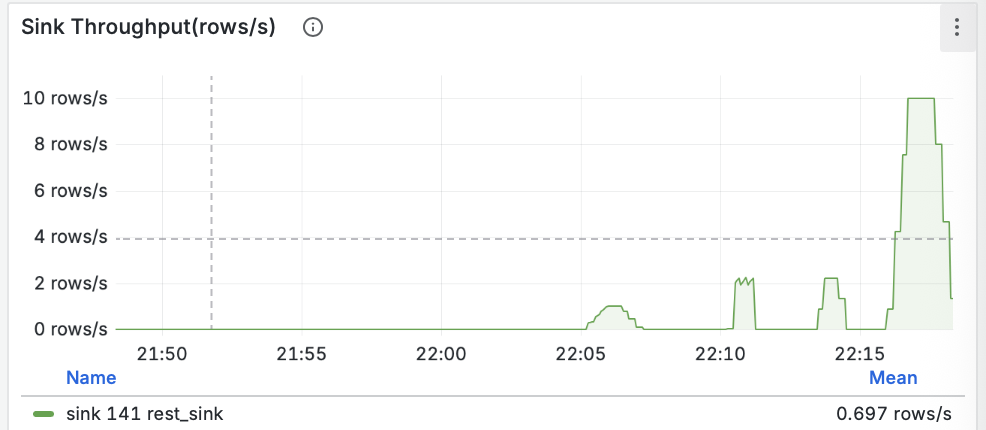
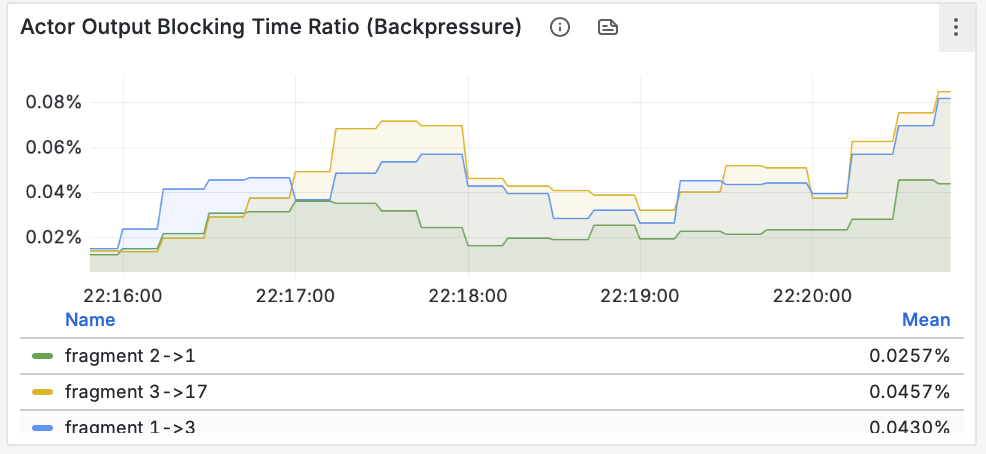
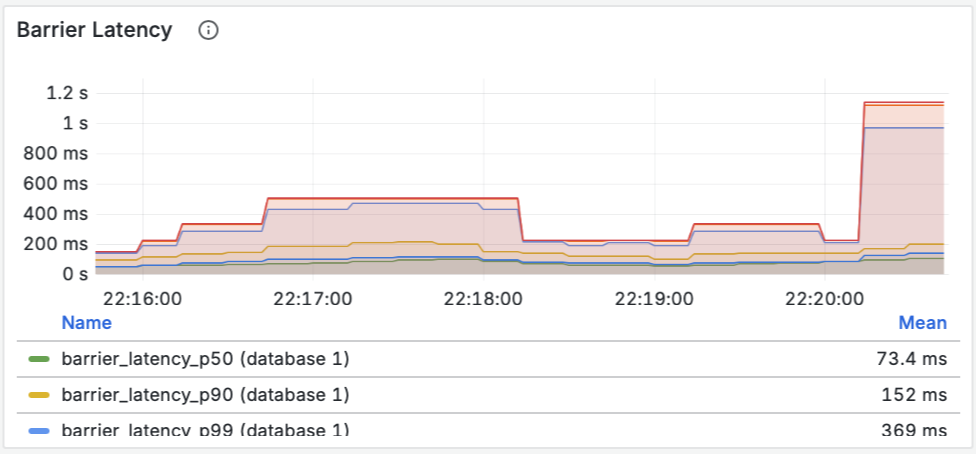
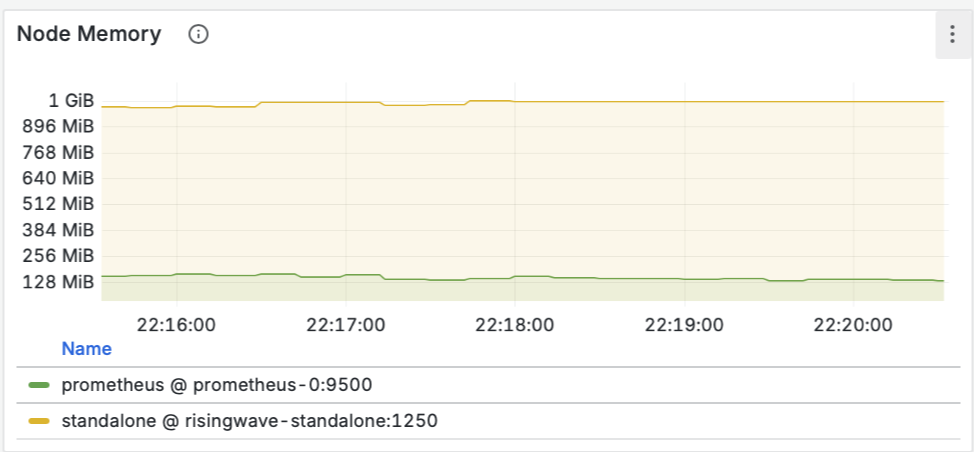
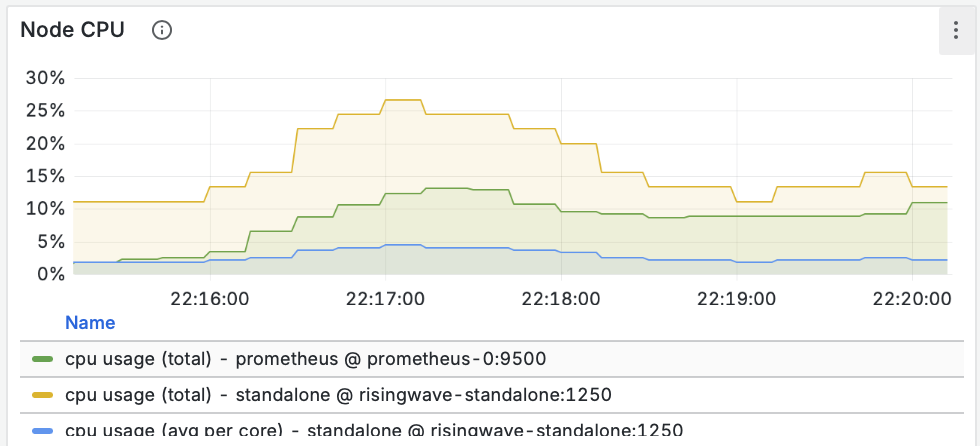
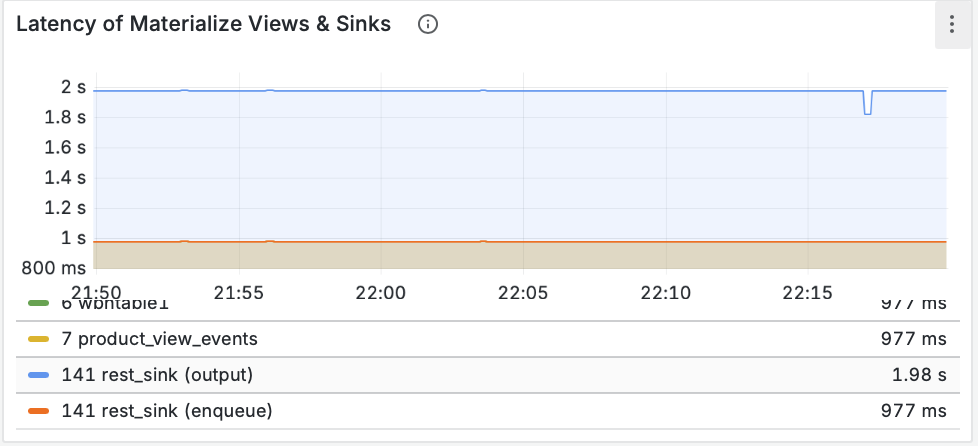
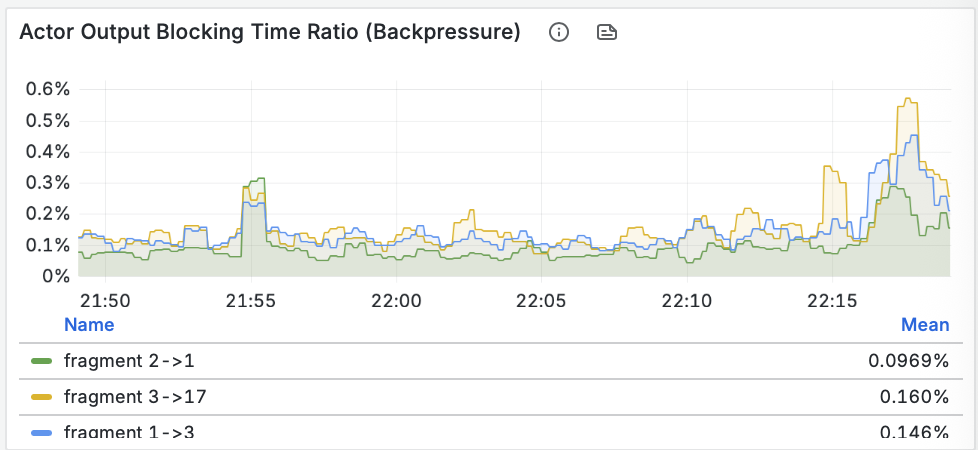
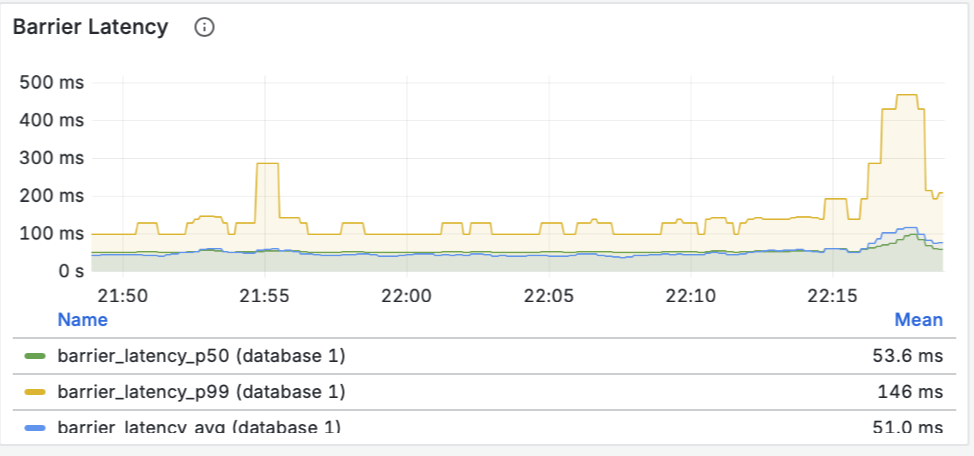
Построение надежных ML-систем и технический долг
Машинное обучение (ML) превратилось из чисто исследовательской дисциплины в мощный инструмент для создания сложных и полезных продуктов. Сегодня ML-системы принимают критически важные решения в медицине, финансах и автономном транспорте medium.com. Однако быстрая разработка и развертывание — лишь верхушка айсберга. Основные трудности и затраты возникают при их долгосрочной поддержке. Неожиданные сбои моделей являются одним из главных барьеров для внедрения технологий ИИ arxiv.org.
