Новые архитектуры современной инфраструктуры данных: a16z
Источник: Emerging Architectures for Modern Data Infrastructure
Авторы: Matt Bornstein, Jennifer Li, and Martin Casado
PDF: Тут
Индустрия инфраструктуры данных продолжает стремительно развиваться. С момента публикации первой версии эталонных архитектур в 2020 году, на рынке появилось множество новых продуктов, а метрики ключевых компаний достигли рекордных высот. Эта статья представляет собой обновленный анализ ключевых архитектурных шаблонов и трендов, основанный на опыте ведущих специалистов в области данных.
Основная гипотеза заключается в том, что, хотя ядро систем обработки данных осталось относительно стабильным, вокруг него произошел “Кембрийский взрыв” — стремительное размножение поддерживающих инструментов и приложений. Это явление можно объяснить формированием настоящих платформ данных, которые становятся фундаментом для новой экосистемы.
Обновленные эталонные архитектуры
Статья предлагает два общих взгляда на современный стек данных.
1. Единая инфраструктура данных (Unified Data Infrastructure 2.0)
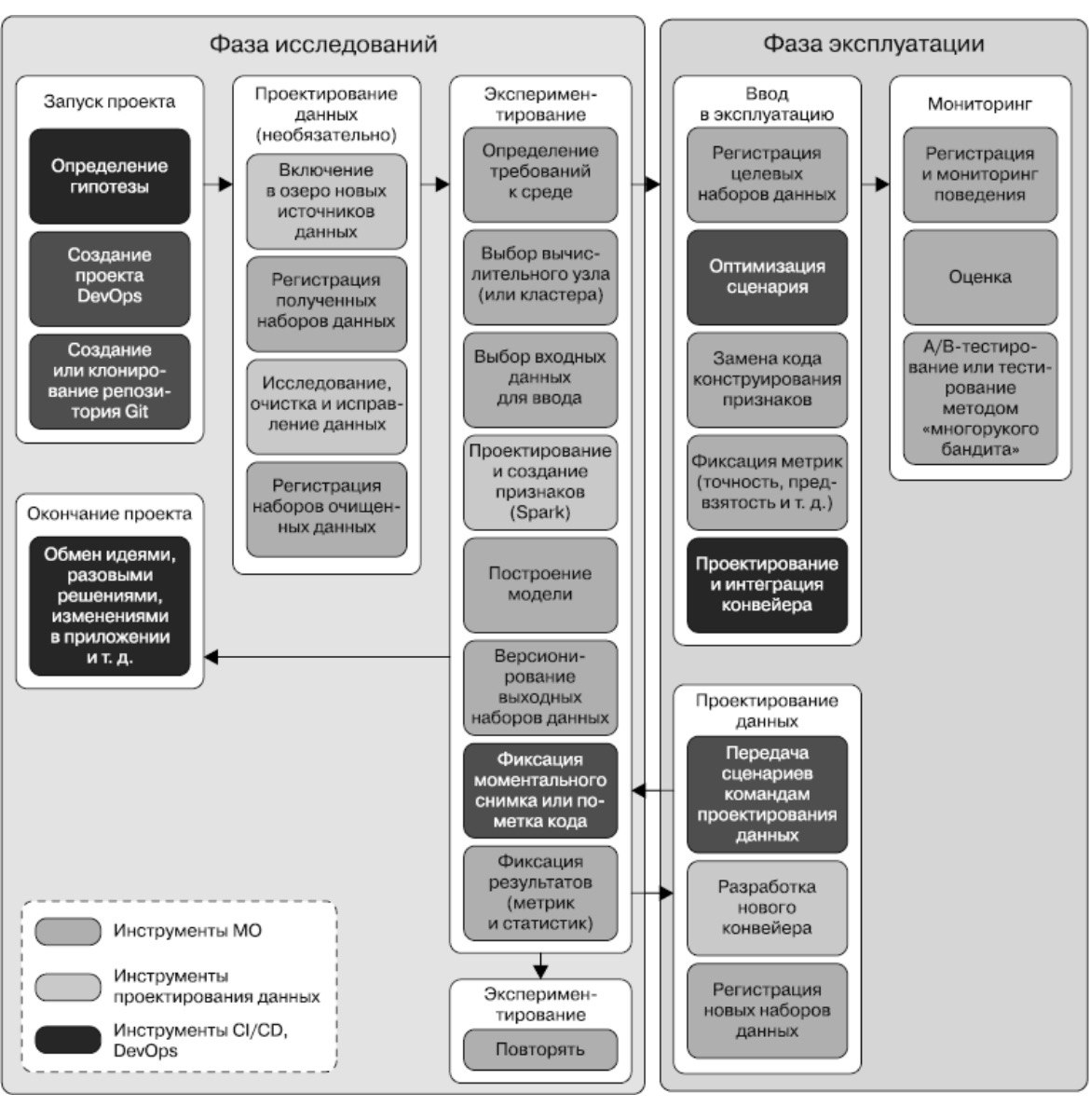
Эта схема дает комплексное представление о стеке данных, охватывая все основные варианты использования — от аналитики до операционных систем.
