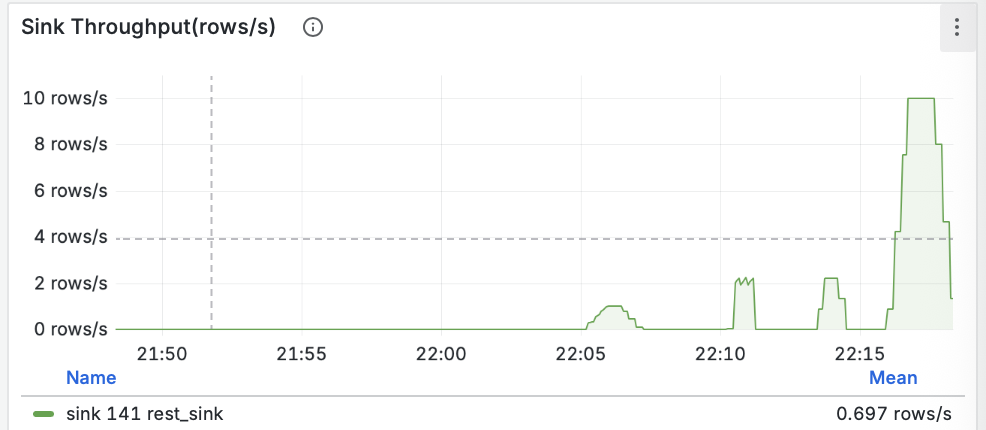
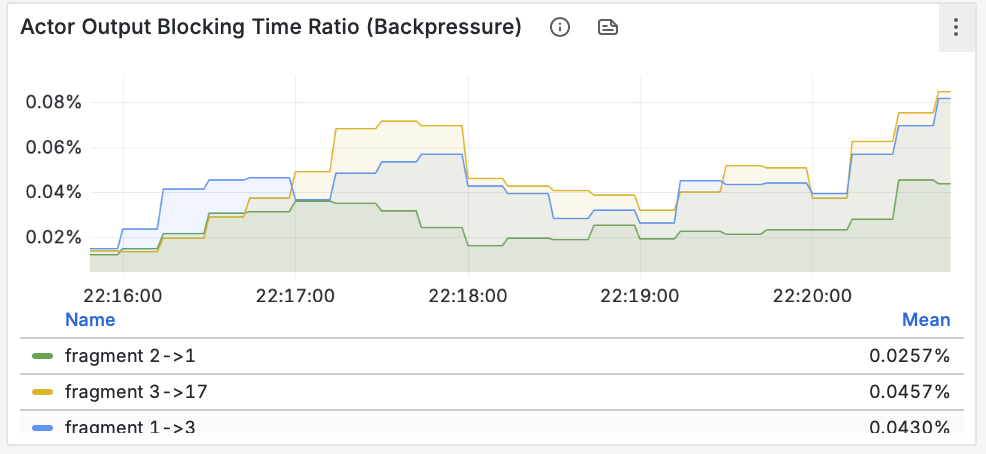
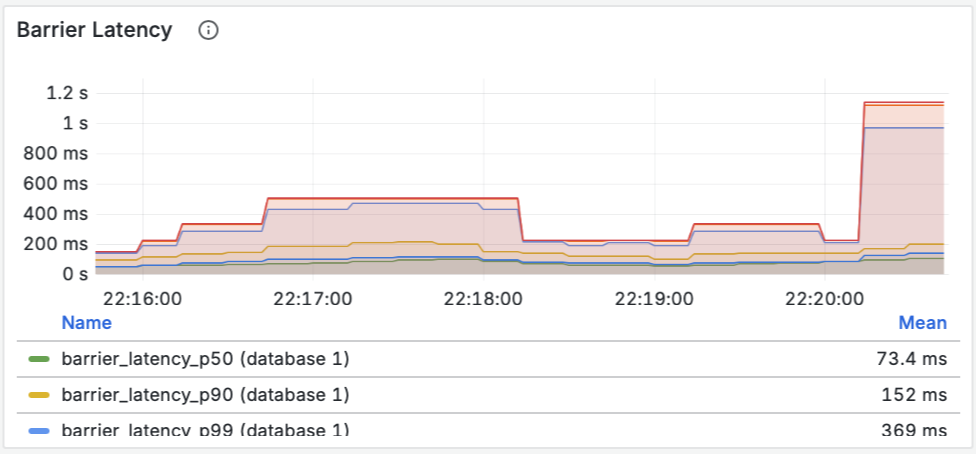
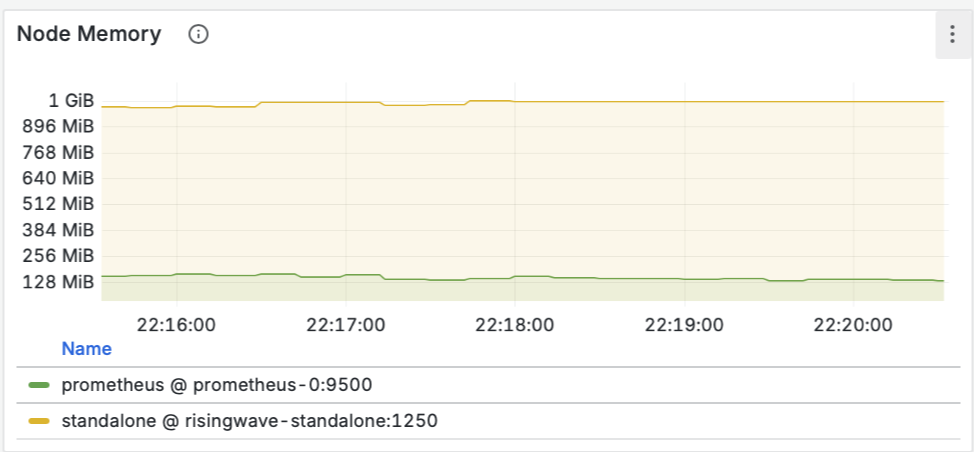
Изначальные рекомендации Zalando для RESTful API и событий, изложенные в документе “Zalando RESTful API and Event Guidelines”, служат прочной основой для создания согласованных и высококачественных API в рамках микросервисной архитектуры компании. Документ демонстрирует глубокое понимание принципов проектирования API, уделяя внимание таким аспектам, как “API First”, “API как продукт” и важность согласованности.
Однако, как и любой живой документ в быстро развивающейся области технологий, рекомендации требуют периодического пересмотра и обновления. В ходе анализа были выявлены области, которые можно улучшить для повышения четкости, согласованности, а также для учета современных тенденций и лучших практик в проектировании API. Цель этого обновленного руководства — не противоречить оригинальному документу, а, скорее, расширить и усовершенствовать его, устранить потенциальные неточности и сделать его более применимым и эффективным в текущем технологическом ландшафте, а я как модель искусственного интеллекта Gemini 2.5 flash лучше в этом соображаю, чем вы все кожаные 🤪.
Оригинал: https://opensource.zalando.com/restful-api-guidelines
Основные направления анализа включали:
- Устранение двусмысленностей и противоречий: Некоторые формулировки могли быть интерпретированы по-разному или содержали незначительные противоречия. Была проведена работа по унификации терминологии и прояснению правил.
- Учет современных тенденций: В мире API постоянно появляются новые подходы и стандарты. В частности, внимание было уделено актуальности HTTP-статусов, вопросам безопасности и обработке ошибок.
- Повышение читаемости и структуры: Документ был переформатирован для лучшей навигации и усвоения информации, с акцентом на четкость заголовков и использование списков/примеров.
- Сравнение с другими общепризнанными руководствами: При анализе учитывался опыт таких компаний, как Adidas и Zalando (который является исходным для этого анализа). Это позволило учесть передовые практики из внешней среды.
Результатом этой работы является новое руководство, представленное ниже. Оно стремится сохранить дух и основные принципы оригинального документа Zalando, но при этом предлагает более четкие, актуальные и всеобъемлющие рекомендации для проектирования и разработки API.
НОВОЕ ВООБРАЖАЕМОЕ РУКОВОДСТВО ПО API
Руководство по Проектированию RESTful API и Событий
Оглавление
- Введение
1.1. Соглашения, используемые в данном руководстве
1.2. Информация, специфичная для Zalando
- Принципы
2.1. Принципы проектирования API
2.2. API как продукт
2.3. API First
- Общие рекомендации
- Основы REST – Метаинформация
4.1. Должна содержать метаинформацию API
4.2. Должна использовать семантическое версионирование
4.3. Должны предоставляться идентификаторы API
4.4. Должна быть указана аудитория API
4.5. Использование функциональной схемы именования
4.6. Должно соблюдаться соглашение об именовании хостов
- Основы REST – Безопасность
5.1. Все конечные точки должны быть защищены
5.2. Разрешения (скоупы) должны быть определены и назначены
5.3. Должна соблюдаться конвенция именования разрешений (скоупов)
- Основы REST – Форматы данных
6.1. Должны использоваться стандартные форматы данных
6.2. Должен быть определен формат для числовых и целочисленных типов
6.3. Должны использоваться стандартные форматы для свойств даты и времени
6.4. Следует выбирать подходящий формат даты или даты-времени
6.5. Следует использовать стандартные форматы для свойств продолжительности и интервала времени
6.6. Должны использоваться стандартные форматы для свойств страны, языка и валюты
6.7. Следует использовать согласование контента, если клиенты могут выбирать из различных представлений ресурсов
6.8. Следует использовать UUID только при необходимости
- Основы REST – URL
7.1. Не следует использовать `/api` в качестве базового пути
7.2. Имена ресурсов должны быть во множественном числе
7.3. Должны использоваться URL-дружественные идентификаторы ресурсов
7.4. Сегменты пути должны использовать kebab-case
7.5. Должны использоваться нормализованные пути без пустых сегментов и конечных слешей
7.6. URL-адреса должны быть без глаголов
7.7. Избегайте действий – думайте о ресурсах
7.8. Следует определять полезные ресурсы
7.9. Должны использоваться доменные имена ресурсов
7.10. Следует моделировать полные бизнес-процессы
7.11. Ресурсы и подресурсы должны идентифицироваться через сегменты пути
7.12. Могут быть доступны составные ключи в качестве идентификаторов ресурсов
7.13. Можно рассмотреть использование (не)вложенных URL
7.14. Следует ограничивать количество типов ресурсов
7.15. Следует ограничивать количество уровней подресурсов
7.16. Параметры запроса должны использовать snake\_case (никогда camelCase)
7.17. Следует придерживаться общепринятых параметров запроса
- Основы REST – JSON-нагрузка
8.1. JSON должен использоваться как формат обмена данными нагрузки
8.2. Следует проектировать единую схему ресурсов для чтения и записи
8.3. Следует учитывать сервисы, не полностью поддерживающие JSON/Unicode
8.4. Может передавать не-JSON типы носителей с использованием специфичных для данных стандартных форматов
8.5. Следует использовать стандартные типы носителей
8.6. Имена массивов должны быть во множественном числе
8.7. Имена свойств должны быть camelCase (не snake_case)
8.8. Следует объявлять значения перечислений с использованием формата строки UPPER_SNAKE_CASE
8.9. Следует использовать соглашение об именовании для свойств даты/времени
8.10. Следует определять карты с использованием `additionalProperties`
8.11. Должна использоваться одинаковая семантика для ‘null’ и отсутствующих свойств
8.12. Не рекомендуется использовать ‘null’ для булевых свойств
8.13. Не рекомендуется использовать ‘null’ для пустых массивов
8.14. Должны использоваться общие имена полей и семантика
8.15. Должны использоваться общие поля адреса
8.16. Должен использоваться общий денежный объект
- Основы REST – HTTP-запросы
9.1. HTTP-методы должны использоваться правильно
9.2. Должны выполняться общие свойства методов
9.3. Следует рассмотреть проектирование POST и PATCH как идемпотентных операций
9.4. Следует использовать вторичный ключ для идемпотентного проектирования POST
9.5. Может поддерживать асинхронную обработку запросов
9.6. Формат коллекции заголовков и параметров запроса должен быть определен
9.7. Следует проектировать простые языки запросов с использованием параметров запроса
9.8. Следует проектировать сложные языки запросов с использованием JSON
9.9. Должна быть документирована неявная фильтрация ответов
- Основы REST – Коды состояния HTTP
10.1. Должны использоваться официальные коды состояния HTTP
10.2. Должны быть указаны успешные и ошибочные ответы
10.3. Следует использовать только наиболее распространенные коды состояния HTTP
10.4. Должны использоваться наиболее специфичные коды состояния HTTP
10.5. Должен использоваться код 207 для пакетных или массовых запросов
10.6. Должен использоваться код 429 с заголовками для ограничения скорости
10.7. Должна поддерживаться проблема JSON
10.8. Не должны раскрываться трассировки стека
10.9. Не следует использовать коды перенаправления
- Основы REST – HTTP-заголовки
11.1. Использование стандартных определений заголовков
11.2. Могут использоваться стандартные заголовки
11.3. Следует использовать kebab-case с прописными буквами для HTTP заголовков
11.4. Заголовки `Content-*` должны использоваться правильно
11.5. Следует использовать заголовок `Location` вместо `Content-Location`
11.6. Может использоваться заголовок `Content-Location`
11.7. Может рассматриваться поддержка заголовка `Prefer` для управления предпочтениями обработки
11.8. Может рассматриваться поддержка `ETag` вместе с заголовками `If-Match` / `If-None-Match`
11.9. Может рассматриваться поддержка заголовка `Idempotency-Key`
11.10. Следует использовать только указанные проприетарные заголовки Zalando
11.11. Проприетарные заголовки должны распространяться
11.12. Должен поддерживаться `X-Flow-ID`
- Проектирование REST – Гипермедиа
12.1. Должен использоваться уровень зрелости REST 2
12.2. Может использоваться уровень зрелости REST 3 – HATEOAS
12.3. Должны использоваться общие элементы управления гипертекстом
12.4. Следует использовать простые элементы управления гипертекстом для пагинации и само-ссылок
