Перевод Open Source Data Engineering Landscape 2025
Введение
Сфера Open Source инструментов для инженерии данных продолжает стремительно развиваться, демонстрируя значительный прогресс в области хранения, обработки, интеграции и аналитики данных в 2024 году.
Это второй год публикации обзора ландшафта Open Source инструментов для инженерии данных. Цель обзора — выявить и представить ключевые активные проекты и известные инструменты в этой области, а также предоставить всесторонний обзор динамично развивающейся экосистемы инженерии данных, основных тенденций и разработок.
Хотя этот обзор публикуется ежегодно, соответствующий репозиторий GitHub обновляется регулярно в течение года. Не стесняйтесь вносить свой вклад, если заметите какой-либо недостающий компонент.
Методология исследования
Проведение такого обширного исследования требует значительных усилий и времени. Я постоянно исследую и стараюсь быть в курсе значительных событий в экосистеме инженерии данных в течение всего года, включая новости, мероприятия, тенденции, отчеты и достижения.
В прошлом году я создал свою собственную небольшую платформу данных для отслеживания событий публичных репозиториев GitHub, что позволило лучше анализировать метрики Open Source инструментов, связанные с GitHub, такие как активность кода, количество звезд, вовлеченность пользователей и разрешение проблем.
Стек включает в себя озеро данных (S3), Parquet в качестве формата сериализации, DuckDB для обработки и аналитики, Apache NiFi для интеграции данных, Apache Superset для визуализации и PostgreSQL для управления метаданными, а также другие инструменты. Эта установка позволила мне собрать около 1 ТБ необработанных данных о событиях GitHub, состоящих из миллиардов записей, а также агрегированный набор данных, который накапливается ежедневно, в общей сложности более 500 миллионов записей за 2024 год.
Критерии выбора инструментов
Доступных Open Source проектов для каждой категории, очевидно, много, поэтому включить каждый инструмент и проект в представленный обзор непрактично.
Хотя страница GitHub содержит более полный список инструментов, ежегодно публикуемый обзор содержит только активные проекты, исключая неактивные и довольно новые проекты без минимальной зрелости или популярности. Однако не все включенные инструменты могут быть полностью готовы к промышленному использованию; некоторые все еще находятся на пути к зрелости.
Итак, без лишних слов, представляем обзор Open Source инструментов для инженерии данных 2025 года:
Обзор Open Source инструментов для инженерии данных 2025
Состояние Open Source в 2025 году
Экосистема Open Source инструментов для инженерии данных значительно выросла в 2024 году: в этом году в обзор добавлено более 50 новых инструментов, при этом удалено около 10 неактивных и архивных проектов. Хотя не все эти инструменты были запущены в 2024 году, они представляют собой важные дополнения к экосистеме.
Хотя этот рост демонстрирует постоянные инновации, в этом году также наблюдались некоторые тревожные события, связанные с изменением лицензирования. Устоявшиеся проекты, включая Redis, CockroachDB, ElasticSearch и Kibana, перешли на более закрытые и проприетарные лицензии, хотя Elastic позже объявила о возвращении к Open Source лицензированию.
Однако эти изменения были уравновешены значительным вкладом в Open Source сообщество со стороны крупных игроков отрасли. Вклад Snowflake в Polaris, открытие исходного кода Unity Catalog от Databricks, пожертвование OneHouse Apache XTable и выпуск Netflix Maestro продемонстрировали постоянную приверженность ведущих компаний отрасли разработке Open Source.
Фонд Apache сохранил свои позиции в качестве ключевого управляющего технологиями данных, активно инкубируя несколько перспективных проектов в течение 2024 года. Среди заметных проектов в инкубации были Apache XTable (универсальный формат таблиц), Apache Amoro (управление Lakehouse), Apache HoraeDB (база данных временных рядов), Apache Gravitino (каталог данных), Apache Gluten (промежуточное ПО) и Apache Polaris (каталог данных).
Фонд Linux также укрепил свои позиции в области данных, продолжая размещать такие исключительные проекты, как Delta Lake, Amundsen, Kedro, Milvus и Marquez. Фонд расширил свой портфель в 2024 году, добавив новые значительные проекты, включая vLLM, пожертвованный Калифорнийским университетом в Беркли, и OpenSearch, который был передан из AWS в Фонд Linux.
Open Source vs Open Core vs Open Foundation
Не все перечисленные проекты являются полностью совместимыми, независимыми от поставщиков Open Source инструментами. Некоторые работают по модели Open Core, где не все компоненты полной системы доступны в Open Source версии. Как правило, критически важные функции, такие как безопасность, управление и мониторинг, зарезервированы для платных версий.
Остаются вопросы об устойчивости бизнес-модели Open Core. Эта модель сталкивается со значительными проблемами, что заставляет некоторых полагать, что она может уступить место модели Open Foundation. В этом подходе программное обеспечение с открытым исходным кодом служит основой коммерческих предложений, гарантируя, что оно остается полностью жизнеспособным продуктом для производства со всеми необходимыми функциями.
Обзор категорий
Ландшафт инженерии данных разделен на 9 основных категорий:
* Системы хранения: базы данных и механизмы хранения, охватывающие OLTP, OLAP и специализированные решения для хранения.
* Платформа озера данных: инструменты и фреймворки для построения и управления озерами данных и Lakehouse.
* Обработка и интеграция данных: фреймворки для пакетной и потоковой обработки, а также инструменты обработки данных Python.
* Оркестрация рабочих процессов и DataOps: инструменты для оркестрации конвейеров данных и управления операциями с данными.
* Интеграция данных: решения для приема данных, CDC (Change Data Capture) и интеграции между системами.
* Инфраструктура данных: основные компоненты инфраструктуры, включая оркестрацию контейнеров и мониторинг.
* ML/AI платформа: инструменты, ориентированные на ML-платформы, MLOps и векторные базы данных.
* Управление метаданными: решения для каталогов данных, управления и управления метаданными.
* Аналитика и визуализация: BI-инструменты, фреймворки визуализации и аналитические механизмы.
В следующем разделе кратко обсуждаются последние тенденции, инновации и текущее состояние основных продуктов в каждой категории.
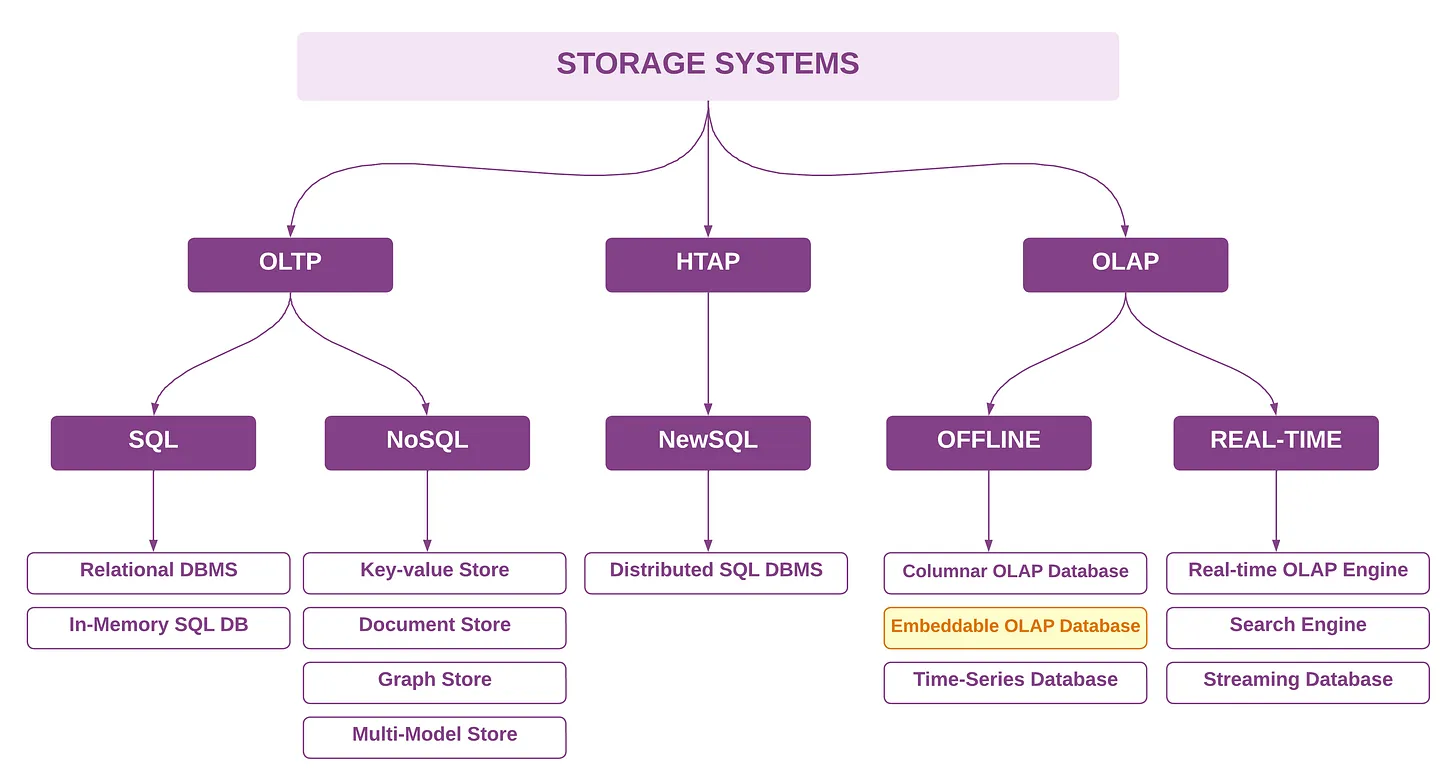
- Системы хранения
В 2024 году ландшафт систем хранения данных претерпел значительные архитектурные изменения, особенно в области систем баз данных OLAP.
DuckDB стал историей крупного успеха, особенно после выпуска версии 1.0, которая продемонстрировала готовность к промышленному использованию для предприятий. Новая категория встраиваемых OLAP расширилась за счет новых участников, таких как chDB (построенный на ClickHouse), GlareDB и SlateDB, что отражает растущий спрос на легкие аналитические возможности обработки.
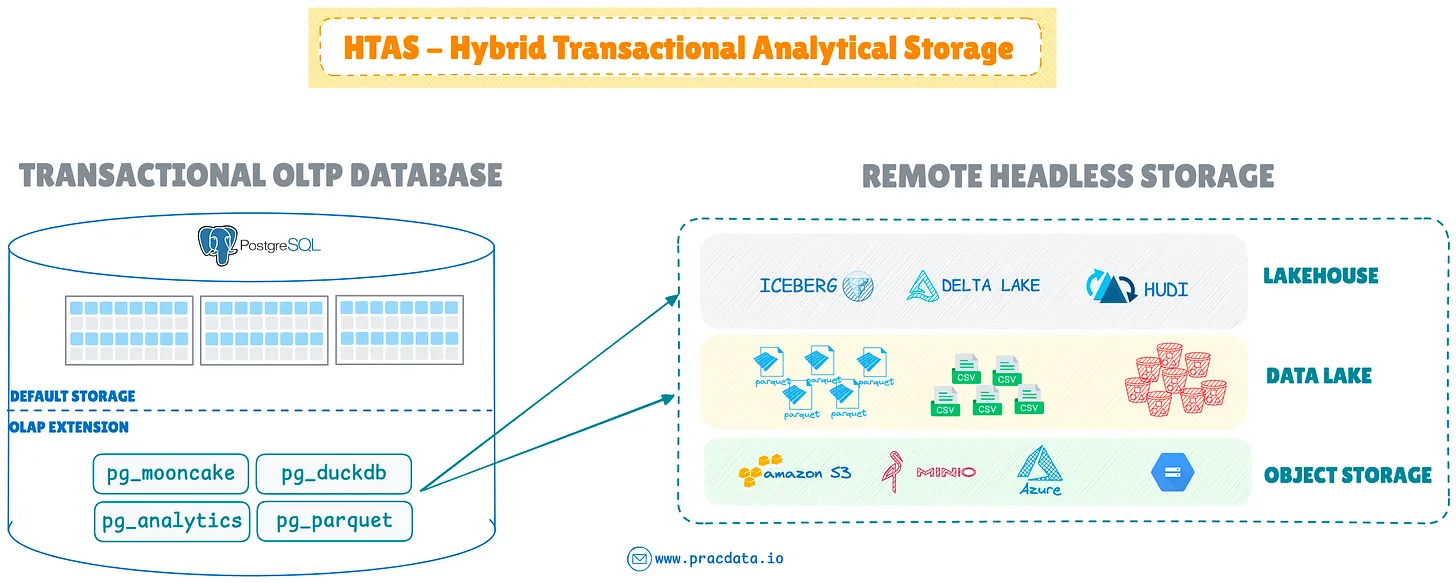
Расширения OLAP и HTAS
Значительным событием стало распространение новых расширений OLAP, особенно в экосистеме PostgreSQL.
