Битва персональных AI-суперкомпьютеров ( подготовил DeepSeek 😁 и спасибо ему за это )
Если чего, то эти игрушки для подходят для запуска средних моделей у себя дома. Железа должно хватит.
Впрочем битва только начинается. посмотрим, что еще выйдет. А пока наслаждаемся тем, что есть.
1. Аппаратная платформа: Архитектура и Производительность
NVIDIA DGX Spark
Чипсет: GB10 Grace Blackwell Superchip – гибрид 20-ядерного ARM-процессора (Cortex-X925 + Cortex-A725) и GPU Blackwell с Tensor Core 5-го поколения .
Память: 128 ГБ LPDDR5X с единым адресным пространством (CPU+GPU), что критично для обработки моделей до 200B параметров без перегрузок .
Производительность: 1 PFLOPS при FP4 с поддержкой спарсности. Для моделей >200B параметров два устройства связываются через ConnectX-7, достигая 405B .
Энергоэффективность: Потребляет ~120–240 Вт, работает от розетки 220 В .
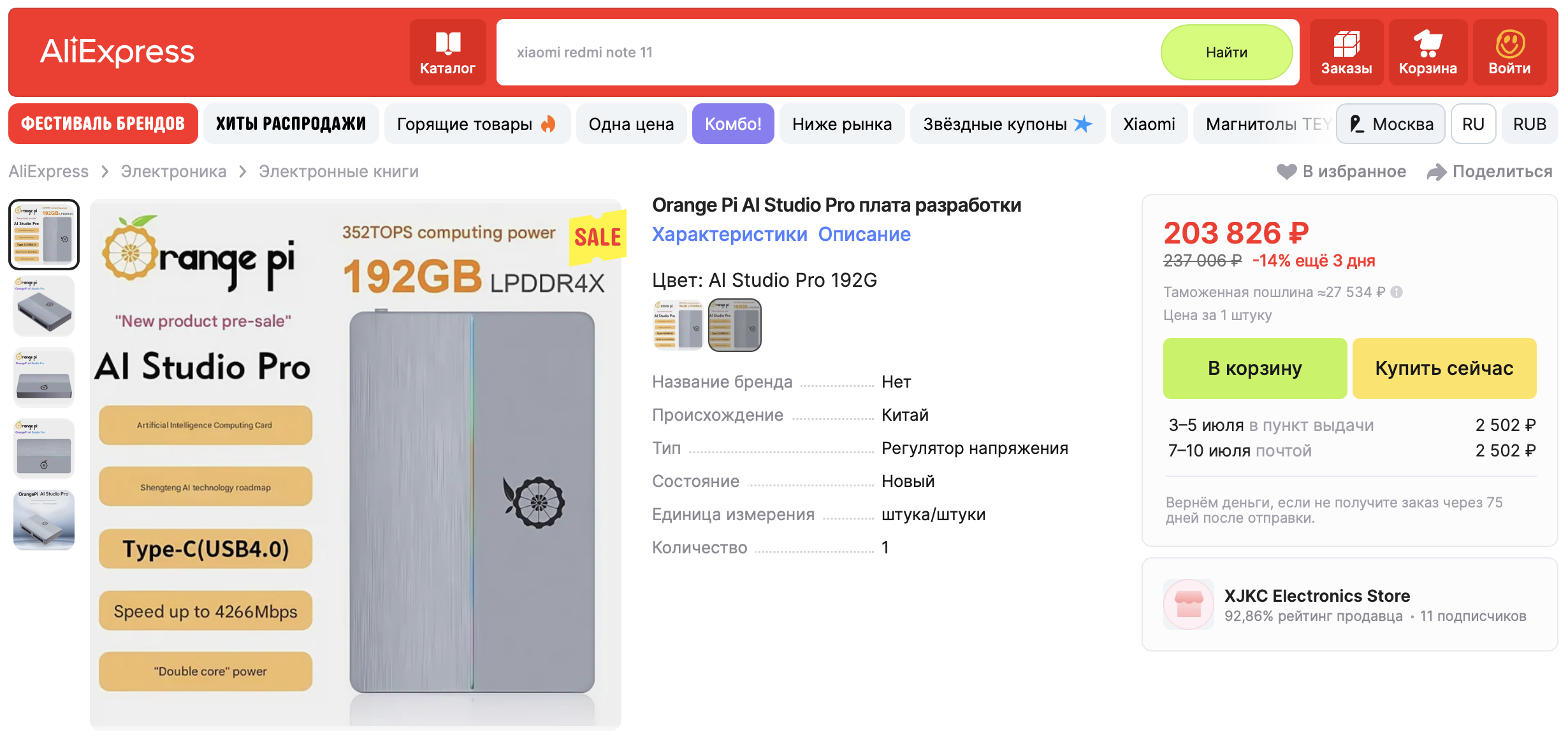
Orange Pi AI Studio Pro
Чипсет: Huawei Ascend 310s с NPU, заявленная производительность – 352 TOPS (INT8) в Pro-версии .
Память: До 192 ГБ LPDDR4X (в конфигурации Pro), но без унификации. Пользователи Reddit отмечают проблемы с пропускной способностью при загрузке LLM >70B параметров .
Масштабируемость: Нет аналога NVLink. Для больших моделей требуется ручная оптимизация через swap-файлы .
Охлаждение: Инженерные образцы склонны к перегреву при длительной нагрузке, что требует дополнительного кулера .
Резюме: DGX Spark выигрывает в балансе памяти и вычислений, Orange Pi предлагает сырую мощность TOPS, но страдает от архитектурных ограничений.
---
2. Программная экосистема: Готовность к работе
NVIDIA
Стек: Полная предустановка DGX OS + CUDA, NeMo, RAPIDS, поддержка PyTorch/Jupyter. Бесшовная интеграция с NGC-каталогом и облаком DGX .
Развертывание: Локальная тонкая настройка (fine-tuning) моделей до 70B параметров с последующим деплоем в дата-центр без переписывания кода .
Для разработчиков: Поддержка Windows через WSL2, что упрощает миграцию с ПК .
Orange Pi
ПО: Базовые образы Ubuntu/OpenEuler. Для работы AI требуется CANN-Toolkit (только через Docker), установка которого занимает 5–6 часов из-за зависимостей .
Поддерживаемые фреймворки: ONNX, TensorFlow, Caffe. Нет поддержки PyTorch напрямую! Экспорт LLM (например, Whisper) возможен только через ONNX с ручной конвертацией .
Сообщество: Документация – преимущественно на китайском. Англоязычные гайды фрагментарны, а на Reddit жалуются на сложность отладки .
Резюме: NVIDIA предлагает enterprise-решение «из коробки», Orange Pi требует экспертных знаний и времени для настройки.
---
3. Сценарии использования: Для кого эти устройства?
NVIDIA DGX Spark:
Исследователи: Локальный запуск Llama 3 70B или GPT-4-class моделей.
Корпорации: Разработка edge-приложений для робототехники (Isaac) или медвизуализации (Clara) с гарантией совместимости .
Стартапы: Прототипирование агентов ИИ с помощью NIM-микросервисов .
Orange Pi AI Studio Pro:
Энтузиасты: Эксперименты с компьютерным зрением (YOLO) на дешевом железе.
Нишевые проекты: Развертывание специфичных моделей (например, для обработки сенсорных данных), где не нужна интеграция с облаком.
Китайский рынок: Альтернатива Jetson Orin для вузов и госпредприятий .
---
4. Цена и Доступность
NVIDIA: От $3000, доступен с мая 2025 через партнеров (например, Dell, Supermicro) .
Orange Pi: Цена не объявлена, но аналоги (Atlas 200I DK) стоили ~$500. Ориентировочно Pro-версия – $700–$1000. Важно: нет глобальных поставок; покупка только через AliExpress .
Итоговая таблица сравнения
Критерий
NVIDIA DGX Spark
Orange Pi AI Studio Pro
----------------------------
------------------------------------------
--------------------------------------
Аппаратная мощность
1 PFLOPS (FP4), 128 ГБ RAM
352 TOPS (INT8), 192 ГБ RAM
Поддержка LLM
До 405B параметров (2 устройства)
До 70B (с оговорками)
Программная готовность
Полный стек AI Enterprise
Ручная настройка CANN-Toolkit
Экосистема
CUDA, PyTorch, облачная интеграция
ONNX/TensorFlow, изолированность
Целевая аудитория
Enterprise, исследователи
Энтузиасты, нишевые разработчики
Цена
От $3000
~$700–$1000 (оценка)
Заключение: Что выбрать?
NVIDIA DGX Spark – выбор для тех, кому нужен промышленный инструмент с минимумом настройки. Идеален для команд, внедряющих ИИ в продукты с последующим масштабированием. Демократизация без жертв .
Orange Pi AI Studio Pro – экспериментальная платформа для тех, кому важен TOPS/$ и кто готов бороться с китайской документацией. Подойдет для R&D в условиях санкционных ограничений или бюджетных проектов .
Тренд: Оба устройства подтверждают сдвиг ИИ в сторону edge-вычислений. Но если NVIDIA ведет к «персонализации суперкомпьютеров», то Orange Pi остается хардварным хаком для избранных. Ориентируйтесь на задачи: для стартапа или лаборатории – DGX Spark; для образовательных целей или кастомных задач – Orange Pi, если вы готовы к боли.
*«AI будет мейнстримом в каждом приложении для каждой индустрии»* (Дженсен Хуанг, NVIDIA ). В 2025 это звучит как констатация факта, а не прогноз.
Mira Pro Color – это первый цветной E Ink монитор от бренда ONYX BOOX. Он отлично подходит для работы с самыми разными текстами, а также со схемами, диаграммами и чертежами – в том числе и цветными, разумеется. При этом, правда, он не годится для работы с фотографиями и видео, так как его экран отображает только 4096 оттенков и является довольно медлительным (таковы, к сожалению, особенности E Ink дисплеев).
Почему стоит купить ONYX BOOX Mira Pro Color?
Главным доводом в пользу покупки ONYX BOOX Mira Pro Color является экран – даже несмотря на его недостатки, описанные выше. Дело в том, что он очень похож на лист бумаги и по этой причине не так утомляет глаза, как обычные светящиеся экраны. Кроме того, картинка на нём остаётся чёткой даже на ярком солнце, а при плохом освещении можно использовать встроенную подсветку без мерцания. Стоит отметить и высокое разрешение в режиме «16 оттенков серого» – 3200 на 1800 пикселей при диагонали 25,3” (разрешение в цветном режиме составляет 1600 на 900 пикселей).
Помимо этого, монитор ONYX BOOX Mira Pro Color примечателен возможностью регулировки не только угла наклона, но и высоты, а также возможностью поворота на 90 градусов. Есть здесь и крепление VESA 75, два динамика и порты USB-C, HDMI, mini HDMI и DisplayPort. В комплекте с монитором идут три кабеля и высококачественная подставка, которая выполнена из алюминия (как и сам монитор).
Под конец заметим, что ONYX BOOX Mira Pro Color можно использовать в паре с компьютерами на базе операционных систем Windows и macOS, а также с мобильными устройствами на базе операционных систем Android и iOS.
В чём заключается разница между Mira Pro Color и Mira Pro?
Эти модели идентичны по дизайну и габаритам, но снабжаются разными экранами. На ONYX BOOX Mira Pro Color установлен экран E Ink Kaleido 3, отображающий 4096 цветов, а на ONYX BOOX Mira Pro – экран E Ink Carta, отображающий 16 оттенков серого. Диагональ экрана в обоих случаях составляет 25,3“; разрешение в чёрно-белом режиме тоже одинаковое – 3200 на 1800 пикселей. Подсветка есть на обеих моделях, но при этом следует заметить, что ранее выпускалась версия Mira Pro без подсветки.
Вот обзор и рецензия на книгу «Масштабируемые данные от Gemini 2.5 Pro. Высоконагруженные архитектуры, Data Mesh и Data Fabric. 2-е изд.», основанные на информации об ее оригинальном издании “Data Management at Scale” за авторством Питхайна Стренгхолта.
Обзор и рецензия на книгу «Масштабируемые данные. 2-е изд.» Питхайна Стренгхолта
Эта книга является русским изданием работы Питхайна Стренгхолта “Data Management at Scale” и посвящена современным подходам к управлению данными в крупных организациях. Она фокусируется на архитектурных концепциях, таких как Data Mesh и Data Fabric, которые призваны решить проблемы традиционных монолитных систем, вроде централизованных озер и хранилищ данных.
О чем эта книга?
Основная идея, которую продвигает автор, заключается в переходе от централизованной модели управления данными к децентрализованной. Вместо того чтобы одна команда инженеров отвечала за все данные компании, Стренгхолт предлагает распределить ответственность между доменными командами (например, команда маркетинга, продаж, логистики).
Ключевые концепции, разбираемые в книге:
Децентрализация и Data Mesh: Книга подробно описывает архитектуру Data Mesh, впервые предложенную Жэмаком Дегани и популяризированную Мартином Фаулером. Этот подход рассматривает данные как продукт и передает владение ими командам, которые эти данные создают и лучше всего понимают https://medium.com/it-architecture/review-data-management-at-scale-fc52fda45e0b. При этом метаданные остаются централизованными, что позволяет другим командам легко находить, понимать и использовать нужные им данные.
Данные как продукт (Data as a Product): Это фундаментальный сдвиг в мышлении. Данные перестают быть побочным эффектом работы приложений и становятся полноценным продуктом со своим жизненным циклом, владельцем, стандартами качества и SLA. Доступ к таким продуктам данных обычно предоставляется через стандартизированные API https://www.linkedin.com/pulse/data-mesh-book-review-beyond-antti-pikkusaari.
Стратегический взгляд: Книга дает отличное высокоуровневое представление о том, как переосмыслить управление данными в масштабах всей организации. Она идеально подходит для архитекторов и руководителей, которым нужно понять «почему» и «что», а не «как» в деталях.
Актуальность: Концепции Data Mesh и Data Fabric находятся на пике популярности. Книга помогает систематизировать знания по этим темам и понять их философские основы.
Четкая аргументация: Автор убедительно доказывает, почему традиционные подходы к данным перестают работать при росте компании и увеличении сложности, и почему децентрализация ответственности является логичным шагом эволюции.
Критика и слабые стороны
Основная претензия, которую можно встретить в отзывах на оригинальное издание, — это высокий уровень абстракции и недостаток практических деталей реализации.
Нехватка технических деталей: Книга отлично объясняет принципы, но не углубляется в конкретные технологии и инструменты. Например, она говорит о необходимости API для доступа к данным, но не предлагает детальных руководств по их созданию или выбору технологий https://www.linkedin.com/pulse/data-mesh-book-review-beyond-antti-pikkusaari.
Полет в облаках: Один из рецензентов на Goodreads метко подмечает, что книга «предпочитает витать в облаках», не опускаясь на более низкий уровень для разъяснения тонкостей. Например, остается не до конца ясным, где проходит грань между данными, метаданными и кодом в рамках одного «продукта данных» data-management-at-scale.
Инженеру, который ищет пошаговое руководство по построению Data Mesh, эта книга может показаться слишком теоретической.
Кому стоит читать эту книгу?
Дата-архитекторам, CDO (Chief Data Officer) и руководителям отделов данных: Для них это мастрид. Книга поможет сформировать стратегическое видение и защитить новые подходы перед бизнесом.
Продукт-менеджерам и тимлидам: Поможет понять, как выстраивать процессы вокруг «данных как продукта» и эффективно взаимодействовать с другими командами.
Дата-инженерам и аналитикам: Будет полезна для понимания общей картины и современных трендов, но ее нужно будет дополнять более техническими статьями и докладами для практической реализации.
Заключение
«Масштабируемые данные» Питхайна Стренгхолта — это важный и своевременный труд, который предлагает стратегический взгляд на решение проблем управления данными в больших компаниях. Это не техническое руководство, а скорее манифест и философское обоснование для перехода к децентрализованным, продуктово-ориентированным архитектурам, таким как Data Mesh.
