DuckDB + Attached postgres
Давно уже прошел вебинар про DuckDB, а я еще обещал ответить на вопросы.
Один из них был про работу с postgres. Напомню, что DuckDB это встраиваемая аналитическая база данных.
т.е. Так как она встраиваемая и уже встроена в DBeaver, то пробовать я это буду именно там. И так приступим.
Создаю новую утиную базу
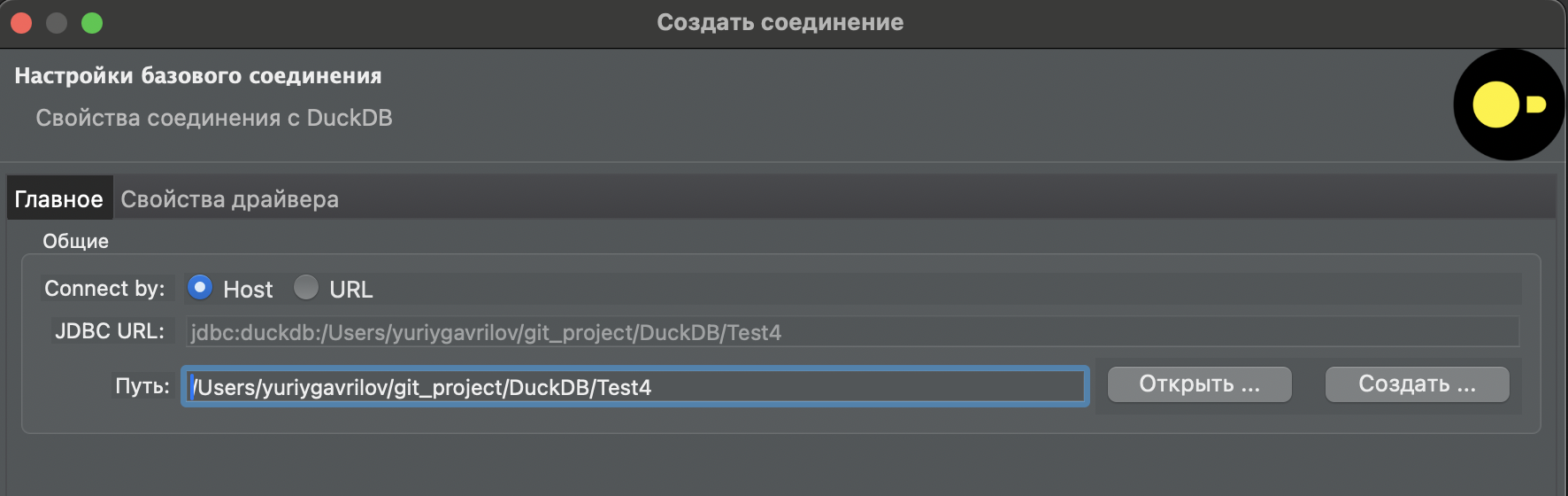
База пока пустая
Надо бы что то в ней создать. Сделаем пару insert и подключим внешний каталог Postgres.
Базу Postgres я подниму локально в Docker этой командой
docker run --name some-postgres -p 5432:5432 -e POSTGRES_PASSWORD=mysecretpassword -d postgresТак как она тоже пустая там понадобятся insert. А еще я хотел попробовать прочитать данные DuckDB с s3 и записать их через подключенный postgres прямо в него. Ну например данные такси нью йорка, там где-то 2 гигабайта, будет хороший кейс нагрузки.
Запускаю Postgres
docker run --name some-postgres -p 5432:5432 -e POSTGRES_PASSWORD=mysecretpassword -d postgresПодключаю бобра.
