Slowly Changing Dimensions (SCD), или Медленно меняющиеся измерения, — это концепция и набор методов из области хранилищ данных (Data Warehousing), которые используются для управления изменениями в атрибутах измерений с течением времени. Измерения — это справочные таблицы, которые описывают бизнес-сущности, такие как клиенты, продукты, сотрудники, географические регионы.
Атрибуты этих сущностей (например, адрес клиента или категория продукта) меняются, но обычно не очень часто — отсюда и название “медленно меняющиеся”. Основная задача SCD — решить, как хранить эти изменения, чтобы обеспечить точность исторических отчетов www.datacamp.com.
Например, если вы просто перезапишете адрес клиента, вы потеряете информацию о том, где он жил раньше. Это может исказить анализ продаж по регионам за прошлые периоды. Патерны SCD предлагают различные стратегии для решения этой проблемы.
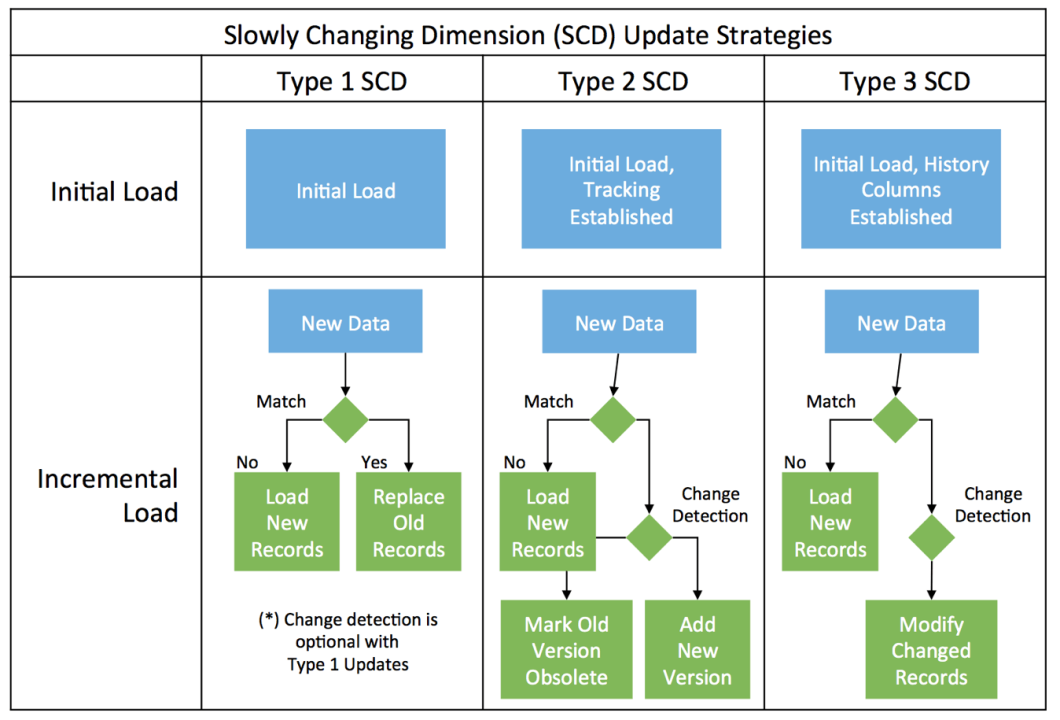
Основные типы SCD
Существует несколько типов SCD, но самыми распространенными и фундаментальными являются Типы 1, 2 и 3.
---
Тип 1: Перезапись атрибута (Overwrite)
Это самый простой подход. При изменении атрибута старое значение просто перезаписывается новым.
- Как работает:** Находится существующая запись в таблице измерения и значение в нужном столбце обновляется.
- Когда использовать:** Когда нет необходимости хранить историю изменений. Например, для исправления опечатки в имени клиента.
- Преимущества:** Простота реализации, не требует увеличения объема хранилища.
- Недостатки: **История изменений полностью теряется. Анализ, основанный на исторических значениях атрибута, становится невозможным.
Пример:
У нас есть клиент Анна Петрова, которая живет в Москве.