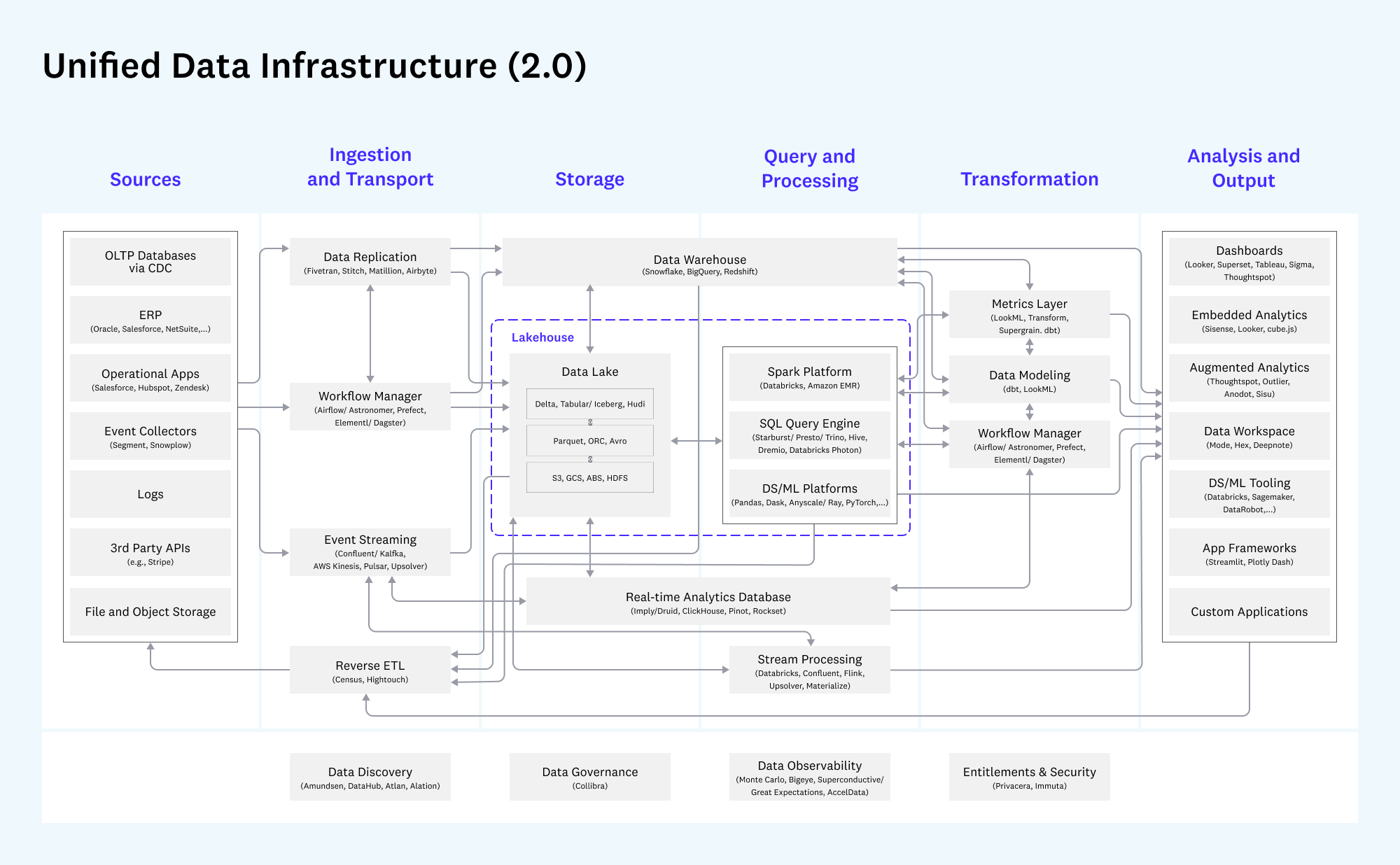
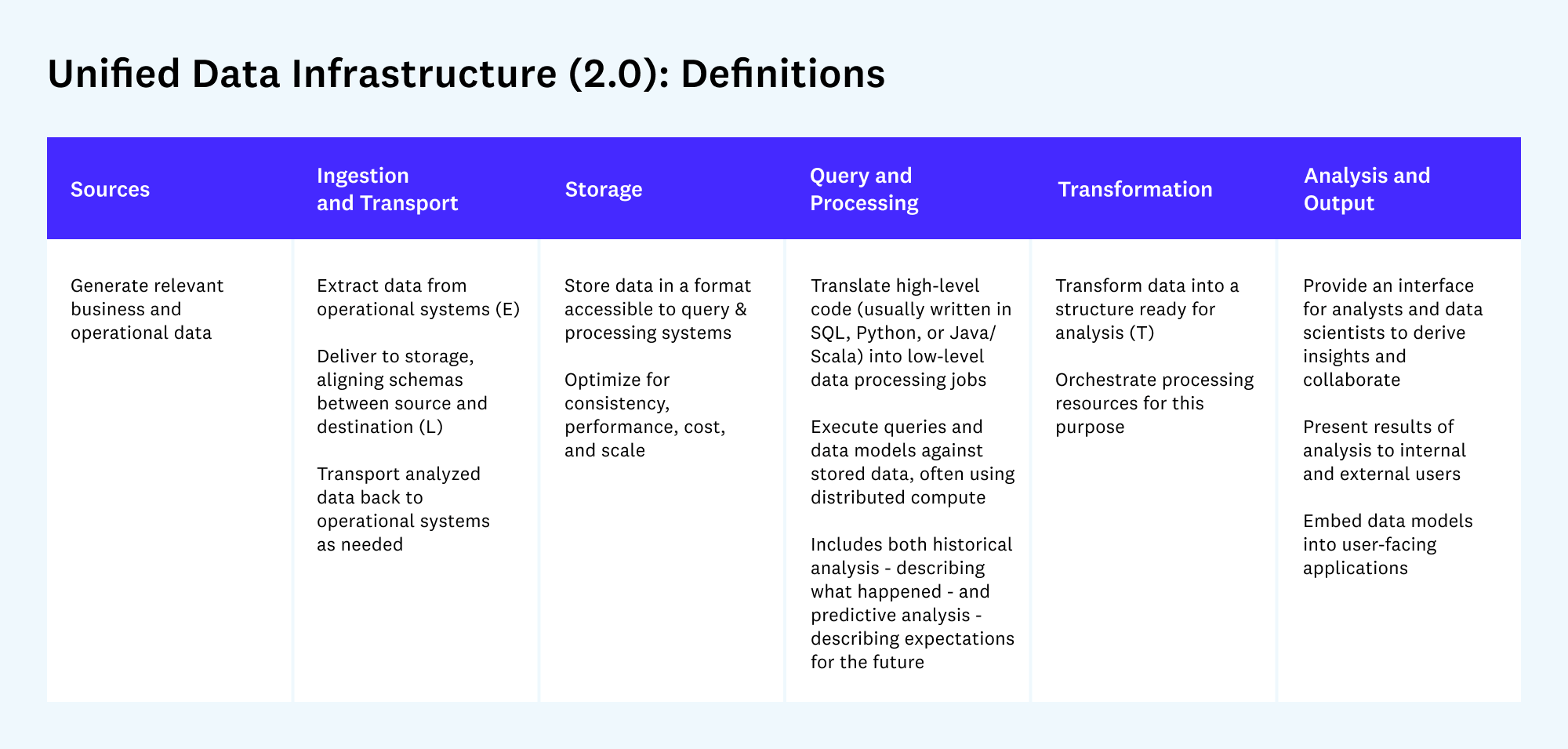
Схема демонстрирует путь данных от источников (`Sources`) через этапы загрузки и транспортировки (`Ingestion and Transport`), хранения (`Storage`), обработки запросов (`Query and Processing`), трансформации (`Transformation`) до конечного анализа и вывода (`Analysis and Output`).
2. Инфраструктура для машинного обучения (Machine Learning Infrastructure 2.0)
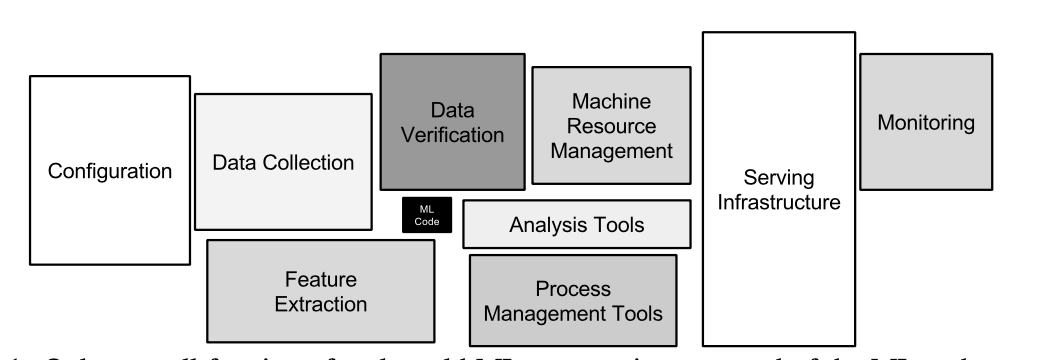
Вторая схема подробно рассматривает сложную и все более независимую цепочку инструментов для машинного обучения.
