Распределенное машинное обучение с помощью Bacalhau Bluesky Bot
Распределенное машинное обучение с помощью Bacalhau Bluesky Bot
Использование моделей машинного обучения стало проще, чем когда-либо!
Шон М. Трейси
22 января 2025
Оригинал: https://blog.bacalhau.org/p/distributed-ml-with-the-bacalhau
Бот: https://github.com/bacalhau-project/bacalhau-bluesky-bot
---
Некоторое время назад мы выпустили Bacalhau Bluesky Bot (профиль Bluesky). Мы подумали, что это будет интересный способ показать людям, насколько просто интегрировать существующие приложения и сервисы с сетью Bacalhau, а также дать возможность пользователям запускать задачи.
Но Bacalhau Bot может делать гораздо больше, чем просто выполнять код и возвращать результаты. Мы решили продемонстрировать, как легко Bacalhau можно использовать для запуска моделей машинного обучения на любых доступных вычислительных ресурсах, и вот что у нас получилось!
Что он делает?
В первой версии Bacalhau Bluesky Bot вы могли запускать задачи, отправляя команды, как в Bacalhau CLI. Например:
```
@jobs.bacalhau.org job run
```
Мы сделали это так, чтобы люди, знакомые с CLI, сразу понимали, что можно делать с помощью бота, а те, кто никогда не использовал CLI, могли познакомиться с Bacalhau, не настраивая всю сеть.