Эти расширения позволяют легко расширять базы данных OLTP, преобразовывая эти системы в HTAP (гибридная транзакционная/аналитическая обработка) или новый механизм базы данных HTAS (гибридное транзакционное аналитическое хранилище), который интегрирует безголовое хранилище данных, такое как озера данных и lakehouse, с транзакционными системами баз данных.
Выпуск MotherDuck pg_duckdb стал важным шагом вперед, позволив DuckDB служить встроенным механизмом OLAP в PostgreSQL. За ним последовало расширение pg_mooncake, предоставляющее собственные возможности хранения столбцов в открытых табличных форматах, таких как Iceberg и Delta. Crunchy Data и ParadeDB внесли аналогичный вклад через pg_parquet и pg_analytics соответственно, обеспечивая прямую аналитику по файлам Parquet в озерах данных.
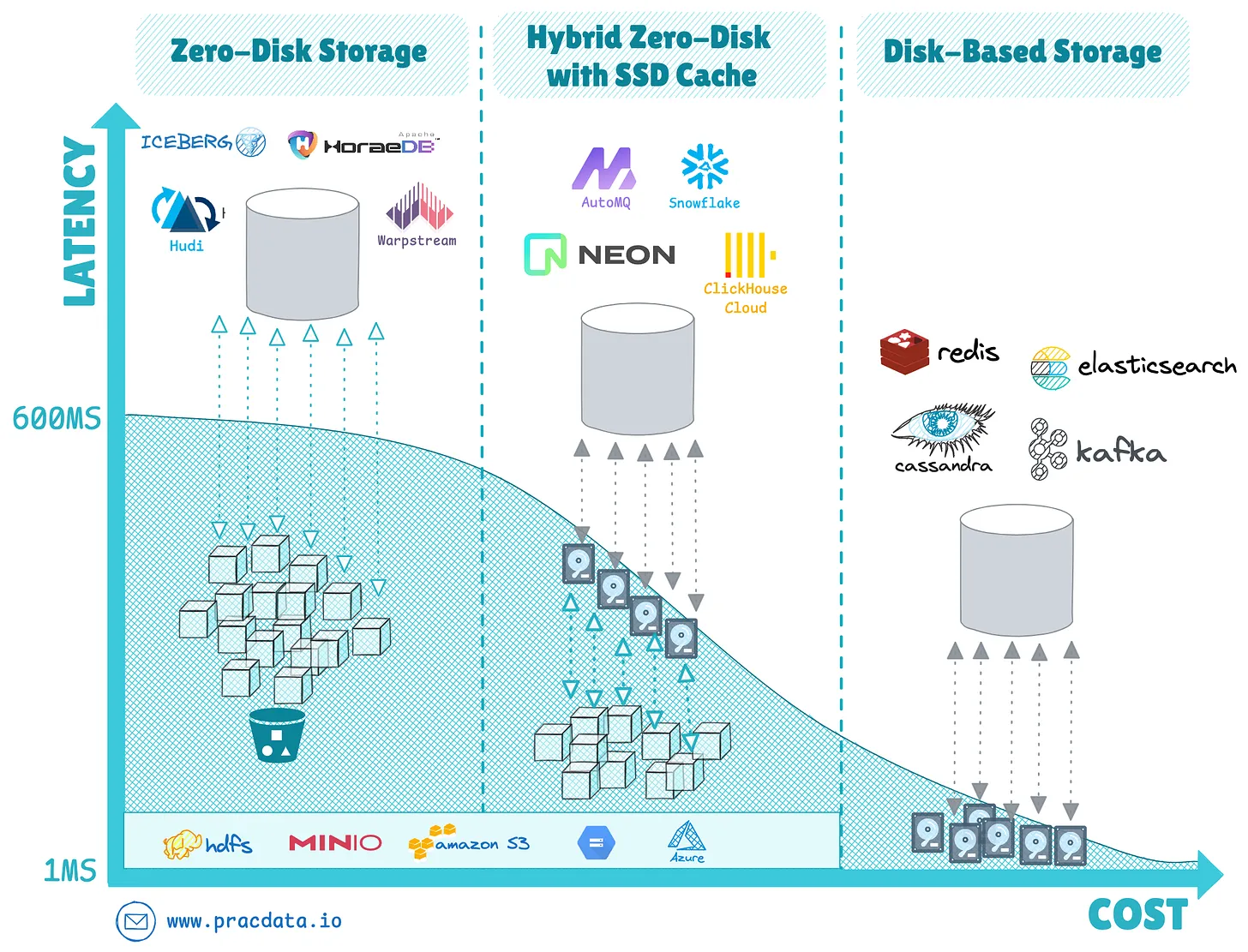
Архитектура без дисков (Zero-Disk)
Архитектура без дисков стала, пожалуй, самой преобразующей тенденцией в системах хранения, фундаментально изменив то, как системы баз данных управляют уровнями хранения и вычислений.
Этот архитектурный подход полностью устраняет необходимость в локально подключенных дисках, вместо этого используя удаленные решения для глубокого хранения, такие как объектное хранилище S3, в качестве основного уровня персистентности.
Помимо систем хранения OLAP, таких как облачные хранилища данных и открытые табличные форматы, мы наблюдаем значительное появление этой модели в NoSQL, системах реального времени, потоковых и транзакционных системах.
Основным компромиссом для систем на основе дисков и систем без дисков является соотношение цены и производительности, а также задержка ввода-вывода для чтения и записи данных на физическое хранилище. В то время как дисковые системы могут управлять быстрым вводом-выводом менее миллисекунды, системы без дисков достигают экономии за счет масштаба с дешевым масштабируемым объектным хранилищем, ценой задержек до одной секунды при чтении и записи данных в службу объектного хранилища.
Новые системы баз данных, включая базу данных временных рядов SlateDB и Apache HoraeDB, были построены с нуля с использованием этой архитектуры, в то время как устоявшиеся системы, такие как Apache Doris и StarRocks, приняли ее в 2024 году. Другие механизмы реального времени, такие как AutoMQ и InfluxDB 3.0, все чаще применяют парадигму без дисков.
Для всестороннего анализа архитектуры без дисков и ее последствий см. подробное исследование в следующей статье: Архитектура без дисков: будущее облачных систем хранения. https://www.pracdata.io/p/zero-disk-architecture-the-future
Другие заметные разработки
После перехода Redis на проприетарную лицензию в 2024 году Valkey стала ведущей альтернативой с открытым исходным кодом, став самой звездной системой хранения на GitHub в 2024 году. Крупные облачные провайдеры быстро приняли ее: Google интегрировал ее в Memorystore, а Amazon поддерживает ее через сервисы ElastiCache и MemoryDB.
Другие заметные разработки включают ParadeDB, альтернативу Elasticsearch, построенную на движке PostgreSQL, и новые гибридные системы потокового хранения, такие как Proton от TimePlus и Fluss, представленные Ververica. Эти системы направлены на интеграцию функций потоковой передачи и OLAP с основой хранения столбцов.
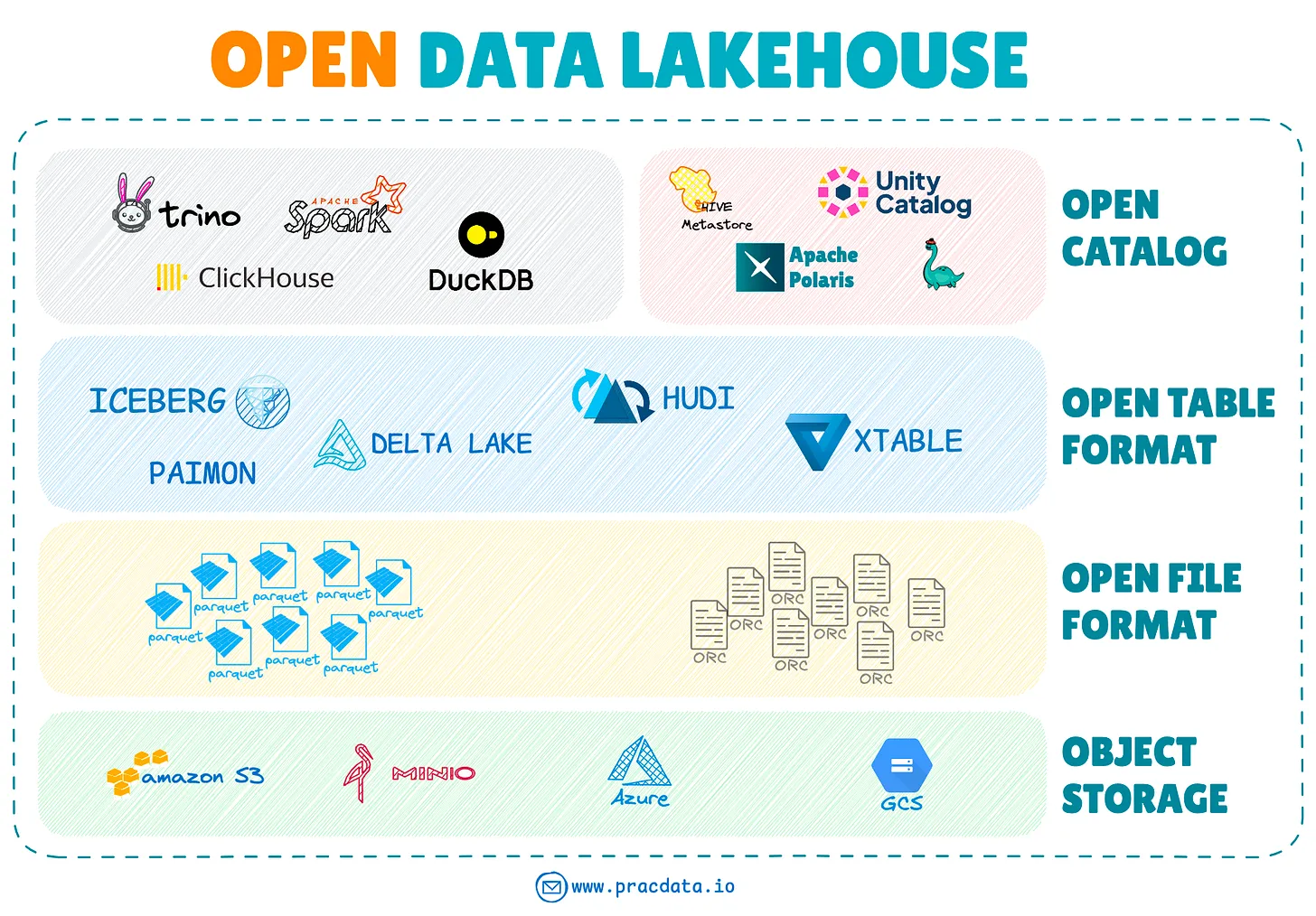
- Платформа озера данных
Поскольку пионер баз данных Майкл Стоунбрейкер одобрил архитектуру lakehouse и открытые табличные форматы как «архетип OLAP СУБД на следующее десятилетие», lakehouse остается самой горячей темой в инженерии данных.