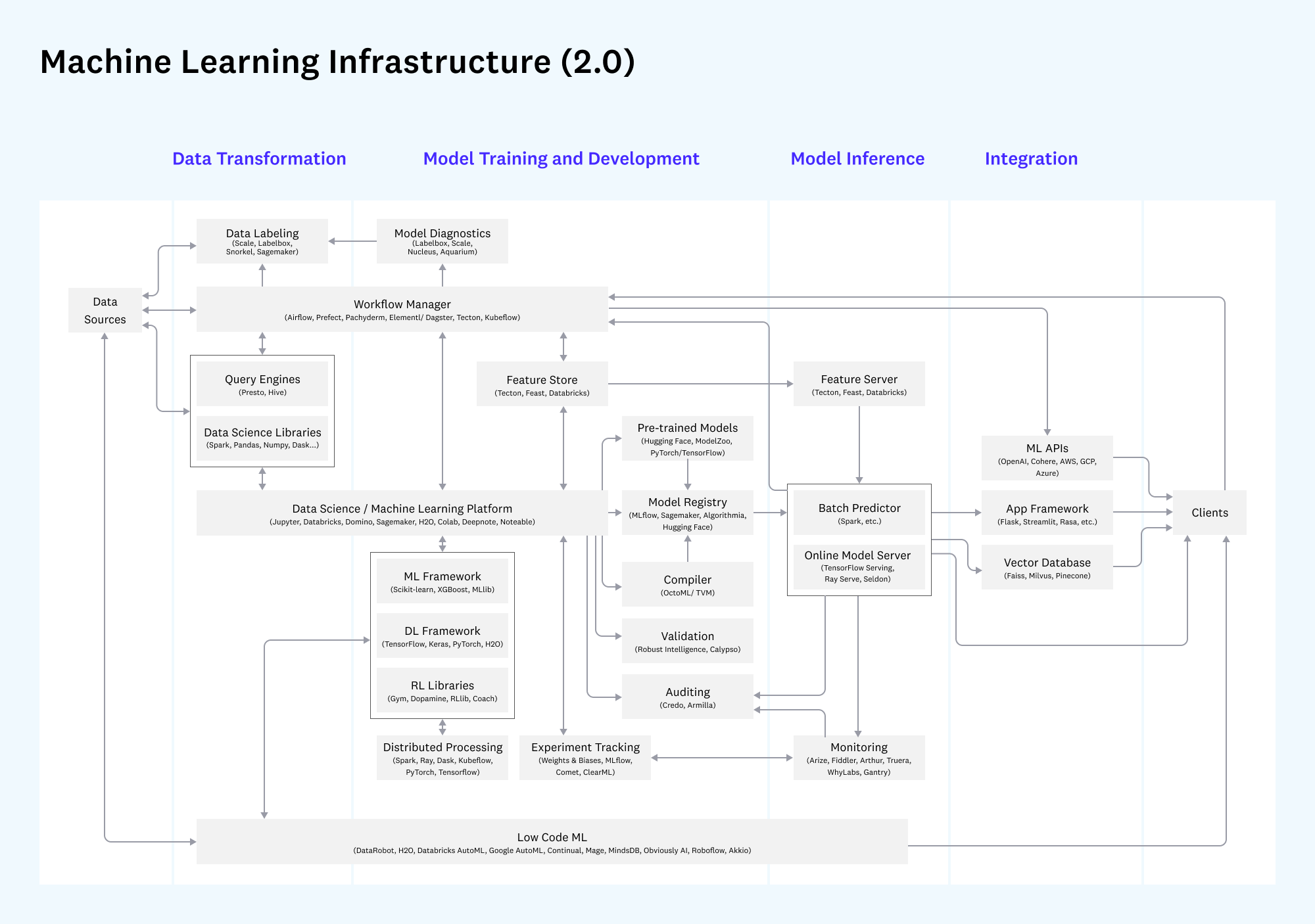

Здесь показан жизненный цикл ML-модели: от трансформации данных и разработки модели (`Data Transformation`, `Model Training and Development`) до ее развертывания (`Model Inference`) и интеграции в конечные продукты (`Integration`).
Что изменилось? Стабильное ядро и “Кембрийский взрыв”
Что не изменилось: стабильность в ядре
Несмотря на активное развитие рынка, базовые архитектурные паттерны сохранили свою актуальность. По-прежнему существует разделение между:
- Аналитическими системами (Analytic Systems), которые помогают принимать решения на основе данных (`data-driven decisions`).
- Операционными системами (Operational Systems), которые являются основой для продуктов, использующих данные (`data-powered products`).
Ключевые технологии в ядре стека доказали свою устойчивость и продолжают доминировать:
- В аналитике связка `Fivetran` (для репликации данных), `Snowflake`/`BigQuery` (облачные хранилища данных) и `dbt` (для SQL-трансформаций) стала почти стандартом де-факто.
- В операционных системах укрепились такие стандарты, как `Databricks`/`Spark`, `Confluent`/`Kafka` и `Airflow`.
Что нового: “Кембрийский взрыв”
Вокруг стабильного ядра наблюдается бурный рост новых инструментов и приложений, которые можно разделить на две категории:
- Новые инструменты для поддержки ключевых процессов обработки данных:
- Data Discovery: Каталоги данных для поиска и понимания имеющихся активов (`Amundsen`, `DataHub`, `Atlan`).
- Data Observability: Инструменты для мониторинга состояния и качества конвейеров данных (`Monte Carlo`, `Bigeye`).
- ML Model Auditing: Решения для аудита и валидации ML-моделей.
- Новые приложения для извлечения ценности из данных:
- Data Workspaces: Интерактивные среды для совместной работы аналитиков и Data Scientist’ов (`Mode`, `Hex`, `Deepnote`).
- Reverse ETL: Сервисы, которые возвращают обогащенные данные из хранилища обратно в операционные системы (CRM, ERP), такие как `Census` и `Hightouch`.
- ML Application Frameworks: Фреймворки для создания приложений на основе ML-моделей (`Streamlit`).
Три основных архитектурных шаблона (Blueprints)
Шаблон 1: Современная Business Intelligence (BI)
Этот шаблон предназначен для компаний любого размера, которые строят облачную BI-аналитику.