В этой статье мы разберем полный жизненный цикл ML-проекта, проанализируем концепцию «скрытого технического долга» и объединим эти знания в единую методику для создания надежных и развиваемых систем.
Часть 1. Карта жизненного цикла ML-проекта
Любой ML-проект — это не просто обучение модели, а сложный, итеративный процесс. Рассмотрим его типичный жизненный цикл, разделив на две основные фазы: Исследования и Эксплуатация.
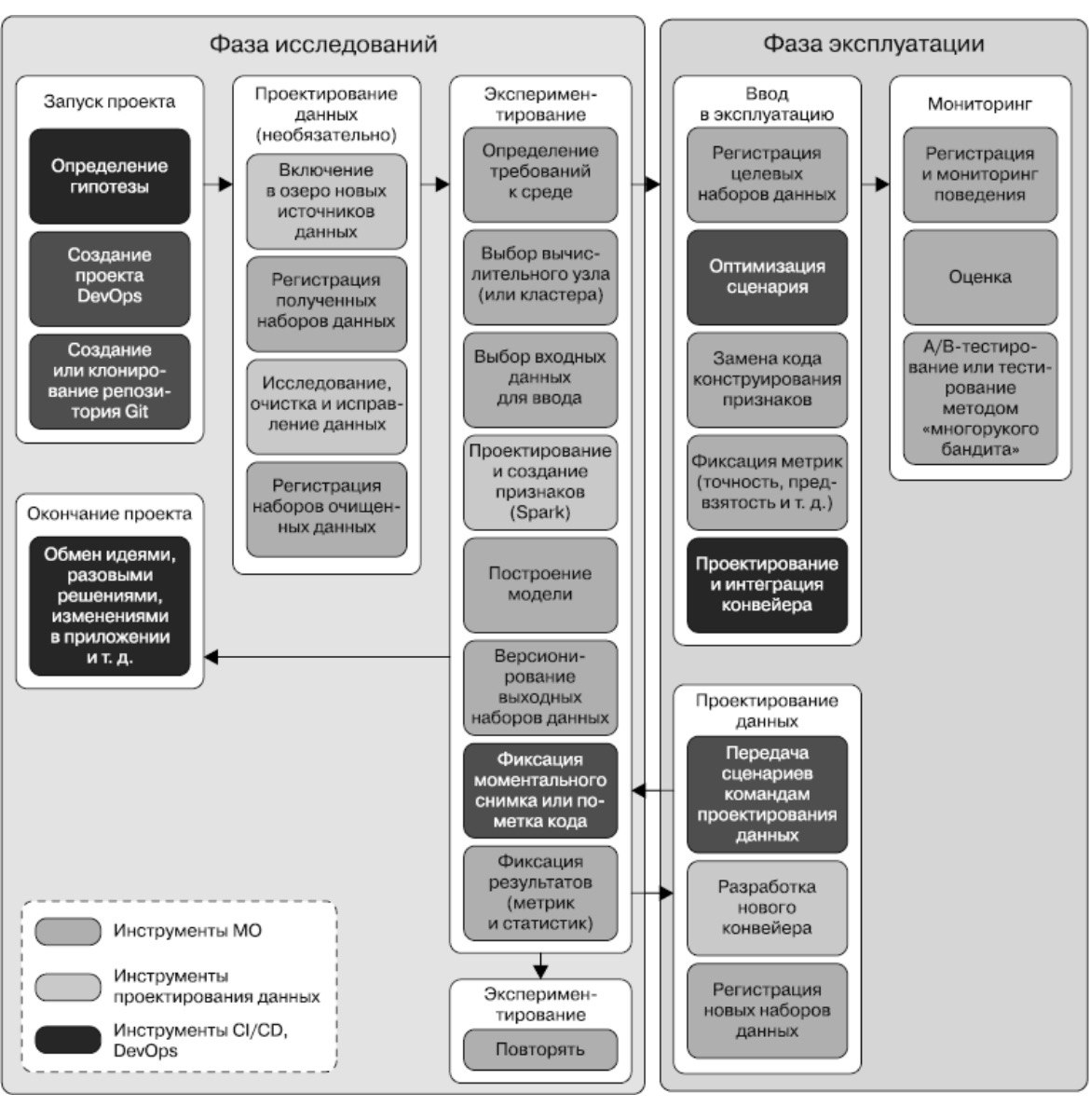
Фаза 1: Исследования (Research)
Это итеративный этап проверки гипотез. Главная цель — доказать (или опровергнуть), что с помощью ML можно решить поставленную бизнес-задачу с приемлемым качеством.
