Книга “I ♥ Logs” Джея Крепса
Часть 1: Книга “I Love Logs” EVENT DATA, STREAM PROCESSING, AND DATA INTEGRATION
Джей Крепс

Оригинальные идеи и рекомендации книги:
- Лог как фундаментальная абстракция:
- Ключевая идея: лог — это не просто текстовый файл для отладки, а упорядоченная, неизменяемая (append-only) последовательность записей (событий), снабженная уникальными, последовательно увеличивающимися номерами (offset’ами), которые служат “временем” в распределенной системе.
- Он является “источником истины” (`source of truth`) и позволяет восстановить состояние системы.
- State Machine Replication Principle: Если два детерминированных процесса начинают в одном состоянии и получают одинаковые входные данные в одном и том же порядке, они произведут одинаковый вывод и закончат в одном и том же состоянии. Лог обеспечивает этот “одинаковый порядок”.
- Роль логов в базах данных:
- Логи лежат в основе работы ACID-баз данных (commit log, transaction log) для обеспечения атомарности, изоляции и долговечности.
- Используются для репликации данных между мастером и репликами (Change Data Capture – CDC).
- Применения логов:
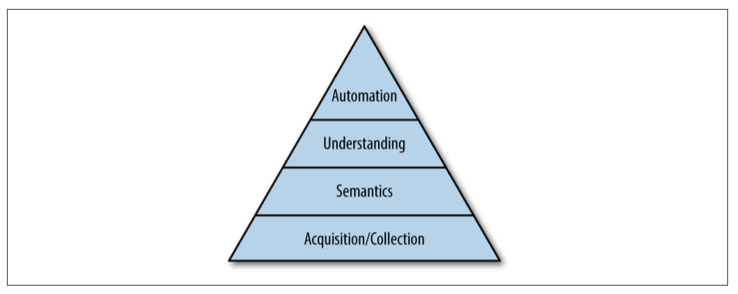
- Интеграция данных (Data Integration): Лог становится центральной “магистралью данных” или единой “шиной событий” для всей организации. Он решает проблему интеграции “N систем с N системами” (N²) путем преобразования ее в “N систем с одним логом” (N). Крепс приводит “Иерархию потребностей Маслоу для данных” (сбор/аквизиция данных, семантика, понимание, автоматизация), подчеркивая, что без надежного сбора данных невозможно ничего другого.
- Организационная масштабируемость**: Ответственность за чистоту и формат данных лежит на *производителе* данных, а не на потребителях или центральной команде ETL.
- Потоковая обработка в реальном времени (Real-time Stream Processing): Лог — это естественное представление потока данных. Любое событие в реальном времени, база данных, изменяющаяся с течением времени, — всё это логи.
- Крепс выступает за Kappa-архитектуру как альтернативу Lambda-архитектуре.
- Критика Lambda: Дублирование логики (один и тот же расчет в batch и stream слоях), сложность оперирования.
- Альтернативная модель репроцессинга: Вместо двух отдельных фреймворков (batch и stream) — использовать единую потоковую систему, которая может пересчитывать историю, используя лог как источник исторических данных. Когда логика меняется, запускается новый потоковый Job с начала лога, записывающий результат в новую таблицу, и после догона старая таблица заменяется новой.
- Проектирование распределенных систем: Лог упрощает дизайн. Вместо того, чтобы каждая система занималась согласованностью, репликацией и восстановлением, эти функции можно передать логированию.
- Паттерн “Сервис = Лог + Serving Layer”: Лог хранит все изменения (source of truth), а “serving layer” (например, поисковая система, key-value хранилище) строит индексированные или материализованные представления на основе лога для быстрых запросов.
- Технические особенности и оптимизации:
- Партиционирование лога: Для горизонтального масштабирования (Kafka). Позволяет обрабатывать записи независимо, не требует глобального порядка. Порядок гарантируется только в пределах одной партиции.
- Батчинг (Batching): Соединение мелких операций в крупные для повышения пропускной способности.
- Zero-Copy Data Transfer: Передача данных между слоями памяти без их копирования, что улучшает производительность.
- Log Compaction (Компактирование лога): Оптимизация хранения для “лагов изменений” (changelogs). Вместо хранения всех версий записи, оставляется только последняя версия для каждого ключа. Это позволяет восстановить *текущее* состояние, но не *всю* историю.