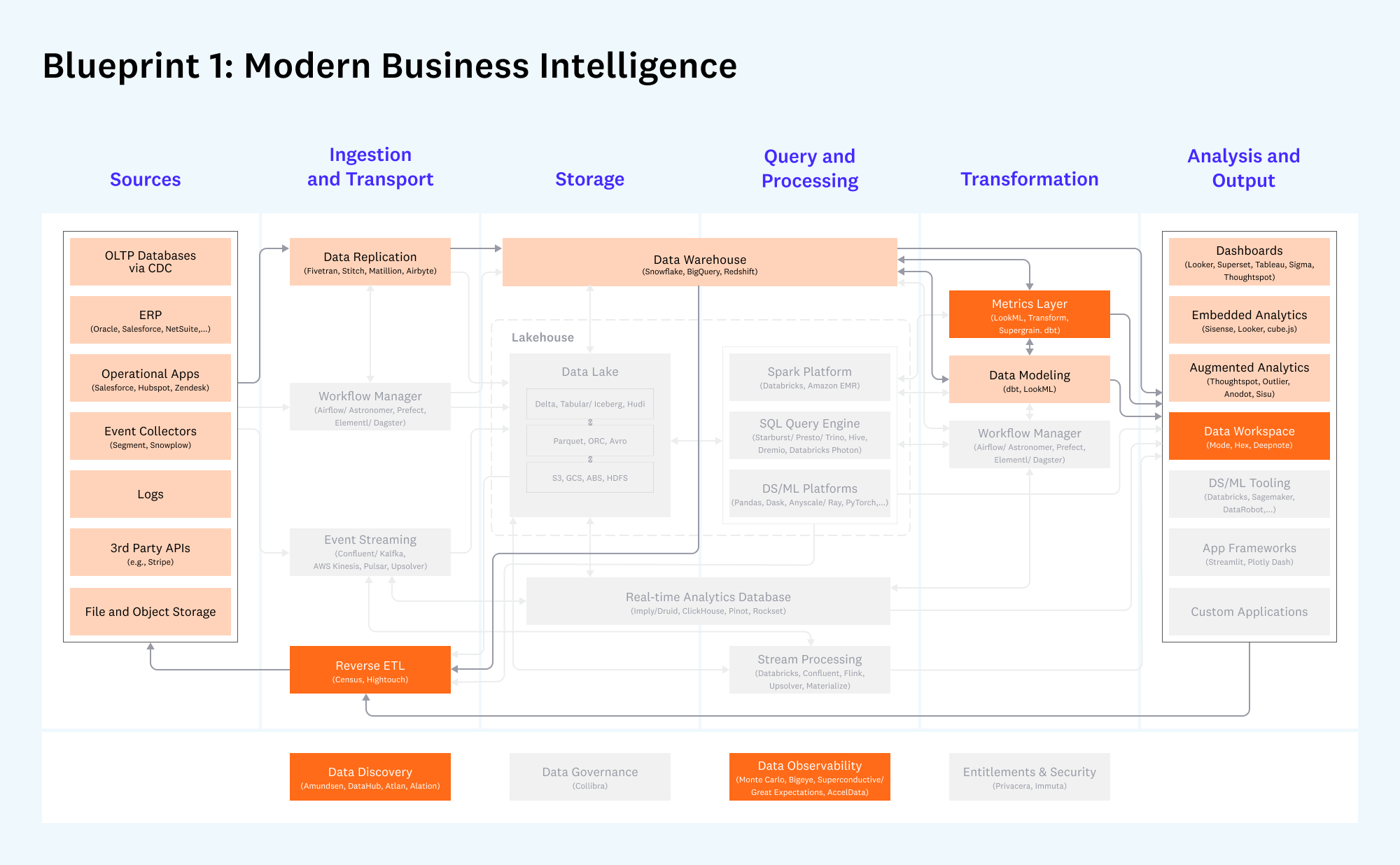
- Что не изменилось: Основой по-прежнему является комбинация репликации данных (`Fivetran`), облачного хранилища (`Snowflake`) и SQL-моделирования (`dbt`). Дашборды (`Looker`, `Tableau`, `Superset`) остаются главным инструментом анализа.
- Что нового:
- Metrics Layer: Появился активный интерес к слою метрик — системе, которая предоставляет стандартизированные бизнес-определения поверх хранилища данных (`Transform`, `LookML`). `dbt` также движется в этом направлении. ( dbt кстати открыла в общий доступ свои метрики тут
- Reverse ETL: Этот инструмент позволяет операционализировать аналитику, отправляя результаты (например, скоринг лидов) из хранилища напрямую в `Salesforce` или `Hubspot`. ( теперь мы знаем как эта штука называется по-модному, когда кто-то просит excele’чку всунуть к табличке рядышком :) )
- Data Workspaces: Новые приложения для более гибкого и глубокого анализа, чем стандартные дашборды.
Шаблон 2: Мультимодальная обработка данных
Этот шаблон развивает концепцию “озера данных” (`Data Lake`) для поддержки как аналитических, так и операционных задач. Часто используется компаниями, которые “мигрировали” с `Hadoop`.