Книга блестяще отвечает на вопрос «Зачем?», но оставляет читателю самому искать ответ на вопрос «Как?». Если вы архитектор или менеджер, отвечающий за стратегию данных, эта книга станет для вас ценным источником идей. Если вы инженер, ищущий готовые рецепты, — будьте готовы к тому, что это лишь отправная точка для дальнейших исследований.
WAIC (World Artificial Intelligence Conference) — это крупнейшая международная конференция по искусственному интеллекту, проходящая в Китае. Её ключевые аспекты:
300 000 посетителей 😱 и 1300 спикеров 😱 https://www.worldaic.com.cn – программу не ищите, ее просто нет. еще.
Демонстрация прорывных технологий, включая робототехнику и Embodied AI (физические роботы, заменяющие людей в локальных сценариях). Например, на WAIC 2024 было представлено [более 50 роботов], многие из которых дебютировали именно здесь.
Участие ведущих компаний (включая Alibaba, SenseTime), даже тех, кто не специализируется исключительно на ИИ.
Глобальное управление ИИ:
Конференция служит площадкой для обсуждения этических норм и международного регулирования ИИ. В 2025 году запланирован [высокоуровневый саммит по глобальному управлению ИИ с участием политических деятелей (например, министра иностранных дел Китая Ван И).
Бизнес-экосистема:
Стартапы (например, SenseTime, разработчик систем распознавания лиц) привлекают многомиллионные инвестиции через WAIC.
Выставки и нетворкинг объединяют инвесторов, разработчиков и корпорации.
Тренды:
Акцент на практическом применении ИИ в промышленности, здравоохранении и повседневной жизни.
Рост темпов развития не только программных, но и аппаратных решений (роботы, сенсоры).
⚠️ Не путать с Western Association of Independent Camps WAIC https://www.waic.org — это отдельная организация, не связанная с ИИ.
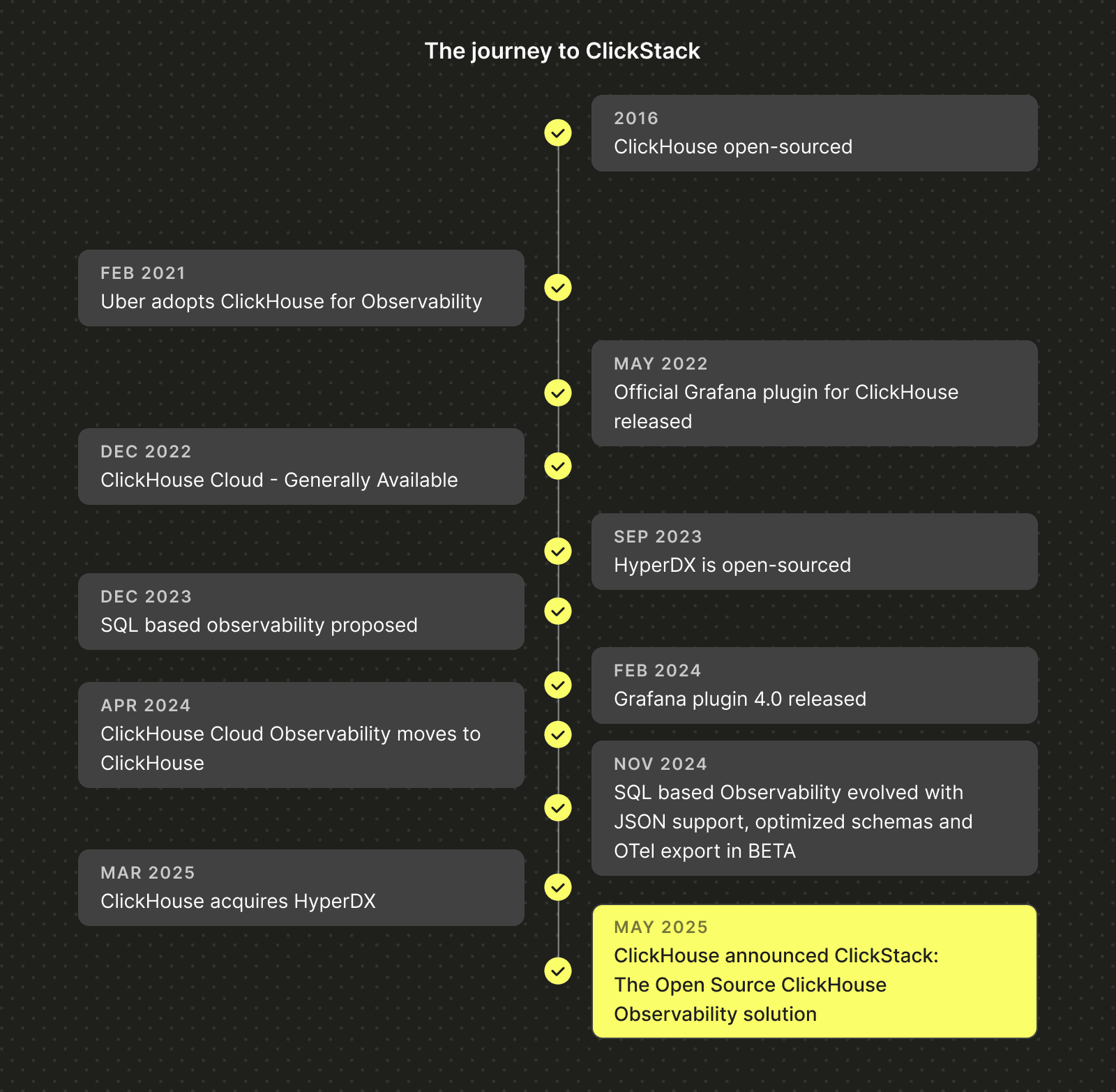
Сегодня мы рады анонсировать ClickStack — новое опенсорсное решение для обсервабилити, созданное на базе ClickHouse. ClickStack предоставляет полноценное решение «из коробки» для работы с логами, метриками, трейсами и воспроизведением сессий. Оно работает на основе производительности и эффективности ClickHouse, но спроектировано как полноценный стек для обсервабилити — открытый, доступный и готовый для всех.
В течение многих лет крупные инженерные команды, такие как в Netflix и eBay, выбирали ClickHouse в качестве основной базы данных для обсервабилити. Её колоночная структура, сжатие и высокопроизводительный векторизованный движок запросов сделали её идеальной для хранения «широких событий» — записей с богатым контекстом и высокой кардинальностью, которые объединяют логи, метрики и трейсы. Этот современный подход к обсервабилити (некоторые называют его «Observability 2.0») отходит от традиционной модели «трёх столпов» и устраняет сложность объединения разрозненных источников телеметрии.
До сих пор все преимущества этой модели были в основном доступны только командам, обладавшим ресурсами для создания специализированных решений для обсервабилити на базе ClickHouse. А все остальные? Они полагались на универсальные инструменты визуализации или сторонние проприетарные платформы, созданные на ClickHouse. Хотя эти инструменты предоставляли базовые интерфейсы для ClickHouse, они иногда требовали длинных SQL-запросов для рутинных задач обсервабилити или не в полной мере использовали производительность и открытую архитектуру ClickHouse.
Сегодня всё меняется. С выпуском ClickStack на базе HyperDX мы уравниваем шансы. Этот полностью опенсорсный стек включает в себя готовый коллектор OpenTelemetry, пользовательский интерфейс, разработанный для «широких событий», запросы на естественном языке, воспроизведение сессий, оповещения и многое другое.
И всё это работает на том же высокопроизводительном движке ClickHouse с высоким уровнем сжатия, которому доверяют крупнейшие имена в сфере обсервабилити.
Раньше командам часто приходилось выбирать между дорогими проприетарными SaaS-продуктами и сборкой собственных решений из опенсорсных альтернатив. Поисковые движки предлагали быстрые и гибкие запросы, но их эксплуатация в больших масштабах и достижение высокой производительности агрегации оказывались сложными. Хранилища метрик обеспечивали лучшую производительность агрегации, но требовали жёсткой предварительной агрегации и не имели возможностей для глубокого поиска. Ни один из подходов не справлялся хорошо с данными высокой кардинальности, а их объединение добавляло сложности, не решая основной проблемы.
С ClickStack вам не придётся выбирать — наслаждайтесь быстрым поиском и быстрыми агрегациями по данным высокой кардинальности в формате «широких событий». В больших масштабах. С открытым исходным кодом. И теперь — для всех.
Эволюция ClickHouse для обсервабилити
Всего лишь очередная задача по работе с данными
Первые пользователи ClickHouse осознали нечто фундаментальное: обсервабилити — это задача по работе с данными. Выбранная вами база данных определяет стоимость, масштабируемость и возможности вашей платформы для обсервабилити, поэтому её выбор часто является самым важным архитектурным решением при создании собственного решения или запуске компании в этой сфере.
Именно поэтому ClickHouse уже много лет находится в основе стеков обсервабилити. От отраслевых гигантов, таких как Netflix и eBay, до стартапов в сфере обсервабилити, таких как Sentry и Dash0, ClickHouse обеспечивает работу с логами, метриками и трейсами в огромных масштабах. Её колоночное хранилище, агрессивное сжатие и векторизованный движок выполнения запросов значительно снижают затраты и обеспечивают выполнение запросов за доли секунды, что необходимо инженерам для отладки систем в реальном времени без ожидания медленных инструментов.
Всё, что вам нужно, — это «широкие события»… и колоночное хранилище
В нашей предыдущей статье «Состояние обсервабилити на основе SQL» и последующих публикациях мы подробно исследовали этот тренд. Хотя тогда мы не дали ему названия, он идеально совпадает с сегодняшним движением «Observability 2.0»: единая модель, построенная вокруг «широких событий», а не «столпов». Слишком долго команды полагались на отдельные хранилища для логов, метрик и трейсов, что приводило к фрагментации, ручной корреляции и ненужной сложности. «Широкие события» устраняют эти разрозненные хранилища, объединяя все сигналы обсервабилити в единую, запрашиваемую структуру.
«Широкое событие» фиксирует полный контекст приложения в одной записи — пользователя, сервис, HTTP-путь, код состояния, результат кеширования и многое другое. Эта унифицированная структура является ключом к устранению разрозненности и обеспечению быстрого поиска и агрегации по данным высокой кардинальности — при условии, что у вас есть движок хранения, способный эффективно их сжимать и хранить!
Хотя NoSQL-решения, такие как поисковые движки, приняли эту структуру, им не хватало производительности агрегации, чтобы реализовать её потенциал — они отлично подходили для поиска и «нахождения иголок в галактиках», но не для агрегации по широким диапазонам. Секретный ингредиент ClickHouse для решения этой проблемы остаётся неизменным: колоночное хранение, богатая библиотека кодеков для глубокого сжатия и массивно-параллельный движок, оптимизированный для аналитических нагрузок.
Эффективность ресурсов и масштабируемость
В ClickHouse Cloud мы пошли дальше и внедрили объектное хранилище, чтобы обеспечить разделение хранения и вычислений, что крайне важно, если вам нужно масштабировать вашу систему обсервабилити до петабайт и более, а также эластично масштабироваться. Для поддержки ещё более требовательных сценариев мы также ввели разделение вычислений, позволяя пользователям выделять вычислительные ресурсы для конкретных нагрузок (например, для приёма данных и для выполнения запросов), читая при этом одни и те же данные.
По мере усложнения потребностей в обсервабилити мы поняли, что нативная поддержка JSON для полуструктурированных событий стала необходимым минимумом. ClickHouse развивался, чтобы удовлетворить эту потребность, добавив первоклассную поддержку полуструктурированных данных, сохраняя при этом преимущества колоночной обработки. Колонки создаются автоматически по мере поступления данных, и ClickHouse автоматически управляет повышением типов и ростом колонок. Это та самая «схема при записи» (schema-on-write), которая вам нужна для обсервабилити, с производительностью, сжатием и гибкостью, ожидаемыми от современного аналитического движка.
Рост популярности OpenTelemetry
Эта эволюция совпала с ростом популярности OpenTelemetry (OTel), который сейчас является стандартом де-факто для сбора телеметрии, включая логи, метрики и трейсы. Мы начали официально поддерживать и вносить вклад в OpenTelemetry Exporter для ClickHouse.
OpenTelemetry стал большим прорывом для нашей экосистемы. Он предлагает стандартизированный, независимый от поставщика способ сбора и экспорта данных обсервабилити, а его коллектор можно настроить для отправки данных напрямую в ClickHouse с помощью экспортёра, который мы теперь помогаем поддерживать. Мы тесно сотрудничали с сообществом, чтобы убедиться, что экспортёр надёжен, масштабируем и соответствует основным принципам ClickHouse.
Одной из самых сложных проблем, которую мы решили на раннем этапе, был дизайн схемы. Не существует универсальной схемы для обсервабилити; у каждой команды свои паттерны запросов, потребности в хранении и архитектуры сервисов. Поэтому экспортёр поставляется со схемами по умолчанию для логов, метрик и трейсов, которые хорошо подходят большинству пользователей, но мы призываем команды настраивать их в соответствии со своими собственными нагрузками.
Недостающие элементы
Но, как мы быстро поняли, просто иметь отличную базу данных, хорошую схему и надёжные средства сбора и приёма данных недостаточно. Инженерам нужен готовый к использованию приём данных, визуализация, оповещения и пользовательский интерфейс, адаптированный под их рабочий процесс. До сих пор это означало использование OpenTelemetry для сбора и Grafana для дашбордов.
Это работало достаточно хорошо — даже наша собственная команда по обсервабилити заменила Datadog стеком на базе ClickHouse, сэкономив миллионы и добившись снижения затрат более чем в 200 раз. Сегодня наша внутренняя система логирования хранит более 43 петабайт данных OpenTelemetry, со схемами и первичными ключами, настроенными специально для такого масштаба. Это доказало производительность и экономическую эффективность подхода, но мы знали, что опыт может быть проще.
Мы хотели чего-то более продуманного. Более простого способа для начала работы. Но самое главное — интерфейс, созданный для ClickHouse. И не просто любой интерфейс, а тот, который понимает, как строить эффективные запросы, выявлять паттерны в «широких событиях» и обеспечивать исключительный пользовательский опыт, не скрывая при этом мощь базы данных.
Наконец, хотя мы считаем, что обсервабилити на основе SQL сыграла важную роль в укреплении модели «широких событий», мы также понимали, что должны пойти навстречу пользователям. Поисковые движки, такие как стек ELK, добились успеха, потому что они предлагали нечто интуитивно понятное: естественный язык для запроса логов. Мы хотели предоставить такой же опыт нашим пользователям, но на базе ClickHouse.
Добро пожаловать, HyperDX
Именно тогда мы нашли HyperDX — опенсорсный слой для обсервабилити, специально созданный на ClickHouse. Когда HyperDX открыл исходный код своего интерфейса v2 в конце 2024 года, мы протестировали его внутри компании и быстро поняли, что это и есть недостающий элемент. Настройка была бесшовной, опыт разработчика — превосходным, и мы знали, что наши пользователи заслуживают того же.
Сбор данных на основе стандартов:** HyperDX с самого начала использовал OpenTelemetry, что идеально совпало с нашими инвестициями в экспортёр OpenTelemetry для ClickHouse.
Опенсорс в первую очередь:** Мы считаем, что надёжные инструменты для обсервабилити должны быть доступны всем, и HyperDX разделяет эту философию. Его облачно-нативная архитектура обеспечивает простую и экономичную эксплуатацию.
Помимо соответствия стандартам, HyperDX создан с учётом особенностей ClickHouse. Команда серьёзно относится к оптимизации запросов, так что вам не придётся об этом думать. Пользовательский интерфейс тесно связан с движком, обеспечивая быструю и надёжную производительность там, где миллисекунды имеют значение, особенно во время расследования инцидентов.