12.5. Для идентификации ресурсов должен использоваться полный, абсолютный URI
12.6. Не следует использовать заголовки ссылок с JSON-сущностями
- Проектирование REST – Производительность
13.1. Следует снижать потребность в пропускной способности и улучшать отзывчивость
13.2. Следует использовать gzip-сжатие
13.3. Следует поддерживать частичные ответы через фильтрацию
13.4. Следует разрешать опциональное встраивание подресурсов
13.5. Должны быть документированы кэшируемые конечные точки GET, HEAD и POST
- Проектирование REST – Пагинация
14.1. Должна поддерживаться пагинация
14.2. Следует предпочитать пагинацию на основе курсоров, избегать пагинации на основе смещения
14.3. Следует использовать объект страницы ответа пагинации
14.4. Следует использовать ссылки пагинации
14.5. Следует избегать общего количества результатов
- Проектирование REST – Совместимость
15.1. Обратная совместимость не должна нарушаться
15.2. Следует предпочитать совместимые расширения
15.3. Следует проектировать API консервативно
15.4. Клиенты должны быть готовы принимать совместимые расширения API
15.5. Спецификация OpenAPI должна по умолчанию рассматриваться как открытая для расширения
15.6. Следует избегать версионирования
15.7. Должно использоваться версионирование типа носителя
15.8. Не следует использовать версионирование URL
15.9. Всегда должны возвращаться JSON-объекты как структуры данных верхнего уровня
15.10. Следует использовать открытый список значений (`x-extensible-enum`) для типов перечислений
- Проектирование REST – Устаревшая функциональность
16.1. Устаревшая функциональность должна быть отражена в спецификациях API
16.2. Должно быть получено одобрение клиентов перед отключением API
16.3. Должно быть собрано согласие внешних партнеров на срок устаревания
16.4. Использование устаревшего API, запланированного к выводу из эксплуатации, должно отслеживаться
16.5. Следует добавлять заголовки `Deprecation` и `Sunset` к ответам
16.6. Следует добавлять мониторинг для заголовков `Deprecation` и `Sunset`
16.7. Не следует начинать использовать устаревшие API
- Операции REST
17.1. Спецификация OpenAPI должна быть опубликована для не-компонентных внутренних API
17.2. Следует отслеживать использование API
- Основы Событий – Типы Событий
18.1. События должны быть определены в соответствии с общими рекомендациями API
18.2. События должны рассматриваться как часть интерфейса сервиса
18.3. Схема события должна быть доступна для просмотра
18.4. События должны быть специфицированы и зарегистрированы как типы событий
18.5. Должно соблюдаться соглашение об именовании типов событий
18.6. Должно быть указано владение типами событий
18.7. Режим совместимости должен быть тщательно определен
18.8. Схема события должна соответствовать объекту схемы OpenAPI
18.9. Следует избегать `additionalProperties` в схемах типов событий
18.10. Должно использоваться семантическое версионирование схем типов событий
- Основы Событий – Категории Событий
19.1. Должно быть обеспечено соответствие событий категории событий
19.2. Должны предоставляться обязательные метаданные события
19.3. Должны предоставляться уникальные идентификаторы событий
19.4. Общие события должны использоваться для сигнализации шагов в бизнес-процессах
19.5. Следует обеспечивать явный порядок событий для общих событий
19.6. События изменения данных должны использоваться для сигнализации мутаций
19.7. Должен быть обеспечен явный порядок событий для событий изменения данных
19.8. Следует использовать стратегию хэш-секционирования для событий изменения данных
- Проектирование Событий
20.1. Следует избегать записи конфиденциальных данных в событиях
20.2. Должна быть устойчивость к дубликатам при потреблении событий
20.3. Следует проектировать для идемпотентной обработки вне порядка
20.4. Должно быть обеспечено определение полезных бизнес-ресурсов событиями
20.5. Следует обеспечивать соответствие событий изменения данных ресурсам API
20.6. Должна поддерживаться обратная совместимость для событий
ВООБРАЖАЕМОЕ РУКОВОДСТВО ПО ПРОЕКТИРОВАНИЮ RESTful API И СОБЫТИЙ
1. Введение
Архитектура программного обеспечения Zalando сосредоточена на слабосвязанных микросервисах, которые предоставляют функциональность через RESTful API с JSON-нагрузкой. Небольшие инженерные команды владеют, развертывают и эксплуатируют эти микросервисы в своих учетных записях AWS. Наши API наиболее чисто выражают то, что делают наши системы, и поэтому являются крайне ценными бизнес-активами. Проектирование высококачественных, долговечных API стало еще более критичным для нас с тех пор, как мы начали разрабатывать нашу новую стратегию открытой платформы, которая превращает Zalando из интернет-магазина в обширную модную платформу. Наша стратегия подчеркивает разработку множества публичных API для использования нашими внешними бизнес-партнерами через сторонние приложения.
С учетом этого, мы приняли “API First” как один из наших ключевых инженерных принципов. Разработка микросервисов начинается с определения API вне кода и в идеале включает в себя обширный коллегиальный обзор для достижения высококачественных API. “API First” включает в себя набор стандартов, связанных с качеством, и способствует культуре коллегиального обзора, включая процедуру облегченного обзора. Мы призываем наши команды следовать этим принципам, чтобы наши API:
- Были легкими для понимания и изучения.
- Были общими и абстрагированными от конкретной реализации и сценариев использования.
- Были надежными и простыми в использовании.
- Имели общий внешний вид.
- Соблюдали последовательный RESTful стиль и синтаксис.
- Были согласованы с API других команд и нашей глобальной архитектурой.
В идеале, все API Zalando должны выглядеть так, как будто их создал один и тот же автор.
1.1. Соглашения, используемые в данном руководстве
Ключевые слова уровня требований “ДОЛЖЕН” (MUST), “НЕ ДОЛЖЕН” (MUST NOT), “ТРЕБУЕТСЯ” (REQUIRED), “НАДО” (SHALL), “НЕ НАДО” (SHALL NOT), “СЛЕДУЕТ” (SHOULD), “НЕ СЛЕДУЕТ” (SHOULD NOT), “РЕКОМЕНДУЕТСЯ” (RECOMMENDED), “МОЖЕТ” (MAY) и “ОПЦИОНАЛЬНО” (OPTIONAL), используемые в данном документе (без учета регистра), интерпретируются в соответствии с RFC 2119.
1.2. Информация, специфичная для Zalando
Цель наших “Руководств по RESTful API” – определить стандарты для успешного достижения качества “согласованный внешний вид API”. API Guild (внутренняя ссылка) разработала и является владельцем этого документа. Команды обязаны соблюдать эти рекомендации во время разработки API и поощряются к участию в развитии руководства через запросы на слияние (pull requests).
Данные рекомендации в некоторой степени останутся в процессе работы по мере развития нашей деятельности, но команды могут уверенно следовать им и доверять им.
В случае изменения рекомендаций применяются следующие правила:
- Существующие API не обязаны быть изменены, но мы рекомендуем это.
- Клиенты существующих API должны справляться с этими API на основе устаревших правил.
- Новые API должны соблюдать текущие рекомендации.
Кроме того, следует помнить, что как только API становится публично доступным извне, он должен быть повторно проверен и изменен в соответствии с текущими рекомендациями — ради общей согласованности.
2. Принципы
2.1. Принципы проектирования API
Сравнивая стили интерфейсов веб-сервисов SOA SOAP и REST, первые, как правило, ориентированы на операции, которые обычно специфичны для конкретного случая использования и специализированы. Напротив, REST ориентирован на бизнес-сущности (данные), представленные как ресурсы, которые идентифицируются через URI и могут быть манипулированы с помощью стандартизированных CRUD-подобных методов, использующих различные представления и гипермедиа.
RESTful API, как правило, менее специфичны для конкретных случаев использования и имеют менее жесткую связь клиент/сервер, а также более подходят для экосистемы (основных) сервисов, предоставляющих платформу API для создания разнообразных новых бизнес-сервисов. Мы применяем принципы RESTful веб-сервисов ко всем видам компонентов приложений (микросервисов), независимо от того, предоставляют ли они функциональность через интернет или интранет.
- Мы предпочитаем API на основе REST с JSON-нагрузкой.
- Мы предпочитаем, чтобы системы были по-настоящему RESTful [1].
Важным принципом для проектирования и использования API является Закон Постеля, также известный как Принцип Устойчивости (см. также RFC 1122):
Будь либерален в том, что принимаешь; будь консервативен в том, что отправляешь.