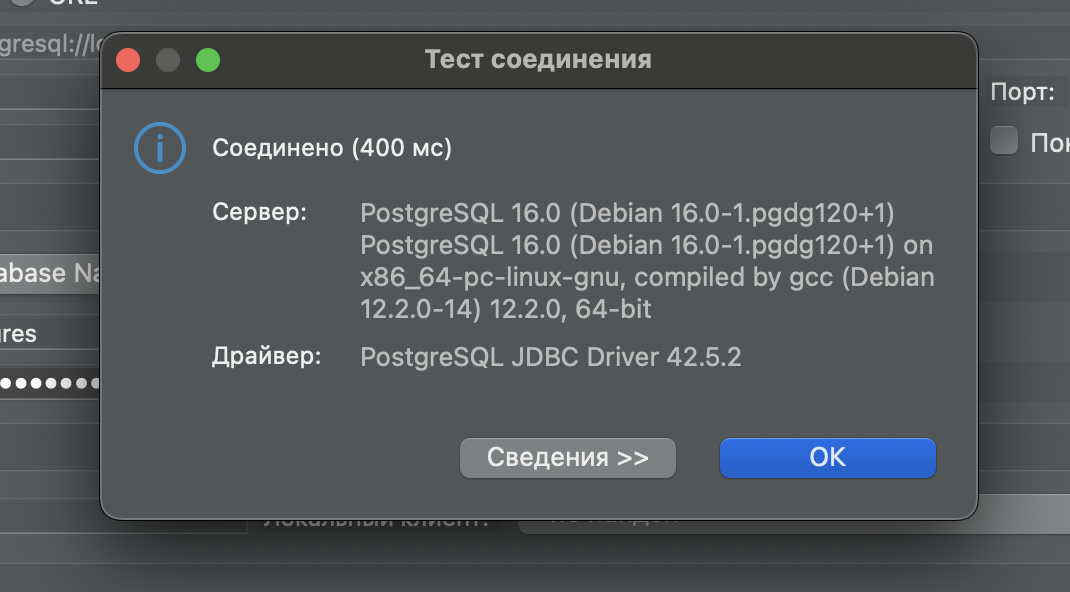
Теперь сделаем табличку и запишем туда пару
CREATE TABLE public.test (
a bigint,
b varchar,
c float,
cdate date
)
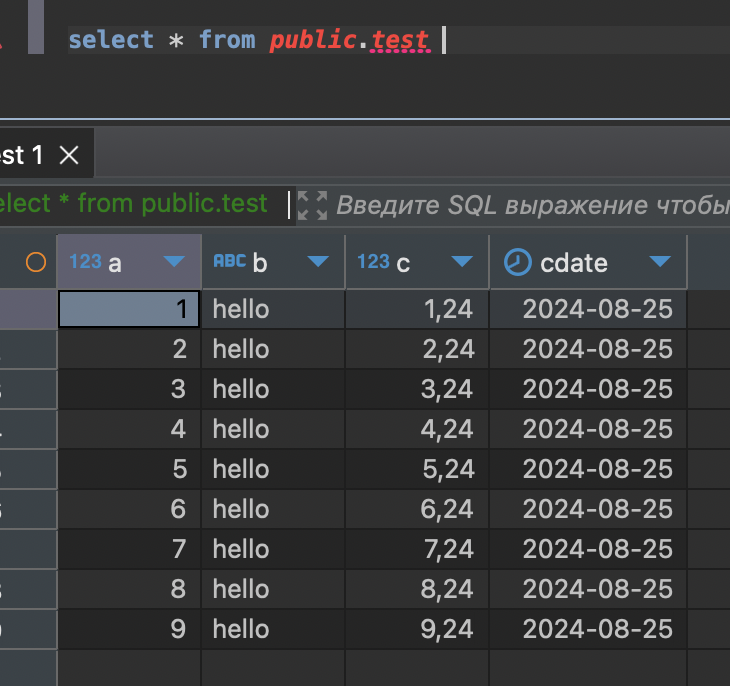
INSERT INTO public.test VALUES (1,'hello', 1.24, now());
INSERT INTO public.test VALUES (2,'hello', 2.24, now());
INSERT INTO public.test VALUES (3,'hello', 3.24, now());
INSERT INTO public.test VALUES (4,'hello', 4.24, now());
INSERT INTO public.test VALUES (5,'hello', 5.24, now());
INSERT INTO public.test VALUES (6,'hello', 6.24, now());
INSERT INTO public.test VALUES (7,'hello', 7.24, now());
INSERT INTO public.test VALUES (8,'hello', 8.24, now());
INSERT INTO public.test VALUES (9,'hello', 9.24, now());отлично
Возвращаемся в утку и будем настраивать.
Установим для начала плагины
INSTALL postgres;
LOAD postgres;Судя по документации можно использоваться простую команду для локального postgres
ATTACH '' AS postgres_db (TYPE POSTGRES);Но я решил использовать чуть подробное описание с параметрами.
ATTACH 'dbname=postgres user=postgres host=127.0.0.1 password=mysecretpassword port=5432' AS db (TYPE POSTGRES);Дополнительные параметры можно узнать из доки тут https://duckdb.org/docs/extensions/postgres
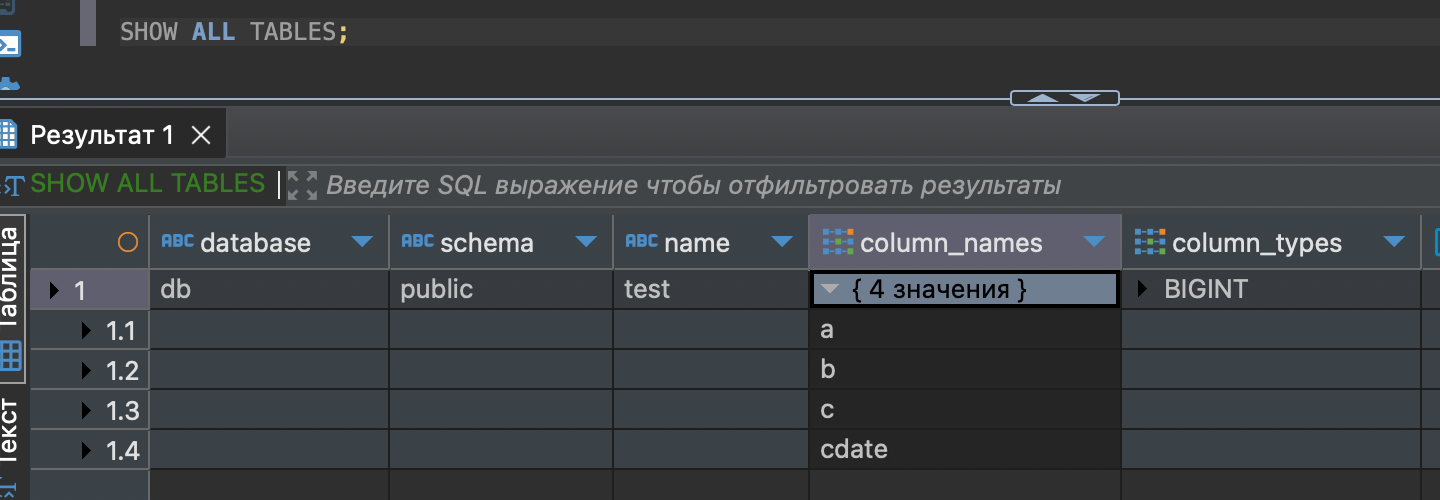
Делаю SHOW ALL TABLES и вижу что то уже из Утки.
