https://medium.com/airbnb-engineering/data-quality-score-the-next-chapter-of-data-quality-at-airbnb-851dccda19c3
Автор: Кларк Райт
Введение
В наши дни, с увеличением объема данных, собираемых компаниями, мы все осознаем, что больше данных не всегда означает лучше. Фактически больше данных, особенно если нельзя полагаться на их качество, может замедлить компанию, затруднить принятие решений или привести к плохим решениям.
С 1,4 миллиарда кумулятивных посещений гостей на конец 2022 года рост Airbnb вынудил нас прийти к точке перегиба, где ухудшение качества данных начало препятствовать работе наших специалистов по данным. Еженедельные отчеты по метрикам были трудно подготовить в срок. Вроде бы базовые метрики, такие как “Активные объявления”, зависели от сложной сети зависимостей. Для проведения значимой работы с данными требовалось значительное институциональное знание для преодоления скрытых трудностей с данными.
Для решения этой проблемы мы ввели процесс Midas для подтверждения наших данных. Начиная с 2020 года процесс Midas, вместе с работой по переархитектуре наших самых важных моделей данных, привел к драматическому повышению качества и своевременности данных для самых критически важных данных Airbnb. Однако достижение полных критериев качества данных, требуемых Midas, требует значительных кросс-функциональных инвестиций для проектирования, разработки, проверки и поддержания необходимых активов данных и документации.
Хотя это имело смысл для наших самых важных данных, достижение таких строгих стандартов в масштабах представляло сложности. Мы подходили к моменту убыточности вложений в качество данных. Мы подтвердили наши самые критические активы, восстанавливая их надежность. Однако для всех наших несертифицированных данных, которые оставались большинством наших офлайн-данных, нам не хватало видимости в их качество и не было четких механизмов для повышения его уровня.
Как мы могли бы распространить выигрыши и лучшие практики Midas на весь наш хранилище данных?
В этом блоге мы расскажем о нашем инновационном подходе к оценке качества данных — Оценке качества данных Airbnb (“DQ Score”). Мы расскажем, как мы разработали DQ Score, как он используется сегодня и как он будет поддерживать следующий этап обеспечения качества данных в Airbnb.
Масштабирование качества данных
В 2022 году мы начали исследование идей по масштабированию качества данных за пределами сертификации Midas. Производители данных запрашивали процесс более легкого веса, который мог бы предоставить некоторые ограждающие поручни качества Midas, но с меньшей строгостью и временными затратами. В то же время потребители данных продолжали летать слепо на всех данных, которые не были сертифицированы Midas. Бренд вокруг сертифицированных данных Midas был настолько сильным, что потребители начали сомневаться, стоит ли доверять каким-либо несертифицированным данным. Чтобы избежать разбавления бренда Midas, мы хотели избежать введения упрощенной версии сертификации, которая дополнительно стратифицировала бы наши данные, не открыв при этом долгосрочной масштабируемости.
Решив эти проблемы, мы решили перейти к стратегии качества данных, направленной на то, чтобы прямо подталкивать стимулы в области качества данных к производителям и потребителям данных. Мы приняли решение, что мы больше не можем полагаться на принуждение для масштабирования качества данных в Airbnb, и вместо этого нам нужно полагаться на поощрение как производителя данных, так и потребителя.
Для полного включения этого подхода поощрения мы считали важным представить концепцию оценки качества данных, прямо связанную с данными активами.
Мы определили следующие цели для оценки:
Эволюция нашего понимания качества данных за пределами простого двоичного определения (сертифицированные против несертифицированных).
Выравнивание входных компонентов для оценки качества данных.
Обеспечение полной видим
ости в качество нашего офлайн-хранилища данных и отдельных данных активов. Эта видимость должна 1) создавать естественные стимулы для производителей для улучшения качества данных, которые они владеют, и 2) стимулировать спрос на данные высокого качества со стороны потребителей данных и позволять им решать, является ли качество подходящим для их потребностей.