- Запуск проекта:
- Задачи:** Четкое определение бизнес-проблемы и формулировка ML-гипотезы («Сможем ли мы предсказывать Y с помощью данных X с точностью N?»). На этом этапе важно задать фундаментальный вопрос: а нужно ли здесь вообще машинное обучение? Создается техническая инфраструктура: репозиторий в Git, проект в системе CI/CD (например, Jenkins, GitLab CI).
- Участники:** Бизнес-заказчики, продуктовые менеджеры, аналитики, специалисты по Data Science.
- Проектирование данных:
- Задачи:** Поиск, сбор и интеграция данных из различных источников в единое хранилище («озеро данных»). Затем данные исследуются на предмет полноты, аномалий и качества, после чего происходит их очистка, трансформация и регистрация в качестве «очищенных» наборов данных.
- Участники:** Инженеры данных (Data Engineers), команда DWH, специалисты по Data Science.
- Экспериментирование:
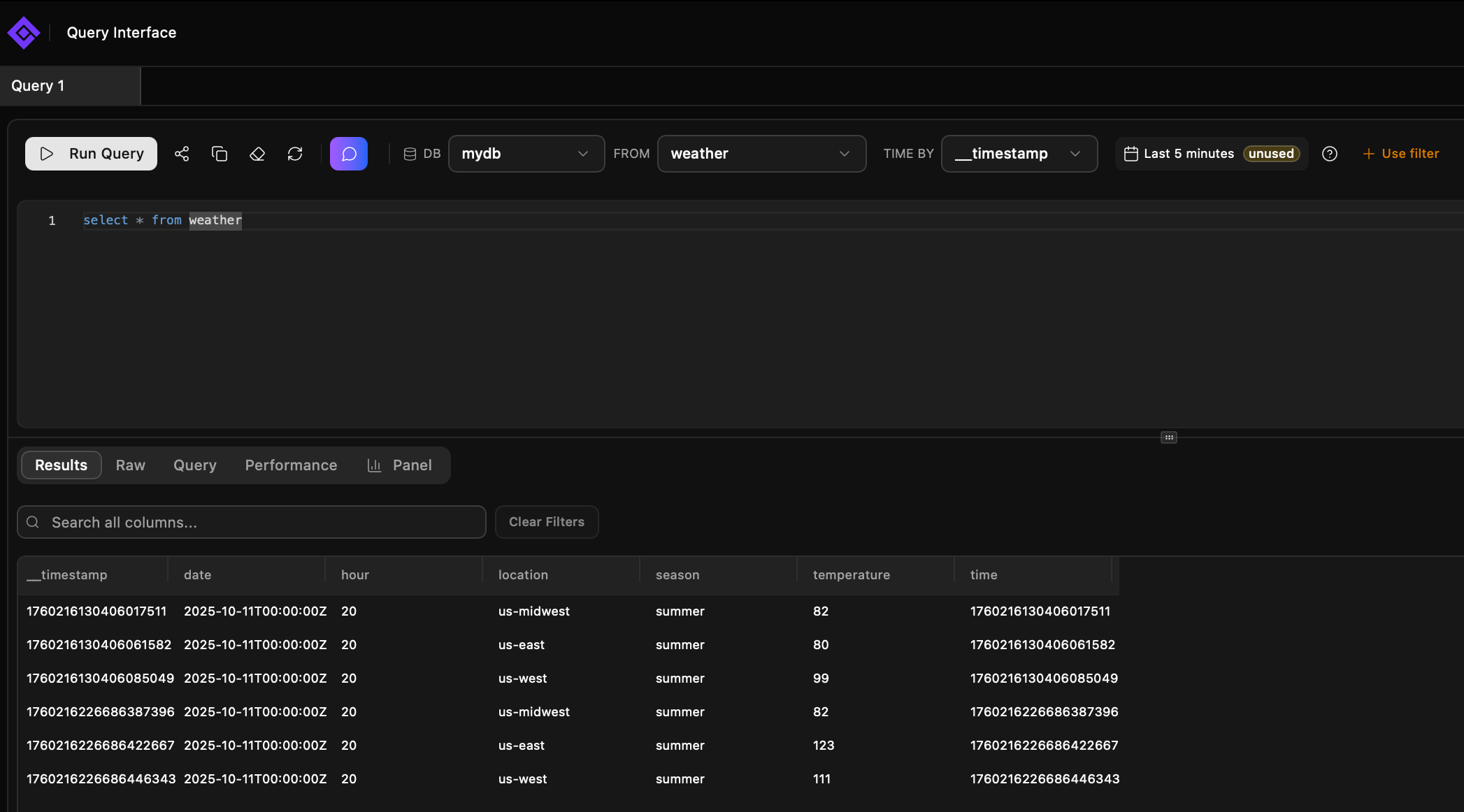
- Задачи:** Это сердце работы Data Scientist. Здесь происходит генерация признаков (`feature engineering`), подбор архитектуры модели, ее обучение, валидация и оценка. Критически важными шагами являются версионирование данных и кода, а также фиксация всех результатов и метрик для обеспечения воспроизводимости.