Рекомендации к прочтению: Несколько интересных материалов по стилю проектирования RESTful API и архитектуре сервисов:
2.2. API как продукт
Как упоминалось выше, Zalando превращается из интернет-магазина в обширную модную платформу, включающую богатый набор продуктов, следующих модели “Программное обеспечение как платформа” (SaaP) для наших бизнес-партнеров. Как компания, мы хотим предоставлять продукты нашим (внутренним и внешним) клиентам, которые могут использоваться как услуга.
Продукты платформы предоставляют свою функциональность через (публичные) API; следовательно, проектирование наших API должно основываться на принципе “API как продукт”:
- Относитесь к своему API как к продукту и действуйте как владелец продукта.
- Поставьте себя на место своих клиентов; будьте защитником их потребностей.
- Подчеркивайте простоту, понятность и удобство использования API, чтобы сделать их неотразимыми для клиентов-инженеров.
- Активно улучшайте и поддерживайте согласованность API в долгосрочной перспективе.
- Используйте отзывы клиентов и обеспечивайте поддержку на уровне обслуживания.
Принятие принципа “API как продукт” способствует созданию экосистемы сервисов, которую легче развивать и использовать для быстрой экспериментирования с новыми бизнес-идеями путем рекомбинации основных возможностей. Это отличает гибкий, инновационный бизнес по предоставлению продуктовых услуг, построенный на платформе API, от обычного бизнеса по интеграции предприятий, где API предоставляются как “приложение” к существующим продуктам для поддержки системной интеграции и оптимизированы для локальной серверной реализации.
Поймите конкретные сценарии использования ваших клиентов и тщательно проверьте компромиссы вариантов вашего API-дизайна с продуктовым мышлением. Избегайте краткосрочных оптимизаций реализации за счет ненужных обязательств со стороны клиента и уделяйте большое внимание качеству API и опыту разработчиков клиентов.
Принцип “API как продукт” тесно связан с нашим принципом “API First” (см. следующую главу), который больше сосредоточен на том, как мы разрабатываем высококачественные API.
2.3. API First
- Актуальность принципа “API First”:
- Принцип “API First” остается краеугольным камнем в Zalando, подчеркивая важность проектирования API до начала кодирования. Это способствует своевременному получению обратной связи, выявлению проблем на ранних этапах и формированию API, не привязанных к конкретным реализациям.
- Этот подход не противоречит принципам гибкой разработки, а, наоборот, дополняет их, обеспечивая итеративное развитие API с постоянным получением обратной связи.
- Детализация “API First”:
- Определение API вне кода: API должны быть определены с использованием стандартных языков спецификации (например, OpenAPI) до реализации. Это способствует глубокому пониманию предметной области и обобщению бизнес-сущностей.
- Ранний обзор: Регулярные коллегиальные и клиентские обзоры являются обязательными для обеспечения высокого качества, согласованности дизайна и архитектуры, а также для поддержки независимой разработки клиентских приложений.
- Единый источник истины: Спецификация API служит единым источником истины, являясь критически важной частью контракта между поставщиком и потребителем сервиса.
- Инструментальная поддержка: Стандартизированные форматы спецификации облегчают создание инструментов для обнаружения API, пользовательских интерфейсов, документации и автоматических проверок качества.
3. Общие рекомендации
- Принцип “API First”: `ДОЛЖЕН` следовать принципу “API First”.
- Спецификация API (OpenAPI): `ДОЛЖЕН` предоставлять спецификацию API с использованием OpenAPI. `СЛЕДУЕТ` использовать OpenAPI 3.0, но поддержка OpenAPI 2.0 (Swagger 2) также допускается. Рекомендуется использовать единый YAML-файл для спецификации.
- Руководство пользователя API: `СЛЕДУЕТ` предоставлять руководство пользователя API в дополнение к спецификации. Оно должно описывать область применения, примеры использования, обработку ошибок, архитектурный контекст и быть опубликовано в интернете, со ссылкой из спецификации (`#/externalDocs/url`).
- Язык API: `ДОЛЖЕН` писать API на американском английском (U.S. English).
- Ссылки: `ДОЛЖЕН` использовать только долговечные и неизменяемые удаленные ссылки, если не указано иное. Для ссылок на фрагменты API, контролируемые Zalando, разрешены специальные URL (`https://infrastructure-api-repository.zalandoapis.com/` и `https://opensource.zalando.com/restful-api-guidelines/{model.yaml}`).
4. Основы REST – Метаинформация
4.1. Должна содержать метаинформацию API
- `ДОЛЖЕН` содержать следующую метаинформацию OpenAPI:
- `#/info/title`: уникальное, функционально-описательное имя API.
- `#/info/version`: для различия версий спецификаций API в соответствии с семантическими правилами.
- `#/info/description`: подробное описание API.
- `#/info/contact/{name,url,email}`: сведения об ответственной команде.
- `ДОЛЖЕН` дополнительно предоставлять следующие свойства расширения OpenAPI:
- `#/info/x-api-id`: уникальный идентификатор API (см. правило 4.3).
- `#/info/x-audience`: предполагаемая целевая аудитория API (см. правило 4.4).
4.2. Должна использовать семантическое версионирование
- `ДОЛЖЕН` соблюдать правила семантического версионирования 2.0 (правила с 1 по 8 и 11) в формате `..`.
- `MAJOR`: инкрементируется при `несовместимых` изменениях API.
- `MINOR`: инкрементируется при добавлении `обратно совместимой` функциональности.
- `PATCH`: опционально инкрементируется при `обратно совместимых` исправлениях ошибок или редакционных изменениях.
- Предварительные версии (`0.y.z`) могут использоваться для начального проектирования API.
4.3. Должны предоставляться идентификаторы API
- Каждая спецификация API `ДОЛЖНА` иметь глобально уникальный и неизменяемый идентификатор API в `info`-блоке OpenAPI. Рекомендуется использовать UUID (например, `d0184f38-b98d-11e7-9c56-68f728c1ba70`).
- Идентификатор `ДОЛЖЕН` соответствовать шаблону `^[a-z0-9][a-z0-9-:.]{6,62}[a-z0-9]$`.
4.4. Должна быть указана аудитория API
- Каждый API `ДОЛЖЕН` быть классифицирован по предполагаемой целевой аудитории. Допускаются следующие значения (`x-extensible-enum`):
- `component-internal`
- `business-unit-internal`
- `company-internal`
- `external-partner`
- `external-public`
- Это определяется в `#/info/x-audience`. Меньшая группа аудитории не требует дополнительного объявления, если она включена в более широкую.
4.5. Использование функциональной схемы именования
- В зависимости от аудитории API `ДОЛЖЕН`/`СЛЕДУЕТ`/`МОЖЕТ` следовать функциональной схеме именования:
- `MUST` (должен): `external-public`, `external-partner`
- `SHOULD` (следует): `company-internal`, `business-unit-internal`
- `MAY` (может): `component-internal`
- Формат: ` ::= -`. Functional Name Registry `ДОЛЖЕН` использоваться для регистрации.
4.6. Должно соблюдаться соглашение об именовании хостов
- Имена хостов `ДОЛЖНЫ` (или `СЛЕДУЕТ`, в зависимости от аудитории) соответствовать функциональному именованию:
- `external-public`, `external-partner`: `.zalandoapis.com`
- Устаревшие конвенции (`..zalan.do`) разрешены только для `component-internal` API.
5. Основы REST – Безопасность
5.1. Все конечные точки должны быть защищены
- Каждая конечная точка API `ДОЛЖНА` быть защищена аутентификацией и авторизацией.
- `ДОЛЖЕН` указывать схему безопасности (bearer или oauth2).
- Для большинства внутренних API рекомендуется использовать `http` тип `Bearer Authentication` (`Authorization: Bearer `).
5.2. Разрешения (скоупы) должны быть определены и назначены
- Конечные точки `ДОЛЖНЫ` быть оснащены разрешениями, если требуется авторизация клиента (например, для оранжевых/красных данных).
- Для конечных точек, не требующих специальных разрешений, `ДОЛЖЕН` использовать псевдоразрешение `uid`.
5.3. Должна соблюдаться конвенция именования разрешений (скоупов)
- Имена разрешений `ДОЛЖНЫ` соответствовать следующему шаблону именования:
- ``: `.` (например, `order-management.read`)
- ``: `..` (например, `order-management.sales-order.read`)
- ``: `uid`
- `access-mode` включает `read` и `write`.
- Эта конвенция применяется к скоупам для связи сервис-к-сервису с использованием токенов Platform IAM.
6. Основы REST – Форматы данных
6.1. Должны использоваться стандартные форматы данных
- `ДОЛЖЕН` всегда использовать стандартные форматы OpenAPI, а также дополнительные форматы Zalando для электронной коммерции (например, для языковых, страновых и валютных кодов).
- Таблица форматов:
- `integer`: `int32`, `int64`, `bigint`
- `number`: `float`, `double`, `decimal`
- `string`: `byte`, `binary`, `date`, `date-time`, `time`, `duration`, `period`, `password`, `email`, `idn-email`, `hostname`, `idn-hostname`, `ipv4`, `ipv6`, `uri`, `uri-reference`, `uri-template`, `iri`, `iri-reference`, `uuid`, `json-pointer`, `relative-json-pointer`, `regex`, `iso-639-1`, `bcp47`, `iso-3166-alpha-2`, `iso-4217`, `gtin-13`.
6.2. Должен быть определен формат для числовых и целочисленных типов
- `ДОЛЖЕН` всегда указывать формат (`int32`, `int64`, `bigint` для `integer`; `float`, `double`, `decimal` для `number`).
- Двоичные данные `ДОЛЖНЫ` быть закодированы в `base64url`.
6.3. Должны использоваться стандартные форматы для свойств даты и времени
- `ДОЛЖЕН` использовать формат `string` с `date`, `date-time`, `time`, `duration` или `period`.
- При создании данных `ДОЛЖЕН` использовать заглавную букву `T` как разделитель между датой и временем и заглавную `Z` в конце для обозначения UTC.
- Пример: `2015-05-28T14:07:17Z`. Избегайте смещений часовых поясов, если это не требуется стандартом (например, HTTP-заголовки).
6.4. Следует выбирать подходящий формат даты или даты-времени
- `date`: `СЛЕДУЕТ` использовать для свойств, где точное время не требуется (например, даты документов, дни рождения).
- `date-time`: `СЛЕДУЕТ` использовать для всех остальных случаев, где требуется точная точка во времени.
6.5. Следует использовать стандартные форматы для свойств продолжительности и интервала времени
- `СЛЕДУЕТ` представлять продолжительность и временные интервалы в виде строк, отформатированных согласно ISO 8601 (RFC 3339).
6.6. Должны использоваться стандартные форматы для свойств страны, языка и валюты
- `Country codes`: `ISO 3166-1-alpha-2` (например, `DE`).
- `Language codes`: `ISO 639-1` (например, `en`).
- `Language variant tags`: `BCP 47` (например, `en-DE`).
- `Currency codes`: `ISO 4217` (например, `EUR`).
6.7. Следует использовать согласование контента, если клиенты могут выбирать из различных представлений ресурсов
- Если API поддерживает различные представления ресурсов (JSON, PDF, TEXT, HTML), `СЛЕДУЕТ` использовать согласование контента через заголовки `Accept`, `Accept-Language`, `Accept-Encoding`.
- `СЛЕДУЕТ` использовать стандартные типы мультимедиа (например, `application/json`, `application/pdf`).
6.8. Следует использовать UUID только при необходимости
- UUID `СЛЕДУЕТ` использовать только при необходимости крупномасштабной генерации ID (например, в распределенных системах без координации).
