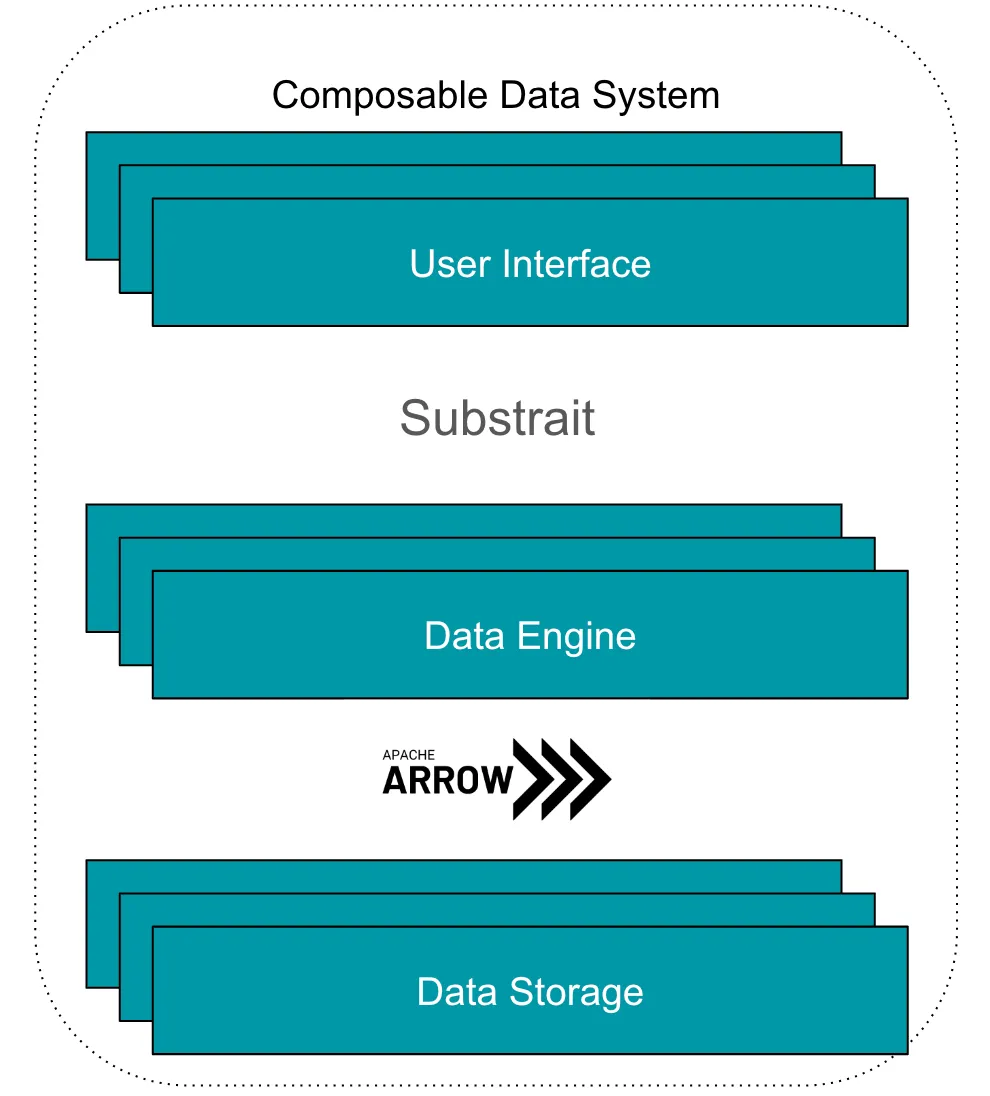
Однако композиционные системы обработки данных возможны сегодня благодаря появлению открытых стандартов в этой области, которые могут соединить эти разрывы. Два из них, в частности, предоставляют необходимый клей, который делает эту систему возможной: Apache Arrow и Substrait.
Apache Arrow начался как встроенное столбцовое представление данных, но проект существенно вырос за годы, и с добавлением компонентов, таких как Arrow Flight, Flight SQL и ADBC. Теперь доступно множество инструментов для помощи системам в эффективном общении, и, таким образом, передача данных в формате Arrow никогда не была такой простой. Таким образом, Arrow может очень эффективно действовать как связующее звено между слоем хранения и двигателем в композиционной системе обработки данных при условии:
- Слой хранения данных поддерживает создание и прием данных в формате Arrow.
- Двигатель данных может принимать и обрабатывать данные Arrow.
С этим на месте, двигатель в композиционной системе легко может читать данные из множества слоев хранения. Каждая сторона этого моста должна лишь оптимизировать свою часть, чтобы обеспечить отличный опыт пользователей при обмене.
Substrait — это кросс-языковая спецификация для операций обработки данных, или так называемое “промежуточное представление” (IR) для реляционной алгебры. Это означает, что вместо управления сетью соединений между интерфейсами и двигателями композиционная система обработки данных должна только указать:
- Интерфейсы в конечном итоге создают план Substrait.
