
Архитектура Client Spooling: Как быстро выгружать гигантские датасеты в Trino и Apache DataFusion
Работа с Big Data часто упирается в классическое “узкое горлышко”: кластер может обработать терабайты данных за секунды, но передача результатов (Result Set) обратно на сторону клиента (например, в Jupyter или скрипт) занимает часы. На дворе апрель 2026 года, и современные аналитические движки предлагают эффективные методы обхода этой проблемы — концепцию Spooling.
Немного душноты: https://www.starburst.io/blog/trino-spooling-protocol/
Архитектура Client Spooling в Trino создавалась с параноидальным акцентом на безопасность, в S3 выкидываются куски сырых, возможно, чувствительных данных.
Когда Trino решает сбросить данные в объектное хранилище, он всегда шифрует их на лету.
Для этого используется механизм S3 SSE-C (Server-Side Encryption with Customer-provided keys). Trino генерирует уникальный случайный AES-ключ для каждого запроса, отправляет его в MinIO вместе с данными, а клиенту (вашему Jupyter) отдает ссылку + этот же ключ для расшифровки.
Если мы используем локальный MinIO по адресу http://minio:9000 (без SSL/TLS), сервер MinIO видит, что ему пытаются передать секретный пароль (SSE-C ключ) по открытому незащищенному HTTP-каналу.
MinIO (как и настоящий AWS S3) строго запрещает это по спецификации. Он возвращает HTTP 400 Bad Request с ошибкой: “Requests specifying Server Side Encryption... must be made over a secure connection”. Поэтому тестировать лучше на реальном s3. И еще
Мгновенное удаление (Сборка мусора)
Главное правило Client Spooling: Trino удаляет файлы сразу же, как только они были прочитаны клиентом.
Как только ваш Python-скрипт или Jupyter получает ссылку на файл, скачивает его и отправляет координатору Trino HTTP-сигнал (ACK), что кусок получен, координатор дает команду немедленно удалить этот объект из S3.
Если запрос отменен или упал с ошибкой, Trino тоже моментально зачищает за собой fs.location. Вы просто не успеете их там увидеть.
Данных слишком мало (Thresholds)
Писать 10 строк в S3, генерировать для них Pre-signed URLs и отдавать клиенту — это дольше, чем просто плюнуть эти 10 строк текстом через координатор. Trino использует эвристику: если Result Set маленький, он отдается “инлайн” (внутри JSON-ответа самого координатора), и S3 не задействуется.
В этой статье мы разберем, как передавать результаты запросов через промежуточное S3-хранилище, на примере движков Trino и Apache DataFusion.
Физика проблемы и математика Spooling
В классической архитектуре все воркеры кластера отправляют вычисленные строки на главный узел (Coordinator), а тот уже отдает их по одному каналу клиенту.
Если D — это объем результирующей выборки, а B c — пропускная способность сети координатора, то время выгрузки данных клиенту без спулинга равно:
T classic = B / Dc
В режиме Spooling координатор не гоняет данные через себя. Воркеры напрямую, параллельно пишут куски результата в дешевое объектное хранилище (S3/MinIO). Клиент получает лишь ссылки на эти файлы и скачивает их напрямую. Если у нас N файлов в S3, доступных для многопоточного скачивания с пропускной способностью клиента B client: T spooling ≈ min(N×B s3,B client)D
Это позволяет ускорить выгрузку в десятки раз, так как $B_{client}$ и распределенный $B_{s3}$ обычно значительно больше ограничений одного координатора.
Подготовка минимальной инфраструктуры
Для демонстрации двух подходов мы убрали из нашего кластера все тяжелые клиентские среды (Jupyter, Spark) и оставили только “голое” ядро: хранилище S3, REST-каталог и SQL-движок.