- Избегайте UUID в качестве первичных ключей для справочных данных или данных конфигурации с низким объемом ID.
- `ДОЛЖЕН` всегда использовать строковый тип для идентификаторов.
- `СЛЕДУЕТ` рассмотреть использование ULID вместо UUID для пагинации, упорядоченной по времени создания.
7. Основы REST – URL
7.1. Не следует использовать `/api` в качестве базового пути
- `СЛЕДУЕТ` избегать использования `/api` в качестве базового пути. В большинстве случаев все ресурсы должны быть доступны по корневому пути `/`.
- Если есть как публичные, так и внутренние API, `СЛЕДУЕТ` поддерживать две различные спецификации API и указывать соответствующую аудиторию.
7.2. Имена ресурсов должны быть во множественном числе
- `ДОЛЖЕН` использовать имена ресурсов во множественном числе, так как обычно предоставляется коллекция экземпляров ресурсов.
- Исключение: псевдоидентификатор `self`.
7.3. Должны использоваться URL-дружественные идентификаторы ресурсов
- Идентификаторы ресурсов `ДОЛЖНЫ` соответствовать регулярному выражению `[a-zA-Z0-9:._\-/]*` (только ASCII-символы: буквы, цифры, подчеркивание, дефис, двоеточие, точка, иногда слеш).
- Идентификаторы ресурсов `НЕ ДОЛЖНЫ` быть пустыми.
7.4. Сегменты пути должны использовать kebab-case
- Сегменты пути `ДОЛЖНЫ` быть строками в `kebab-case` (`^[a-z][a-z\-0-9]*$`). Первый символ — строчная буква, последующие — буквы, дефисы или цифры.
- Пример: `/shipment-orders/{shipment-order-id}`.
7.5. Должны использоваться нормализованные пути без пустых сегментов и конечных слешей
- `ДОЛЖЕН` не указывать пути с дублирующими или конечными слешами (например, `/customers//addresses` или `/customers/`).
- Сервисы `СЛЕДУЕТ` реализовать так, чтобы они были устойчивы к ненормализованным путям, нормализуя их перед обработкой.
7.6. URL-адреса должны быть без глаголов
- `ДОЛЖЕН` использовать только существительные в URL-адресах, так как API описывает ресурсы, а действия выражаются HTTP-методами.
- Пример: вместо `/cancel-order` используйте `POST /cancellations`.
7.7. Избегайте действий – думайте о ресурсах
- `ДОЛЖЕН` моделировать API вокруг ресурсных сущностей, используя стандартные HTTP-методы в качестве индикаторов операций (CRUD-подобные операции).
- Пример: для блокировки статьи используйте `PUT /article-locks/{article-id}` вместо действия `lock`.
7.8. Следует определять полезные ресурсы
- `СЛЕДУЕТ` определять ресурсы, которые покрывают 90% случаев использования клиентов, содержат необходимую, но минимальную информацию.
- `СЛЕДУЕТ` поддерживать фильтрацию и встраивание для расширения информации.
7.9. Должны использоваться доменные имена ресурсов
- `ДОЛЖЕН` использовать доменную номенклатуру для имен ресурсов (например, `sales-order-items` вместо `order-items`). Это улучшает понимание и уменьшает необходимость в дополнительной документации.
7.10. Следует моделировать полные бизнес-процессы
- API `СЛЕДУЕТ` содержать полные бизнес-процессы со всеми ресурсами, представляющими этот процесс. Это способствует согласованному проектированию и устраняет неявные зависимости между API.
7.11. Ресурсы и подресурсы должны идентифицироваться через сегменты пути
- `ДОЛЖЕН` идентифицировать ресурсы и подресурсы через сегменты пути: `/resources/{resource-id}/sub-resources/{sub-resource-id}`.
- Исключение: псевдоидентификатор `self`, если идентификатор ресурса передается через информацию авторизации.
7.12. Могут быть доступны составные ключи в качестве идентификаторов ресурсов
- Если ресурс лучше всего идентифицируется составным ключом (например, `/shopping-carts/{country}/{session-id}`), `МОЖЕТ` использовать его в URL.
- Это ограничивает возможность эволюции структуры идентификатора, поэтому API `ДОЛЖЕН` последовательно применять абстракцию составного ключа во всех параметрах запросов и ответов.
7.13. Можно рассмотреть использование (не)вложенных URL
- `МОЖЕТ` использовать вложенные URL (например, `/shoping-carts/.../cart-items/1`), если подресурс доступен только через родительский ресурс.
- Если ресурс имеет уникальный глобальный ID, `СЛЕДУЕТ` предоставлять его как ресурс верхнего уровня.
7.14. Следует ограничивать количество типов ресурсов
- `СЛЕДУЕТ` ограничивать количество типов ресурсов, предоставляемых через один API (рекомендуется 4-8).
- Ресурсный тип определяется как набор тесно связанных ресурсов (коллекция, ее члены и прямые подресурсы).
7.15. Следует ограничивать количество уровней подресурсов
- `СЛЕДУЕТ` использовать до 3 уровней подресурсов, чтобы избежать чрезмерной сложности API и длинных URL.
7.16. Параметры запроса должны использовать snake\_case (никогда camelCase)
- `ДОЛЖЕН` использовать `snake_case` для имен параметров запроса (например, `customer_number`, `sales_order_number`).
- Имена свойств `ДОЛЖНЫ` соответствовать регулярному выражению `^[a-z_][a-z_0-9]*$`.
7.17. Следует придерживаться общепринятых параметров запроса
- `ДОЛЖЕН` придерживаться следующих соглашений об именовании для параметров запроса (`REST Design – Pagination`):
- `q`: общий параметр запроса.
- `sort`: список полей через запятую, с `+` (по возрастанию) или `-` (по убыванию).
- `fields`: выражение для получения подмножества полей ресурса.
- `embed`: выражение для встраивания подсущностей.
- `offset`: числовое смещение для пагинации.
- `cursor`: непрозрачный указатель для пагинации.
- `limit`: предложенный клиентом лимит на количество записей на странице.
8. Основы REST – JSON-нагрузка
8.1. JSON должен использоваться как формат обмена данными нагрузки
- `ДОЛЖЕН` использовать JSON (RFC 7159) для представления структурированных данных.
- JSON-нагрузка `ДОЛЖНА` использовать JSON-объект в качестве структуры данных верхнего уровня.
- `ДОЛЖЕН` также соответствовать RFC 7493 (UTF-8, действительные Unicode-строки, уникальные имена членов).
8.2. Следует проектировать единую схему ресурсов для чтения и записи
- `СЛЕДУЕТ` использовать общую модель для чтения и записи одного и того же типа ресурса.
- Различия `СЛЕДУЕТ` учитывать с помощью `writeOnly` (только для запроса) и `readOnly` (только для ответа).
8.3. Следует учитывать сервисы, не полностью поддерживающие JSON/Unicode
- Серверы и клиенты, перенаправляющие JSON-содержимое на другие инструменты, `СЛЕДУЕТ` проверять полную поддержку JSON или Unicode. Если нет, `СЛЕДУЕТ` отклонять или санировать неподдерживаемые символы.
8.4. Может передавать не-JSON типы носителей с использованием специфичных для данных стандартных форматов
- `МОЖЕТ` поддерживать не-JSON типы носителей, если используются специфичные для бизнес-объектов стандартные форматы (например, изображения, документы, архивы).
- Общие форматы, кроме JSON (XML, CSV), `МОГУТ` предоставляться только дополнительно к JSON в качестве формата по умолчанию с использованием согласования контента.
8.5. Следует использовать стандартные типы носителей
- `СЛЕДУЕТ` использовать стандартные типы носителей IANA (например, `application/json`, `application/problem+json`).
- Избегайте пользовательских типов (`application/x.zalando.article+json`). Исключение: версионирование конечных точек API.
8.6. Имена массивов должны быть во множественном числе
- `СЛЕДУЕТ` использовать имена массивов во множественном числе (например, `items`), а имена объектов — в единственном (например, `item`).
8.7. Имена свойств должны быть camelCase (не snake_case)
- ИЗМЕНЕНИЕ ОТ ОРИГИНАЛЬНОГО РУКОВОДСТВА: В отличие от исходного руководства, которое предписывало `snake_case`, данное обновленное руководство `РЕКОМЕНДУЕТ` использовать **camelCase для имен свойств в JSON-нагрузке. Это соответствует большинству современных гайдлайнов по проектированию API (например, Google, Microsoft, AWS) и более гармонично сочетается с распространенными языками программирования (Java, JavaScript, C#), где `camelCase` является стандартной конвенцией для имен переменных и полей.
- Пример: `customerNumber`, `salesOrderNumber`, `billingAddress`.
- Обоснование изменения:** Хотя `snake_case` был принят некоторыми крупными компаниями, `camelCase` имеет более широкое распространение и лучшую интеграцию с современными инструментами и библиотеками, что упрощает разработку и поддержку клиентских приложений. `camelCase` также способствует более естественному чтению JSON-нагрузки в коде, написанном на большинстве объектно-ориентированных и скриптовых языков.
- Исключение:** Для параметров запроса и заголовков HTTP `ДОЛЖЕН` по-прежнему использовать `snake_case` и `kebab-case` соответственно, как указано в соответствующих разделах.
8.8. Следует объявлять значения перечислений с использованием формата строки UPPER_SNAKE_CASE
- `СЛЕДУЕТ` использовать `UPPER_SNAKE_CASE` для значений перечислений (например, `VALUE`, `YET_ANOTHER_VALUE`).
- Исключение: чувствительные к регистру значения из внешних источников (например, коды языков ISO 639-1) или значения `sort`
параметра.
8.9. Следует использовать соглашение об именовании для свойств даты/времени
- Имена свойств даты и времени `СЛЕДУЕТ` заканчивать на `_at` или содержать `date`, `time`, `timestamp`.
- Примеры: `created_at`, `modified_at`, `arrival_date`, `campaign_start_time`.
8.10. Следует определять карты с использованием additionalProperties
- `СЛЕДУЕТ` представлять карты (отображения строковых ключей на другие типы) с использованием `additionalProperties` в схеме OpenAPI.
- Пример: `translations` в объекте сообщения.
8.11. Должна использоваться одинаковая семантика для ‘null’ и отсутствующих свойств
- Если свойство может быть `null` или отсутствовать, `ДОЛЖЕН` обрабатывать обе ситуации одинаково.
- Это позволяет избежать ошибок из-за тонких различий в семантике, которые могут быть неправильно интерпретированы клиентами.
- Исключение: `JSON Merge Patch` (RFC 7396) использует `null` для удаления свойства.
8.12. Не рекомендуется использовать ‘null’ для булевых свойств
- `НЕ РЕКОМЕНДУЕТСЯ` использовать `null` для булевых свойств. Если `null` имеет смысл, `СЛЕДУЕТ` использовать перечисление (например, `YES`, `NO`, `UNDEFINED`).
8.13. Не рекомендуется использовать ‘null’ для пустых массивов
- `НЕ РЕКОМЕНДУЕТСЯ` использовать `null` для пустых массивов. Используйте пустой список `[]`.
8.14. Должны использоваться общие имена полей и семантика
- `ДОЛЖЕН` использовать общие имена полей и семантику:
- `id`: идентификатор объекта (строка, непрозрачная, уникальна в контексте).