- Дуальность таблиц и событий (Tables and Events Are Dual):
- Крепс проводит аналогию с системами контроля версий (Git): история изменений (патчи) — это лог, а текущая рабочая копия — это таблица.
- Данные могут свободно “перетекать” между состоянием (таблица) и потоком изменений (лог).
Стоило бы дополнить (2023-2024):
- Эволюция экосистемы:
- Книга вышла в 2014 году. С тех пор Kafka стала де-факто стандартом. Появились альтернативы Apache Pulsar его, кстати, умеет читать и писать Seatunnel :) и множество надстроек/фреймворков (Kafka Streams, Flink SQL, Materialize).
- Рост Serverless-архитектур и их интеграция с логами (AWS Lambda, Google Cloud Functions, Azure Functions как потребители логов).
- Повсеместное использование Kubernetes и операторов для развертывания и управления Kafka-кластерами.
- Управление схемами (Schema Management):
- Книга упоминает структурированные логи, но не углубляется в детали. Сегодня критически важен Schema Registry (например, Confluent Schema Registry или http://apicur.io) для обеспечения совместимости схем данных в логах и управления их версиями. Это предотвращает “data swamp” и делает логи действительно надежным источником данных.
- Качество данных и Observability:
- Помимо “структуры”, важна *семантика* и *качество* данных. Мониторинг “data quality”, “data lineage” (происхождение данных) и “data governance” становятся ключевыми.
- Observability: Трассировка событий через лог-пайплайн (например, OpenTelemetry), сбор метрик (lag потребителей, пропускная способность, ошибки) с Prometheus/Grafana.
- Безопасность (Security):
- Шифрование данных в пути (TLS) и в состоянии покоя (at-rest encryption).
- Аутентификация и авторизация (RBAC) для продюсеров и потребителей Kafka.
- Аудит доступа к логам.
- Паттерны микросервисной архитектуры:
- Event Sourcing и CQRS стали стандартными паттернами.
- Saga Pattern для координации распределенных транзакций между микросервисами, часто реализуемых через лог.
- Data Mesh: Принцип, что данные должны рассматриваться как продукт. Команда-владелец домена отвечает за свой “дата-продукт” и предоставляет его через лог, который является частью этого “продукта”.
- Real-time Analytics и ML:
- Пайплайны с логами используются для обучения и инференса ML-моделей в реальном времени. Например, логи кликов для рекомендательных систем.
- Появление GPU-ускоренных фреймворков для потоковой обработки (например, NVIDIA RAPIDS).
- Антипаттерны и ошибки: Конкретные примеры из практики, как неправильное внедрение логов может привести к проблемам.
---
Часть 2: Современный взгляд Логи: Кровеносная система Data-Driven компаний
Представьте себе, что данные – это жизненная сила вашей компании, а IT-инфраструктура – ее тело. Тогда логи, как это ни парадоксально, стали бы ее кровеносной системой. Они несут информацию от каждой клетки к каждому органу, обеспечивая слаженность и жизнеспособность всего организма.
В эпоху распределенных систем, микросервисов, Big Data и искусственного интеллекта, когда скорость обработки информации определяет конкурентное преимущество, традиционные подходы к интеграции и обработке данных трещат по швам. Книга, которая у вас в руках – это переосмысление ключевых идей Джея Крепса, соавтора Apache Kafka, о том, как “скромный” лог превратился из технической детали в центральный архитектурный примитив.
Мы пройдем путь от понимания природы лога до его применения в масштабных системах, интеграции данных, потоковой обработке и построении отказоустойчивых архитектур. Эта книга не только сохранит оригинальные прозрения, но и дополнит их новейшими практиками, инструментами и опытом, накопленным IT-индустрией за последнее десятилетие. Вы узнаете, как избежать распространенных ошибок и построить по-настоящему гибкую и масштабируемую систему, где данные действительно “текут” свободно.
---
Глава 1: Лог: Недооцененный фундамент современных систем
Когда речь заходит о логах, большинство инженеров представляют себе длинные текстовые файлы с отладочной информацией. Однако, как показал Джей Крепс, истинная природа лога гораздо глубже.
Что такое Лог? Глубже, чем кажется.
