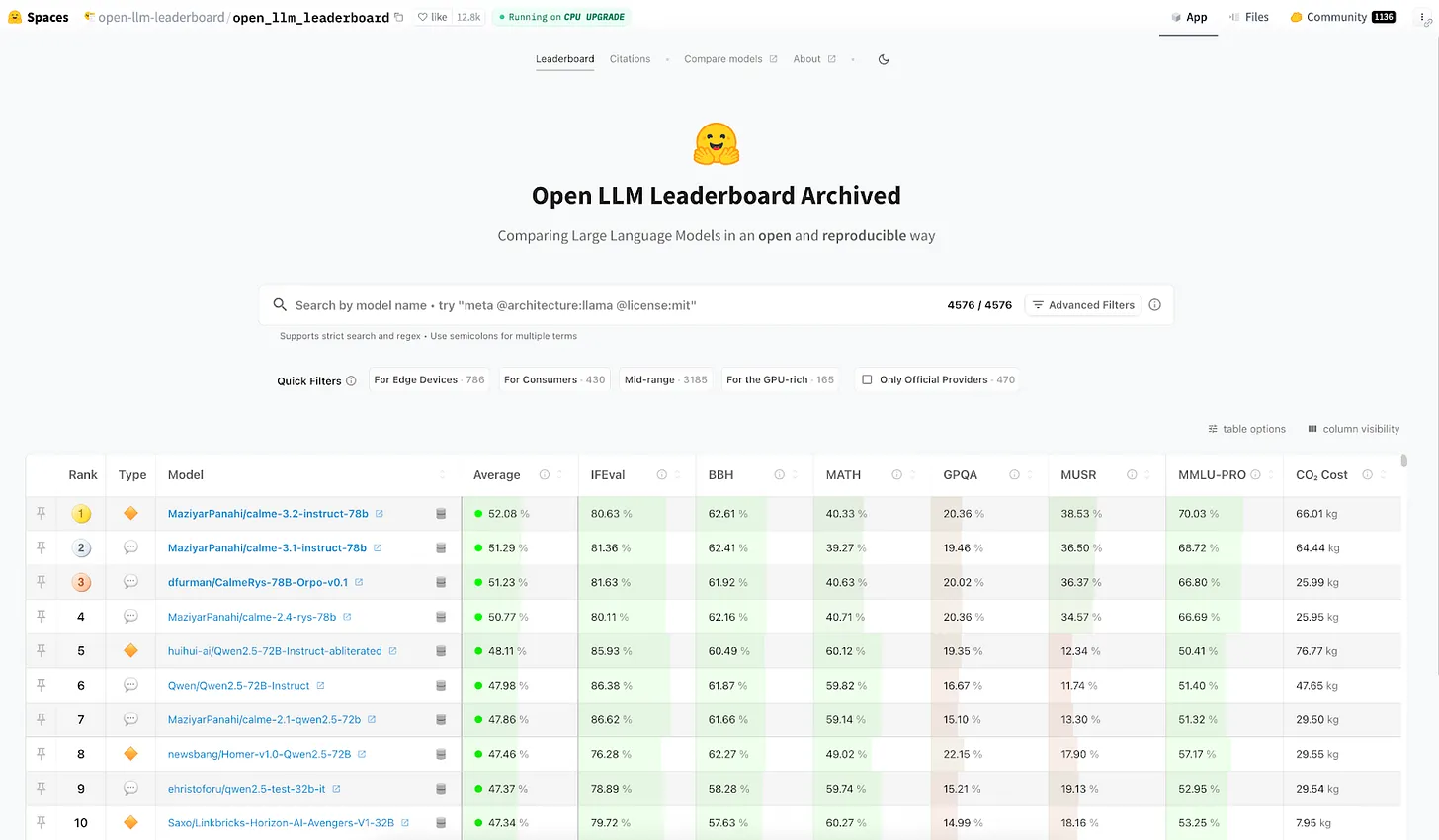
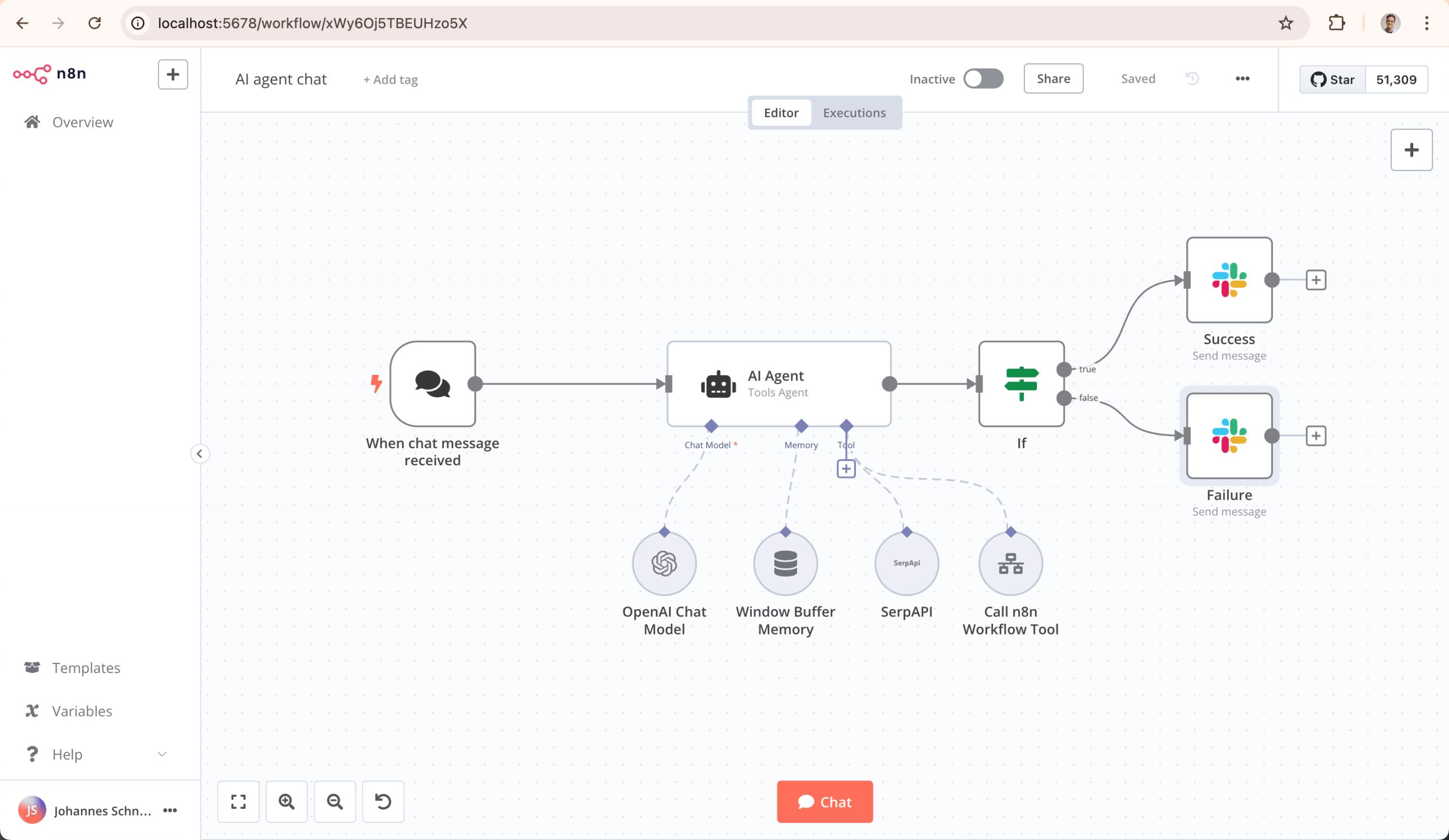
DataHub 1.0
DataHub 1.0 уже здесь! Получите максимальную отдачу от нового UX
00:00:00 Введение и анонсы
• Приветствие участников и анонс гостей.
• Мэгги расскажет об обновлении дорожной карты DataHub.
• Паулина и Анна представят новый UX DataHub 10.
• Харшел из команды DataHub поделится новостями от Block.
• Шершанка, технический директор и соучредитель, подведет итоги.
00:01:01 Анонс DataHub 10
• Анонс DataHub 10 и ссылки на блог и видеоролики.
• Видео о начале проекта DataHub.
00:02:33 Важность DataHub
• DataHub как важный компонент инфраструктуры.
• Переход на DataHub и отключение собственного инструмента lineage.
• Расширение модели DataHub для поддержки элементов данных.
00:04:11 Обновления дорожной карты DataHub
• Мэгги рассказывает о последних обновлениях DataHub.
• Четыре столпа: открытие, управление, метаданные и наблюдаемость.
