
Сравнительный анализ self-hosted S3-совместимых хранилищ
Четкое сравнение семи self-hosted S3-совместимых решений для хранения данных.
Оригинал тут: Команда RepoFlow. 9 августа 2025 г.
Локальное (self-hosted) объектное хранилище — это отличный выбор для разработчиков и команд, которые хотят иметь полный контроль над хранением и доступом к своим данным. Независимо от того, заменяете ли вы Amazon S3, размещаете внутренние файлы, создаете CI-конвейер или обслуживаете репозитории пакетов, уровень хранения может значительно повлиять на скорость и стабильность.
Мы протестировали семь популярных решений для объектного хранения, поддерживающих протокол S3. Цель состояла в том, чтобы сравнить их производительность в идентичных условиях, используя реальные операции загрузки и скачивания.
Тестируемые решения
Каждое из следующих решений было развернуто с помощью Docker на одном и том же сервере без монтирования томов и без специальной настройки:
- `MinIO`
- `Ceph`
- `SeaweedFS`
- `Garage`
- `Zenko` (Scality Cloudserver)
- `LocalStack`
- `RustFS`
Скорость последовательного скачивания
Средняя скорость скачивания одного файла разного размера.
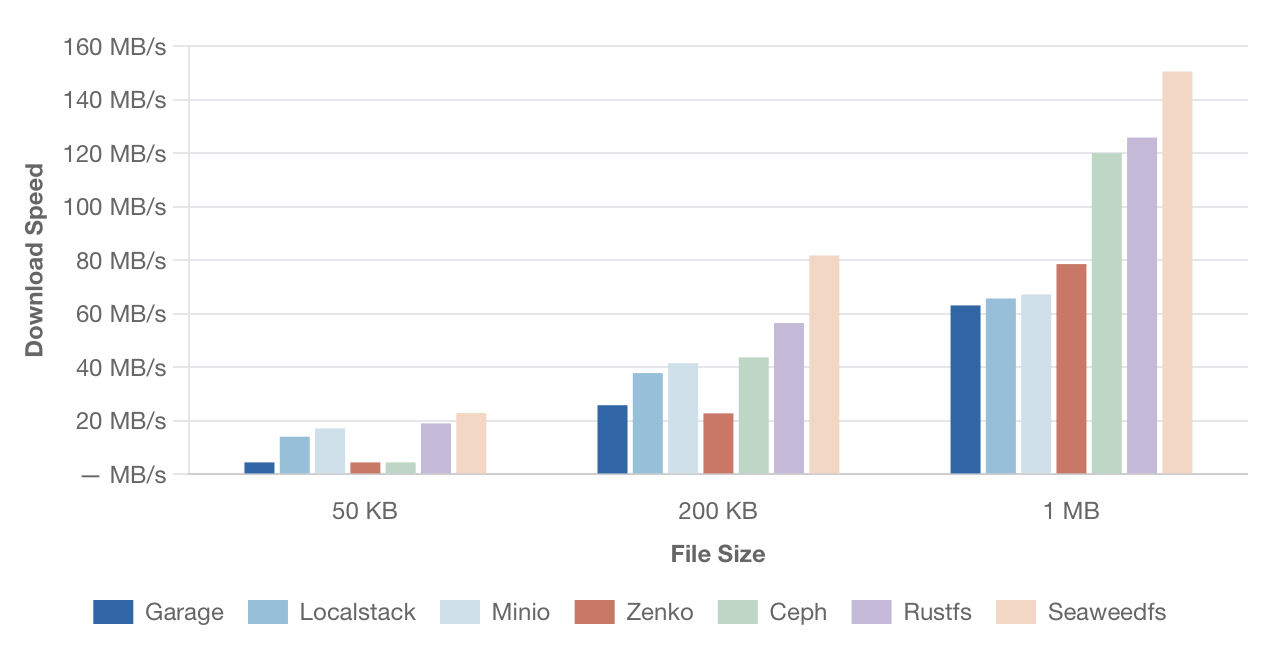
[Изображение: График скорости последовательного скачивания для малых файлов размером 50 КБ и 200 КБ. По оси Y — скорость в МБ/с, по оси X — размер файла. Сравниваются Garage, Localstack, Minio, Zenko, Ceph, RustFS, SeaweedFS.]
