
Битва Новых Архитектур: Сравниваем Arc, GigAPI и DuckLake
В мире данных происходит тихая революция. На смену тяжеловесным и дорогим OLAP-системам приходят легковесные, но мощные решения, построенные на идеологии Lakehouse. Они обещают гибкость озер данных и надежность хранилищ без лишней сложности и затрат.
Можно еще почитать тут: https://habr.com/ru/articles/955536/
В этой статье мы сравним два таких проекта для работы с временными рядами — Arc и GigAPI. А также разберемся, какое место в этой экосистеме занимает DuckLake — технология, которую пока еще могут путать с Arc.
🆚 Arc vs. GigAPI: Сравнительная таблица


Это прямые конкуренты, решающие задачу хранения и анализа временных рядов, но с разной философией.
| Параметр | Arc | GigAPI |
| Основной подход | Автономная Time-Series база данных «в одном файле» на базе DuckDB. | Унифицированный слой для запросов и управления жизненным циклом данных (Lakehouse). |
| Стадия развития | Альфа, не для продакшена. | Открытая бета, активные релизы. |
| Архитектура | Монолитный бинарный файл, простой запуск. | Набор микросервисов (`aio`, `readonly`, `writeonly`, `compaction`). |
| Производительность (ingest) | Заявлено до ~1.89 млн записей/сек (нативным протоколом). | Субсекундные аналитические запросы. Производительность ingest зависит от бэкенда. |
| Протоколы ввода данных | MessagePack (рекомендуемый), InfluxDB Line Protocol arc. | InfluxDB Line Protocol, Native JSON. Планируется FlightSQL gigapi. |
| Управление данными | ACID-транзакции, Time Travel, Schema Evolution (унаследовано от Lakehouse-архитектуры). | Автоматическая компакция, перемещение данных (tiering) между FS и S3, удаление по TTL. |
| Лицензия | AGPL-3.0 (важное ограничение для коммерческого использования). | MIT (максимально разрешительная). |
Ключевые отличия в подходах: Arc и GigAPI
Arc: Максимальная простота и скорость для старта
Arc arc — это полноценная база данных временных рядов, которую можно скачать и запустить одной командой.
- Идеология: “Батарейки в комплекте”. Arc предоставляет готовое решение с ACID-транзакциями, time travel и эволюцией схемы “из коробки”. Он спроектирован для максимальной простоты развертывания и сверхбыстрого приема данных.
- Сценарий использования: Идеален для R&D, прототипирования и внутренних проектов, где нужна высокая производительность без сложной настройки.
- Ключевой компромисс: Лицензия AGPL-3.0 требует, чтобы любое сетевое приложение, использующее Arc, также открывало свой исходный код. Это делает его неприменимым для многих коммерческих продуктов.
GigAPI: Операционная мощь для продакшена
GigAPI gigapi — это не база данных, а скорее интеллектуальный операционный слой или шлюз, который работает поверх ваших данных.
- Идеология: “Оркестратор и оптимизатор”. GigAPI фокусируется на промышленной эксплуатации и автоматизации рутинных задач. Его микросервисы (`merge`, `move`, `drop`) следят за здоровьем хранилища: уплотняют мелкие файлы, перемещают старые данные в дешевое S3-хранилище и удаляют их по истечении срока жизни (TTL).
- Сценарий использования: Построение зрелого, экономически эффективного и надежного пайплайна для временных рядов в production-среде. Разрешительная лицензия MIT делает его отличным выбором для бизнеса.
- Ключевое преимущество: Архитектурная гибкость и фокус на снижении эксплуатационных расходов (OpEx).
А где же DuckLake?
DuckLake — это не база данных, а открытый табличный формат и расширение для DuckDB ducklake. Его цель — упростить создание Lakehouse, используя SQL в качестве слоя метаданных ducklake blog.