docker-compose.ymlversion: '3.8'
services:
minio:
image: minio/minio:latest
ports:
- "19000:9000"
- "19001:9001"
environment:
MINIO_ROOT_USER: "minio-root-user"
MINIO_ROOT_PASSWORD: "minio-root-password"
command: server /data --console-address ":9001"
minio-setup:
image: minio/mc:latest
depends_on:
- minio
entrypoint: >
/bin/sh -c "
sleep 5;
mc alias set myminio http://minio:9000 minio-root-user minio-root-password;
mc mb myminio/warehouse || true;
"
lakekeeper:
image: dalongrong/lakekeeper:latest
ports:
- "8181:8181"
environment:
- S3_ENDPOINT=http://minio:9000
- S3_REGION=us-east-1
- S3_ACCESS_KEY_ID=minio-root-user
- S3_SECRET_ACCESS_KEY=minio-root-password
depends_on:
- minio-setup
trino:
image: trinodb/trino:latest
ports:
- "8080:8080"
Сначала мы генерируем данные в Trino. Запрос
CREATE CATALOGиспользует динамическое подключение к Lakekeeper REST API. Скрипт записывает файлы в формате Parquet в MinIO:
config.properties
protocol.spooling.enabled=true
# 256-битный ключ в формате base64. Вы можете сгенерировать свой с помощью команды `openssl rand -base64 32`
protocol.spooling.shared-secret-key=jxTKysfCBuMZtFqUf8UJDQ1w9ez8rynEJsJqgJf66u0=
catalog.management=dynamicspooling-manager.properties
spooling-manager.name=filesystem
# Включаем чтение/запись в S3 для Spooling
fs.s3.enabled=true
# Путь внутри MinIO (указываем через s3://)
fs.location=s3://warehouse/client-spooling/
# Системные настройки S3 (MinIO)
s3.endpoint=http://minio:9000
s3.region=us-east-1
s3.aws-access-key=minio-root-user
s3.aws-secret-key=minio-root-password
s3.path-style-access=true-- 1. Подключение каталога Iceberg
CREATE CATALOG test_warehouse USING iceberg
WITH (
"iceberg.catalog.type" = 'rest',
"iceberg.rest-catalog.uri" = 'http://lakekeeper:8181/catalog/',
"iceberg.rest-catalog.warehouse" = '00000000-0000-0000-0000-000000000000/test_warehouse',
"iceberg.rest-catalog.security" = 'OAUTH2',
"iceberg.rest-catalog.nested-namespace-enabled" = 'true',
"iceberg.rest-catalog.vended-credentials-enabled" = 'true',
"fs.native-s3.enabled" = 'true',
"s3.region" = 'us-east-1',
"s3.path-style-access" = 'true',
"s3.endpoint" = 'http://minio:9000'
);-- 2. Создание структуры
CREATE SCHEMA test_warehouse.test_schema;
CREATE TABLE test_warehouse.test_schema.my_table (
id BIGINT,
data VARCHAR
) WITH (format = 'PARQUET');-- 3. Запись данных
INSERT INTO test_warehouse.test_schema.my_table VALUES (1, 'hello'), (2, 'world');Если написать Select – должно быть как-то так
Аналог Spooling в Apache DataFusion (Через экспорт)
Trino поддерживает протокол *Client Spooling* “из коробки” — когда Python-клиент запрашивает огромный `SELECT`, Trino сам незаметно пишет куски в S3 и отдает клиенту готовые ссылки.
В Apache DataFusion (который часто работает как локальный движок `datafusion-cli` или встраиваемая библиотка поверх S3) применяется более прозрачный паттерн делегирования (Explicit Spooling). Мы вручную инструктируем движок сохранить результаты агрегации в распределенное хранилище, чтобы позже забрать их в удобном формате — например, упаковав их в `JSON` и сжав алгоритмом `ZSTD`.
1. Подключение к S3 и маппинг исходной таблицы
Запускаем `datafusion-cli`, передав доступы как переменные среды (для предотвращения ошибок парсинга опций):
AWS_ACCESS_KEY_ID="minio-root-user" \
AWS_SECRET_ACCESS_KEY="minio-root-password" \
AWS_ENDPOINT="http://localhost:19000" \
AWS_REGION="us-east-1" \
AWS_ALLOW_HTTP="true" \
datafusion-cliВнутри консоли подключаем директорию с Parquet-файлами, сгенерированными Trino:
CREATE EXTERNAL TABLE my_parquet_data
STORED AS PARQUET
LOCATION 's3://warehouse/019d81a3-c2d6-7ed2-ab15-070becf62582/my_table-13e4b91a2b4e47d98f312b1384263880/data/';2. Массовая конвертация и выгрузка (DataFusion COPY)
Вместо того чтобы тянуть миллионы строк на локальный терминал, мы просим DataFusion выполнить преобразование и записать итог запроса обратно в MinIO.