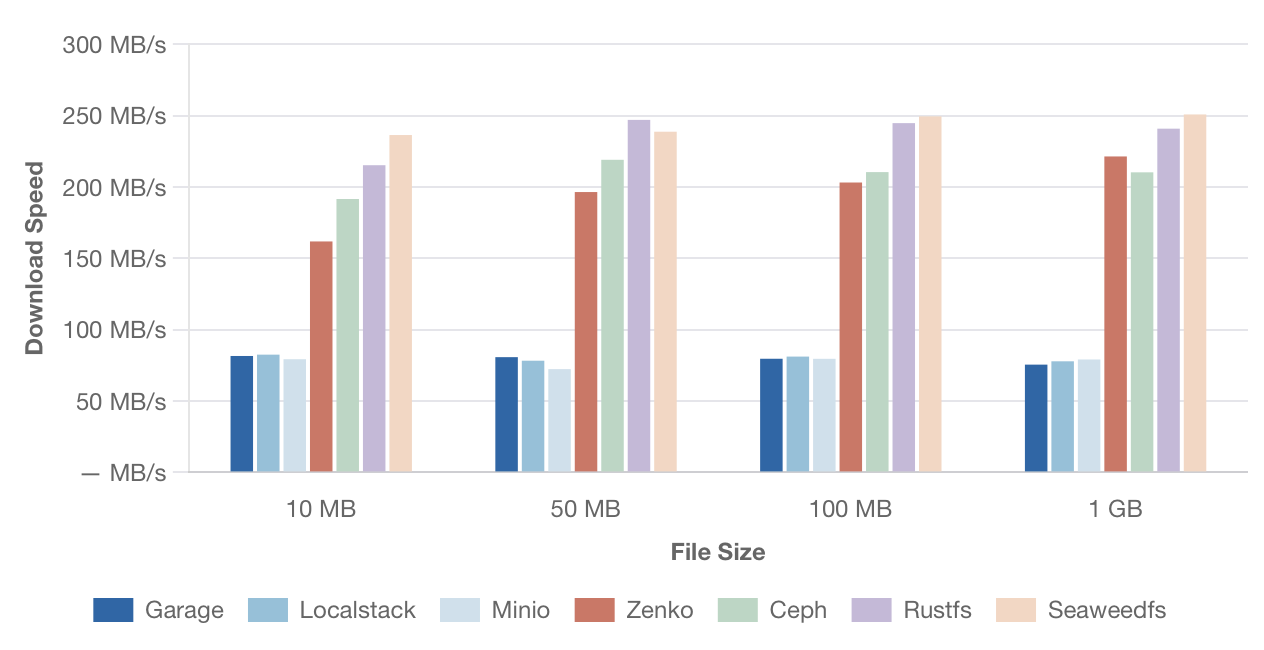
[Изображение: График скорости последовательного скачивания для больших файлов размером 10 МБ, 50 МБ, 100 МБ и 1 ГБ. По оси Y — скорость в МБ/с, по оси X — размер файла. Сравниваются те же решения.]
Скорость последовательной загрузки
Средняя скорость загрузки одного файла разного размера.
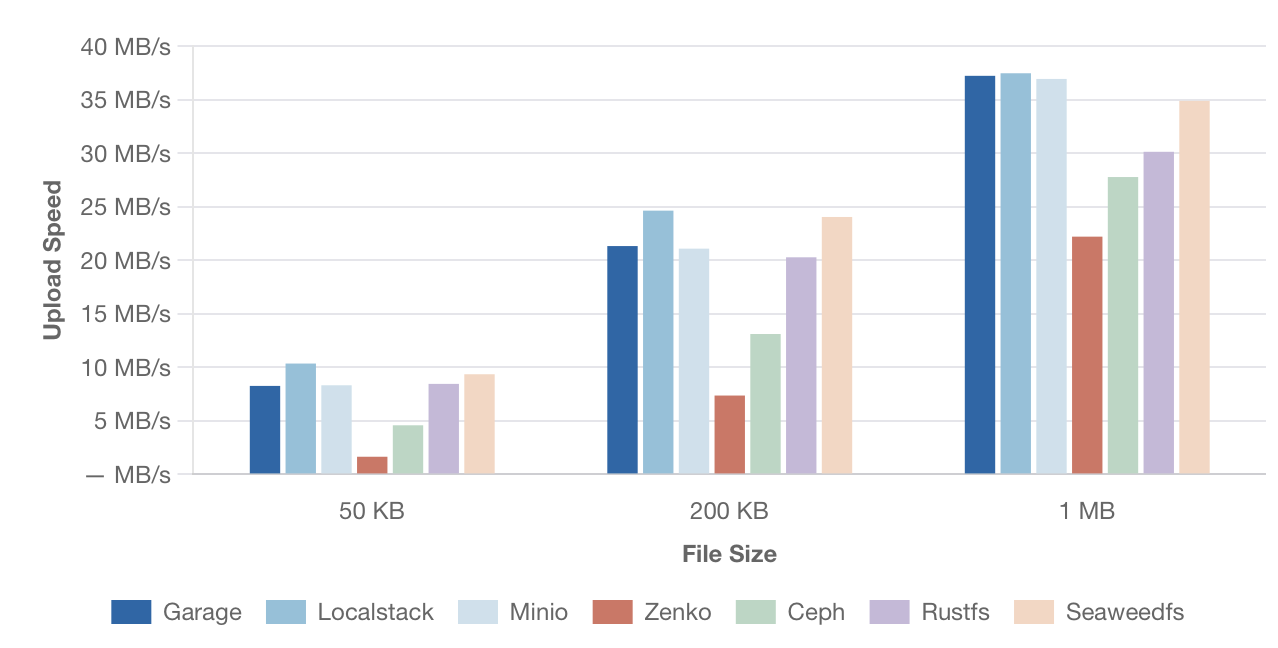
[Изображение: График скорости последовательной загрузки для малых файлов размером 50 КБ и 200 КБ. По оси Y — скорость в МБ/с, по оси X — размер файла. Сравниваются те же решения.]