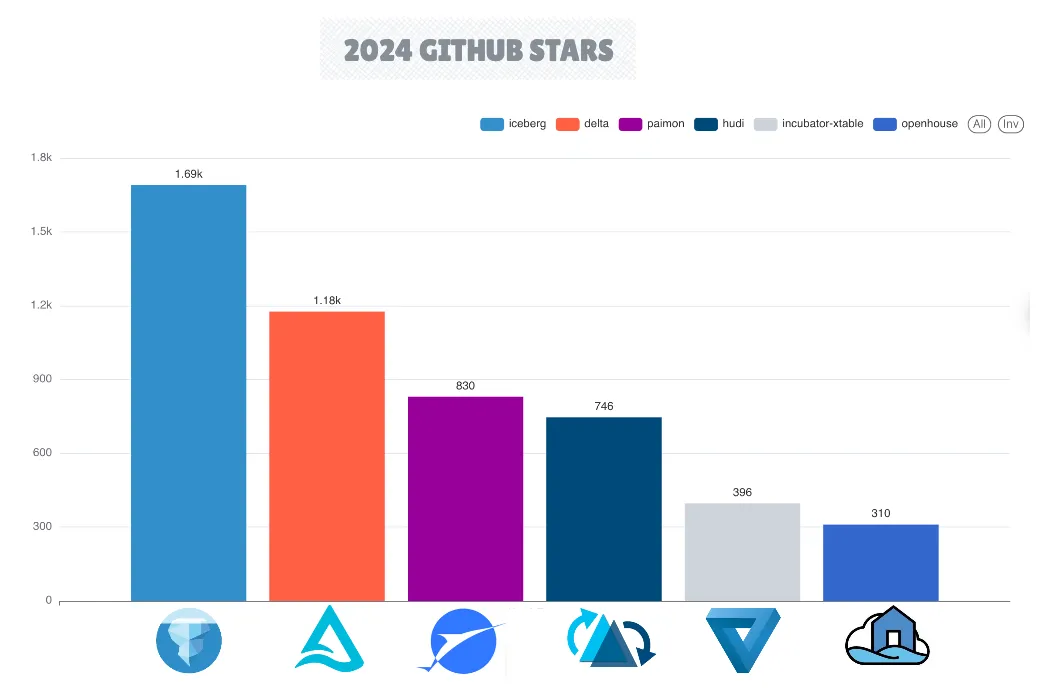
Ландшафт открытых табличных форматов продолжал значительно развиваться в 2024 году. Четвертый основной открытый табличный формат, Apache Paimon, вышел из инкубации, предоставив возможности потоковой передачи lakehouse с интеграцией Apache Flink. Apache XTable появился как новый проект, ориентированный на двунаправленное преобразование форматов, в то время как Apache Amoro вошел в инкубацию со своим фреймворком управления lakehouse.
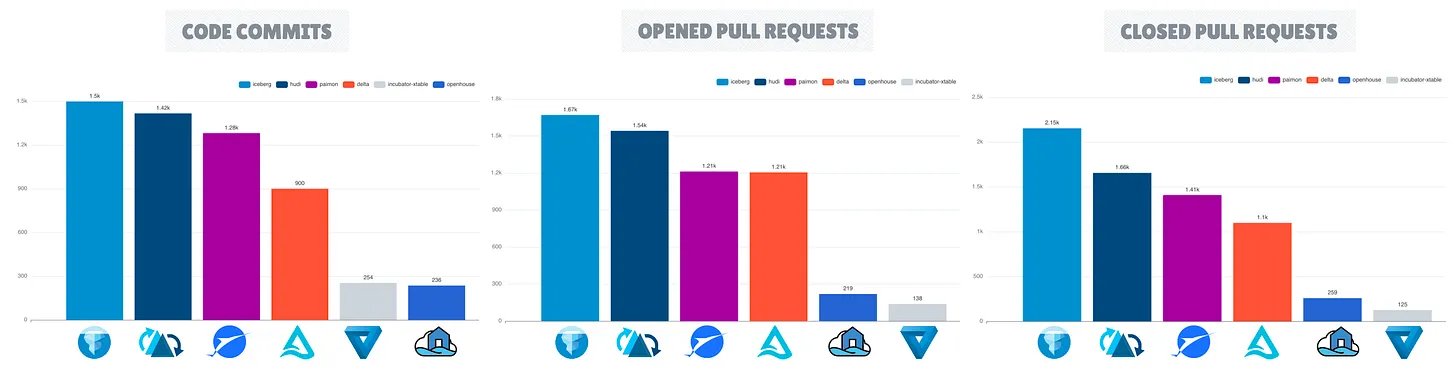
В 2024 году Apache Iceberg зарекомендовал себя как ведущий проект среди фреймворков с открытым табличным форматом, отличающийся расширением своей экосистемы и метриками репозитория GitHub, включая большее количество звезд, форков, запросов на вытягивание и коммитов.
Все основные поставщики SaaS и облачных технологий улучшили свои платформы для поддержки доступа к открытым табличным форматам. Однако поддержка записи была менее распространена, причем Apache Iceberg был предпочтительным выбором для комплексной интеграции CRUD (Create, Read, Update, Delete).
Управляемые таблицы BigLake от Google, позволяющие изменять таблицы Iceberg в облачном хранилище, управляемом клиентом, недавно анонсированные таблицы S3 от Amazon с нативной поддержкой Iceberg, а также другие основные инструменты SaaS, такие как Redpanda, запускающие Iceberg Topics, и Crunchy Data Warehouse, глубоко интегрирующиеся с Apache Iceberg, являются примерами растущего внедрения и глубокой интеграции с Iceberg в экосистеме.
В будущем универсальные табличные форматы, такие как Apache XTable и Delta UniForm (Delta Lake Universal Format), могут столкнуться со значительными трудностями в навигации по потенциальному расхождению функций в различных форматах, а судьба открытых табличных форматов может отражать судьбу открытых файловых форматов, когда Parquet стал фактическим стандартом.
По мере того, как экосистема lakehouse продолжает расти, ожидается, что внедрение совместимых открытых стандартов и фреймворков в рамках платформы Open Data Lakehouse приобретет большую популярность.
Появление библиотек нативных табличных форматов