Мы выбираем построчный JSON с экстремальным сжатием:
COPY (
-- Тут может быть любая сложная агрегация:
-- SELECT id, count(data) FROM my_parquet_data GROUP BY id
SELECT * FROM my_parquet_data
)
TO 's3://warehouse/019d81a3-c2d6-7ed2-ab15-070becf62582/my_table-13e4b91a2b4e47d98f312b1384263880/json_export/'
STORED AS JSON
OPTIONS (
'format.compression' 'zstd'
);Результат:
+-------+
| count |
+-------+
| 2 |
+-------+
1 row(s) fetched.
Elapsed 0.270 seconds.За миллисекунды (0.270 sec) DataFusion прочитал партиции, трансформировал бинарные столбцы в текст и сжал его.
В чем преимущество подхода DataFusion?
Описанный паттерн выполнения команды `COPY TO` с сохранением `.json.zst` в MinIO полностью воспроизводит механику Spooling:
- Отсутствие OOM (Out Of Memory): Клиент получает только метаданные `count`, а не гигабайты сырых данных в оперативную память.
- Параллелизм: Если исходных файлов много, DataFusion будет писать множество потоков `part-0.json.zst`, `part-1.json.zst` в бакет параллельно.
- Удаленное потребление: Вы можете запустить легкий Python-скрипт (Pandas) на дешевой машине, который просто прочитает эти сжатые легковесные JSON объекты напрямую из MinIO, минуя дорогостоящие вычислительные кластеры.
Еще немного про Fault-Tolerant Execution (FTE), нужно провести важную границу между архитектурой Trino (готовый распределенный кластер) и архитектурой DataFusion (ядро/библиотека выполнения запросов).
В самом “голом” ядре DataFusion (которое вы запускаете в `datafusion-cli` или в Jupyter) нет встроенного механизма Task Retries, потому что процессы выполняются на одной машине в рамках одного приложения. Если сервер падает — запрос прерывается.
Однако, в экосистеме DataFusion есть механизмы отказоустойчивости, которые делятся на два уровня: локальный (Spilling) и распределенный (Apache Ballista / Ray).
1. Локальная отказоустойчивость (защита от OOM)
В Trino частой причиной падения задач является нехватка памяти (Out of Memory). В DataFusion реализован мощный механизм управления памятью.
Если DataFusion понимает, что оперативной памяти для агрегации или JOIN’а не хватает, он не “роняет” задачу, а начинает сбрасывать промежуточные данные на диск (Spill to Disk).
- Это настраивается через конфигурацию `datafusion.execution.disk_manager`.
- Это аналог локального `spill-enabled = true` в Trino. Запрос замедлится, но выполнится до конца, не упав с ошибкой.
2. Распределенная отказоустойчивость (Аналог Trino FTE)
Trino использует архитектуру Fault-Tolerant Execution (FTE), при которой промежуточные результаты (Shuffle Exchange) пишутся в S3, а упавшие воркеры заменяются, и их задачи (Tasks) перезапускаются координатором.
В мире DataFusion эту задачу решает не само ядро, а распределенные планировщики, построенные поверх него:
А. Apache Ballista (Официальный распределенный DataFusion)
Ballista — это надстройка над DataFusion, превращающая его в полноценный кластер (с Coordinator и Executors), архитектурно очень похожая на Apache Spark и Trino.
- Task Retries: Если один из Executor’ов теряется из-за сбоя сети или железа, Ballista Coordinator замечает это и переназначает задачу (Task) другому воркеру.
- Shuffle Spilling: Промежуточные данные между стадиями (Stages) записываются во временные файлы. Следовательно, если упала только последняя стадия, кластеру не нужно пересчитывать весь запрос с нуля — он прочитает промежуточные Shuffle-файлы и повторит только упавший кусок.
Б. DataFusion on Ray (datafusion-ray)
Сейчас огромную популярность набирает запуск DataFusion поверх кластера Ray.
Ray — это супер-устойчивый распределенный фреймворк. Интеграция `datafusion-ray` позволяет разбить SQL-запрос на граф задач прямо в Ray.
- За отказоустойчивость, Retry-логику и восстановление упавших узлов (Actor/Task) здесь отвечает сам Ray, который делает это на уровне индустриального стандарта.
- Это максимально близко к концепции отказоустойчивого кластера.
Резюме: Как получить “Trino-like” Fault Tolerance в DataFusion?
