
QueryFlux: Universal SQL Proxy для аналитических движков
В этой статье я расскажу, как поднять полноценную инфраструктуру для аналитических запросов, используя QueryFlux — высокопроизводительный SQL-прокси на Rust, который умеет принимать запросы по разным протоколам (Trino HTTP, PostgreSQL wire, MySQL wire) и маршрутизировать их на различные бэкенды (Trino, StarRocks, DuckDB, Athena). Мы соберем стек: Trino как основной движок, Lakekeeper как Iceberg REST-каталог, MinIO как S3-хранилище, StarRocks как альтернативный MPP-движок, и наконец сам QueryFlux, который предоставит единую точку входа для клиентов.

Все конфигурации взяты из реального рабочего проекта, запущенного на macOS с Podman (но совместимы и с Docker). Детально разберем файлы, шаги запуска, решим типичные проблемы, покажем интерфейс управления и сравним QueryFlux с Trino Gateway и другими решениями.
https://github.com/lakeops-org/queryflux/blob/main/examples/full-stack/docker-compose.yml
1. Что такое QueryFlux и зачем он нужен
Современные data-платформы часто состоят из нескольких движков: Trino для федеративных запросов, StarRocks/ClickHouse для низкой задержки, DuckDB для ad-hoc аналитики, Athena для serverless-задач. Каждый движок имеет свой wire-протокол, свой диалект SQL и свои настройки аутентификации. Клиенты вынуждены либо подключаться напрямую к каждому движку, создавая $N \times M$ интеграций, либо использовать «костыли» в коде.
QueryFlux решает эту проблему, становясь единым шлюзом:
- Принимает запросы по протоколам: Trino HTTP, PostgreSQL Wire, MySQL Wire, Arrow Flight SQL.
- Маршрутизирует запросы по правилам (протокол, заголовки, regex, Python-скрипты).
- Ограничивает конкурентность (через параметр `maxRunningQueries`), ведет очереди, отдает метрики в Prometheus.
- Поддерживает аутентификацию (OIDC, static, LDAP) и авторизацию (OpenFGA).
Документация: queryflux.dev
2. Наша лабораторная конфигурация
Мы развернем следующий стек через `podman-compose` (или `docker-compose`):
| Сервис | Назначение | Порт на хосте |
| trino | Движок запросов (федерация + Iceberg) | 8081 (прямой доступ) |
| starrocks | Альтернативный MPP-движок | 9030 (MySQL протокол) |
| lakekeeper | Iceberg REST-каталог | 8181 |
| minio | S3-совместимое хранилище (данные Iceberg) | 19000 (API), 19001 (консоль) |
| postgres | БД метаданных Lakekeeper | 5433 |
| queryflux | Прокси-сервер | 8080 (Trino), 5434 (PG wire), 3306 (MySQL), 9000 (Admin API), 3000 (Studio UI) |
3. Математика планирования нагрузки (ограничение ресурсов)
Одним из важных аспектов настройки QueryFlux является управление конкурентностью (concurrency limit) через параметр `maxRunningQueries`.
Если мы обозначим лимит конкурентных запросов в группе маршрутизации как N, а среднее время выполнения одного запроса на бэкенде как T (в секундах), то теоретическая максимальная пропускная способность группы (Throughput, обозначается как R, в запросах в секунду) рассчитывается так:
R = N /T
Например, в нашем файле `config.yaml` мы задаем N = 100. Если средний аналитический запрос отрабатывает за T = 2.5 секунды, то пропускная способность нашей Trino-группы составит R = 40 запросов в секунду. Запросы сверх этого лимита попадают в очередь на стороне самого QueryFlux.
4. Конфигурационные файлы
Создайте папку `queryflux-demo/examples/full-stack` и перейдите в нее. Ниже приведены все необходимые файлы.