- Двигатели могут функционировать, принимая план Substrait.
Это позволяет Substrait действовать как связующее звено между первыми двумя слоями в композиционной системе обработки данных. И, еще раз, каждая сторона моста может сосредотачиваться на оптимизации своей части для вписывания в композиционную архитектуру.
Собрав все вместе, мы приходим к нашему первому чертежу для композиционной системы обработки данных:
Теория хороша только в том случае, если ее лучше всего применять, поэтому естественно возникает вопрос “Работает ли это на практике?” Неудивительно, что многие высокотехнологичные компании уже строят композиционные системы обработки данных на основе Apache Arrow и Substrait. Например, в недавней презентации Two Sigma обсуждается использование Arrow и Substrait, вместе с Acero, для создания системы стриминговой фичификации. Meta также недавно открыла код Velox, унифицированного двигателя выполнения, который работает с Substrait и Arrow и, очевидно, может использоваться для начала создания основ композиционной системы. Кроме того, новая база данных DuckDB, пользующаяся популярностью, совпадающим образом поддерживает как Substrait, так и Arrow.
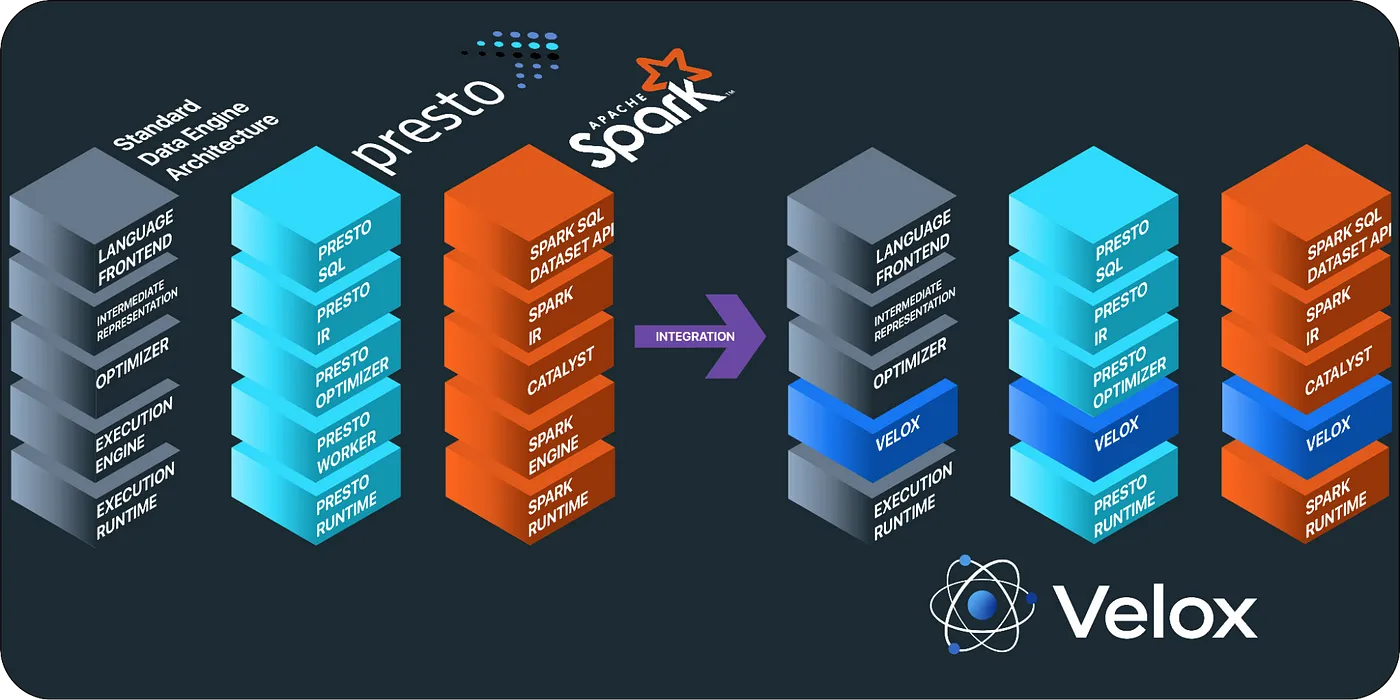
Velox использует открытые стандарты для построения композиционного двигателя обработки данных.
Композиционная система обработки данных варится уже довольно долгое время и теперь, похоже, пришло идеальное время для ее появления. Большинство компаний уже накопили достаточный технический долг, чтобы количество данных необходимых решений, которые могут легко работать с различными слоями хранения. Рост принятия облака подчеркивает разделение вычислений и хранения, что является естественной точкой входа для композиционных систем. Кроме того, появление открытых стандартов, таких как Apache Arrow и Substrait, означает, что создание и использование композиционных систем стало намного проще, чем это было бы всего пять лет назад. Это значительное изменение в архитектуре данных, которое принесет радикальные выгоды для потребителей.