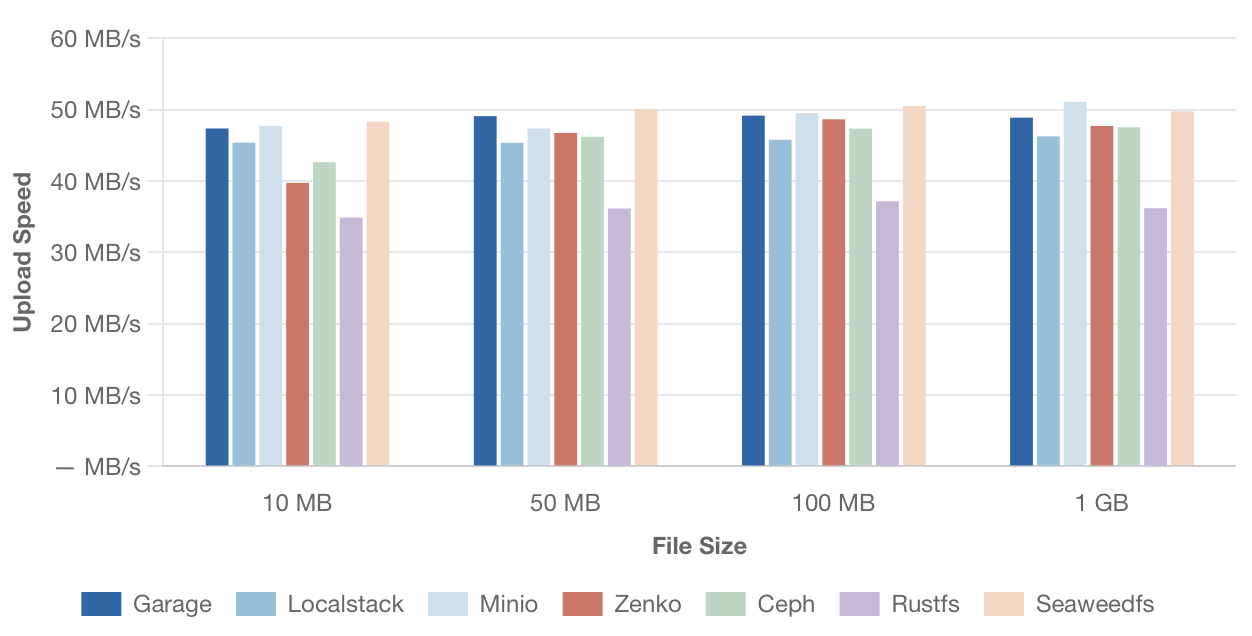
[Изображение: График скорости последовательной загрузки для больших файлов размером 10 МБ, 50 МБ, 100 МБ и 1 ГБ. По оси Y — скорость в МБ/с, по оси X — размер файла. Сравниваются те же решения.]
Производительность листинга
Измеряет время, необходимое для получения списка всех 2000 тестовых объектов в бакете с использованием разных размеров страницы (100, 500 и 1000 результатов на запрос).