Пробуем сделать Select и кстати в дереве каталогов уже появилась моя табличка.
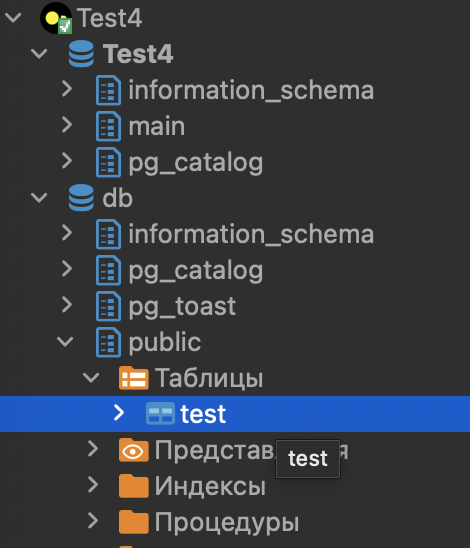
select * from db.public.test t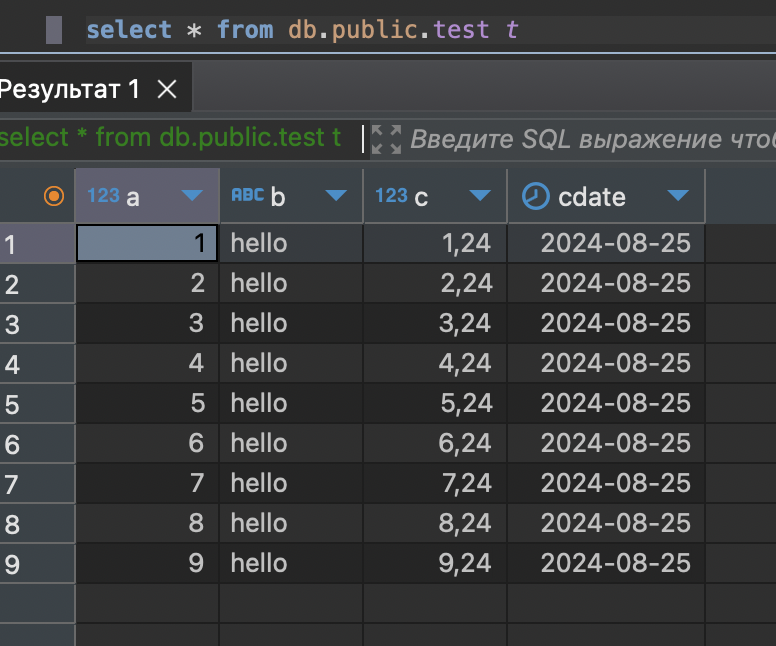
Класс, работает.
можно даже скопировать всю таблицу в утку из postgres.