Преимущества композиционных систем обработки данных:
- Гибкость:
- Композиционные системы предоставляют пользователям максимальную гибкость. Общие жалобы от конечных пользователей монолитных систем включают: a) Отсутствие поддержки предпочитаемого ими языка работы (например, SQL-системы, которые не имеют интеграции с API для dataframe, или системы на основе API для dataframe, не обладающие хорошей поддержкой SQL, R против Python и т.д.) и b) Реалистичные сценарии использования требуют данных, заточенных под более чем одну систему. В композиционных системах пользователи получат свободу работать на выбранном ими языке и легко подключаться к разным источникам данных. Это повышает производительность команд обработки данных, поскольку они могут придерживаться знакомого интерфейса для всех своих работ и не сталкиваются с барьерами между системами данных.
- Производительность:
- Не секрет, что многие системы данных затянуты техническим долгом, который сложно и дорого устранить. С течением времени системы данных теряют свою “современность” и, вероятно, будут превзойдены более новыми системами по производительности. Это явление мы видели много раз за последние пятьдесят лет, и нет причин считать, что оно прекратится в ближайшее время. Для компаний, которые заинтересованы в получении передовой производительности от своих систем данных, это означает, что они постоянно оценивают новые системы и переносят рабочие нагрузки на новые системы, предлагающие лучшую производительность. Многие также сталкиваются с дополнительной сложностью или ухудшением пользовательского опыта только потому, что производительность для них настолько важна. Системы передового уровня, оптимизированные под производительность, часто не сосредотачиваются на обеспечении отличного пользовательского опыта. Результатом является множество своевременных и дорогостоящих миграций данных, переписывание рабочих процессов и общее напряжение в команде обработки данных, так как им трудно следовать современным тенденциям. Принятие композиционной платформы обработки данных позволило бы этим организациям минимизировать нарушения в потоках данных, сохраняя при этом использование передовых технологий. Предположим, что выходит новый слой хранения, обещающий значительное улучшение времени доступа и ускорение нескольких рабочих процессов. Команда данных может начать использовать его, не переписывая рабочих процессов или изменяя двигатель, просто переместив некоторые данные и попробовав его. Или, если появляется новый двигатель, обещающий значительный прирост производительности для ключевых рабочих процессов, его легко можно заменить, не изменяя кода рабочего процесса или перемещая данные. Фактически, композиционные системы обработки данных упрощают оптимизацию собственных рабочих процессов вокруг производительности и всегда позволяют использовать последние достижения в проектировании систем обработки данных.
- Управление затратами:
- Вместе с повышенной гибкостью и увеличением производительности композиционные системы обработки данных предоставляют потребителям гораздо больший контроль над затратами на систему. Монолиты, по определению, представляют собой комплексные предложения, и потребители, вероятно, платят за функции, которые они не используют, и/или застревают при использовании дорогостоящих и сложных проприетарных компонентов, которые позднее трудно мигрировать. Композиционные системы предоставляют модульные компоненты, что позволяет организациям данных более детально соответствовать дизайн системы своим потребностям. Для компаний, которые хотят получить максимальную производительность, они могут решиться на роскошный двигатель с поддержкой поставщика и использовать хранилища данных с открытым исходным кодом и интерфейсы пользователя. Это также позволяет компаниям более легко использовать преимущества достижений в области аппаратного ускорения, которые распространяются в последние несколько лет и которые должны значительно снизить общую стоимость владения (TCO) их систем данных
.
- Инкрементальное принятие:
- Композиционные системы обработки данных позволяют организациям постепенно переходить к новому подходу, перемещая определенные нагрузки, сохраняя при этом другие рабочие процессы на традиционных системах, если они работают хорошо. Если что-то не сломано, не чините. Однако во многих рабочих процессах обработки данных должно быть достаточно проблем, оправдывающих изучение композиционных систем. Это низкорискованное предложение с ограниченным недостатком, поскольку оно не нарушает существующие рабочие процессы, и пользователи могут легко начать, дополнив свои собственные среды, вместо того чтобы сталкиваться с еще одной дорогостоящей миграцией.
- Удобство оптимизации:
- Модульный характер композиционных систем позволяет более гибко подстраивать систему под конкретные потребности, включая выбор оптимальных компонентов для каждой части системы. Это дает пользователям больше возможностей для оптимизации и эффективного использования своих данных.
- Постепенное внедрение:
- Композиционные системы данных позволяют организациям постепенно переходить к новому подходу, перемещая определенные рабочие нагрузки, сохраняя при этом другие процессы на традиционных системах, если они хорошо функционируют. Это обеспечивает гибкость внедрения и минимизирует риски, связанные с переходом к новой системе.
Чтобы узнать больше:
Voltron Data предоставляет отличный обзор композиционных систем, который стоит прочитать всем, кто интересуется этой темой и хочет начать что-то новое с своими данными.
Перевод с GPT 3.5