В экосистеме lakehouse появляется новая тенденция, сосредоточенная на разработке нативных библиотек на Python и Rust. Эти библиотеки направлены на обеспечение прямого доступа к открытым табличным форматам без необходимости использования тяжелых фреймворков, таких как Spark.
Яркими примерами являются Delta-rs, нативная библиотека Rust для Delta Lake со связями Python; Hudi-rs, реализация Rust для Apache Hudi с API Python, и PyIceberg, развивающаяся библиотека Python, предназначенная для улучшения доступа к табличному формату Iceberg за пределами движка Spark по умолчанию.
- Обработка и интеграция данных
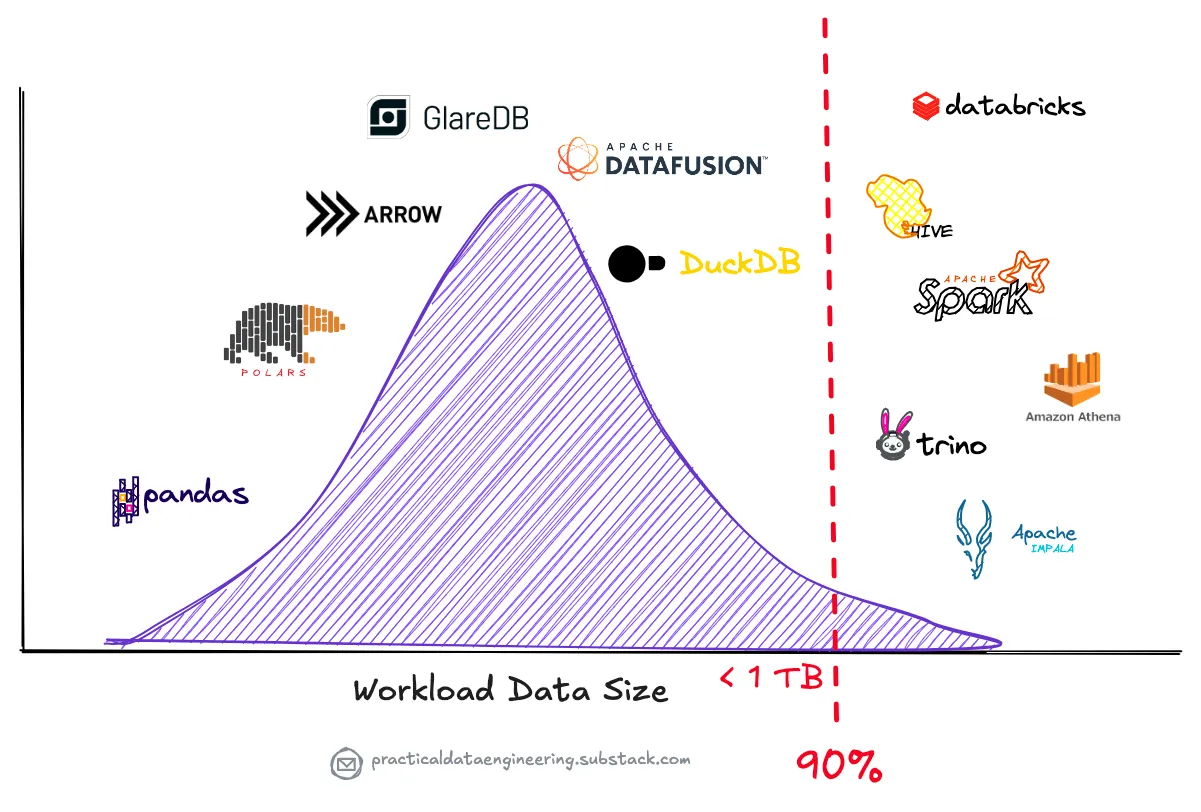
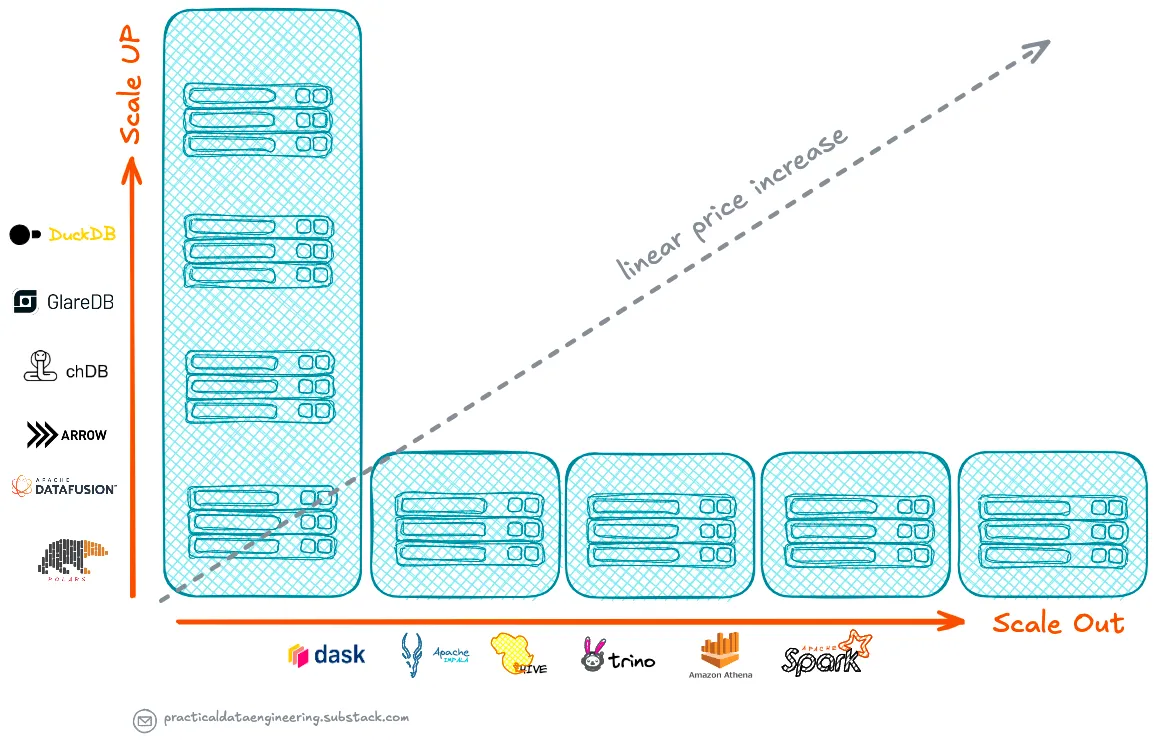
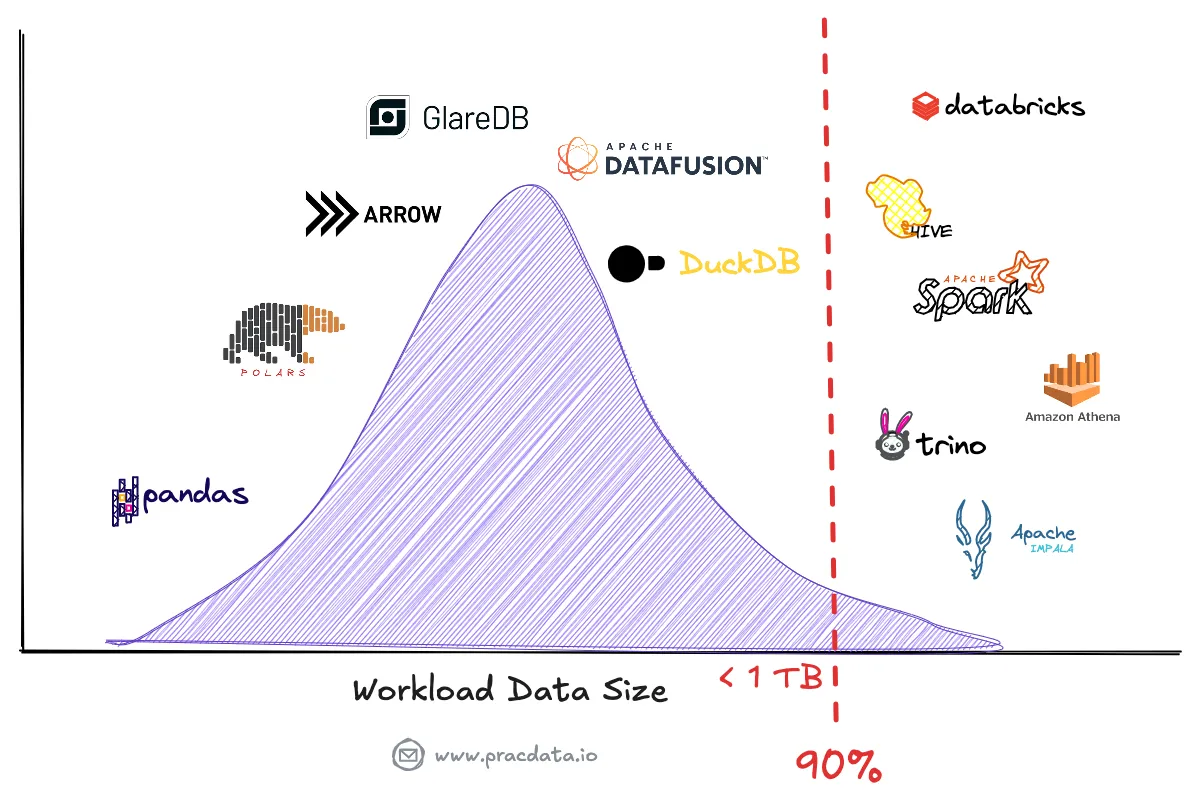
Подъем одноузловой обработки
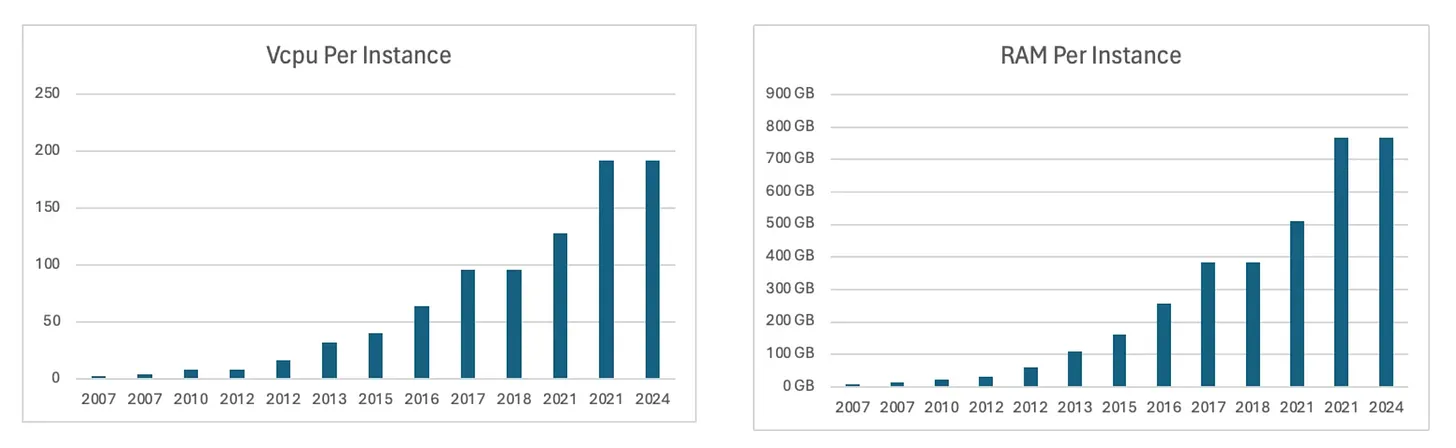
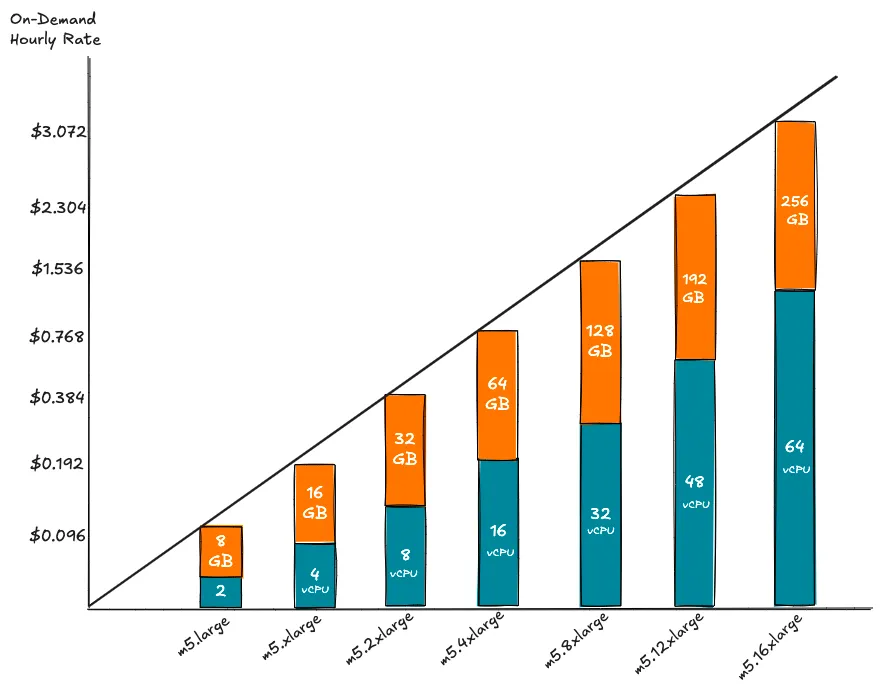
Подъем одноузловой обработки представляет собой фундаментальный сдвиг в обработке данных, бросающий вызов традиционным подходам, ориентированным на распределенные системы.
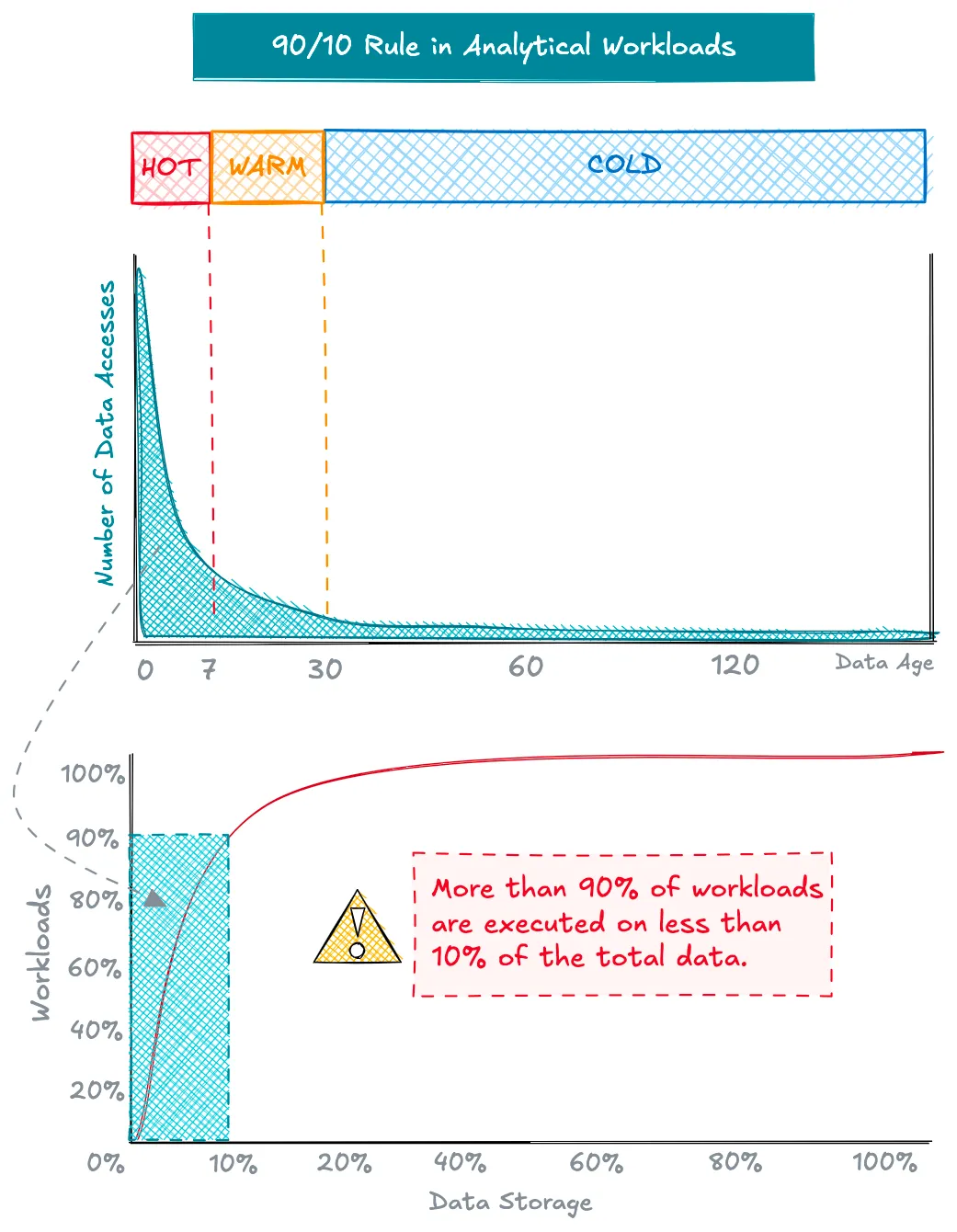
Недавний анализ показывает, что многие компании переоценили свои потребности в больших данных, что побудило пересмотреть свои требования к обработке данных. Даже в организациях с большими объемами данных примерно 90% запросов остаются в пределах управляемого размера рабочей нагрузки для запуска на одной машине, сканируя только последние данные.
Современные механизмы одноузловой обработки, такие как DuckDB, Apache DataFusion и Polars, стали мощными альтернативами, способными обрабатывать рабочие нагрузки, которые ранее требовали распределенных систем, таких как Hive/Tez, Spark, Presto или Amazon Athena.
Чтобы ознакомиться с полным анализом состояния одноузловой обработки, перейдите по ссылке ниже: https://www.pracdata.io/p/the-rise-of-single-node-processing или тут есть перевод https://gavrilov.info/all/rascvet-odnouzlovoy-obrabotki-brosaya-vyzov-podhodu-raspredelyon/
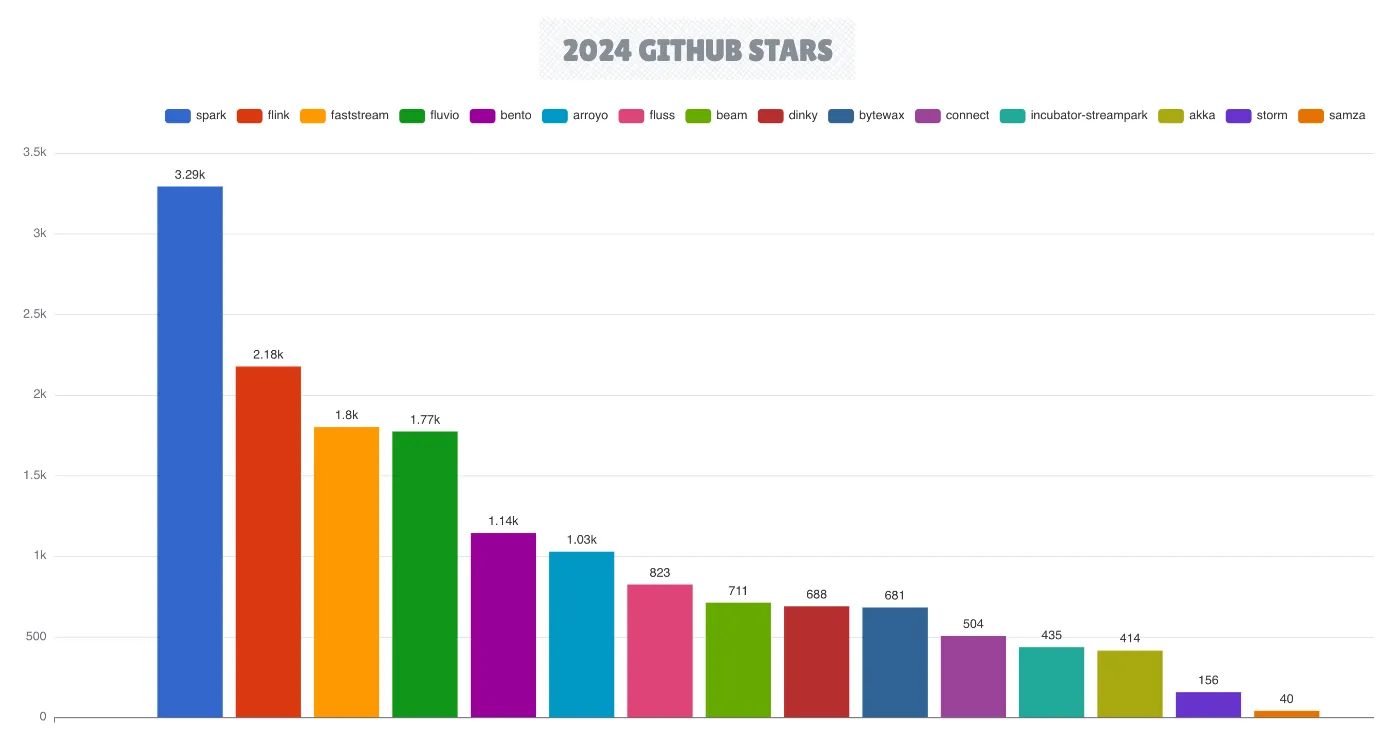
Потоковая обработка
Экосистема потоковой обработки продолжала расширяться в 2024 году, причем Apache Flink еще больше укрепил свои позиции в качестве ведущего движка потоковой обработки, в то время как Apache Spark сохраняет свои сильные позиции.