• Фокус на открытии данных и интеграции с новыми инструментами.
00:05:09 Открытие данных
• Фокус на человеко-ориентированном понимании данных.
• Интеграция с новыми инструментами, такими как MLflow и Cockroach DB.
• Разработка новых интеграций, включая Hex и Vertex AI.
00:07:32 Управление данными
• Введение иерархической родословной для упрощения графиков.
• Расширение поддержки терминов в глоссарии.
• Обеспечение всеобщего доступа к данным и централизованного соответствия требованиям.
00:10:52 Наблюдаемость данных
• Обеспечение доступности и демократизация качества данных.
• Централизованное отслеживание и разрешение инцидентов.
• Улучшения в утверждениях и расширенный поток инцидентов.
00:12:53 Основные направления проекта
• Фокус на API и SDK для автоматизации регистрации, обогащения и поиска данных.
• Важность качества обслуживания и аудита ведения журнала.
• Улучшение отслеживаемости событий в центре обработки данных.
00:13:40 Пакет SDK для Python
• Работа над улучшением пакета SDK для Python версии 2.
• API для регистрации, обогащения и извлечения данных.
• Вклад в документацию для улучшения понимания улучшений.
00:14:42 Учетные записи служб
• Внедрение учетных записей служб для команд.
• Управление автоматизацией и рабочими процессами.
• Призыв к обратной связи и сотрудничеству.
00:15:41 Будущие обновления и DataHub Cloud
• Опрос о будущих обновлениях DataHub и DataHub Cloud.
• DataHub Cloud как управляемый сервис с дополнительными возможностями.
• Переход к повестке дня и представлению UX-дизайнеров.
00:16:47 Дизайн продуктов в DataHub
• Инвестиции в дизайн продуктов в DataHub.
• Важность дизайна для инноваций и постоянного совершенствования.
• Использование данных и отзывов пользователей для улучшения продукта.
00:18:44 Принципы дизайна
• Философия дизайна: простота, обратная связь, последовательность.
• Создание системы проектирования в Figma и Storybook.
• Внедрение токенов и принципов для компонентов.
00:19:43 Примеры изменений
• Изменения в цветах и стилях кнопок и диаграмм.
• Введение специальных дизайнерских жетонов.
• Постепенные обновления пользовательского интерфейса.
00:20:54 Панель навигации и структурированные свойства
• Улучшение панели навигации для удобства пользователей.
• Гибкость отображения структурированных свойств.
• Постоянное совершенствование продукта на основе отзывов пользователей.
00:23:37 Введение и принципы последовательности
• Обсуждение предварительных просмотров вкладки “Стоп”.
• Введение в принципы согласованности и последовательности.
• Создание графической библиотеки для визуализации данных.
00:24:02 Итеративность и визуализация данных
• Итеративный процесс создания графических элементов.
• Примеры различных диаграмм и их эволюция.
• Переход от высокой плотности данных к более сжатым диаграммам.
00:25:46 Новые функции и панель вкладок
• Введение новой панели вкладок “Статистика”.
• Улучшение представления данных для пользователей.
• Демонстрация новых функций и взаимодействий.
00:28:27 Взаимодействие с пользователями
• Призыв к участию в исследовании пользователей.
• Важность обратной связи для улучшения продукта.
• Возможности участия в опросах и тестировании юзабилити.
00:31:19 Обнаружение данных с агентами ИИ
• Введение в тему обнаружения данных с агентами ИИ.
• Представление Сэма Осборна и его роли в компании Block.
• Обзор управления данными и блокчейна в компании.
00:32:39 Проблемы и перспективы управления данными
• Переход на облачный сервис Data Hub.
• Проблемы и возможности каталогизации данных.
• Введение агентов ИИ для улучшения управления данными.
00:34:33 Демонстрация работы с Cloud Desktop
• Cloud Desktop настроен для взаимодействия с LLM.
• Возможность задавать вопросы о данных, связанных с домашними животными.
• Программа ищет данные на сервере Data Hub и предоставляет резюме.
00:35:23 Анализ данных и ключевые показатели
• Программа ищет данные и предоставляет информацию о ключевых показателях.
• Возможность задавать дополнительные вопросы о профилях домашних животных.
• Программа показывает количество строк и активные инциденты.
00:37:05 Использование Slack и Data Hub
• Возможность использовать Slack для планирования изменений в Data Hub.
• Программа помогает определить, на какие данные повлияет изменение.
• Возможность узнать, кому нужно сообщить об изменениях.