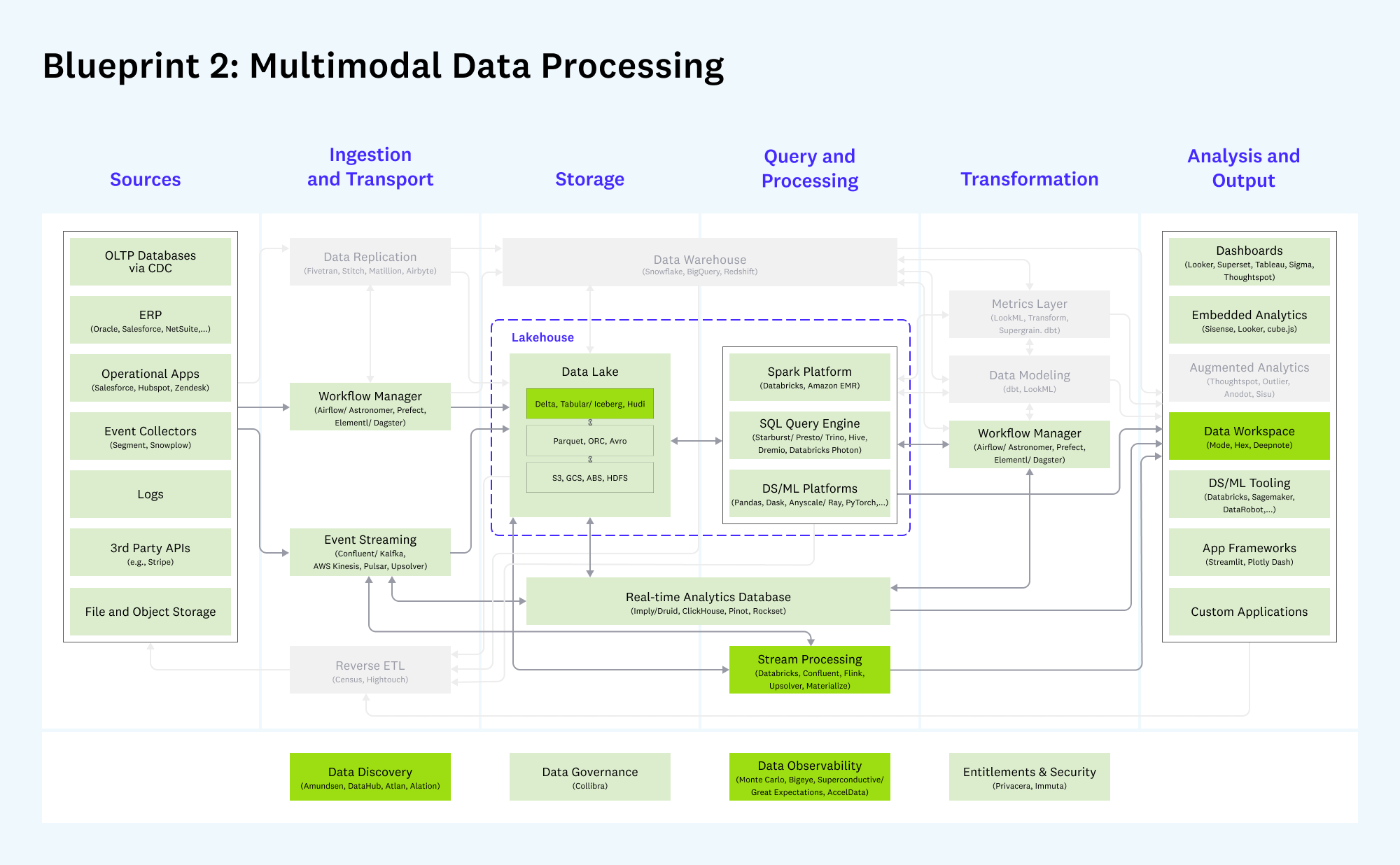
- Что не изменилось: Ядром остаются системы обработки (`Databricks`, `Starburst`), транспортировки (`Confluent`, `Airflow`) и хранения (`AWS S3`).
- Что нового:
- Архитектура Lakehouse: Получила широкое признание концепция `Lakehouse` — гибрид, объединяющий гибкость озера данных и производительность/управляемость хранилища данных. Она позволяет использовать поверх одного и того же хранилища (`S3`) множество движков: `Spark`, `Presto`, `Druid`/`ClickHouse` и др.
- Форматы хранения: Быстрое распространение получают открытые табличные форматы, такие как `Delta Lake`, `Apache Iceberg` и `Apache Hudi`, которые привносят транзакционность и надежность в озера данных.
- Stream Processing: Растет популярность потоковой обработки данных в реальном времени. Появляются новые, более простые в использовании инструменты (`Materialize`, `Upsolver`), а существующие (`Databricks Streaming`, `Confluent`/`ksqlDB`) наращивают функциональность.
Шаблон 3: Искусственный интеллект и машинное обучение (AI/ML)
Стек для разработки, тестирования и эксплуатации ML-моделей.