Отмечая свое 10-летие, Flink выпустил версию 2.0, представляющую первое крупное обновление с момента дебюта Flink 1.0 восемь лет назад. Экосистема Apache Flink значительно расширилась с появлением открытого табличного формата Apache Paimon и недавно открытого движка потоковой обработки Fluss. В 2024 году ведущие облачные провайдеры все чаще интегрировали Flink в свои управляемые сервисы, последним из которых стало бессерверное решение Google BigQuery Engine для Apache Flink.
Появляющиеся движки потоковой обработки — Fluvio, Arroyo и FastStream — стремятся конкурировать с этими признанными претендентами. Fluvio и Arroyo выделяются как единственные движки на основе Rust, которые направлены на устранение накладных расходов, обычно связанных с традиционными движками потоковой обработки на основе JVM.
В главных новостях потоковой передачи с открытым исходным кодом Redpanda приобрела Benthos.dev, переименовав ее в Redpanda Connect и переведя на более проприетарную лицензию. В ответ WarpStream создал форк проекта Benthos, переименовав его в Bento и обязавшись сохранить его 100% лицензированным по MIT.
Фреймворки обработки Python
В экосистеме обработки данных Python Polars в настоящее время является доминирующей высокопроизводительной библиотекой DataFrame для задач инженерии данных (за исключением PySpark). Polars достиг впечатляющих 89 миллионов загрузок в 2024 году, отметив важный этап выпуска версии 1.0.
Однако теперь Polars сталкивается с конкуренцией со стороны API DataFrame от DuckDB, который привлек внимание сообщества своей удивительно простой интеграцией с внешними системами хранения и интеграцией без копирования (прямое совместное использование памяти между различными системами) с Apache Arrow, аналогично Polars. Обе библиотеки входят в 1% самых загружаемых библиотек Python в прошлом году.
Apache Arrow укрепил свои позиции в качестве фактического стандарта для представления данных в памяти в экосистеме обработки данных Python. Фреймворк установил глубокую интеграцию с различными фреймворками обработки Python, включая Apache DataFusion, Ibis, Daft, cuDF и Pandas 3.0.
Ibis и Daft — это другие инновационные проекты DataFrame с высоким потенциалом. Ibis имеет удобный внутренний интерфейс для различных баз данных на основе SQL, а Daft предоставляет возможности распределенных вычислений, созданные с нуля для поддержки распределенной обработки DataFrame.
Оркестрация рабочих процессов и DataOps
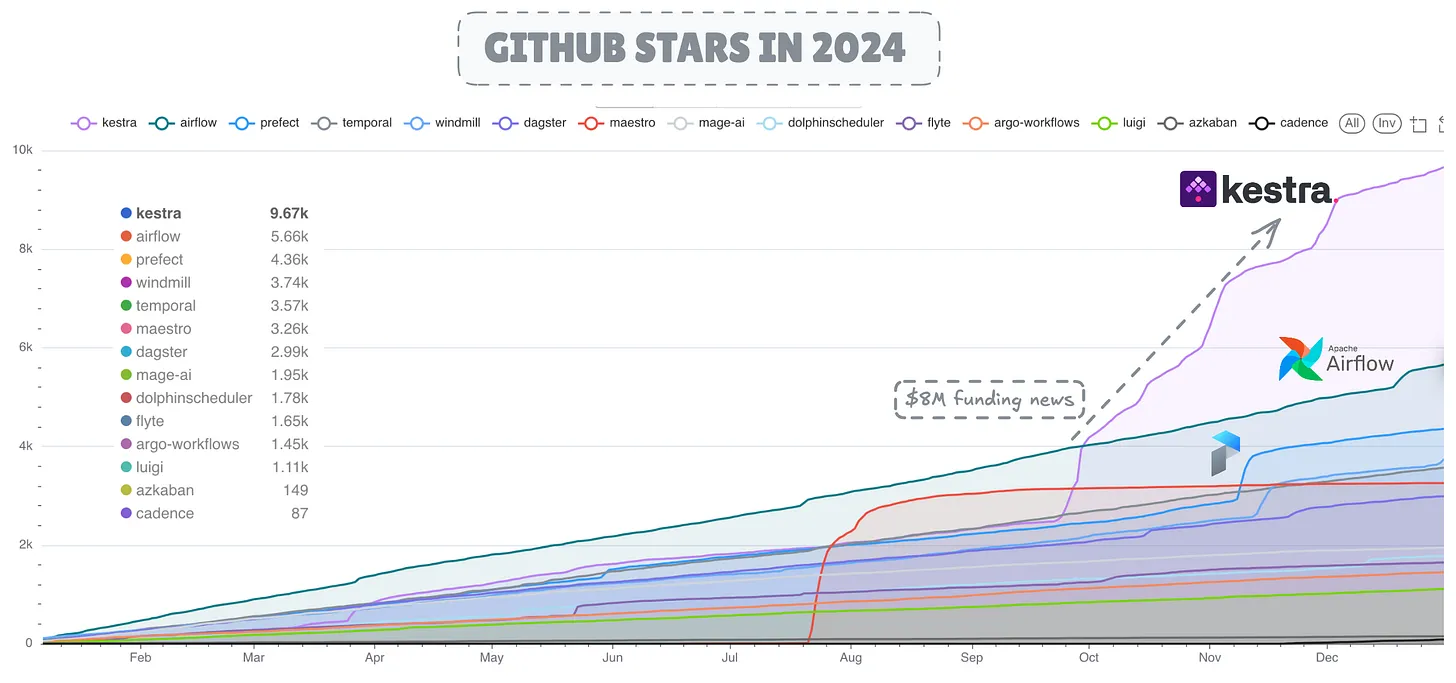
В 2025 году категория оркестрации рабочих процессов с открытым исходным кодом продолжает оставаться одним из самых динамичных сегментов экосистемы инженерии данных, включающей более 10 активных проектов, от устоявшихся платформ, таких как Apache Airflow, до недавно открытых движков, таких как Maestro от Netflix.
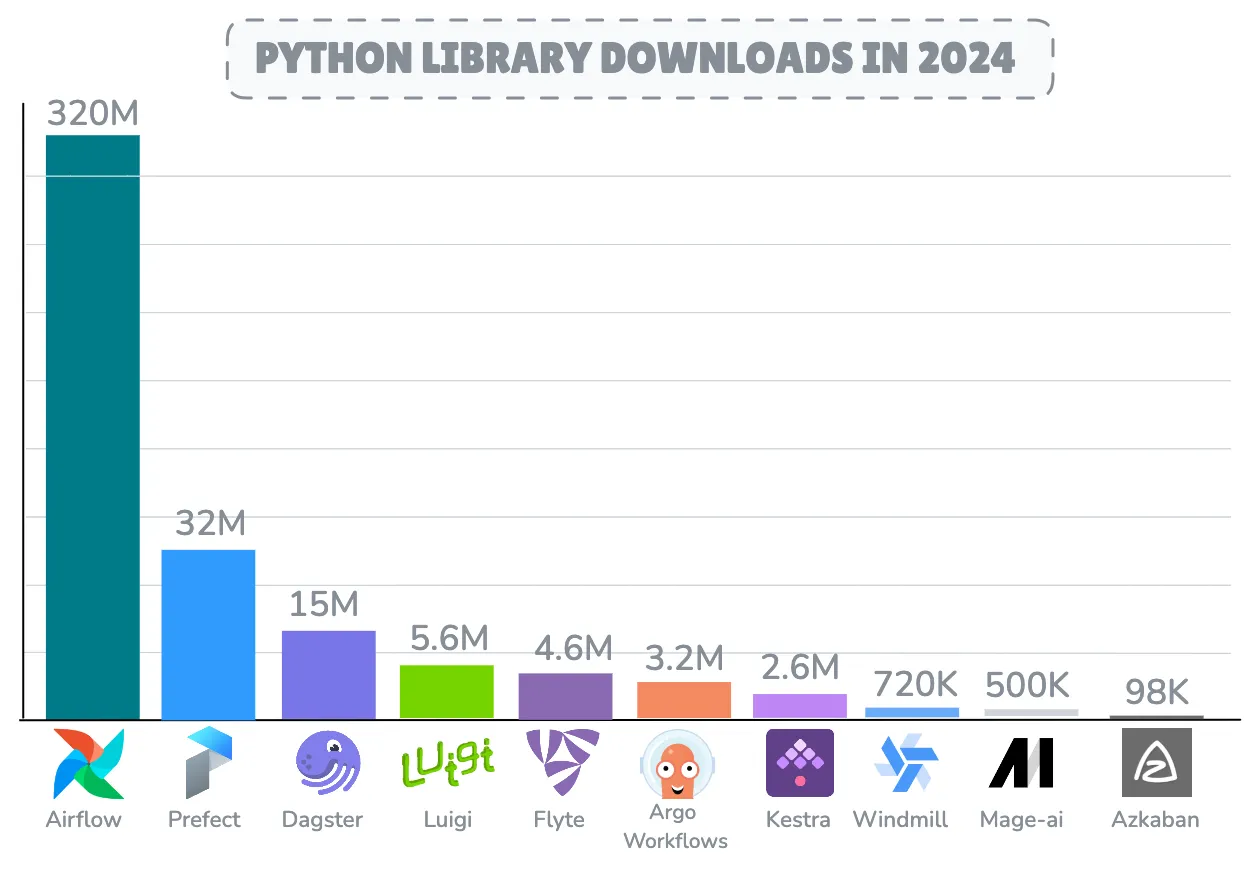
После десятилетия Apache Airflow продолжает оставаться наиболее развернутым и принятым движком оркестрации рабочих процессов с ошеломляющими 320 миллионами загрузок только в 2024 году, сталкиваясь с конкуренцией со стороны растущих конкурентов, таких как Dagster, Prefect и Kestra.
Интересно, что Kestra получил наибольшее количество звезд на GitHub в 2024 году, причем всплеск напрямую связан с объявлением о его финансировании в размере 8 миллионов долларов в сентябре, которое было опубликовано на TechCrunch. С точки зрения активности кода, Dagster продемонстрировал замечательную активность разработки с впечатляющими 27 000 коммитов и почти 6 000 закрытыми запросами на вытягивание в 2024 году.
Для всестороннего анализа состояния систем оркестрации рабочих процессов прочтите следующую статью: https://www.pracdata.io/p/state-of-workflow-orchestration-ecosystem-2025
Качество данных
Great Expectations продолжает оставаться ведущим фреймворком Python для обеспечения качества данных и валидации, также представленным в 10 лучших продуктах Databricks для данных и ИИ 2024 года, за которым следуют Soda и Pandera в практике инженерии данных. Однако есть и разочаровывающие новости: проект Data-Diff был заархивирован своим основным разработчиком, Datafold, в 2024 году.
Версионирование данных
Версионирование данных остается важной темой в 2024 году, поскольку продолжаются усилия по внедрению возможностей современных систем управления версиями, таких как Git, в озера данных и lakehouse.
