В современном вебе часто возникает задача автоматического создания скриншотов веб-страниц. Это может быть нужно для генерации превью ссылок, мониторинга доступности сайтов, создания PDF-отчетов или даже для работы сервисов по автоматизации контента.
В этой статье мы пошагово создадим свой собственный, надежный и масштабируемый микросервис для рендеринга скриншотов. Мы будем использовать мощную связку технологий:
- Node.js & Express: для создания легковесного API.
- Puppeteer: для управления headless-браузером Chromium и создания скриншотов.
- Docker: для упаковки нашего приложения в изолированный контейнер.
- Kubernetes (k3s): для оркестрации, масштабирования и обеспечения отказоустойчивости нашего сервиса.
В итоге мы получим простое API, которое по GET-запросу с URL-адресом будет возвращать готовую картинку.
Зачем нужен собственный сервис?
Хотя существуют готовые SaaS-решения вроде https://urlbox.com, создание собственного сервиса дает несколько ключевых преимуществ:
- Контроль: Вы полностью контролируете окружение, версии браузера и параметры рендеринга.
- Безопасность: Вы можете запускать сервис в своей приватной сети для обработки внутренних ресурсов, недоступных извне.
- Стоимость: При большом объеме запросов собственный сервис может оказаться значительно дешевле SaaS.
- Гибкость: Вы можете легко расширить функциональность, добавив, например, генерацию PDF, выполнение кастомных скриптов на странице и многое другое.
Шаг 1: Создание Node.js приложения
Сначала создадим основу нашего сервиса — Express-приложение, которое будет принимать запросы и управлять Puppeteer.
Структура проекта
Создадим папку для нашего проекта и внутри нее — необходимые файлы.
puppeteer-k8s/
├── dockerb/
│ ├── Dockerfile
│ ├── .dockerignore
│ ├── server.js
│ ├── package.json
│ └── package-lock.json
└── deployment.yaml
*Обратите внимание: мы поместили все, что относится к Docker, в подпапку `dockerb` для удобства.*
Код сервера (`server.js`)
Это ядро нашего приложения. Оно принимает HTTP-запросы, запускает Puppeteer, переходит на указанный URL и делает скриншот. Мы также добавим полезные параметры для управления качеством и размером.
// server.js. -- в моем докере server_v3.js
const express = require('express');
const puppeteer = require('puppeteer');
const app = express();
const PORT = 3000;
app.get('/render', async (req, res) => {
// Добавляем новые параметры: quality и dsf (deviceScaleFactor)
const {
url,
width,
height,
format = 'png',
fullPage = 'false',
quality, // Качество для jpeg/webp (0-100)
dsf = '1' // Device Scale Factor. Для Retina-качества используйте '2'
} = req.query;
if (!url) {
return res.status(400).json({
error: 'Параметр "url" обязателен.',
example: '/render?url=https://example.com'
});
}
let browser;
try {
console.log(`[${new Date().toISOString()}] Начинаем рендеринг для: ${url}`);
// Добавляем аргументы для улучшения рендеринга
browser = await puppeteer.launch({
args: [
'--no-sandbox',
'--disable-setuid-sandbox',
'--font-render-hinting=none', // Может улучшить отрисовку шрифтов
'--disable-infobars' // Убирает инфо-панели
]
});
const page = await browser.newPage();
const viewportWidth = parseInt(width, 10) || 1280;
const viewportHeight = parseInt(height, 10) || 720;
const deviceScaleFactor = parseInt(dsf, 10) || 1;
// Устанавливаем viewport с учетом deviceScaleFactor
await page.setViewport({
width: viewportWidth,
height: viewportHeight,
deviceScaleFactor: deviceScaleFactor
});
console.log(`Viewport: ${viewportWidth}x${viewportHeight}, DeviceScaleFactor: ${deviceScaleFactor}`);
await page.goto(url, { waitUntil: 'networkidle2' });
// Если есть "ленивая" загрузка изображений, можно "проскроллить" страницу
// Это необязательный шаг, но он помогает прогрузить все картинки
if (fullPage === 'true') {
await page.evaluate(async () => {
await new Promise((resolve) => {
let totalHeight = 0;
const distance = 100;
const timer = setInterval(() => {
const scrollHeight = document.body.scrollHeight;
window.scrollBy(0, distance);
totalHeight += distance;
if (totalHeight >= scrollHeight) {
clearInterval(timer);
resolve();
}
}, 100);
});
});
}
const screenshotOptions = {