В сочетании со встроенным шлюзом для коллектора OpenTelemetry и схемой, оптимизированной для интерфейса HyperDX, ClickStack объединяет приём, хранение и визуализацию данных в единое решение. Схема по умолчанию спроектирована так, чтобы работать «из коробки», поэтому пользователям не нужно о ней думать — если только они не захотят настроить её под свои конкретные нужды.
Простота ClickStack означает, что каждый слой масштабируется независимо. Нужна более высокая пропускная способность приёма данных? Просто добавьте больше шлюзов коллектора OpenTelemetry. Нужно больше ресурсов для запросов или хранения? Масштабируйте ClickHouse напрямую. Эта модульная конструкция позволяет легко расти вместе с вашими данными и вашей командой — без полной перестройки стека.
С момента приобретения HyperDX мы сосредоточились на упрощении продукта и расширении его гибкости. Вы можете использовать схему по умолчанию для бесшовной настройки «из коробки» или использовать собственную схему, адаптированную под ваши нужды. Как и в случае с самим ClickHouse, мы понимаем, что универсального решения не существует, и гибкость — ключ к масштабированию.
В то же время мы остались верны своим SQL-корням. SQL остаётся универсальным языком данных, и для многих опытных пользователей ClickHouse это по-прежнему самый выразительный и эффективный способ исследования данных. Именно поэтому интерфейс HyperDX включает поддержку нативных SQL-запросов, предоставляя продвинутым пользователям прямой доступ к движку без компромиссов.
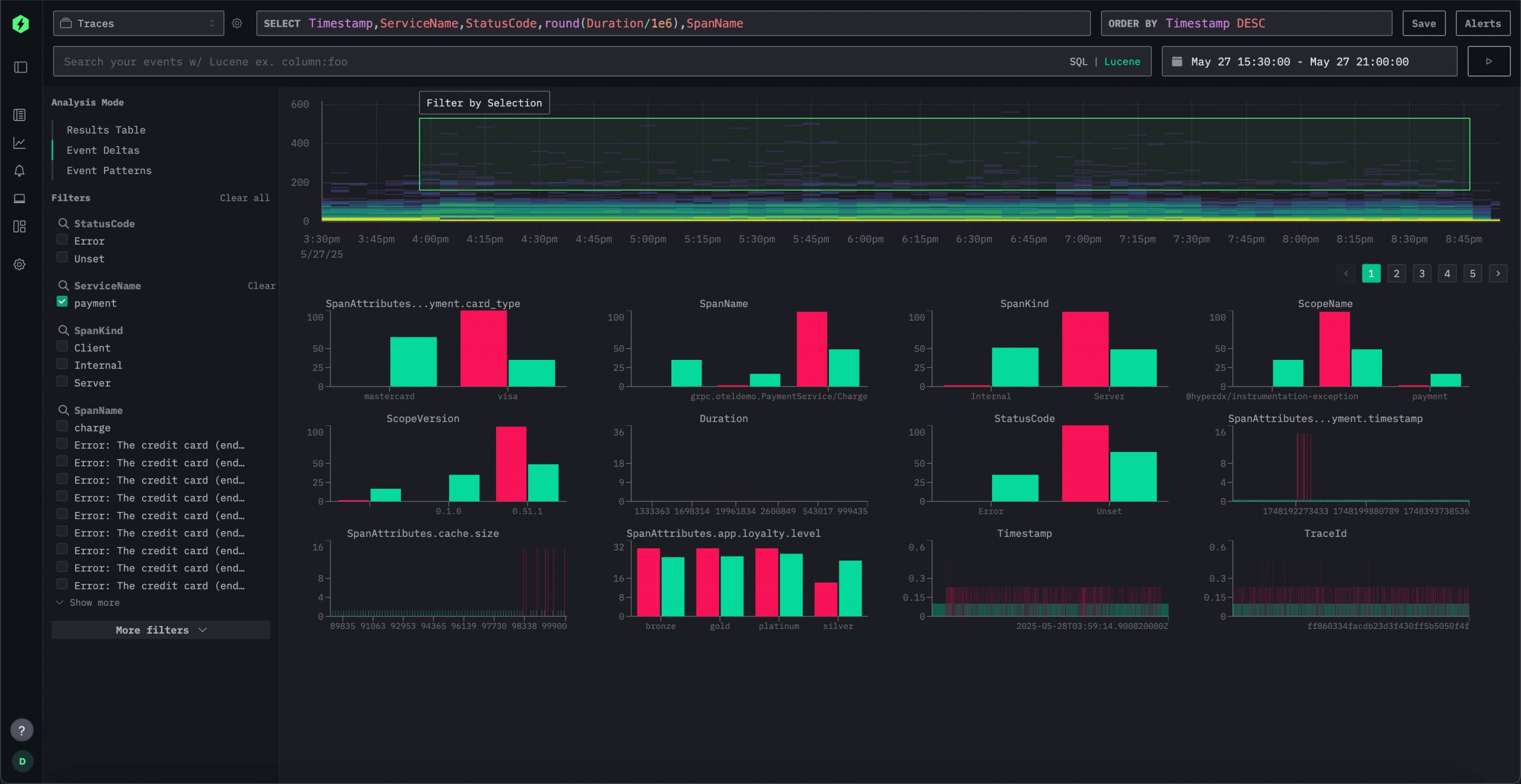
Мы также добавили новые функции для облегчения отладки и исследования. Одним из примеров являются дельты событий, которые помогают пользователям быстро выявлять аномалии и регрессии производительности. Сэмплируя данные по уникальным значениям заданного атрибута, интерфейс выявляет различия в производительности и отклонения, облегчая понимание того, что изменилось и почему.
Возможно, самое важное — стек стал проще. С утверждением OpenTelemetry в качестве повсеместного стандарта все данные теперь поступают через OTel-коллектор. Настройка по умолчанию использует продуманную схему для быстрого старта, но пользователи могут изменять или расширять её по мере необходимости. Стек является нативным для OpenTelemetry, но не эксклюзивным для него: благодаря открытой схеме HyperDX может работать и с вашими существующими пайплайнами данных и схемами.
Заключение и взгляд в будущее
ClickStack представляет собой следующий этап развития инвестиций ClickHouse в экосистему обсервабилити, предлагая интуитивно понятное и продуманное полностековое решение на базе открытого исходного кода и открытых стандартов. Объединяя высокопроизводительный колоночный движок ClickHouse, стандарты инструментирования OpenTelemetry и специализированный интерфейс HyperDX в единое решение, мы наконец делаем современный подход к обсервабилити доступным для всех.
Наша приверженность открытому исходному коду гарантирует, что ClickStack останется доступным для всех — от развёртываний с одним сервисом до систем объёмом в несколько петабайт. Мы продолжим инвестировать как в ядро базы данных для высокопроизводительной обсервабилити, так и в интеграции с уже зарекомендовавшими себя инструментами, такими как Grafana, обеспечивая бесшовную совместимость с существующими стеками.
С ClickStack мы предлагаем больше, чем просто очередной инструмент — мы предоставляем единую основу, где все телеметрические сигналы сходятся в высокопроизводительной колоночной базе данных, дополненной запросами на естественном языке, воспроизведением сессий и возможностями оповещения прямо «из коробки».
Начните свой путь с ClickStack, ознакомившись с нашим руководством по началу работы в документации.
Начните работать с ClickHouse Cloud сегодня и получите $300 в виде кредитов. По окончании 30-дневного пробного периода вы можете продолжить работу по плану с оплатой по мере использования или связаться с нами, чтобы узнать больше о наших скидках за объём. Посетите нашу страницу с ценами для получения подробной информации.
----
Что предлагается?
Высокопроизводительный опенсорсный стек для обсервабилити
Молниеносные запросы и мощные агрегации по логам, метрикам, трейсам, воспроизведениям сессий и ошибкам с непревзойденной эффективностью использования ресурсов даже для данных с самой высокой кардинальностью. Всё в одном стеке — на базе ClickHouse.
---
Поиск, дашборды и оповещения
ClickStack объединяет логи, метрики, трейсы и воспроизведение сессий на одной платформе с помощью интерфейса HyperDX. Оптимизированный для ClickHouse, он поддерживает быстрый поиск в стиле Lucene и полный доступ по SQL для углубленного анализа с использованием более 100 встроенных функций.
Создавайте дашборды и оповещения с минимальной настройкой. Выявляйте аномалии с помощью дельт событий и ускоряйте анализ первопричин, используя паттерны событий.
Хранилище на базе ClickHouse
Работая на базе ClickHouse, HyperDX выполняет поиск по терабайтам данных за секунды и ежедневно принимает миллиарды событий высокой кардинальности. ClickStack поставляется с оптимизированными схемами, что устраняет необходимость в ручной настройке и позволяет вам сосредоточиться на получении инсайтов.
В ClickHouse Cloud ClickStack получает эластичное масштабирование и экономическую эффективность благодаря полному разделению хранения и вычислений. Приём данных и запросы могут выполняться независимо на выделенных ресурсах благодаря разделению между вычислительными мощностями, что обеспечивает стабильную производительность при любом масштабе.
Сбор данных
ClickStack нативно поддерживает стандарт OpenTelemetry, собирая логи, метрики и трейсы в виде «широких событий» — записей с богатым контекстом, которые объединяют данные обсервабилити в ClickHouse.
Благодаря нативной поддержке JSON, ClickHouse эффективно обрабатывает развивающиеся, полуструктурированные данные. Поля создаются автоматически при приёме данных, а сжатое колоночное хранилище обеспечивает быстрые запросы и высокую степень сжатия без необходимости предварительного определения схемы.
---
Хотите собрать свой собственный стек?
Нужен собственный пайплайн или схема? Интерфейс HyperDX не зависит от схемы и работает с любым пайплайном телеметрии, подключаясь к любому экземпляру ClickHouse для полного контроля над вашими данными обсервабилити.
Создаёте свой собственный стек? ClickHouse предоставляет все необходимые инструменты: высокопроизводительный движок SQL, приём данных по HTTP, масштабируемое хранилище MergeTree и материализованные представления для трансформации данных в реальном времени. Для гибкой работы с дашбордами используйте плагин для Grafana, чтобы сопоставлять данные из ClickHouse с другими источниками.
---
Снизьте ваши затраты на обсервабилити
ClickHouse обеспечивает исключительную экономическую эффективность, избегая накладных расходов систем на базе JVM, благодаря аппаратно-оптимизированной колоночной структуре, которая сокращает объём хранения до 90% без ущерба для скорости.
Бесшовное масштабирование от одной машины до сотен ядер, с автоматическим ярусным хранением данных между локальными дисками и объектным хранилищем для максимальной производительности и эффективности.
✨ Простое развертывание и обслуживание
Оцените простоту эксплуатации благодаря однородной архитектуре ClickHouse — один исполняемый файл справляется со всем, от автономных развертываний до огромных кластеров.
Для нулевых накладных расходов выберите ClickStack в ClickHouse Cloud для автоматического масштабирования, резервного копирования и обслуживания. Разделение хранения и вычислений обеспечивает как бесконечную масштабируемость, так и производительность запросов менее чем за секунду благодаря интеллектуальному кэшированию.
📄 Откройте для себя обсервабилити в реальном времени
ClickHouse спроектирован для обработки огромных объёмов непрерывных потоков входящих данных, поддерживая скорость приёма данных в гигабайты в секунду, при этом обеспечивая доступность новых данных для поиска с задержкой менее секунды.
Созданный для самых интенсивных нагрузок в реальном времени, HyperDX использует мощный набор функций агрегации и анализа ClickHouse с глубокими оптимизациями для обеспечения молниеносных запросов в системе обсервабилити.
💡 Не только для обсервабилити
ClickHouse — это не просто хранилище для обсервабилити, это высокопроизводительная SQL база данных, созданная для быстрой аналитики.
Обсервабилити — это просто еще одна задача по работе с данными, и с ClickHouse вы можете бесшовно объединять данные обсервабилити, бизнес-данные и данные безопасности в одной системе, получая более глубокие инсайты по всему вашему стеку с помощью вашего любимого инструмента визуализации.
Инструментируйте ваши приложения
Отслеживайте каждый лог, API-запрос, запрос к БД и многое другое всего несколькими строками кода. Инструментируйте и наблюдайте за своим стеком за считанные минуты с ClickStack.
Большой процент так называемых экспертов сегодня умеет только настраивать инструменты, но ничего не понимает о том, как вещи работают на более глубоком уровне. Это настоящий вызов и большая проблема для будущего.
Рулевое колесо — это абстракция, которая облегчает мне вождение автомобиля. Усилитель руля — это еще один уровень абстракции, который еще больше улучшает опыт вождения. Абстракции хороши, они, как правило, улучшают качество жизни. Однако в Дании есть поговорка:
Слишком мало и слишком много всё портит.
Какая польза от абстракции, когда она ломается и никто больше не понимает, как работает технология “под капотом”?
Вся технологическая индустрия движима очень жестким стремлением к прибыли и очень малым интересом к чему-либо еще. Поэтому вам нужно иметь возможность выпускать новые продукты или новые услуги как можно быстрее. Это означает больше абстракций и больше автоматизации, всё меньше и меньше людей и всё меньше глубокого понимания.
Сегодня программистов и системных администраторов больше не существует, вместо них у нас есть DevOps и даже DevSecOps, в которых индустрия очень старательно пытается втиснуть каждую отдельную задачу в должностную инструкцию одного человека. Специалисты по технологиям должны выполнять разработку (Dev), безопасность (Sec) и операции (Ops), то есть системное администрирование, но поскольку ни один человек не может по-настоящему освоить все это, нам нужно автоматизировать как можно больше, чтобы сэкономить деньги и избежать сложностей человеческого социального взаимодействия между различными техническими отделами. В результате современному специалисту по технологиям enseñan только тому, как использовать конкретные инструменты, и он или она очень мало знает о технологии “под капотом”.
Не помогает и то, что технологии стало всё труднее понимать, но всё больше и больше современной жизни сильно зависит от используемых нами технологий. Так что же произойдет, когда уровень понимания в технологической индустрии достигнет такой низкой точки, при которой большинство людей даже не будут знать, как починить инструменты, которыми они пользуются?
Люди привыкли к состоянию абстракции и считают, что это правильный подход, и с радостью способствуют беспорядку, добавляя еще больше абстракции.
Да, давайте все вернемся к кодированию на ассемблере!
— Саркастический комментарий высокомерного разработчика
Нам нужны абстракции, в этом нет сомнений, но каждый уровень абстракции обходится дорогой ценой, которая, как ни иронично, в конечном итоге может привести к огромным потерям прибыли.
Современное программирование пугает меня во многих отношениях, когда они просто строят слой за слоем, который ничего не делает, кроме перевода.
— Кен Томпсон
Уже сейчас большинство “специалистов по безопасности” очень мало знают о безопасности и только о том, как использовать какой-то готовый инструмент для тестирования на проникновение. Инструмент для тестирования на проникновение показывает кучу зеленых лампочек на своей веб-панели, и все считается в порядке. Тем не менее, настоящий эксперт по безопасности со злыми намерениями давно взломал систему и продолжает продавать ценные данные в даркнете. Ничего не утекло и ничего не обнаружено. Это может продолжаться годами, никто ничего не узнает, потому что, ну, на панели GUI написано, что все в порядке.
Некоторые студенты сегодня, по-видимому, даже не знают, что такое файлы и папки.
Советы изучающим технологии:
Никогда не следуйте за хайпом или трендами.
Будьте любопытны. Не просто изучайте инструменты, старайтесь понять, как работает базовая технология.
Если возможно, попробуйте хотя бы один раз вручную сделать то, что, например, делает для вас инструмент конфигурации.
Если возможно, попробуйте посмотреть код инструмента. Даже базовое понимание кода может быть очень ценным.
Сохраняйте любопытство. Продолжайте учиться. Экспериментируйте. Погружайтесь глубже в интересующие вас технологии. Если возможно, создайте домашнюю лабораторию и используйте ее как игровую площадку для обучения и слома вещей.