- Если вы используете локальный DataFusion (в Python или CLI): Отказоустойчивости уровня узлов нет, но есть защита от падений по памяти (Spill to Disk). Если упадет процесс — нужно перезапускать запрос руками.
- Если вам нужен настоящий Task Repeat / Fault Tolerance на сотнях серверов, где падение серверов — норма: вы используете движок DataFusion вместе с кластерным менеджером Apache Ballista или Ray, которые прозрачно обеспечат перезапуск задач (Retries) и сохранение промежуточных состояний (Shuffle), полностью повторяя логику Trino FTE.
UPD: В локальном тестировании есть некоторые особенности. Когда контейнеры внутри имеют свою сеть, то трино посылает в dbeaver ссылки. А есть хост не знает что это за минива или localstack-spooling, то оно отдаст кусок данных, а остальные части просто не доедут. Квери упадет как отмененная, так как клиент получил не все результаты. Короче, надо просто так сделать
sudo nano /etc/hostsи вставить строку вашего s3 хоста.
127.0.0.1 localstack-spoolingто есть при спулинге клиент должен не только иметь сетевую связанность с s3 но различать dns имена корректно.
Короче сравния строк пройдено, все сошлося :)
со спулингом 2.2 сек
без спулинга 4.4 сек

Питончик 2.16 сек с чанками
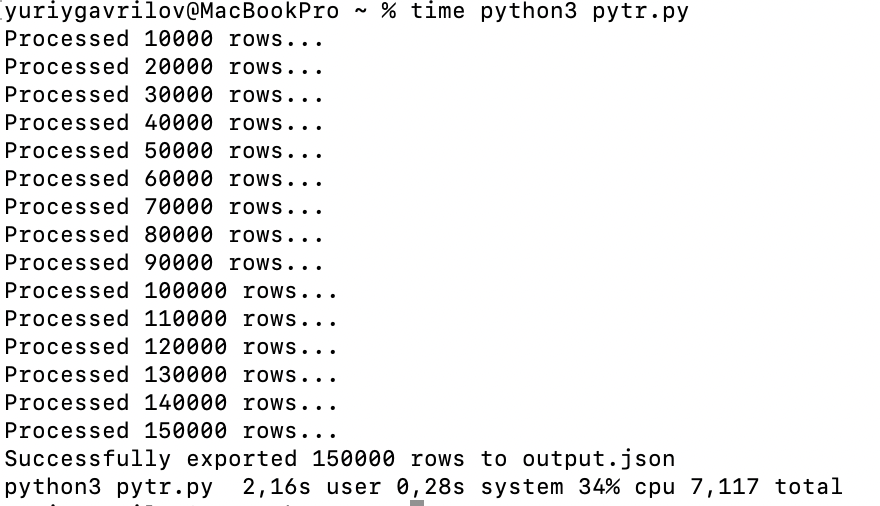
в самом трино еще быстрее
все строки на месте: 150тыщъ

код !!
from trino.dbapi import connect
import json
– Конфигурация –
TRINO_HOST = “localhost”
TRINO_PORT = 9999
TRINO_USER = “trino”
TRINO_CATALOG = “test_warehouse”
TRINO_SCHEMA = “test_schema”
OUTPUT_FILE = “output.json”
CHUNK_SIZE = 10000 # Количество строк, обрабатываемых за один раз
def export_to_json():
conn = connect(
host=TRINO_HOST,
port=TRINO_PORT,
user=TRINO_USER,
catalog=TRINO_CATALOG,
schema=TRINO_SCHEMA,
)
cursor = conn.cursor()
try:
Отключаем Fault-Tolerant Execution
cursor.execute(“SET SESSION retry_policy = ‘NONE’”)
cursor.execute(“SELECT * FROM my_table2”)
column_names = [desc[0] for desc in cursor.description]
row_count = 0
with open(OUTPUT_FILE, “w”, encoding=“utf-8”) as f:
Используем fetchmany для чанков
while True:
rows = cursor.fetchmany(CHUNK_SIZE)
if not rows:
break
for row in rows:
row_dict = dict(zip(column_names, row))
f.write(json.dumps(row_dict, ensure_ascii=False, default=str) + “\n”)
row_count += len(rows)
print(f“Processed {row_count} rows...”)