type: (format === 'jpeg' || format === 'webp') ? format : 'png',
fullPage: fullPage === 'true'
};
// Устанавливаем качество, если параметр был передан
if ((screenshotOptions.type === 'jpeg' || screenshotOptions.type === 'webp') && quality) {
screenshotOptions.quality = parseInt(quality, 10);
} else if (screenshotOptions.type === 'jpeg') {
screenshotOptions.quality = 90; // Ставим хорошее качество по умолчанию для JPEG
}
const imageBuffer = await page.screenshot(screenshotOptions);
console.log(`[${new Date().toISOString()}] Рендеринг успешно завершен.`);
res.setHeader('Content-Type', `image/${screenshotOptions.type}`);
res.send(imageBuffer);
} catch (error) {
console.error(`[${new Date().toISOString()}] Ошибка рендеринга для ${url}:`, error.message);
res.status(500).json({
error: 'Не удалось отрендерить страницу.',
details: error.message
});
} finally {
if (browser) {
await browser.close();
}
}
});
app.get('/', (req, res) => {
res.setHeader('Content-Type', 'text/plain; charset=utf-8');
res.send(`
API для рендеринга сайтов (v2 - Улучшенное качество)
----------------------------------------------------
Используйте GET-запрос на /render с параметрами.
Обязательные параметры:
- url: Адрес сайта для скриншота.
Необязательные параметры:
- width: Ширина окна (по умолч. 1280).
- height: Высота окна (по умолч. 720).
- format: Формат файла ('png', 'jpeg', 'webp'). По умолч. 'png'.
- fullPage: Сделать скриншот всей страницы ('true' или 'false'). По умолч. 'false'.
- dsf: Device Scale Factor для Retina/HiDPI качества (например, '2'). По умолч. '1'.
- quality: Качество для jpeg/webp от 0 до 100.
Пример для высокого качества (Retina):
curl -o site_retina.png "http://localhost:3000/render?url=https://github.com&dsf=2&width=1440&height=900"
Пример для JPEG с максимальным качеством:
curl -o site_hq.jpeg "http://localhost:3000/render?url=https://apple.com&format=jpeg&quality=100&width=1920&height=1080"
`);
});
app.listen(PORT, () => {
console.log(`Сервис рендеринга запущен на http://localhost:${PORT}`);
});
*Запустите `npm install` в папке `dockerb`, чтобы сгенерировать `package-lock.json`.*
Шаг 2: Создание Docker-образа
Теперь упакуем наше приложение. Этот шаг — самый каверзный, так как Puppeteer требует особого подхода к правам доступа и зависимостям.
мой пример тут образа
Файл `.dockerignore`
Крайне важно не копировать локальную папку `node_modules` в образ. Они должны устанавливаться внутри контейнера для правильной архитектуры.
# .dockerignore
node_modules
Финальный `Dockerfile`
Этот `Dockerfile` — результат множества проб и ошибок. Он решает все основные проблемы:
- Устанавливает необходимые системные библиотеки для Chromium.
- Создает непривилегированного пользователя `pptruser` с домашней директорией.
- Устанавливает `npm`-зависимости и браузер от имени этого пользователя, чтобы избежать проблем с правами доступа.
# 1. Базовый образ
FROM node:18-slim
# 2. Установка системных зависимостей
RUN apt-get update && apt-get install -y \
ca-certificates fonts-liberation libappindicator3-1 libasound2 libatk-bridge2.0-0 \
libatk1.0-0 libc6 libcairo2 libcups2 libdbus-1-3 libexpat1 libfontconfig1 libgbm1 \
libgcc1 libgconf-2-4 libgdk-pixbuf2.0-0 libglib2.0-0 libgtk-3-0 libnspr4 libnss3 \
libpango-1.0-0 libpangocairo-1.0-0 libstdc++6 libx11-6 libx11-xcb1 libxcb1 \
libxcomposite1 libxcursor1 libxdamage1 libxext6 libxfixes3 libxi6 libxrandr2 \
libxrender1 libxss1 libxtst6 lsb-release wget xdg-utils \
&& rm -rf /var/lib/apt/lists/*
# 3. создаем пользователя с домом
# Флаг -m (--create-home) гарантирует создание папки /home/pptruser
RUN useradd -r -m -g root -s /bin/bash pptruser
# 4. Устанавливаем рабочую директорию
WORKDIR /app
# 5. Копируем файлы зависимостей и сразу назначаем владельцем pptruser
# (современный и более чистый способ, чем chown после)
COPY --chown=pptruser:root package*.json ./
# 6. Переключаемся на нашего пользователя
USER pptruser
# 7. Устанавливаем всё от имени pptruser. Кэш ляжет в /home/pptruser/.cache
RUN npm ci
RUN npx puppeteer browsers install chrome
# 8. Копируем остальной код, также сразу назначая владельца
COPY --chown=pptruser:root . .