Ставьте под сомнение все. Особенно то, что вам кажется бессмысленным. Не думайте, что кто-то знает лучше — так вы быстро превратитесь в слепого последователя. Иногда кто-то действительно знает лучше, но не делайте такого вывода по умолчанию. И будьте смелыми! Стойте на стороне правды и своих убеждений, даже если это заставляет вас чувствовать себя одиноким.
Люди слепо следуют друг за другом.
Смысл, который я закладываю в этот пост, не в том, что все должно быть понято всеми с первых принципов, или что вы не должны использовать никакие инструменты. Как я уже сказал, нам нужны абстракции. Кроме того, у нас есть люди, которые специализируются в разных областях, так что, например, механик чинит грузовик, а водитель водит грузовик.
Скорее, я затрагиваю важную ценность инженерного отношения к технологиям у людей, работающих с технологиями.
В, например, разработке программного обеспечения слишком многие специалисты были абстрагированы и заменены инструментами и автоматизацией, и все меньше и меньше людей понимают что-либо даже на один уровень ниже того слоя, на котором они работают.
Это большая проблема, потому что в конечном итоге мы достигнем точки, когда очень немногие смогут что-либо исправить на нижних уровнях. И дело в том, что мы уже частично достигли этой точки!
Примерно полгода назад я наткнулся на несколько фронтенд-веб-разработчиков, которые не знали, что веб-сайт можно создать без инструмента развертывания и что JavaScript вообще не нужен, даже если веб-сайт принимает платежи. Я спросил об этом своего друга, который в то время преподавал программирование на Python, и он сказал:
Не удивляйтесь этому. Это нынешний уровень. Индустрия хочет, чтобы мы массово производили людей, которые умеют "нажимать кнопки", а не людей, которые понимают что-то на более глубоком уровне.
Я знаю, что всегда найдутся люди, которые будут интересоваться более глубокими уровнями, дело не в этом. Дело в том, что именно в разработке программного обеспечения мы давно достигли точки, когда добавили слишком много слоев абстракции, и слишком мало людей понимают, что они делают. Индустрия стреляет себе в ногу.
Если, например, я веб-разработчик, будь то фронтенд или бэкенд, или занимаюсь так называемой “интеграционной работой” и создаю веб-сайты без особого кодирования или каких-либо знаний о TCP/IP, DNS, HTTP, TLS, безопасности и т. д., используя только готовые инструменты или фреймворки, то это сделает меня примерно таким же полезным, как обезьяна с динамометрическим ключом, когда что-то пойдет не так.
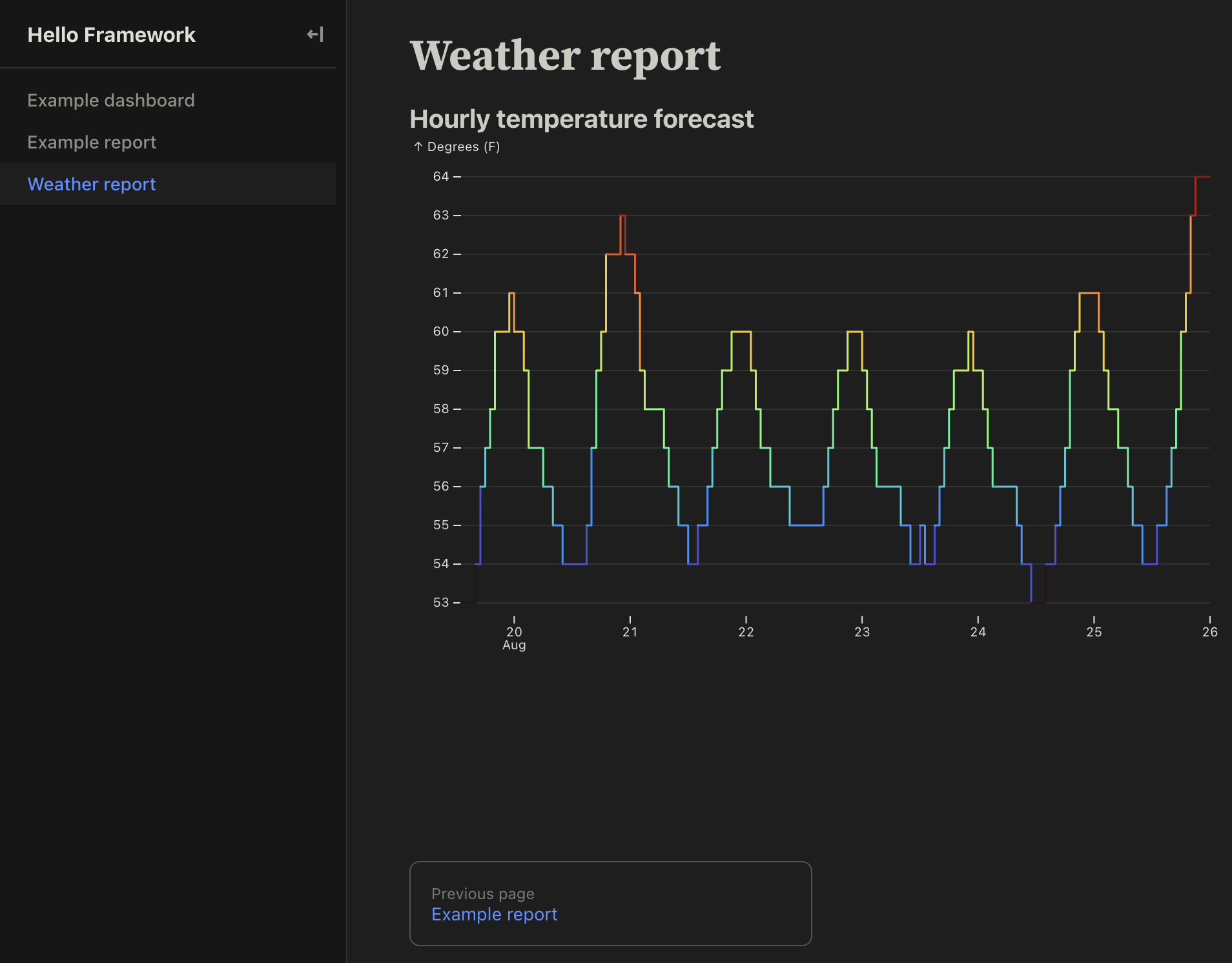
Сравнение самых популярных BI-as-code инструментов: Evidence, Streamlit, Dash, Observable, Shiny и Quarto
Кейси Хуанси Ли – Приглашенный Автор 30 октября 2024 г. · 4 мин чтения
Кейси – специалист по данным, инженер-программист и писатель. Ранее она работала в McKinsey & QuantumBlack, а в настоящее время работает в Shopify.
Не существует единственного «лучшего» инструмента бизнес-аналитики (BI); лучший инструмент для вас зависит от ваших конкретных потребностей, рабочего процесса и набора навыков.
Это руководство сравнивает некоторые из самых популярных инструментов BI-as-code, чтобы помочь вам найти то, что наилучшим образом подходит для вашего стека анализа данных и технических компетенций:
* Evidence: Конструктор приложений на Markdown и SQL для аналитиков данных.
* Streamlit: Оболочка для веб-приложений для Python-специалистов по данным.
* Dash: Фреймворк для веб-приложений для Python-разработчиков.
* Observable: Набор инструментов для визуализации данных для JavaScript-разработчиков.
* Shiny: Простая R/Python-оболочка для статистиков и исследователей.
* Quarto: Минималистичная система публикации Jupyter/Markdown для ученых и технических писателей.
Каждый из этих инструментов является открытым исходным кодом, и вы можете найти исходный код на GitHub.
Инструмент
Репозиторий GitHub
Лицензия
Языки
Звезды
Evidence
evidence-dev/evidence
MIT
SQL/Markdown
4.3k
Streamlit
streamlit/streamlit
Apache 2.0
Python
35k
Dash
plotly/dash
MIT
Python
21k
Observable
observablehq/framework
ISC
JavaScript
2.5k
Shiny
rstudio/shiny
GPL-3.0
R/Python
5.4k
Quarto
quarto-dev/quarto-cli
MIT
Markdown/Jupyter
3.9k
Evidence
Инструмент для создания приложений на SQL и Markdown
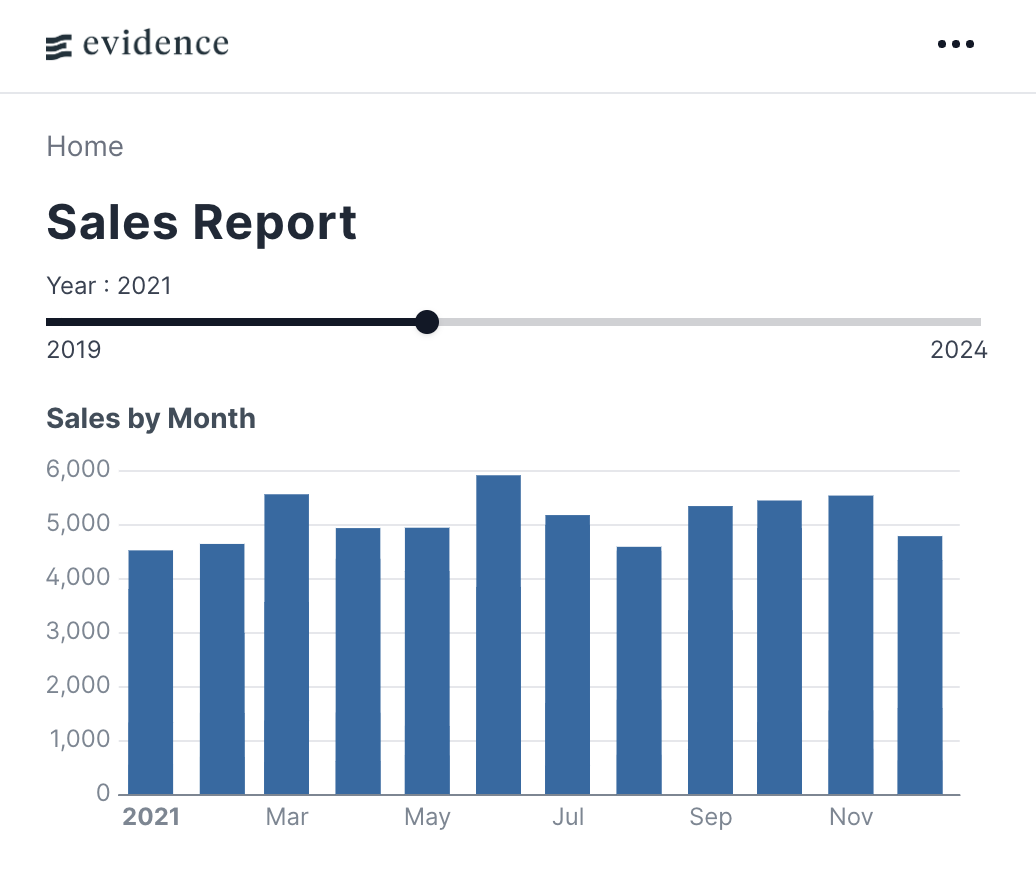
Evidence выделяется своим управлением входными данными через SQL-запросы и созданием содержимого страниц с помощью Markdown и предварительно созданных компонентов.
Входные данные в Evidence управляются с помощью SQL-запросов. Содержимое страницы создается с помощью Markdown и предварительно созданных компонентов Evidence для общих визуализаций, таких как таблицы или столбчатые диаграммы.
Evidence разработан для аналитиков, знакомых с SQL и Markdown, предлагая расширяемость через веб-стандарты. Приложения Evidence отлаженные, производительные и легко воспринимаются бизнес-стейкхолдерами.
Evidence также предлагает неограниченные возможности для определения ваших собственных пользовательских компонентов с использованием HTML и JavaScript, а также стилизации страниц через CSS. Он также поддерживает постоянно растущий список вариантов развертывания, включая Evidence Cloud — безопасный, управляемый хостинг-сервис.
Пример кода:
# Sales Report
<Slider min=2019 max=2024 name=year_pick title=Year size=full/>
```sql sales_by_month
SELECT
order_month,
category,
sum(sales) AS sales
FROM orders
WHERE year = '${inputs.year_pick}'
GROUP BY ALL
```
<BarChart
data={sales_by_month}
title="Sales by Month"
x=order_month
y=sales
/>
Хороший выбор, если:
Вы в основном работаете с SQL и хотите получать удобные для бизнеса результаты.
Вы не являетесь в первую очередь JavaScript-разработчиком.
Вы хотите иметь возможность добавлять пользовательские компоненты, если ваши потребности выходят за рамки готовой функциональности.
Не рекомендуется, если:
Вы не хотите использовать SQL-запросы для управления входными данными.
---
Streamlit
Веб-приложение-обертка для pandas, numpy и других основных инструментов Python для анализа данных
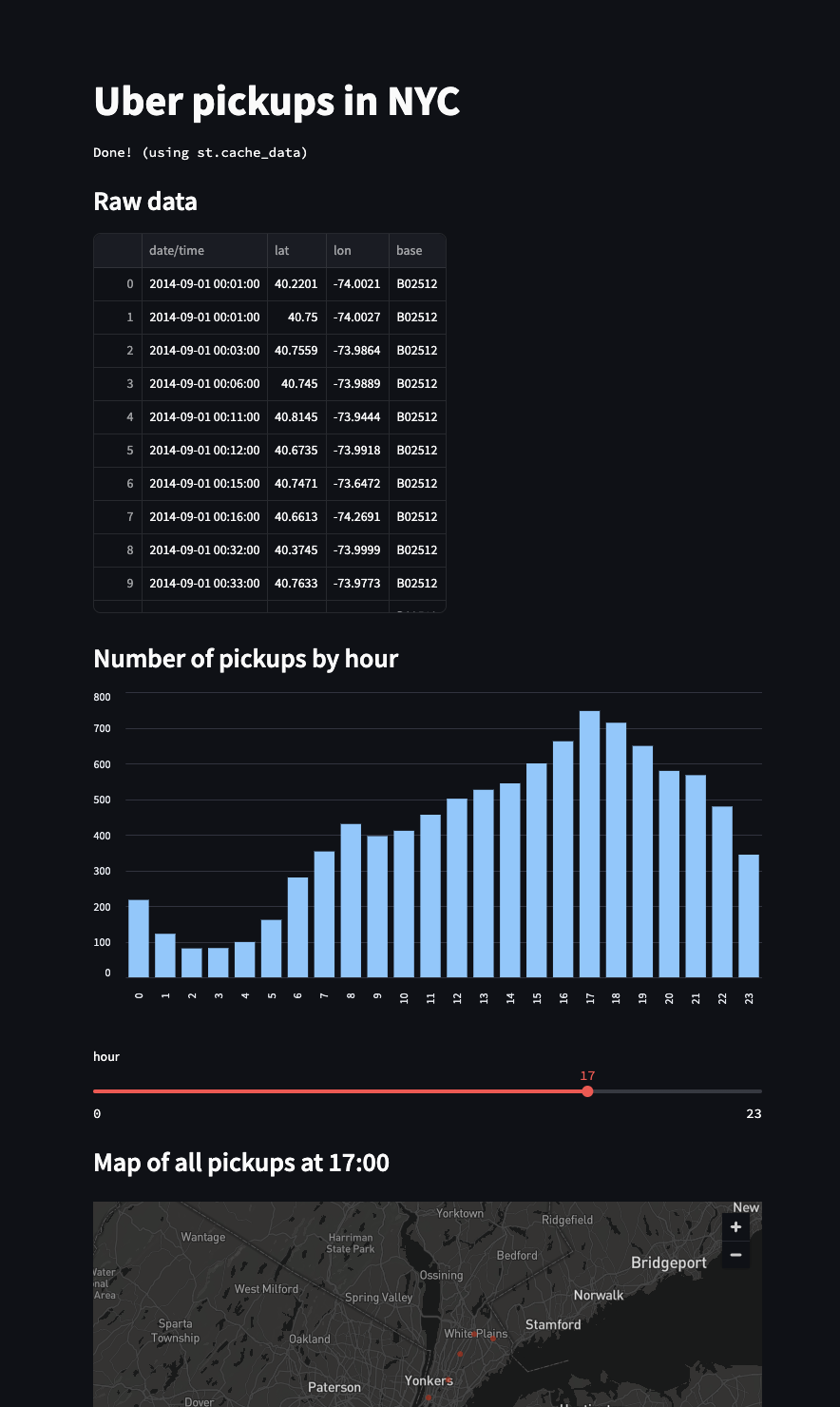
Если вы уже знакомы с такими вещами, как numpy или pandas, документация Streamlit заставит вас почувствовать себя как дома. Оборачивая, например, `np.histogram` во что-то вроде `st.bar_chart`, Streamlit берет на себя перевод вашего Python-кода в веб-приложение.