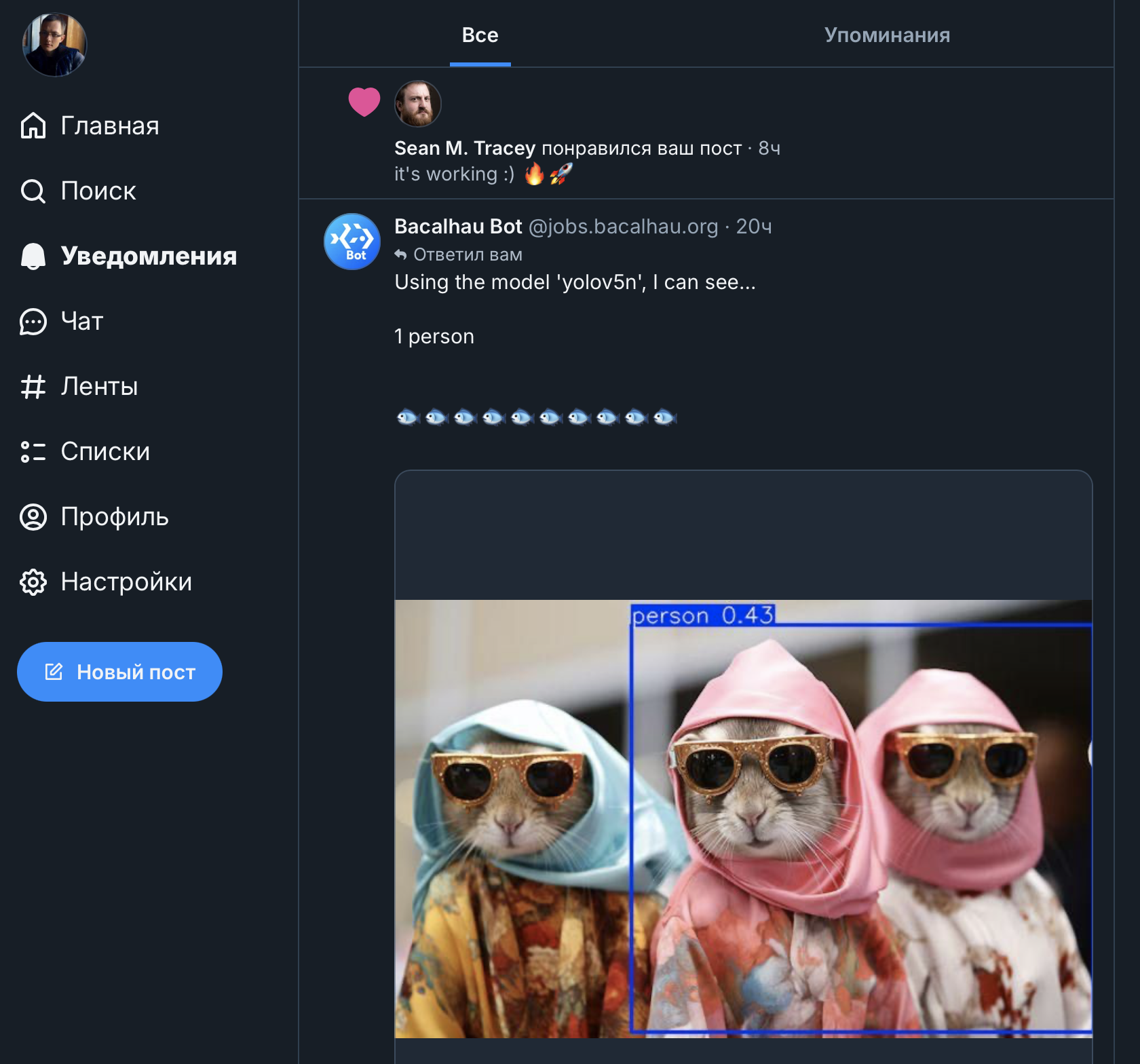
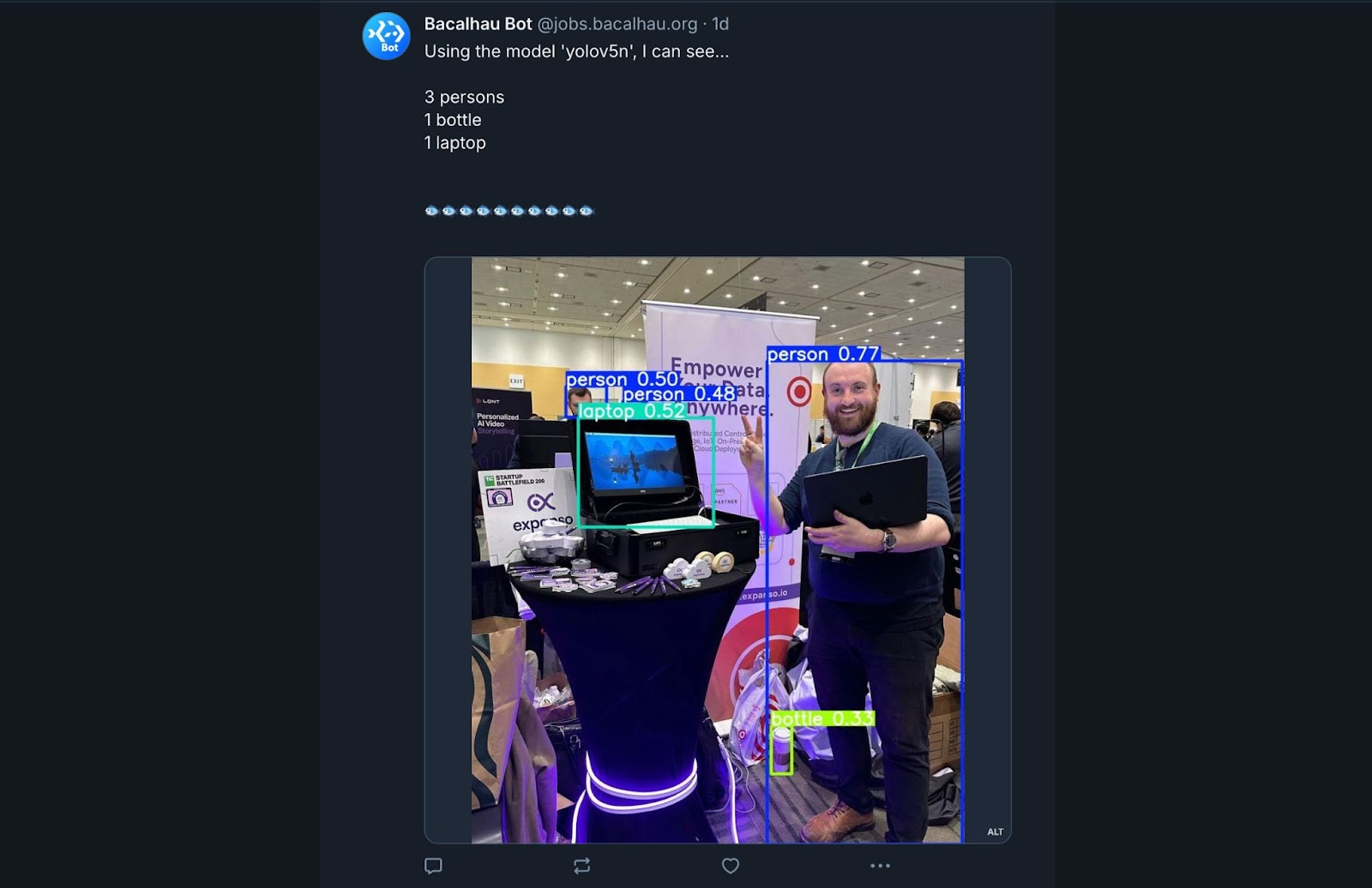
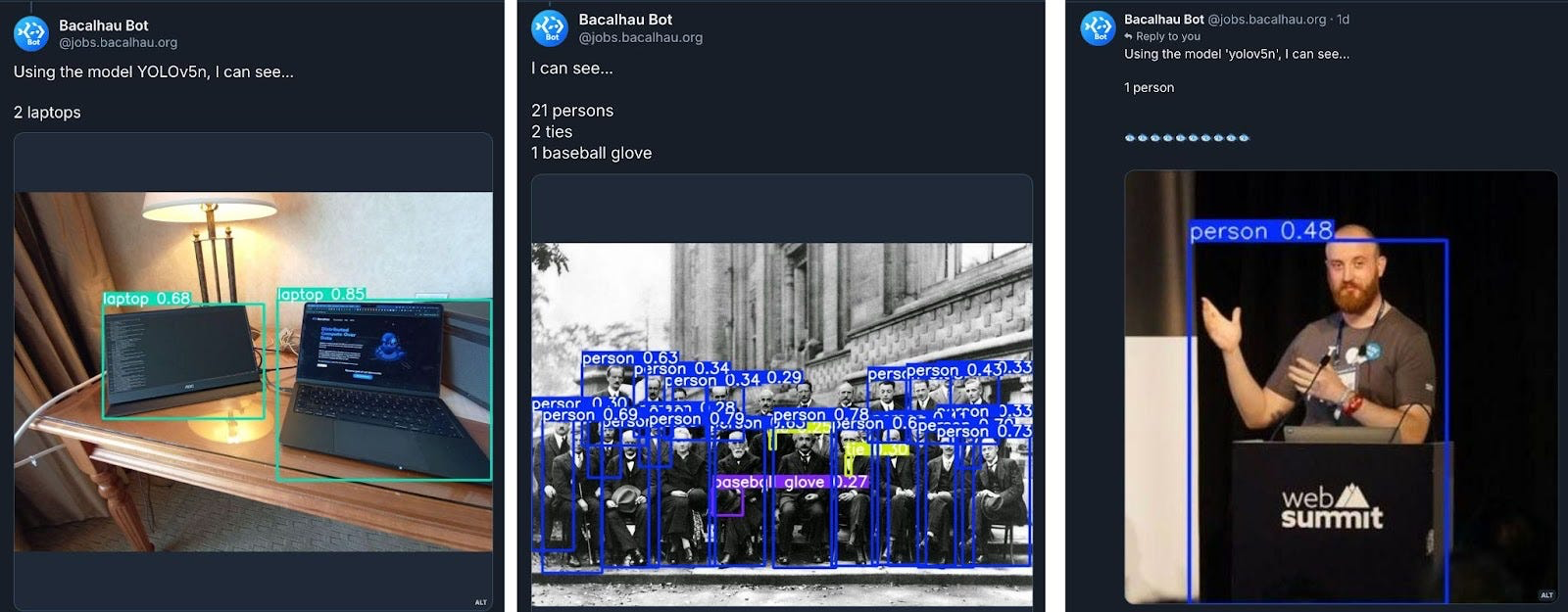
Теперь мы немного отошли от интерфейса CLI, чтобы показать более специализированные сценарии использования. Начиная с сегодняшнего дня, вы можете классифицировать любое изображение, отправив его Bacalhau Bluesky Bot с прикрепленной картинкой в посте. Bacalhau использует YOLO для обнаружения объектов на изображении и отправляет результат обратно — всё это занимает менее 30 секунд!