print(f“Successfully exported {row_count} rows to {OUTPUT_FILE}”)
finally:
cursor.close()
conn.close()
if __name__ == “__main__”:
export_to_json()
Вот еще с уточкой и чанками
код
import duckdb
import json
OUTPUT_FILE = “/home/jovyan/examples/output_duckdb.json”
CHUNK_SIZE = 10000
conn = duckdb.connect()
расширения и настройки (как у вас)
conn.execute(“INSTALL httpfs; LOAD httpfs;”)
conn.execute(“INSTALL iceberg; LOAD iceberg;”)
conn.execute(“SET memory_limit = ‘4GB’;”)
conn.execute(“SET s3_region = ‘us-east-1’;”)
conn.execute(“‘’
CREATE OR REPLACE SECRET minio_secret (
TYPE S3,
KEY_ID ‘minio-root-user’,
SECRET ‘minio-root-password’,
ENDPOINT ‘minio:9000’,
USE_SSL false,
URL_STYLE ‘path’
);
‘‘’)
conn.execute(‘‘’
CREATE OR REPLACE SECRET iceberg_secret (
TYPE ICEBERG,
TOKEN ‘dummy’
);
‘‘’)
conn.execute(‘‘’
ATTACH ‘test_warehouse’ AS lakekeeper_db (
TYPE ICEBERG,
ENDPOINT ’http://lakekeeper:8181/catalog/',
ACCESS_DELEGATION_MODE ‘none’,
SECRET iceberg_secret
);
‘‘’)
Используем cursor и fetchmany для чанков
cursor = conn.cursor()
cursor.execute(‘SELECT * FROM lakekeeper_db.test_schema.my_table2’)
Получаем имена колонок
col_names = [desc[0] for desc in cursor.description]
total_rows = 0
with open(OUTPUT_FILE, ‘w’, encoding=’utf-8’) as f:
while True:
rows = cursor.fetchmany(CHUNK_SIZE)
if not rows:
break
for row in rows:
row_dict = dict(zip(col_names, row))
f.write(json.dumps(row_dict, ensure_ascii=False, default=str) + ‘\n’)
total_rows += len(rows)
print(f’Обработано строк: {total_rows}’)
print(f’✅ Загружено и сохранено строк: {total_rows}”)
print(f“📁 Данные сохранены в {OUTPUT_FILE}”)
conn.close()
Можно даже так внутри уточки

import duckdb
OUTPUT_FILE = “/home/jovyan/examples/output_duckdb_direct.json”
conn = duckdb.connect()
Расширения и настройки
conn.execute(“INSTALL httpfs; LOAD httpfs;”)
conn.execute(“INSTALL iceberg; LOAD iceberg;”)
conn.execute(“SET memory_limit = ‘4GB’;”)
conn.execute(“SET s3_region = ‘us-east-1’;”)
Секрет для MinIO
conn.execute(“‘’
CREATE OR REPLACE SECRET minio_secret (
TYPE S3,
KEY_ID ‘minio-root-user’,
SECRET ‘minio-root-password’,
ENDPOINT ‘minio:9000’,
USE_SSL false,
URL_STYLE ‘path’
);
‘‘’)
Секрет для Iceberg REST
conn.execute(‘‘’
CREATE OR REPLACE SECRET iceberg_secret (
TYPE ICEBERG,
TOKEN ‘dummy’
);
‘‘’)
Подключение каталога Lakekeeper
conn.execute(‘‘’
ATTACH ‘test_warehouse’ AS lakekeeper_db (
TYPE ICEBERG,
ENDPOINT ’http://lakekeeper:8181/catalog/',
ACCESS_DELEGATION_MODE ‘none’,
SECRET iceberg_secret
);
‘‘’)
Экспорт в JSON (массив)
conn.execute(f’’’
COPY (
SELECT * FROM lakekeeper_db.test_schema.my_table2
) TO ‘{OUTPUT_FILE}’ (FORMAT JSON);
‘‘’)
print(f’✅ Данные сохранены в {OUTPUT_FILE}’)
conn.close()
К конце концов я использовал
localstack-spooling
protocol.spooling.enabled=true