Представьте, что у вас есть набор Parquet-файлов в S3. Чтобы работать с ними как с единой таблицей и иметь транзакции, традиционно нужен сложный компонент вроде Hive Metastore или Nessie. DuckLake предлагает более простой путь:
Используйте обычную SQL-базу (например, DuckDB, SQLite или даже Postgres) для хранения всей метаинформации о файлах, версиях и схеме.
Таким образом, DuckLake — это фундаментальный строительный блок, а не готовое приложение. Он конкурирует с Apache Iceberg и Delta Lake, предлагая более простую альтернативу. Недавние обновления даже добавили совместимость с Iceberg, что делает его еще более мощным инструментом ducklake.select.
Сравнение с рынком: Альтернативы и выбор
| Система | Сильные стороны | Слабые стороны / Риски |
| InfluxDB 3.0 | Зрелая экосистема для временных рядов, Lakehouse архитектура “под капотом”. | Стоимость для enterprise, привязка к своей экосистеме. |
| QuestDB | Высокая скорость вставок и SQL-запросов, простой опыт TSDB. | Менее универсален для “озер” на S3, чем конкуренты. |
| TimescaleDB | Полная совместимость с экосистемой PostgreSQL. | Привязанность к PostgreSQL и его модели масштабирования. |
| ClickHouse | Универсальный OLAP-движок, мощные возможности для временных рядов, горизонтальное масштабирование. | Высокие эксплуатационные расходы, сложность настройки кластера. |
Когда что выбирать?
- Выберите Arc, если вам нужен максимально быстрый старт для прототипа или внутреннего проекта, вы не боитесь альфа-версии и вас полностью устраивает лицензия AGPL-3.0.
- Выберите GigAPI, если вы строите продакшн-систему, вам важна автоматизация рутинных задач (compaction, tiering, TTL) и нужна разрешительная лицензия MIT для коммерческого использования.
- Используйте DuckLake, если вы уже работаете с DuckDB и хотите построить свой собственный, простой Lakehouse на базе Parquet-файлов, избегая сложности стека Hadoop/Spark.
- Обратитесь к ClickHouse/Druid, когда нужны жесткие SLA, горизонтальное масштабирование и высокий параллелизм для тысяч одновременных пользователей.
- Рассмотрите QuestDB/Timescale, если приоритетом является предельно простой опыт работы с TSDB или глубокая интеграция с экосистемой Postgres.
Заключение
Arc, GigAPI и DuckLake — яркие представители тренда на прагматичные и экономичные решения для данных.
- Arc — спринтер для быстрого старта.
- GigAPI — марафонец для надежной работы в продакшене.
- DuckLake — набор инструментов для архитектора, позволяющий построить легковесный и современный дом для данных.
Их появление говорит о том, что рынку нужны не только монструозные системы, но и решения с оптимальным соотношением “простота/стоимость/функциональность”.