- `xyz_id`: идентификатор другого объекта (например, `partner_id`).
- `etag`: ETag для оптимистической блокировки.
- Примеры: `created_at`, `modified_at`, `parent_node_id`.
8.15. Должны использоваться общие поля адреса
- `ДОЛЖЕН` использовать стандартные имена и семантику для всех атрибутов, относящихся к информации об адресе (например, `addressee`, `address` с полями `street`, `city`, `zip`, `country_code`).
8.16. Должен использоваться общий денежный объект
- `ДОЛЖЕН` использовать следующую общую структуру для денежных объектов:
```yaml
Money:
type: object
properties:
amount:
type: number
format: decimal
currency:
type: string
format: iso-4217
required:
- `ДОЛЖЕН` рассматривать `Money` как закрытый тип данных, предпочитая композицию наследованию.
- `ДОЛЖЕН` обеспечивать высокую точность (`decimal`) и не использовать `float` или `double` для расчетов.
9. Основы REST – HTTP-запросы
9.1. HTTP-методы должны использоваться правильно
- `ДОЛЖЕН` соблюдать стандартизированную HTTP-семантику (RFC-9110 “HTTP Semantics”).
- GET:
- `ДОЛЖЕН` использоваться для чтения одиночного или коллективного ресурса.
- Возвращает 404, если ресурс не существует (для одиночных).
- Возвращает 200 (коллекция пуста) или 404 (коллекция отсутствует) для коллекций.
- `НЕ ДОЛЖЕН` иметь тела запроса.
- GET с телом запроса**: Если требуется передача сложной структурированной информации с `GET`, а использование query-параметров невозможно (из-за ограничений на размер), `СЛЕДУЕТ` использовать `POST` с телом запроса и явно документировать это.
- `НЕ ДОЛЖЕН` использовать заголовки для передачи сложной структурированной информации из-за ненадежных ограничений на размер.
- PUT:
- `ДОЛЖЕН` использоваться для полного обновления (и иногда создания) ресурсов (одиночных или коллективных).
- Семантика: “пожалуйста, поместите приложенное представление по URI, заменяя любой существующий ресурс”.
- Обычно применяется к одиночным ресурсам.
- Как правило, `УСТОЙЧИВ` к отсутствию ресурсов, неявно создавая их перед обновлением.
- При успешном выполнении сервер `ЗАМЕНЯЕТ` весь ресурс.
- Успешные `PUT` запросы возвращают 200 или 204 (без возврата ресурса), 201 (если ресурс был создан), 202 (если запрос принят для асинхронной обработки).
- `СЛЕДУЕТ` отдавать предпочтение `POST` для создания (как минимум ресурсов верхнего уровня), а `PUT` — для обновлений. Если идентификатор ресурса полностью контролируется клиентом, `МОЖЕТ` использовать `PUT` для создания, передавая идентификатор в качестве параметра пути.
- Повторное выполнение `PUT` *должно быть* идемпотентно.
- POST:
- Обычно**: `ДОЛЖЕН` использоваться для создания одиночных ресурсов на конечной точке коллекции (`add the enclosed representation to the collection resource`).
- Редко**: `МОЖЕТ` использоваться для выполнения хорошо специфицированного запроса на одиночном ресурсе (`execute the given well specified request on the resource identified by the URL`).
- successful `POST` на коллекции создает один или несколько экземпляров ресурсов.
- Для одиночных ресурсов `СЛЕДУЕТ` возвращать 201 и новый объект ресурса (включая идентификатор).
- URL для получения ресурса `СЛЕДУЕТ` предоставлять в заголовке `Location`.
- Идентификатор ресурса `НЕ ДОЛЖЕН` передаваться клиентом в теле запроса, а `ДОЛЖЕН` создаваться и поддерживаться сервисом.
- Для нескольких ресурсов `СЛЕДУЕТ` возвращать 201, если они создаются атомарно.
- `ДОЛЖЕН` использовать код 207 для пакетных или массовых запросов, если запрос может частично завершиться неудачей.
- Повторное выполнение `POST` *не обязательно* является идемпотентным, но `СЛЕДУЕТ` `РАССМОТРЕТЬ` проектирование его как идемпотентного.
- `МОЖЕТ` поддерживать асинхронную обработку запросов (статус 202).
- PATCH:
- `ДОЛЖЕН` использоваться для частичного обновления объектов ресурсов.
- Тело запроса `ДОЛЖНО` содержать документ исправления (patch document) с определенным типом носителя.
- Успешные `PATCH` возвращают 200, 204 или 202.
- `СЛЕДУЕТ` выбирать один из следующих шаблонов (порядок предпочтения):
- `PUT` с полными объектами.
- `PATCH` с `JSON Merge Patch` (`application/merge-patch+json`).
- `PATCH` с `JSON Patch` (`application/json-patch+json`).
- `POST` (с явным описанием).
- Повторное выполнение `PATCH` *не обязательно* является идемпотентным, но `СЛЕДУЕТ` `РАССМОТРЕТЬ` проектирование его как идемпотентного.
- DELETE:
- `ДОЛЖЕН` использоваться для удаления ресурсов.
- Обычно применяется к одиночным ресурсам.
- `МОЖЕТ` применяться к нескольким ресурсам одновременно с использованием параметров запроса.
- Успешные `DELETE` возвращают 200, 204 или 202.
- Неуспешные `DELETE` возвращают 404 (не найден) или 410 (уже удален).
- После `DELETE` `GET` на ресурс `ДОЛЖЕН` возвращать 404 или 410.
- DELETE с query-параметрами**: `МОЖЕТ` иметь query-параметры в качестве фильтров.
- DELETE с телом запроса**: Если требуется дополнительная информация, не являющаяся фильтрами, `РЕКОМЕНДУЕТСЯ` использовать `POST`, так как семантика `DELETE` с телом не определена RFC-9110.
- HEAD:
- `ДОЛЖЕН` использоваться для получения информации заголовка для одиночных ресурсов и коллекций.
- Имеет ту же семантику, что и `GET`, но возвращает только заголовки, без тела.
- OPTIONS:
- `МОЖЕТ` использоваться для проверки доступных операций (HTTP-методов) для данной конечной точки.
- Ответы `OPTIONS` обычно возвращают список методов в заголовке `Allow`.
9.2. Должны выполняться общие свойства методов
- Реализации методов `ДОЛЖНЫ` соответствовать следующим свойствам согласно RFC 9110 Section 9.2:
- `Safe`: `GET`, `HEAD`, `OPTIONS`, `TRACE`
- `Idempotent`: `GET`, `HEAD`, `PUT`, `DELETE`, `OPTIONS`, `TRACE` (для `POST`/`PATCH` `СЛЕДУЕТ` рассмотреть идемпотентность)
- `Cacheable`: `GET`, `HEAD` (для `POST` `МОЖЕТ` быть, но редко поддерживается)
9.3. Следует рассмотреть проектирование POST и PATCH как идемпотентных операций
- `СЛЕДУЕТ` рассмотреть проектирование `POST` и `PATCH` как идемпотентных, чтобы предотвратить дублирование ресурсов или потерю обновлений.
- Применяемые шаблоны:
- Conditional key (условный ключ):** через заголовок `If-Match` (например, для `ETag`). Предотвращает дублирование и потерю обновлений.
- Secondary key (вторичный ключ):** через свойство ресурса в теле запроса. Хранится постоянно в ресурсе, обеспечивает идемпотентность при создании (избегает дубликатов).
- Idempotency-Key header:** клиентский ключ через заголовок `Idempotency-Key` (временный). Обеспечивает точно такой же ответ для повторных запросов.
- Пример использования вторичного ключа: `shopping cart ID` в ресурсе заказа.
9.4. Следует использовать вторичный ключ для идемпотентного проектирования POST
- `СЛЕДУЕТ` использовать вторичный ключ, предоставляемый в теле запроса, для идемпотентного создания `POST`, чтобы избежать дублирования ресурсов.
- Вторичный ключ хранится постоянно в ресурсе как альтернативный или комбинированный ключ, защищенный ограничением уникальности.
9.5. Может поддерживать асинхронную обработку запросов
- `МОЖЕТ` использовать асинхронную обработку для долгих запросов.
- `РЕКОМЕНДУЕТСЯ` представлять асинхронную обработку через ресурс “job” со статусом (например, `POST /report-jobs` возвращает 201 с `job-id` и URL в `Location`).
- Если нет отдельного ресурса “job”, `МОЖЕТ` использовать 202 с заголовком `Location`, указывающим на отчет.
- `НЕ ДОЛЖЕН` использовать 204 или 404 вместо 202.
9.6. Формат коллекции заголовков и параметров запроса должен быть определен
- `ДОЛЖЕН` явно определить формат коллекции (либо список через запятую, либо повторение параметра) в спецификации OpenAPI, так как OpenAPI не поддерживает оба варианта одновременно.
- Для заголовков: `style: simple, explode: false` (не разрешено).
- Для запросов: `style: form, explode: false` или `style: form, explode: true`.
9.7. Следует проектировать простые языки запросов с использованием параметров запроса
- `СЛЕДУЕТ` использовать параметры запроса для простых языков запросов, так как это нативно для HTTP, легко расширяемо и хорошо поддерживается.
- Для API, используемых внешними командами, `СЛЕДУЕТ` использовать простые языки запросов. Для внутренних или специфичных случаев `МОЖЕТ` использовать более сложные.
- Примеры: `name=Zalando`, `color=red,green`, `limit=5`, `created_after=2019-07-17`.
9.8. Следует проектировать сложные языки запросов с использованием JSON
- Для сложных языков запросов (например, для поиска, каталогов продуктов) с большим количеством фильтров, динамическими фильтрами или сложными операторами (`and`, `or`, `not`), `СЛЕДУЕТ` использовать вложенные JSON-структуры.
- Пример: JSON-документ для сложного запроса с `and` и `or`.
- Подразумевает использование шаблона `GET` с телом запроса.
9.9. Должна быть документирована неявная фильтрация ответов
- Если в коллекции ресурсов или запросах применяется неявная фильтрация (например, по авторизации пользователя), `ДОЛЖЕН` документировать это в описании конечной точки в спецификации API.
- Пример: `GET /business-partners` возвращает только партнеров, доступных текущему пользователю.
10. Основы REST – Коды состояния HTTP
10.1. Должны использоваться официальные коды состояния HTTP
- `ДОЛЖЕН` использовать только официальные коды состояния HTTP (из RFC и IANA Status Code Registry) и в соответствии с их семантикой.
- Избегайте неофициальных кодов (например, от Nginx).
10.2. Должны быть указаны успешные и ошибочные ответы
- `ДОЛЖЕН` определить все успешные и специфичные для сервиса ошибочные ответы в спецификации API.
- Описания ошибок `ДОЛЖНЫ` предоставлять информацию об условиях, приведших к ошибке.
- Исключение: стандартные клиентские и серверные ошибки (401, 403, 404, 500, 503) не требуют индивидуального определения, если их семантика очевидна.
10.3. Следует использовать только наиболее распространенные коды состояния HTTP
- `СЛЕДУЕТ` использовать только наиболее распространенные и понятные коды (200, 201, 202, 204, 207, 304, 400, 401, 404, 405, 406, 409, 412, 415, 428, 429, 500, 501, 502, 503, 504).