Представьте себе не просто текстовый файл, а упорядоченную, неизменяемую последовательность записей. Каждая запись добавляется в конец. Это фундаментальное отличие от базы данных, где данные можно изменять “на месте”. В логе ни одна запись не удаляется и не меняется. Вместо этого, новые изменения *добавляются* как новые записи.
Каждая запись в логе имеет уникальный, последовательно возрастающий номер, который можно считать её “временем” или “позицией” в потоке. Это ключевое свойство: оно дает нам гарантию порядка.
Принцип State Machine Replication: Волшебство порядка
Это краеугольный камень распределенных систем. Он гласит:
Если два идентичных, детерминированных процесса начинают в одном состоянии и получают одинаковые входные данные в одном и том же порядке, они произведут одинаковый вывод и закончат в одном и том же состоянии.
В этом принцип “лога” критически важен: он обеспечивает “одинаковый порядок” входных данных для всех реплик. Если у вас есть лог всех изменений (событий), вы можете “воспроизвести” этот лог на разных машинах, чтобы они достигли идентичного состояния.
*Пример из практики*: Банковский счет. Вместо хранения одного числа (текущий баланс), мы храним лог всех транзакций: “снятие 1000 руб.”, “поступление 5000 руб.”. Текущий баланс – это всего лишь функция, которая суммирует все записи в логе до текущего момента. Если банк “забудет” состояние баланса, он всегда может его восстановить, проиграв лог всех транзакций.
Логи в базах данных: Невидимый двигатель
Внутри любой надежной реляционной базы данных или NoSQL-хранилища уже давно работает лог: `commit log` или `transaction log`. Он гарантирует, что даже при сбое системы, транзакции не будут потеряны, а данные останутся согласованными (свойства ACID). Механизмы репликации баз данных (например, бинарные логи MySQL или WAL PostgreSQL) – это по сути потоковая передача записей из такого лога. Это и есть Change Data Capture (CDC) – захват изменений данных.
Дополнение (2023-2024):
- Структурированные логи и схемы: Для машинного чтения и обработки логам необходим строгий формат. Сегодня это почти всегда JSON, Apache Avro или Google Protocol Buffers.
- Рекомендация: Используйте Schema Registry**. Это централизованное хранилище ваших схем, которое позволяет эволюционировать схемы логов, не ломая обратную совместимость. Оно критически важно для долгосрочной жизнеспособности вашей data-инфраструктуры. Без Schema Registry ваши логи быстро превратятся в “data swamp” – болото неструктурированных, непонятных данных.
- Лог как Event Stream: В современных архитектурах каждый чих в системе – это событие. Логи веб-сервера, действия пользователя, метрики микросервисов, изменения в БД – все это может быть представлено как лог событий.
Ошибки, которых стоит избегать:
- “Лог для людей, а не для машин”: Если вы используете логи только для чтения человеком при отладке, вы упускаете их колоссальный потенциал как источника данных для других систем.
- Отсутствие структурированности: Произвольные текстовые сообщения в логах делают их крайне сложными для автоматического анализа и интеграции. Всегда! используйте структурированные форматы.
- Игнорирование порядка: Если события записываются без гарантии порядка, вы никогда не сможете надежно воспроизвести состояние системы или построить корректные агрегаты.
---
Глава 2: Данные как потоки: Интеграция через Логи
Одна из самых болезненных проблем в больших компаниях – это интеграция данных. Исторически это решалось кастомными ETL (Extract, Transform, Load) пайплайнами, где каждая система “говорила” с каждой. Такая модель приводит к экспоненциальному росту сложности (N² соединений для N систем).
Централизованная шина событий: Революция в интеграции
Идея Крепса: вместо N² соединений, создайте универсальный централизованный лог, который будет выступать в роли “шины событий” или “артерии данных”.
- Производители данных: Системы, генерирующие данные, публикуют их в этот центральный лог.
- Потребители данных: Системы, которым нужны эти данные, подписываются на соответствующие части лога (топики) и потребляют их независимо, в своем темпе.