Вот так выглядит:
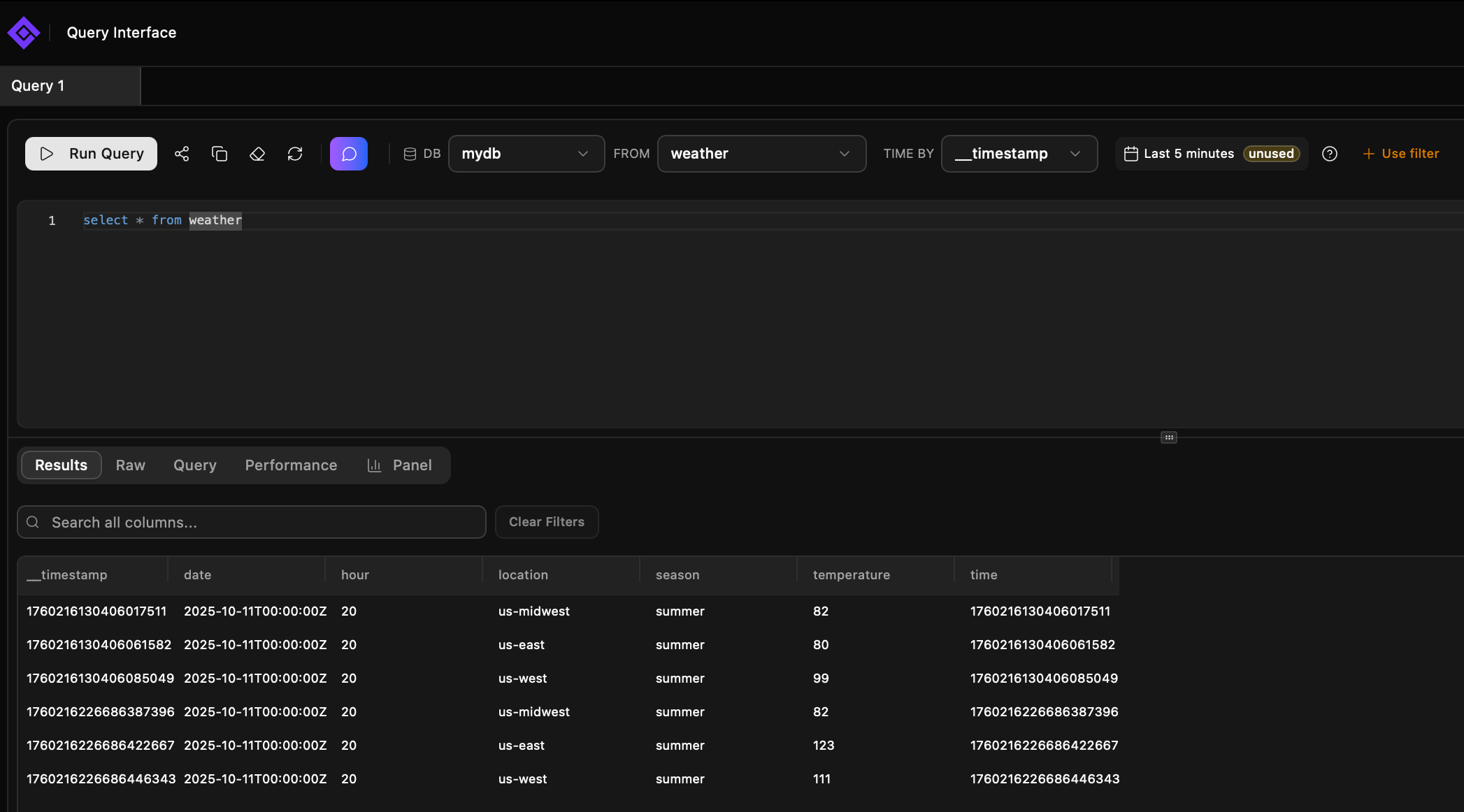
services:
gigapi:
image: ghcr.io/gigapi/gigapi:latest
container_name: gigapi
hostname: gigapi
restart: unless-stopped
volumes:
- ./data:/data
ports:
- "7971:7971"
- "8082:8082"
environment:
- PORT=7971
- GIGAPI_ENABLED=true
- GIGAPI_MERGE_TIMEOUT_S=10
- GIGAPI_ROOT=/data
- GIGAPI_LAYERS_0_NAME=default
- GIGAPI_LAYERS_0_TYPE=fs
- GIGAPI_LAYERS_0_URL=file:///data
- GIGAPI_LAYERS_0_GLOBAL=false
- GIGAPI_LAYERS_0_TTL=12h
- GIGAPI_LAYERS_1_NAME=s3
- GIGAPI_LAYERS_1_TYPE=s3
- GIGAPI_LAYERS_1_URL=s3://gateway.XXXXX/test/gigapi
- GIGAPI_LAYERS_1_AUTH_KEY=XXXXX
- GIGAPI_LAYERS_1_AUTH_SECRET=XXXXX
- GIGAPI_LAYERS_1_GLOBAL=true
- GIGAPI_LAYERS_1_TTL=0А данные пишем так:
cat <<EOF | curl -X POST "http://localhost:7971/write?db=mydb" --data-binary @/dev/stdin
weather,location=us-midwest,season=summer temperature=82
weather,location=us-east,season=summer temperature=123
weather,location=us-west,season=summer temperature=111
EOFПервый раз нужно отправить сообщение, что бы создалась база.