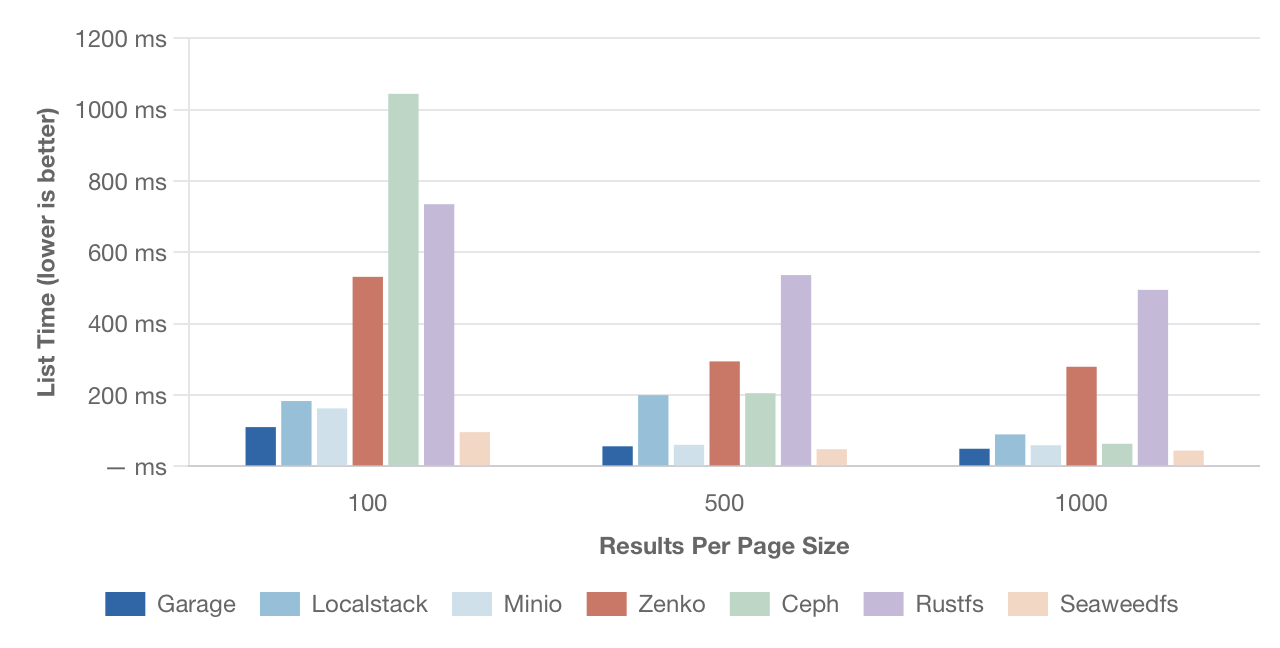
[Изображение: График производительности листинга. По оси Y — время в мс, по оси X — количество результатов на страницу (100, 500, 1000). Сравниваются те же решения.]
Скорость параллельной загрузки
Измеряет время, необходимое для параллельной загрузки нескольких файлов одинакового размера. Скорость загрузки рассчитывается по формуле:
(number of files × file size) ÷ total time
Скорость параллельной загрузки – файлы 1 МБ