Как это работает?
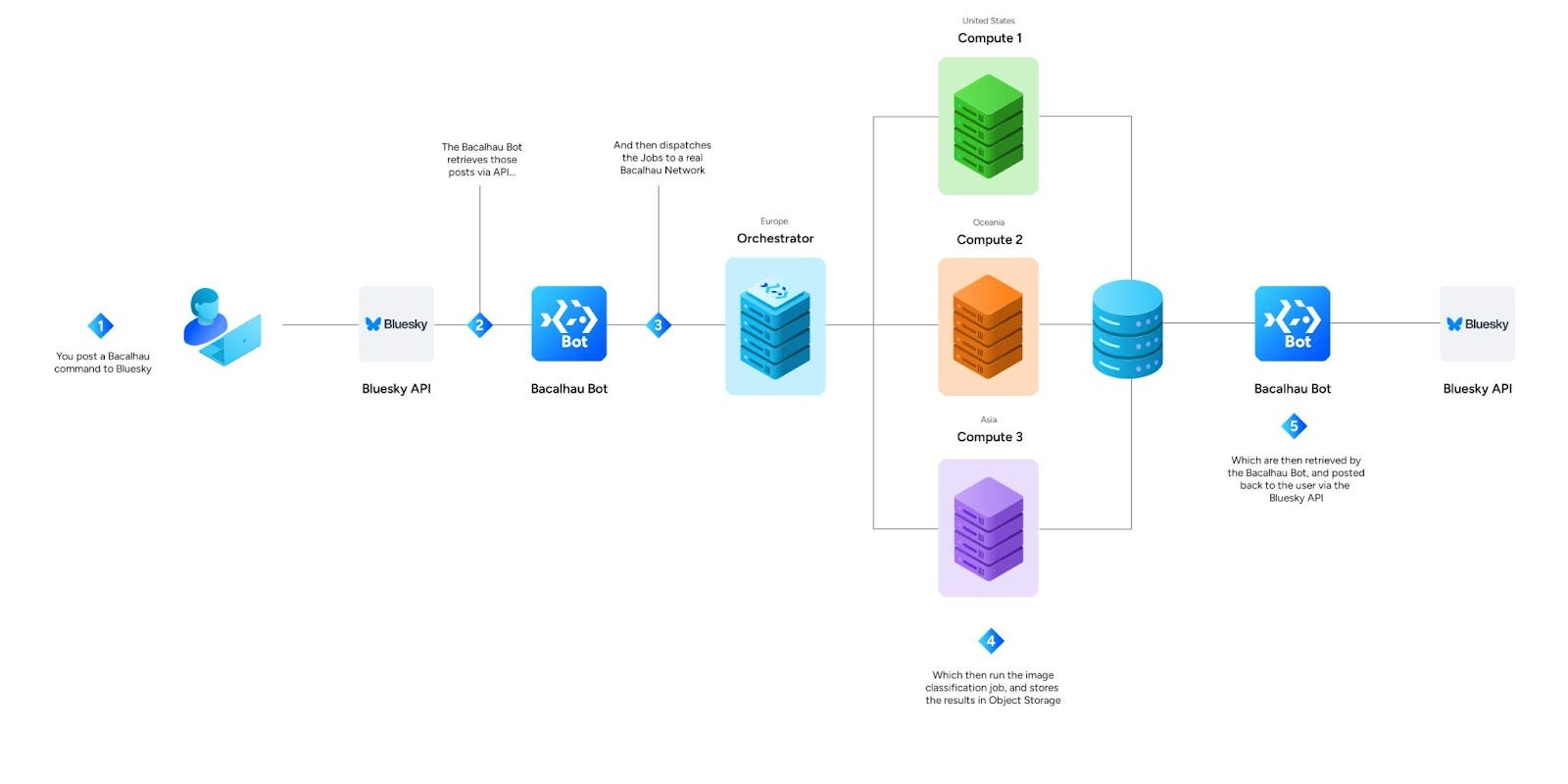
В принципе работы Bacalhau Bluesky Bot мало что изменилось, просто добавился код для обработки задач классификации и возврата результатов после их выполнения.
Когда вы отправляете изображение боту с командой:
```
@jobs.bacalhau.org classify
```
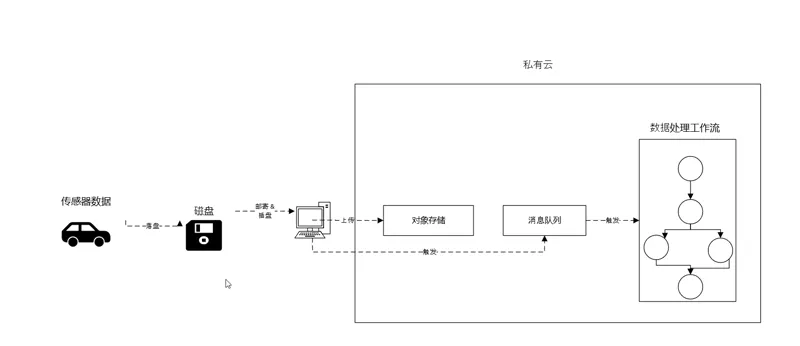
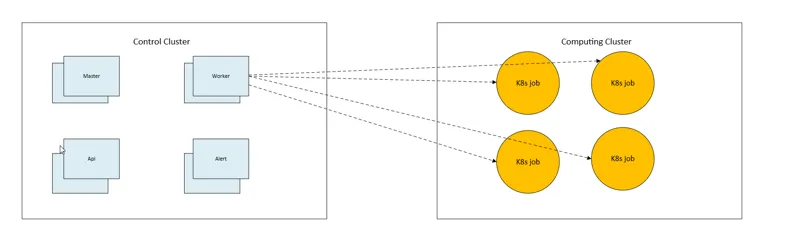
Бот читает ваш пост, получает URL изображения и отправляет задачу в сеть Bacalhau Bot Network. Эта сеть ничем не отличается от обычной сети Bacalhau, за исключением того, что взаимодействовать с ней можно только через Bacalhau Bluesky Bot.
Бот загружает шаблонный файл `job.yaml`, который указывает контейнер для выполнения задачи, и передает переменные для загрузки вашего изображения и его классификации.