*Таблица `DimCustomer` до изменений:*
| CustomerKey |
FullName |
City |
| :--- |
:--- |
:--- |
| 101 |
Анна Петрова |
Москва |
Анна переезжает в Санкт-Петербург. При использовании SCD Тип 1 таблица будет обновлена:
*Таблица `DimCustomer` после изменений:*
| CustomerKey |
FullName |
City |
| :--- |
:--- |
:--- |
| 101 |
Анна Петрова |
Санкт-Петербург |
Теперь невозможно узнать, что раньше Анна жила в Москве.
---
Тип 2: Добавление новой строки (Add New Row)
Это самый распространенный и мощный тип SCD, так как он позволяет сохранять полную историю изменений.
- Как работает:** Вместо перезаписи существующей записи, создается новая запись для той же сущности (например, того же клиента). Старая запись помечается как неактуальная (истекшая), а новая — как актуальная. Для этого в таблицу измерения обычно добавляют несколько служебных столбцов learn.microsoft.com:
- `StartDate` / `EffectiveDate` — дата, с которой запись стала актуальной.
- `EndDate` — дата, когда запись перестала быть актуальной.
- `IsCurrent` / `CurrentFlag` — флаг (например, ‘Yes’/’No’ или 1/0), показывающий, является ли эта запись текущей.
- Когда использовать:** Когда сохранение истории критически важно для анализа. Это стандартный выбор для большинства атрибутов в хранилищах данных.
- Преимущества:** Сохраняется полная, точная история. Позволяет проводить корректный point-in-time анализ (анализ на определенный момент времени).
- Недостатки:** Увеличивается объем таблицы, так как для одного клиента может быть несколько записей. Запросы могут стать сложнее (нужно фильтровать по флагу `IsCurrent` или по диапазону дат) hevodata.com.
Пример:
Снова используем пример с Анной Петровой.
*Таблица `DimCustomer` до изменений:*
| SurrogateKey |
CustomerID |
FullName |
City |
StartDate |
EndDate |
IsCurrent |
| :--- |
:--- |
:--- |
:--- |
:--- |
:--- |
:--- |
| 1 |
101 |
Анна Петрова |
Москва |
2020-01-15 |
NULL |
Yes |
Анна переезжает 16 августа 2024 года. При использовании SCD Тип 2 таблица изменится так:
*Таблица `DimCustomer` после изменений:*
| SurrogateKey |
CustomerID |
FullName |
City |
StartDate |
EndDate |
IsCurrent |
| :--- |
:--- |
:--- |
:--- |
:--- |
:--- |
:--- |
| 1 |
101 |
Анна Петрова |
Москва |
2020-01-15 |
2024-08-15 |
No |
| 2 |
101 |
Анна Петрова |
Санкт-Петербург |
2024-08-16 |
NULL |
Yes |
Теперь мы сохранили всю историю перемещений Анны.
---
Тип 3: Добавление нового атрибута (Add New Attribute)
Этот тип сохраняет ограниченную историю, добавляя в таблицу отдельный столбец для предыдущего значения атрибута.
- Как работает:** Создается новый столбец, например, `PreviousCity`. Когда атрибут `City` меняется, его старое значение копируется в `PreviousCity`, а новое записывается в `City`.
- Когда использовать:** Когда важно отслеживать только предыдущее состояние для сравнения, а более глубокая история не нужна.
- Преимущества:** Простота реализации, не увеличивает количество строк, легко запрашивать текущее и предыдущее значения.
- Недостатки:** Сохраняет историю только на один шаг назад. Не масштабируется, если нужно хранить более двух-трех последних значений.
Пример:
Анна переезжает из Москвы в Санкт-Петербург.
*Таблица `DimCustomer` до изменений:*
| CustomerKey |
FullName |
CurrentCity |
PreviousCity |
| :--- |
:--- |
:--- |
:--- |
| 101 |
Анна Петрова |
Москва |
NULL |
*Таблица `DimCustomer` после изменений:*
| CustomerKey |
FullName |
CurrentCity |
PreviousCity |
| :--- |
:--- |
:--- |
:--- |
| 101 |
Анна Петрова |
Санкт-Петербург |
Москва |
Если Анна переедет снова, значение “Москва” будет потеряно.