00:38:38 Демонстрация работы с Goose
• Goose – агент искусственного интеллекта с открытым исходным кодом.
• Интеграция с локальной и удаленной системами через расширения.
• Пример использования для поиска данных и владельцев данных.
00:43:39 Демонстрация работы в среде IDE
• Проект DBT с использованием идентификатора на базе искусственного интеллекта.
• Возможность проверять изменения в Data Hub и их влияние.
• Программа помогает избежать проблем и обеспечивает безопасность.
00:45:59 Введение в агентов искусственного интеллекта
• Агенты организуют контекстное управление разговорами с LLM.
• Интеграция с системами через протокол MCP.
• Агенты взаимодействуют с LLM и внешними службами данных.
00:47:50 Модель контекстного протокола MCP
• MCP – открытый стандарт для использования данных и инструментов в контексте взаимодействия с ИИ.
• Охватывает аспекты запроса данных, вызова служб и чтения/записи информации.
• Может использоваться для конкретных случаев использования и внешних серверов.
00:48:41 Агенты и спецификация MCP
• Представлен агент искусственного интеллекта с открытым исходным кодом codename goose.
• Спецификация MCP выпущена компанией Anthropic и является стандартным протоколом для ИИ.
• Обсуждается сотрудничество с ACRIL и улучшения Python SDK для приложений ИИ.
00:49:45 Демонстрация и использование codename goose
• Codename goose поддерживает стандарт MCP и позволяет подключаться к различным моделям и поставщикам.
• Демонстрационное видео показывает, как codename goose помогает в выполнении различных задач и упрощении рабочих процессов.
00:50:12 Интеграция и улучшения
• Агенты, стандарты MCP и центр обработки данных помогают быстрее подключать пользователей и интегрироваться с внутренними службами.
• Обсуждаются улучшения Python SDK для поиска сущностей и lineage, оптимизированных для интеграции с ИИ.
00:51:16 Будущее MCP
• В спецификацию MCP добавлены элементы авторизации с помощью OAuth и элементы для выборки и потоковой передачи.
• Ожидается появление множества официальных и неофициальных серверов MCP для различных приложений и сервисов.
00:51:50 Философия Data Hub
• Спецификация MCP вписывается в философию Data Hub, подчеркивающую важность стандартов и переносимости.
• Внедряются стандарты Open Lineage, Iceberg REST Catalog и MCP Model для более эффективного взаимодействия с метаданными.
00:53:02 Рекомендации и советы
• Видео на YouTube и ресурсы на GitHub подробно рассказывают о стандарте MCP.
• Профессиональный совет: делайте сеансы короткими, обобщайте данные и записывайте их в текст для предотвращения разрыва контекстного окна.
00:53:57 Заключение
• Агенты искусственного интеллекта и центр обработки данных помогают в обнаружении данных.
• Проект codename goose и его интеграция с Data Hub являются важными шагами в развитии ИИ.
00:54:38 Введение и прогресс проекта
• Проект быстро развивается, появляются интересные функции.
• Все продемонстрированные элементы, кроме Slack, имеют открытый исходный код.
• Пользовательский интерфейс улучшается, версии 1 и 2 уже доступны.
00:55:50 Проблемы и решения центра обработки данных
• Центр обработки данных решает сложные проблемы в цепочке поставок данных.
• Включает производственные системы, системы преобразования данных и системы искусственного интеллекта.
• Цель – связать всю цепочку поставок данных и обеспечить недостающий контекст.
00:56:32 Важность контекста для различных ролей
• Потребители данных ищут доверие и доступность данных.
• Специалисты по обработке данных беспокоятся о своевременности и изменениях.
• Руководители команд следят за доступом и использованием данных.
00:57:25 Управление искусственным интеллектом
• Важно отслеживать данные, используемые моделями искусственного интеллекта.
• Управление искусственным интеллектом должно быть машинно-ориентированным.
• Понимание доступа моделей к персональным данным и автономных агентов.
00:59:16 Переход к машинно-ориентированному управлению
• Агенты будут действовать автономно, преобразовывать и создавать данные.
• Важно отслеживать действия агентов и гарантировать их правильность.
• Центр обработки данных помогает создавать контекст для машин и агентов.
01:00:53 Заключение и благодарности
• Благодарность участникам за участие и вопросы.
• Обещание предоставить запись и более подробную информацию.
• Призыв обращаться через Slack для дальнейших вопросов и обсуждений.