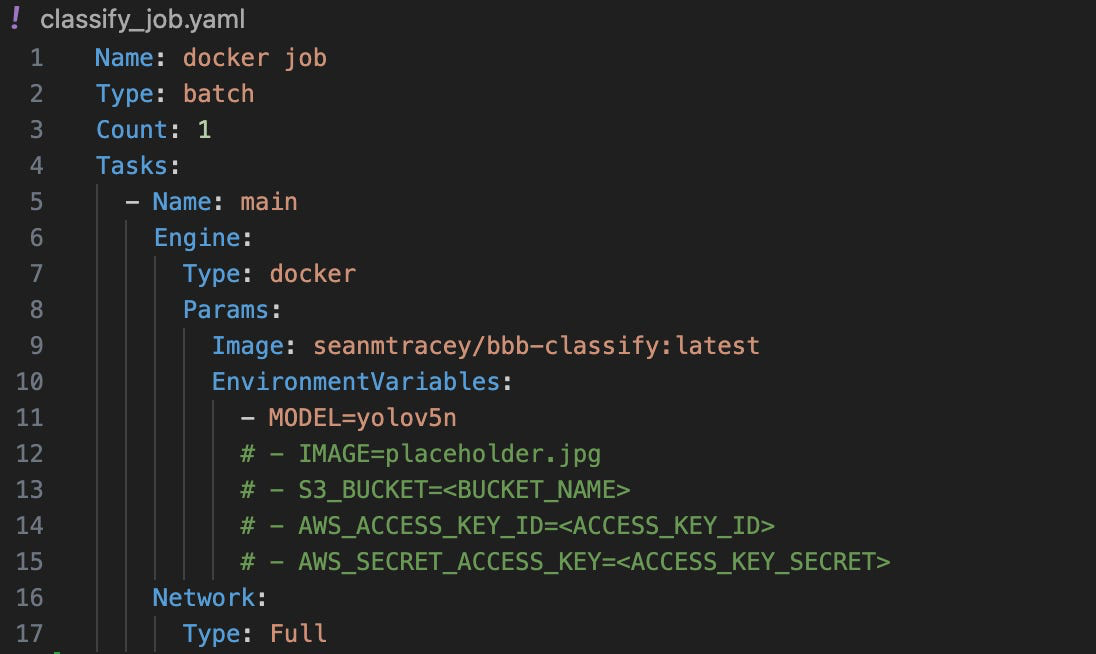
После загрузки YAML-файла он преобразуется в JSON и отправляется через API в оркестратор Bacalhau, который запускает задачу и возвращает ID задачи.
Оркестратор анализирует сеть и назначает задачу на любой доступный вычислительный узел.
Узел, получивший задачу, использует переменные окружения из `job.yaml`, чтобы загрузить изображение из CDN Bluesky, а затем применяет YOLO для классификации объектов на изображении.
Этот процесс занимает около 10 секунд — даже на машине без GPU. Это яркий пример того, насколько продвинулись модели машинного обучения за последние годы, позволяя выполнять сложные задачи на устройствах, которые раньше с этим не справлялись.
После классификации изображения наш код рисует ограничивающие рамки вокруг объектов на новом файле, отправляет его в хранилище объектов вместе с метаданными для последующего извлечения ботом и возвращает UUID, который бот использует для доступа к этим данным.
Пока всё это происходит, Bacalhau Bluesky Bot отслеживает задачу и через 30 секунд использует возвращенный UUID, чтобы получить классифицированное изображение и метаданные из общего хранилища объектов.
После этого бот использует API Bluesky, чтобы опубликовать ответ с метаданными и аннотированным изображением в ответ на исходный пост. И вуаля! Вы получаете результат работы распределенной системы машинного обучения прямо в уведомлениях Bluesky!
Попробуйте сами!
Эти изменения уже доступны! Просто зайдите в Bluesky под своим аккаунтом и отправьте пост:
```
@jobs.bacalhau.org classify
```
...с прикрепленным изображением, и мы предоставим вам результаты классификации менее чем за минуту!
Заключение
Мы создали Bacalhau Bluesky Bot, чтобы показать, насколько просто интегрировать продукты, приложения и платформы с Bacalhau. Если у вас есть идея, как можно использовать распределенные вычисления, дайте нам знать! Мы всегда рады услышать интересные и инновационные идеи, которые продвигают распределенные вычисления вперед!