Такие проекты, как LakeFS и Nessie, улучшают современные озера данных и открытые табличные форматы, такие как Iceberg и Delta Lake, за счет расширения их транзакционных уровней метаданных.
Преобразование данных
Сфера использования dbt для преобразования данных расширяется за пределы ее первоначальной направленности на моделирование данных в системах хранилищ данных. В настоящее время она проникает в среды вне хранилищ данных, такие как озера данных, благодаря новым интеграциям и плагинам, которые используют временные вычислительные движки, такие как Trino.
В настоящее время dbt сталкивается с конкуренцией в основном со стороны SQLMesh. Примечательным противостоянием в 2024 году стали дебаты SQLMesh против dbt, освещенные генеральным директором Tobiko, который заявил в социальных сетях, что SQLMesh настолько хорош, что его запретили на конференции Coalesce от dbt!
Интеграция данных
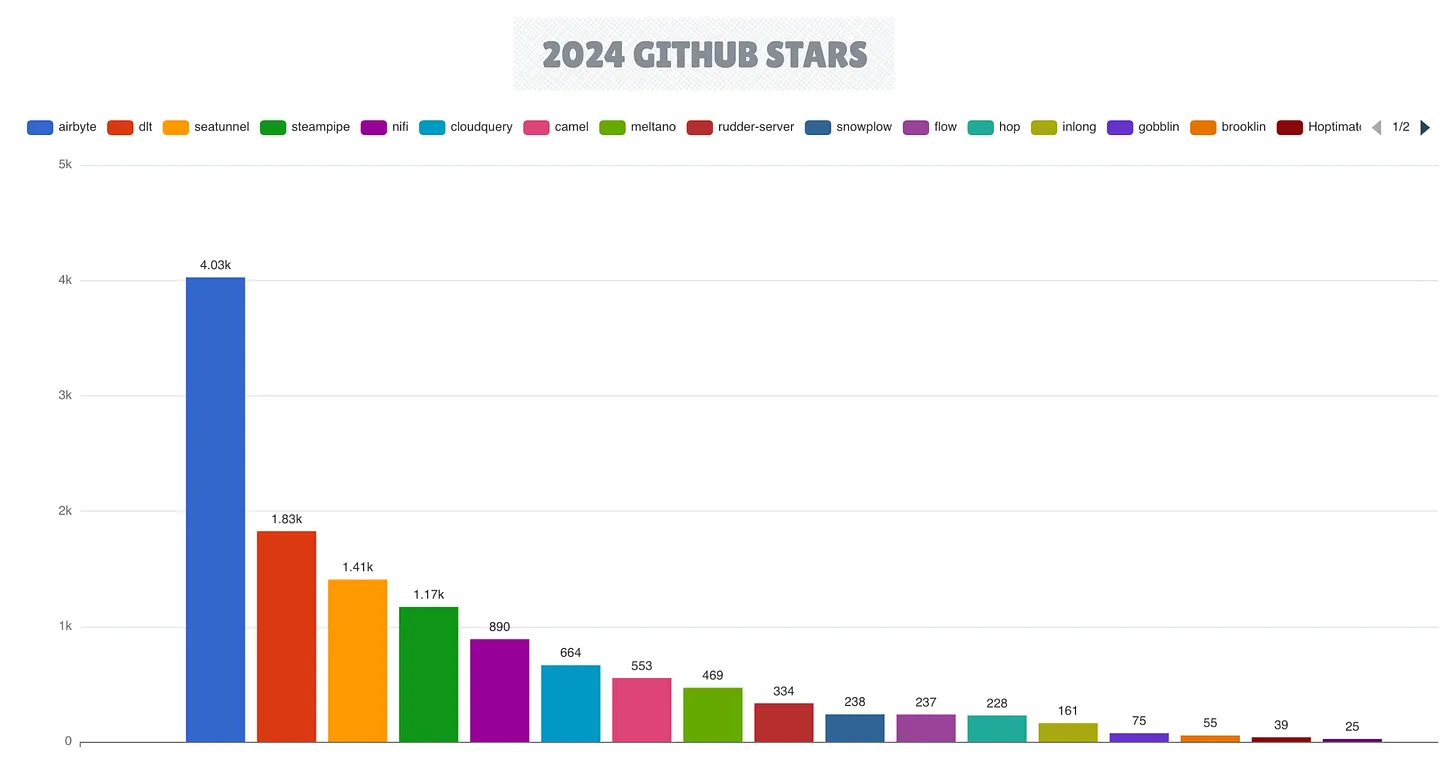
В области интеграции данных Airbyte сохранил свои лидирующие позиции, достигнув впечатляющей вехи, закрыв 13 000 запросов на вытягивание в рамках подготовки к версии 1.x. Фреймворк dlt продемонстрировал значительное созревание с выпуском версии 1.0, в то время как Apache SeaTunnel набрал обороты в качестве убедительной альтернативы.
Ландшафт фреймворков Change Data Capture (CDC) развивался с появлением новых инструментов, включая Artie Transfer и PeerDB (приобретен ClickHouse), в то время как коннекторы Flink CDC получают распространение среди платформ, использующих Flink в качестве основного движка потоковой передачи.
Центры событий (службы потоковой публикации/подписки)
Одно из самых заметных нововведений в области интеграции данных в 2024 году произошло из развивающегося ландшафта потоковой передачи данных. Значительным архитектурным сдвигом в этой категории является разделение хранения и вычислений в сочетании с внедрением объектного хранилища в архитектуре без дисков. WarpStream является пионером в реализации этой архитектуры в области потоковой передачи в реальном времени.
Эта модель также обеспечивает гибкую стратегию развертывания Bring Your Own Cloud (BYOC), поскольку как вычисления, так и хранилище могут размещаться в предпочитаемой клиентом инфраструктуре, в то время как поставщик услуг поддерживает плоскость управления.
Успех WarpStream побудил крупных конкурентов принять аналогичные архитектуры. Redpanda запустила Cloud Topics, улучшив свои предложения, в то время как AutoMQ реализовала гибридный подход с быстрым уровнем кеширования для повышения производительности ввода-вывода.
Кроме того, StreamNative представила движок Ursa для Apache Pulsar, а Confluent представила свои собственные облачные кластеры Freight Clusters в 2024 году. В конечном итоге Confluent решила приобрести WarpStream, еще больше расширив свое предложение с помощью модели BYOC. Между тем, замечательный Apache Kafka стоит на распутье, которое может определить его дальнейшее направление в экосистеме.
Инфраструктура данных
Ландшафт инфраструктуры данных в 2024 году оставался в основном стабильным: Kubernetes отпраздновал свое 10-летие, сохранив при этом свои позиции в качестве ведущего движка планирования ресурсов и виртуализации в облачных средах.
В области наблюдаемости InfluxDB, Prometheus и Grafana продолжали доминировать, причем Grafana Labs обеспечила себе заметный раунд финансирования в размере 270 миллионов долларов, который укрепил долгосрочную жизнеспособность их основных продуктов, таких как Grafana, в качестве универсальных решений для наблюдаемости.
ML/AI платформа
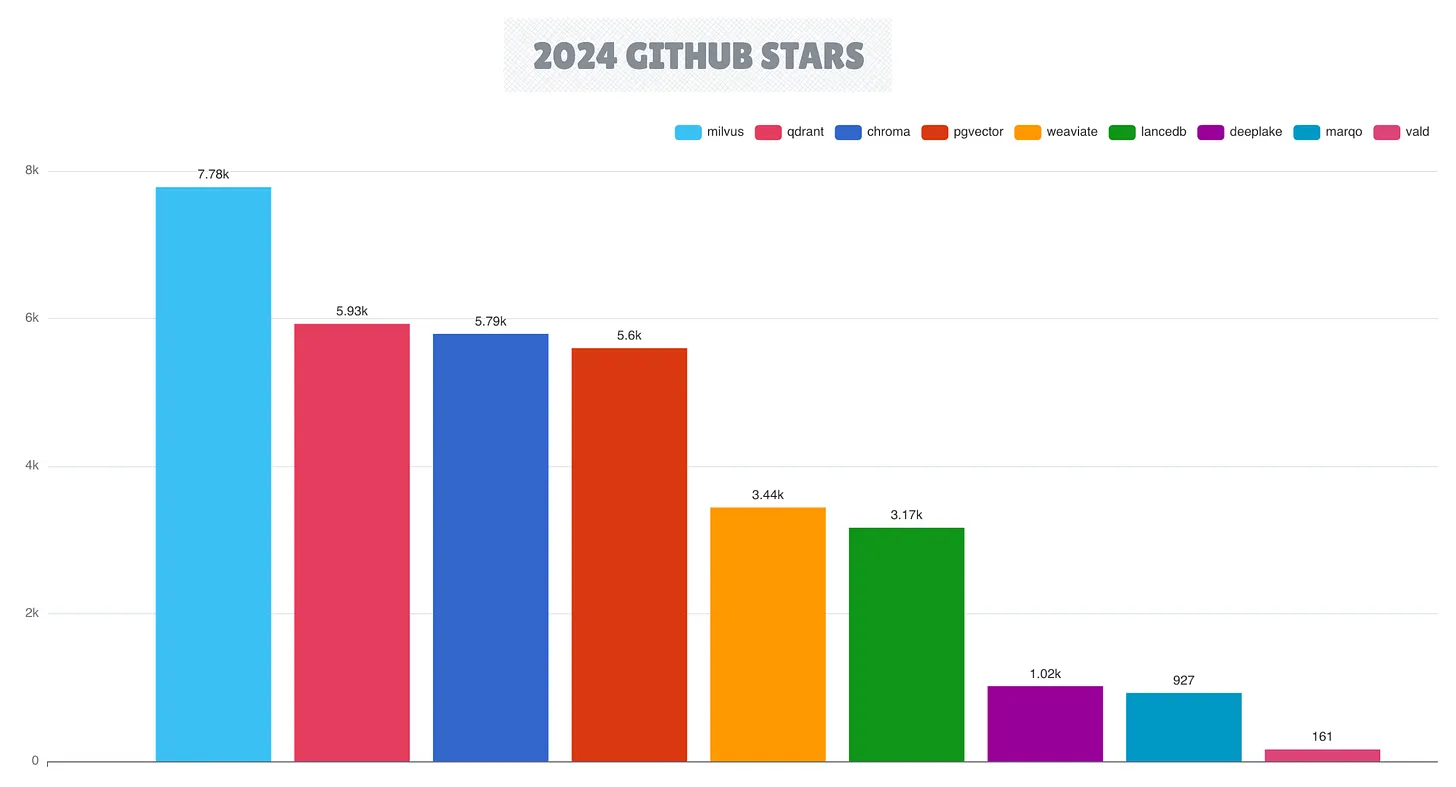
Векторные базы данных сохранили сильный импульс с 2023 года, причем Milvus стала лидером наряду с Qdrant, Chroma и Weaviate. В настоящее время эта категория включает десять активных проектов векторных баз данных, что отражает растущую важность возможностей векторного поиска в современных архитектурах данных с поддержкой ИИ.
Внедрение LLMOps (также называемого GenOps) в качестве отдельной категории в представленном в этом году ландшафте было отмечено быстрым ростом новых проектов, таких как Dify и vLLM, специально созданных для управления LLM-моделями.
Управление метаданными
Платформы управления метаданными приобрели значительный импульс в последние годы, причем DataHub лидирует в области открытого исходного кода благодаря своей активной разработке и участию сообщества.
Однако наиболее заметные события в 2024 году произошли в управлении каталогами. В то время как в 2023 году доминировала конкуренция в открытых табличных форматах, 2024 год ознаменовал начало «войны каталогов».
В отличие от предыдущих лет, в 2024 году на рынок вышла волна новых решений для открытых каталогов, включая Polaris (открытый исходный код от Snowflake), Unity Catalog (открытый исходный код от Databricks), LakeKeeper и Apache Gravitino.
Это распространение отражает осознание того, что появляющимся платформам lakehouse, которые в значительной степени полагаются на открытые табличные форматы, не хватает передовых встроенных возможностей управления каталогами для бесшовной взаимодействия между различными движками.
Все эти проекты имеют потенциал для установления нового стандарта для независимых от поставщиков открытых каталожных сервисов на платформах lakehouse. Подобно тому, как Hive Metastore стал фактическим стандартом для платформ на основе Hadoop, эти новые каталоги могут окончательно заменить давнее доминирование Hive Metastore в управлении каталогами на открытых платформах данных.