📄 Показать содержимое файла
docker-compose.yml(Полный стек)
name: queryflux-example-full
services:
queryflux:
image: ghcr.io/lakeops-org/queryflux:latest
platform: linux/amd64
ports:
- "8080:8080" # Trino HTTP через QueryFlux
- "9000:9000" # Admin API
- "3000:3000" # QueryFlux Studio
- "3306:3306" # MySQL wire
- "5434:5434" # PostgreSQL wire
volumes:
- ./config.yaml:/etc/queryflux/config.yaml:ro
environment:
RUST_LOG: ${RUST_LOG:-queryflux=info,queryflux_frontend=info}
depends_on:
postgres:
condition: service_healthy
trino:
condition: service_healthy
starrocks:
condition: service_healthy
restart: unless-stopped
trino:
image: trinodb/trino:latest
platform: linux/amd64
environment:
CATALOG_MANAGEMENT: dynamic
ports:
- "8081:8080"
healthcheck:
test: ["CMD", "curl", "-sf", "http://localhost:8080/v1/info"]
interval: 10s
timeout: 5s
retries: 15
start_period: 30s
volumes:
- ./trino-config/access-control.properties:/etc/trino/access-control.properties:ro
starrocks:
image: starrocks/allin1-ubuntu:latest
platform: linux/amd64
ports:
- "9030:9030"
- "8030:8030"
healthcheck:
test: ["CMD", "curl", "-sf", "http://localhost:8030/api/health"]
interval: 15s
timeout: 10s
retries: 20
start_period: 60s
postgres:
image: postgres:16-alpine
platform: linux/amd64
ports:
- "5433:5432"
environment:
POSTGRES_DB: queryflux
POSTGRES_USER: queryflux
POSTGRES_PASSWORD: queryflux
volumes:
- queryflux-pg:/var/lib/postgresql/data
healthcheck:
test: ["CMD-SHELL", "pg_isready -U queryflux"]
interval: 5s
timeout: 3s
retries: 10
lakekeeper-db:
image: postgres:17
platform: linux/amd64
environment:
POSTGRES_PASSWORD: postgres
healthcheck:
test: ["CMD-SHELL", "pg_isready -U postgres -p 5432 -d postgres"]
interval: 2s
timeout: 10s
retries: 10
start_period: 10s
minio:
image: minio/minio:latest
platform: linux/amd64
environment:
MINIO_ROOT_USER: minio-root-user
MINIO_ROOT_PASSWORD: minio-root-password
command: ["server", "--console-address", ":9001", "/data"]
ports:
- "19000:9000"
- "19001:9001"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/ready"]
interval: 2s
timeout: 10s
retries: 20
start_period: 15s
createbuckets:
image: minio/mc:latest
platform: linux/amd64
depends_on:
minio:
condition: service_healthy
restart: on-failure
entrypoint: >
/bin/sh -c "
/usr/bin/mc alias set local http://minio:9000 minio-root-user minio-root-password;
/usr/bin/mc mb --ignore-existing local/warehouse;
exit 0;
"
migrate:
image: quay.io/lakekeeper/catalog:latest-main
platform: linux/amd64
pull_policy: always
environment:
LAKEKEEPER__PG_ENCRYPTION_KEY: dev-key-not-secure
LAKEKEEPER__PG_DATABASE_URL_READ: postgresql://postgres:postgres@lakekeeper-db:5432/postgres
LAKEKEEPER__PG_DATABASE_URL_WRITE: postgresql://postgres:postgres@lakekeeper-db:5432/postgres