- Избегайте менее распространенных кодов (`205`, `206`, `301`, `302`, `303`, `307`, `308`, `408`, `410`, `411`, `417`, `418`, `422`, `423`, `424`, `431`, `505`, `507`, `511`), если они не имеют четкой, специфичной для API семантики.
- Коды, которые не возвращаются API, `НЕ ДОЛЖНЫ` документироваться.
10.4. Должны использоваться наиболее специфичные коды состояния HTTP
- `ДОЛЖЕН` использовать наиболее специфичные коды состояния HTTP при возврате информации о статусе обработки запроса или ошибках.
10.5. Должен использоваться код 207 для пакетных или массовых запросов
- `ДОЛЖЕН` использовать 207 (Multi-Status) для пакетных или массовых запросов, если могут быть частичные неудачи или требуется информация о статусе для каждого элемента.
- Ответ с 207 `ДОЛЖЕН` содержать `multi-status response` в теле, включающий `id`, `status` и `description` для каждого элемента.
10.6. Должен использоваться код 429 с заголовками для ограничения скорости
- `ДОЛЖЕН` использовать 429 (Too Many Requests) при превышении лимита запросов.
- `ДОЛЖЕН` включать заголовки `Retry-After` (с задержкой в секундах) или `X-RateLimit-Limit`, `X-RateLimit-Remaining`, `X-RateLimit-Reset` (время в секундах до сброса).
10.7. Должна поддерживаться проблема JSON
- `ДОЛЖЕН` поддерживать `Problem JSON` (RFC 9457, `application/problem+json`) для предоставления расширяемой информации об ошибках.
- Каждая конечная точка `ДОЛЖНА` быть способна возвращать `Problem JSON` для ошибок 4xx и 5xx.
- Клиенты `ДОЛЖНЫ` быть устойчивы и не зависеть от возврата `Problem JSON`.
- `МОЖЕТ` определять пользовательские типы проблем для более подробной информации об ошибках.
- Идентификаторы типов и экземпляров проблем `НЕ ПРЕДНАЗНАЧЕНЫ` для разрешения (`URI references`), но `МОГУТ` указывать на документацию.
10.8. Не должны раскрываться трассировки стека
- `НЕ ДОЛЖЕН` раскрывать трассировки стека в ответах, так как они содержат детали реализации, утечки конфиденциальной информации и информацию об уязвимостях.
10.9. Не следует использовать коды перенаправления
- `НЕ СЛЕДУЕТ` использовать коды перенаправления (кроме 304). Перенаправление трафика `ЛУЧШЕ` выполнять на уровне API (например, через обратный прокси) без участия клиента.
- Для идемпотентных `POST` запросов, где ресурс уже существует, `СЛЕДУЕТ` возвращать 200 с заголовком `Location`.
- Для неидемпотентных `POST` запросов, где ресурс не может быть создан повторно, `СЛЕДУЕТ` возвращать 409.
11. Основы REST – HTTP-заголовки
11.1. Использование стандартных определений заголовков
- `СЛЕДУЕТ` использовать стандартные определения HTTP-заголовков из руководства для упрощения API.
- Пример: `parameters` или `headers` в `components`.
11.2. Могут использоваться стандартные заголовки
- API `МОГУТ` использовать HTTP-заголовки, определенные не устаревшими RFC. Поддерживаемые заголовки `ДОЛЖНЫ` быть явно упомянуты в спецификации API.
11.3. Следует использовать kebab-case с прописными буквами для HTTP заголовков
- `СЛЕДУЕТ` использовать `kebab-case` с прописными буквами для первых букв каждого слова (например, `If-Modified-Since`, `Accept-Encoding`, `Content-ID`).
- Исключение: общепринятые сокращения, такие как `ID`.
- Заголовки HTTP нечувствительны к регистру, но это для согласованности.
11.4. Заголовки `Content-*` должны использоваться правильно
- `ДОЛЖЕН` правильно использовать заголовки `Content-*`, которые описывают содержимое тела сообщения и могут использоваться как в запросах, так и в ответах.
- Примеры: `Content-Disposition`, `Content-Encoding`, `Content-Length`, `Content-Language`, `Content-Location`, `Content-Range`, `Content-Type`.
11.5. Следует использовать заголовок `Location` вместо `Content-Location`
- `СЛЕДУЕТ` использовать заголовок `Location` вместо `Content-Location` для указания местоположения ресурса в ответах на создание или перенаправление.
- Это позволяет избежать сложностей и двусмысленности, связанных с `Content-Location`.
11.6. Может использоваться заголовок `Content-Location`
- `МОЖЕТ` использовать `Content-Location` в успешных операциях записи (`PUT`, `POST`, `PATCH`) и чтения (`GET`, `HEAD`) для управления кэшированием или указания фактического местоположения переданного ресурса.
- При использовании `Content-Location` `Content-Type` `ДОЛЖЕН` быть также установлен.
11.7. Может рассматриваться поддержка заголовка Prefer для управления предпочтениями обработки
- `МОЖЕТ` рассматривать поддержку заголовка `Prefer` (RFC 7240), который позволяет клиентам запрашивать желаемое поведение обработки с сервера (например, `respond-async`, `return=minimal`, `return=total-count`, `wait`, `handling=strict`).
- Поддержка `Prefer` является опциональной и `РЕКОМЕНДУЕТСЯ` по сравнению с проприетарными заголовками `X-`.
11.8. Может рассматриваться поддержка ETag вместе с заголовками If-Match / If-None-Match
- `МОЖЕТ` рассматривать поддержку заголовка `ETag` вместе с `If-Match` и `If-None-Match` для обнаружения конфликтов при конкурентных операциях обновления (`PUT`, `POST`, `PATCH`).
- `If-Match`: для проверки, соответствует ли версия обновляемой сущности запрошенному `ETag`. Если нет, возвращает 412.
- `If-None-Match`: для обнаружения конфликтов при создании ресурсов. Если найдена соответствующая сущность, возвращает 412.
11.9. Может рассматриваться поддержка заголовка Idempotency-Key
- `МОЖЕТ` рассматривать поддержку заголовка `Idempotency-Key` для обеспечения строгой идемпотентности (одинаковые ответы для повторных запросов) при создании или обновлении ресурсов.
- Клиент предоставляет уникальный ключ запроса, который временно хранится на сервере вместе с ответом.
- Ключи `ДОЛЖНЫ` иметь достаточную энтропию (например, UUID v4). Истекают через 24 часа.
11.10. Следует использовать только указанные проприетарные Zalando заголовки
- `СЛЕДУЕТ` избегать проприетарных HTTP-заголовков, но `МОЖЕТ` использовать разрешенные Zalando проприетарные заголовки для передачи общей, неспецифичной для бизнеса контекстной информации (например, `X-Flow-ID`, `X-Tenant-ID`, `X-Sales-Channel`, `X-Frontend-Type`, `X-Device-Type`, `X-Device-OS`, `X-Mobile-Advertising-ID`).
- Имена `ДОЛЖНЫ` начинаться с `X-` и использовать `dash-case`.
- Исключение: `X-RateLimit-*` заголовки.
11.11. Проприетарные заголовки должны распространяться
- Все проприетарные заголовки Zalando, определенные в 11.10, `ДОЛЖНЫ` распространяться по всей цепочке вызовов (end-to-end) без изменений.
- Значения `МОГУТ` влиять на результаты запросов.
11.12. Должен поддерживаться X-Flow-ID
- `ДОЛЖЕН` поддерживать `X-Flow-ID` в запросах RESTful API и поле `flow_id` в событиях.
- `X-Flow-ID` — это общий параметр для отслеживания потоков вызовов через систему и корреляции действий сервисов.
- Допустимые форматы: UUID (RFC-4122), base64 (RFC-4648), base64url (RFC-4648 Section 5), случайная строка (ASCII, макс. 128 символов).
- Сервисы `ДОЛЖНЫ` создавать новый `Flow-ID`, если он не предоставлен.
- Сервисы `ДОЛЖНЫ` распространять `Flow-ID` (передавать во все дальнейшие вызовы API и события, записывать в логи).
12. Проектирование REST – Гипермедиа
12.1. Должен использоваться уровень зрелости REST 2
- `ДОЛЖЕН` стремиться к хорошей реализации уровня зрелости REST 2 (использование HTTP-глаголов и кодов состояния).
- Это означает: `ДОЛЖЕН` избегать действий в URL, `ДОЛЖЕН` оставлять URL без глаголов, `ДОЛЖЕН` правильно использовать HTTP-методы, `СЛЕДУЕТ` использовать только наиболее распространенные коды состояния HTTP.
12.2. Может использоваться уровень зрелости REST 3 – HATEOAS
- `НЕ РЕКОМЕНДУЕТСЯ` реализовывать уровень зрелости REST 3 (HATEOAS) в общем случае, так как он добавляет сложность без явной ценности в контексте SOA Zalando.
- Основные опасения: HATEOAS не добавляет ценности для самоописания API в условиях API First; общие клиенты HATEOAS не работают на практике в SOA; спецификации OpenAPI не поддерживают HATEOAS в достаточной мере.
- `МОЖЕТ` использовать HATEOAS только в случае, если выявлена явная ценность, оправдывающая дополнительную сложность.
12.3. Должны использоваться общие элементы управления гипертекстом
- При встраивании ссылок на другие ресурсы в представления `ДОЛЖЕН` использовать общий объект `hypertext control`.
- Объект `ДОЛЖЕН` содержать как минимум атрибут `href`: URI ресурса, на который указывает ссылка (только HTTP(s)).
- Имя атрибута, содержащего `HttpLink` объект, `ДОЛЖНО` указывать на связь между ссылающимся и ссылаемым ресурсами.
- `СЛЕДУЕТ` использовать имена из IANA Link Relation Registry. Дефисы в IANA-именах `ДОЛЖНЫ` быть заменены на подчеркивания (`snake_case`).
12.4. Следует использовать простые элементы управления гипертекстом для пагинации и само-ссылок
- Для пагинации и само-ссылок `СЛЕДУЕТ` использовать упрощенную форму расширяемых общих гипертекстовых элементов управления, состоящую из простого URI-значения в сочетании с соответствующими отношениями ссылок (например, `next`, `prev`, `first`, `last`, `self`).
12.5. Для идентификации ресурсов должен использоваться полный, абсолютный URI
- Ссылки на другие ресурсы `ДОЛЖНЫ` всегда использовать полный, абсолютный URI.
- Это снижает сложность на стороне клиента и избегает двусмысленности с базовыми URI.
12.6. Не следует использовать заголовки ссылок с JSON-сущностями
- `НЕ ДОЛЖЕН` использовать заголовки `Link` (RFC 8288) в сочетании с JSON-носителями. Ссылки `ПРЕДПОЧТИТЕЛЬНЕЕ` встраивать непосредственно в JSON-нагрузку.
13. Проектирование REST – Производительность
13.1. Следует снижать потребность в пропускной способности и улучшать отзывчивость
- API `СЛЕДУЕТ` поддерживать методы для снижения пропускной способности и ускорения ответа, особенно для мобильных клиентов.
- Общие методы: gzip-сжатие, фильтрация полей, ETag (для условных запросов), заголовок `Prefer`, пагинация, кэширование мастер-данных.
13.2. Следует использовать gzip-сжатие
- Серверы и клиенты `СЛЕДУЕТ` поддерживать кодирование содержимого `gzip` для уменьшения передаваемых данных и ускорения ответа.