Аналитика и визуализация
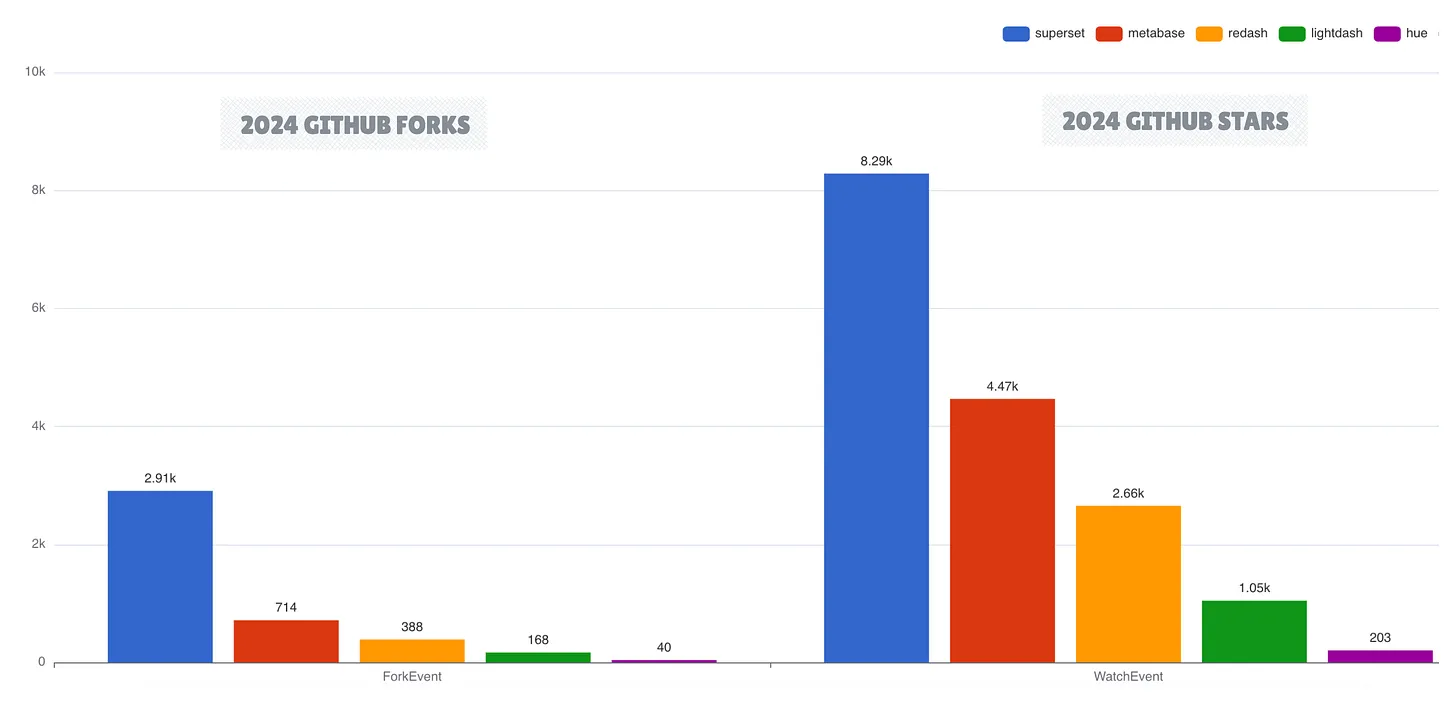
В области бизнес-аналитики с открытым исходным кодом Apache Superset и Metabase остаются ведущими BI-решениями. В то время как Superset лидирует по популярности на GitHub, Metabase демонстрирует наивысшую активность разработки. Lightdash стал многообещающим новичком, получив финансирование в размере 11 миллионов долларов и продемонстрировав рыночный спрос на легкие BI-решения.
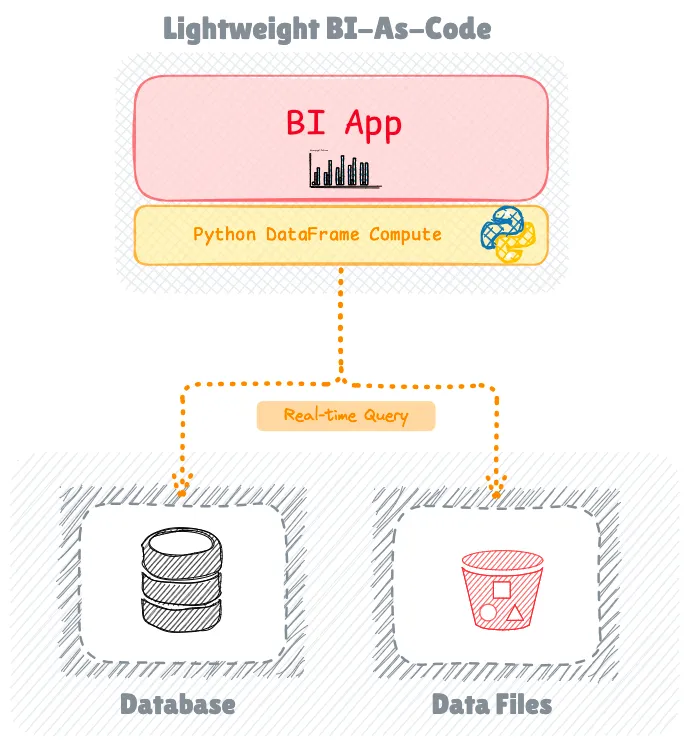
BI-as-Code решения
BI-as-Code появился как отдельная категория благодаря продолжающемуся успеху Streamlit, который сохранил свои позиции в качестве самого популярного решения BI-as-Code.
Эти инструменты позволяют разработчикам создавать интерактивные приложения и легкие BI-панели управления с помощью кода, SQL и шаблонов, таких как Markdown или YAML, имея возможность комбинировать лучшие практики разработки программного обеспечения, такие как контроль версий, тестирование и CI/CD, в рабочий процесс разработки панелей управления.
В дополнение к Streamlit и известному Evidence новые участники, такие как Quary и Vizro, набрали обороты, причем Quary, в частности, реализовал подход на основе Rust, который отличается от нормы, ориентированной на Python, в этой категории.
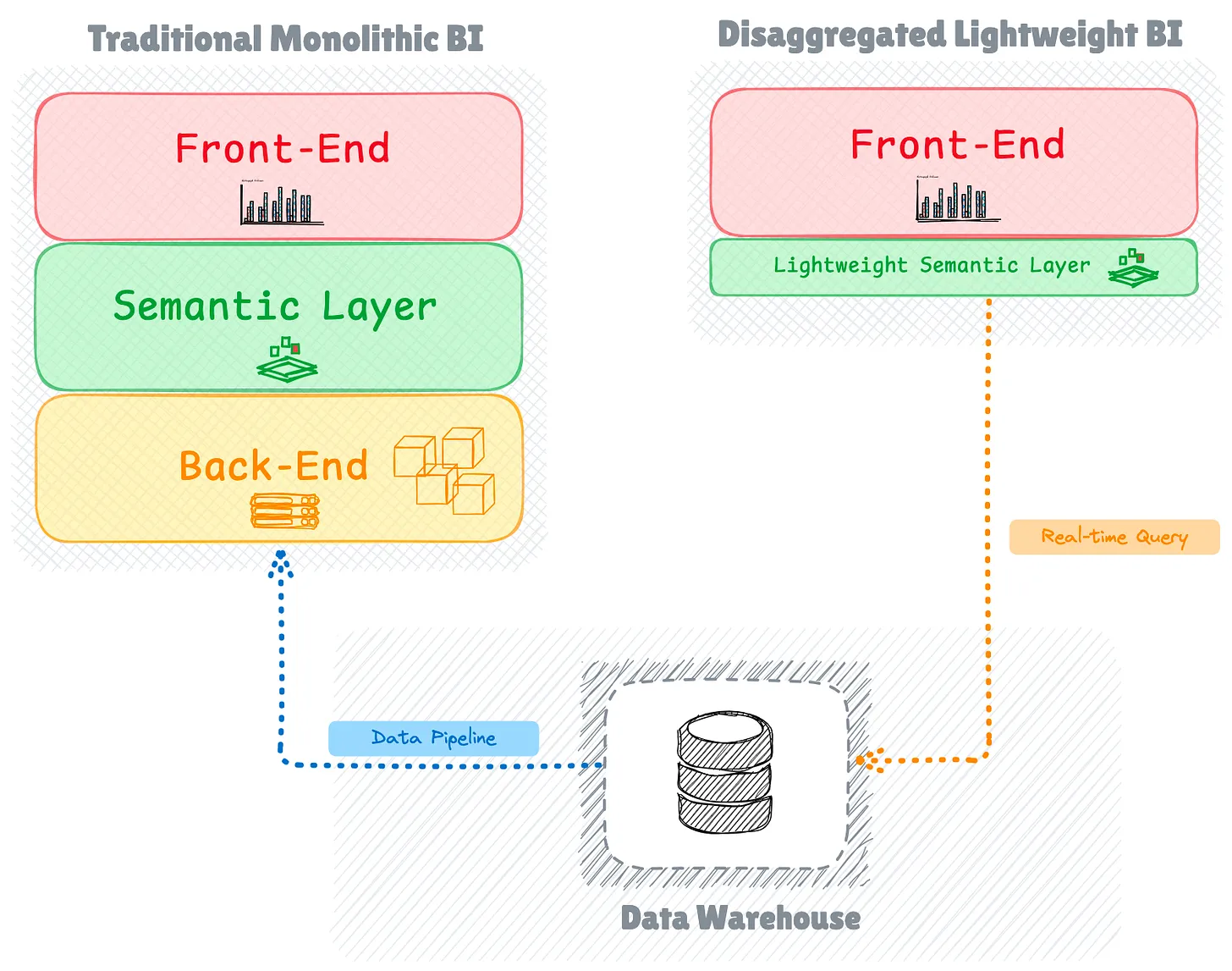
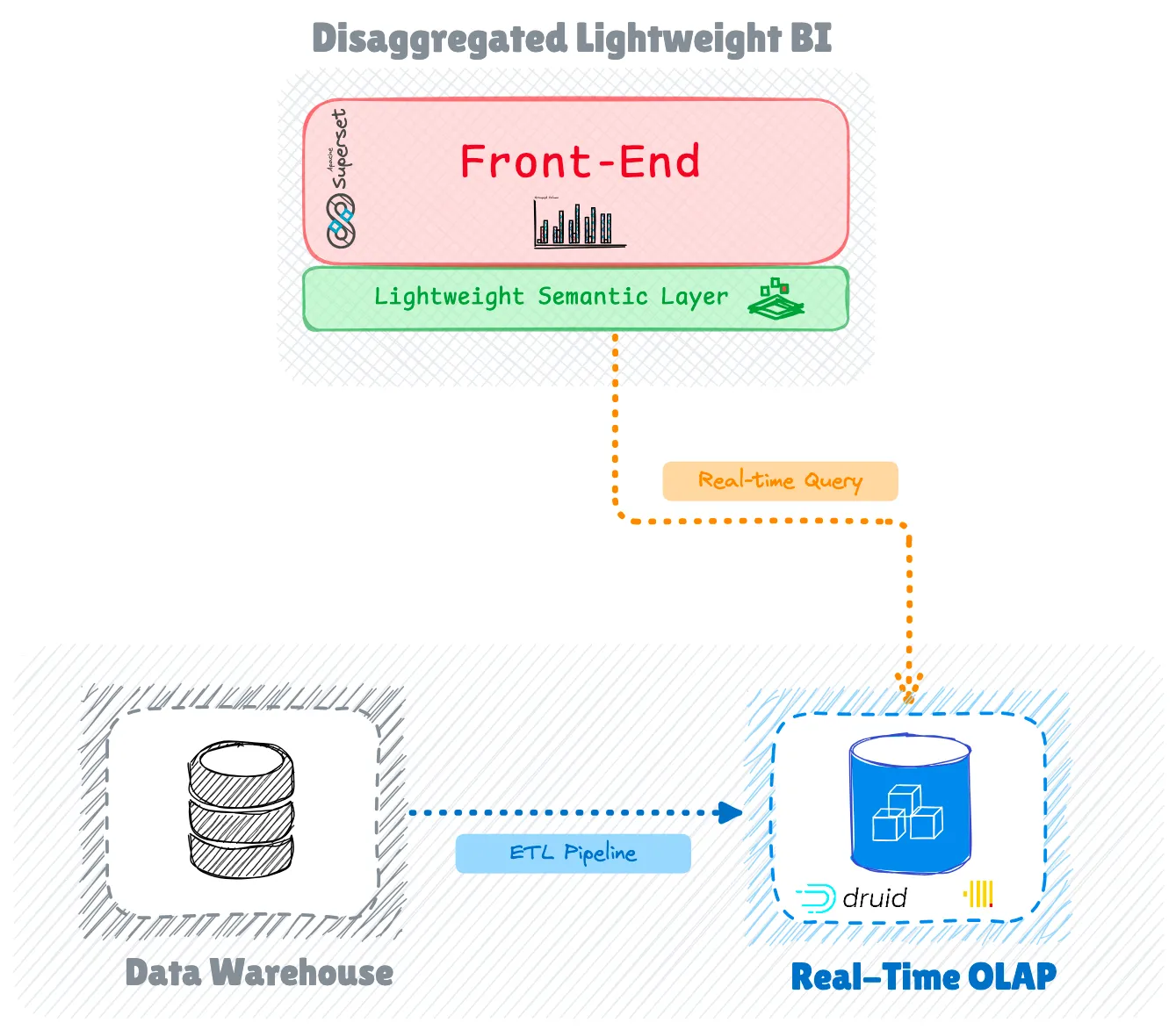
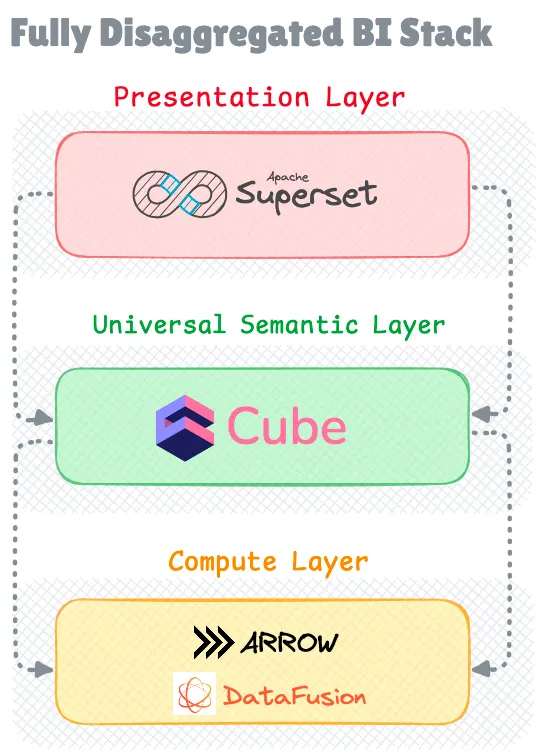
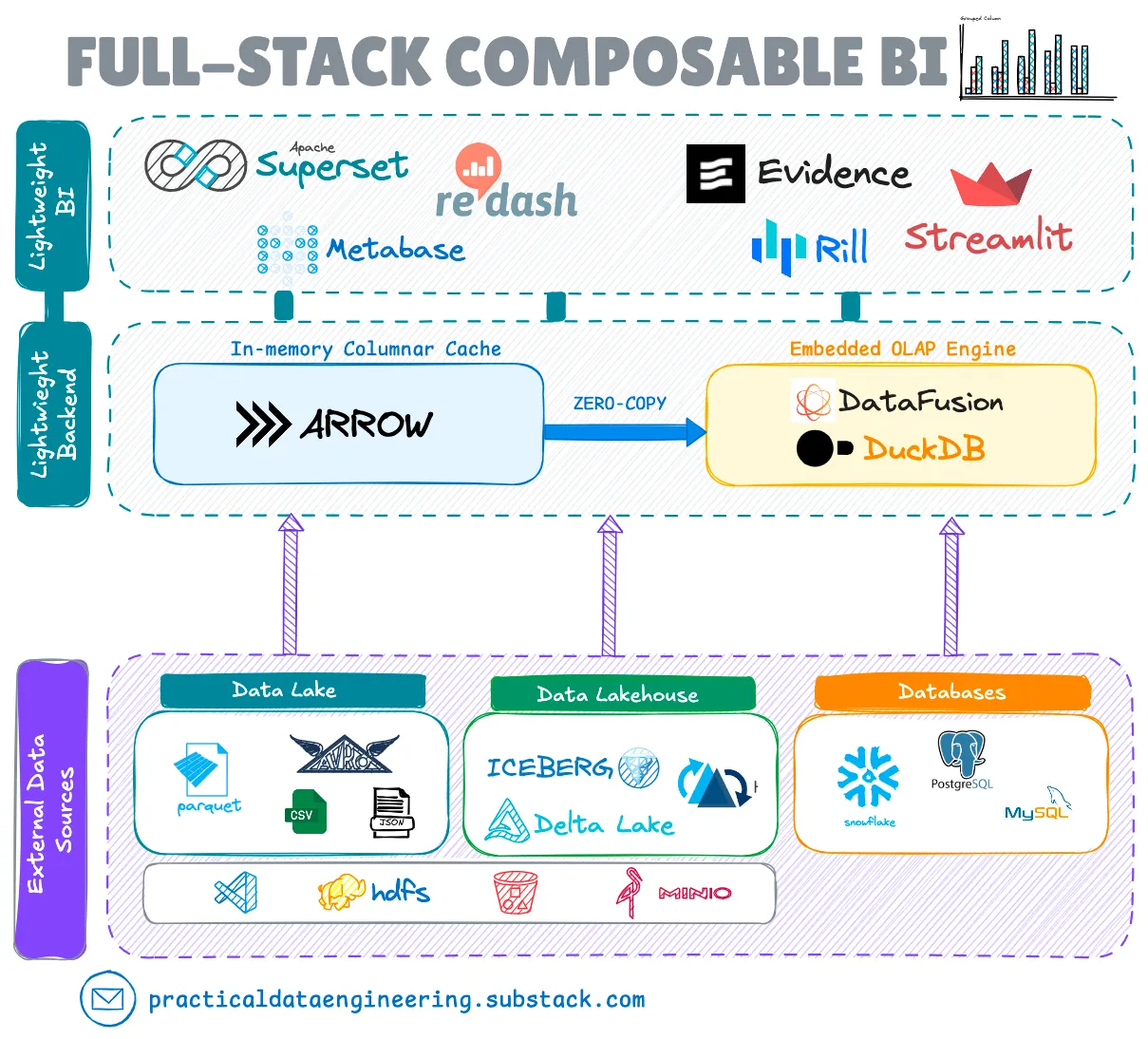
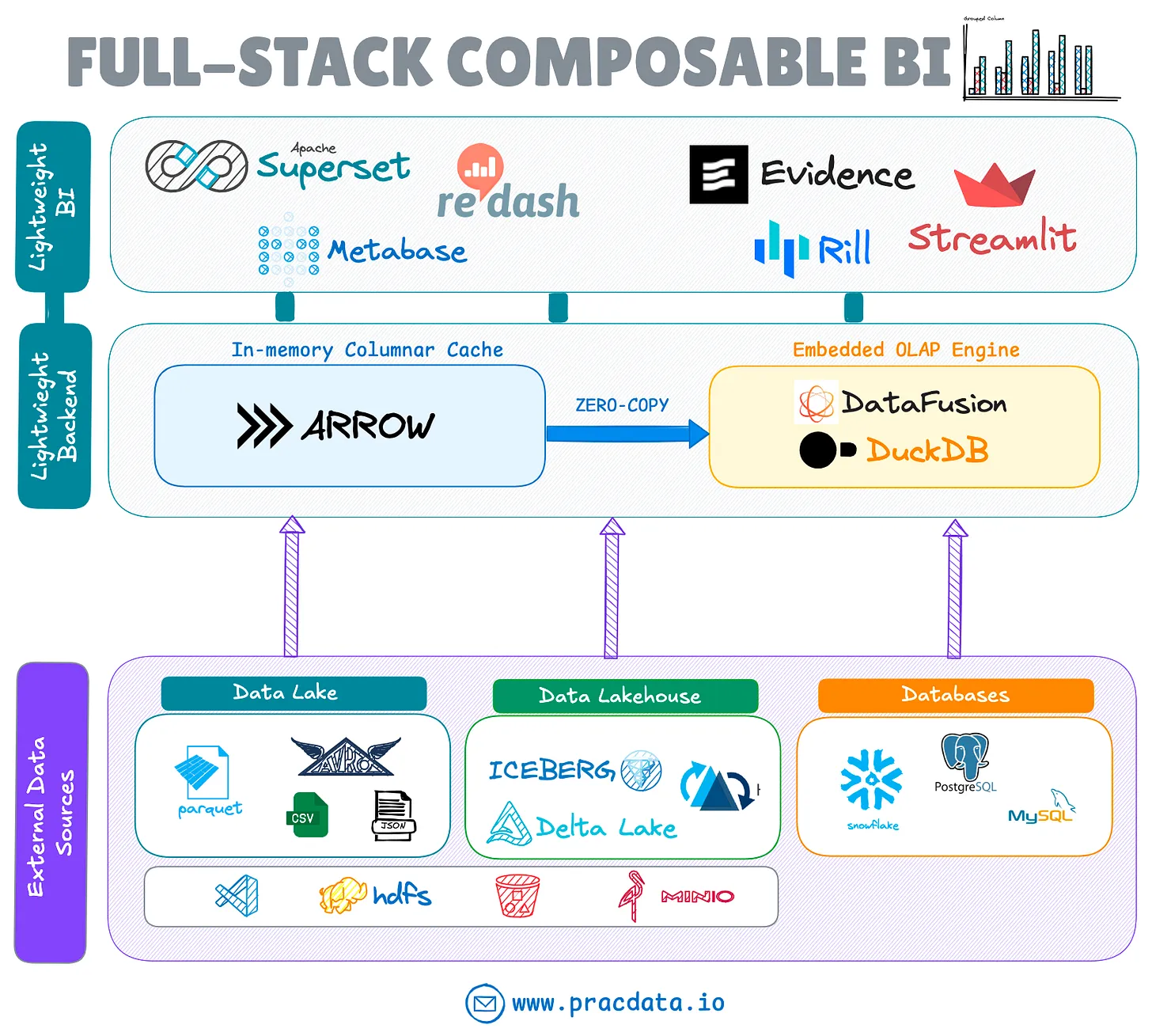
Компонуемый BI-стек
Эволюция декомпозиции систем не ограничивается системами хранения; она также повлияла на стеки бизнес-аналитики (BI). Появляется новая тенденция, которая сочетает в себе легкие, бездонные BI-инструменты (которые не имеют внутреннего сервера) с безголовыми встраиваемыми решениями OLAP, такими как Apache DataFusion, Apache Arrow и DuckDB.
Эта интеграция устраняет несколько пробелов в BI-стеке с открытым исходным кодом, таких как собственная способность запрашивать внешние озера данных и lakehouse, сохраняя при этом преимущества легких, дезагрегированных архитектур.