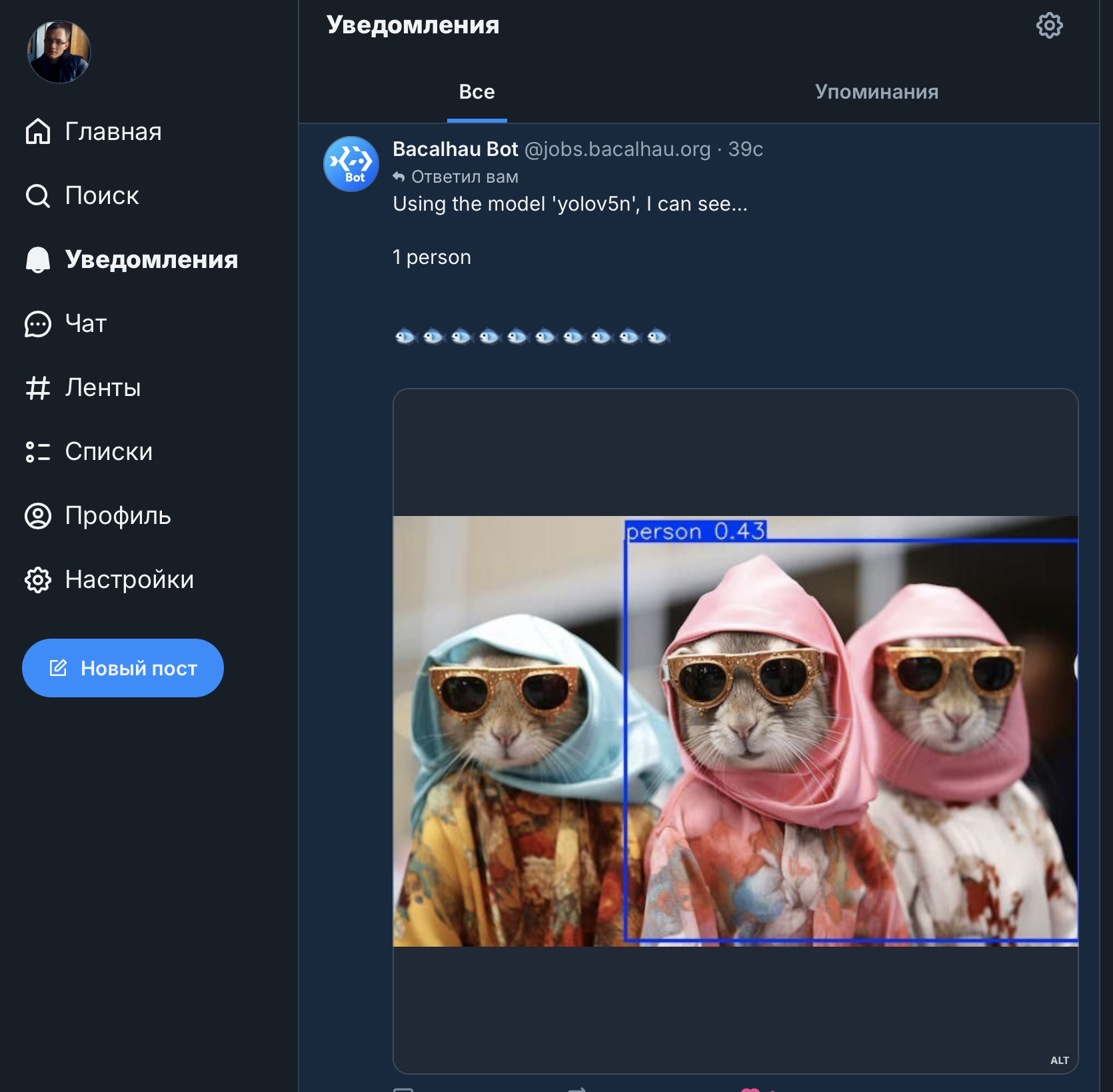
Работает :)
@jobs.bacalhau.org