Составление оценки
Прежде чем погружаться в тонкости измерения качества данных, мы достигли согласия по видению, определив принципы направления DQ Score. При участии многофункциональной группы практиков данных мы выработали согласие по следующим основным принципам:
Полное охват — оценка может быть применена к любому активу данных офлайн-хранилища данных
Автоматизированность — сбор входных данных, определяющих оценку, на 100% автоматизирован
Действенность — оценка легко обнаруживается и используется как для производителей, так и для потребителей
Многомерность — оценку можно разложить на столбы качества данных
Эволютивность — критерии оценки и их определения могут меняться со временем
Хотя они могут показаться простыми или очевидными, установка этих принципов была критичной, поскольку они направляли каждое принятое решение в разработке оценки. Вопросы, которые в противном случае могли бы сорвать прогресс, были сопоставлены нашими принципами.
Например, наши принципы были критичными при определении того, какие элементы из нашего списка желаемых критериев оценки следует рассматривать. Было несколько входов, которые, конечно, могли бы нам помочь измерить качество, но если их нельзя было измерить автоматически (Автоматизированность) или если они были настолько запутанными, что практики данных не могли бы понять, что означает или как это можно улучшить (Действенность), то они были отклонены.
У нас также был ряд входных сигналов, которые более прямо измеряли качество (сертификация Midas, проверка данных, ошибки, SLA, автоматические проверки качества данных и т. д.), в то время как другие были более похожи на показатели качества (например, правильная принадлежность, хорошая гигиеничность управления, использование инструментов планирования). Были ли более явные и прямые измерения качества более ценными, чем показатели?
Руководствуясь нашими принципами, мы в конечном итоге определили четыре измерения качества данных: Точность, Надежность (Своевременность), Управление и Удобство использования. Было несколько других возможных измерений, которые мы рассматривали, но эти четыре измерения были наиболее смысловыми и полезными для наших практиков данных и имели смысл как оси улучшения, на которых нам важно и мы готовы инвестировать в улучшение наших данных вдоль этих измерений.
Каждое измерение могло объединять неявные и явные показатели качества, где ключевое заключалось в том, что не каждый потребитель данных должен полностью понимать каждый отдельный компонент оценки, но они будут понимать, что набор данных, который плохо справляется с Надежностью и Удобством использования.