Другие типы SCD
Существуют и более сложные гибридные типы:
- Тип 4 (History Table):** Основная таблица измерения хранит только текущие данные (как Тип 1), а вся история изменений выносится в отдельную таблицу. Это полезно, когда изменения происходят часто в очень больших таблицах измерений medium.com.
- Тип 6 (Hybrid):** Комбинирует подходы Типов 1, 2 и 3. Например, в таблице хранятся поля для полной истории (SCD2) и одновременно поле для текущего значения (SCD1 для быстрого доступа) и предыдущего значения (SCD3 для сравнения).
Тип 4: Добавление исторической таблицы (History Table / Audit Table)
Идея: Разделить текущие данные и исторические данные в разные таблицы для оптимизации производительности.
- Как работает:** Создаются две таблицы:
- Таблица измерения (Dimension Table): Хранит *только* текущие, самые последние данные. Эта таблица по своей сути работает как SCD Тип 1 (данные просто перезаписываются). Она маленькая, быстрая и идеально подходит для большинства запросов, где история не нужна.
- Историческая таблица (History Table): Хранит всю историю изменений. Каждый раз, когда в основной таблице происходит изменение, старая версия строки (до обновления) добавляется в историческую таблицу. Эта таблица часто содержит служебные поля, как в SCD Тип 2 (`StartDate`, `EndDate`, `Version`), для отслеживания временного периода.
- Когда использовать:** Когда у вас есть очень большая таблица измерений (например, десятки миллионов клиентов), и большинство аналитических запросов относится только к текущим данным. Разделение таблиц позволяет сделать эти частые запросы очень быстрыми, не жертвуя при этом возможностью проводить глубокий исторический анализ при необходимости.
- Преимущества:**
- Высокая производительность для запросов к текущим данным.
- Логическое разделение данных: актуальные и исторические.
- Недостатки:**
- Усложнение ETL/ELT процесса, так как нужно управлять двумя таблицами.
- Анализ, требующий одновременного доступа к историческим и текущим данным, усложняется, так как требует `JOIN` или `UNION` между двумя таблицами.
Пример:
Клиент Анна Петрова переезжает из Москвы в Санкт-Петербург.
*Таблицы до изменений:*
`DimCustomer` (основная таблица)
| CustomerID |
FullName |
City |
| :--- |
:--- |
:--- |
| 101 |
Анна Петрова |
Москва |
`HistoryCustomer` (историческая таблица) – *пустая*
*Процесс изменения:*
- Перед обновлением основной таблицы, текущая строка (Анна в Москве) копируется в `HistoryCustomer`.
- Затем основная таблица `DimCustomer` обновляется новым значением.
*Таблицы после изменений:*
`DimCustomer` (всегда хранит только актуальные данные)
| CustomerID |
FullName |
City |
| :--- |
:--- |
:--- |
| 101 |
Анна Петрова |
Санкт-Петербург |
`HistoryCustomer` (накапливает историю)
| HistoryID |
CustomerID |
FullName |
City |
StartDate |
EndDate |
| :--- |
:--- |
:--- |
:--- |
:--- |
:--- |
| 1 |
101 |
Анна Петрова |
Москва |
2020-01-15 |
2024-08-15 |
Тип 5: Гибридный подход (Mini-Dimension + Type 1 Outrigger)
Идея: Вынести часто меняющиеся атрибуты из большой таблицы измерений в отдельную “мини-таблицу”, чтобы избежать “раздувания” основной таблицы.
- Как работает:**
- Из основной таблицы измерения (например, `DimCustomer`) выделяется группа атрибутов, которые часто меняются вместе (например, “Тарифный план”, “Статус подписки”).
- Создается отдельная таблица — “мини-измерение” (например, `DimSubscriptionProfile`) — только для этих атрибутов. Эта мини-таблица управляется по SCD Тип 2 (добавление новой строки для каждого уникального набора значений).
- В основной таблице `DimCustomer` эти атрибуты удаляются, и вместо них добавляется один внешний ключ (например, `SubscriptionProfileKey`), который ссылается на мини-измерение.
- Этот ключ в основной таблице `DimCustomer` обновляется по принципу SCD Тип 1 (просто перезаписывается), указывая на *актуальную* запись в мини-измерении.