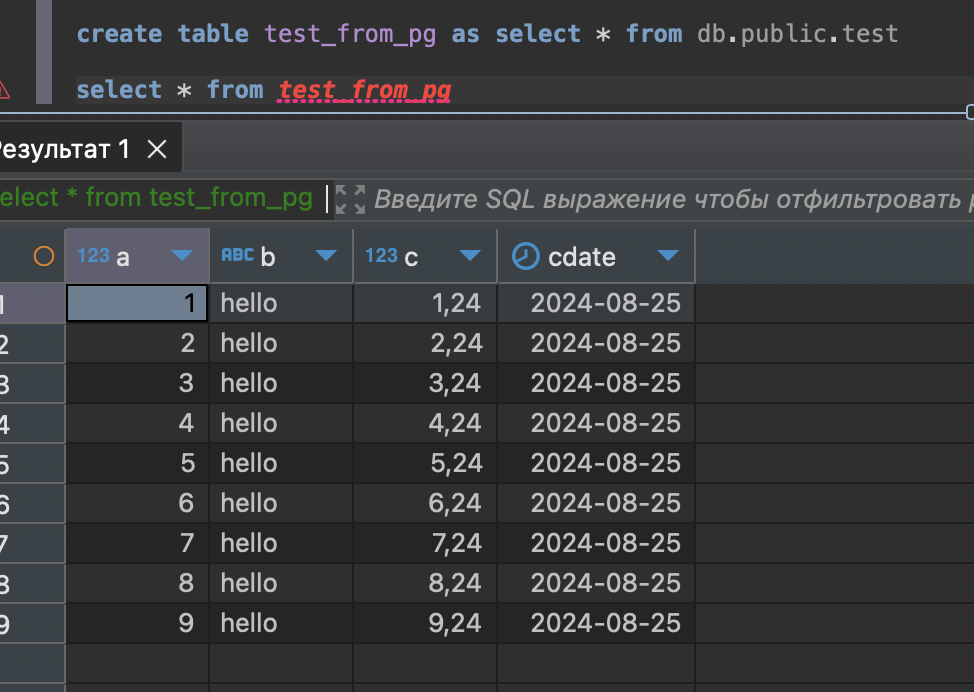
Теперь попробуем пример из вебинара, прочитать данные с s3 уткой и записать их в Postgres.
Настраиваю s3:
INSTALL httpfs;
LOAD httpfs;
CREATE SECRET secret1 (
TYPE S3,
KEY_ID 'jvvgблаблачтотоещеjuma',
SECRET 'jyehmo3kfитуткакаятофигняещеmikcfak3v4lv6',
ENDPOINT 'gateway.storjshare.io'
);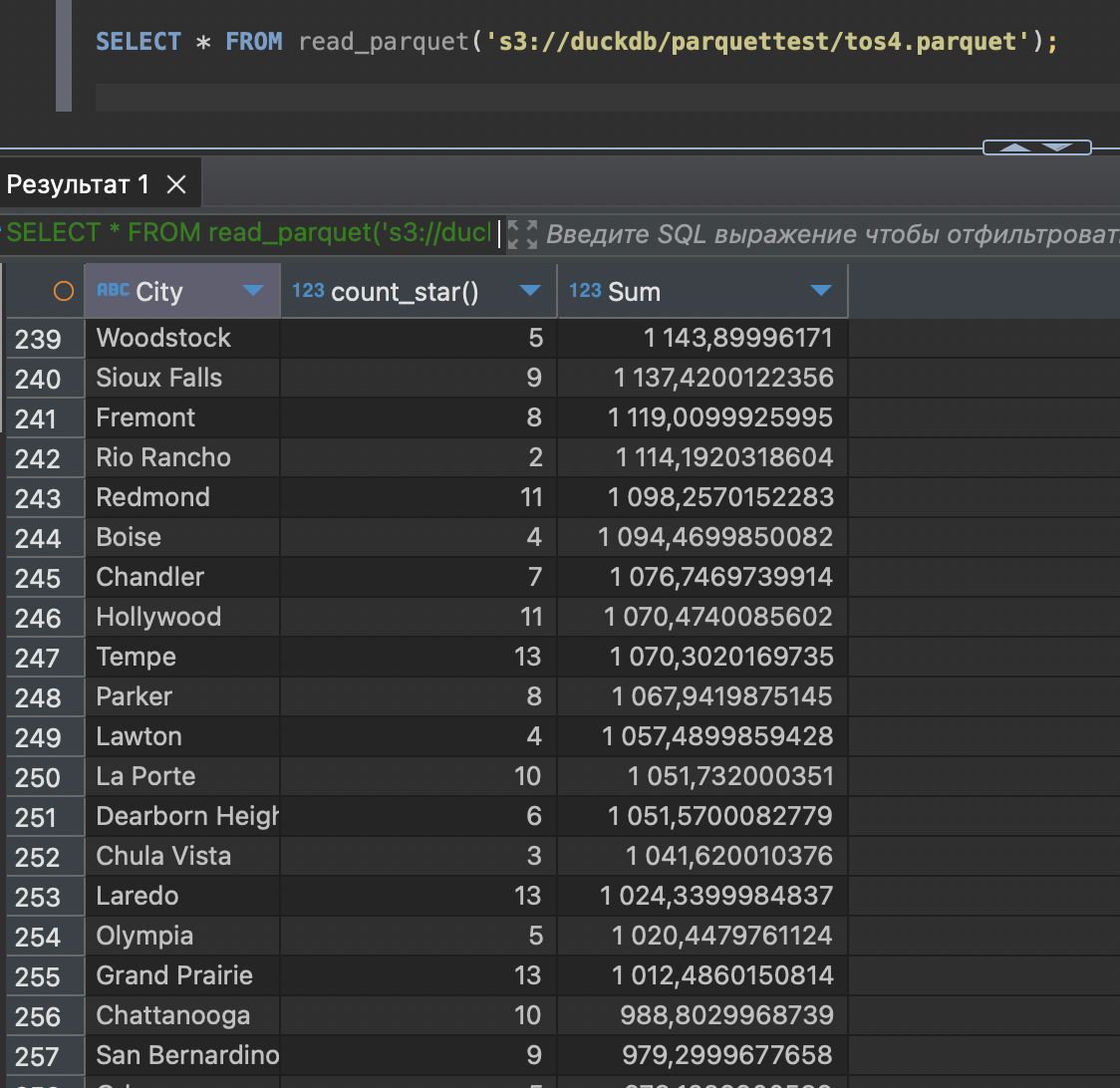
Работает.