restart: "no"
command: ["migrate"]
depends_on:
lakekeeper-db:
condition: service_healthy
lakekeeper:
image: quay.io/lakekeeper/catalog:latest-main
platform: linux/amd64
pull_policy: always
environment:
LAKEKEEPER__PG_ENCRYPTION_KEY: dev-key-not-secure
LAKEKEEPER__PG_DATABASE_URL_READ: postgresql://postgres:postgres@lakekeeper-db:5432/postgres
LAKEKEEPER__PG_DATABASE_URL_WRITE: postgresql://postgres:postgres@lakekeeper-db:5432/postgres
command: ["serve"]
ports:
- "8181:8181"
healthcheck:
test: ["CMD", "/home/nonroot/lakekeeper", "healthcheck"]
interval: 2s
timeout: 10s
retries: 30
start_period: 10s
depends_on:
migrate:
condition: service_completed_successfully
lakekeeper-db:
condition: service_healthy
minio:
condition: service_healthy
createbuckets:
condition: service_completed_successfully
bootstrap:
image: alpine/curl
platform: linux/amd64
tty: true
stdin_open: true
depends_on:
lakekeeper:
condition: service_healthy
restart: "no"
entrypoint: /bin/sh
command:
- -c
- |
curl -sv -X POST http://lakekeeper:8181/management/v1/bootstrap \
-H 'Content-Type: application/json' \
--data '{"accept-terms-of-use": true}'
exit 0
initialwarehouse:
image: alpine/curl
platform: linux/amd64
tty: true
stdin_open: true
depends_on:
lakekeeper:
condition: service_healthy
bootstrap:
condition: service_completed_successfully
restart: "no"
entrypoint: /bin/sh
command:
- -c
- |
curl -sv -X POST http://lakekeeper:8181/management/v1/warehouse \
-H 'Content-Type: application/json' \
--data @/config/create-warehouse.json
exit 0
volumes:
- ./create-warehouse.json:/config/create-warehouse.json:ro
sentinel:
image: alpine
platform: linux/amd64
command: ["tail", "-f", "/dev/null"]
depends_on:
lakekeeper:
condition: service_healthy
initialwarehouse:
condition: service_completed_successfully
healthcheck:
test: ["CMD", "true"]
interval: 1s
retries: 1
start_period: 0s
data-loader:
image: trinodb/trino:476
platform: linux/amd64
profiles: ["loader"]
environment:
TPCH_SCALE: ${TPCH_SCALE:-tiny}
entrypoint: ["/bin/bash", "-c"]
command:
- |
set -euo pipefail
sed "s/FROM tpch\\.tiny\\./FROM tpch.$${TPCH_SCALE}./g" /test-data/init.sql > /tmp/init.run.sql
exec trino --server http://trino:8080 --user loader --file /tmp/init.run.sql
volumes:
- ../../docker/fixtures/init.docker-network.sql:/test-data/init.sql:ro
depends_on:
trino:
condition: service_healthy
sentinel:
condition: service_healthy
starrocks-catalog-setup:
image: mysql:8.0
platform: linux/amd64
profiles: ["loader"]
entrypoint: ["/bin/bash", "-c"]
command: ["mysql -h starrocks -P 9030 -u root --connect-timeout=30 < /setup/starrocks-setup.sql"]
volumes:
- ../../docker/fixtures/starrocks-setup.sql:/setup/starrocks-setup.sql:ro