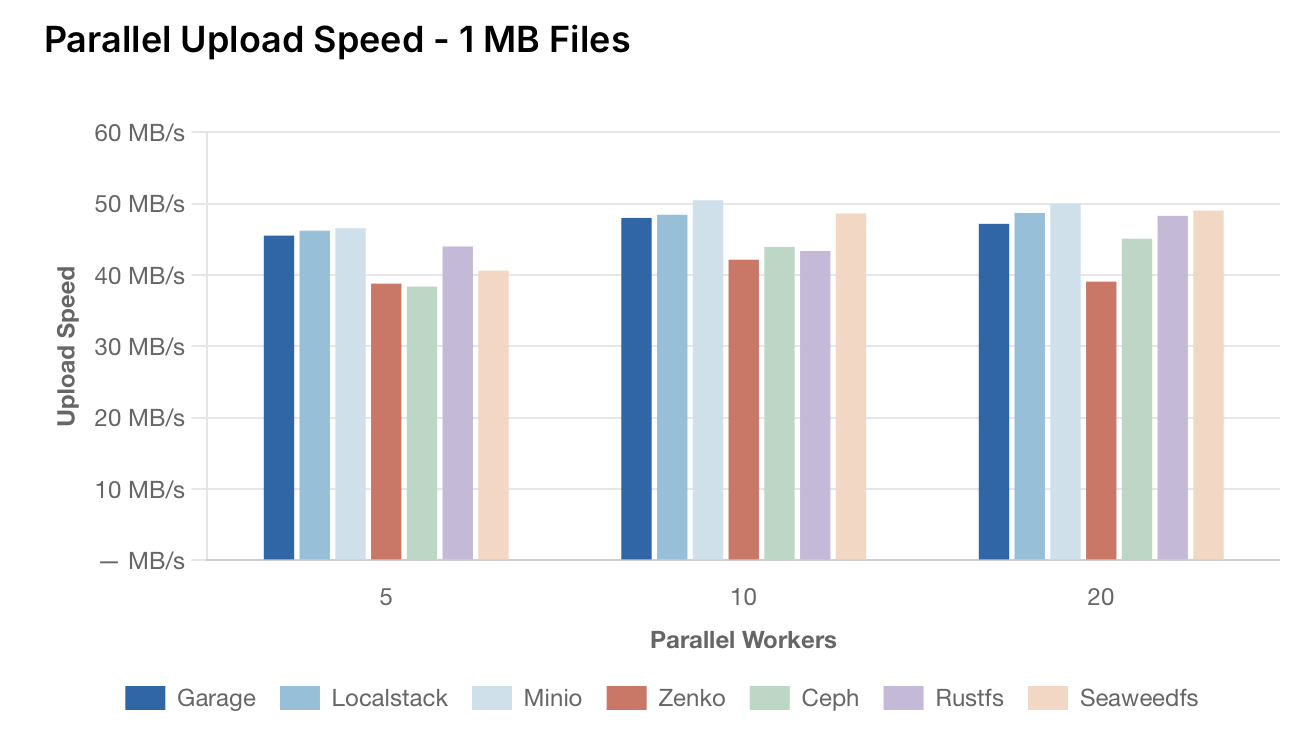
[Изображение: График скорости параллельной загрузки файлов размером 1 МБ. По оси Y — скорость в МБ/с, по оси X — количество параллельных потоков (5, 10, 20). Сравниваются те же решения.]
Скорость параллельной загрузки – файлы 10 МБ
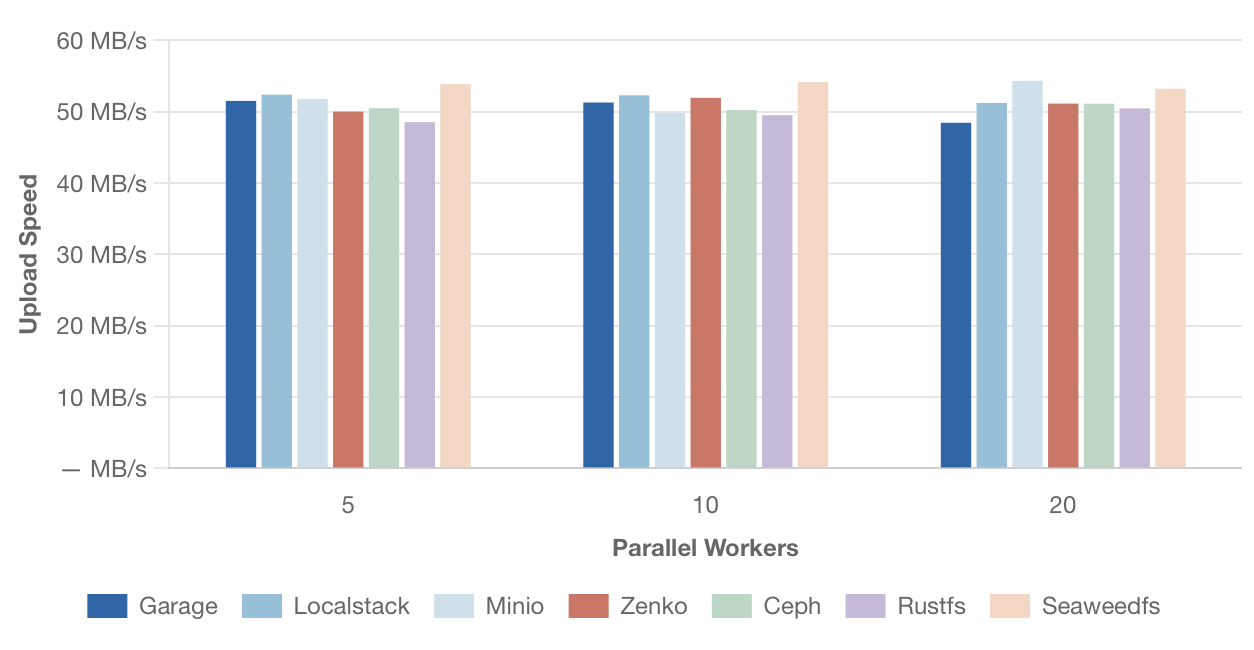
[Изображение: График скорости параллельной загрузки файлов размером 10 МБ. По оси Y — скорость в МБ/с, по оси X — количество параллельных потоков (5, 10, 20). Сравниваются те же решения.]