ну и пробуем писать в postgres.
CREATE table db.public.test2 as SELECT * FROM read_parquet('s3://duckdb/parquettest/tos4.parquet');Сходу не получилось
Ошибка:
SQL Error: Invalid Error: Failed to prepare COPY "
COPY (SELECT "City", "count_star()", "Sum" FROM "public"."test2" WHERE ctid BETWEEN '(0,0)'::tid AND '(4294967295,0)'::tid) TO STDOUT (FORMAT binary);
": ERROR: column "City" does not exist
LINE 2: COPY (SELECT "City", "count_star()", "Sum" FROM "public"."t...
^
HINT: Perhaps you meant to reference the column "test2.city".Попробуем чуть попроще типы указать и наименования полей. Вдруг поможет. Для начала так:
SELECT City, "count_star()" Cnt, ceiling(Sum) Sum FROM read_parquet('s3://duckdb/parquettest/tos4.parquet');Запрос отработал, но это пока еще ничего не значит.
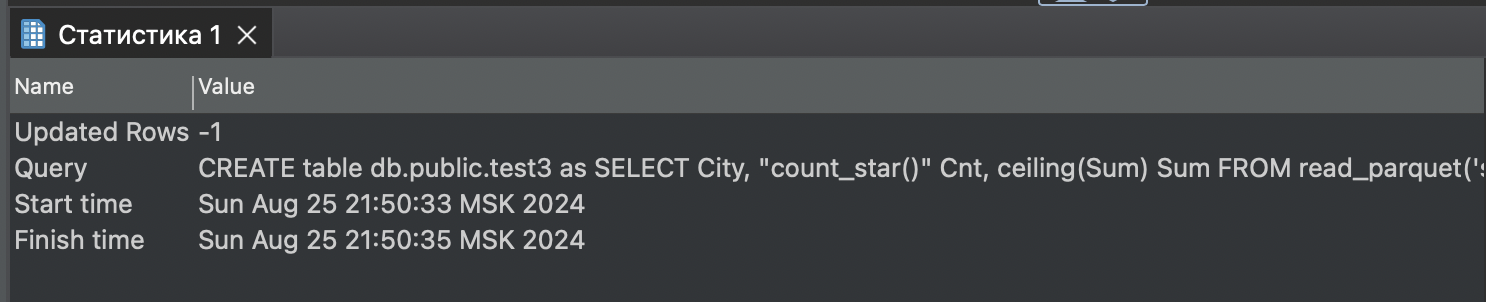
Пробуем select но он не хочет.
SQL Error: Invalid Error: Failed to prepare COPY "
COPY (SELECT "City", "Cnt", "Sum" FROM "public"."test3" WHERE ctid BETWEEN '(0,0)'::tid AND '(4294967295,0)'::tid) TO STDOUT (FORMAT binary);
": ERROR: column "City" does not exist
LINE 2: COPY (SELECT "City", "Cnt", "Sum" FROM "public"."test3" WHE...
^
HINT: Perhaps you meant to reference the column "test3.city".А если через COPY? Тоже не получилось, написал что то такое.
copy (SELECT City, "count_star()" Cnt, ceiling(Sum) Sum FROM read_parquet('s3://duckdb/parquettest/tos4.parquet')) TO db.public.test4
SQL Error: java.sql.SQLException: Parser Error: syntax error at or near "."
org.jkiss.dbeaver.model.sql.DBSQLException: SQL Error: java.sql.SQLException: Parser Error: syntax error at or near "."