BI-продукты, такие как Omni, GoodData, Evidence и Rilldata, уже включили эти движки в свои BI-инструменты и инструменты исследования данных. Как Apache Superset (с использованием библиотеки duckdb-engine), так и Metabase теперь поддерживают встроенные подключения DuckDB.
Для всестороннего анализа развивающейся компонуемой BI-архитектуры см. подробное исследование в следующей статье: https://www.pracdata.io/p/the-evolution-of-business-intelligence-stack
Перевод тут https://gavrilov.info/all/evolyuciya-biznes-analitiki-ot-monolitnoy-k-komponuemoy-arhitekt/
MPP Query Engines
В пост-Hadoop эпоху было мало инноваций и внедрения новых систем MPP (массовой параллельной обработки) с открытым исходным кодом, в то время как существующие движки продолжают развиваться.
В то время как доля Hive сокращается, Presto и Trino по-прежнему остаются лучшими движками запросов MPP с открытым исходным кодом, используемыми в производстве, несмотря на жесткую конкуренцию со стороны Spark как унифицированного движка и управляемых облачных продуктов MPP, таких как Databricks, Snowflake и AWS Redshift Spectrum плюс Athena.
Перспективы на будущее и заключение
Экосистема данных с открытым исходным кодом вступает в фазу зрелости в таких ключевых областях, как lakehouse, которая характеризуется консолидацией вокруг проверенных технологий и повышенным вниманием к операционной эффективности.
Ландшафт продолжает развиваться в сторону облачных, компонуемых архитектур, стандартизируясь вокруг доминирующих технологий. Ключевые области, за которыми следует следить, включают:
- Дальнейшая консолидация в области открытых табличных форматов
- Продолжающаяся эволюция архитектур без дисков в системах реального времени и транзакционных системах
- Стремление к предоставлению унифицированного опыта lakehouse
- Подъем LLMOps и AI Engineering
- Расширение экосистемы lakehouse в таких областях, как интеграция открытых каталогов и разработка нативных библиотек
- Растущая популярность одноузловой обработки данных и встроенной аналитики