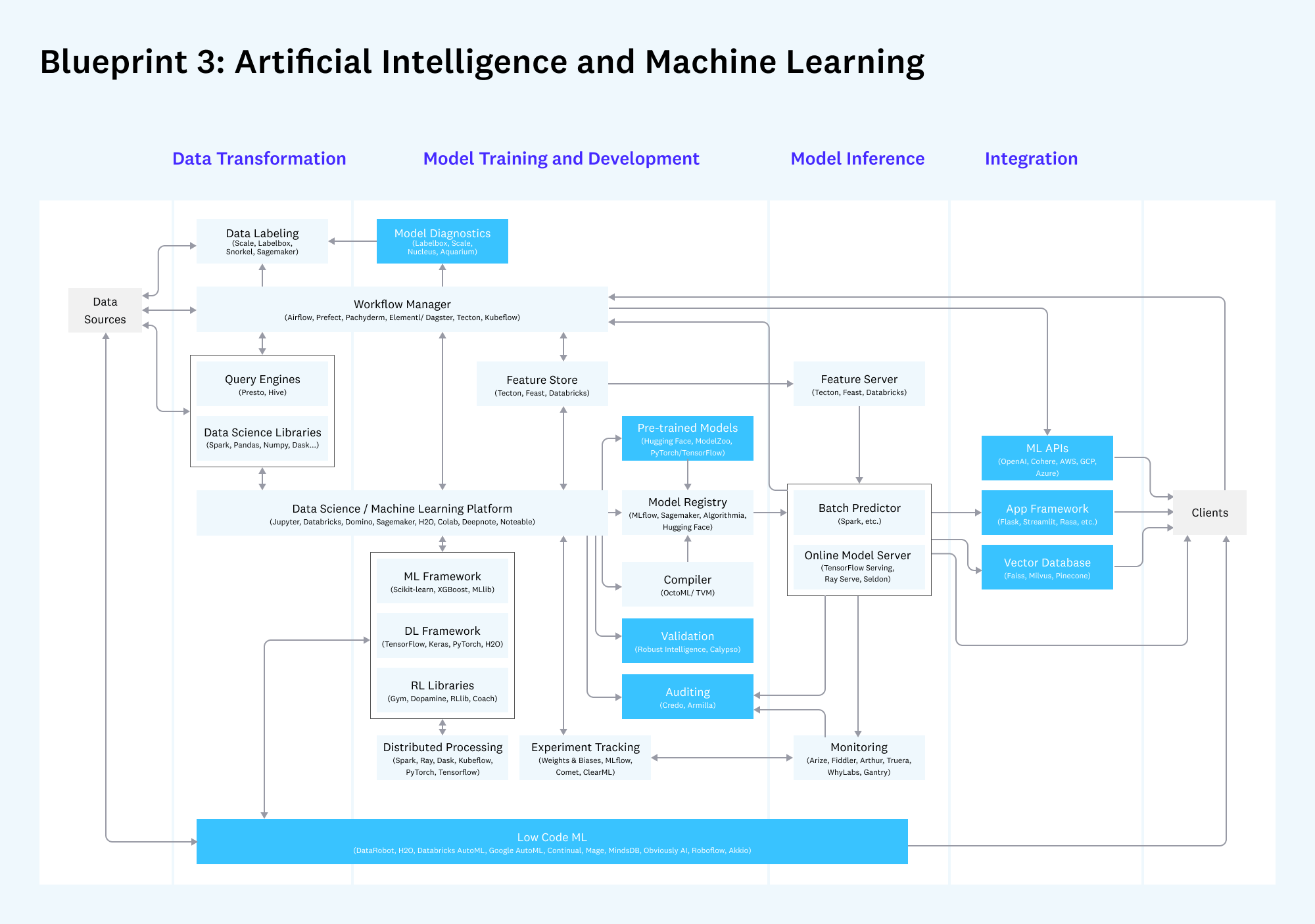
- Что не изменилось: Инструменты для разработки моделей в целом остались прежними: облачные платформы (`AWS Sagemaker`, `Databricks`), ML-фреймворки (`PyTorch`, `XGBoost`) и системы для отслеживания экспериментов (`Weights & Biases`, `Comet`).
- Что нового:
- Data-Centric AI: Произошел сдвиг парадигмы в сторону подхода, ориентированного на данные. Вместо бесконечного улучшения кода модели, фокус сместился на улучшение качества и управления данными для обучения. Это привело к росту сервисов разметки данных (`Scale AI`, `Labelbox`).
- Feature Stores: Увеличилось внедрение хранилищ признаков (`Tecton`, `Feast`) для совместной разработки и использования ML-признаков в production.
- Pre-trained Models: Использование предобученных моделей (особенно в NLP) стало стандартом. Компании, как `OpenAI` и `Hugging Face`, играют здесь ключевую роль.
- MLOps: Инструменты для эксплуатации моделей стали более зрелыми, особенно в области мониторинга (`Arize`, `Fiddler`) на предмет деградации качества и дрифта данных.
Гипотеза о “платформе данных”
Ключевая идея статьи — объяснить наблюдаемые изменения через формирование платформ данных.
В широком смысле, платформа — это то, на чем могут строить свои продукты другие разработчики. Определяющей чертой является взаимная зависимость между поставщиком платформы и большим пулом сторонних разработчиков.
Применительно к данным, “бэкенд” стека (загрузка, хранение, обработка) консолидируется вокруг небольшого числа облачных вендоров. Эти вендоры (`Snowflake`, `Databricks`) активно инвестируют в то, чтобы сделать данные легкодоступными для других через стандартные интерфейсы (например, SQL).
В свою очередь, “фронтенд” разработчики пользуются этим, создавая множество новых приложений поверх единой точки интеграции, не беспокоясь о сложностях базовой инфраструктуры. Это приводит к появлению нового класса `warehouse-native` (или `lakehouse-native`) приложений, которые работают непосредственно с данными клиента в его хранилище.