Streamlit запускает ваш Python-скрипт сверху вниз, передавая выходные данные, такие как текст, таблицы или диаграммы, на страницу. Этот инструмент также можно использовать для создания чат-бота в стиле ChatGPT с использованием выходных данных на основе Python.
Пример кода:
import streamlit as st
import pandas as pd
import numpy as np
st.title('Uber pickups in NYC')
DATE_COLUMN = 'date/time'
DATA_URL = ('https://s3-us-west-2.amazonaws.com/'
'streamlit-demo-data/uber-raw-data-sep14.csv.gz')
@st.cache_data
def load_data(nrows):
data = pd.read_csv(DATA_URL, nrows=nrows)
lowercase = lambda x: str(x).lower()
data.rename(lowercase, axis='columns', inplace=True)
data[DATE_COLUMN] = pd.to_datetime(data[DATE_COLUMN])
return data
# Create a text element and let the reader know the data is loading.
data_load_state = st.text('Loading data...')
# Load 10,000 rows of data into the dataframe.
data = load_data(10000)
# Notify the reader that the data was successfully loaded.
data_load_state.text("Done! (using st.cache_data)")
st.subheader('Raw data')
st.write(data)
st.subheader('Number of pickups by hour')
hist_values = np.histogram(
data[DATE_COLUMN].dt.hour, bins=24, range=(0,24))[0]
st.bar_chart(hist_values)
hour_to_filter = st.slider('hour', 0, 23, 17) # min: 0h, max: 23h, default: 17h
filtered_data = data[data[DATE_COLUMN].dt.hour == hour_to_filter]
st.subheader(f'Map of all pickups at {hour_to_filter}:00')
st.map(filtered_data)
Хороший выбор, если:
Вы являетесь Python-специалистом по данным, который хочет быстро создать веб-приложение, которым можно поделиться.
Не рекомендуется, если:
Вам нужно настроить UI/UX, выходя за рамки базовых цветовых тем.
Вам нужен точный контроль над повторной отрисовкой страницы (весь скрипт перезапускается при изменении входных данных, если вы не управляете фрагментами вручную).
Вам не нравится писать Python-скрипты.
---
Dash
Фреймворк для веб-приложений на Python, предоставляющий прямой контроль над макетами, элементами DOM и обратными вызовами.
Dash позволяет Python-разработчикам создавать интерактивные веб-приложения без необходимости изучать JavaScript. Он предлагает существенный контроль и настройку для тех, кто готов углубиться в документацию. Ядро Dash — это класс Python, который объединяет несколько концепций:
Python-обертки для отображения общих элементов DOM и визуализаций plotly (например, `html.H1`, `dcc.Graph`);
Макет приложения, определенный как список вышеуказанных элементов в `app.layout`;
Загрузка и обработка данных с помощью обычных средств анализа данных, таких как numpy или pandas;
Интерактивность посредством обратных вызовов, которые принимают именованные входные данные из приложения (например, значение из выпадающего списка) и возвращают именованные выходные данные (например, отфильтрованный DataFrame);
Возможность добавлять собственный CSS и JavaScript при необходимости.
Dash построен на базе Flask, поэтому любой Python-разработчик, имеющий опыт работы с веб-фреймворками, должен чувствовать себя в нем комфортно. Хотя R, Julia и F# также указаны как совместимые языки, подавляющее большинство документации Dash написано для Python.
Dash — мощный выбор для опытных программистов на Python, которым нужен точный контроль. Однако, если вам неудобны ментальные модели, такие как классы, обратные вызовы или DOM, кривая обучения в Dash может показаться несколько крутой.
У вас сильные навыки Python, и вы хотите более прямого контроля над макетом, стилизацией и интерактивностью, чем в Streamlit.
Вы уже хорошо работаете с веб-фреймворками на базе Python, такими как Flask или Django.
Вы знакомы с библиотеками для анализа данных на базе Python, такими как pandas, numpy и plotly.
Не рекомендуется, если:
Вам неудобно работать с классами, обратными вызовами, методами или декораторами Python.
Вам неудобно напрямую взаимодействовать с DOM.
---
Observable Framework
Инструментарий для визуализации данных для веб-разработчиков на JavaScript.
Если `npm run dev` — это ваша скорость, Observable Framework — отличный выбор для использования всей мощи веб-разработки при визуализации данных. Предоставляя вам импортируемые вспомогательные элементы, такие как Plot и FileAttachment, Observable упрощает интеграцию входных данных и предварительно созданных компонентов визуализации в ваше веб-приложение. У вас по-прежнему есть все обычные инструменты веб-разработки: HTML, JSX, компоненты React, стили CSS, функции JavaScript и импорты и т.д.
Хотя загрузчики данных для Observable могут быть написаны на любом языке программирования, базовый уровень комфорта с концепциями веб-разработки (например, HTML, CSS и JavaScript) позволит вам наилучшим образом использовать многие функции Observable.
Вы веб-разработчик, который разбирается в HTML, CSS и JavaScript и хочет в полной мере использовать свои обычные инструменты (например, Node, React).
Не рекомендуется, если:
Вы не уверены, что такое node и npm, или что означает async/await.
---
Shiny
Авторитетная оболочка для R и Python, с акцентом на эффективную реактивность.
Если R или Python — ваш основной язык для анализа данных, и вы не заинтересованы в полноценной веб-разработке или ручном управлении обратными вызовами, то, возможно, стоит потрудиться, чтобы изучить ментальные модели Shiny. Из всех инструментов, рассмотренных в этой статье, он, вероятно, наиболее авторитетен в плане создания новых, специфичных для Shiny концепций, которые должен освоить пользователь. Например, все пользовательские входы (т.е. выпадающие списки) определяются с помощью функций `ui.input_*()`, а все выходы создаются декораторами, такими как `@render.plot`. Даже для опытного Python-разработчика понимание всех этих концепций может занять время. Код для сложной панели инструментов Shiny может стать довольно громоздким.
Преимущество всего этого заключается в том, что Shiny автоматически эффективно управляет реактивностью за вас. Их документация даже приводит пример воспроизведения панели инструментов Streamlit для более быстрой работы.
HTML, CSS и JavaScript могут управляться вручную, но необходимость их размещения внутри Python-оберток может привести к тому, что код будет выглядеть немного громоздко.
Если вы довольны использованием чистых, минималистичных, предварительно стилизованных компонентов Shiny и цените эффективную реактивность, Shiny может быть хорошим выбором.
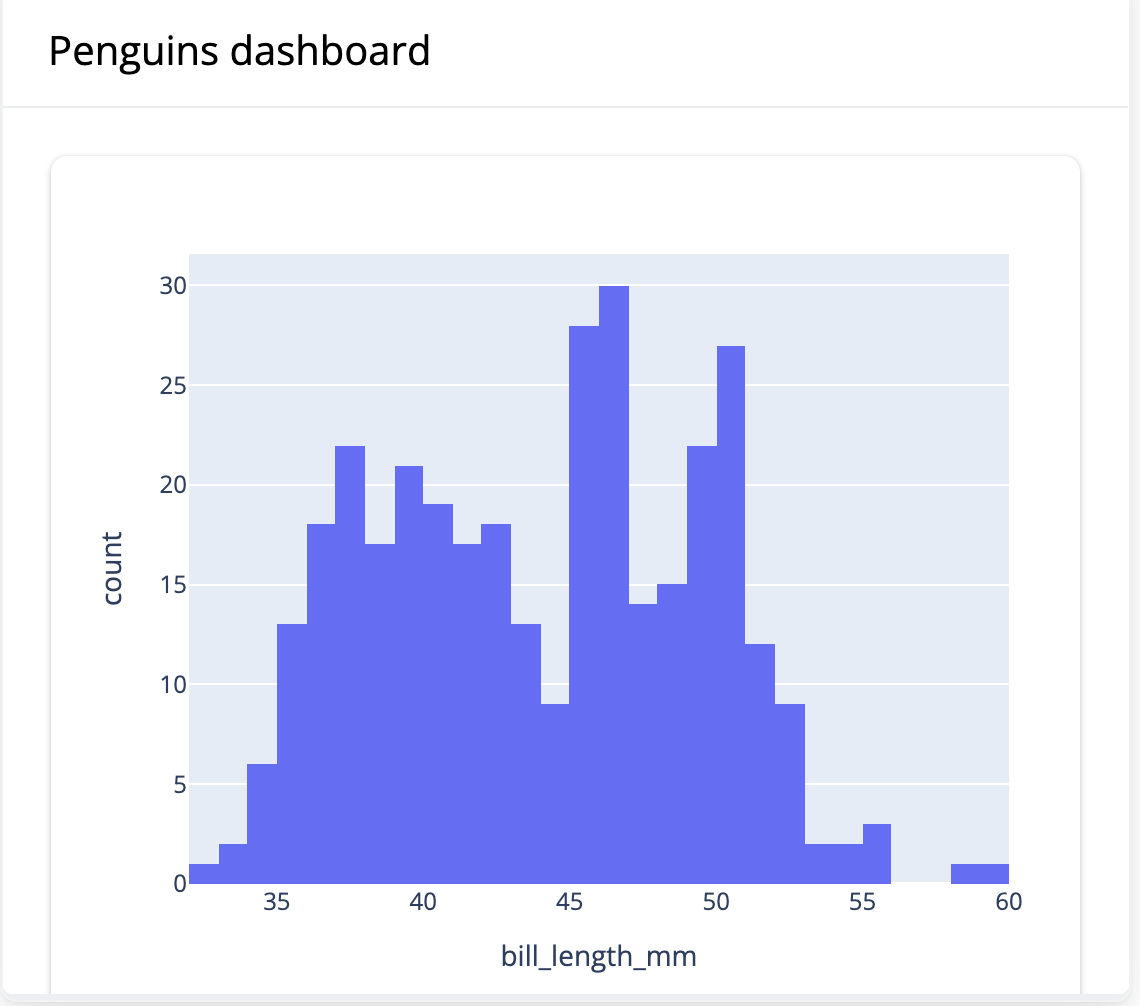
Пример кода:
from shiny.express import input, render, ui
from shinywidgets import render_plotly
ui.page_opts(title="Penguins dashboard", fillable=True)
with ui.sidebar():
ui.input_selectize(
"var", "Select variable",
["bill_length_mm", "bill_depth_mm", "flipper_length_mm", "body_mass_g", "year"]
)
ui.input_numeric("bins", "Number of bins", 30)
with ui.card(full_screen=True):
@render_plotly
def hist():
import plotly.express as px
from palmerpenguins import load_penguins
return px.histogram(load_penguins(), x=input.var(), nbins=input.bins())
Хороший выбор, если:
У вас сильные навыки R или Python, и вы хотите использовать только эти языки.
Вы цените быструю, эффективную реактивность и не хотите вручную управлять обратными вызовами.
Вам нравится использовать чистые, минималистичные, предварительно стилизованные компоненты.
Не рекомендуется, если:
Вы не хотите изучать специфические для Shiny ментальные модели для управления UI и реактивностью.
Вы предпочитаете напрямую контролировать UI с помощью более традиционного стека веб-разработки (например, HTML / CSS / JS).
Вам требуется очень тонкий контроль над внешним видом и ощущениями.
---
Quarto
Минималистичный рендерер страниц на Jupyter / Markdown, предназначенный для научной и технической публикации.
Если ваша цель — как можно быстрее и без излишеств преобразовать результаты анализа данных в HTML-файлы, .doc или PDF, Quarto может быть хорошим выбором. Quarto берет заметки Jupyter или Markdown в стиле Quarto и преобразует их в широкий спектр форматов. Доступны темы, а также некоторые параметры интерактивности. Фактически, если вы готовы потрудиться и изучить ее, Quarto предоставляет документацию для большинства задач, которые вы можете захотеть выполнить. В целом, однако, Quarto — хороший выбор для тех, кто уже знаком с заметками Jupyter и хочет быстро представить свою работу в общем формате без чрезмерной настройки или суеты.
Если вы привыкли публиковать свои работы в LaTeX, Quarto также может показаться более современной, гибкой альтернативой, которая по-прежнему предлагает чистый, простой, академический вид документа LaTeX.
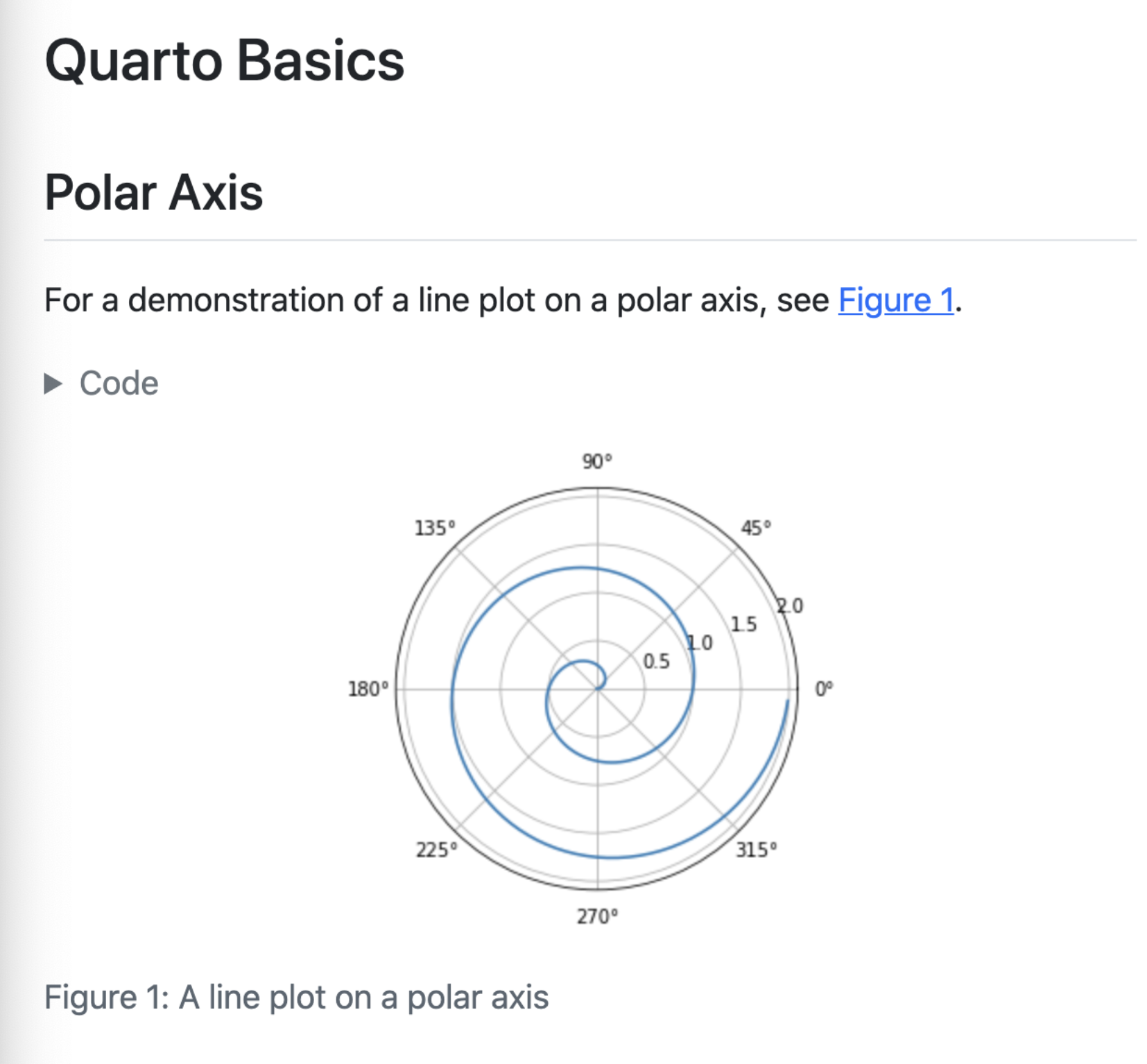
For a demonstration of a line plot on a polar axis, see @fig-polar.