depends_on:
starrocks:
condition: service_healthy
volumes:
queryflux-pg:
📄 Вспомогательные конфигурационные файлы
Файл `config.yaml` (настройки QueryFlux):
queryflux:
externalAddress: http://localhost:8080
frontends:
trinoHttp:
enabled: true
port: 8080
postgresWire:
enabled: true
port: 5434
persistence:
type: inMemory
clusters:
trino-1:
engine: trino
endpoint: http://trino:8080
enabled: true
auth:
type: basic
username: trino
password: ""
clusterGroups:
trino-default:
enabled: true
maxRunningQueries: 100
members: [trino-1]
routers:
- type: protocolBased
trinoHttp: trino-default
postgresWire: trino-default
routingFallback: trino-defaultФайл `trino-config/access-control.properties`:
access-control.name=allow-allЭтот файл монтируется в `trino` и разрешает имперсонацию и чтение системных таблиц – иначе статистика в QueryFlux Studio не будет работать.
Файл `./create-warehouse.json` (инициализация warehouse Lakekeeper):
{
"warehouse-name": "test_warehouse",
"project-id": "00000000-0000-0000-0000-000000000000",
"storage-profile": {
"type": "s3",
"bucket": "warehouse",
"endpoint": "http://minio:9000",
"region": "us-east-1",
"path-style-access": true,
"flavor": "minio",
"sts-enabled": false
},
"storage-credential": {
"type": "s3",
"credential-type": "access-key",
"aws-access-key-id": "minio-root-user",
"aws-secret-access-key": "minio-root-password"
}
}5. Запуск стека и проверка
Запускаем весь стек в фоновом режиме:
cd examples/full-stack
podman-compose up -d --wait5.1. Тест прямого доступа к Trino
curl -X POST http://localhost:8081/v1/statement \
-H 'X-Trino-User: test' \
-d 'SELECT 1'5.2. Тест через QueryFlux (PostgreSQL wire)
Подключимся через стандартный клиент `psql` к порту `5434`, который прослушивает QueryFlux:
psql -h localhost -p 5434 -U trino -d trinoСначала выполним простой запрос для проверки работоспособности протокола:
SELECT 42;А теперь проверим аналитический потенциал стека. Выполним тяжелый запрос к таблице `call_center` в БД Iceberg, сгенерированной по стандарту TPC-DS:
SELECT cc_call_center_sk, cc_call_center_id, cc_rec_start_date, cc_rec_end_date,
cc_closed_date_sk, cc_open_date_sk, cc_name, cc_class, cc_employees,
cc_sq_ft, cc_hours, cc_manager, cc_mkt_id, cc_mkt_class, cc_mkt_desc,
cc_market_manager, cc_division, cc_division_name, cc_company,
cc_company_name, cc_street_number, cc_street_name, cc_street_type,
cc_suite_number, cc_city, cc_county, cc_state, cc_zip, cc_country,
cc_gmt_offset, cc_tax_percentage
FROM tpcds.sf10.call_center;*Скриншот успешного выполнения запроса через psql*
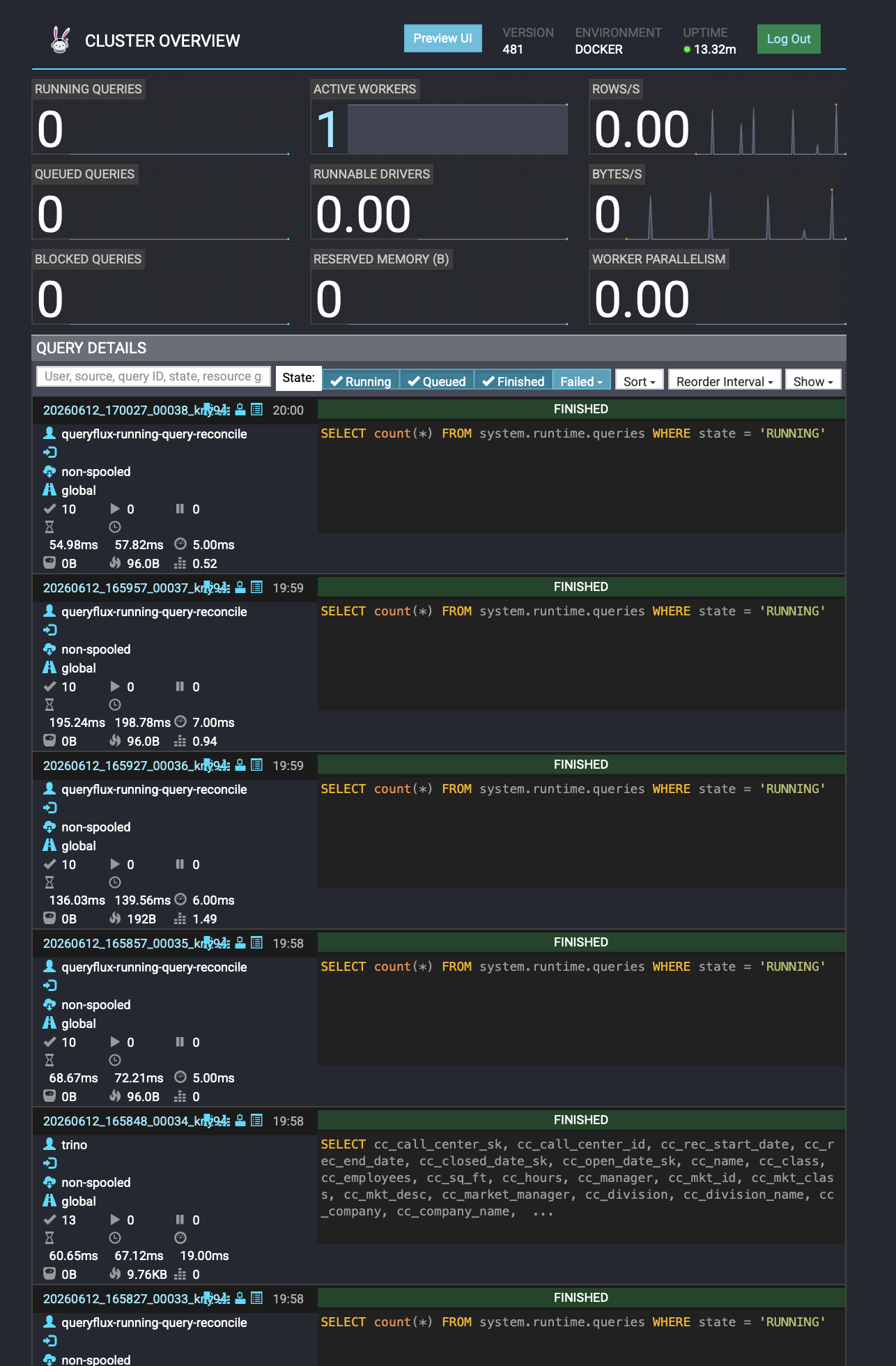
5.3. Проверка QueryFlux Studio
Откройте браузер и перейдите на `http://localhost:3000`. Логин по умолчанию: `admin` / `admin`.