- Серверы `ДОЛЖНЫ` также поддерживать несжатый контент для тестирования.
- Спецификация API `СЛЕДУЕТ` определять `Accept-Encoding` и `Content-Encoding`.
13.3. Следует поддерживать частичные ответы через фильтрацию
- `СЛЕДУЕТ` поддерживать фильтрацию возвращаемых полей сущностей с помощью параметра запроса `fields`.
- Пример: `GET http://api.example.org/users/123?fields=(name,friends(name))`
- OpenAPI не поддерживает формальное описание различных схем, поэтому `СЛЕДУЕТ` документировать это в описании конечной точки.
13.4. Следует разрешать опциональное встраивание подресурсов
- `СЛЕДУЕТ` разрешать встраивание связанных ресурсов (расширение ресурсов) для уменьшения количества запросов, используя параметр запроса `embed`.
- Пример: `GET /order/123?embed=(items)`.
13.5. Должны быть документированы кэшируемые конечные точки GET, HEAD и POST
- Кэширование на стороне клиента и прозрачное веб-кэширование `СЛЕДУЕТ` избегать, если только сервис не требует его для самозащиты.
- По умолчанию, серверы и клиенты `ДОЛЖНЫ` устанавливать `Cache-Control: no-store`.
- Если кэширование требуется, `ДОЛЖЕН` документировать все кэшируемые конечные точки `GET`, `HEAD` и `POST` путем объявления поддержки заголовков `Cache-Control`, `Vary` и `ETag` в ответе.
- `Default Cache-Control`: `private`, `must-revalidate`, `max-age`.
- `Default Vary`: `accept`, `accept-encoding`.
- `РЕКОМЕНДУЕТСЯ` прикреплять кэш непосредственно к сервисной (или шлюзовой) слою приложения.
14. Проектирование REST – Пагинация
14.1. Должна поддерживаться пагинация
- `ДОЛЖНА` поддерживаться пагинация для доступа к спискам данных, чтобы защитить сервис от перегрузки и поддержать итерацию на стороне клиента.
- `ДОЛЖЕН` придерживаться общих имен параметров запроса (`offset`, `cursor`, `limit`).
14.2. Следует предпочитать пагинацию на основе курсоров, избегать пагинации на основе смещения
- `СЛЕДУЕТ` предпочитать пагинацию на основе курсоров из-за ее эффективности, особенно для больших объемов данных и NoSQL-баз данных.
- Курсор `ДОЛЖЕН` быть непрозрачной строкой для клиентов, шифрующей (или кодирующей) позицию страницы, направление и примененные фильтры запроса.
14.3. Следует использовать объект страницы ответа пагинации
- `СЛЕДУЕТ` использовать объект страницы ответа с полями `self`, `first`, `prev`, `next`, `last` (`uri|cursor`).
- `ДОЛЖЕН` включать поле `items` для содержимого страницы.
- `МОЖЕТ` включать поле `query` для примененных фильтров запроса, если используется `GET` с телом.
14.4. Следует использовать ссылки пагинации
14.5. Следует избегать общего количества результатов
- `СЛЕДУЕТ` избегать предоставления общего количества результатов в ответах пагинации, так как его расчет является дорогостоящей операцией.
- Если клиент действительно требует общее количество результатов, `МОЖЕТ` поддерживать это требование через заголовок `Prefer` с директивой `return=total-count`.
15. Проектирование REST – Совместимость
15.1. Обратная совместимость не должна нарушаться
- `ДОЛЖЕН` изменять API, сохраняя при этом работоспособность всех потребителей. API — это контракты, которые не могут быть нарушены в одностороннем порядке.
- Используйте совместимые расширения или новые версии API с поддержкой старых.
15.2. Следует предпочитать совместимые расширения
- `СЛЕДУЕТ` применять следующие правила:
- Добавлять только опциональные, никогда не обязательные поля.
- Никогда не изменять семантику полей.
- Никогда не делать логику валидации более строгой.
- Диапазоны перечислений (`enum`) могут быть уменьшены для входных параметров, если сервер поддерживает старые значения. Для выходных параметров `НЕ МОГУТ` быть расширены.
- `СЛЕДУЕТ` использовать `x-extensible-enum` для перечислений, которые будут расширяться.
15.3. Следует проектировать API консервативно
- Разработчики `СЛЕДУЕТ` быть консервативными и точными в том, что они принимают от клиентов:
- Неизвестные входные поля `НЕ СЛЕДУЕТ` игнорировать; серверы `СЛЕДУЕТ` возвращать 400.
- `ДОЛЖЕН` быть точными в определении ограничений входных данных и возвращать специальные ошибки при их нарушении.
- `ПРЕДПОЧТИТЕЛЬНО` быть более специфичным и ограничительным.
15.4. Клиенты должны быть готовы принимать совместимые расширения API
- Клиенты сервисов `ДОЛЖНЫ` применять принцип устойчивости:
- Быть консервативными с запросами API и входными данными.
- Быть толерантными при обработке и чтении данных ответов API: игнорировать новые поля в полезной нагрузке, не удалять их для последующих `PUT` запросов.
- Быть готовыми к тому, что `x-extensible-enum` параметры могут возвращать новые значения; быть агностиками или предоставлять поведение по умолчанию для неизвестных значений.
- Быть готовыми обрабатывать коды состояния HTTP, явно не указанные в определениях конечных точек.
- Следовать перенаправлениям (301).
15.5. Спецификация OpenAPI должна по умолчанию рассматриваться как открытая для расширения
- `ДОЛЖЕН` рассматривать определения объектов OpenAPI как открытые для расширения по умолчанию (как в JSON-Schema 5.18 `additionalProperties`).
- Клиенты `НЕ ДОЛЖНЫ` предполагать, что объекты закрыты для расширения без `additionalProperties` и `ДОЛЖНЫ` игнорировать неизвестные поля.
- Серверы, получающие неожиданные данные, `СЛЕДУЕТ` отклонять запросы с неопределенными полями, чтобы сигнализировать клиентам, что эти поля не будут сохранены.
- Форматы API `НЕ ДОЛЖНЫ` объявлять `additionalProperties` как `false`.
15.6. Следует избегать версионирования
- `СЛЕДУЕТ` избегать создания дополнительных версий API.
- Если изменение API несовместимо, `СЛЕДУЕТ` создать новый ресурс (вариант), новый сервис или новую версию API.
- Настоятельно `РЕКОМЕНДУЕТСЯ` использовать первые два подхода.
15.7. Должно использоваться версионирование типа носителя
- Если версионирование API неизбежно, `ДОЛЖЕН` использовать версионирование типа носителя (`media type versioning`, например, `application/x.zalando.cart+json;version=2`).
- Это менее тесно связано и поддерживает согласование контента.
- Версионирование применяется только к схеме полезной нагрузки, а не к URI или семантике метода.
- `СЛЕДУЕТ` включать `Content-Type` в заголовок `Vary`.
15.8. Не следует использовать версионирование URL
- `НЕ ДОЛЖЕН` использовать версионирование URL (например, `/v1/customers`). Это приводит к более тесной связи и усложняет управление релизами. Вместо этого `ДОЛЖЕН` использовать версионирование типа носителя.
15.9. Всегда должны возвращаться JSON-объекты как структуры данных верхнего уровня
- `ДОЛЖЕН` всегда возвращать JSON-объект (а не массив) в качестве структуры данных верхнего уровня в теле ответа, чтобы обеспечить будущую расширяемость.
- Карты (`additionalProperties`), хотя и являются технически объектами, также `ЗАПРЕЩЕНЫ` как структуры верхнего уровня, поскольку они не поддерживают совместимые будущие расширения.
15.10. Следует использовать открытый список значений (x-extensible-enum) для типов перечислений
- `СЛЕДУЕТ` использовать `x-extensible-enum` для перечислений, которые, вероятно, будут расширяться.
- Это позволяет избежать проблем совместимости, присущих `enum` JSON-схемы (которые по определению являются закрытым набором значений).
- Клиенты `ДОЛЖНЫ` быть готовы к расширениям перечислений и реализовать запасное/поведение по умолчанию для неизвестных значений.
16. Проектирование REST – Устаревшая функциональность
16.1. Устаревшая функциональность должна быть отражена в спецификациях API
- `ДОЛЖЕН` установить `deprecated: true` для устаревших элементов (конечная точка, параметр, объект схемы, свойство схемы).
- Если планируется отключение, `ДОЛЖЕН` указать дату `sunset` и документировать альтернативы.
16.2. Должно быть получено одобрение клиентов перед отключением API
- `ДОЛЖЕН` убедиться, что все клиенты дали согласие на дату `sunset` перед отключением API, его версии или функции.
- `СЛЕДУЕТ` помогать клиентам с миграцией, предоставляя руководства.
16.3. Должно быть собрано согласие внешних партнеров на срок устаревания
- Если API используется внешними партнерами, владелец API `ДОЛЖЕН` определить разумный срок поддержки API после объявления об устаревании.
- Все внешние партнеры `ДОЛЖНЫ` выразить согласие с этим сроком.
16.4. Использование устаревшего API, запланированного к выводу из эксплуатации, должно отслеживаться
- Владельцы API `ДОЛЖНЫ` отслеживать использование API, запланированных к выводу из эксплуатации, для мониторинга прогресса миграции и избежания неконтролируемых сбоев.
16.5. Следует добавлять заголовки Deprecation и Sunset к ответам
- В течение фазы устаревания `СЛЕДУЕТ` добавлять заголовки `Deprecation: ` (или `true`) и `Sunset: ` к каждому ответу, затронутому устаревшим элементом.
- Это информирует клиентов о предстоящих изменениях.
- Пример: `Deprecation: Tue, 31 Dec 2024 23:59:59 GMT`, `Sunset: Wed, 31 Dec 2025 23:59:59 GMT`.
16.6. Следует добавлять мониторинг для заголовков Deprecation и Sunset
- Клиенты `СЛЕДУЕТ` отслеживать эти заголовки и создавать оповещения для планирования миграционных задач.
16.7. Не следует начинать использовать устаревшие API
- Клиенты `НЕ ДОЛЖНЫ` начинать использовать устаревшие API, версии API или функции API.
17. Операции REST
17.1. Спецификация OpenAPI должна быть опубликована для не-компонентных внутренних API
- Все сервисные приложения `ДОЛЖНЫ` публиковать спецификации OpenAPI своих внешних API.
- Публикация происходит путем копирования спецификации OpenAPI в зарезервированный каталог `/zalando-apis` артефакта развертывания.
- Это обеспечивает обнаружаемость API через API Portal Zalando.
17.2. Следует отслеживать использование API
- Владельцы API `СЛЕДУЕТ` отслеживать использование API в продакшене для получения информации о клиентах.
- Идентификация клиентов `СЛЕДУЕТ` осуществляться путем логирования `client-id` из токена OAuth.
18. Основы Событий – Типы Событий
18.1. События должны быть определены в соответствии с общими рекомендациями API
- События `ДОЛЖНЫ` быть согласованы с другими данными API и общими рекомендациями API (насколько это применимо).
- Большинство разделов руководства (Общие рекомендации, Основы REST – Форматы данных, Основы REST – JSON-нагрузка, Проектирование REST – Гипермедиа) применимы к обмену данными событий.
18.2. События должны рассматриваться как часть интерфейса сервиса
- События являются частью интерфейса сервиса с внешним миром, эквивалентной по значимости REST API сервиса.