Мы также могли бы взвесить каждое измерение в соответствии с нашим восприятием его важности для определения качества. Мы учитывали 1) сколько оценочных компонентов принадлежит каждому измерению, 2) обеспечивая быстрый умственный расчет, и 3) какие элементы важны больше всего для наших практикующих, чтобы распределить 100 общих баллов между измерениями:
The “Dimensions of Data Quality” and their weights
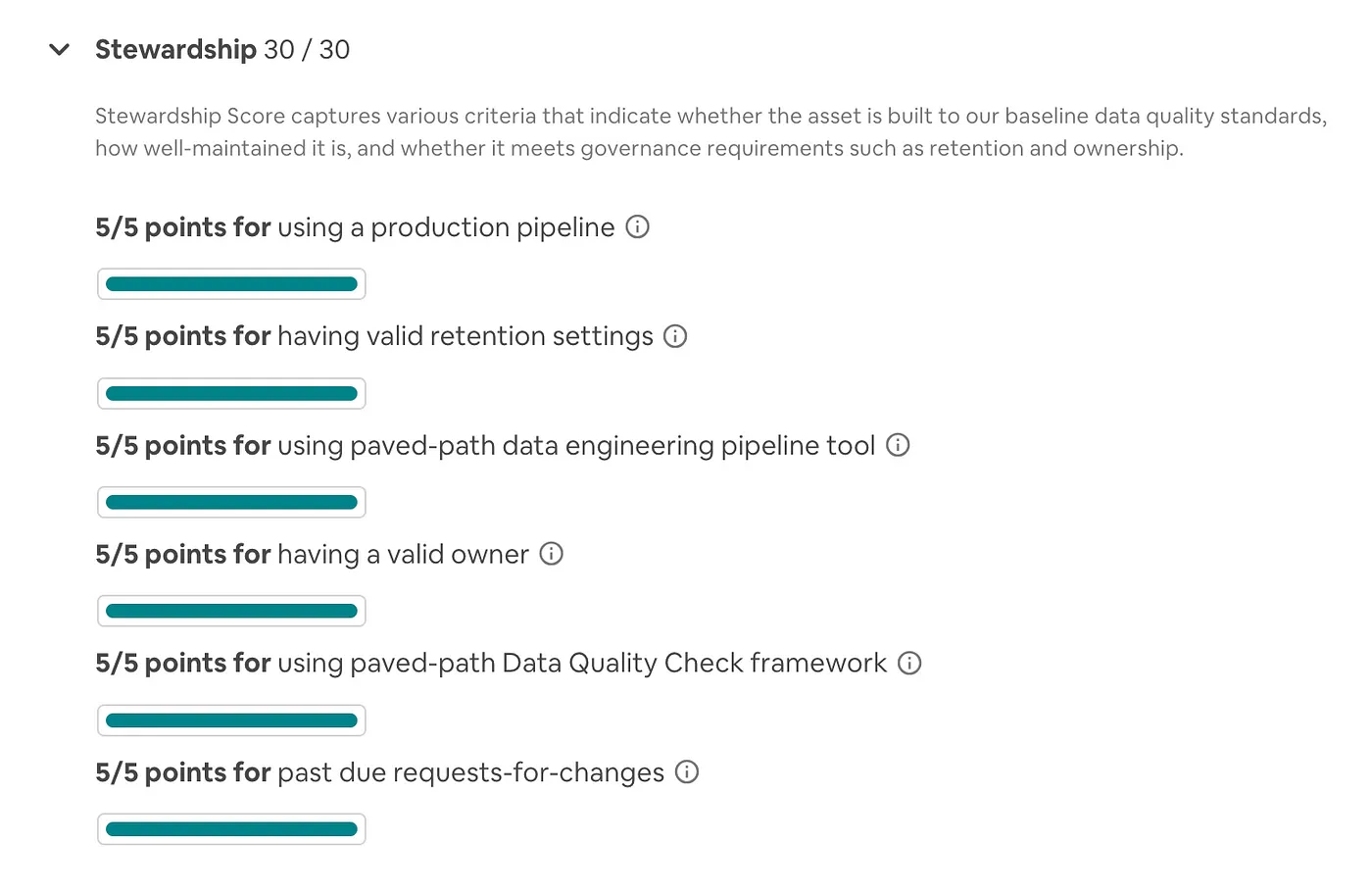
Тем временем, при необходимости, измерения могут быть раскрыты для получения более детального представления о проблемах качества данных. Например, измерение “Стюардшип” оценивает актив для показателей качества, таких как то, построено ли оно с использованием наших инструментов для инженерии данных, его соблюдение правил управления, и соответствие стандартам валидного владения данных.
Unpacking the Data Stewardship Dimension
Представление Рейтинга для Практиков
Мы понимали, что представление Рейтинга качества данных в формате, который можно исследовать и использовать, является ключевым моментом для его принятия и успеха. Кроме того, нам нужно было предоставить информацию о качестве данных непосредственно в том месте, где пользователи данных уже обнаруживали и исследовали данные.
К счастью, у нас было два существующих инструмента, которые сделали бы это гораздо проще: Dataportal (каталог данных и пользовательский интерфейс для исследования данных Airbnb) и Unified Metadata Service (UMS). Сам рейтинг вычисляется в ежедневном автономном потоке данных, который собирает и преобразует различные элементы метаданных из наших систем данных. Завершающий этап потока данных загружает рейтинг для каждого актива данных в UMS. Подключив DQ Score к UMS, мы можем предоставлять рейтинг и его компоненты наряду с каждым активом данных в Dataportal, отправной точке для всех открытий и исследований данных в Airbnb. Оставалось только разработать его представление.
Одной из наших целей было предоставить концепцию качества данным практикующим с различным уровнем экспертизы и потребностей. Наши пользователи полностью приняли динамичный подход “сертифицированные против несертифицированных”, но впервые мы представляли концепцию спектра качества, а также критерии, используемые для его определения.
Какова была бы наиболее интерпретируемая версия Рейтинга качества данных? Нам нужно было представить единый рейтинг качества данных, который был бы понятен на первый взгляд, а также делать возможным исследование рейтинга более подробно.