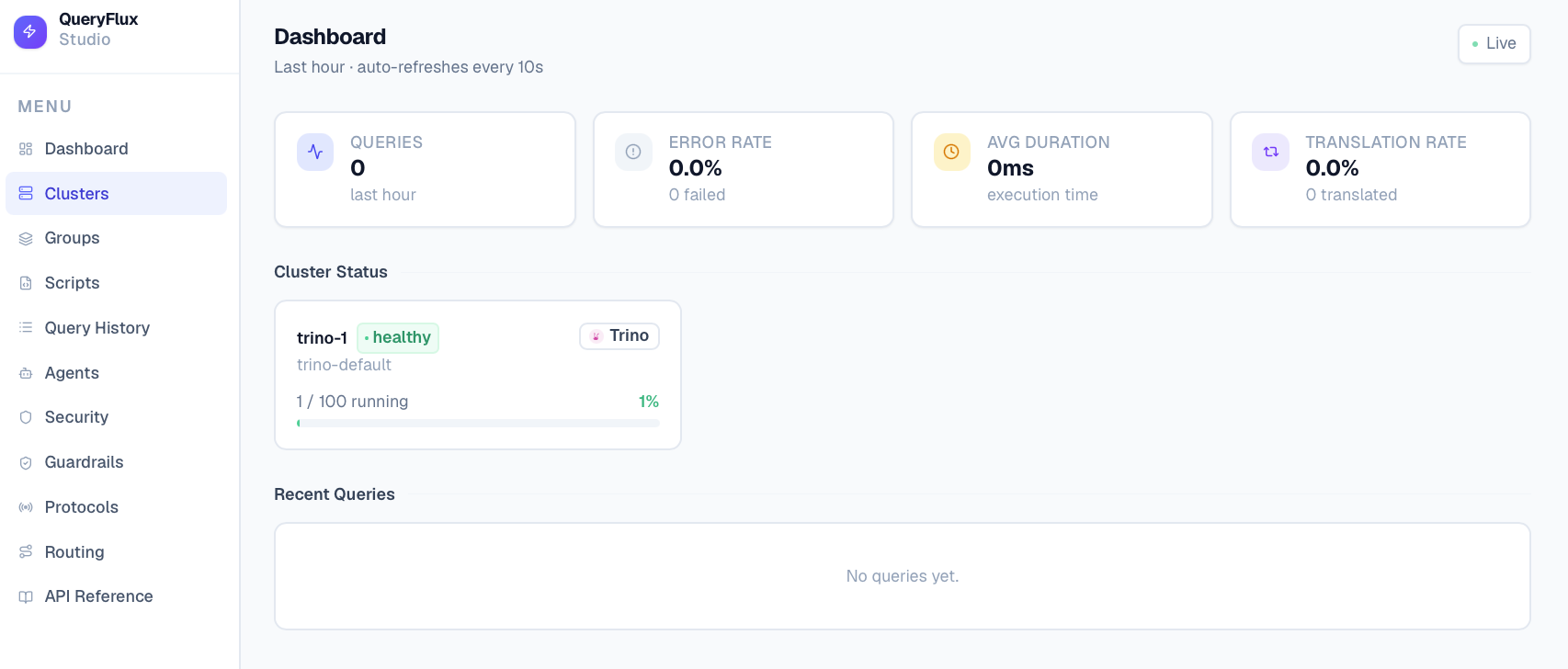
*Главная панель (Dashboard)*
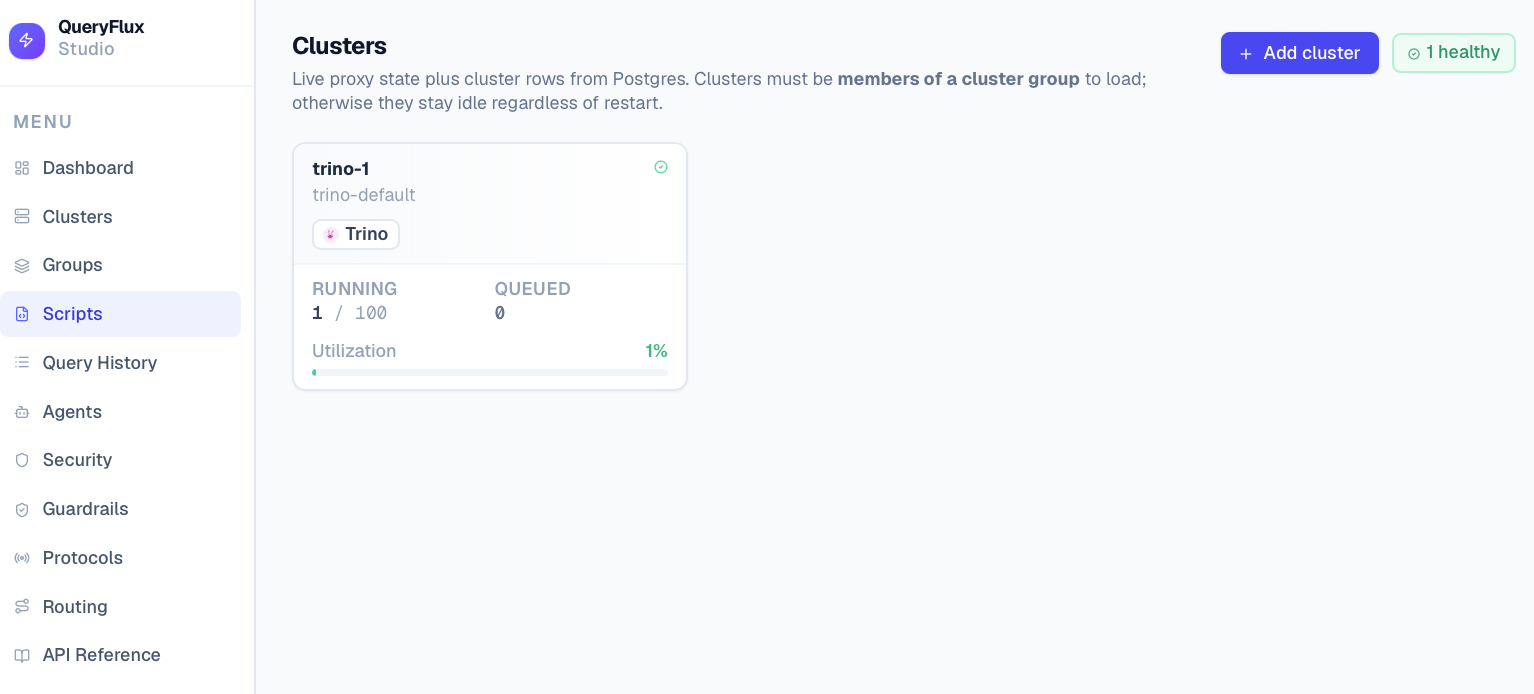
*Список кластеров*
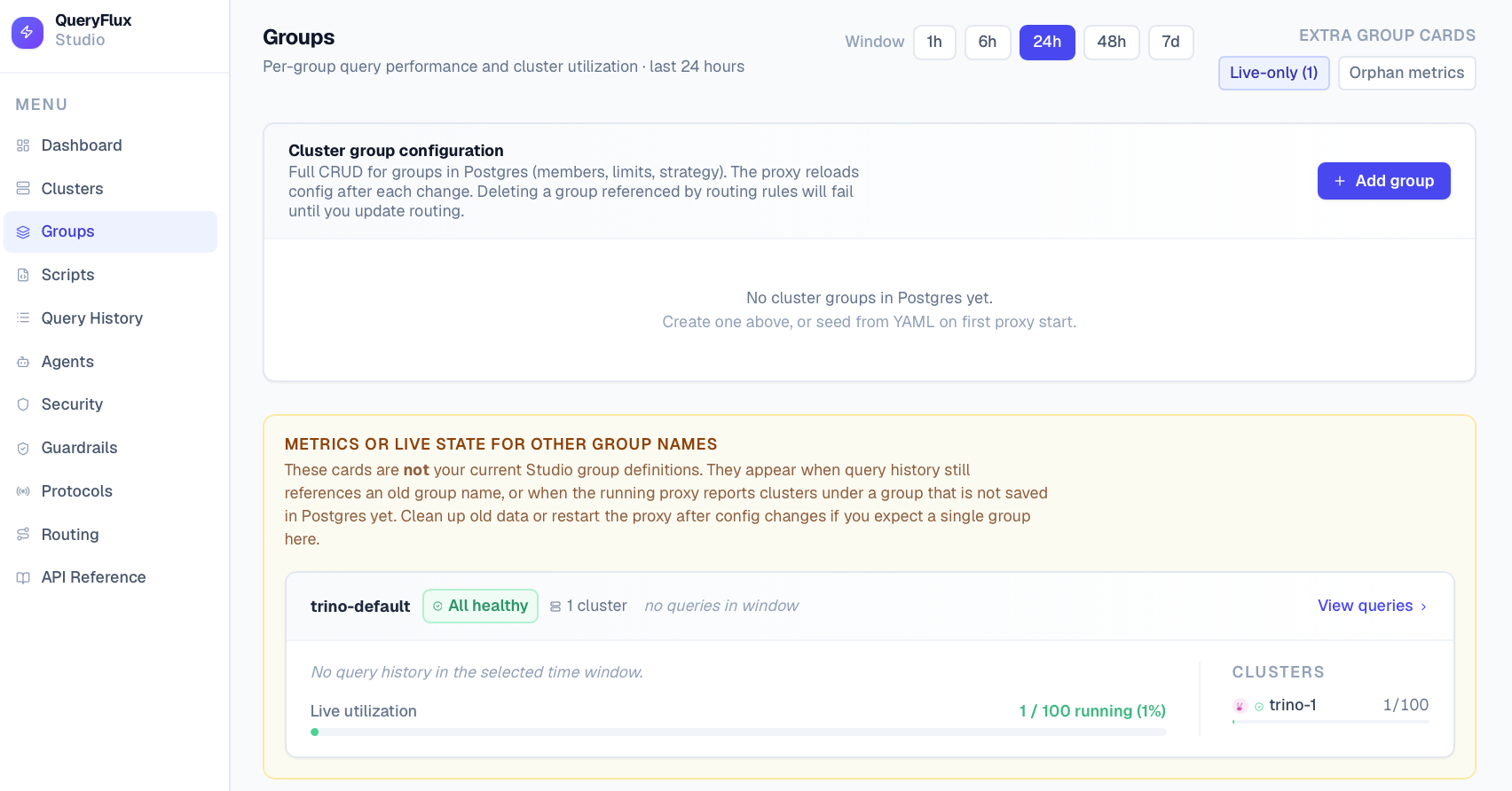
*Группы кластеров*
*Скрипты (translation fixups)*
*Guardrails (ограничения)*
*Протоколы (frontends)*
*Маршрутизация*
*Admin API (Swagger)*
6. Решение типичных проблем
🐞 1. Ошибка
internal libpod errorдля одноразовых контейнеров на macOS
Причина: podman-compose на macOS иногда имеет баг с `tty` и `stdin_open`.