#| label: fig-polar
#| fig-cap: "A line plot on a polar axis"
import numpy as np
import matplotlib.pyplot as plt
r = np.arange(0, 2, 0.01)
theta = 2 * np.pi * r
fig, ax = plt.subplots(
subplot_kw = {'projection': 'polar'}
)
ax.plot(theta, r)
ax.set_rticks([0.5, 1, 1.5, 2])
ax.grid(True)
plt.show()
Хороший выбор, если:
Вы уже знакомы с заметками Jupyter или Markdown и хотите быстро представить свою работу в общем формате с минимальной стилизацией.
Вы не против изучать документацию для выполнения более сложных задач (например, пользовательские темы или развертывание в определенном сервисе, таком как Netlify).
Не рекомендуется, если:
Вам требуется полноценная функциональность веб-разработки.
Вам нужен обширный контроль над внешним видом и ощущениями, или интерактивностью.
---
Заключение
При выборе инструмента BI-as-code учитывайте технические навыки вашей команды и конкретные потребности:
* Evidence идеально подходит для аналитиков, которые в основном работают с SQL и хотят быстро создавать приложения для данных с использованием Markdown.
* Streamlit хорошо подходит для Python-специалистов по данным, стремящихся к быстрому прототипированию.
* Dash предлагает больше контроля для Python-разработчиков, знакомых с веб-фреймворками.
* Observable предоставляет полные возможности веб-разработки для JavaScript-разработчиков.
* Shiny подходит для пользователей R/Python, которым нужно эффективное управление реактивностью.
* Quarto идеально подходит для ученых и технических писателей, сосредоточенных на публикации документов.
Если вы хотите попробовать Evidence сами, вы можете начать бесплатно.
Evidence можно хостить на huggingface.co, но вот чем лучше в своей закрытой корпоративной среде пока не ясно. думаемс. 🤔
DuckLake упрощает Lakehouse, используя стандартную базу данных SQL для всех метаданных вместо сложных файловых систем, при этом храня данные в открытых форматах, таких как Parquet. Это делает его более надежным, быстрым и простым в управлении.
Хотите послушать содержание этого манифеста? Мы также выпустили эпизод подкаста на ютубе, объясняющий, как мы пришли к формату DuckLake.
Или тут можно посмотреть:
Предыстория
Инновационные системы данных, такие как BigQuery и Snowflake, показали, что разделение хранилища и вычислений — отличная идея в то время, когда хранилище является виртуализированным товаром. Таким образом, и хранилище, и вычисления могут масштабироваться независимо, и нам не нужно покупать дорогие машины баз данных только для хранения таблиц, которые мы никогда не будем читать.
В то же время рыночные силы вынудили людей настаивать на том, чтобы системы данных использовали открытые форматы, такие как Parquet, чтобы избежать слишком распространенного “захвата” данных одним поставщиком. В этом новом мире множество систем данных с удовольствием резвились вокруг нетронутого «озера данных», построенного на Parquet и S3, и все было хорошо. Кому нужны эти старомодные базы данных!
Но быстро выяснилось, что – шокирующе – люди хотели вносить изменения в свои наборы данных. Простые добавления работали довольно хорошо, просто помещая больше файлов в папку, но что-либо, кроме этого, требовало сложных и подверженных ошибкам пользовательских сценариев без какого-либо понятия правильности или – упаси господь, Кодд – транзакционных гарантий.
Настоящее озеро данных/Lakehouse
Настоящее озеро данных. Может быть, больше похоже на домик у озера.
Iceberg и Delta
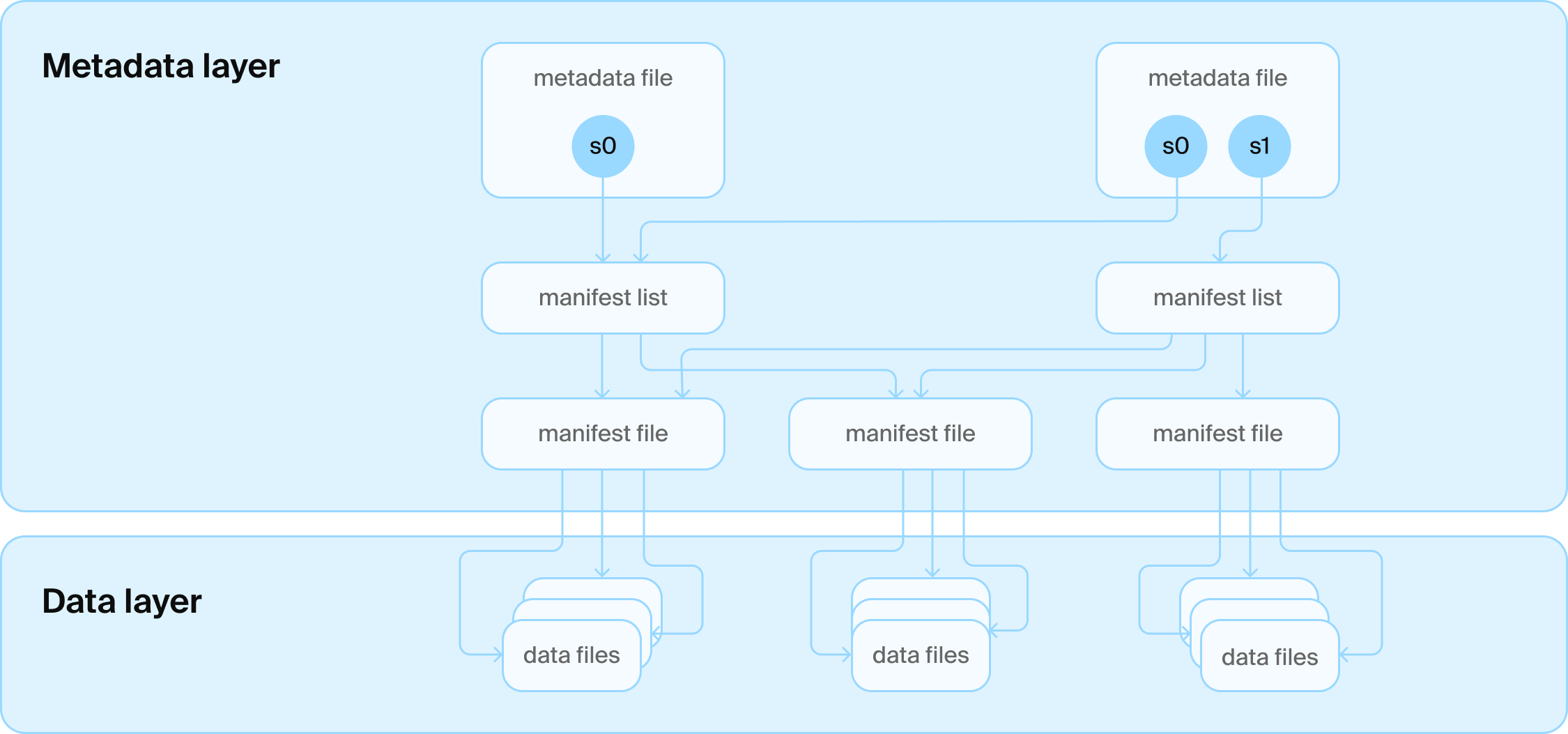
Для решения основной задачи изменения данных в озере появились различные новые открытые стандарты, наиболее заметные из которых — Apache Iceberg и Linux Foundation Delta Lake. Оба формата были разработаны для того, чтобы, по сути, вернуть некоторую разумность в изменении таблиц, не отказываясь от основной предпосылки: использовать открытые форматы в блочном хранилище. Например, Iceberg использует лабиринт файлов JSON и Avro для определения схем, снимков и того, какие файлы Parquet являются частью таблицы в определенный момент времени. Результат был назван «Lakehouse», по сути, дополнением функций базы данных к озерам данных, что позволило реализовать множество новых увлекательных вариантов использования для управления данными, например, обмен данными между движками.
Архитектура таблицы Iceberg
Но оба формата столкнулись с проблемой: поиск последней версии таблицы затруднен в блочных хранилищах с их изменчивыми гарантиями согласованности. Трудно атомарно (буква «А» в ACID) поменять указатель, чтобы убедиться, что все видят последнюю версию. Iceberg и Delta Lake также знают только об одной таблице, но люди – опять же, шокирующе – хотели управлять несколькими таблицами.
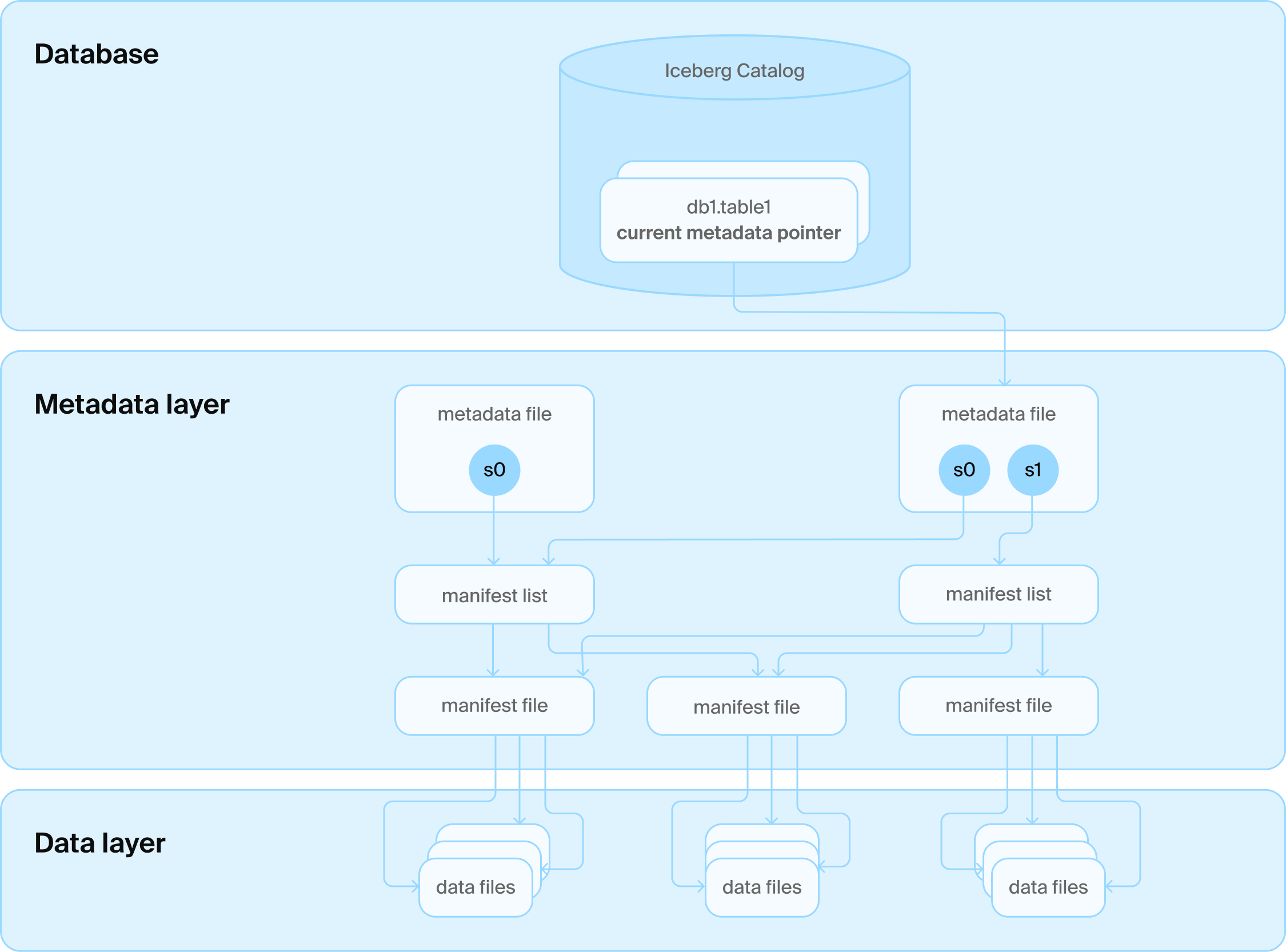
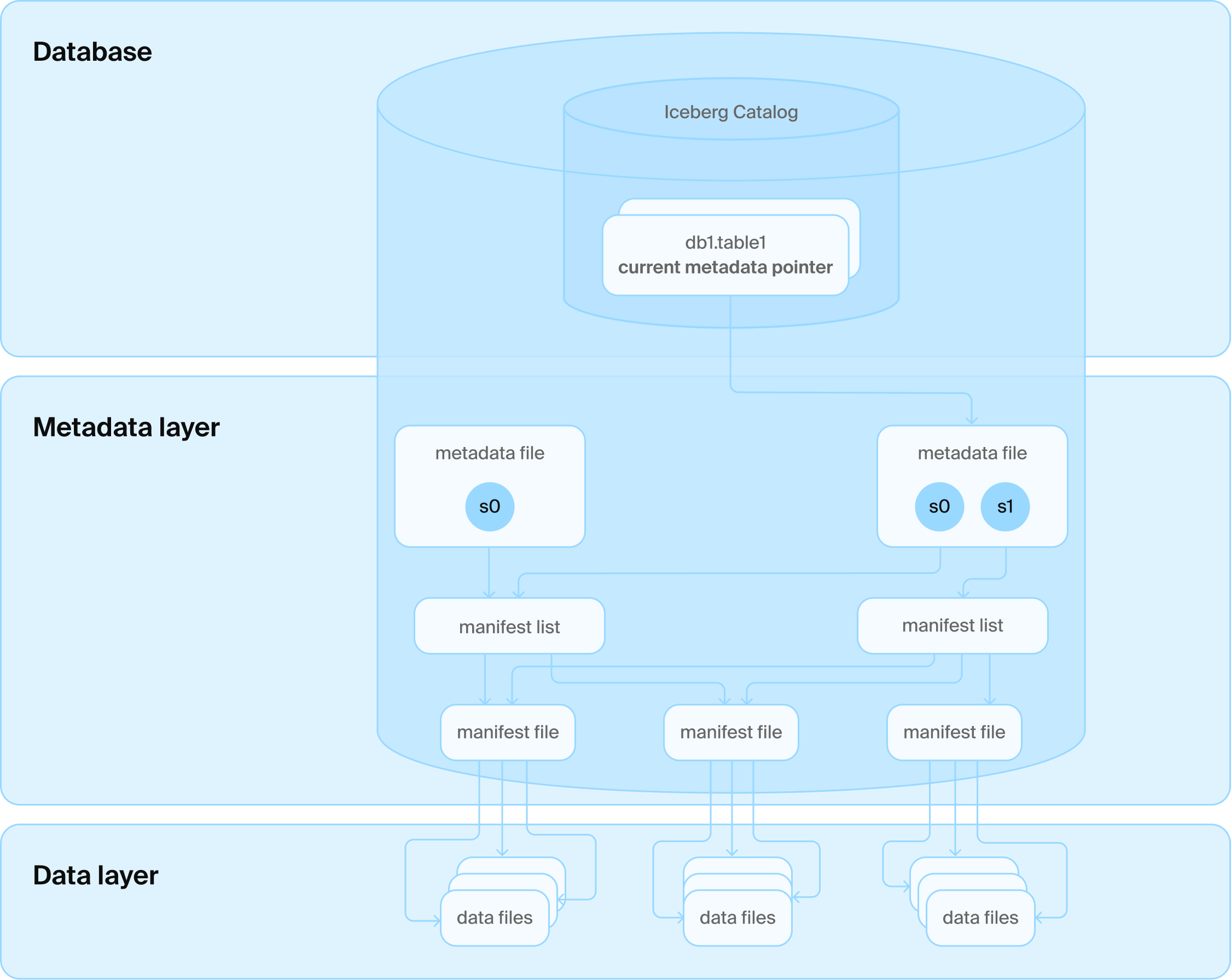
Каталоги
Решением стал еще один слой технологий: мы добавили службу каталогов поверх различных файлов. Эта служба каталогов, в свою очередь, взаимодействует с базой данных, которая управляет всеми именами папок таблиц. Она также управляет самой печальной таблицей всех времен, которая содержит только одну строку для каждой таблицы с текущим номером версии. Теперь мы можем использовать транзакционные гарантии базы данных для обновления этого номера, и все счастливы.