Наш конечный дизайн представляет качество данных тремя способами, каждый со своим особым применением:
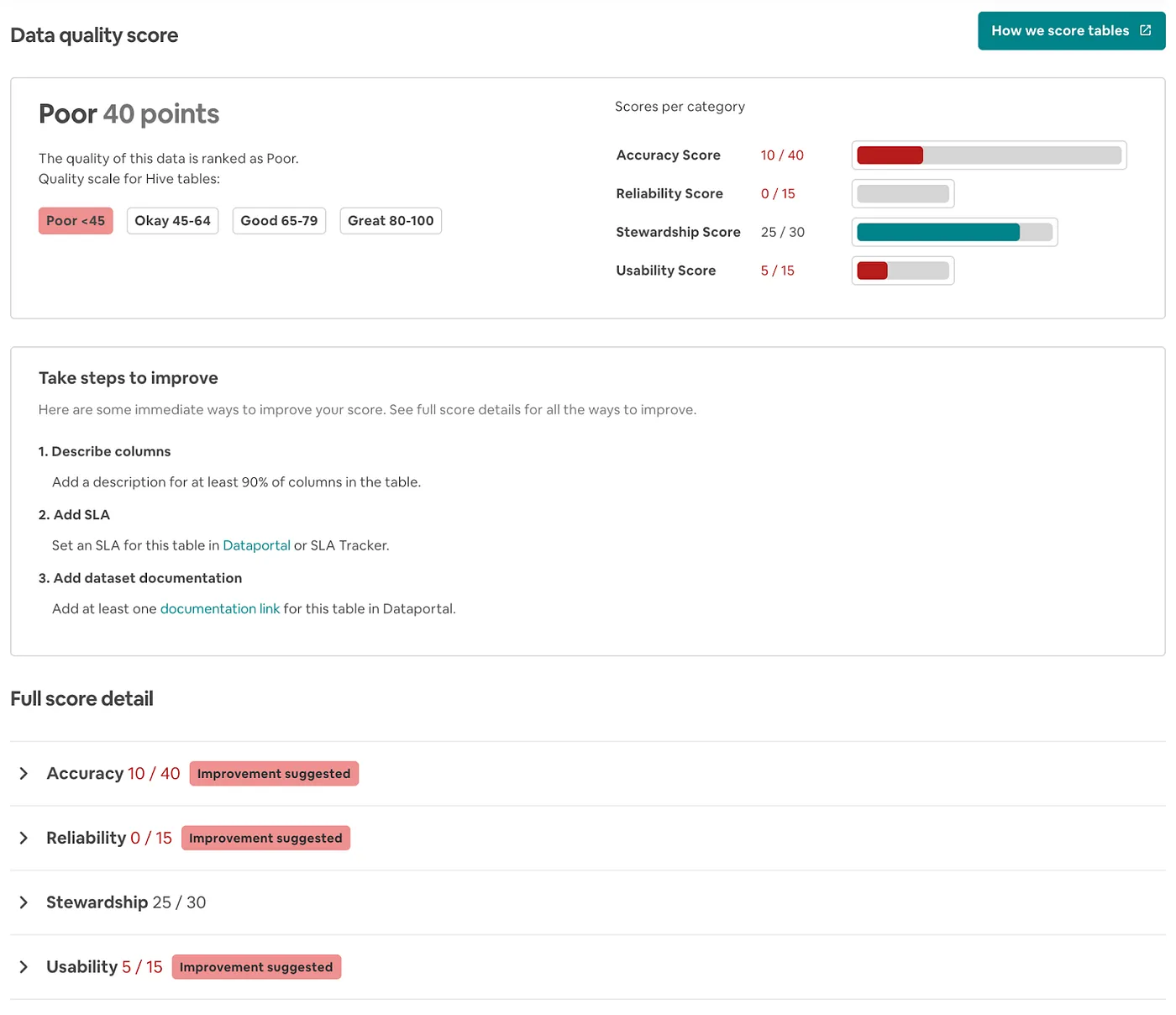
- Единый высокоуровневый рейтинг от 0 до 100. Мы установили категориальные пороги “Плохо”, “Хорошо”, “Отлично” и “Превосходно” на основе анализа профилирования нашего хранилища данных, который изучал существующее распределение нашего Рейтинга DQ. Подходит для быстрой высокоуровневой оценки общего качества набора данных.
- Измерения рейтинга, где актив может иметь идеальный балл по точности, но низкий по надежности. Полезно, когда конкретная область недостатка не проблематична (например, потребитель хочет, чтобы данные были очень точными, но не беспокоится о том, что они поступают каждый день быстро).