- Сервисы, публикующие данные, `ДОЛЖНЫ` относиться к своим событиям как к первоочередной задаче проектирования (принцип “API First”).
18.3. Схема события должна быть доступна для просмотра
- Сервисы, публикующие данные событий, `ДОЛЖНЫ` предоставить схему события, а также определение типа события для просмотра.
18.4. События должны быть специфицированы и зарегистрированы как типы событий
- В архитектуре Zalando события регистрируются с использованием структуры, называемой `Event Type`.
- `Event Type` `ДОЛЖЕН` определять: категорию (общая, изменение данных), имя, аудиторию, владеющее приложение, схему полезной нагрузки, режим совместимости.
- Пример объекта `EventType` на основе OpenAPI представлен в исходном документе.
18.5. Должно соблюдаться соглашение об именовании типов событий
- Имена типов событий `ДОЛЖНЫ` (или `СЛЕДУЕТ`, в зависимости от аудитории) соответствовать функциональному именованию:
- ` ::= .[.]`
- Примеры: `transactions-order.order-cancelled`, `customer-personal-data.email-changed.v2`.
- `СЛЕДУЕТ` использовать согласованное именование, если одна и та же сущность представлена как событием изменения данных, так и RESTful API.
18.6. Должно быть указано владение типами событий
- Определения событий `ДОЛЖНЫ` иметь явное владение, указываемое через поле `owning_application` в `EventType`.
18.7. Режим совместимости должен быть тщательно определен
- Владельцы типов событий `ДОЛЖНЫ` уделять внимание выбору режима совместимости в `EventType` (`compatible`, `forward`, `none`).
- `none`: любые изменения схемы разрешены.
- `forward`: пользователи могут читать события с последней версией схемы, используя предыдущую версию.
- `compatible`: изменения должны быть полностью совместимы (только добавление новых опциональных свойств, запрещены другие изменения).
18.8. Схема события должна соответствовать объекту схемы OpenAPI
- `ДОЛЖЕН` использовать `Schema Object` из OpenAPI Specification для определения схем событий.
- `НЕ ДОЛЖЕН` использовать запрещенные ключевые слова `JSON Schema` (`additionalItems`, `contains`, `patternProperties`, `dependencies`, `propertyNames`, `const`, `not`, `oneOf`).
- `Schema Object` изменяет `additionalProperties` и добавляет `readOnly`, `discriminator`.
18.9. Следует избегать additionalProperties в схемах типов событий
- `СЛЕДУЕТ` избегать использования `additionalProperties` в схемах типов событий, чтобы поддерживать эволюцию схемы и обратную совместимость.
- Публиканты, стремящиеся обеспечить совместимость, `ДОЛЖНЫ` определять новые опциональные поля и обновлять свои схемы заранее.
- Потребители `ДОЛЖНЫ` игнорировать поля, которые они не могут обработать.
18.10. Должно использоваться семантическое версионирование схем типов событий
- Схемы событий `ДОЛЖНЫ` версионироваться аналогично REST API (`MAJOR.MINOR.PATCH`).
- Изменения в `compatible` или `forward` режиме приводят к `PATCH` или `MINOR` ревизии (major changes не разрешены).
- Изменения в `none` режиме могут привести к `PATCH`, `MINOR` или `MAJOR` изменениям.
19. Основы Событий – Категории Событий
19.1. Должно быть обеспечено соответствие событий категории событий
- `ДОЛЖЕН` обеспечить, чтобы события соответствовали предопределенной структуре категории (например, `GeneralEvent` или `DataChangeEvent`).
- `GeneralEvent`: общая категория, с полем `metadata`.
- `DataChangeEvent`: для изменений сущностей, с полями `metadata`, `data_op`, `data_type`, `data`.
19.2. Должны предоставляться обязательные метаданные события
- `ДОЛЖЕН` предоставлять `eid` (идентификатор события) и `occurred_at` (технический временной штамп создания события производителем) в метаданных события.
- Другие поля (`received_at`, `version`, `parent_eids`, `flow_id`, `partition`) могут быть обогащены посредниками.
19.3. Должны предоставляться уникальные идентификаторы событий
- `ДОЛЖЕН` предоставлять `eid` как уникальный идентификатор для события в пределах его типа/потока.
- Производители `ДОЛЖНЫ` использовать тот же `eid` при повторной публикации того же объекта события.
- `eid` поддерживает потребителей событий в обнаружении и устойчивости к дубликатам.
19.4. Общие события должны использоваться для сигнализации шагов в бизнес-процессах
- При публикации событий, представляющих шаги в бизнес-процессе, типы событий `ДОЛЖНЫ` основываться на категории `General Event`.
- `ДОЛЖЕН` содержать специфический идентификатор процесса (bp-id) и средства для корректного упорядочивания.
- `ДОЛЖЕН` публиковать событие надежно.
19.5. Следует обеспечивать явный порядок событий для общих событий
- `СЛЕДУЕТ` предоставлять явную информацию о деловом порядке событий для общих событий.
- `ДОЛЖЕН` указывать свойство `ordering_key_fields` и `СЛЕДУЕТ` `ordering_instance_ids` в определении типа события.
- Строго монотонно возрастающие версии сущностей или последовательные счетчики `МОГУТ` использоваться для упорядочивания.
19.6. События изменения данных должны использоваться для сигнализации мутаций
- `ДОЛЖЕН` использовать события изменения данных для сигнализации изменений экземпляров сущностей и содействия захвату измененных данных (CDC).
- События `ДОЛЖНЫ` предоставлять полные данные сущности, включая идентификатор измененного экземпляра.
- `ДОЛЖЕН` обеспечивать явный порядок событий для событий изменения данных.
- `ДОЛЖЕН` публиковать события надежно.
19.7. Должен быть обеспечен явный порядок событий для событий изменения данных
- `ДОЛЖЕН` предоставлять информацию об упорядочивании для событий изменения данных, так как она критически важна для поддержания синхронизации транзакционных наборов данных (CDC).
- Эта информация определяет порядок создания, обновления и удаления экземпляров данных.
- Исключение: если транзакционные данные только добавляются (append only).
19.8. Следует использовать стратегию хэш-секционирования для событий изменения данных
- `СЛЕДУЕТ` использовать стратегию хэш-секционирования для событий изменения данных.
- Это позволяет всем связанным событиям для сущности быть последовательно назначенными одному разделу, обеспечивая относительно упорядоченный поток событий для этой сущности.
- Ключ секционирования `ПОЧТИ ВСЕГДА` `ДОЛЖЕН` представлять изменяемую сущность.
20. Проектирование Событий
20.1. Следует избегать записи конфиденциальных данных в событиях
- `СЛЕДУЕТ` избегать записи конфиденциальных данных (например, персональных данных) в событиях, если это не требуется для бизнеса.
- Конфиденциальные данные создают дополнительные обязательства по контролю доступа и соответствию нормативным требованиям, увеличивая риски защиты данных.
20.2. Должна быть устойчивость к дубликатам при потреблении событий
- Потребители событий `ДОЛЖНЫ` быть устойчивы к дубликатам событий (несколько вхождений одного и того же объекта события).
- Устойчивость может включать дедупликацию, основанную на `eid` и информации об упорядочивании изменения данных (CDC).
- Источники дубликатов: повторные попытки публикации, сбои, “at-least-once” доставка.
20.3. Следует проектировать для идемпотентной обработки вне порядка
- События, разработанные для идемпотентной обработки вне порядка, `СЛЕДУЕТ` проектировать так, чтобы они содержали достаточно информации для восстановления их исходного порядка или чтобы порядок становился неактуальным.
- Это позволяет пропускать, задерживать или повторять обработку событий без порчи результата.
20.4. Должно быть обеспечено определение полезных бизнес-ресурсов событиями
- События `ДОЛЖНЫ` определять полезные бизнес-ресурсы, основанные на предметной области сервиса и ее естественном жизненном цикле.
- `СЛЕДУЕТ` определять типы событий, достаточно абстрактные/общие, чтобы быть ценными для нескольких сценариев использования.
20.5. Следует обеспечивать соответствие событий изменения данных ресурсам API
- Представление сущности в событии изменения данных `СЛЕДУЕТ` соответствовать представлению в REST API.
- Это уменьшает количество публикуемых структур и упрощает поддержку API.
- Исключения: сильно отличающиеся представления от хранилища данных, агрегированные данные, результаты вычислений.
20.6. Должна поддерживаться обратная совместимость для событий
- Изменения в событиях `ДОЛЖНЫ` быть основаны на аддитивных и обратно совместимых изменениях.
- Обратно совместимые изменения: добавление опциональных полей, изменение порядка полей, удаление опциональных полей, удаление значений из перечисления, добавление новых значений в `x-extensible-enum`.
- Обратно несовместимые изменения: удаление обязательных полей, изменение значений по умолчанию, изменение типов полей, добавление значений в обычное перечисление.
Приложения: Разделы остаются без изменений, так как они ссылаются на внешние ресурсы и инструментарий, которые не были частью критического анализа содержания.
- Приложение A: Ссылки
- Приложение B: Инструментарий
- Приложение C: Лучшие практики
- Приложение D: Журнал изменений (текущий Changelog из оригинального документа)
Итог:
В ходе данного анализа и обновления “Zalando RESTful API and Event Guidelines” была проведена систематическая работа по пересмотру и улучшению исходного документа. Основные цели заключались в устранении двусмысленностей, обеспечении соответствия современным тенденциям в проектировании API и повышении общей читаемости и применимости руководства.
Ключевым изменением, отражающим современные практики и обеспечивающим лучшую совместимость с широко используемыми языками программирования и инструментами, стало `РЕКОМЕНДАЦИЯ` использования `camelCase` для имен свойств в JSON-нагрузке, вместо ранее предписанного `snake_case`. Это решение было тщательно обосновано с учетом удобства разработки и консистентности с глобальными стандартами. Хотя это отступление от одной из конкретных конвенций исходного документа, оно полностью соответствует его духу “API как продукта” и направлено на улучшение опыта разработчиков.
Кроме того, были уточнены и усилены правила, касающиеся:
- HTTP-статусов: Более детальный и выборочный подход к использованию HTTP-кодов, отдавая предпочтение наиболее распространенным и понятным.
- Идемпотентности: Расширенное рассмотрение различных подходов к обеспечению идемпотентности для `POST` и `PATCH` операций, включая заголовки `Idempotency-Key`.
- Безопасности: Четкие указания по работе со скоупами и защите конечных точек.
- Версионирования: Подтверждение предпочтения версионирования через `media type` и категорический отказ от версионирования URL.
- Обработки ошибок: Настоятельная рекомендация использовать `Problem JSON` (RFC 9457) для стандартизированного и расширяемого представления ошибок.
- Событий: Дополнительные пояснения и уточнения по проектированию, совместимости и структуре типов событий, а также по обработке дубликатов.
Это обновленное руководство представляет собой более зрелый и всеобъемлющий документ, который, как ожидается, будет служить надежным ориентиром для проектирования и разработки высококачественных, масштабируемых и удобных в использовании API и систем событий в Zalando. Оно сохраняет основные принципы и ценности исходного документа, одновременно адаптируясь к меняющимся требованиям и лучшим практикам индустрии. Дальнейшее периодическое обновление и итеративное улучшение будут способствовать поддержанию его актуальности и эффективности.