Скорость параллельной загрузки – файлы 100 МБ
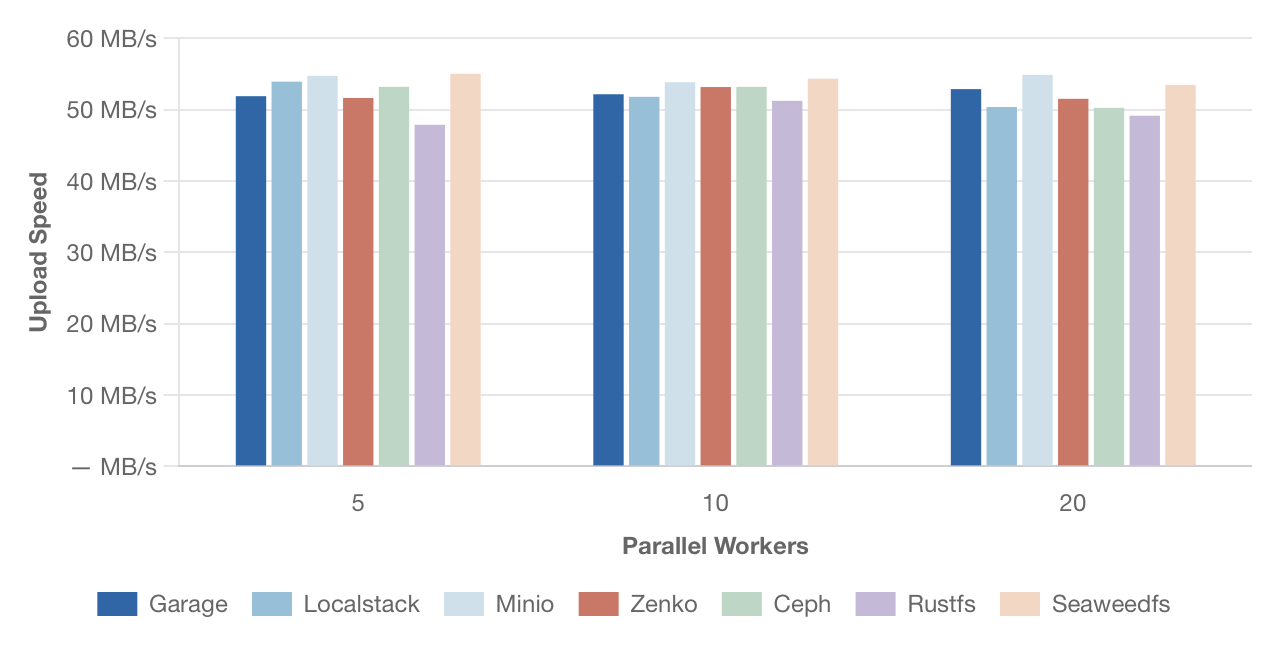
[Изображение: График скорости параллельной загрузки файлов размером 100 МБ. По оси Y — скорость в МБ/с, по оси X — количество параллельных потоков (5, 10, 20). Сравниваются те же решения.]
Скорость параллельного скачивания
Измеряет время, необходимое для параллельного скачивания нескольких файлов одинакового размера. Скорость скачивания рассчитывается по формуле:
(number of files × file size) ÷ total time
Скорость параллельного скачивания – файлы 1 МБ