- Участники:** Специалисты по Data Science (ML/DS).
Эта фаза завершается решением: если эксперименты успешны, проект переходит в фазу эксплуатации. Если нет — он либо отправляется на новый виток исследований, либо закрывается.
Фаза 2: Эксплуатация (Operations / MLOps)
Цель этой фазы — превратить успешный прототип в надежный, масштабируемый и автоматически работающий продукт, а также поддерживать его работоспособность во времени.
- Ввод в эксплуатацию:
- Задачи: Код, написанный для экспериментов, часто требует серьезного рефакторинга и оптимизации для производственной среды. Строится автоматизированный конвейер (pipeline), который выполняет все шаги: от получения свежих данных до выгрузки предсказаний. Этот процесс должен быть не только автоматизированным, но и устойчивым к сбоям, что является ключевым принципом как MLOps, так и классической инженерии надежности Reliability Engineering arxiv.org.
- Участники: ML-инженеры, DevOps-инженеры, инженеры данных.
- Мониторинг:
- Задачи: После развертывания работа не заканчивается. Необходимо постоянно отслеживать как технические, так и качественные показатели модели: стабильность входных данных, качество предсказаний (точность, полнота), а также бизнес-метрики. Для оценки реального влияния на продукт проводятся А/В-тесты.
- Участники: ML-инженеры, SRE (Site Reliability Engineers), аналитики, продуктовые менеджеры.
Этот цикл непрерывен. Данные мониторинга могут выявить деградацию модели, что повлечет за собой запуск нового витка исследований для ее улучшения.
Часть 2. «Скрытый технический долг в системах машинного обучения»
В 2015 году исследователи из Google опубликовали знаковую работу «Hidden Technical Debt in Machine Learning Systems». Они показали, что в ML-системах технический долг накапливается быстрее и опаснее, чем в традиционном ПО.
Основная идея: Легко построить прототип ML-системы, но чрезвычайно сложно и дорого поддерживать его в рабочем состоянии. Причина — множество скрытых проблем системного уровня, которые не являются багами в коде, но со временем делают систему хрупкой и непредсказуемой.
Ключевые источники технического долга в ML:
- Эрозия границ и связанность (Entanglement): В ML практически невозможно изолировать компоненты из-за принципа CACE («Changing Anything Changes Everything» — «Изменение чего угодно меняет всё»).
- Изменение одного признака влияет на важность всех остальных.
- Добавление нового признака `x_n+1` может полностью изменить веса старых `x_1...x_n`.
- Зависимости от данных (Data Dependencies): Эти зависимости коварнее зависимостей от кода, так как их сложнее отследить статически.
- Нестабильные данные: Использование данных из другой ML-системы, которая может обновляться без вашего ведома — это бомба замедленного действия. «Улучшение» в той системе может сломать вашу.
- Недоиспользуемые данные: Со временем признаки могут становиться ненужными (Legacy Features), добавляться «пачкой» ради мнимого прироста метрик (Bundled Features) или дублировать друг друга (Correlated Features). Они не приносят пользы, но увеличивают сложность и уязвимость системы.
- Антипаттерны проектирования:
- Код-клей (Glue Code): Огромное количество кода пишется для «склеивания» данных с универсальной ML-библиотекой (например, `scikit-learn`, `TensorFlow`). Авторы утверждают, что в зрелой системе ML-код может составлять всего 5%, а остальное — «клей».
- Джунгли конвейеров (Pipeline Jungles): Системы подготовки данных часто разрастаются органически, превращаясь в запутанные «джунгли» из скриптов, которые невозможно тестировать, отлаживать и развивать.
- Мертвые пути экспериментов: В коде остаются ветки `if/else` от прошлых экспериментов, которые усложняют тестирование и создают риск неожиданного поведения.
- Петли обратной связи (Feedback Loops): Модель в реальном мире влияет на среду, из которой она же и получает данные для будущего обучения. Это может привести к сужению разнообразия и деградации модели, когда она начинает усиливать свои собственные прошлые решения.
- Долг конфигурации (Configuration Debt): Конфигурация ML-систем (какие признаки использовать, параметры алгоритма, пороги) часто занимает больше строк, чем сам код. Ею сложно управлять, ее редко тестируют, а ошибки в ней могут приводить к катастрофическим последствиям.
Часть 3. Практические выводы
Схема жизненного цикла из Части 1 показывает, ЧТО и КОГДА нужно делать. Статья о техническом долге из Части 2 объясняет, ПОЧЕМУ и КАК это нужно делать правильно, чтобы система не развалилась через полгода.
Взаимосвязь очевидна: почти каждый источник технического долга зарождается на фазе исследований и проявляется во всей красе на фазе эксплуатации.
- Блок Экспериментирование — это фабрика по производству `кода-клея` и `недоиспользуемых признаков`. Погоня за сотыми долями процента в метрике качества часто приводит к огромному усложнению системы.