at org.jkiss.dbeaver.model.impl.jdbc.exec.JDBCStatementImpl.executeStatement(JDBCStatementImpl.java:133)
at org.jkiss.dbeaver.ui.editors.sql.execute.SQLQueryJob.executeStatement(SQLQueryJob.java:615)
at org.jkiss.dbeaver.ui.editors.sql.execute.SQLQueryJob.lambda$2(SQLQueryJob.java:506)
at org.jkiss.dbeaver.model.exec.DBExecUtils.tryExecuteRecover(DBExecUtils.java:192)
at org.jkiss.dbeaver.ui.editors.sql.execute.SQLQueryJob.executeSingleQuery(SQLQueryJob.java:525)
at org.jkiss.dbeaver.ui.editors.sql.execute.SQLQueryJob.extractData(SQLQueryJob.java:977)
at org.jkisА вот первый пример заработает как-то))
select * from db.public.test2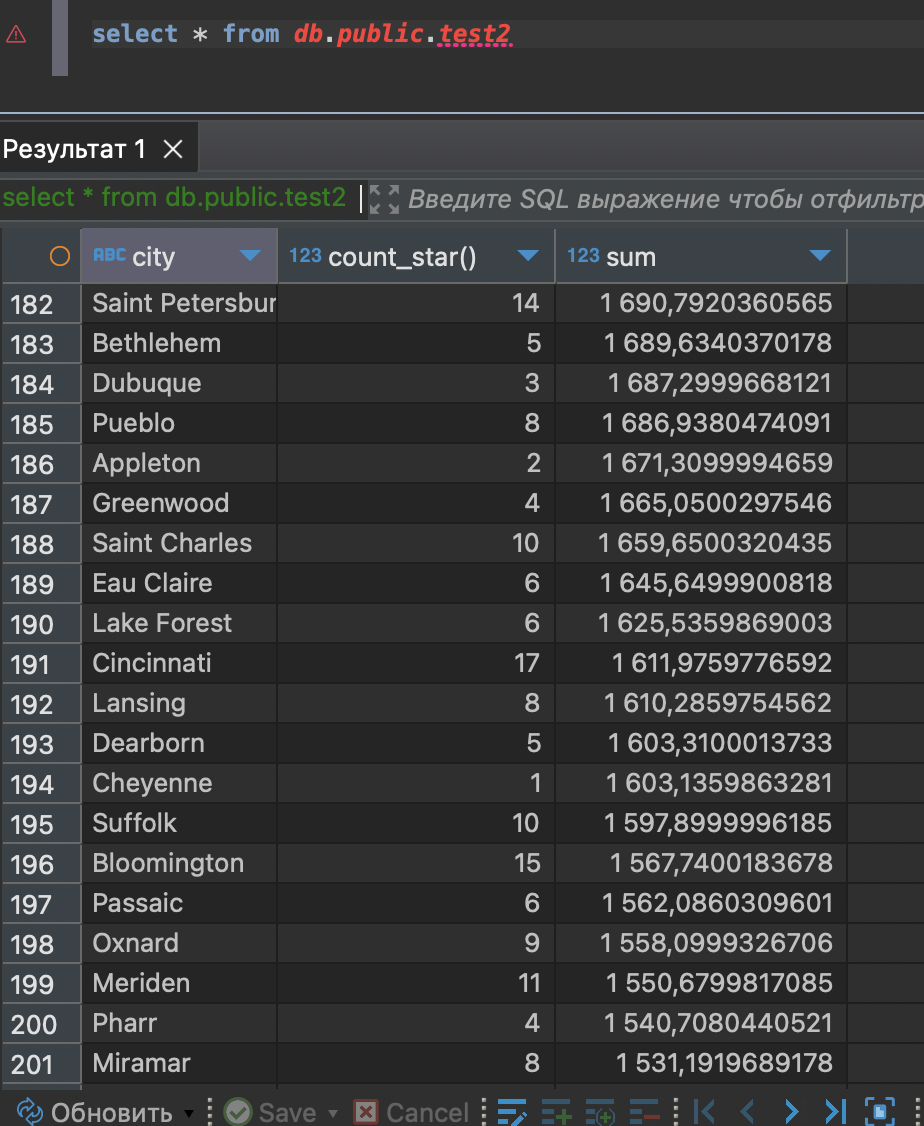
Пробуем еще раз:
CREATE table db.public.test5 as SELECT City, "count_star()" Cnt, ceiling(Sum) Sum FROM read_parquet('s3://duckdb/parquettest/tos4.parquet');ошибка на select * from db.public.test5
SQL Error: Invalid Error: Failed to prepare COPY "
COPY (SELECT "City", "Cnt", "Sum" FROM "public"."test5" WHERE ctid BETWEEN '(0,0)'::tid AND '(4294967295,0)'::tid) TO STDOUT (FORMAT binary);
": ERROR: column "City" does not exist
LINE 2: COPY (SELECT "City", "Cnt", "Sum" FROM "public"."test5" WHE...
^
HINT: Perhaps you meant to reference the column "test5.city".Хм)) ну как то же db.public.test2 заполнилась. Какая-то магия. Еще пока неизвестная.
Попробуем с того как начинали, но пока никак.
Кстати вот так работает: COPY db.public.test7 FROM ‘s3://duckdb/parquettest/tos4.parquet’;
Но прочитать таблицу все равно не дает.
Ну а вот и сама магия.
Если зайти в сам постгрес, то все Талицы на месте. и даже данные там есть.