- Полная детализация рейтинга + Шаги по улучшению, где пользователи данных могут видеть, в чем конкретно актив уступает, и продюсеры данных могут предпринять меры для улучшения качества актива.
Все три эти представления показаны на скриншотах ниже. Стандартное представление предоставляет измерения “Баллы за категорию”, категориальный дескриптор “Плохо” вместе с 40 баллами и шагами по улучшению.
Full data quality score page in Dataportal
Если пользователь исследует полные детали рейтинга, он может изучить конкретные недостатки качества и просматривать информативные подсказки, предоставляющие более подробное описание определения и заслуг компонента оценки.
Full score detail presentation
Как сегодня используется рейтинг
Для производителей данных рейтинг предоставляет:
Ясные, действенные шаги для улучшения качества данных своих активов.
Количественную оценку качества данных, измеряя их работу.
Ясные ожидания в отношении качества данных.
Цели для устранения технического долга.
Для потребителей данных рейтинг качества данных:
Повышает обнаруживаемость данных.
Служит сигналом доверия к данным (аналогично тому, как работает система отзывов для гостей и хозяев Airbnb).
Информирует потребителей о конкретных недостатках качества, чтобы они могли быть уверены в использовании данных.
Позволяет потребителям искать и требовать качества данных.
С точки зрения стратегии данных, мы используем внутренние данные запросов в сочетании с рейтингом качества данных для управления усилиями по улучшению качества данных в нашем хранилище данных. Рассматривая как объем, так и тип потребления (например, является ли определенная метрика доступной в нашем исполнительском отчете), мы можем направлять команды данных на наиболее значимые улучшения качества данных. Эта видимость была очень просветительной для команд, которые не были осведомлены о своем длинном хвосте активов низкого качества, и она позволила нам удвоить усилия в области инвестиций в качество для сложных моделей данных, которые обеспечивают значительную часть нашего потребления данных.
Наконец, разработав рейтинг качества данных, мы смогли предоставить единое руководство нашим производителям данных по созданию высококачественных, хотя и несертифицированных активов. Рейтинг качества данных не заменил сертификацию (например, только данные, сертифицированные Midas, могут получить рейтинг DQ > 90). Мы продолжаем сертифицировать наш самый критический поднабор данных и считаем, что сценарии использования для этих активов всегда будут обосновывать ручную проверку, строгость и поддержание сертификации. Но для всего остального рейтинг DQ укрепляет и масштабирует принципы Midas в нашем хранилище данных.
Что дальше
Мы рады тому, что теперь можем измерять и наблюдать количественные улучшения в качестве данных, но мы только начали. Недавно мы расширили исходный рейтинг DQ, чтобы оценивать наши метрики и измерения Minerva. Точно так же мы планируем внедрить концепцию рейтинга DQ для других активов данных, таких как наши журналы событий и функции машинного обучения.
Поскольку требования и запросы к нашим данным продолжают развиваться, также будут меняться наши ожидания качества. Мы будем продолжать разрабатывать, как мы определяем и измеряем качество, и с быстрым улучшением в областях, таких как управление метаданными и классификация данных, мы ожидаем дополнительного повышения эффективности и производительности для всех практиков данных в Airbnb.
Благодарности
Рейтинг DQ не был бы возможен без участия нескольких кросс-функциональных и кросс-организационных коллег. К ним относятся, но не ограничиваются: Марк Стейнбрик, Читта Широлкар, Джонатан Паркс, Сильвия Томияма, Феликс Оук, Джейсон Флиттнер, Ин Пан, Логан Джордж, Вуди Чжоу, Мишель Томас и Эрик Риттер.
Отдельное спасибо членам обширного сообщества данных Airbnb, которые предоставили входные данные или помощь команде реализации на протяжении фаз дизайна, разработки и запуска.
Если вас интересует такая работа, ознакомьтесь с некоторыми из наших связанных вакансий.
****************
Все названия продуктов, логотипы и бренды являются собственностью соответствующих владельцев. Все названия компаний, продуктов и услуг, использованные на этом сайте, представлены исключительно в информационных целях. Использование этих названий, логотипов и брендов не подразумевает их одобрение.
Перевод ChatGPT