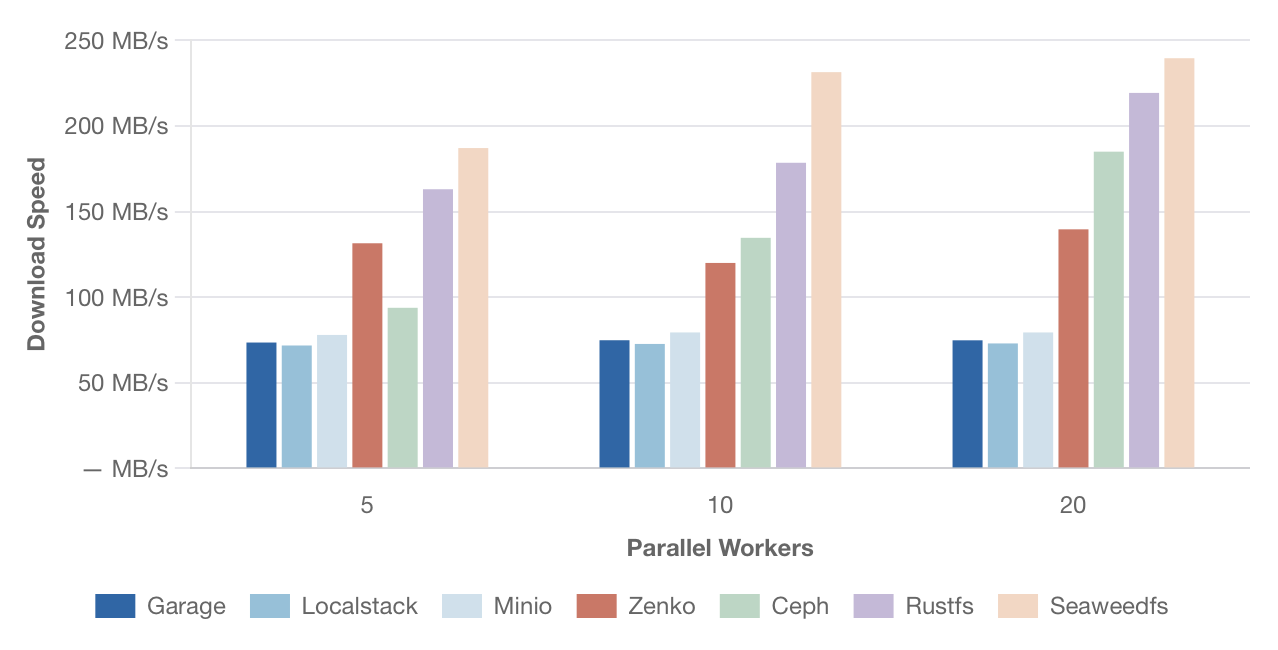
[Изображение: График скорости параллельного скачивания файлов размером 1 МБ. По оси Y — скорость в МБ/с, по оси X — количество параллельных потоков (5, 10, 20). Сравниваются те же решения.]
Скорость параллельного скачивания – файлы 10 МБ
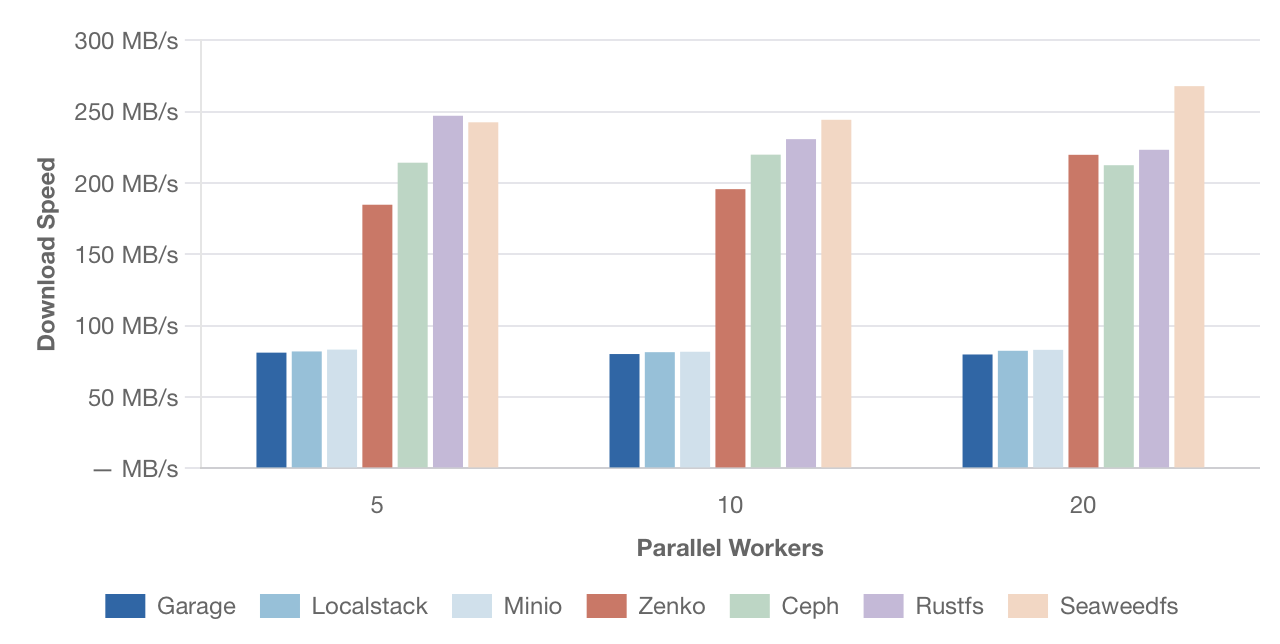
[Изображение: График скорости параллельного скачивания файлов размером 10 МБ. По оси Y — скорость в МБ/с, по оси X — количество параллельных потоков (5, 10, 20). Сравниваются те же решения.]