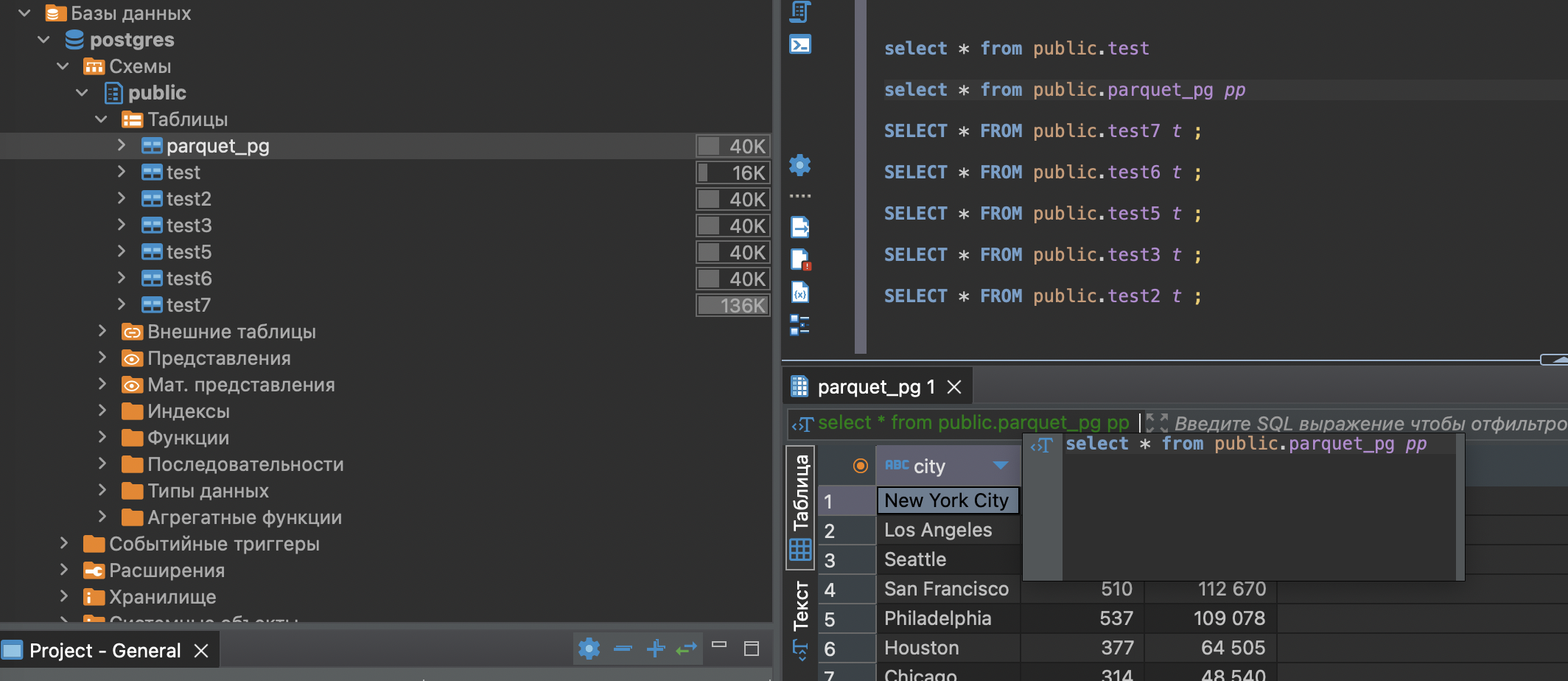
Вероятно есть еще некие ошибки при записи данных через приатачченый постгрес, но их скоро поправят.
Думаю если заново переаттачить это постгрес, то данные можно будет прочитать корректнее.
Ну да, так и получилось
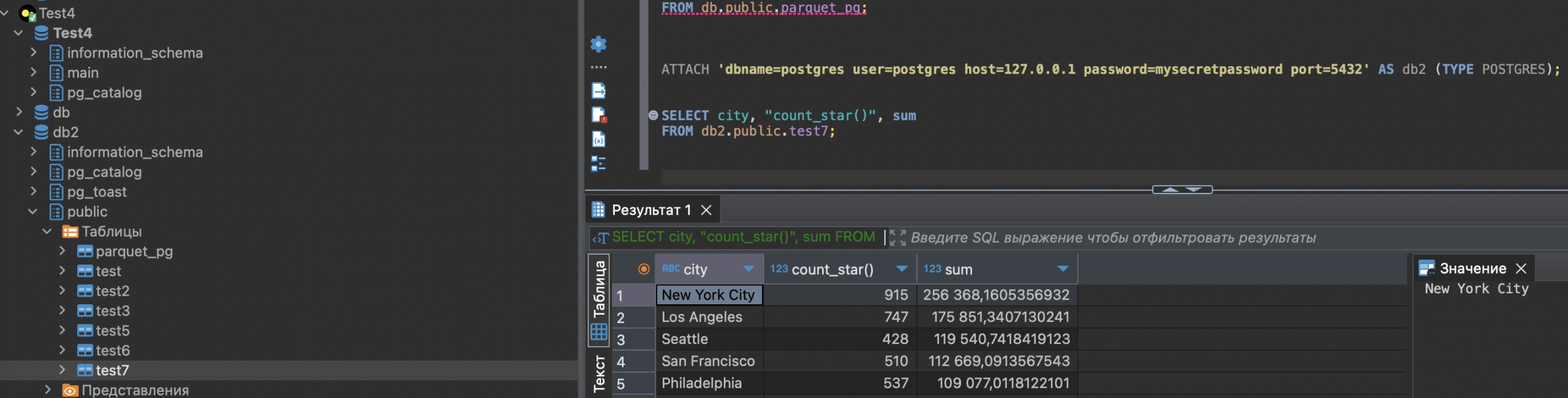
В общем вариант рабочий, но есть еще баги. Ждем фиксов.