файлики пишет, но че то пока не на s3, видимо надо дождаться как они переедут с кеша на s3
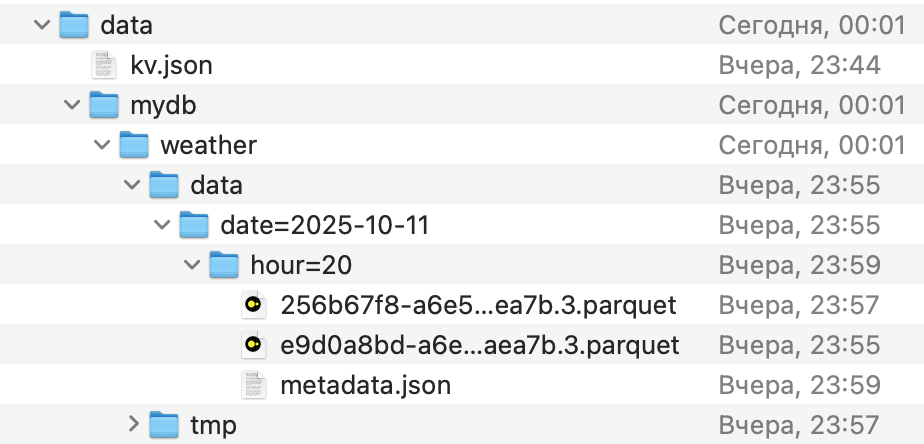
Выше пример не сработал, точнее он работал, но не копировал данные на s3
вот это рабочий вариант
# docker-compose.yml
version: '3.8'
services:
gigapi:
build: .
container_name: gigapi
restart: unless-stopped
volumes:
- ./gigapi_data:/data
ports:
- "7971:7971"
- "8082:8082"
environment:
# --- Общие настройки GigAPI ---
- GIGAPI_ROOT=/data
- HTTP_PORT=7971
- LOGLEVEL=info
- GIGAPI_UI=true
# --- Конфигурация Слоя 0: Локальный кэш на диске ---
- GIGAPI_LAYERS_0_NAME=local_cache
- GIGAPI_LAYERS_0_TYPE=fs
- GIGAPI_LAYERS_0_URL=file:///data/cache
- GIGAPI_LAYERS_0_GLOBAL=false
- GIGAPI_LAYERS_0_TTL=10m
# --- Конфигурация Слоя 1: Хранилище Storj S3 ---
- GIGAPI_LAYERS_1_NAME=storj_s3
- GIGAPI_LAYERS_1_TYPE=s3
- GIGAPI_LAYERS_1_URL=s3://gateway.storjshare.io/test/gigapi/data?url-style=path
- GIGAPI_LAYERS_1_AUTH_KEY=XXXXXX
- GIGAPI_LAYERS_1_AUTH_SECRET=XXXXX
- GIGAPI_LAYERS_1_GLOBAL=true
- GIGAPI_LAYERS_1_TTL=0И пришлось серты обновить
# Dockerfile
# Берем за основу официальный образ gigapi
FROM ghcr.io/gigapi/gigapi:latest
# Переключаемся на пользователя root для установки пакетов
USER root