- Когда использовать:** В очень больших (широких и/или с большим количеством строк) таблицах измерений, где лишь небольшая группа атрибутов меняется относительно часто. Это позволяет отслеживать историю этих атрибутов, не создавая новую многомиллионную запись в основной таблице при каждом изменении.
- Преимущества:**
- Экономия места и контроль над ростом основной таблицы измерения.
- Позволяет вести детальную историю для подгруппы атрибутов.
- Недостатки:**
- Более сложная модель данных, требующая дополнительных `JOIN`.
- Может быть сложнее для понимания конечными пользователями.
Пример:
Клиент Иван меняет свой тарифный план.
*Таблицы до изменений:*
`DimCustomer`
| CustomerKey |
FullName |
SubscriptionProfileKey |
| :--- |
:--- |
:--- |
| 202 |
Иван Иванов |
55 |
`DimSubscriptionProfile` (мини-измерение, управляется по SCD2)
| ProfileKey |
Plan |
Status |
IsCurrent |
| :--- |
:--- |
:--- |
:--- |
| 55 |
Basic |
Active |
Yes |
*Процесс изменения:* Иван переходит на план “Premium”.
- В `DimSubscriptionProfile` добавляется новая строка для “Premium”, а старая помечается как неактуальная.
- В `DimCustomer` у Ивана обновляется ключ `SubscriptionProfileKey`.
*Таблицы после изменений:*
`DimCustomer` (здесь изменился только ключ)
| CustomerKey |
FullName |
SubscriptionProfileKey |
| :--- |
:--- |
:--- |
| 202 |
Иван Иванов |
56 |
`DimSubscriptionProfile` (здесь хранится вся история)
| ProfileKey |
Plan |
Status |
IsCurrent |
| :--- |
:--- |
:--- |
:--- |
| 55 |
Basic |
Active |
No |
| 56 |
Premium |
Active |
Yes |
Тип 6: Гибридный (Комбинация Типа 1, 2 и 3)
Идея: Обеспечить максимальную гибкость для анализа, объединив сильные стороны трех основных типов в одной таблице.
- Как работает: Этот тип строится на основе **SCD Тип 2 (добавление новой строки для истории), но с добавлением атрибутов из SCD Тип 1 (перезапись) для упрощения некоторых запросов.
- Основная структура — это SCD Тип 2: есть строки для каждой исторической версии с полями `StartDate`, `EndDate` и `IsCurrent`. Поле атрибута (например, `City`) хранит значение, актуальное на тот исторический период.
- Дополнительно в таблицу добавляется столбец `CurrentCity`. Этот столбец для *всех* записей одного клиента (и исторических, и текущей) всегда хранит актуальное на данный момент значение (поведение SCD Тип 1).
- Когда использовать:** Когда аналитикам часто нужно отвечать на два типа вопросов:
- “Каким был город клиента на момент продажи?” (Используется историческое поле `City`).
- “Каковы продажи всем клиентам, которые *сейчас* живут в Москве, за всю историю?” (Используется поле `CurrentCity` для фильтрации).
- Преимущества:**
- Невероятная гибкость анализа без сложных `JOIN` или подзапросов для определения текущего состояния.
- Недостатки:**
- Усложнение ETL/ELT. При изменении адреса нужно не только создать новую строку и закрыть старую, но и обновить поле `CurrentCity` во всех предыдущих строках для этого клиента. Это может быть ресурсозатратно.
Пример:
Снова Анна, переезжающая из Москвы в Санкт-Петербург.
*Таблица `DimCustomer` до изменений:*
| SurrogateKey |
CustomerID |
City |
CurrentCity |
StartDate |
EndDate |
IsCurrent |
| :--- |
:--- |
:--- |
:--- |
:--- |
:--- |
:--- |
| 1 |
101 |
Москва |
Москва |
2020-01-15 |
NULL |
Yes |
*Процесс изменения:*
- Старая строка “закрывается” (обновляется `EndDate`, `IsCurrent` = ‘No’).
- Создается новая актуальная строка.
- Во всех строках для CustomerID=101 поле `CurrentCity` обновляется до “Санкт-Петербург”.