Решение: Параметры уже добавлены в наш `docker-compose.yml`, но если баг не ушел, выполните инициализацию Lakekeeper вручную:
podman run --rm --network queryflux-example-full_default alpine/curl \
-X POST http://lakekeeper:8181/management/v1/bootstrap \
-H 'Content-Type: application/json' \
-d '{"accept-terms-of-use": true}'
🐞 2. PostgreSQL Extended Query Protocol
QueryFlux поддерживает только Simple Query Protocol (сообщение `Q`). Extended Query (Parse/Bind/Execute) не поддерживается.
- `psql` работает “из коробки”.
- JDBC-драйверы: добавьте параметр `prepareThreshold=0` в строку подключения, чтобы переключиться в Simple Query режим.
Пример:
jdbc:postgresql://localhost:5434/trino?prepareThreshold=0
🐞 3. Ошибка
Access Denied: User trino cannot impersonate user queryflux-running-query-reconcile
Причина: Trino не разрешает имперсонацию для системных запросов QueryFlux.
Решение: Мы добавили файл `access-control.properties` со свойством `access-control.name=allow-all`. После этого статистика в Studio заработала (см. Рис. 1 и Рис. 2).
7. Мониторинг и управление
QueryFlux предоставляет три основных интерфейса для наблюдения:
- QueryFlux Studio (порт 3000) – веб-интерфейс для просмотра истории запросов, управления кластерами, группами, маршрутами, скриптами и guardrails.
- Admin API (порт 9000) – REST API для автоматизации (логин: admin/admin). Документация OpenAPI доступна на `/docs`.
- Prometheus метрики (порт 9000/metrics) – стандартные метрики для интеграции с Grafana.
Рекомендуемая практика: для production используйте `persistence: postgres`, чтобы конфигурация групп и маршрутов сохранялась при перезапусках, а история запросов накапливалась.
8. Сравнение QueryFlux с альтернативами
8.1. Trino Gateway (официальный)
| Характеристика | QueryFlux | Trino Gateway |
| Поддерживаемые протоколы клиента | Trino HTTP, PostgreSQL wire, MySQL wire, Arrow Flight SQL | Только Trino HTTP |
| Бэкенды | Trino, DuckDB, StarRocks, Athena, ClickHouse (planned) | Только Trino |
| Маршрутизация | По протоколу, заголовкам, тегам, regex, Python скриптам | По весам, группам, header `X-Trino-Routing-Group` |
| SQL трансляция | Да (sqlglot) – из PostgreSQL в Trino и наоборот | Нет |
| Конкурентность и очереди | `maxRunningQueries` на группу, очередь на прокси, spillover | `maxConcurrentQueries` на кластер, очереди нет |
| Auth/AuthZ | OIDC, LDAP, Static, OpenFGA | Базовая поддержка `X-Trino-User` |
| Метрики | Prometheus, Grafana, Admin API, Studio | Prometheus (JMX), менее развит |
| GUI управления | Полноценный веб-интерфейс (Studio) | Отсутствует (только конфигурация API) |
Плюсы QueryFlux: гетерогенность (один шлюз на разные виды движков), гибкая маршрутизация, встроенный перевод диалектов, PostgreSQL wire, наличие красивого веб-интерфейса.
Минусы: молодой проект (версия 0.1.2), не поддерживается Extended Query Protocol для PostgreSQL, требует настройки доступа к системным таблицам Trino.
8.2. Другие альтернативы
- Trino + многокаталожность – простейшее решение, но требует доработки приложений для переключения на trino диалект.
- Apache Linkis – тяжеловесный ETL-ориентированный шлюз, не подходит для лёгкой ad-hoc аналитики.
- Nginx + Lua + sqlglot – сложно поддерживать, требует глубокой кастомной разработки.
- Коммерческие решения (Starburst, Dremio) – дорогостоящие, но предоставляют готовую маршрутизацию, закрытый код и полноценный SLA. но 100% всего не решает так как это готовые коробки. явно захочется что-то под себя подкрутить.