```mermaid
graph LR
A[Система 1 (Продюсер)] -- Публикует --> C(Центральный Лог)
B[Система 2 (Продюсер)] -- Публикует --> C
C -- Потребляет --> D[Система A (Потребитель)]
C -- Потребляет --> E[Система B (Потребитель)]
C -- Потребляет --> F[Система C (Потребитель)]
```Вместо множества прямых соединений между A-D, A-E, A-F, B-D, B-E, B-F, мы получаем лишь несколько соединений к центральному логу. Сложность снижается с N² до N.
Иерархия потребностей данных по Маслоу (адаптировано Крепсом):
- Аквизиция/Сбор данных: Самый важный базовый уровень. Без надежного, полного и структурированного сбора данных не имеет смысла говорить о чём-то другом. Многие компании пытаются “прыгнуть” сразу к ИИ и машинному обучению, имея хаотично собираемые данные. Это обратная логика.
- Семантика: Понимание значения данных, их контекста, метаданных.
- Понимание: Способность строить отчеты, визуализации.
- Автоматизация: Реализация сложных алгоритмов, прогнозов.
Задача интеграции данных лежит в основе этой иерархии. Логи — это инструмент для её решения.
Дополнение (2023-2024):
- Data Mesh и Data Products: Эта концепция идеально ложится на идею центрального лога. Каждая команда-владелец домена (например, “Клиенты”, “Заказы”) становится ответственной за свой “Data Product”. Этот продукт включает в себя данные (часто в виде топиков лога), их схемы, качество, доступность и документацию.
- Рекомендация: Внедряйте `Data Contracts`. Это соглашения между командами о структуре и семантике данных, которые они передают через лог, аналогично API-контрактам.
- Cloud-Native решения:
- Managed Kafka: Облачные провайдеры предлагают управляемые сервисы Kafka (Confluent Cloud, AWS MSK, Azure Event Hubs). Это снимает бремя операционного управления.
- CDC: Инструменты вроде Debezium позволяют легко интегрировать изменения из традиционных баз данных (PostgreSQL, MySQL, MongoDB) напрямую в Kafka в реальном времени, превращая их в логи событий.
- Трансформации данных: Где делать ETL?
- Source-side: Продюсер должен публиковать максимально чистые, канонические данные.
- Stream-side: Для добавления обогащённых данных или агрегатов могут быть использованы потоковые процессоры (см. Глава 3), создающие новые, производные топики лога.
- Sink-side: Минимальные трансформации при загрузке в целевые системы (например, для специфичных схем БД хранилища).
Ошибки, которых стоит избегать:
- “Big Ball of Mud”: Не пытайтесь создавать слишком сложные ETL-пайплайны внутри самого лога. Идеально, если лог остаётся “сырым” источником событий, а трансформации и обогащения происходят в отдельных потоковых приложениях.
- Отсутствие ownership: Если нет четкой ответственности за данные, опубликованные в логе, они быстро теряют качество. Команда-производитель должна быть “владельцем” своих данных в логе.
- Blindly копирование всего: Не все данные нужны всем. Фильтруйте и маршрутизируйте данные к нужным потребителям, чтобы не перегружать системы и сократить расходы.
---
Глава 3: Потоковая обработка в реальном времени и не только
Логи и потоковая обработка неотделимы друг от друга. Лог — это естественная модель для потока событий.
Что такое потоковая обработка? Шире, чем кажется.
Крепс расширил определение потоковой обработки. Это не просто “обработка данных по мере их поступления и затем отбрасывание”. Это непрерывная обработка данных, способная выдавать результаты с низкой задержкой, но при этом иметь дело с историческими данными (то есть, лог можно переиграть).
От Lambda к Kappa: Парадокс репроцессинга
Традиционная Lambda-архитектура предполагала два параллельных пути обработки:
- Batch-слой (партия): Высокая задержка, высокая точность, обработка всей истории (например, Hadoop MapReduce).
- Speed-слой (скорость): Низкая задержка, возможно, меньшая точность, обработка только новых данных (например, Storm).
Результаты из обоих слоев объединяются для получения полной картины.
Проблема Lambda: Дублирование бизнес-логики. Один и тот же расчет должен быть написан и поддерживаться дважды, на двух разных фреймворках (например, HiveQL/Spark для batch и Flink/Storm для stream). Это приводит к ошибкам, задержкам в разработке и высоким операционным издержкам.
Kappa-архитектура (Преимущество лога): Изобретая колесо заново, но лучше.