Архитектура каталога Iceberg
Вы говорите, база данных?
Но вот в чем проблема: Iceberg и Delta Lake были специально разработаны так, чтобы не требовать базу данных. Их дизайнеры приложили большие усилия, чтобы закодировать всю информацию, необходимую для эффективного чтения и обновления таблиц, в файлы в блочном хранилище. Они идут на многие компромиссы, чтобы достичь этого. Например, каждый корневой файл в Iceberg содержит все существующие снимки со схемой и т. д. Для каждого изменения записывается новый файл, который содержит полную историю. Многие другие метаданные должны были быть объединены, например, в двухуровневых файлах манифеста, чтобы избежать записи или чтения слишком большого количества мелких файлов, что не было бы эффективным в блочных хранилищах. Внесение небольших изменений в данные также является в значительной степени нерешенной проблемой, которая требует сложных процедур очистки, которые до сих пор не очень хорошо изучены и не поддерживаются реализациями с открытым исходным кодом. Существуют целые компании, и до сих пор создаются новые, чтобы решить эту проблему управления быстро меняющимися данными. Почти так, как если бы специализированная система управления данными была бы хорошей идеей.
Но, как указано выше, дизайны Iceberg и Delta Lake уже были вынуждены пойти на компромисс и добавить базу данных в качестве части каталога для обеспечения согласованности. Однако они никогда не пересматривали остальные свои проектные ограничения и стек технологий, чтобы приспособиться к этому фундаментальному изменению дизайна.
DuckLake
Здесь, в DuckDB, мы на самом деле любим базы данных. Это удивительные инструменты для безопасного и эффективного управления довольно большими наборами данных. Раз уж база данных все равно вошла в стек Lakehouse, имеет безумный смысл использовать ее и для управления остальными метаданными таблицы! Мы все еще можем использовать «бесконечную» емкость и «безграничную» масштабируемость блочных хранилищ для хранения фактических данных таблицы в открытых форматах, таких как Parquet, но мы можем гораздо более эффективно и действенно управлять метаданными, необходимыми для поддержки изменений в базе данных! По совпадению, это также то, что выбрали Google BigQuery (со Spanner) и Snowflake (с FoundationDB), только без открытых форматов в нижней части.
Архитектура DuckLake: просто база данных и несколько файлов Parquet.
Для решения фундаментальных проблем существующей архитектуры Lakehouse мы создали новый открытый табличный формат под названием DuckLake. DuckLake переосмысливает то, как должен выглядеть формат «Lakehouse», признавая две простые истины:
Хранение файлов данных в открытых форматах в блочном хранилище — отличная идея для масштабируемости и предотвращения привязки к поставщику.
Управление метаданными — это сложная и взаимосвязанная задача управления данными, которую лучше оставить системе управления базами данных.
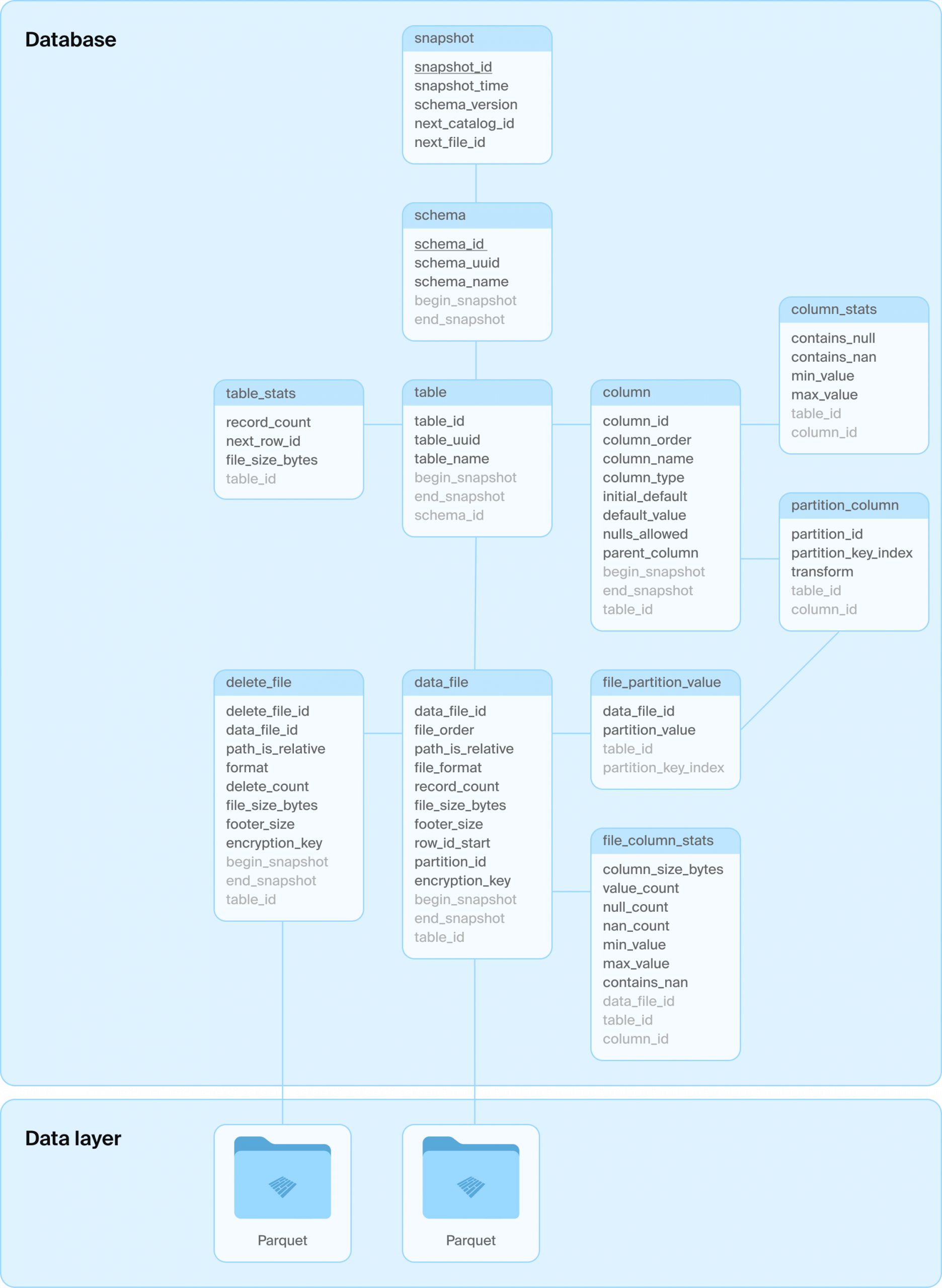
Основная идея DuckLake заключается в перемещении всех структур метаданных в базу данных SQL, как для каталога, так и для табличных данных. Формат определяется как набор реляционных таблиц и «чистые» транзакции SQL над ними, описывающие операции с данными, такие как создание, изменение схемы, а также добавление, удаление и обновление данных. Формат DuckLake может управлять произвольным количеством таблиц с межтабличными транзакциями. Он также поддерживает «расширенные» концепции баз данных, такие как представления, вложенные типы, транзакционные изменения схемы и т. д.; см. ниже список. Одним из основных преимуществ такого дизайна является использование ссылочной целостности (буква «C» в ACID), схема гарантирует, например, отсутствие дублирующихся идентификаторов снимков.
Схема DuckLake
Какую именно базу данных SQL использовать, решает пользователь, единственные требования — система должна поддерживать операции ACID и первичные ключи, а также стандартный SQL. Внутренняя схема таблицы DuckLake намеренно сделана простой, чтобы максимизировать совместимость с различными базами данных SQL. Вот основная схема на примере.
Давайте рассмотрим последовательность запросов, которые происходят в DuckLake при выполнении следующего запроса на новой, пустой таблице:
INSERT INTO demo VALUES (42), (43);
BEGIN TRANSACTION;
-- некоторые чтения метаданных здесь пропущены
INSERT INTO ducklake_data_file VALUES (0, 1, 2, NULL, NULL, 'data_files/ducklake-8196...13a.parquet', 'parquet', 2, 279, 164, 0, NULL, NULL);
INSERT INTO ducklake_table_stats VALUES (1, 2, 2, 279);
INSERT INTO ducklake_table_column_stats VALUES (1, 1, false, NULL, '42', '43');
INSERT INTO ducklake_file_column_statistics VALUES (0, 1, 1, NULL, 2, 0, 56, '42', '43', NULL);
INSERT INTO ducklake_snapshot VALUES (2, now(), 1, 2, 1);
INSERT INTO ducklake_snapshot_changes VALUES (2, 'inserted_into_table:1');
COMMIT;
Мы видим единую целостную транзакцию SQL, которая:
Вставляет новый путь к файлу Parquet
Обновляет глобальную статистику таблицы (теперь имеет больше строк)
Обновляет глобальную статистику столбцов (теперь имеет другое минимальное и максимальное значение)
Обновляет статистику столбцов файла (также записывает помимо прочего минимум/максимум)
Создает новый снимок схемы (#2)
Регистрирует изменения, произошедшие в снимке
Обратите внимание, что фактическая запись в Parquet не является частью этой последовательности, она происходит заранее. Но независимо от того, сколько значений добавлено, эта последовательность имеет ту же (низкую) стоимость.
Давайте обсудим три принципа DuckLake: простоту, масштабируемость и скорость.
Простота
DuckLake следует принципам проектирования DuckDB, заключающимся в сохранении простоты и постепенности. Для запуска DuckLake на ноутбуке достаточно просто установить DuckDB с расширением ducklake. Это отлично подходит для целей тестирования, разработки и прототипирования. В этом случае хранилищем каталога является просто локальный файл DuckDB.
Следующим шагом является использование внешних систем хранения. Файлы данных DuckLake неизменяемы, он никогда не требует модификации файлов на месте или повторного использования имен файлов. Это позволяет использовать его практически с любой системой хранения. DuckLake поддерживает интеграцию с любой системой хранения, такой как локальный диск, локальный NAS, S3, Azure Blob Store, GCS и т. д. Префикс хранения для файлов данных (например, s3://mybucket/mylake/) указывается при создании таблиц метаданных.
Наконец, база данных SQL, размещающая сервер каталога, может быть любой более-менее компетентной базой данных SQL, которая поддерживает ACID и ограничения первичного ключа. Большинство организаций уже имеют большой опыт эксплуатации такой системы. Это значительно упрощает развертывание, поскольку помимо базы данных SQL не требуется никакого дополнительного программного обеспечения. Кроме того, базы данных SQL в последние годы стали широко доступны, существует бесчисленное множество размещенных служб PostgreSQL или даже размещенных DuckDB, которые могут использоваться в качестве хранилища каталога! Опять же, привязка к поставщику здесь очень ограничена, потому что переход не требует перемещения данных таблицы, а схема проста и стандартизирована.
Нет файлов Avro или JSON. Нет дополнительного сервера каталогов или дополнительного API для интеграции. Все это просто SQL. Мы все знаем SQL.
Масштабируемость
DuckLake фактически увеличивает разделение проблем в архитектуре данных на три части: хранение, вычисления и управление метаданными. Хранение остается на специализированном файловом хранилище (например, блочное хранилище), DuckLake может масштабироваться бесконечно в хранении.
Произвольное количество вычислительных узлов запрашивают и обновляют базу данных каталога, а затем независимо читают и записывают из хранилища. DuckLake может масштабироваться бесконечно в отношении вычислений.
Наконец, база данных каталога должна быть способна выполнять только те транзакции метаданных, которые запрашиваются вычислительными узлами. Их объем на несколько порядков меньше, чем фактические изменения данных. Но DuckLake не привязан к одной базе данных каталога, что позволяет мигрировать, например, из PostgreSQL на что-то другое по мере роста спроса. В конечном итоге, DuckLake использует простые таблицы и базовый, переносимый SQL. Но не беспокойтесь, DuckLake, поддерживаемый PostgreSQL, уже сможет масштабироваться до сотен терабайт и тысяч вычислительных узлов.
Опять же, это именно тот дизайн, который используют BigQuery и Snowflake, которые уже успешно управляют огромными наборами данных. И, ничего не мешает вам использовать Spanner в качестве базы данных каталога DuckLake, если это необходимо.
Скорость
Как и сам DuckDB, DuckLake очень ориентирован на скорость. Одной из самых больших проблем Iceberg и Delta Lake является сложная последовательность операций ввода-вывода файлов, необходимая для выполнения самого маленького запроса. Следование по пути каталога и метаданных файлов требует многих отдельных последовательных HTTP-запросов. В результате существует нижний предел того, насколько быстро могут выполняться чтения или транзакции. Много времени тратится на критический путь фиксации транзакций, что приводит к частым конфликтам и дорогостоящему разрешению конфликтов. Хотя кэширование может использоваться для решения некоторых из этих проблем, это добавляет дополнительную сложность и эффективно только для «горячих» данных.
Единые метаданные в базе данных SQL также позволяют планировать запросы с низкой задержкой. Чтобы прочитать данные из таблицы DuckLake, один запрос отправляется в базу данных каталога, которая выполняет сокращение на основе схемы, разделов и статистики, чтобы, по сути, получить список файлов для чтения из блочного хранилища. Нет множественных обращений к хранилищу для извлечения и восстановления состояния метаданных. Также меньше вероятность возникновения ошибок, нет регулирования S3, нет неудачных запросов, нет повторных попыток, нет еще не согласованных представлений хранилища, которые приводят к невидимости файлов и т. д.
DuckLake также способен улучшить две самые большие проблемы производительности озер данных: небольшие изменения и множество одновременных изменений.
Для небольших изменений DuckLake значительно сократит количество мелких файлов, записываемых в хранилище. Нет нового файла снимка с крошечным изменением по сравнению с предыдущим, нет нового файла манифеста или списка манифестов. DuckLake даже опционально позволяет прозрачно встраивать небольшие изменения в таблицы непосредственно в метаданные! Оказывается, систему баз данных можно использовать и для управления данными. Это позволяет выполнять запись за доли миллисекунды и улучшать общую производительность запросов за счет уменьшения количества файлов, которые необходимо считывать. Записывая гораздо меньше файлов, DuckLake также значительно упрощает операции очистки и сжатия.
В DuckLake изменения таблицы состоят из двух шагов: подготовки файлов данных (если таковые имеются) к хранению, а затем выполнения одной транзакции SQL в базе данных каталога. Это значительно сокращает время, затрачиваемое на критический путь фиксации транзакций, поскольку нужно выполнить только одну транзакцию. Базы данных SQL довольно хорошо справляются с разрешением конфликтов транзакций. Это означает, что вычислительные узлы тратят гораздо меньше времени на критический путь, где могут возникать конфликты. Это позволяет значительно быстрее разрешать конфликты и выполнять гораздо больше параллельных транзакций. По сути, DuckLake поддерживает столько изменений таблицы, сколько может зафиксировать база данных каталога. Даже почтенный Postgres может выполнять тысячи транзакций в секунду. Можно было бы запустить тысячу вычислительных узлов, выполняющих добавление в таблицу с интервалом в одну секунду, и это работало бы нормально.