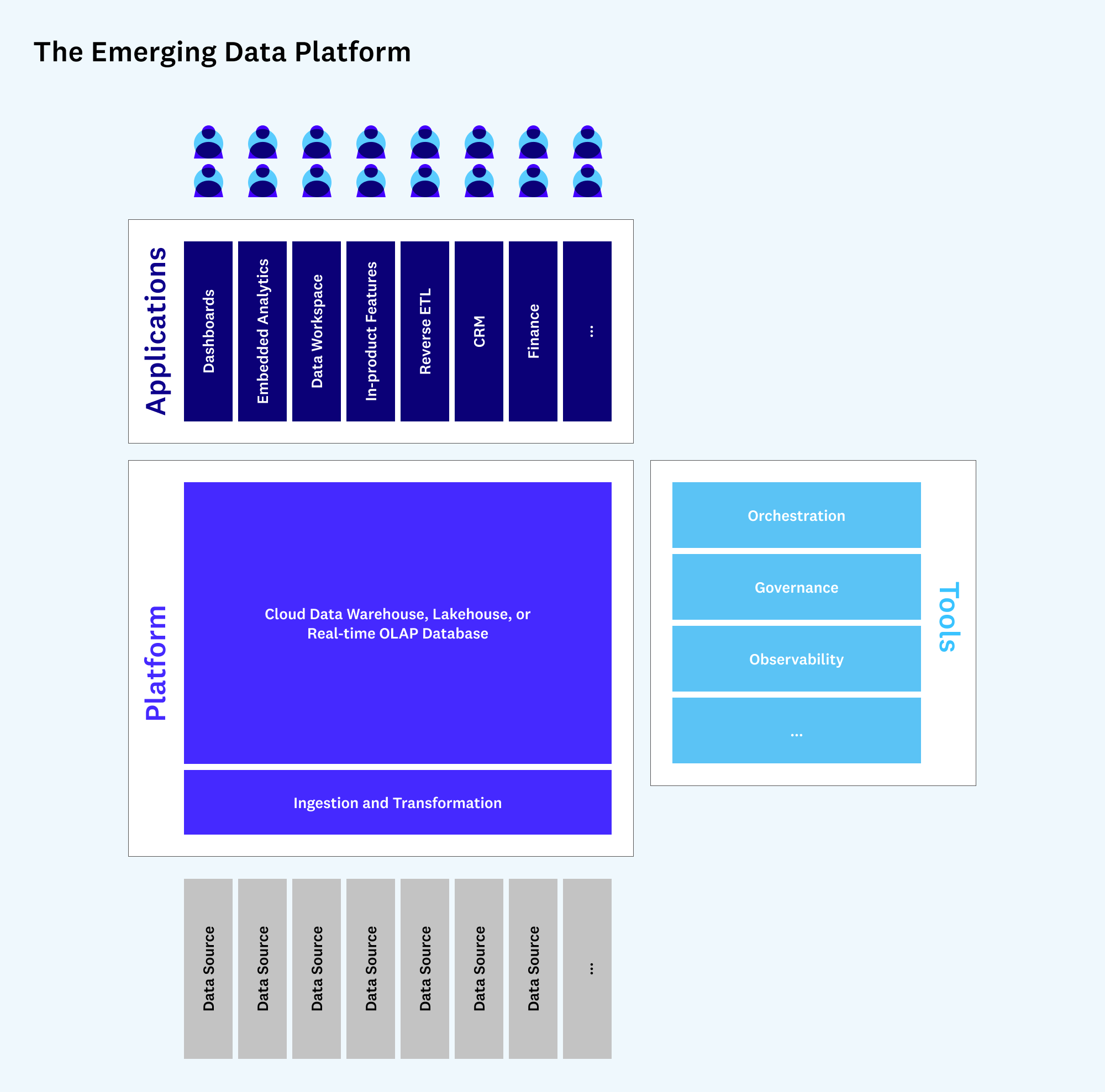
Эта модель объясняет, почему поставщики ядра данных (`Snowflake`, `Databricks`) так высоко ценятся (они борются за долгосрочную позицию платформы) и почему наблюдается взрывной рост в экосистеме инструментов (`Reverse ETL`, `Metrics Layer`) — они становятся важными компонентами, встроенными в эту новую платформенную архитектуру.
Итог и акценты в трендах
- Стабилизация ядра и консолидация. Ключевые компоненты стека (хранилище/озеро, движки обработки) консолидируются вокруг нескольких крупных игроков, которые становятся де-факто стандартами.
- Взрывной рост экосистемы. Вокруг стабильного ядра формируется богатая экосистема вспомогательных инструментов (`observability`, `discovery`) и бизнес-приложений (`reverse ETL`, `workspaces`), которые повышают ценность данных.
- Платформизация стека данных. Центральные хранилища данных (`Data Warehouse`, `Lakehouse`) превращаются из простых баз данных в полноценные платформы для разработки. Это открывает путь для нового поколения `warehouse-native` SaaS-приложений.
- Операционализация данных. Тренд смещается от простой аналитики (посмотреть на дашборд) к активному использованию данных в операционных процессах бизнеса. Технологии `Reverse ETL` являются главным драйвером этого тренда.
- Data-Centric AI. В мире машинного обучения фокус окончательно сместился с улучшения алгоритмов на улучшение данных, что стимулирует рынок инструментов для управления жизненным циклом данных в ML (`data labeling`, `feature stores`, `monitoring`).