# Обновляем список пакетов и устанавливаем корневые сертификаты.
# Эта команда сначала пытается использовать 'apt-get' (для Debian/Ubuntu).
# Если эта команда завершается с ошибкой (оператор ||), то
# выполняется вторая команда с 'apk' (для Alpine).
# Это делает Dockerfile более универсальным.
RUN if command -v apt-get &> /dev/null; then \
apt-get update && apt-get install -y --no-install-recommends ca-certificates && apt-get clean && rm -rf /var/lib/apt/lists/*; \
elif command -v apk &> /dev/null; then \
apk add --no-cache ca-certificates; \
else \
echo "Error: Neither apt-get nor apk found. Cannot install ca-certificates." >&2; \
exit 1; \
fi
# Возвращаемся к стандартному пользователю (если он есть)
# USER gigapi
Там кстати еще чатгпт апи можно вставить
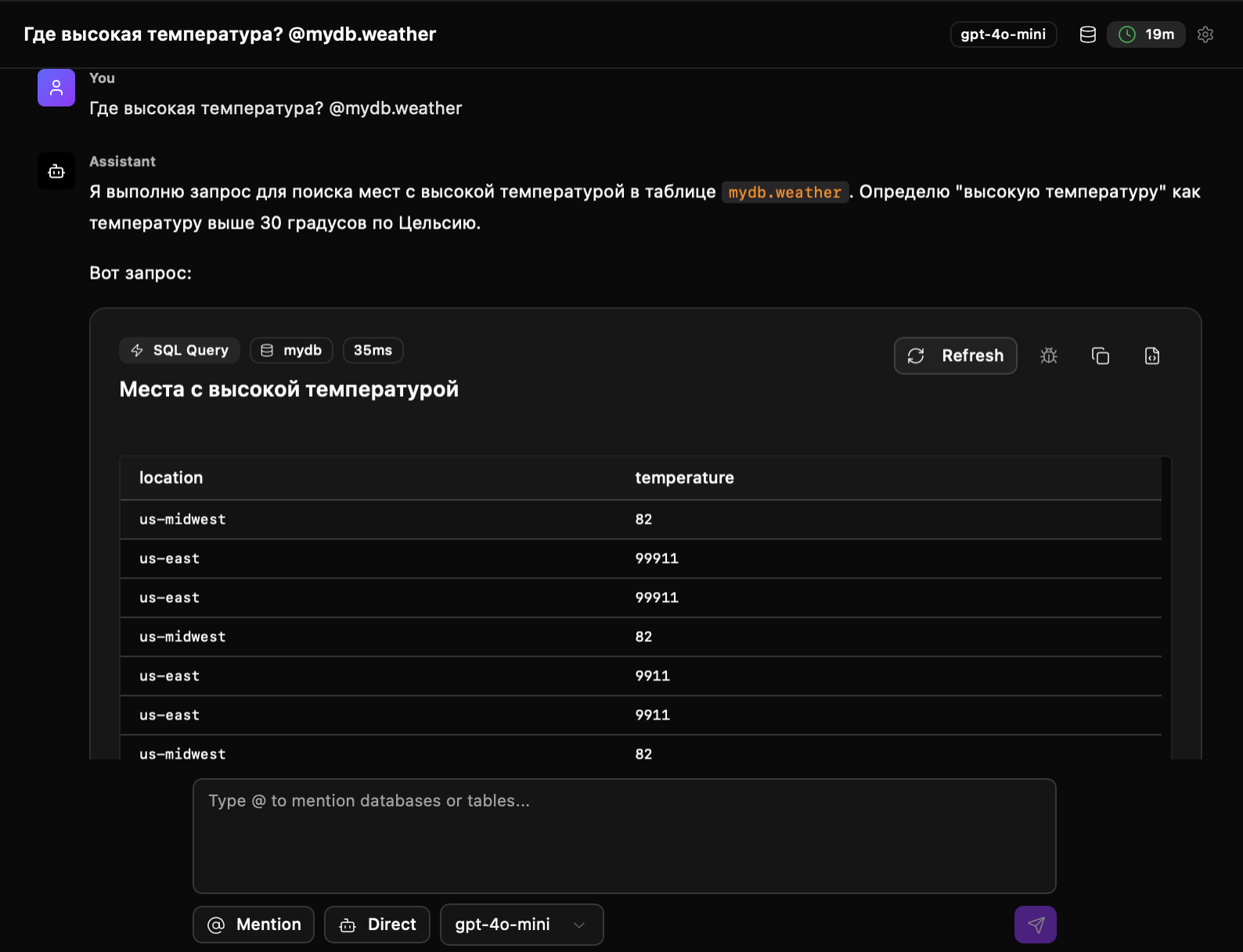
И дашборды есть еще
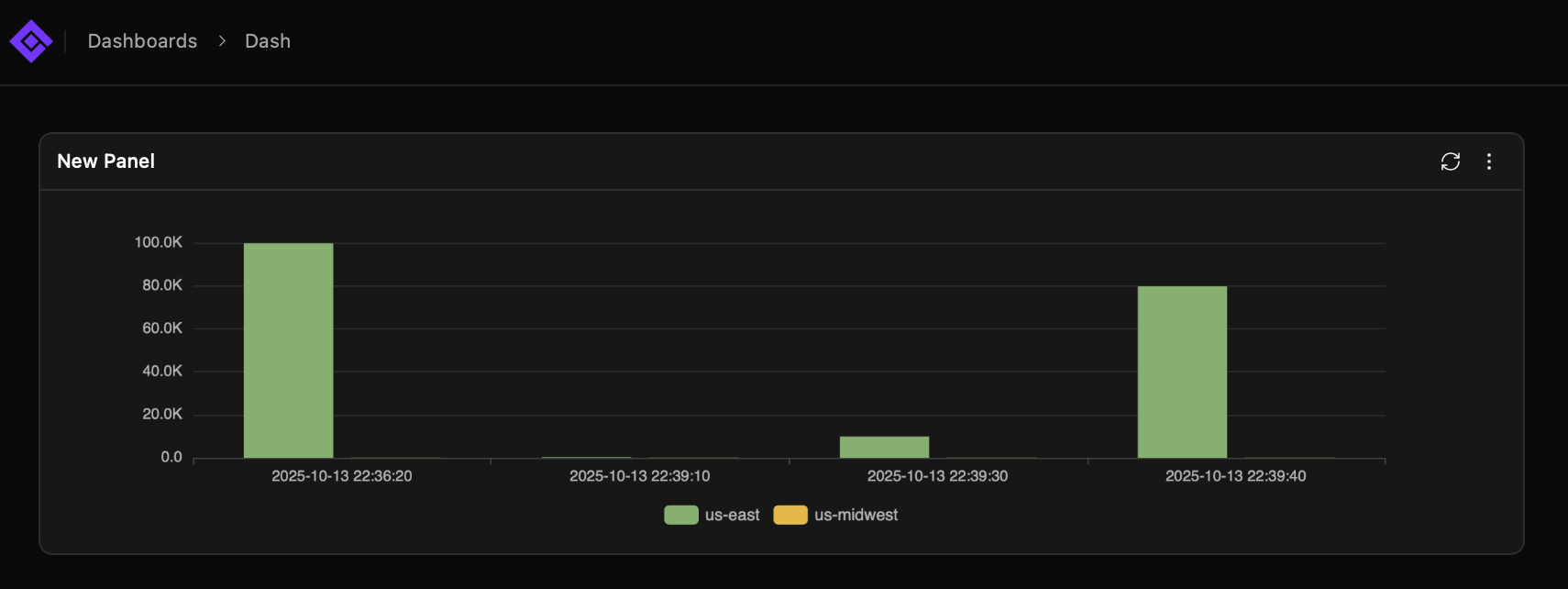
Еще про s3 подобные архитектуры:
https://gavrilov.info/all/sozdaem-streaming-lakehouse-za-chas-rukovodstvo-po-risingwave-la