Ну а следующий вебинар сделаю про “УТИлизацию Табло” – Будем готовить утку с Табло в s3шном соусе. :))
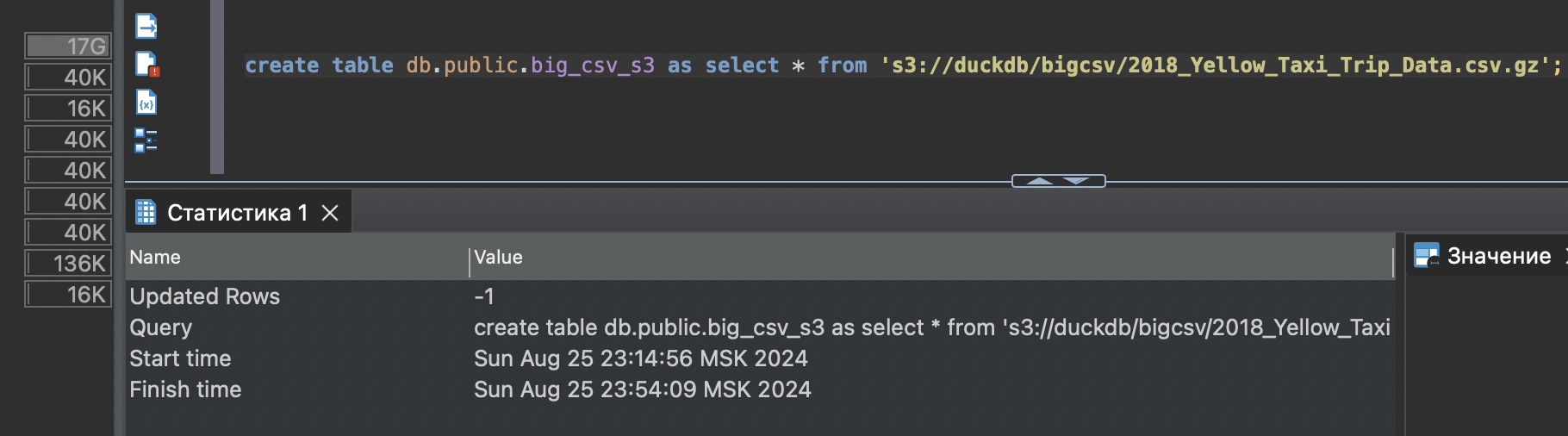
таблица большая в итоге загрузилась с s3.
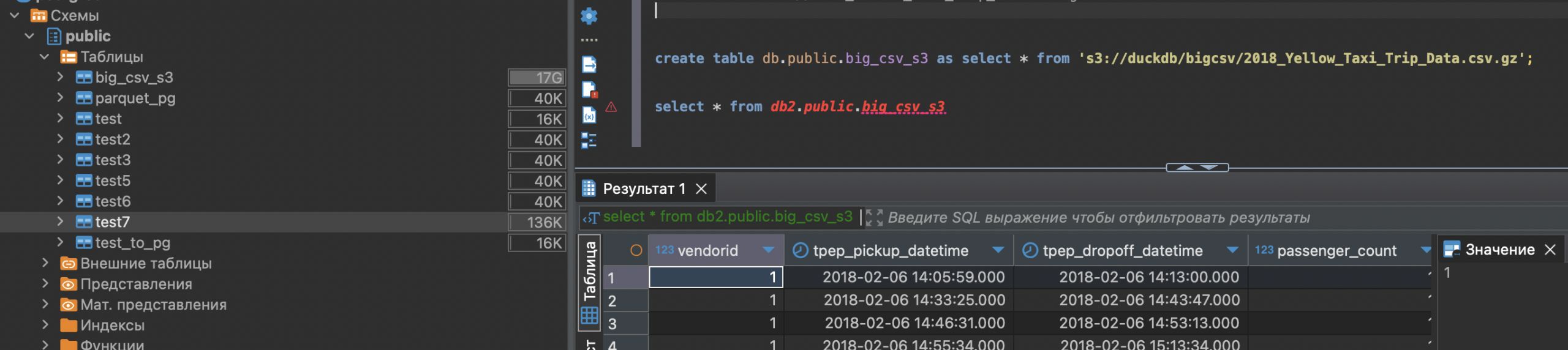
Долго было