*Таблица `DimCustomer` после изменений:*
| SurrogateKey |
CustomerID |
City |
CurrentCity |
StartDate |
EndDate |
IsCurrent |
| :--- |
:--- |
:--- |
:--- |
:--- |
:--- |
:--- |
| 1 |
101 |
Москва |
Санкт-Петербург |
2020-01-15 |
2024-08-15 |
No |
| 2 |
101 |
Санкт-Петербург |
Санкт-Петербург |
2024-08-16 |
NULL |
Yes |
Теперь можно легко отфильтровать по `City` для исторического анализа или по `CurrentCity` для анализа в разрезе текущего состояния.
Ссылки для дальнейшего изучения
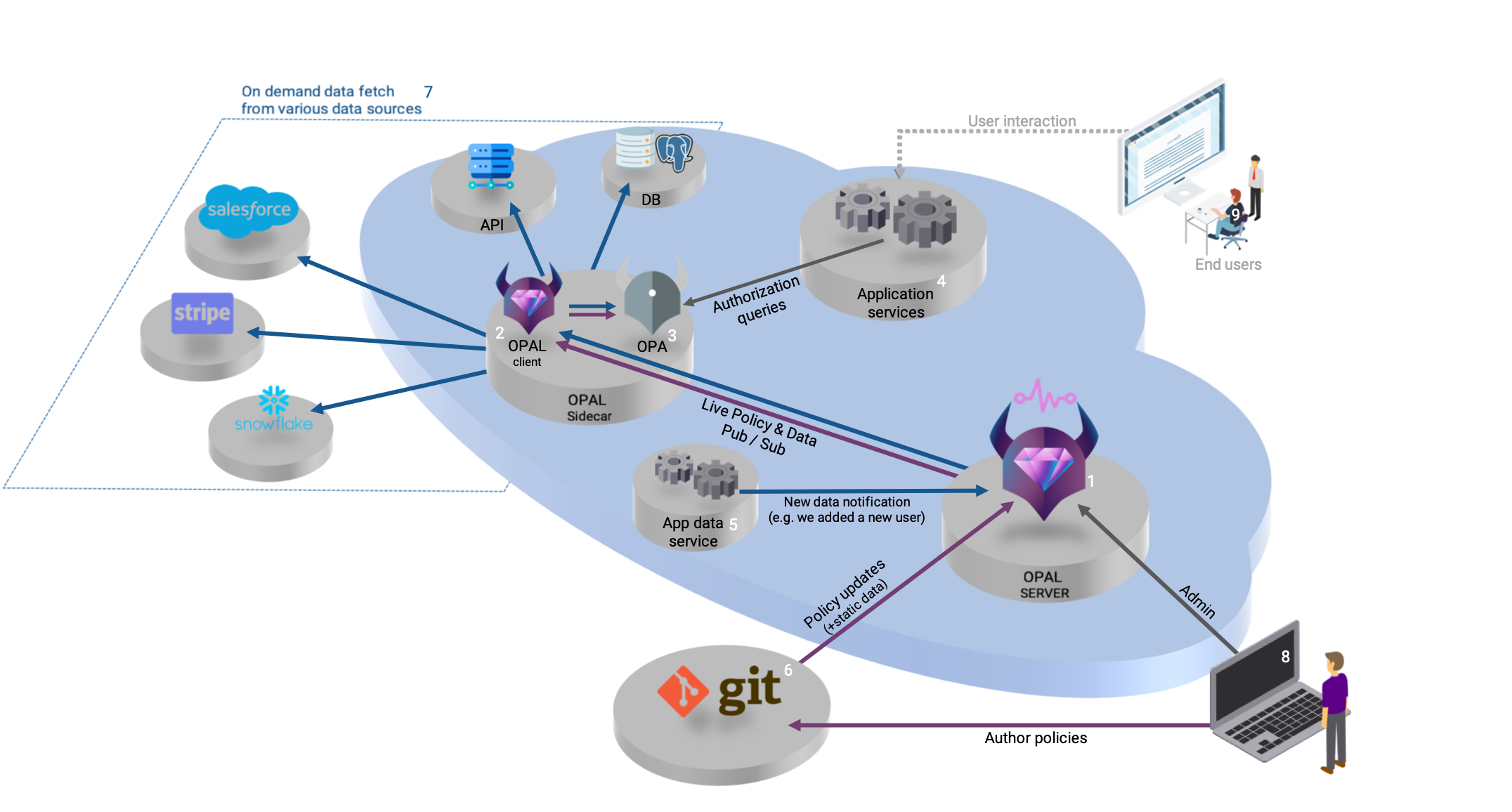
Идея: Концептуальная архитектура: SCD на стеке Lakehouse + Data Mesh + dbt
Основная идея заключается в создании надежных, версионируемых и децентрализованных “продуктов данных”, одним из которых является таблица измерений с полной историей (SCD). (Автоматическая)
Вот как компоненты взаимодействуют друг с другом:
- Lakehouse (Основа): Это наша физическая среда. Мы используем открытое озеро данных (например, S3, ADLS) для хранения, а поверх него — табличный формат Apache Iceberg. Iceberg предоставляет нам ACID-транзакции, эволюцию схемы и, что самое важное для SCD, атомарные и эффективные операции `MERGE` (`UPDATE`/`INSERT`/`DELETE`) на уровне строк прямо в озере данных.