- Блок Ввод в эксплуатацию без рефакторинга и целостного проектирования порождает `джунгли конвейеров`.
- Блок Мониторинг — главный инструмент для обнаружения последствий технического долга: смещения данных (Data Drift) и деградации модели (Model Drift).
Рекомендации по созданию надежных ML-систем
Чтобы построить устойчивую ML-систему, необходимо с самого начала применять инженерную дисциплину.
- Целостный подход к надежности. ML-система — это не только модель. Это данные, признаки, код, конвейеры и мониторинг. Цель — не просто высокая точность, а построение надежной и заслуживающей доверия системы ieeexplore.ieee.org.
- Версионирование всего. Для борьбы с хаосом необходимо версионировать всё: данные, код, параметры экспериментов и итоговые модели. Это единственный способ обеспечить воспроизводимость и возможность отката.
- Автоматизация (MLOps). Ручные шаги — источник ошибок. Все процессы, от сборки данных до развертывания модели, должны быть автоматизированы. Тестирование должно включать не только код, но и данные (проверки на соответствие схеме, распределению), а также качество самой модели.
- Проактивный мониторинг. Настройте алерты на аномалии во входных данных (data drift), падение качества предсказаний (model drift) и нарушение ключевых бизнес-метрик. Это ваш радар для обнаружения скрытого технического долга в реальном времени.
- Проектирование с учетом отказоустойчивости. Система должна быть спроектирована так, чтобы изящно справляться с частичными сбоями: например, иметь логику-запасной вариант (fallback), если источник данных недоступен, или временно отключать модель, если ее предсказания становятся неадекватными medium.com.
- Кросс-функциональные команды и культура. Жесткое разделение ролей «исследователь» (Data Scientist) и «инженер» (ML Engineer) — корень многих проблем. Наиболее успешные команды — это гибридные группы, где инженеры и исследователи работают вместе. Такая культура ценит не только прирост точности, но и упрощение системы, удаление лишних признаков и снижение общей сложности.
Заключение
В конечном счете, успех ML-проекта определяется не тем, как быстро была создана первая версия, а тем, как долго и эффективно она может приносить пользу, адаптируясь к меняющемуся миру. Игнорирование технического долга — это взятие кредита под высокий процент, который неизбежно придется выплачивать временем, деньгами и репутационными потерями.
Ниже представлен перевод и краткий пересказ ключевых идей научной статьи «Скрытый технический долг в системах машинного обучения» от D. Sculley и других исследователей из Google. Пояснения к терминам и концепциям добавлены в формате ``.
Оригинал тут: http://a.gavrilov.info/data/posts/ml-Paper.pdf
Скрытый технический долг в системах машинного обучения
Аннотация
Машинное обучение (МО) предлагает мощный инструментарий для быстрого создания сложных систем прогнозирования. Однако эта статья утверждает, что опасно считать такие быстрые успехи бесплатными. Используя концепцию технического долга из инженерии программного обеспечения, мы показываем, что в реальных МО-системах часто возникают огромные постоянные затраты на их поддержку. Мы исследуем несколько специфичных для МО факторов риска, которые необходимо учитывать при проектировании: размывание границ, связанность, скрытые петли обратной связи, необъявленные потребители, зависимости от данных, проблемы конфигурации, изменения во внешнем мире и различные антипаттерны на уровне системы.
1. Введение
По мере того как сообщество машинного обучения накапливает опыт работы с реальными системами, проявляется неприятная тенденция: разработка и развертывание МО-систем выполняются относительно быстро и дёшево, но их поддержка со временем становится сложной и дорогой.
Эту дихотомию можно понять через призму технического долга . Как и в случае с финансовым долгом, иногда существуют веские стратегические причины для его накопления. Не весь долг плох, но весь долг нужно обслуживать. «Выплата» технического долга может включать рефакторинг кода, улучшение тестов, удаление мёртвого кода, сокращение зависимостей и улучшение документации. Откладывание этих выплат приводит к накоплению затрат, подобно процентам по кредиту.
Мы утверждаем, что МО-системы особенно склонны к накоплению технического долга, поскольку они наследуют все проблемы поддержки традиционного кода и добавляют к ним свой набор специфичных для МО проблем. Этот долг трудно обнаружить, так как он существует на уровне системы, а не на уровне кода. Данные влияют на поведение МО-системы, что может незаметно нарушать традиционные абстракции и границы.
На уровне системы МО-модель может незаметно размывать границы абстракций. Повторное использование входных сигналов может непреднамеренно связать в остальном изолированные системы. Пакеты МО могут рассматриваться как «чёрные ящики», что приводит к появлению большого количества «кода-клея». Изменения во внешнем мире могут непредвиденным образом повлиять на поведение системы. Даже мониторинг поведения МО-системы может оказаться сложной задачей без продуманного дизайна.
2. Размывание границ из-за сложности моделей
Сильные абстракции и модульность помогают создавать поддерживаемый код. К сожалению, в МО-системах трудно обеспечить строгие границы абстракции, поскольку желаемое поведение часто нельзя выразить в виде логики без зависимости от внешних данных.
- Связанность (Entanglement). МО-системы смешивают сигналы, делая изоляцию улучшений невозможной. Это принцип CACE (Changing Anything Changes Everything — «Изменение чего угодно меняет всё»). Изменение распределения одного признака (x₁) может изменить важность или веса всех остальных признаков. Добавление или удаление признаков имеет тот же эффект. Улучшение одной модели в ансамбле может ухудшить общую точность системы, если ошибки станут более коррелированными.