Крепс предложил элегантную альтернативу — Kappa-архитектуру, которая устраняет необходимость в отдельном batch-слое. Идея проста:
- Храните все сырые данные в логе (Kafka): Настройте достаточно длинный `retention` (срок хранения), например, 30, 90 дней или даже дольше, если это необходимо для исторического анализа.
- Единый потоковый процессор: Используйте один фреймворк (например, Apache Flink, Kafka Streams) для обработки данных. Этот же код обрабатывает как новые, так и исторические данные.
- Репроцессинг без боли: Если вам нужно изменить логику обработки или исправить ошибку:
- Запустите новый экземпляр потокового Job.
- Он начинает читать данные с начала лога.
- Результаты записываются в новую целевую таблицу/топик.
- Как только новый Job “догонит” текущее время, переключите потребителей с “устаревшей” целевой таблицы на “новую”.
- Остановите и удалите старый Job и старую таблицу.

```mermaid
graph TD
A[Исходный Лог (Kafka)]
B[Старый Processing Job (v1)]
C[Новый Processing Job (v2)]
A -- Читает с offset 0 --> C
A -- Читает с текущего offset --> B
B -- Записывает в --> D[Старая Выходная Таблица]
C -- Записывает в --> E[Новая Выходная Таблица]
F[Приложение]-->D
subgraph Reprocessing
C
end
subgraph Switch
direction LR
F --> G[Переключить на E]
G --> H[Удалить D, остановить B]
end
```Дополнение (2023-2024):
- Фреймворки:
- Apache Flink**: Де-факто стандарт для сложных stateful-вычислений с `exactly-once` семантикой. Поддерживает `event time`, `watermarks` (для обработки событий, пришедших не по порядку) и гибкие окна агрегации.
- Kafka Streams / ksqlDB**: Для более простых задач обработки в рамках экосистемы Kafka. Идеально для микросервисов.
- Apache Spark Streaming / Structured Streaming**: Позволяет использовать привычные API Spark для потоков.
- Работа с состоянием (Stateful Processing): Многие потоковые задачи требуют сохранения состояния (например, подсчёт уникальных пользователей за час). Современные фреймворки (Flink) позволяют хранить это состояние отказоустойчиво, часто используя RocksDB локально и чекпоинты в удаленном хранилище (S3/HDFS).
- Real-time OLAP / Data Warehousing: Появляется класс решений, которые строят агрегаты и индексы напрямую из логов для интерактивных аналитических запросов (например, ClickHouse, Apache Druid, Materialize).
- GPU-ускорение: Для ML-инференса и сложных расчетов на потоках, где время критично (например, обнаружение аномалий, фрод-мониторинг), начинают использоваться GPU-ускоренные библиотеки (NVIDIA RAPIDS).
Ошибки, которых стоит избегать:
- Игнорирование late data: События в реальном мире не всегда приходят по порядку. Используйте `watermarks` и `event time` для корректной обработки “поздних” данных.
- Репроцессинг “на потом”: Откладывание возможности репроцессинга приводит к накоплению технического долга и невозможности быстро исправлять ошибки в логике. Заложите её в архитектуру с самого начала.
- Чрезмерное усложнение: Не пытайтесь написать собственный потоковый движок. Используйте проверенные фреймворки, они уже решили большинство проблем с распределенностью, отказоустойчивостью и производительностью.
---
Глава 4: Логи как фундамент для отказоустойчивых систем
Помимо интеграции и потоковой обработки, логи играют решающую роль в построении самих распределенных систем, упрощая их внутреннюю архитектуру.
Паттерн “Сервис = Лог + Serving Layer”
В этом паттерне логика сервиса разделяется на две основные части:
- Лог (The Log): Выступает как *единственный источник истины* для всех изменений состояния сервиса. Все записи (события, команды) сначала попадают в лог.
- Serving Layer (Слой обслуживания/запросов): Это набор вычислительных узлов, которые подписываются на лог и строят локальные, оптимизированные для запросов, представления данных (индексы).
- Пример: Пользователь хочет обновить свой профиль. Запрос на обновление фиксируется как событие в логе. Serving Layer, потребляя это событие, обновляет свою локальную копию данных (например, в базе данных или поисковом индексе Elasticsearch). Когда пользователь запрашивает профиль, запрос идет в Serving Layer.