# 256-битный ключ в формате base64. Вы можете сгенерировать свой с помощью команды `openssl rand -base64 32`
protocol.spooling.shared-secret-key=jxTKysfCBuMZtFqUf8UJDQ1w9ez8rynEJsJqgJf66u0=
catalog.management=dynamicтак
spooling-manager.name=filesystem
fs.s3.enabled=true
fs.location=s3://spooling-bucket/client-spooling/
s3.endpoint=http://localstack-spooling:4566
s3.region=us-east-1
s3.aws-access-key=test
s3.aws-secret-key=test
s3.path-style-access=trueи так
services:
trino:
build: ./trino
environment:
- CATALOG_MANAGEMENT=dynamic
- LANCE_ALLOW_HTTP=true
- AWS_ALLOW_HTTP=true
- AWS_ACCESS_KEY_ID=minio-root-user
- AWS_SECRET_ACCESS_KEY=minio-root-password
- AWS_REGION=us-east-1
- AWS_ENDPOINT_URL=http://minio:9000
- CATALOG_MANAGEMENT=dynamic
- JDK_JAVA_OPTIONS=--add-opens=java.base/java.nio=ALL-UNNAMED --add-opens=java.base/sun.nio.ch=ALL-UNNAMED --add-opens=java.base/java.util=ALL-UNNAMED --add-opens=java.base/java.lang=ALL-UNNAMED
healthcheck:
test: ["CMD", "curl", "-I", "http://localhost:8080/v1/status"]
interval: 2s
timeout: 10s
retries: 2
start_period: 10s
ports:
- "9999:8080"
volumes:
- ./lance5.properties:/etc/trino/catalog/lance5.properties
- ./lance_rest.properties:/etc/trino/catalog/lance_rest.properties
- ./lance_ice.properties:/etc/trino/catalog/lance_ice.properties
# --- ДОБАВЬТЕ ЭТУ СТРОКУ ---
- ./spooling-manager.properties:/etc/trino/spooling-manager.properties
# (При необходимости пробросьте и config.properties, если он не копируется при build: ./trino)
- ./config.properties:/etc/trino/config.properties
- spooling-data:/tmp/spooling
networks:
- lakekeeper-network
depends_on:
localstack-setup: # <--- Trino ждет, пока AWS CLI не создаст бакет!
condition: service_completed_successfully
localstack-spooling:
image: localstack/localstack:3.4.0 # Жестко фиксируем бесплатную рабочую версию!
container_name: localstack-spooling
ports:
- "4566:4566"
environment:
- SERVICES=s3
- AWS_DEFAULT_REGION=us-east-1
networks:
- lakekeeper-network
localstack-setup:
image: amazon/aws-cli:latest
container_name: localstack-setup
depends_on:
- localstack-spooling
restart: "no"
environment:
- AWS_ACCESS_KEY_ID=test
- AWS_SECRET_ACCESS_KEY=test
- AWS_DEFAULT_REGION=us-east-1
entrypoint: >
/bin/sh -c "
echo 'Waiting for LocalStack to fully start...';
sleep 10;
aws --endpoint-url=http://localstack-spooling:4566 s3 mb s3://spooling-bucket;
echo 'LocalStack bucket created successfully!';
"
networks:
- lakekeeper-network
jupyter:
image: quay.io/jupyter/pyspark-notebook:2024-10-14
depends_on:
lakekeeper:
condition: service_healthy
# Исправлено: теперь зависим от рабочего setup сервиса
lakekeeper-setup:
condition: service_completed_successfully
trino:
condition: service_healthy
# Удалено: starrocks (сервис не описан в compose файле)
command: start-notebook.sh --NotebookApp.token=''
volumes:
- ./notebooks:/home/jovyan/examples/
- spooling-data:/tmp/spooling
networks:
- lakekeeper-network
ports:
- "8888:8888"