- Каскады исправлений (Correction Cascades). Часто возникает соблазн исправить проблему A’, которая немного отличается от уже решенной проблемы A, создав новую модель `m’` поверх существующей модели `mA`. Эта новая модель `m’` учится вносить небольшую поправку. Однако это создаёт новую зависимость от `mA`, что делает будущий анализ улучшений `mA` значительно дороже. Каскады таких исправлений могут привести к тупиковой ситуации, когда улучшение любого отдельного компонента ухудшает общую производительность системы.
- Необъявленные потребители (Undeclared Consumers). Часто предсказания МО-модели становятся общедоступными (например, через логи). Другие системы могут начать тайно использовать эти данные в качестве входных. В классической инженерии это называют долгом видимости . Такие необъявленные потребители создают скрытую жёсткую связь. Любые изменения в исходной модели, даже улучшения, могут негативно и непредсказуемо повлиять на эти системы-потребители.
3. Зависимости от данных стоят дороже зависимостей от кода
Зависимости от данных в МО-системах могут накапливать долг так же, как и зависимости кода, но их гораздо труднее обнаружить. Зависимости кода можно выявить статическим анализом, а для зависимостей от данных таких инструментов мало.
- Нестабильные зависимости от данных. Удобно использовать в качестве признаков данные из других систем. Однако если эти входные сигналы нестабильны (например, сами являются выходом другой МО-модели, которая со временем обновляется), они могут меняться. Даже «улучшения» входного сигнала могут иметь разрушительные последствия для потребляющей его системы. Распространённая стратегия смягчения — создание версионных, «замороженных» копий таких данных.
- Недостаточно используемые зависимости от данных. Это входные сигналы, которые дают очень небольшой прирост производительности, но делают систему излишне уязвимой к изменениям. Они могут появиться несколькими путями:
- Устаревшие признаки (Legacy Features): Признак добавляется на ранней стадии, со временем новые признаки делают его избыточным, но его не удаляют.
- Пакетные признаки (Bundled Features): Группа признаков добавляется вместе, потому что «в пакете» они показали пользу, хотя некоторые из них по отдельности бесполезны.
- ε-признаки : Признаки, которые добавляют ради крошечного прироста точности, но при этом значительно усложняют систему.
- Коррелированные признаки (Correlated Features): Когда два признака сильно коррелируют, модель может ошибочно отдать предпочтение не причинно-следственному, а зависимому, что делает систему хрупкой, если в будущем эта корреляция изменится.
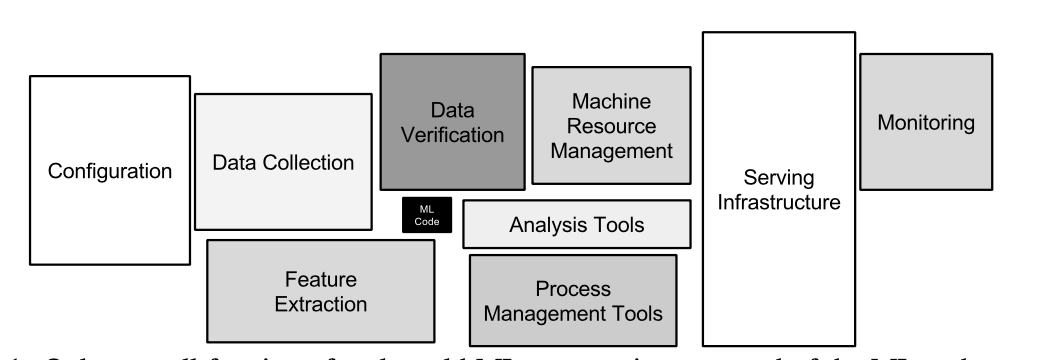
Необходимая окружающая инфраструктура огромна и сложна.
- `ML Code` — Код МО
- `Configuration` — Конфигурация
- `Data Collection` — Сбор данных
- `Feature Extraction` — Извлечение признаков
- `Data Verification` — Верификация данных
- `Machine Resource Management` — Управление ресурсами
- `Analysis Tools` — Инструменты анализа
- `Process Management Tools` — Инструменты управления процессами
- `Serving Infrastructure` — Инфраструктура для развёртывания
- `Monitoring` — Мониторинг
4. Петли обратной связи
Ключевая особенность работающих МО-систем — они часто начинают влиять на собственное поведение.
- Прямые петли обратной связи. Модель напрямую влияет на выбор данных для своего будущего обучения. Например, система рекомендаций показывает пользователю определённые товары; если пользователь кликает на них, эти клики используются для дообучения модели, что закрепляет её текущее поведение.
- Скрытые петли обратной связи. Две отдельные системы косвенно влияют друг на друга через реальный мир. Пример: одна система выбирает товары для показа на веб-странице, а другая — связанные с ними отзывы. Улучшение одной системы (например, показ более релевантных товаров) приведёт к изменению поведения пользователей (больше кликов), что, в свою очередь, повлияет на вторую систему (какие отзывы показывать).
5. Антипаттерны МО-систем
Для академического сообщества может быть удивительно, что в реальных МО-системах лишь малая часть кода (см. Рисунок 1) отвечает непосредственно за обучение или предсказание. Остальное — это инфраструктурная «обвязка».