- Преимущество: Serving Layer может быть оптимизирован под конкретный тип запроса (например, Elasticsearch для полнотекстового поиска, Redis для быстрого key-value доступа), но при этом получать все данные из единого, надежного лога.

```mermaid
graph TD
A[Client] --> B[API Gateway/Микросервис записи]
B -- Записывает событие/изменение --> C(Центральный Лог)
C -- Подписывается --> D[Serving Layer 1 (напр. Elasticsearch)]
C -- Подписывается --> E[Serving Layer 2 (напр. Redis Cache)]
C -- Подписывается --> F[Serving Layer 3 (напр. Data Warehouse)]
A -- Читает --> D
A -- Читает --> E
```Преимущества такой архитектуры:
- Отказоустойчивость и восстановление: Если Serving Layer упадет, он может полностью восстановить свое состояние, “проиграв” лог с самого начала или с последнего чекпоинта. Лог является его бэкапом.
- Изоляция сбоев: Падение одного Serving Layer не влияет на способность других Serving Layer’ов продолжать работу.
- Детерминированность: Гарантия порядка из лога обеспечивает согласованность данных во всех Serving Layer’ах.
- Горизонтальное масштабирование: Лог можно партиционировать (делим данные на части), и каждый Serving Layer может обрабатывать одну или несколько партиций, что позволяет добавлять узлы по мере роста нагрузки.
- Отсутствие блокировок: Поскольку записи идут в лог, а чтение происходит из Serving Layer, это значительно снижает конкуренцию и улучшает параллелизм.
Log Compaction: Компактирование истории
Не всегда нужно хранить полную историю каждого изменения. Например, если вы отслеживаете текущее местоположение курьера, вам нужна только *последняя* координата, а не весь его путь.
- Log Compaction (компактирование лога) – это процесс, при котором для каждого ключа в логе сохраняется только его *последнее* значение, а все предыдущие дубликаты удаляются.
Это позволяет логу действовать как changelog (журнал изменений), который, будучи проигранным с начала, воссоздаст *текущее* состояние распределенной таблицы. - Пример: Kafka умеет выполнять компактирование топиков, что идеально подходит для хранения состояния Key-Value пар (например, текущие балансы счетов, последние известные IP-адреса).
Дополнение (2023-2024):
- Event Sourcing: Паттерн, при котором основное состояние приложения сохраняется как последовательность событий в логе, а не как изменяемое состояние в базе данных. Состояние агрегатов получается путем применения всех событий.
- Command Query Responsibility Segregation (CQRS): Часто используется вместе с Event Sourcing. Команды (изменения) записываются в лог, а запросы (чтения) обслуживаются из оптимизированных для чтения материализованных представлений, построенных из того же лога.
- Saga Pattern: Для координации долгих распределенных транзакций между множеством микросервисов, лог событий часто используется как механизм асинхронной связи и координации. Каждый сервис публикует событие о завершении своей части работы, а координатор Саги реагирует на эти события.
- Kubernetes Operators: Для управления сложностью распределенных лог-систем, таких как Kafka, существуют Kubernetes Operators, которые автоматизируют развертывание, масштабирование, восстановление и обновление кластеров.
- Observability (наблюдаемость): Логи — это не только данные, но и инструмент для понимания поведения системы. Добавьте трассировку (`trace_id` в события) для отслеживания пути запроса через множество микросервисов и логов. Анализируйте `consumer lag` (отставание потребителей) как ключевую метрику здоровья потоковой системы.
Ошибки, которых стоит избегать:
- “Я напишу свою Kafka”: Построение надежной распределенной лог-системы чрезвычайно сложно. Используйте проверенные решения (Kafka, Pulsar).
- Забыть о версионировании: Изменения в структуре событий могут сломать старых потребителей. Используйте Schema Registry и стратегии совместимости схем (backward/forward compatibility).
- Ручное управление состоянием: Не пытайтесь управлять состоянием stateful-приложений вручную. Доверьте эту задачу фреймворкам потоковой обработки, которые используют лог для отказоустойчивости.
---
Глава 5: Безопасность, Надежность и Операционная Эффективность
Лог, будучи “источником истины” и “кровеносной системой” данных, требует самого высокого уровня внимания к безопасности, надежности и операционной эффективности.