classify
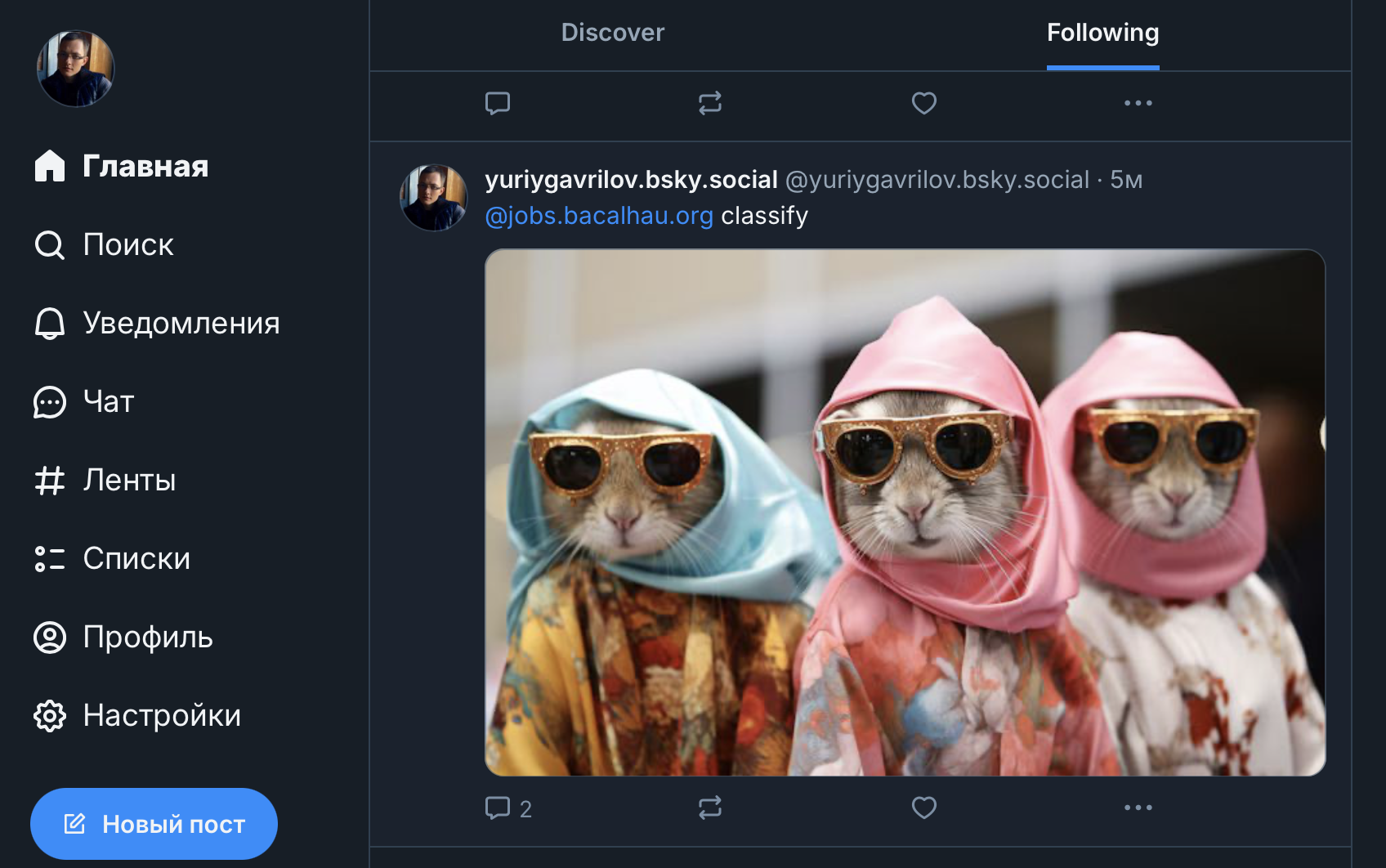
и даже так :)