- «Код-клей» (Glue Code) . Системный дизайн, при котором пишется огромное количество вспомогательного кода для передачи данных в универсальные МО-пакеты и из них. Этот код «приклеивает» систему к особенностям конкретного пакета, делая переход на альтернативы крайне дорогим. Иногда дешевле создать чистое нативное решение, чем использовать универсальный пакет, если 95% системы — это «код-клей».
- «Джунгли конвейеров» (Pipeline Jungles). Особый случай «кода-клея», часто возникающий при подготовке данных. Системы превращаются в «джунгли» из скриптов для парсинга, объединения данных и сэмплирования, которыми сложно управлять и тестировать.
- Мёртвые ветки экспериментального кода (Dead Experimental Codepaths). Часто для экспериментов в основной код добавляются временные условные ветки. Со временем они накапливаются, усложняя поддержку обратной совместимости и тестирование. Знаменитый пример — система Knight Capital, потерявшая $465 млн за 45 минут из-за непредвиденного поведения устаревшего экспериментального кода.
- Долг абстракции (Abstraction Debt). В МО не хватает сильных, общепринятых абстракций, подобных реляционной базе данных в мире СУБД. Это размывает границы между компонентами системы.
Распространённые «запахи» кода в МО
- «Запах» простых типов данных (Plain-Old-Data Type Smell): Использование обычных `float` или `int` вместо более насыщенных типов. Например, параметр модели должен «знать», является он порогом принятия решения или множителем.
- «Запах» многоязычности (Multiple-Language Smell): Использование нескольких языков программирования в одной системе усложняет тестирование и передачу ответственности.
- «Запах» прототипа (Prototype Smell): Постоянное использование отдельной среды для прототипирования может указывать на то, что основная система слишком неповоротлива и сложна для изменений. Существует опасность, что под давлением сроков прототип будет запущен в продакшен.
6. Долг конфигурации
Конфигурация МО-систем — ещё одна область накопления долга. Любая крупная система имеет огромное количество настраиваемых опций. В зрелой системе количество строк конфигурации может значительно превышать количество строк кода. Ошибки в конфигурации могут приводить к потере времени, вычислительных ресурсов и проблемам в продакшене.
Принципы хорошей системы конфигурации:
- Легко задавать новую конфигурацию как небольшое изменение предыдущей.
- Трудно допустить ошибку вручную.
- Легко визуально сравнить две конфигурации.
- Легко автоматически проверять базовые факты (количество признаков, зависимости).
- Возможность обнаруживать неиспользуемые или избыточные настройки.
- Конфигурации должны проходить ревью кода и храниться в репозитории.
7. Работа с изменениями во внешнем мире
МО-системы увлекательны тем, что они напрямую взаимодействуют с внешним миром. Но внешний мир редко бывает стабилен, что создаёт постоянные затраты на поддержку.
- Фиксированные пороги в динамических системах. Часто порог принятия решения (например, для классификации письма как спама) устанавливается вручную. Если модель обновляется на новых данных, этот старый порог может стать недействительным.
- Мониторинг и тестирование. Необходимо в реальном времени отслеживать поведение системы. Ключевые метрики для мониторинга:
- Смещение предсказаний (Prediction Bias): Распределение предсказанных меток должно соответствовать распределению реальных меток. Отклонение этого показателя часто указывает на проблемы.
- Ограничения на действия (Action Limits): В системах, которые выполняют действия в реальном мире (например, делают ставки на аукционе), полезно устанавливать «разумные» лимиты. Срабатывание такого лимита должно вызывать тревогу и требовать ручного вмешательства.
- Поставщики данных (Up-Stream Producers): Системы, поставляющие данные для МО-модели, должны тщательно отслеживаться и тестироваться. Любые сбои в них должны немедленно передаваться в МО-систему.
8. Другие области долга, связанного с МО
- Долг тестирования данных (Data Testing Debt). Если данные заменяют код, то данные, как и код, должны тестироваться.
- Долг воспроизводимости (Reproducibility Debt). Воспроизводить эксперименты в реальных системах сложно из-за рандомизации, недетерминизма параллельных вычислений и взаимодействия с внешним миром.
- Долг управления процессами (Process Management Debt). В зрелых системах могут работать сотни моделей одновременно. Это порождает проблемы с массовым обновлением конфигураций, управлением ресурсами и т.д.
- Культурный долг (Cultural Debt). Жёсткая граница между «исследователями МО» и «инженерами» контрпродуктивна. Важно создавать культуру, в которой удаление признаков, снижение сложности и улучшение стабильности ценятся так же высоко, как и повышение точности.
9. Выводы: Измерение и выплата долга
Технический долг — полезная метафора, но без строгой метрики. Как его измерить? Быстрое продвижение команды вперёд не является доказательством низкого долга, поскольку его полная стоимость становится очевидной только со временем.
Полезные вопросы для оценки долга:
- Насколько легко протестировать совершенно новый алгоритмический подход в полном масштабе?
- Каково транзитивное замыкание всех зависимостей от данных?
- Насколько точно можно измерить влияние нового изменения на систему?
- Ухудшает ли улучшение одной модели или сигнала работу других?
- Как быстро новые члены команды могут войти в курс дела?
Выплата технического долга, связанного с МО, требует осознанного решения, которое часто может быть достигнуто только через изменение культуры команды. Признание, приоритизация и вознаграждение этих усилий важны для долгосрочного здоровья и успеха МО-команд.