Безопасность (Security): Доверяй, но проверяй
- Шифрование данных:
- В пути (In-transit Encryption): Всегда используйте TLS (Transport Layer Security) для обмена данными между клиентами (продюсерами/потребителями) и брокерами лога, а также между самими брокерами.
- В состоянии покоя (At-rest Encryption): Шифруйте данные на диске, где хранятся логи. Это может быть реализовано на уровне операционной системы, файловой системы или диска (LUKS, AWS EBS Encryption).
- Аутентификация и Авторизация (Authentication & Authorization – RBAC):
- Аутентификация: Убедитесь, что только доверенные клиенты могут подключаться к лог-системе (например, с помощью SASL/Kerberos, SSL-сертификатов или OAuth 2.0).
- Авторизация (RBAC): Применяйте принцип наименьших привилегий. Контролируйте, кто может записывать в конкретные топики, а кто может читать из них. Отдельные приложения могут иметь разрешения только на чтение из определённых топиков и запись в свои собственные выходные топики.
- Аудит (Auditing): Включите логи аудита для всех действий в лог-системе (кто, когда, что изменил или прочитал).
Надежность (Reliability): Будьте готовы ко всему
- Репликация данных: Для обеспечения надежности критически важные данные должны быть реплицированы. В Kafka это достигается за счет репликации партиций между брокерами. Определите `replication factor` (фактор репликации) в зависимости от критичности данных (обычно 3).
- Диспетчер сбоев (Disaster Recovery):
- Внутрикластерная отказоустойчивость: Лог-система должна быть способна выдержать отказ отдельных узлов или зон доступности (Availability Zones) без потери данных.
- Географическая репликация: Для защиты от сбоев целых дата-центров используйте мульти-кластерные развертывания с гео-репликацией (например, MirrorMaker2 для Kafka).
- Idempotence Producers: Убедитесь, что продюсеры могут повторно отправлять сообщения при сбоях без создания дубликатов, достигая `at-least-once` или `exactly-once` семантики.
- At-least-once, At-most-once, Exactly-once Semantics: Понимайте и выбирайте подходящую семантику доставки сообщений для каждого пайплайна. `Exactly-once` сложнее всего, но обеспечивает максимальную точность.
Операционная Эффективность (Operational Efficiency): Не замедляйтесь
- Партиционирование: Правильное партиционирование топиков критически важно.
- Должно быть достаточно партиций для параллельной обработки.
- Ключи партиционирования должны распределять нагрузку равномерно.
- Ошибка: Недостаточное количество партиций может привести к узким местам. Слишком много партиций усложняет управление и увеличивает нагрузку на брокеры.
- Батчинг (Batching): Соединяйте мелкие записи в большие “пакеты” перед отправкой в лог. Это значительно уменьшает накладные расходы на I/O и сетевые операции.
- Zero-Copy: Используйте механизмы, позволяющие передавать данные из лога напрямую в сетевой сокет, минуя буферы приложения для копирования. Это снижает нагрузку на CPU.
- Мониторинг: Ключ к здоровой системе.
- Метрики брокеров: CPU, память, диск I/O, сетевой трафик, количество сообщений, пропускная способность.
- Метрики топиков: Размер, количество партиций, скорость записи/чтения.
- Метрики потребителей: Consumer Lag (отставание потребителей) — это самая важная метрика. Если `consumer lag` растет, значит, потребитель не справляется с нагрузкой, и данные накапливаются.
- Алерты: Настройте оповещения на критические метрики (высокий `consumer lag`, ошибки записи/чтения, недоступность брокеров).
- Логирование и Трассировка: Стандартизируйте форматы логов приложений, отправляющих и потребляющих данные из лога. Включите корреляционные ID (`trace_id`, `span_id`) для отслеживания событий через всю распределенную систему (например, с помощью OpenTelemetry).
- Управление ресурсами: Убедитесь, что у брокеров лога достаточно ресурсов (CPU, RAM, диск I/O) для обработки пиковых нагрузок. Используйте быстрые диски (SSD/NVMe).
Дополнение (2023-2024): Chaos Engineering
- Для проверки устойчивости вашей лог-инфраструктуры к сбоям, регулярно проводите эксперименты в контролируемой среде.