Скорость параллельного скачивания – файлы 100 МБ
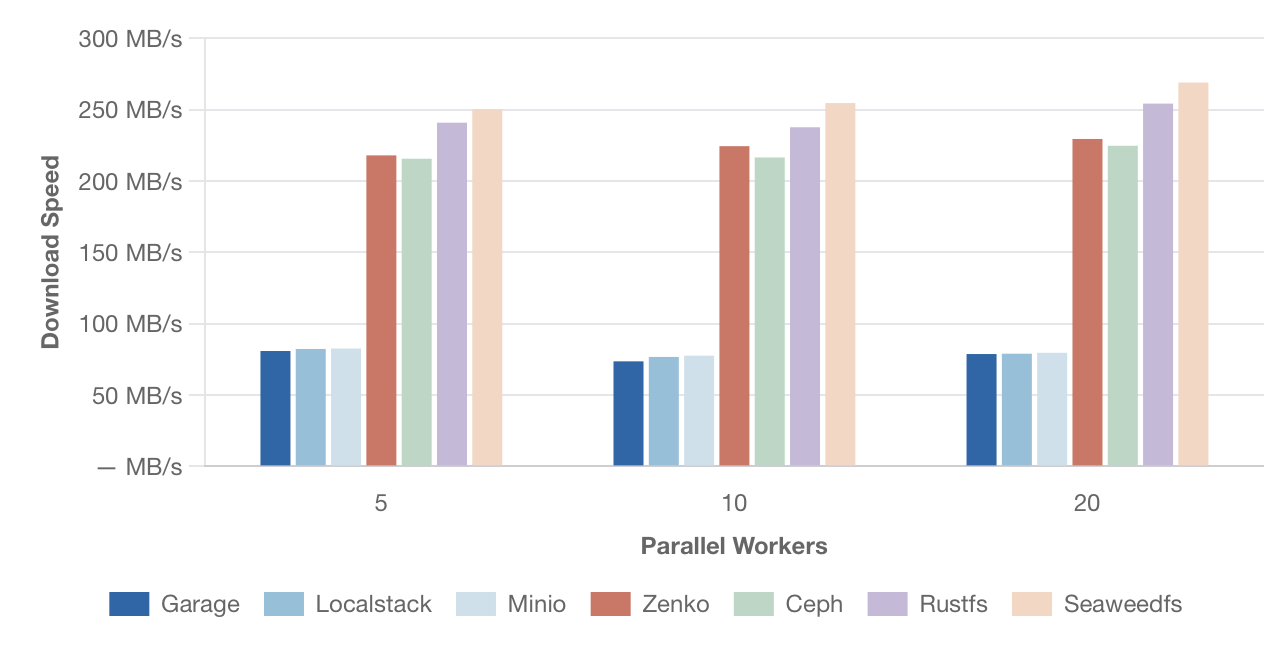
[Изображение: График скорости параллельного скачивания файлов размером 100 МБ. По оси Y — скорость в МБ/с, по оси X — количество параллельных потоков (5, 10, 20). Сравниваются те же решения.]
Как проводились тесты
Для каждого решения мы:
- Загружали и скачивали файлы 7 различных размеров: 50 КБ, 200 КБ, 1 МБ, 10 МБ, 50 МБ, 100 МБ и 1 ГБ.
- Повторяли каждую загрузку и скачивание 20 раз для получения стабильных средних значений.
- Измеряли среднюю скорость загрузки и скачивания в мегабайтах в секунду (МБ/с).
- Выполняли все тесты на одной и той же машине, используя стандартный Docker-контейнер для каждой системы хранения, без внешних томов, монтирования или кешей.
Все решения тестировались в одноузловой конфигурации для обеспечения согласованности. Хотя некоторые системы (например, `Ceph`) спроектированы для лучшей производительности в кластерной среде, мы использовали одинаковые условия для всех решений, чтобы гарантировать справедливое сравнение.
Заключительные мысли
Эти результаты показывают, как каждое решение вело себя в нашей конкретной тестовой среде с одним узлом. Их следует рассматривать как относительное сравнение соотношений производительности, а не как абсолютные жесткие значения, которые будут применимы в любой конфигурации.
При выборе подходящего решения для хранения данных учитывайте типичные размеры файлов, которые вы будете хранить, поскольку одни системы лучше справляются с маленькими файлами, а другие преуспевают с большими. Также подумайте об основных возможностях, которые вам требуются, таких как масштабируемость, репликация, долговечность или встроенный графический интерфейс. Наконец, помните, что производительность может сильно отличаться между одноузловыми и многоузловыми кластерами.
Наши тесты предоставляют базовый уровень для понимания того, как эти системы соотносятся в идентичных условиях, но ваша реальная производительность будет зависеть от вашего конкретного оборудования, рабочей нагрузки и конфигурации.