Кроме того, снимки DuckLake — это всего лишь несколько строк, добавленных в хранилище метаданных, что позволяет существовать множеству снимков одновременно. Нет необходимости заблаговременно удалять снимки. Снимки также могут ссылаться на части файла Parquet, что позволяет существовать гораздо большему количеству снимков, чем файлов на диске. В совокупности это позволяет DuckLake управлять миллионами снимков!
Возможности
DuckLake обладает всеми вашими любимыми функциями Lakehouse:
Произвольный SQL: DuckLake поддерживает все те же обширные возможности SQL, что и, например, DuckDB.
Изменения данных: DuckLake поддерживает эффективное добавление, обновление и удаление данных.
Множественная схема, множественные таблицы: DuckLake может управлять произвольным количеством схем, каждая из которых содержит произвольное количество таблиц в одной и той же структуре метаданных.
Межтабличные транзакции: DuckLake поддерживает транзакции, полностью соответствующие ACID, для всех управляемых схем, таблиц и их содержимого.
Сложные типы: DuckLake поддерживает все ваши любимые сложные типы, такие как списки, произвольно вложенные.
Полная эволюция схемы: Схемы таблиц могут изменяться произвольно, например, столбцы могут быть добавлены, удалены или их типы данных изменены.
Отмотка времени и откат на уровне схемы: DuckLake поддерживает полную изоляцию снимков и отмотку времени, позволяя запрашивать таблицы на определенный момент времени.
Инкрементальное сканирование: DuckLake поддерживает получение только тех изменений, которые произошли между указанными снимками.
Представления SQL: DuckLake поддерживает определение лениво оцениваемых представлений SQL.
Скрытое разбиение на разделы и отсечение: DuckLake учитывает разбиение данных на разделы, а также статистику на уровне таблиц и файлов, что позволяет заранее отсекать сканирование для максимальной эффективности.
Транзакционные DDL: Создание, эволюция и удаление схем, таблиц и представлений полностью транзакционны.
Избегание уплотнения данных: DuckLake требует гораздо меньше операций уплотнения, чем сопоставимые форматы. DuckLake поддерживает эффективное уплотнение снимков.
Встраивание: При внесении небольших изменений в данные DuckLake может опционально использовать базу данных каталога для прямого хранения этих небольших изменений, чтобы избежать записи множества мелких файлов.
Шифрование: DuckLake может опционально шифровать все файлы данных, записываемые в хранилище, что позволяет размещать данные с нулевым доверием. Ключи управляются базой данных каталога.
Совместимость: Файлы данных и (позиционные) файлы удаления, которые DuckLake записывает в хранилище, полностью совместимы с Apache Iceberg, что позволяет выполнять миграцию только метаданных.
Заключение
Мы выпустили DuckLake v0.1 с расширением DuckDB ducklake в качестве первой реализации. Мы надеемся, что вы найдете DuckLake полезным в своей архитектуре данных – с нетерпением ждем ваших творческих вариантов использования!
import sys
import os
import time
from faster_whisper import WhisperModel
# --- Конфигурация модели Whisper ---
model_size = "large-v3"
# Выберите свою конфигурацию:
# model = WhisperModel(model_size, device="cuda", compute_type="float16") # Если есть GPU и CUDA
# model = WhisperModel(model_size, device="cuda", compute_type="int8_float16") # Если есть GPU и CUDA с INT8
model = WhisperModel(model_size, device="cpu", compute_type="int8") # Для CPU (как в вашем примере)
# -----------------------------------
def transcribe_mp3_to_text(mp3_filepath):
"""
Транскрибирует MP3 файл и сохраняет результат в текстовый файл.
"""
if not os.path.exists(mp3_filepath):
print(f"Ошибка: Файл MP3 не найден: {mp3_filepath}")
return False
if not mp3_filepath.lower().endswith(".mp3"):
print(f"Ошибка: Файл '{mp3_filepath}' не является MP3 файлом. Пропускаем.")
return False
# Извлечение имени файла без расширения
filename_without_ext = os.path.splitext(os.path.basename(mp3_filepath))[0]
output_txt_filepath = os.path.join(os.path.dirname(mp3_filepath), f"{filename_without_ext}.txt")
print(f"[{time.strftime('%Y-%m-%d %H:%M:%S')}] Начинаем транскрипцию '{mp3_filepath}'...")
print(f"Результат будет сохранен в '{output_txt_filepath}'")
try:
segments, info = model.transcribe(mp3_filepath, beam_size=5)
detected_language_msg = f"Detected language: '{info.language}' with probability {info.language_probability:.2f}"
print(detected_language_msg)
# Сохранение транскрипции в текстовый файл
with open(output_txt_filepath, 'w', encoding='utf-8') as f_out:
f_out.write(f"--- Транскрипция для: {os.path.basename(mp3_filepath)} ---\n")
f_out.write(f"{detected_language_msg}\n\n")
full_text = [] # Для сбора всего текста, если нужно вывести в конце
for segment in segments:
segment_line = f"[{segment.start:.2f}s -> {segment.end:.2f}s] {segment.text}"
print(segment_line) # Выводим в консоль для отладки
f_out.write(f"{segment.text}\n") # Записываем только текст в файл, по сегментам
full_text.append(segment.text)
# Если вы хотите сохранить всю транскрипцию одним блоком в конце файла или отдельный файл
# f_out.write("\n\n--- Полный текст ---\n")
# f_out.write(" ".join(full_text))
print(f"[{time.strftime('%Y-%m-%d %H:%M:%S')}] Транскрипция успешно завершена! Результат в '{output_txt_filepath}'")
return True
except Exception as e:
print(f"Ошибка при транскрипции файла '{mp3_filepath}': {e}")
# Вы можете добавить логирование ошибки в отдельный файл, если нужно
return False
if __name__ == "__main__":
if len(sys.argv) < 2:
print("Использование: python process_mp3.py <путь/к/вашему/файлу.mp3>")
sys.exit(1)
mp3_file_path_arg = sys.argv[1] # Это будет полный путь к MP3 файлу, переданный из Automator/Bash
transcribe_mp3_to_text(mp3_file_path_arg)
Итоги запуска
(whisper) (base) yuriygavrilov@MacBookPro fastwhisper % python whisp.py
Detected language 'ru' with probability 0.998883
[0.00s -> 4.96s] Раз, два, три, привет, как дела?
[5.94s -> 8.54s] Все хорошо, а у тебя как?
[9.54s -> 10.78s] И у меня все хорошо
[10.78s -> 12.98s] Спасибо, пока
(whisper) (base) yuriygavrilov@MacBookPro fastwhisper %
ограничений по времени нет, кормите его любыми файлами любой длины. Если нужно можно упростить запуск как хотите. На мак можно даже поставить действие на папку и при появлении там файлов типа mp3 они будут автоматически транскрибироваться.
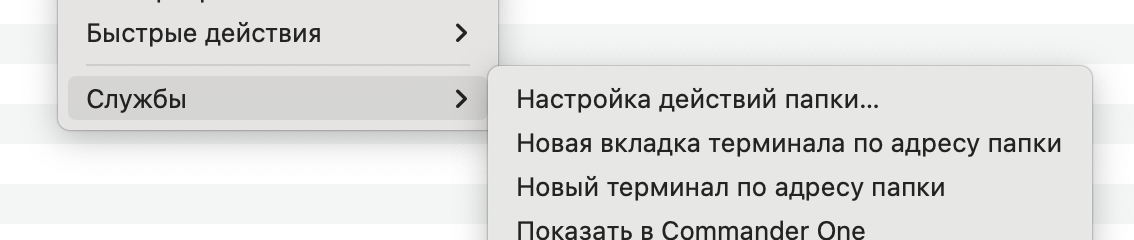
Буду делать через приложении на маке automator
Как то примерно так :)
осталось прикрутить это а действие к папке
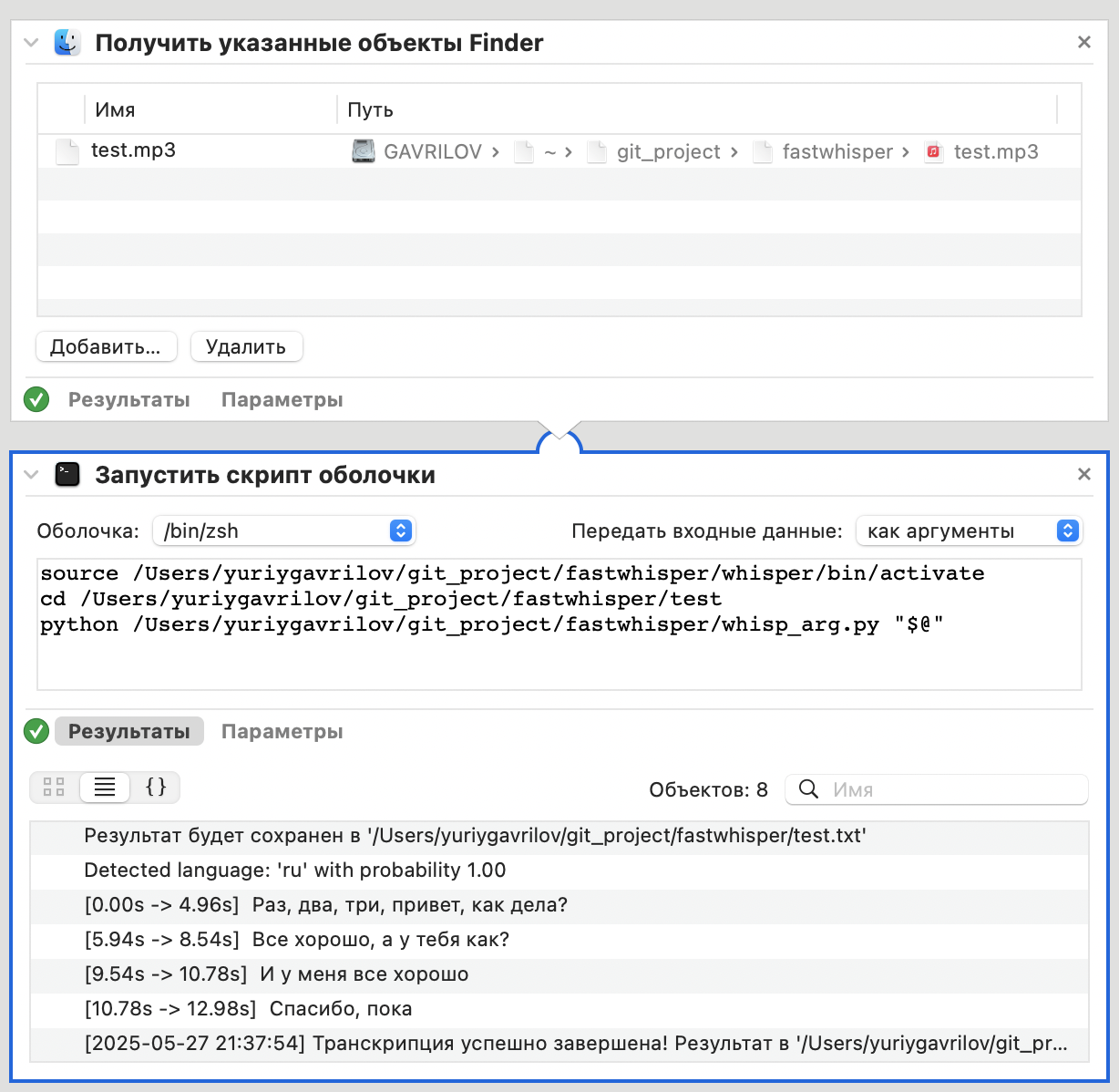
кажись заработало :)
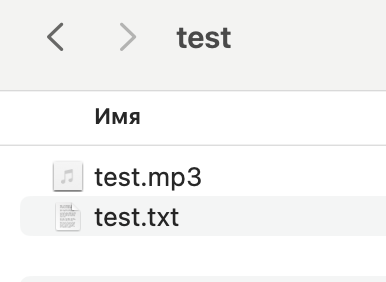
Создалась транскрипция сама
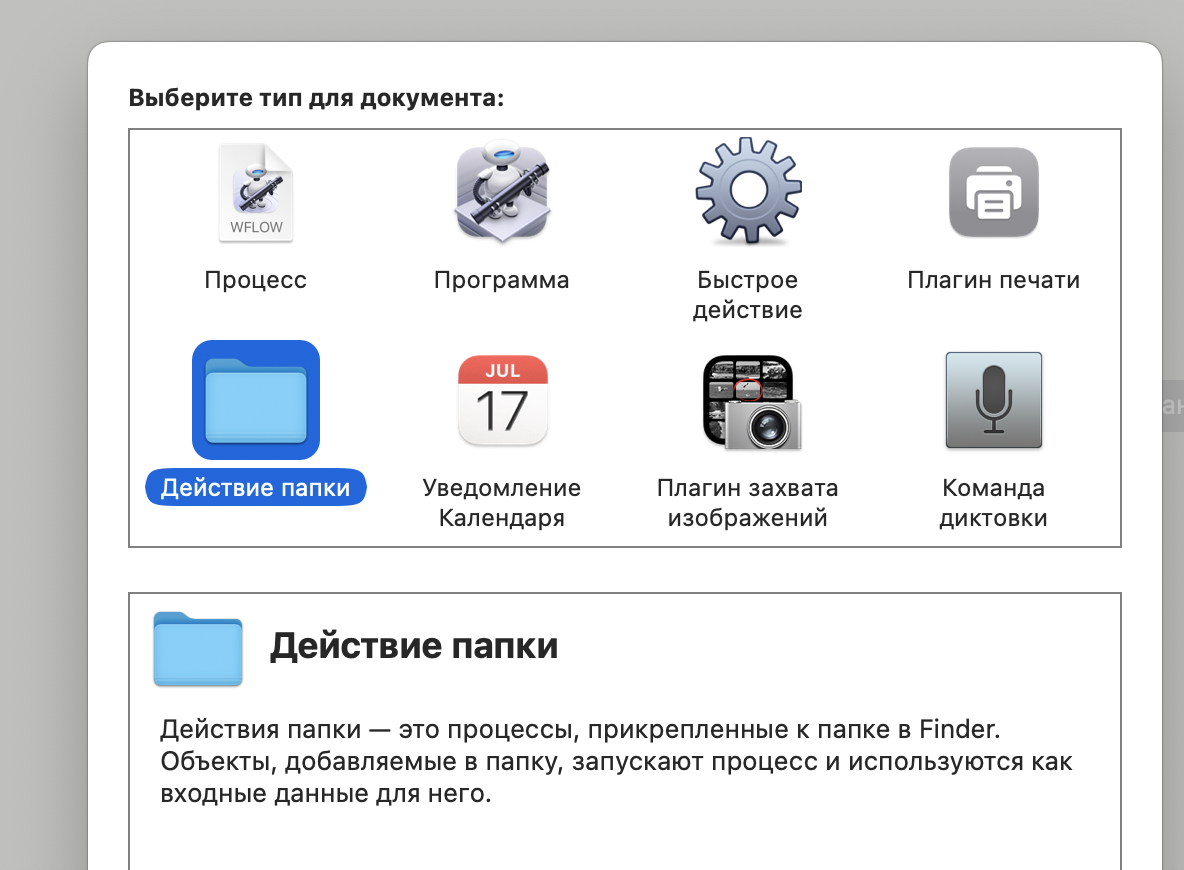
получилось в итоге вот так: Открываем Automator, настраиваем действие и все.
работает так: кидаем файл в папку тест, скрипт запускается, транскрипция появляется рядом. Все.