# 9. Открываем порт и запускаем
EXPOSE 3000
CMD [ "node", "server.js" ]
Сборка и отправка образа
Замените `your_docker_id` на ваш логин в Docker Hub.
# Переходим в папку с Dockerfile
cd puppeteer-k8s/dockerb
# Собираем образ
docker build -t your_docker_id/puppeteer-renderer:v1 .
# Отправляем в репозиторий
docker push your_docker_id/puppeteer-renderer:v1
Шаг 3: Развертывание в Kubernetes
Мы будем использовать `k3s` — легковесный дистрибутив Kubernetes. Можно еще тут посмотреть пример https://github.com/jamesheronwalker/urlbox-puppeteer-kubernetes-demo
или вот статейка еще https://urlbox.com/guides/kubernetes-website-screenshots
Установка окружения (Local)
# Установка lima и k3s (если еще не сделано)
brew install lima
limactl start template://k3s
# Настройка kubectl для работы с кластером
export KUBECONFIG=$(limactl list k3s --format 'unix://{{.Dir}}/copied-from-guest/kubeconfig.yaml')
# Проверка, что все работает
kubectl get nodes
Манифест развертывания (`deployment.yaml`)
Этот YAML-файл описывает желаемое состояние нашего приложения в кластере. Мы будем использовать тип сервиса `LoadBalancer` — он идеально подходит для будущего развертывания в облаке, а для локальной разработки мы будем использовать `port-forward`.
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: puppeteer-renderer
spec:
replicas: 2 # Запускаем два пода для отказоустойчивости
selector:
matchLabels:
app: puppeteer-renderer
template:
metadata:
labels:
app: puppeteer-renderer
spec:
containers:
- name: renderer
image: your_docker_id/puppeteer-renderer:v1 # <<< ВАШ ОБРАЗ (мой тут docker pull 1325gy/my_dev:v4)
ports:
- containerPort: 3000
resources:
requests:
cpu: "500m"
memory: "1Gi"
limits:
cpu: "1"
memory: "2Gi"
readinessProbe:
httpGet:
path: /
port: 3000
initialDelaySeconds: 15
periodSeconds: 10
livenessProbe:
httpGet:
path: /
port: 3000
initialDelaySeconds: 30
periodSeconds: 20
volumeMounts:
- name: dshm
mountPath: /dev/shm
volumes:
- name: dshm
emptyDir:
medium: Memory
---
apiVersion: v1
kind: Service
metadata:
name: pptr-renderer-service
spec:
# Тип LoadBalancer - стандарт для облаков. Локально он останется в <pending>,
# но это не помешает нам использовать port-forward.
type: LoadBalancer
selector:
app: puppeteer-renderer
ports:
- protocol: TCP
port: 80 # Внешний порт сервиса
targetPort: 3000 # Порт, на который нужно перенаправлять трафик внутри пода
Важные моменты в манифесте:
- `resources:`: Puppeteer очень требователен к ресурсам. Указание запросов и лимитов помогает Kubernetes правильно размещать поды.
- `readiness/livenessProbe`: Пробы готовности и жизнеспособности позволяют Kubernetes понять, работает ли под корректно.
- `/dev/shm`: Chromium использует разделяемую память. Увеличение её размера через `emptyDir` предотвращает частые сбои.
Запуск и проверка
# Переходим в корневую папку проекта
cd ..