# Сервис initialwarehouse УДАЛЕН, так как он дублировал lakekeeper-setup
# и ссылался на несуществующие сервисы (bootstrap, createbuckets).
postgres-lakekeeper:
image: postgres:17
container_name: postgres-lakekeeper
environment:
POSTGRES_USER: lakekeeper
POSTGRES_PASSWORD: lakekeeper
POSTGRES_DB: lakekeeper
ports:
- "5435:5432"
volumes:
- lakekeeper-postgres-data:/var/lib/postgresql/data
healthcheck:
test: ["CMD-SHELL", "pg_isready -U lakekeeper -d lakekeeper"]
interval: 2s
timeout: 10s
retries: 5
networks:
- lakekeeper-network
minio:
image: minio/minio:latest
container_name: minio-lakekeeper
environment:
MINIO_ROOT_USER: minio-root-user
MINIO_ROOT_PASSWORD: minio-root-password
# MINIO_DOMAIN: minio
command: server /data --console-address ":9001"
ports:
- "19000:9000"
- "19001:9001"
volumes:
- lakekeeper-minio-data:/data
healthcheck:
test: ["CMD", "mc", "ready", "local"]
interval: 2s
timeout: 10s
retries: 5
networks:
- lakekeeper-network
minio-setup:
image: minio/mc:latest
container_name: minio-setup
depends_on:
minio:
condition: service_healthy
entrypoint: >
/bin/sh -c "
mc alias set myminio http://minio:9000 minio-root-user minio-root-password &&
mc mb myminio/warehouse --ignore-existing &&
echo 'MinIO bucket created'
"
networks:
- lakekeeper-network
lakekeeper-migrate:
image: quay.io/lakekeeper/catalog:latest-main
container_name: lakekeeper-migrate
depends_on:
postgres-lakekeeper:
condition: service_healthy
environment:
- LAKEKEEPER__PG_ENCRYPTION_KEY=test-encryption-key-not-secure
- LAKEKEEPER__PG_DATABASE_URL_READ=postgresql://lakekeeper:lakekeeper@postgres-lakekeeper:5432/lakekeeper
- LAKEKEEPER__PG_DATABASE_URL_WRITE=postgresql://lakekeeper:lakekeeper@postgres-lakekeeper:5432/lakekeeper
restart: "no"
command: ["migrate"]
networks:
- lakekeeper-network
lakekeeper:
image: quay.io/lakekeeper/catalog:latest-main
container_name: lakekeeper
depends_on:
lakekeeper-migrate:
condition: service_completed_successfully
minio-setup:
condition: service_completed_successfully
environment:
- LAKEKEEPER__PG_ENCRYPTION_KEY=test-encryption-key-not-secure
- LAKEKEEPER__PG_DATABASE_URL_READ=postgresql://lakekeeper:lakekeeper@postgres-lakekeeper:5432/lakekeeper
- LAKEKEEPER__PG_DATABASE_URL_WRITE=postgresql://lakekeeper:lakekeeper@postgres-lakekeeper:5432/lakekeeper
- LAKEKEEPER__AUTHZ_BACKEND=allowall
- RUST_LOG=info
command: ["serve"]
healthcheck:
test: ["CMD", "/home/nonroot/lakekeeper", "healthcheck"]
interval: 2s
timeout: 10s
retries: 5
start_period: 5s
ports:
- "8282:8181"
networks:
- lakekeeper-network
lakekeeper-bootstrap:
image: curlimages/curl
container_name: lakekeeper-bootstrap
depends_on:
lakekeeper:
condition: service_healthy
restart: "no"
command:
- -w
- "%{http_code}"
- "-X"
- "POST"
- "-v"
- "http://lakekeeper:8181/management/v1/bootstrap"
- "-H"
- "Content-Type: application/json"
- "--data"
- '{"accept-terms-of-use": true}'
- "-o"
- "/dev/null"
networks:
- lakekeeper-network
lakekeeper-setup:
image: curlimages/curl
container_name: lakekeeper-setup
depends_on:
lakekeeper-bootstrap:
condition: service_completed_successfully
restart: "no"
entrypoint: ["/bin/sh", "-c"]
command:
- |
echo "Creating test_warehouse..."
curl -sf -X POST "http://lakekeeper:8181/management/v1/warehouse" \
-H "Content-Type: application/json" \
-d '{
"warehouse-name": "test_warehouse",
"project-id": "00000000-0000-0000-0000-000000000000",
"storage-profile": {
"type": "s3",
"bucket": "warehouse",
"endpoint": "http://minio:9000",
"region": "us-east-1",
"path-style-access": true,
"flavor": "minio",
"sts-enabled": false
},
"storage-credential": {
"type": "s3",
"credential-type": "access-key",
"aws-access-key-id": "minio-root-user",
"aws-secret-access-key": "minio-root-password"
}
}' && echo "Warehouse created successfully" || echo "Failed to create warehouse"
networks:
- lakekeeper-network
volumes:
lakekeeper-postgres-data:
lakekeeper-minio-data:
spooling-data:
networks:
lakekeeper-network:
driver: bridge