- Примеры**: Имитация отказа брокера (убиваем процесс), сетевые проблемы (Partition), перегрузка диска, увеличение задержки для потребителя. Это помогает выявлять слабые места *до* того, как они проявятся в продакшене.
---
Заключение: пошаговый план к Data-Driven Будущему
Мы проделали большой путь, от понимания фундаментальной природы лога до его роли в современных распределенных системах, интеграции данных и потоковой обработке. Лог — это не просто техническая деталь, а стратегический актив, который позволяет вашей компании быть по-настоящему “data-driven”.
Краткие выводы:
- Лог — это источник истины: Он хранит историю изменений в гарантированном порядке.
- Лог упрощает: Он решает проблемы интеграции (N² → N), репликации и восстановления.
- Лог масштабирует: Благодаря партиционированию и оптимизациям, таким как батчинг и zero-copy.
- Лог — это кровь в организме данных: Без него невозможно построить гибкую, реактивную и отказоустойчивую архитектуру.
- Kappa лучше Lambda: Одна кодовая база для realtime и batch обработки.
Ваш пошаговый план к Data-Driven Архитектуре, управляемой логами:
- Начните с аудита источников данных:
- Определите, какие данные генерируются вашими системами, какие из них критически важны, какие меняются со временем.
- Поймите, где находятся “узкие места” в текущей интеграции.
- Выберите платформу логов:
- Выбор: Apache Kafka — это де-факто стандарт. Рассмотрите Apache Pulsar как альтернативу, если вам нужна расширенная гибкость.
- Развертывание: Для начала можно использовать управляемые облачные сервисы (Confluent Cloud, AWS MSK, Azure Event Hubs) или самостоятельно развернуть Kafka в Kubernetes с помощью операторов. Не пытайтесь строить свой велосипед.
- Внедрите Schema Registry:
- Это не опция, а обязательное условие.
- Соберите команды, которые генерируют данные, и начните совместно разрабатывать строгие схемы для каждого типа событий (Avro/Protobuf).
- *Рекомендация*: Внедрите процесс `data contract` – соглашения между командами о формате и семантике данных.
- Инструментируйте ключевые сервисы для публикации в лог:
- Начните с одного или двух высоконагруженных сервисов.
- Используйте Change Data Capture (CDC) (например, Debezium) для выгрузки изменений из баз данных в лог.
- Для новых сервисов и пользовательских действий изначально проектируйте их как Event Sourcing-системы, публикующие события в лог.
- Настройте базовых потребителей и хранилища:
- Автоматизируйте загрузку данных из лога в ваше основное аналитическое хранилище (Data Warehouse, Data Lake, например, S3/HDFS + Spark/Hive).
- Подключите первый “реальный” потребитель, например, систему мониторинга, которая отслеживает ключевые показатели бизнеса на основе событий из лога.
- Разверните платформу потоковой обработки:
- Начните с Apache Flink или Kafka Streams. Они позволят вам обрабатывать данные из лога, обогащать их, агрегировать и создавать новые, производные потоки данных.
- *Рекомендация*: Сначала решайте простые задачи (агрегаты, фильтрация), затем переходите к более сложным (stateful processing, windowing).
- Сосредоточьтесь на Observability и Автоматизации:
- Внедрите комплексный мониторинг всей лог-инфраструктуры (брокеры, топики, потребители) с ключевыми метриками (consumer lag!).
- Настройте алерты.
- Автоматизируйте процессы развертывания, масштабирования и восстановления лог-компонентов.
- Имплементируйте принципы безопасности:
- Шифрование, аутентификация, авторизация. Пусть это будет часть каждого нового внедрения.
- Готовьтесь к репроцессингу:
- Убедитесь, что ваши логи хранят достаточно истории (длительный retention).
- Проектируйте свои потоковые приложения с учетом возможности запуска нового экземпляра для пересчета исторических данных.
- Примите философию Data Mesh:
- Меняйте культуру: поощряйте команды владеть своими данными как продуктами.
---
Эпилог: Лог – это не просто техническая деталь, а отражение бизнес-процессов. Каждая запись – атом вашей организационной ДНК. Превратите хаос данных в нарратив, где каждая транзакция – это предложение, а каждый поток – глава вашей бизнес-истории, благодаря надежной и гибкой кровеносной системе, управляемой логами.