# Применяем манифест
kubectl apply -f deployment.yaml
# Наблюдаем за созданием подов
kubectl get pods -l app=puppeteer-renderer -w
# Проверяем сервис. EXTERNAL-IP будет <pending>, это нормально.
kubectl get service pptr-renderer-service
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# pptr-renderer-service LoadBalancer 10.43.123.123 <pending> 80:31185/TCP 1m
Шаг 4: Тестирование через Port-Forward
`kubectl port-forward` — это мощный инструмент для отладки, который создает безопасный тоннель с вашего компьютера напрямую к сервису в кластере.
- Откройте новый терминал и выполните команду:
kubectl port-forward service/pptr-renderer-service 8080:80
- `8080` — это порт на вашем локальном компьютере (`localhost`).
- `80` — это порт, который слушает наш `Service` в Kubernetes.
Вы увидите сообщение `Forwarding from 127.0.0.1:8080 -> 3000`. Не закрывайте этот терминал.
- Откройте третий терминал и отправьте тестовый запрос на `localhost:8080`:
curl -o k8s-site.png "http://localhost:8080/render?url=https://kubernetes.io&width=1440&height=900&dsf=2"
Если все сделано правильно, в вашей текущей папке появится файл `k8s-site.png` со скриншотом сайта Kubernetes в высоком разрешении!