- Data Mesh (Философия организации): Вместо централизованной команды данных, мы принимаем философию Data Mesh. A “Команда домена Клиенты” несет полную ответственность за все данные, связанные с клиентами. Их задача — предоставить остальной компании высококачественный продукт данных под названием `dim_customers`. Этот продукт должен включать полную историю изменений (SCD Type 2).
- ETL/ELT (Процесс): Это конвейер, по которому данные текут от источника к потребителю.
- Extract & Load: Исходные данные (например, изменения в базе данных клиентов) захватываются с помощью CDC (Change Data Capture) инструментов типа Debezium и попадают в **Kafka. Оттуда они загружаются (Load) в “бронзовый” слой нашего Lakehouse (в сыром виде, в таблицы Iceberg).
- Transform: Здесь в игру вступает **dbt. Команда домена использует `dbt` для преобразования сырых данных из бронзового слоя в готовую к использованию модель в “серебряном” слое — нашу таблицу `dim_customers`.
- dbt (Инструмент автоматизации SCD): `dbt` является сердцем автоматизации. Он не просто выполняет SQL-скрипты. У него есть встроенный функционал для реализации SCD Type 2, который называется `Snapshots`.
---
Сценарий 1: Автоматическое формирование SCD с помощью `dbt snapshots`
Это наиболее распространенный, надежный и идиоматический способ реализации идеи.
Как это работает:
- Источник: У нас есть “бронзовая” таблица `bronze_customers`, которая содержит текущее состояние всех клиентов. Эта таблица обновляется периодически (например, раз в час) новыми данными из Kafka.
- dbt Snapshot: В проекте `dbt` команда домена создает файл “снэпшота” (`snapshot/customers_snapshot.sql`). Внутри него описывается, как `dbt` должен отслеживать изменения.
{% snapshot customers_snapshot %}
{{
config(
target_schema='silver',
unique_key='customer_id',
strategy='check',
check_cols=['address', 'email', 'phone_number'],
updated_at='last_modified_at',
)
}}
select * from {{ source('bronze', 'customers') }}
{% endsnapshot %}
- Автоматизация: Оркестратор (например, Airflow) запускает команду `dbt snapshot` по расписанию.
- Что делает dbt “под капотом”:
- Он сравнивает записи из исходной таблицы (`bronze_customers`) с текущими записями в целевой таблице (`silver.customers_snapshot`).
- Используя `unique_key` (`customer_id`), он находит совпадающие записи.
- С помощью стратегии `check` он проверяет, изменилось ли значение в любом из столбцов, перечисленных в `check_cols`.
- Если изменение обнаружено:
- Он обновляет старую запись в целевой таблице, проставляя ей дату окончания актуальности (`dbt_valid_to`).
- Он вставляет новую строку с обновленными данными и датой начала актуальности (`dbt_valid_from`).
- `dbt` генерирует одну атомарную операцию `MERGE` для таблицы Iceberg, которая эффективно выполняет все эти обновления и вставки за одну транзакцию.
Результат: В `silver.customers_snapshot` мы получаем идеальную таблицу SCD Type 2, которая обновляется автоматически и надежно, без написания сложной логики `MERGE` вручную.