и еще много с акцентов на gateway: Hoop.dev кстати интересный и GatewayD
- GatewayD и ProxySQL: Не заменяют Trino, но отлично решают вашу задачу с логированием. GatewayD работает с PostgreSQL и может проверять запросы через Casbin, а ProxySQL предоставляет детальное логирование запросов (время, строки, IP и т.д.). Логирование — есть (аудит запросов), диалект Postgres — полный, подключение к 90 БД — сложно (нужно настраивать 90 подключений).
- Mammoth и JumpWire: Специализированные прокси для PostgreSQL. Первый упрощает аудит, логируя каждую команду, второй позволяет гибко настраивать политики доступа и маскировать данные. Логирование — есть, диалект Postgres — полный, подключение к 90 БД — сложно (на каждый экземпляр нужен свой прокси).
- Hoop.dev: Платформа для контролируемого доступа к базам данных с сильным акцентом на аудит и безопасность. Логирует все: от попыток входа до полного текста запросов и даже планов выполнения. Логирование — детальное, диалект Postgres — полный, подключение к 90 БД — сложно (требует развёртывания на каждую базу).
- Уже посмотрели QueryFlux: Это решение ближе всего к Trino, но работает как высокоуровневый шлюз. На входе может принимать запросы через “PostgreSQL wire”, а на выходе автоматически транслировать диалект под Trino, Clickhouse и другие системы. Логирование — ограниченное, диалект Postgres — только как входной интерфейс (запросы уходят в Trino), подключение к 90 БД — замена Trino (шлюз к 90 разным источникам).
- SQL Gateway (CData): Позволяет представить любые ODBC-источники как виртуальную PostgreSQL или SQL Server базу. Логирование — только общее, диалект Postgres — виртуальный (эмуляция), подключение к 90 БД — сложно (настройка ODBC).
- Cloud Service Gateways (Infisical и др.): Специализированные облачные решения. Обещают централизованный доступ и аудит, но их возможности нативных диалектов сильно привязаны к конкретному провайдеру.
- Native PostgreSQL Gateways: Как сборник технологий (например, PgCat), из которых можно построить своё решение. Позволяет гибко настраивать подключения и логи, но требует ручной сборки и высокой квалификации.
Интеграция с Keycloak: К сожалению, прямой интеграции с Keycloak для аутентификации SQL-запросов практически нет. Keycloak используется для аутентификации доступа к веб-интерфейсам административных консолей, но не для самих SQL-клиентов. Исключение — GatewayD, который, хотя и не интегрируется с Keycloak, позволяет реализовать схожую логику через Casbin.
Вывод: QueryFlux идеален, если у вас уже есть несколько движков и вы хотите дать единую точку входа для бизнес-пользователей и аналитиков (особенно тех, кто привык к `psql`). Для production, где критична поддержка prepare-statements, стоит использовать Trino JDBC напрямую или использовать дополнительный прокси (например, `trino-pg-gateway`).
9. Итоги и рекомендации
Мы успешно запустили полноценный аналитический стек с Lakekeeper (Iceberg), Trino и StarRocks, а QueryFlux обеспечил единый вход через HTTP и PostgreSQL wire. Ключевые достижения:
- ✅ QueryFlux принимает Trino HTTP и PostgreSQL wire запросы, направляя их в Trino.
- ✅ Клиент `psql` выполняет сложные `SELECT`-запросы к Iceberg таблицам (даже TPC-DS) через порт 5434.
- ✅ Статистика в Studio отображается корректно.
- ✅ Маршрутизация по протоколу (`protocolBased`) работает как задумано.
- ✅ Веб-интерфейс Studio даёт полный контроль над кластерами, группами, маршрутами и скриптами.
Рекомендации для production:
- Замените `persistence: inMemory` на `persistence: postgres` и настройте репликацию БД конфигурации (чтобы не терять историю и настройки).
- Включите аутентификацию OIDC (Keycloak) и авторизацию OpenFGA для разграничения доступа к группам кластеров.
- Рассчитайте `maxRunningQueries` по формуле N = R \times T, исходя из планируемой нагрузки и SLA.
- Для PostgreSQL-клиентов с GUI (DataGrip/DBeaver) используйте параметр `prepareThreshold=0` (через JDBC) или переключитесь на официальный Trino JDBC драйвер.
- Настройте сбор метрик в Prometheus и дашборды Grafana для мониторинга длины очередей и задержек.
Заключение: QueryFlux — очень перспективный и многообещающий инструмент для построения унифицированного доступа к аналитическим движкам. Несмотря на молодость, он уже пригоден для некоторых сценариев, особенно если вы готовы ограничиться simple query protocol при использовании PostgreSQL wire. В связке с Iceberg-каталогами и объектным хранилищем он образует мощную open-source альтернативу дорогим коммерческим решениям.