Итоги и рекомендации для продакшена
Мы успешно создали и развернули масштабируемый сервис для создания скриншотов. Мы убедились, что он работает локально в `k3s`, используя `LoadBalancer` и `port-forward` для удобной отладки.
Когда придет время переходить в продуктивное окружение (например, в облако Google/AWS):
- Тип Сервиса: Вам не нужно ничего менять! Просто примените тот же `deployment.yaml` с `type: LoadBalancer`. Облачный провайдер автоматически подхватит этот сервис и выделит ему настоящий публичный IP-адрес.
- Ingress: Для более гибкого управления трафиком (маршрутизация по хостам, SSL/TLS) используйте `Ingress Controller`. Он будет направлять внешний трафик на ваш сервис, который уже можно будет сделать типа `ClusterIP`.
- Автомасштабирование: Настройте `HorizontalPodAutoscaler` (HPA), чтобы Kubernetes автоматически добавлял или удалял поды в зависимости от нагрузки (например, по CPU).
- Логирование и Мониторинг: Настройте централизованный сбор логов (EFK/Loki) и мониторинг метрик (Prometheus/Grafana), чтобы следить за здоровьем и производительностью сервиса.
Этот пример — отличная основа, которую можно развивать и адаптировать под самые разные задачи, от простых утилит до сложных систем автоматизации контента.
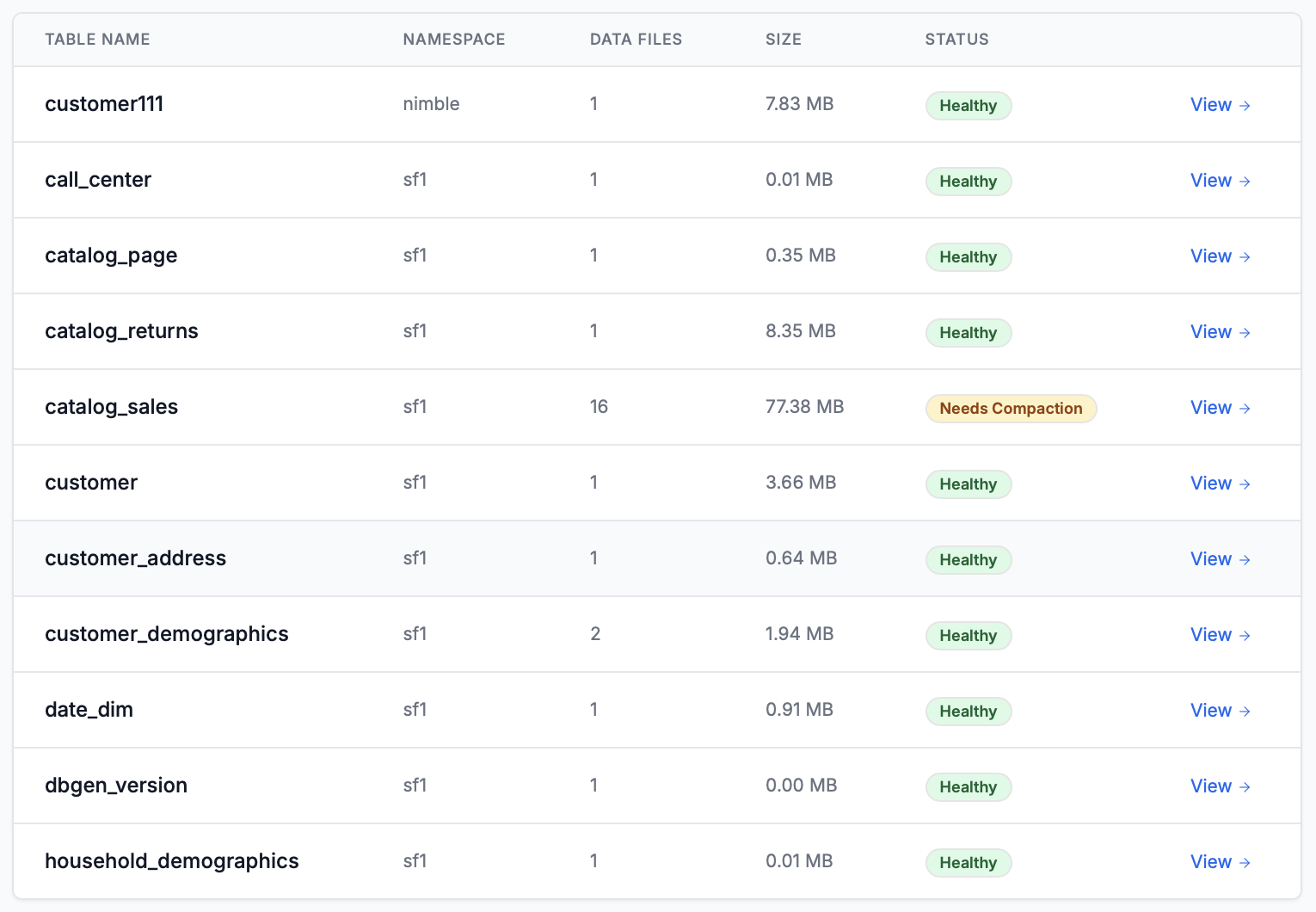
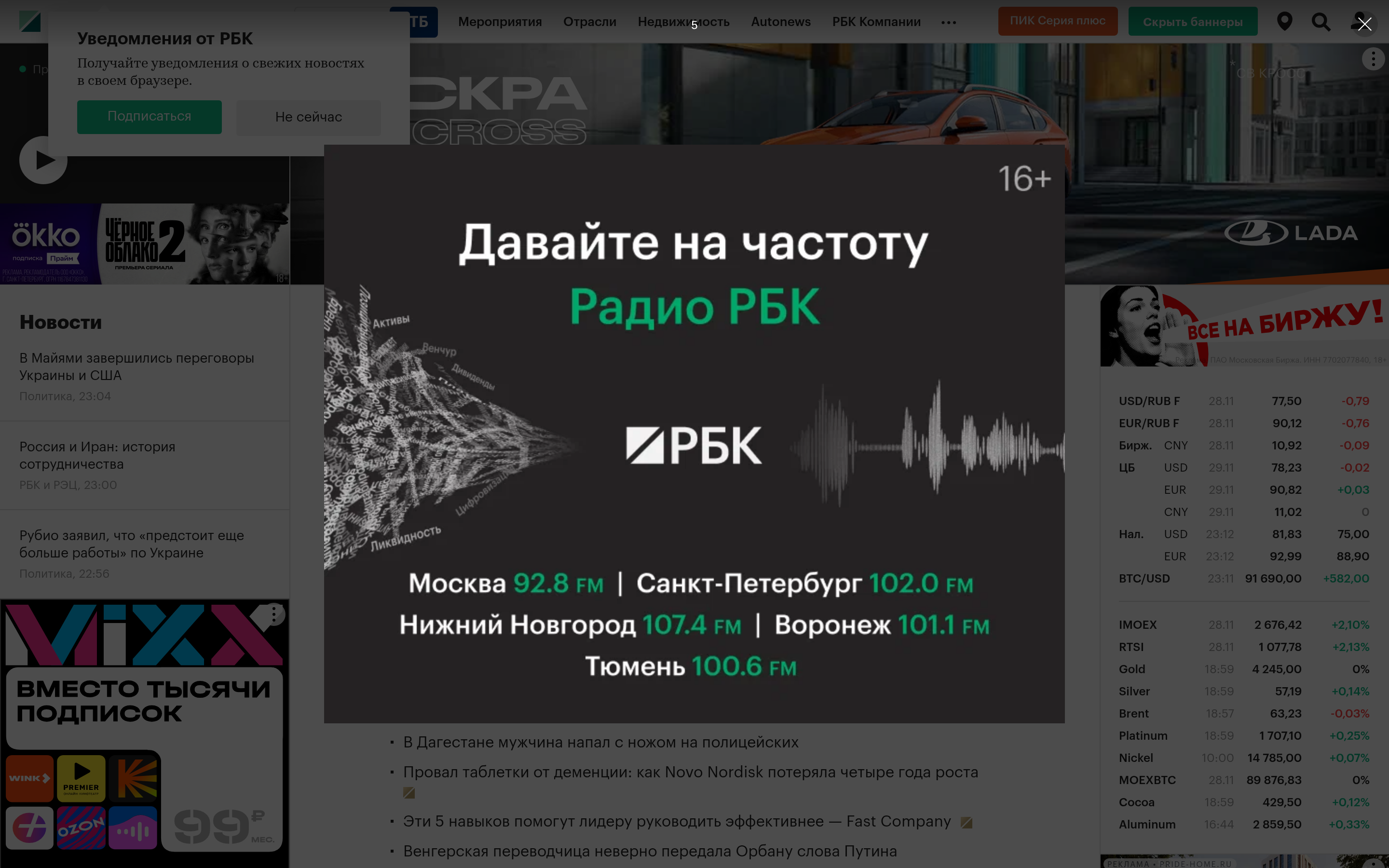
Мне вот удалось rbc заскринить вот так, потом может что то сделаю для статеек с медиума.
curl -o rbc111.png "http://localhost:8080/render?url=https://rbc.ru&width=1440&height=900&dsf=2"
Вот что вышло png тут


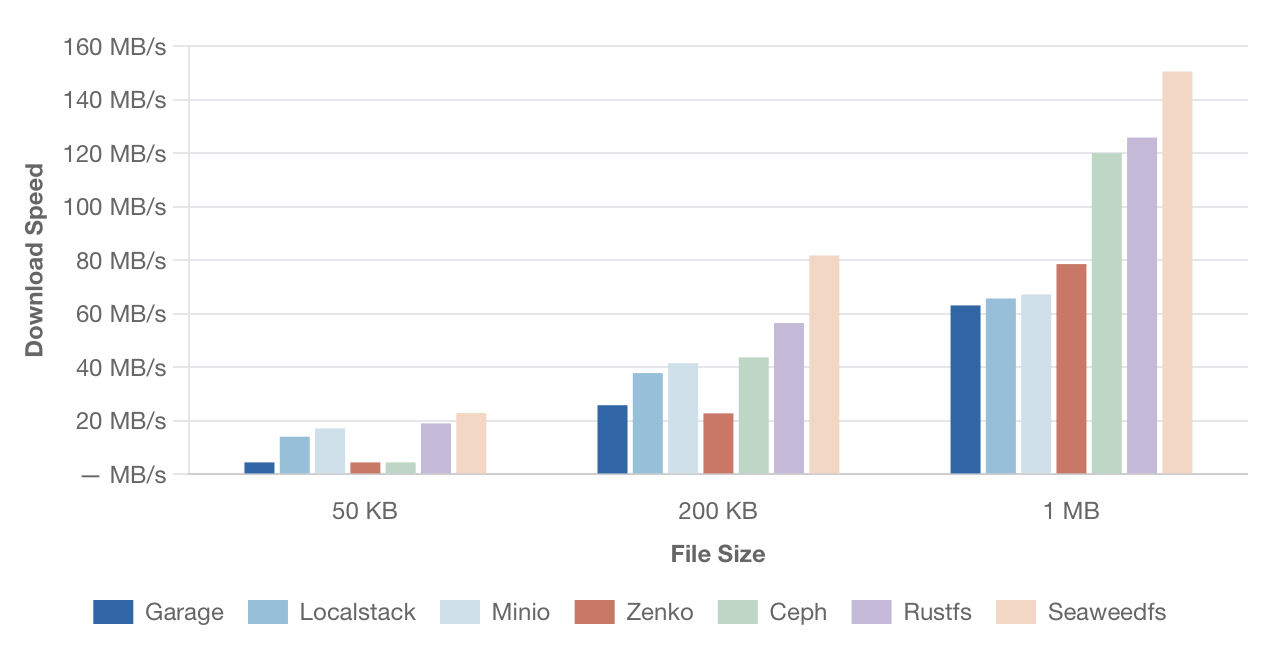
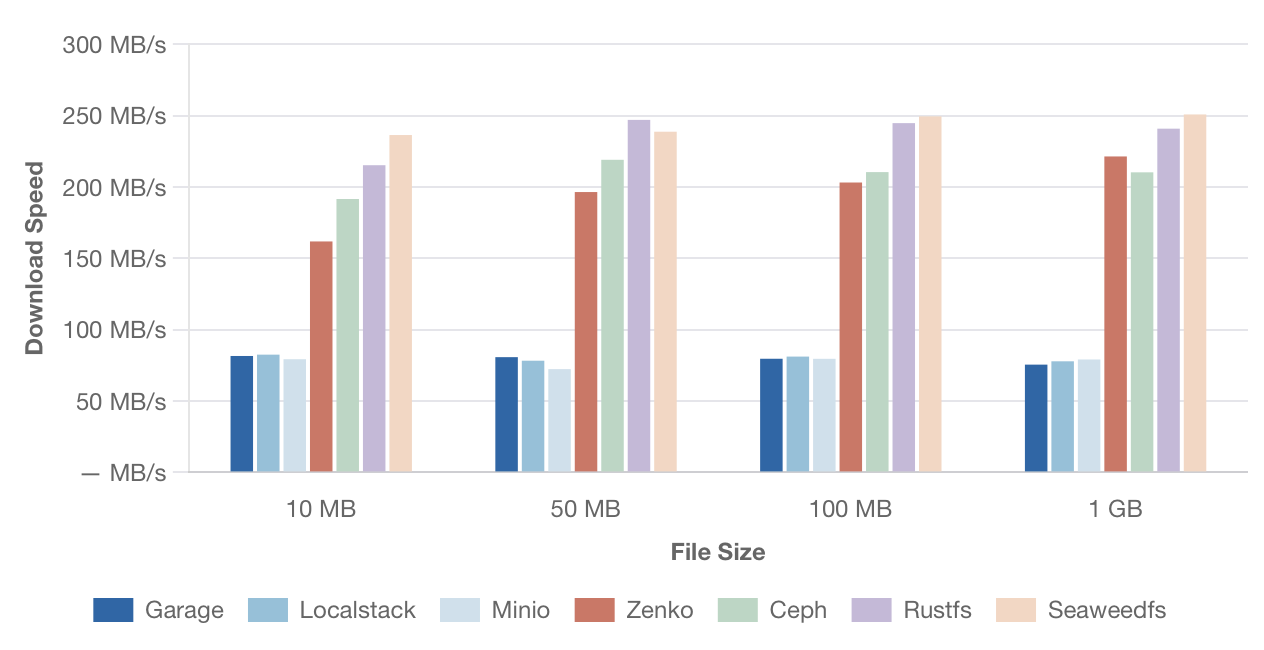
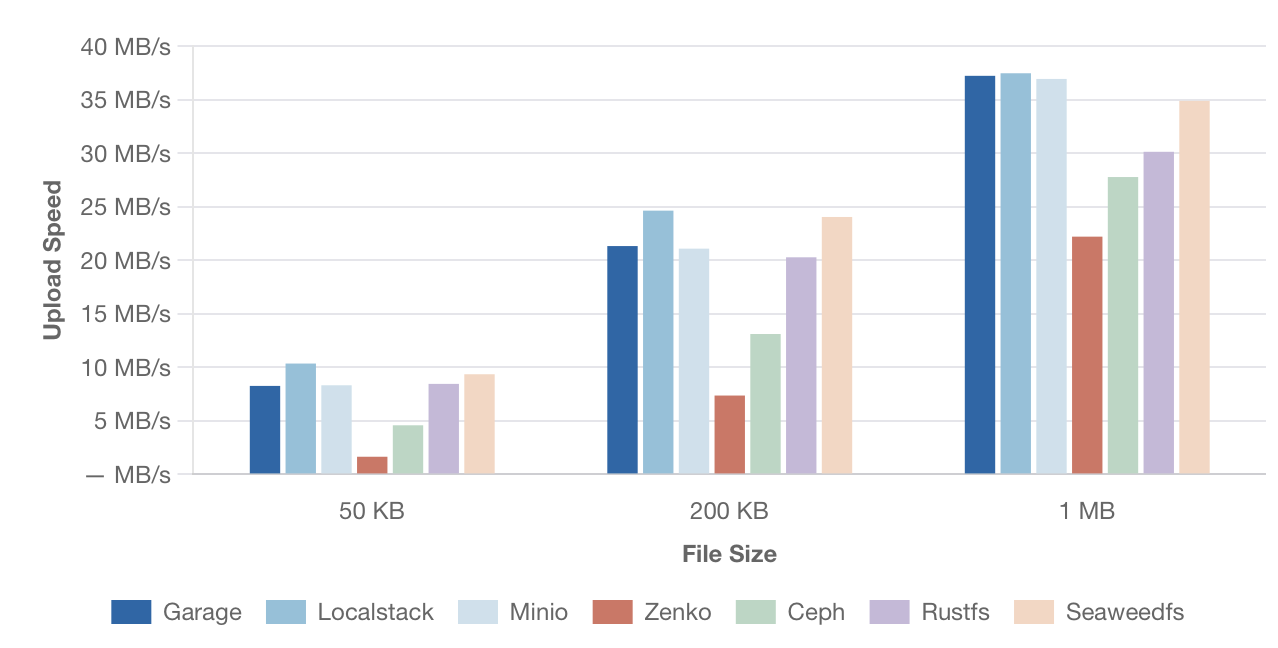
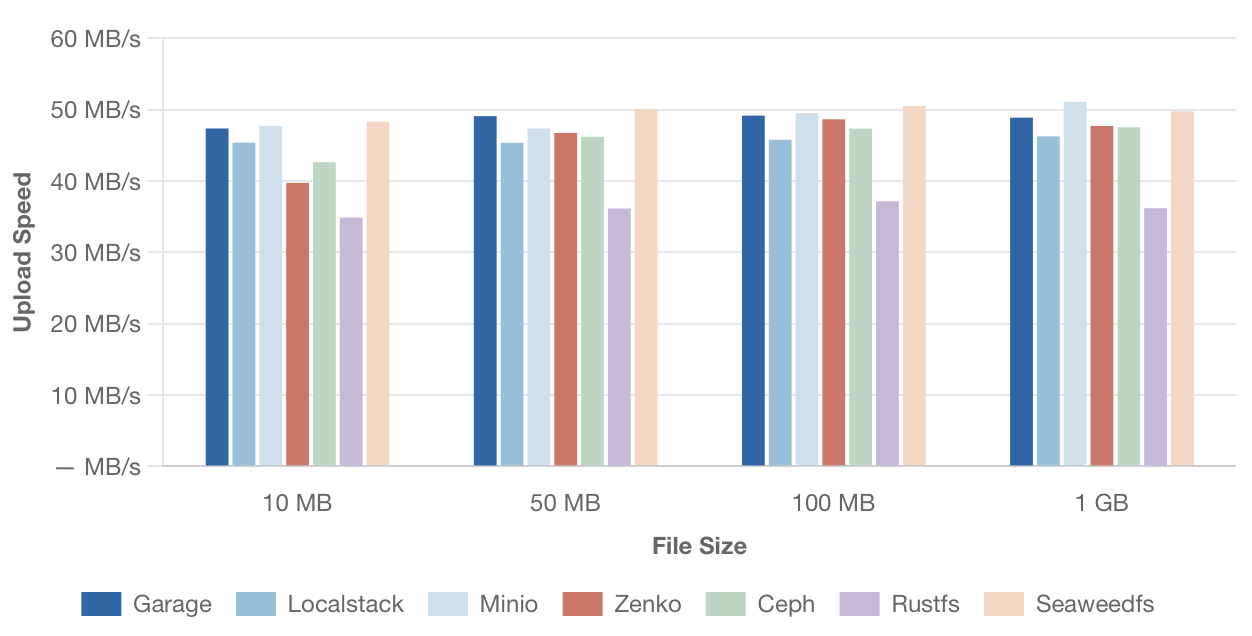


{kind=link}